
从边缘到核心:我看金仓数据库如何扛起发电行业的“数字化大梁”
从边缘到核心:我看金仓数据库如何扛起发电行业的“数字化大梁”
在电力圈摸爬滚打这么多年,如果倒退十年,你跟我说国产数据库能跑在发电的核心生产系统上,我大概率会持保留态度。但这两年,亲眼看着金仓数据库(Kingbase)在各大发电集团落地,从边缘业务一点点渗透到核心控制区,我不得不承认:那个“不敢用、不好用”的时代已经过去了。
今天想从技术人的角度,聊聊金仓是怎么在发电行业这个“容错率为零”的领域站稳脚跟的。
发电数字化:一场不能输的“走钢丝”
那些年我们遇到的技术“硬骨头”
记得有次在技术研讨会上,一位发电集团的CIO苦笑着说:“你们互联网行业崩了是用户体验问题,我们AGC(自动发电控制)要是崩了,那是电网安全事故。” 这话一点不夸张。实时数据库稍微卡顿几百毫秒,电网频率波动就可能这就反应不过来。
对于数据库来说,发电行业的核心诉求其实就三个字:快、准、稳。但要做到极致,全是坑。
核心系统的三大“生死线”
1. 实时性:毫秒级的生死时速
电网调度不等人。金仓在这里做的一个关键优化就是分区策略。数据量大不是问题,问题是怎么在海量数据里瞬间捞出最新的那一条。
这是我们常用的实时监控表设计,重点看分区和索引策略(这是血泪经验):
-- 发电实时监控表:千万别把所有数据堆在一个表里
CREATE TABLE power_generation_realtime (
data_id BIGSERIAL PRIMARY KEY,
plant_id VARCHAR(50) NOT NULL,
unit_id VARCHAR(100) NOT NULL,
data_type VARCHAR(50) NOT NULL, -- 功率、频率、电压等
data_value DECIMAL(10,4),
quality_flag INTEGER DEFAULT 1, -- 1代表好数,0代表坏数,清洗数据时很有用
timestamp TIMESTAMP(3) DEFAULT CURRENT_TIMESTAMP(3), -- 注意:这里必须精确到毫秒
-- 关键点:按时间分区,否则一个月后查询速度直接崩盘
PARTITION BY RANGE (timestamp)
);
-- 自动创建小时级分区(建议写个定时任务自动维护)
CREATE TABLE generation_realtime_20250115 PARTITION OF power_generation_realtime
FOR VALUES FROM ('2025-01-15 00:00:00') TO ('2025-01-15 01:00:00');
-- 针对热点查询的索引优化
CREATE INDEX idx_generation_realtime ON power_generation_realtime
(plant_id, unit_id, data_type, timestamp)
WHERE timestamp > NOW() - INTERVAL '1 hour'; -- 只索引最近一小时数据,保持索引轻量
-- 实时聚合视图:给大屏展示用的,直接查原表会死人的
CREATE MATERIALIZED VIEW plant_realtime_summary AS
SELECT
plant_id,
data_type,
AVG(data_value) as avg_value,
MAX(data_value) as max_value,
MIN(data_value) as min_value,
COUNT(*) as sample_count,
MAX(timestamp) as latest_sample
FROM power_generation_realtime
WHERE timestamp >= NOW() - INTERVAL '5 minutes'
AND quality_flag = 1
GROUP BY plant_id, data_type
WITH DATA;
2. 数据一致性:算错一分钱都是事故
