
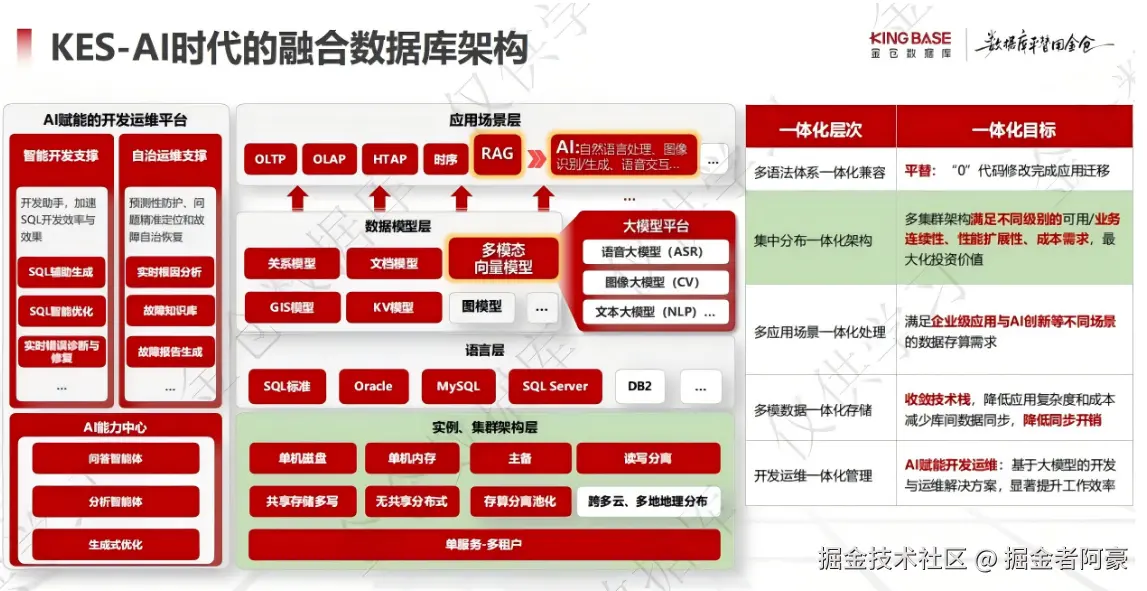
融合之力:金仓数据库“五个一体化“如何重塑国产数据库生态
目录
融合之力:金仓数据库“五个一体化”如何重塑国产数据库生态
在一次银行系统迁移项目中,我们意外发现,原本预计需要三个月的数据库迁移工作,因为金仓数据库的多语法兼容特性,竟然在六周内就完成了——这让我对国产数据库的实用性刮目相看。
在数字化转型的浪潮中,数据库作为IT架构的核心基石,正面临着前所未有的挑战。作为一名长期深耕数据库领域的技术人,我亲眼见证了国产数据库从“能用”到“好用”的蜕变。今天,当我们在讨论金仓数据库的“五个一体化”理念时,我们实际上在探讨一个更深层次的问题:国产数据库如何在激烈的市场竞争中找到自己的差异化优势?
数据库发展的十字路口:融合与专精的抉择
记得去年参与某大型国企的数字化改造项目时,技术栈中竟然同时包含了Oracle、MySQL、MongoDB和Redis四种数据库。运维团队苦不堪言——数据同步困难、运维复杂度高、成本居高不下。项目经理无奈地告诉我:“每次业务需求变更,我们都要协调四个不同的数据库团队,就像在指挥一支各自为战的乐队。”
这正是金仓提出“五个一体化”理念的现实背景。在数据库技术发展的道路上,我们经历了从“一刀切”到“专业化”再到“融合化”的螺旋式上升。而金仓的“五个一体化”,恰恰抓住了当前企业数字化转型中最痛的痛点。
多语法一体化:平滑迁移的“隐形桥梁”
在实际的数据库迁移中,语法兼容性往往是最大的“拦路虎”。我曾经见过团队为了修改存储过程中的语法差异,连续加班数个星期。而金仓的多语法一体化,就像是给不同数据库方言的使用者搭建了一座沟通的桥梁。
-- 场景:银行核心系统迁移中的真实案例
-- 原Oracle分页查询(数千个类似语句需要迁移)
SELECT *
FROM (SELECT t.*, ROWNUM rn
FROM (SELECT * FROM transaction_log
WHERE trans_date >= DATE'2023-01-01'
ORDER BY trans_date DESC) t
WHERE ROWNUM <= 100)
WHERE rn > 0;
-- 在金仓中,除了支持原Oracle语法外,还可以用更简洁的方式实现
SELECT * FROM transaction_log
WHERE trans_date >= '2023-01-01'::date
ORDER BY trans_date DESC
LIMIT 100 OFFSET 0;
-- 甚至支持SQL Server风格的语法
SELECT TOP 100 * FROM transaction_log
WHERE trans_date >= '2023-01-01'
ORDER BY trans_date DESC;
某城商行的迁移案例让我印象深刻:由于历史原因,他们的业务系统包含了Oracle、DB2和MySQL三种不同风格的SQL语句。通过金仓的多语法兼容能力,迁移团队不需要重写大部分SQL代码,仅用了预期时间的60%就完成了整体迁移,而且几乎没有出现语法兼容性问题。
多模数据一体化:打破数据孤岛的“瑞士军刀”
在政务大数据项目中,我们经常遇到这样的困境:关系型数据存放在Oracle中,文档数据在MongoDB中,图数据又需要Neo4j来处理。数据要在多个系统间流转,不仅效率低下,还增加了系统的复杂性。
金仓的多模数据一体化提供了一种全新的解决方案:
-- 智慧城市项目中的真实应用场景
-- 统一管理公民基本信息(关系型)、扩展信息(JSON)、空间数据(GIS)和社交关系(图数据)
-- 1. 传统关系型数据操作
CREATE TABLE citizens (
id BIGINT PRIMARY KEY,
id_card VARCHAR(18),
create_time TIMESTAMP
);
-- 2. JSON文档数据(存储动态扩展字段)
INSERT INTO citizens VALUES (
1, '110101199001011234', NOW(),
'{"name": "张三", "contact": {"mobile": "13800138000", "wechat": "zhangsan2023"},
"education": [{"school": "北京大学", "degree": "本科"},
{"school": "清华大学", "degree": "硕士"}],
