
大模型应用开发实战:从Prompt工程到企业级RAG系统
个人名片
🎓作者简介:java领域优质创作者
🌐个人主页:码农阿豪
📞工作室:新空间代码工作室(提供各种软件服务)
💌个人邮箱:[2435024119@qq.com]
📱个人微信:15279484656
🌐个人导航网站:www.forff.top
💡座右铭:总有人要赢。为什么不能是我呢?

- 专栏导航:
码农阿豪系列专栏导航
面试专栏:收集了java相关高频面试题,面试实战总结🍻🎉🖥️
Spring5系列专栏:整理了Spring5重要知识点与实战演练,有案例可直接使用🚀🔧💻
Redis专栏:Redis从零到一学习分享,经验总结,案例实战💐📝💡
全栈系列专栏:海纳百川有容乃大,可能你想要的东西里面都有🤸🌱🚀
目录
《大模型应用开发实战:从Prompt工程到企业级RAG系统》
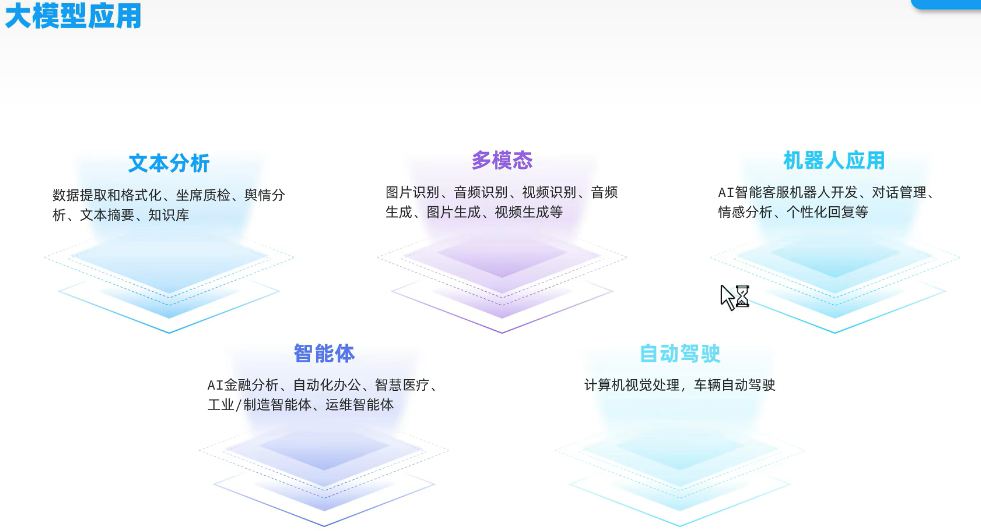
引言:AI应用开发范式革命
2024年Gartner技术成熟度曲线显示,大模型应用开发已越过炒作顶峰进入实质生产阶段。据最新行业调研:
- 采用RAG架构的企业同比增长320%
- Agent工作流在复杂任务中减少人工干预达57%
- 微调(Fine-tuning)成本下降76%(LoRA等技术的普及)
本指南将系统介绍:
- 开发范式迁移:从传统规则引擎到LLM中心的架构变革
- 性能基准:不同方案在客服/内容生成等场景的对比数据
- 企业落地路径:从POC到规模化部署的完整生命周期
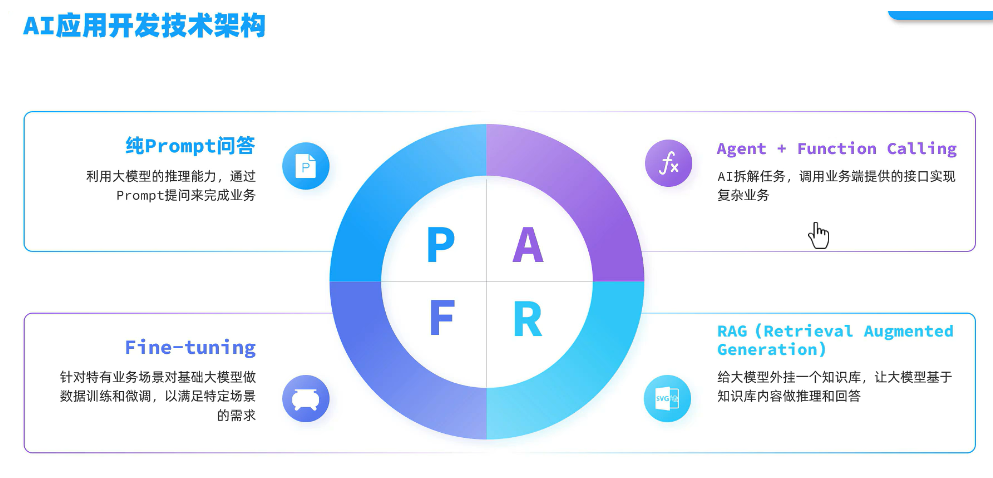
第一章:工业级Prompt工程体系
1.1 结构化提示设计框架
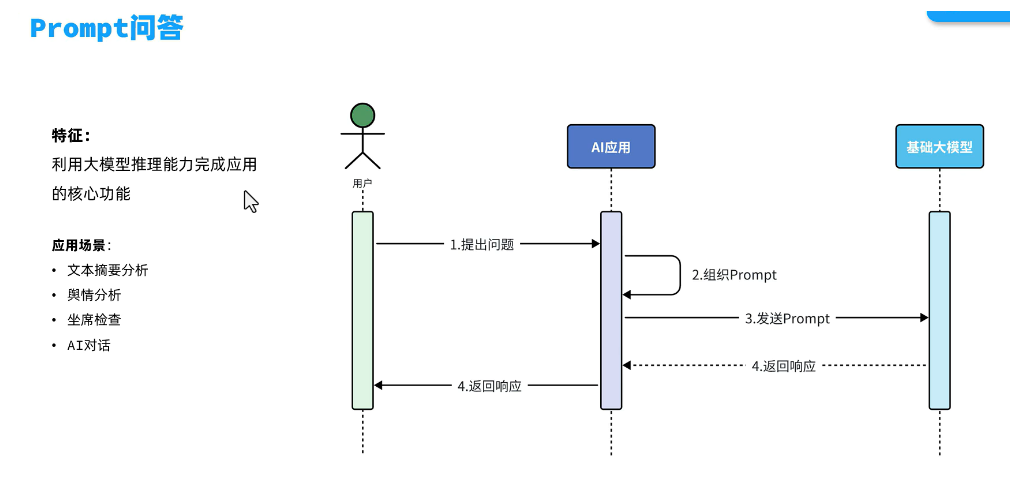
多层提示架构:
class EnterprisePrompt:
def __init__(self):
self.meta_prompt = """你是一位{role},请遵守以下规则:
- 响应语言:{language}
- 专业级别:{level}
- 安全限制:{safety}"""
self.task_prompt = {
'analysis': "请用{format}格式分析:{input}",
'generation': "根据{style}风格生成:{topic}"
}
def build(self, task_type, kwargs):
base = self.meta_prompt.format(kwargs)
return base + "\n\n" + self.task_prompt[task_type].format(kwargs)
# 使用示例
prompter = EnterprisePrompt()
prompt = prompter.build(
task_type='analysis',
role="金融分析师",
language="中文",
level="专家级",
safety="不提供投资建议",
format="Markdown表格",
input="2024Q2财报数据"
)
1.2 动态提示优化技术
实时质量评估系统:
def evaluate_prompt(response):