电力现货交易和以前的计划电不一样,那是真金白银的实时买卖。数据不一致?等着吃官司吧。
我们在结算逻辑里加了双重校验,数据库层面的强一致性是底线:
-- 电力交易结算表
CREATE TABLE power_trading_settlement (
settlement_id BIGSERIAL PRIMARY KEY,
plant_id VARCHAR(50) NOT NULL,
trading_interval TIMESTAMP NOT NULL,
contract_type VARCHAR(20) NOT NULL,
contract_quantity DECIMAL(12,2),
actual_quantity DECIMAL(12,2),
settlement_price DECIMAL(8,4),
settlement_amount DECIMAL(15,2), -- 这里的精度一定要够
settlement_status VARCHAR(20) DEFAULT 'PENDING',
created_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
created_by VARCHAR(100),
updated_by VARCHAR(100)
);
-- 写个函数做“对账”,每天跑一次,睡个安稳觉
CREATE OR REPLACE FUNCTION check_settlement_consistency()
RETURNS TABLE(check_item VARCHAR, status VARCHAR, details TEXT) AS $$
BEGIN
-- 1. 查电量平衡:合同 vs 实际
RETURN QUERY
SELECT
'电量平衡检查' as check_item,
CASE WHEN balance_diff = 0 THEN '正常' ELSE '异常' END as status,
'总电量差额: ' || balance_diff::TEXT as details
FROM (
SELECT ABS(SUM(contract_quantity) - SUM(actual_quantity)) as balance_diff
FROM power_trading_settlement
WHERE trading_interval >= CURRENT_DATE - INTERVAL '1 day'
) balance_check;
-- 2. 查钱算没算对
RETURN QUERY
SELECT
'金额计算检查',
CASE WHEN amount_diff = 0 THEN '正常' ELSE '异常' END,
'金额计算差额: ' || amount_diff::TEXT
FROM (
SELECT ABS(SUM(settlement_amount) - SUM(actual_quantity * settlement_price)) as amount_diff
FROM power_trading_settlement
WHERE settlement_status = 'CONFIRMED'
) amount_check;
END;
$$ LANGUAGE plpgsql;
3. 高可用:99.999% 不是写在PPT上的
对于核心生产系统,停机维护是奢侈的。金仓的集群切换我看过实测,主节点断电,备节点接管的过程基本用户无感。
-- 运维最爱看的监控视图
CREATE VIEW power_ha_cluster_monitor AS
SELECT
node_name,
node_role,
sync_state,
replay_lag, -- 这个指标最关键,延迟大了要报警
client_addr,
application_name,
CASE
WHEN sync_state = 'SYNC' AND replay_lag = 0 THEN '状态完美'