"preferences": {"news_category": ["科技", "财经"], "notification_enabled": true}}'
);
-- 3. 图关系查询(查找二度人脉)
-- 张三 -> 李四 -> 王五 的关系链
SELECT graph_query('
MATCH (c1:Citizen)-[:FRIEND]->(c2:Citizen)-[:FRIEND]->(c3:Citizen)
WHERE c1.id = 1 AND NOT (c1)-[:FRIEND]->(c3)
RETURN c3.name as recommended_friend,
COUNT(*) as common_friends
ORDER BY common_friends DESC
');
-- 4. 空间数据查询(查找5公里范围内的服务设施)
SELECT facility_name, ST_Distance(location, ST_GeomFromText('POINT(116.4 39.9)')) as distance
FROM service_facilities
WHERE ST_DWithin(location, ST_GeomFromText('POINT(116.4 39.9)'), 5000)
ORDER BY distance;
某省会城市的“一网通办”平台采用这种多模一体化架构后,成功将原本分散在多个数据库系统中的数据进行统一管理。项目负责人反馈说:“现在查询公民完整信息,再也不需要在多个系统间跳转了,处理时间从原来的分钟级降低到秒级。”
多应用场景一体化:HTAP的实战价值
传统架构中,OLTP和OLAP系统往往是分离的——白天业务系统处理交易,夜间数据仓库执行分析。但这种模式越来越难以满足实时业务决策的需求。
某电商平台的案例很好地诠释了HTAP的实际价值:
-- 双十一大促期间的实时监控看板
-- OLTP:处理海量并发交易
BEGIN;
-- 用户下单
INSERT INTO orders (order_id, user_id, product_id, quantity, price, status)
VALUES (20231111000001, 123456, 888, 2, 2999.00, '待付款');
-- 库存扣减
UPDATE products SET stock = stock - 2 WHERE product_id = 888;
-- 积分预扣
UPDATE users SET pending_points = pending_points + 59
WHERE user_id = 123456;
COMMIT;
-- 与此同时,OLAP:实时分析大屏数据
-- 监控大屏1:实时销售趋势
SELECT
DATE_TRUNC('minute', create_time) as time_slot,
COUNT(*) as order_count,
SUM(price * quantity) as gmv,
COUNT(DISTINCT user_id) as uv
FROM orders
WHERE create_time >= NOW() - INTERVAL '1 hour'
GROUP BY DATE_TRUNC('minute', create_time)
ORDER BY time_slot DESC;
-- 监控大屏2:热销商品排行
SELECT
p.product_name,
p.category,
COUNT(*) as sale_count,
SUM(o.quantity) as total_quantity,
SUM(o.price * o.quantity) as sale_amount
FROM orders o JOIN products p ON o.product_id = p.product_id
WHERE o.create_time >= NOW() - INTERVAL '30 minutes'
AND o.status != '已取消'
GROUP BY p.product_id, p.product_name, p.category
ORDER BY sale_amount DESC
LIMIT 20;
-- 监控大屏3:实时风险监控(检测异常购买行为)
SELECT
user_id,
COUNT(*) as order_count,
SUM(price * quantity) as total_amount,
AVG(price * quantity) as avg_amount
FROM orders