metrics = {
'relevance': cosine_sim(response, prompt),
'fluency': perplexity_score(response),
'safety': toxicity_detector(response)
}
return weighted_sum(metrics)
def adaptive_prompting(user_input, history):
context = analyze_conversation(history)
candidates = [
build_detail_prompt(user_input),
build_simple_prompt(user_input),
build_example_based_prompt(user_input)
]
return max(candidates, key=lambda x: predict_quality(x, context))
第二章:Function Calling生产实践
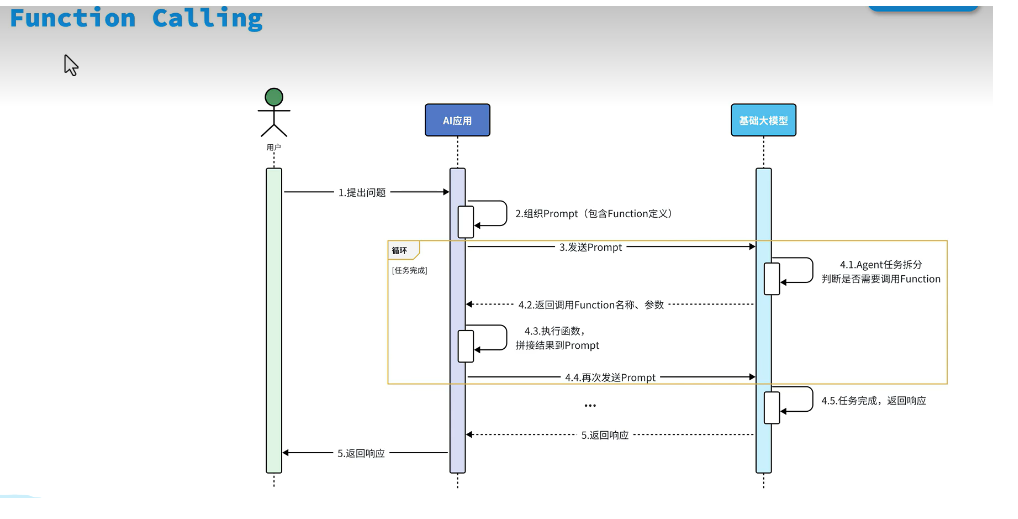
2.1 工具注册中心设计
class ToolRegistry:
def __init__(self):
self.tools = {}
def register(self, name, desc, params, func):
self.tools[name] = {
'description': desc,
'parameters': params,
'function': func
}
def generate_schema(self):
return [{
"name": name,
"description": info['description'],
"parameters": info['parameters']
} for name, info in self.tools.items()]
# 注册CRM查询工具
registry = ToolRegistry()
registry.register(
name="query_customer",
desc="查询客户信息",
params={
"customer_id": {"type": "string"},
"fields": {"type": "array", "items": {"type": "string"}}
},
func=lambda kwargs: crm_api.query(kwargs)
)
2.2 权限控制流水线
第三章:企业级RAG系统构建
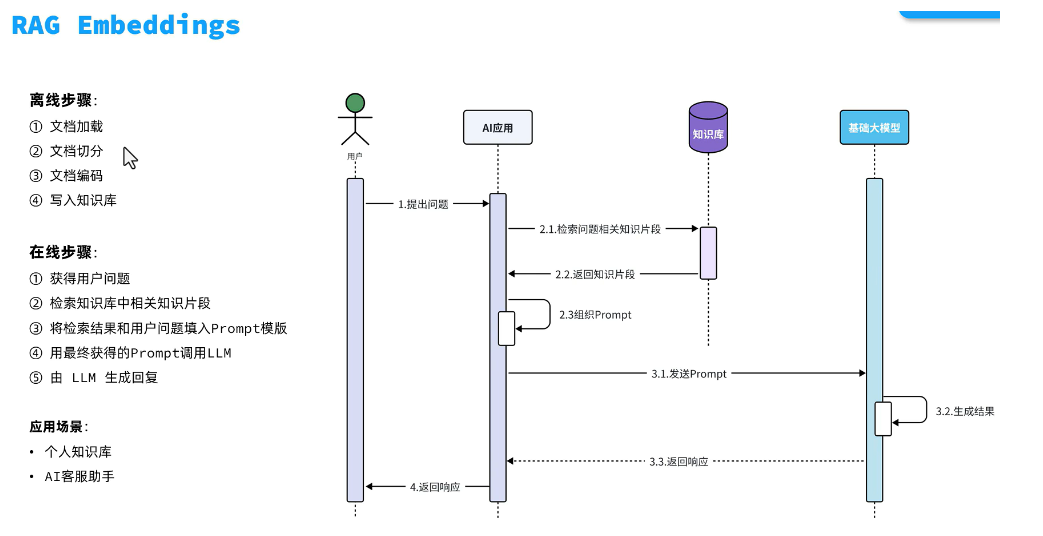
3.1 知识处理流水线
多模态文档处理架构:
class KnowledgeProcessor:
def __init__(self):
self.loaders = {
'.pdf': PDFLoader(),
'.docx': DocxLoader(),
'.pptx': PptxLoader(),
'.html': BeautifulSoupLoader()
}
self.splitter = SemanticSplitter(
