
绿色引擎:金仓数据库如何驱动新能源产业数字化转型
绿色引擎:金仓数据库在新能源数字化一线的真实表现
这几年新能源行业扩张得太快了。
风电、光伏、储能,几乎每个省都在上项目,装机容量一再刷新纪录。表面看是设备在跑,本质上是 数据在撑着整个系统不出事。
我真正开始重视新能源数据库,是从一次风电场事故复盘开始的——不是设备坏了,而是监控数据延迟,调度判断失误,直接造成弃风。
那次之后我才意识到:新能源系统对数据库的要求,和传统业务系统完全是两个量级。
一、新能源系统最怕的,从来不是“慢”,而是“晚”
在一次新能源信息化技术交流会上,一家风电集团的技术负责人提到:
某次大风天气,场站功率实时数据延迟了十几秒,调度侧误判出力情况,错过最佳并网窗口,直接造成经济损失。
问题最后定位出来,不是算法,也不是硬件,而是:
- 实时数据写入撑不住
- 查询延迟不断放大
- 告警滞后
新能源系统的残酷之处就在这:
你晚反应 10 秒,损失的不是 10 秒的数据,是一整段发电周期。
二、新能源业务对数据库,本质上就三句话要求
不是“高性能”“高扩展”这类口号,而是非常直白的三点:
- 测点再多,也不能卡
- 场站再分散,数据也要统一
- 不能停,基本不能丢
这三条,决定了数据库选型不可能只看参数表。
三、实时数据写入:不是技术难,而是“量级难”
一个中型风电场,动辄上千个测点:
- 有功功率
- 电压、电流
- 设备温度
- 健康状态
而这些数据不是“偶尔写一次”,是秒级、甚至亚秒级持续写入。
在实际项目中,这类表基本都会按时间分区:
CREATE TABLE renewable_monitoring_data (
data_id BIGSERIAL PRIMARY KEY,
station_id VARCHAR(50),
device_id VARCHAR(100),
data_type VARCHAR(50),
data_value DECIMAL(10,4),
data_quality INTEGER,
timestamp TIMESTAMP
) PARTITION BY RANGE (timestamp);
最关键的不是建表,而是两点:
- 分区一定要控制容量,不然后面必爆
- 索引永远围绕 station_id + 时间
CREATE INDEX idx_monitoring_realtime
ON renewable_monitoring_data (station_id, data_type, timestamp);
这种结构,本质就是一句话:
我宁愿让存储复杂一点,也不能让调度查询慢。
四、场站分布全国,数据库必须“天生分布式”
新能源不是集中式工厂,而是:
- 西北是风电
- 华北是风光互补
- 华东以光伏为主
- 南方还有水电、储能
如果数据还按“单中心”模式做,迟早会被拖垮。
CREATE TABLE renewable_stations (
station_id VARCHAR(50) PRIMARY KEY,
station_type VARCHAR(20),
region_code VARCHAR(20),
capacity_mw DECIMAL(10,2),
longitude DECIMAL(9,6),
latitude DECIMAL(8,6)
);
真实项目里,常见套路是:
- 省内先聚合
- 全国做总汇总
- 调度只查“结果视图”
不是技术炫技,而是 为了防止一个省的波动拖垮全国系统。
五、新能源系统最严的一条红线:不能停
在新能源生产系统里,“短暂停机”这个说法几乎是不存在的。
停了就是事故。
金仓在这些项目里真正被认可的,不是功能,是这件事:
主节点真断了,备节点能不能在几十秒内顶上?
SELECT node_name, node_role, sync_state, replay_lag
FROM sys_stat_replication;
真实演练数据里,
RTO 压在 30 秒内,RPO 基本为 0,这才算达标。
六、中广核 600+ 场站统一运维:拼的不是技术,是“体系”
600 多个新能源场站,6000 多运维人员,所有工单、巡检、告警全部走一个平台。
统一运维平台架构如下:
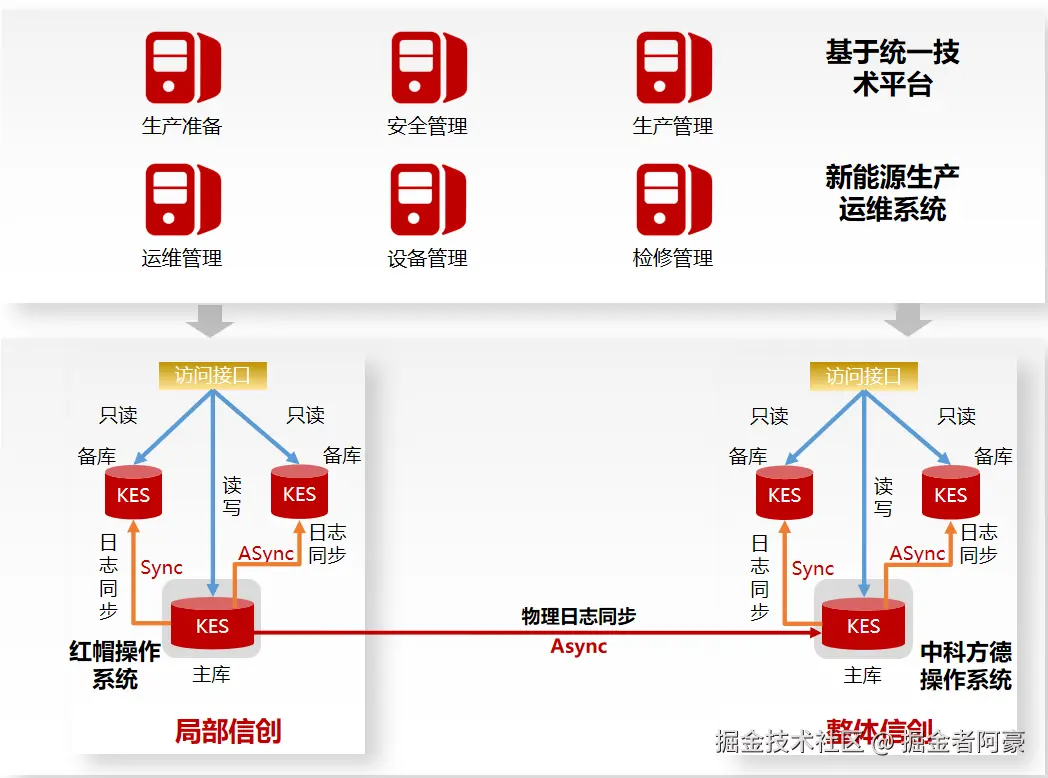
工单表长这样:
CREATE TABLE maintenance_workorders (
workorder_id BIGSERIAL PRIMARY KEY,
station_id VARCHAR(50),
workorder_type VARCHAR(50),
priority INTEGER,
status VARCHAR(20),
created_time TIMESTAMP
) PARTITION BY RANGE (created_time);
真正难的不是字段设计,而是:
- 数据持续膨胀
- 状态变更极其频繁
- 统计口径天天被业务调整
所以后期大量依赖:
- 分区裁剪
- 异步统计
- 预计算视图
否则月报直接能把系统拖死。
七、多源数据迁移:真正难的是“谁敢拍板切换”
新能源的信息系统历史包袱极重:
- MySQL 管基础业务
- Postgres 管调度
- MongoDB 管监控
- ES 管日志
迁移过程中,最关键的不是技术工具,而是这两条 SQL:
SELECT COUNT(*) FROM mysql_customers@mysql_link;
SELECT COUNT(*) FROM customers;
就这么简单。
只要对不上,谁都不敢签切换确认。
八、国家电投甘肃集控:无人值守靠的不是“人少”,是“系统稳”
无人值守并不是“真没人”,而是:
- 异常能不能自动识别
- 告警能不能自动收敛
- 预测性维护能不能提前预警
CREATE TABLE realtime_alerts (
alert_id BIGSERIAL PRIMARY KEY,
equipment_id VARCHAR(100),
alert_level VARCHAR(20),
trigger_time TIMESTAMP
);
真正决定运维效率的不是报多少警,而是:
- 一堆低等级告警能不能自动压缩
- 真正的致命告警能不能 1 秒内弹到人眼前
九、龙源电力 186 个场站:问题从来不在“单点性能”
186 个场站、27 个省区,这种体量的系统:
- 单库性能早就不是瓶颈
- 真正的难点是 跨省调度 + 汇总口径统一
CREATE TABLE regional_power_summary (
region_code VARCHAR(20),
summary_date DATE,
total_capacity_mw DECIMAL(12,2),
actual_generation_mwh DECIMAL(12,2),
availability_factor DECIMAL(5,4)
);
所有报表最终只认这一张汇总表。
底层跑得多复杂,对调度来说并不重要。
十、智能运维不是“上 AI”,而是“少背锅”
很多人理解的智能运维,就是“接个算法模型”。
但在新能源项目里,真正有价值的是:
- 是否能提前发现趋势问题
- 是否能在事故前 10 分钟预警
- 是否能让运维少背一次锅
SELECT
SUM(CASE WHEN mean_time > 1000 THEN 1 ELSE 0 END)
FROM sys_stat_statements;
慢查询比例一抬头,说明系统已经开始“疲劳”了。
十一、AI 预测和云边协同,本质还是为“调度更稳”
功率预测不是为了好看,是为了:
- 减少弃风
- 提高并网成功率
- 让调度敢决策
CREATE TABLE ai_predictions (
station_id VARCHAR(50),
prediction_time TIMESTAMP,
predicted_value DECIMAL(10,4),
confidence_level DECIMAL(3,2)
);
云边协同更不是概念,而是解决:
- 场站网络不稳定
- 电网调度实时性要求极高
- 边缘侧必须“先活下来”
结语:新能源拼到最后,拼的其实是“底座是否可靠”
从中广核的 600+ 场站,到国家电投的无人值守,再到龙源电力的跨省集控,这些项目有个共同特征:
- 业务极重
- 事故容忍度极低
- 出问题就是社会级影响
金仓现在所处的位置,已经不是“能不能用”,而是:
“顶不顶得住国家级新能源系统长期压测。”
至少从这些已经落地的项目来看,它已经站在这个门槛之内。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号