WHERE create_time >= NOW() - INTERVAL '10 minutes'
GROUP BY user_id
HAVING COUNT(*) > 10 OR SUM(price * quantity) > 100000;
该电商平台的技术总监告诉我:“通过金仓的HTAP能力,我们在处理每秒数万笔交易的同时,还能为运营团队提供秒级延迟的数据看板。去年双十一,我们基于实时数据调整营销策略,转化率提升了3个百分点。”
集中分布一体化:架构灵活性的智慧
企业的业务发展往往存在不确定性,今天可能只需要单机部署,明天可能就需要分布式集群。金仓的集中分布一体化架构,为企业提供了平滑演进的技术路径。
某证券公司的案例很好地展示了这种架构优势:
-- 初期:单机架构满足业务需求
-- 创建核心业务表
CREATE TABLE stock_transactions (
id BIGSERIAL PRIMARY KEY,
account_id VARCHAR(20),
stock_code VARCHAR(6),
trade_type VARCHAR(4),
price DECIMAL(10,2),
quantity INTEGER,
trade_time TIMESTAMP
);
-- 业务增长后,平滑升级到读写分离集群
-- 写节点
INSERT INTO stock_transactions (account_id, stock_code, trade_type, price, quantity, trade_time)
VALUES ('1234567890', '000001', 'BUY', 15.60, 1000, NOW());
-- 读节点(负载均衡)
SELECT stock_code, COUNT(*) as trade_count, SUM(quantity) as total_volume
FROM stock_transactions
WHERE trade_time >= CURRENT_DATE
GROUP BY stock_code
ORDER BY total_volume DESC;
-- 业务爆发式增长,升级到分布式集群
-- 创建分片表(按账户ID哈希分片)
CREATE TABLE distributed_transactions (
id BIGINT,
account_id VARCHAR(20),
stock_code VARCHAR(6),
-- 其他字段...
shard_key account_id -- 指定分片键
) PARTITION BY HASH(account_id);
-- 自动路由查询
-- 查询特定用户的交易记录(路由到单个分片)
SELECT * FROM distributed_transactions
WHERE account_id = '1234567890'
AND trade_time >= '2023-11-01';
-- 全量统计分析(并行查询所有分片)
SELECT
trade_type,
COUNT(*) as transaction_count,
SUM(price * quantity) as total_amount
FROM distributed_transactions
WHERE trade_time >= CURRENT_DATE
GROUP BY trade_type;
该证券公司的技术负责人分享道:“我们的用户数从百万级发展到千万级,通过金仓的集中分布一体化架构,实现了从单机到集群的平滑过渡,期间业务几乎没有感知。这种架构弹性为我们节省了大量的前期投入成本。”
开发运维一体化:效率提升的工程实践
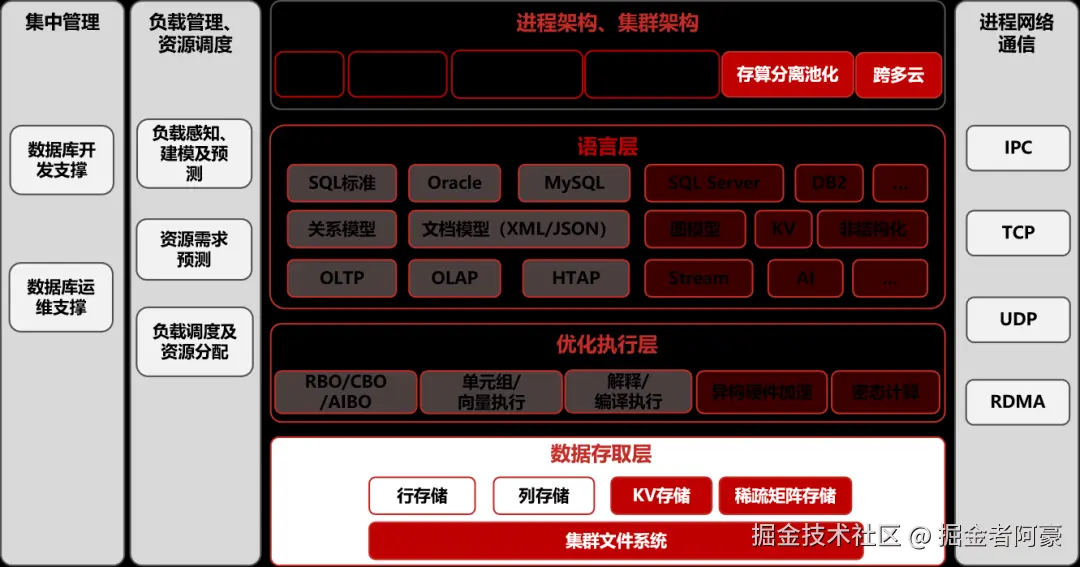
在传统的数据库管理模式下,开发和运维往往是割裂的——开发人员写出SQL,DBA审核执行,出现问题再互相推诿。金仓通过KES Plus等工具平台,真正实现了DevOps的理念。
某大型互联网企业的实践很有代表性:
-- SQL审核自动化:将最佳实践固化为规则
CREATE OR REPLACE FUNCTION sql_review_automation(sql_text TEXT, db_role TEXT)
RETURNS TABLE(rule_name TEXT, violation_level INT, suggestion TEXT) AS $$
BEGIN
-- 规则1:禁止无WHERE条件的UPDATE/DELETE(生产环境)
IF db_role = 'production' AND (