chunk_size=1000,
breakpoint_threshold=0.65
)
def process(self, file_path):
ext = os.path.splitext(file_path)[1]
raw_text = self.loaders[ext].load(file_path)
return self.splitter.split(raw_text)
# 处理10种文件类型
processor = KnowledgeProcessor()
chunks = processor.process("年度报告.pdf")
3.2 混合检索策略
融合检索算法:
def hybrid_retrieval(query, k=5):
# 语义检索
semantic_results = vector_db.similarity_search(query, k=k2)
# 关键词检索
keyword_results = bm25_retriever.search(query, k=k2)
# 混合排序
combined = []
for doc in semantic_results + keyword_results:
semantic_score = cosine_sim(query, doc.embedding)
keyword_score = bm25_score(query, doc.text)
combined.append({
'doc': doc,
'score': 0.7semantic_score + 0.3keyword_score
})
return sorted(combined, key=lambda x: -x['score'])[:k]
第四章:智能体(Agent)系统工程
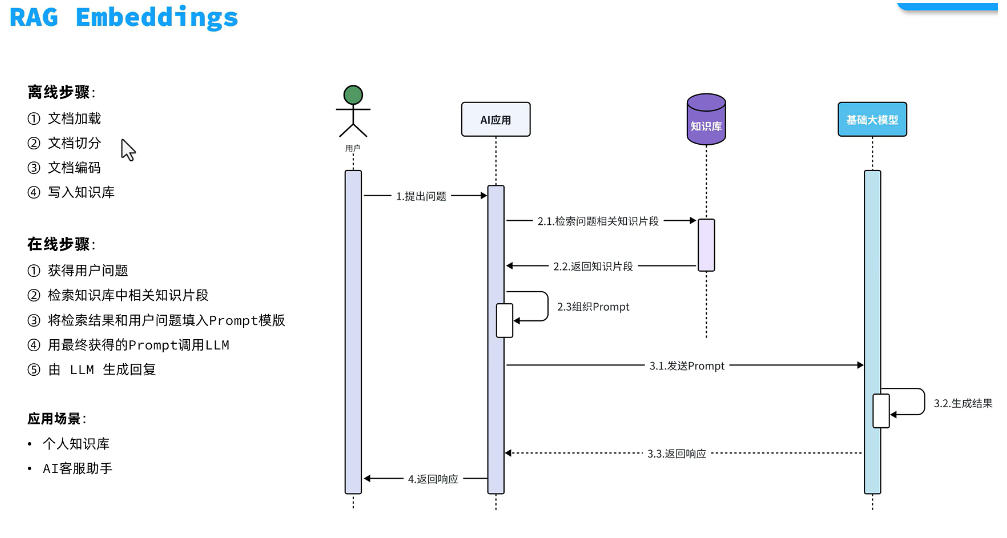
4.1 决策循环优化
基于规则的推理控制器:
class AgentController:
def __init__(self):
self.max_steps = 5
self.reasoning_modes = {
'direct': "直接回答问题",
'multi-step': "分步推理",
'tool-use': "使用工具"
}
def select_mode(self, query):
complexity = self.analyze_complexity(query)
if complexity < 0.3:
return 'direct'
elif 0.3 <= complexity < 0.6:
return 'multi-step'
else:
return 'tool-use'
def run_episode(self, query):
mode = self.select_mode(query)
for step in range(self.max_steps):
if mode == 'direct':
return llm.generate(query)
elif mode == 'multi-step':
# 思维链实现
pass
else:
# 工具调用流程
pass