WHEN sync_state = 'ASYNC' AND replay_lag < 100 THEN '正常波动'
WHEN sync_state = 'ASYNC' AND replay_lag < 1000 THEN '需要关注'
ELSE '赶紧排查'
END as health_status,
last_heartbeat
FROM sys_stat_replication
WHERE sync_state IS NOT NULL
ORDER BY node_role, sync_state;
实战案例:那些“硬仗”是怎么打下来的
中国大唐:现货交易的“算力风暴”
大唐的电力现货交易辅助决策系统,是我见过逻辑最复杂的系统之一。“中长期+现货”混在一起,数据量大不说,查询逻辑还特别绕。
读写分离是刚需 交易时段,申报数据疯狂写入,分析报表同时在疯狂查询。如果不做读写分离,数据库CPU直接100%。
架构图如下:
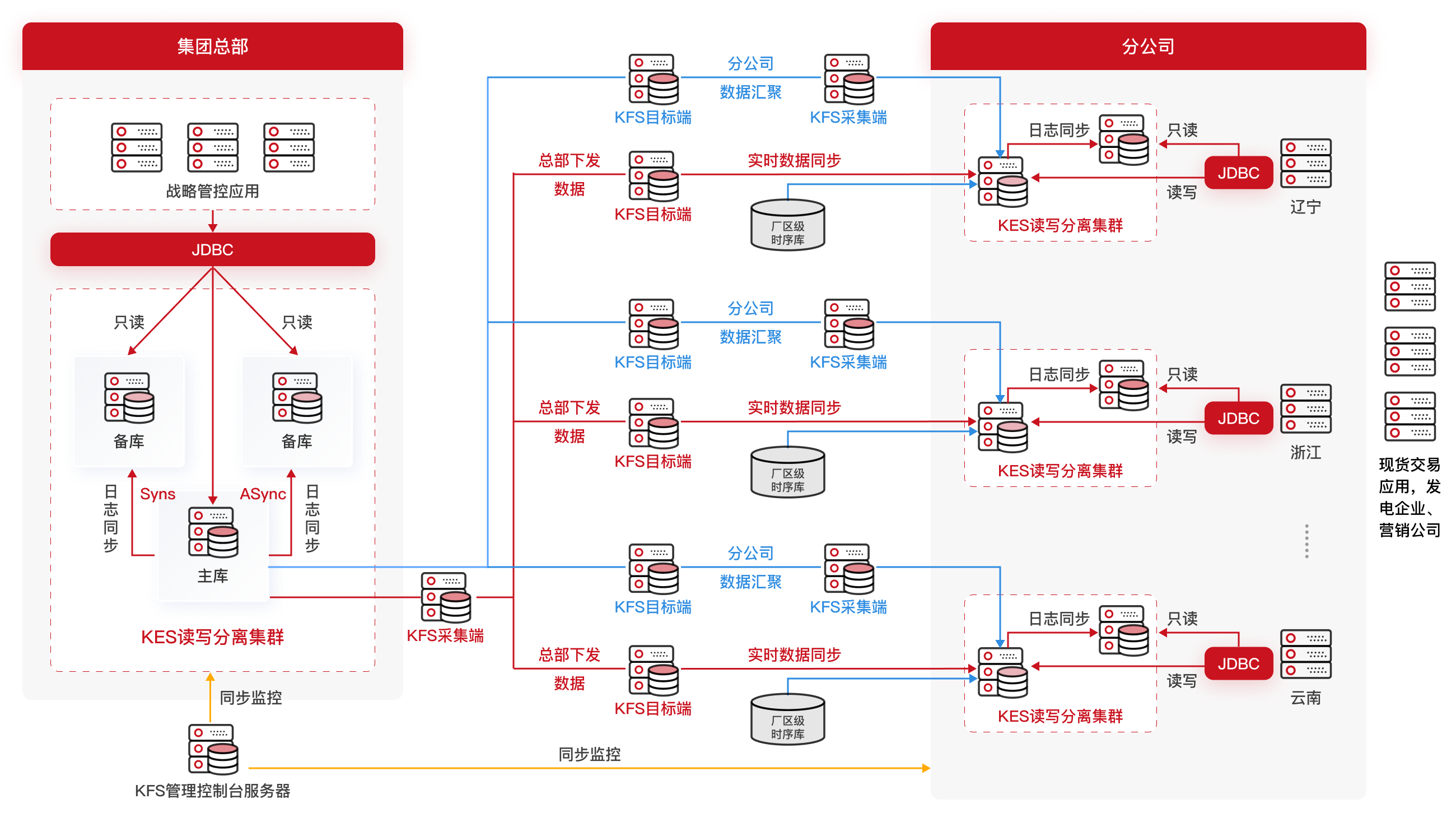
-- 交易数据模型:分区是必须的
CREATE TABLE power_trading_data (
trading_id BIGSERIAL PRIMARY KEY,
plant_id VARCHAR(50) NOT NULL,
trading_date DATE NOT NULL,
trading_interval INTEGER NOT NULL,
market_type VARCHAR(20) NOT NULL,
bid_quantity DECIMAL(10,2),
bid_price DECIMAL(8,4),
cleared_quantity DECIMAL(10,2),
cleared_price DECIMAL(8,4),
trading_status VARCHAR(20) DEFAULT 'SUBMITTED',
created_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
-- 联合唯一索引,防止重复申报
UNIQUE(plant_id, trading_date, trading_interval, market_type)
) PARTITION BY RANGE (trading_date);
-- 读写分离策略
-- 写主库:申报数据
INSERT INTO power_trading_data
(plant_id, trading_date, trading_interval, market_type, bid_quantity, bid_price)
VALUES
('PLANT_001', '2025-01-15', 1, 'DAY_AHEAD', 1000.00, 0.45);
-- 读备库:分析报表(加个hint强制走备库)
SELECT /*+ READONLY */
trading_interval,
AVG(cleared_price) as avg_price,
SUM(cleared_quantity) as total_quantity
FROM power_trading_data
WHERE plant_id = 'PLANT_001'
AND trading_date = '2025-01-15'
GROUP BY trading_interval;
国家电网:D5000的“长跑”奇迹
D5000系统在国网运行了17年,这在IT界简直是化石级的存在,但它依然稳得一批。这里最让我佩服的是金仓对宽表的处理能力。
1443列的宽表,你敢信? 电网的一个断面快照,包含电压、电流、有功、无功等上千个指标。传统关系型数据库看到这种表结构头都大了,但金仓硬是扛下来了。
-- 这种宽表设计虽然反范式,但在电网场景下效率最高
CREATE TABLE grid_wide_table (
record_id BIGSERIAL PRIMARY KEY,
timestamp TIMESTAMP NOT NULL,
-- 下面省略1400多个字段...