sql_text ~* '^\s*UPDATE\s+\w+\s+SET' AND sql_text !~* 'WHERE' OR
sql_text ~* '^\s*DELETE\s+FROM' AND sql_text !~* 'WHERE'
) THEN
RETURN QUERY SELECT '全表更新删除检查', 1,
'生产环境禁止执行无WHERE条件的UPDATE/DELETE操作';
END IF;
-- 规则2:索引使用建议
IF sql_text ~* 'WHERE.*(\w+\.\w+)\s*[=<>]' THEN
RETURN QUERY SELECT '索引使用检查', 2,
'建议为条件字段创建索引: ' ||
(SELECT STRING_AGG(match[1], ', ') FROM
regexp_matches(sql_text, 'WHERE.*?(\w+\.\w+)\s*[=<>]', 'g') AS match);
END IF;
-- 规则3:查询性能预警
IF sql_text ~* 'SELECT.*FROM.*WHERE.*OR.*WHERE' THEN
RETURN QUERY SELECT 'OR条件优化', 2,
'考虑使用UNION替代OR条件以提高查询性能';
END IF;
END;
$$ LANGUAGE plpgsql;
-- 智能运维监控:基于历史数据的预测性维护
CREATE MATERIALIZED VIEW db_health_predictive AS
SELECT
'connection_trend' as metric_type,
time_bucket('1 hour', log_time) as time_window,
COUNT(*) as connection_count,
-- 基于历史数据预测未来1小时连接数
ai_predict('connection_forecast',
ARRAY[EXTRACT(HOUR FROM log_time)::real,
EXTRACT(DOW FROM log_time)::real],
connection_count) as predicted_1h
FROM connection_log
WHERE log_time >= NOW() - INTERVAL '7 days'
GROUP BY time_bucket('1 hour', log_time')
UNION ALL
SELECT
'query_performance' as metric_type,
query_pattern as time_window,
PERCENTILE_CONT(0.95) WITHIN GROUP (ORDER BY execution_time) as p95_time,
ai_predict('performance_risk',
ARRAY[query_complexity::real, data_volume::real],
p95_time) as risk_score
FROM query_performance_log
GROUP BY query_pattern;
该企业的数据库团队负责人告诉我:“通过开发运维一体化平台,我们将数据库变更的平均处理时间从4小时缩短到15分钟,DBA从繁重的审核工作中解放出来,更多地投入到架构优化工作中。”
总结:融合创新的现实意义
回顾金仓数据库的“五个一体化”理念,我认为其核心价值在于解决了企业数字化转型中的几个关键矛盾:
技术债务与创新速度的矛盾。多语法一体化和集中分布一体化让企业能够充分利用现有技术资产,降低迁移成本,加快创新步伐。
数据孤岛与业务协同的矛盾。多模数据一体化和多应用场景一体化打破了数据壁垒,实现了数据的统一管理和实时价值挖掘。
开发效率与运维稳定的矛盾。开发运维一体化在保证系统稳定性的前提下,显著提升了开发交付效率。
在某大型制造业的数字化转型项目中,CIO的一番话让我印象深刻:“选择金仓不是因为它某个单点技术特别突出,而是因为它的一体化架构真正解决了我们面临的实际问题。现在我们的数据团队可以更专注于业务创新,而不是整天解决技术兼容性问题。”
未来,随着云原生、AI大模型等技术的发展,我相信这种一体化、智能化的数据库架构将成为主流。金仓的“五个一体化”理念,不仅为国产数据库的发展提供了新的思路,也为全球数据库技术的演进贡献了中国智慧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号