4.2 企业级监控看板
关键监控指标:
| 指标名称 | 计算方式 | 预警阈值 |
|---|---|---|
| 工具调用成功率 | 成功次数/总调用次数 | <95% |
| 平均推理步数 | 总步数/会话数 | >5 |
| 知识检索准确率 | 相关文档数/返回总数 | <80% |
| 响应时间P99 | 99百分位耗时 | >3000ms |
第五章:生产环境优化策略
5.1 缓存加速方案
三级缓存架构:
class ResponseCache:
def __init__(self):
self.memory_cache = LRUCache(maxsize=1000)
self.redis_cache = RedisClient()
self.disk_cache = DiskCache()
def get(self, query):
# 内存→Redis→磁盘查询
for cache in [self.memory_cache, self.redis_cache, self.disk_cache]:
result = cache.get(query_hash(query))
if result:
return result
return None
def set(self, query, response):
# 同时写入三级缓存
for cache in [self.disk_cache, self.redis_cache, self.memory_cache]:
cache.set(query_hash(query), response)
5.2 负载测试方案
Locust压力测试脚本:
from locust import HttpUser, task
class LLMUser(HttpUser):
@task
def chat_task(self):
prompt = {
"model": "llama3-8b",
"messages": [{"role": "user", "content": "解释量子计算"}]
}
self.client.post("/v1/chat/completions", json=prompt)
@task(3)
def retrieval_task(self):
self.client.get("/v1/retrieval?query=2024市场趋势")
未来架构演进
- 多Agent协作:Agent Swarm技术实现复杂任务分解
- 自优化系统:在线学习自动改进prompt/tools
- 具身智能:物理世界动作规划集成
- 合规架构:自动生成审计追踪报告
开发者资源宝库
-
企业级框架:
# 全栈开发环境 pip install langchain==0.1.0 llama-index==0.9.0 trulens==0.8.0 -
测试数据集:
- HotpotQA(复杂问答)
- Natural Questions(开放域问答)
- CUAD(法律合同理解)
-
性能工具:
- LangSmith(LLM调用追踪)
- Weights & Biases(实验管理)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号