voltage_bus1 DECIMAL(8,2),
voltage_bus2 DECIMAL(8,2),
current_line1 DECIMAL(8,2),
current_line2 DECIMAL(8,2),
power_active DECIMAL(10,2),
power_reactive DECIMAL(10,2),
data_source VARCHAR(50),
data_quality INTEGER
);
-- 全表更新性能测试过程
CREATE OR REPLACE PROCEDURE update_wide_table_performance()
AS $$
DECLARE
start_time TIMESTAMP;
duration INTERVAL;
BEGIN
start_time := CLOCK_TIMESTAMP();
-- 模拟全网数据刷新
UPDATE grid_wide_table
SET voltage_bus1 = voltage_bus1 * 1.01
WHERE timestamp >= NOW() - INTERVAL '1 hour';
duration := CLOCK_TIMESTAMP() - start_time;
RAISE NOTICE '全表刷新耗时: % (性能达标)', duration;
END;
$$ LANGUAGE plpgsql;
技术底座:为什么是金仓?
搞定“宽表”和“高并发”
除了上面提到的宽表优化,连接管理也是个大坑。几千个终端同时连上来,如果不做连接池和资源隔离,数据库分分钟被压垮。
-- 资源组隔离:把SCADA实时业务和报表分析业务隔离开
-- 哪怕报表查询把CPU跑满了,也不能影响实时监控
CREATE RESOURCE GROUP scada_group WITH
(cpu_rate_limit=40, memory_limit='16GB', active_statements=200);
CREATE RESOURCE GROUP trading_group WITH
(cpu_rate_limit=30, memory_limit='8GB', active_statements=100);
-- 给不同用户绑定资源组
CREATE USER scada_user RESOURCE GROUP scada_group;
CREATE USER trading_user RESOURCE GROUP trading_group;
展望:未来的路怎么走?
现在的发电厂越来越像互联网公司了,AI预测、边缘计算都在上。
AI与数据库的融合
以前是数据库存数据,AI跑模型。现在趋势是AI直接在数据库里跑,比如做负荷预测的准确性评估:
-- 直接在库内分析预测准确率
CREATE VIEW forecast_accuracy_analysis AS
SELECT
af.plant_id,
af.forecast_type,
COUNT(*) as forecast_count,
-- 计算MAE和MAPE,评估模型准不准
AVG(ABS(af.predicted_value - ad.actual_value)) as mean_absolute_error,
AVG(ABS(af.predicted_value - ad.actual_value) / ad.actual_value) as mape
FROM ai_power_forecast af
JOIN power_generation_realtime ad ON af.plant_id = ad.plant_id
AND af.forecast_time = ad.timestamp
WHERE af.forecast_time >= CURRENT_DATE - INTERVAL '30 days'
GROUP BY af.plant_id, af.forecast_type;
写在最后
从大唐的现货交易到国网的D5000,金仓这几年的表现确实给国产软件争了口气。作为一名技术人员,最欣慰的不是看到PPT上的漂亮参数,而是看到这些系统在迎峰度夏、春节保电这些关键时刻,安安静静地运行,不出岔子。
稳,就是最大的技术含量。 在电力行业数字化转型的下半场,我相信金仓还能带来更多惊喜。我们拭目以待。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号