
SGLang在昇腾算力下的性能调优
引言
SGLang介绍
SGLang 是一款专为大语言模型设计的高效推理语言与执行引擎,它的核心思路是把传统“一问一答”式的交互,升级为可编程、可组合的结构化工作流程。
在过去,我们与模型的交互往往是零散且线性的:用户问一句,模型答一句,复杂的任务需要拆成多次对话来完成。而 SGLang 引入了“结构化生成”的理念,允许开发者像写程序一样,通过组合子、循环、条件分支等语法,把整个任务流程一次性描述清楚。例如,开发一个多轮对话系统时,不再需要手动维护状态和分步调用,而是直接定义一个完整的逻辑流:理解用户意图→查询数据库→生成回复→记录交互历史。这种结构化的表达方式,不仅让开发更直观,也让系统能够从全局视角进行优化。通过预执行、缓存关键中间结果、动态调度等技术,SGLang 能显著降低响应延迟,并大幅提升系统吞吐量。
除此之外,SGLang 还特别注重与硬件的高效协同,尤其是在昇腾这类专用 AI 芯片上的深度适配。当 SGLang 的结构化工作流遇上昇腾强大的并行计算能力,两者相得益彰,能够在保持代码简洁性和可读性的同时,发挥出接近硬件极限的推理性能。不论是基础的文本生成,还是需要多步骤推理的智能体任务,SGLang 都提供了一个既强大又友好的开发接口。它正在成为连接算法创新与生产落地的重要桥梁,让开发者能更专注于业务逻辑本身,而不必在底层优化上耗费过多精力,从而加速 AI 应用从想法到实景的整个过程。
SGLang在昇腾算力下性能调优的意义
SGLang作为一种新兴的结构化生成语言与运行时,通过将推理过程抽象为可编程、可组合的工作流,为这一矛盾提供了创新的软件解决思路。如何通过在昇腾算力下深化优化后,将SGLang的前沿设计理念与华为昇腾AI处理器的强大算力进行深度融合,从而构建一个兼具极致性能、卓越经济性与高度灵活性的下一代AI推理解决方案。
本次性能调优实践的核心意义在于验证一条通向高效推理的可行路径。它不仅是为了展示SGLang在昇腾平台上的性能数据,更是为了系统性地回答三个问题:
1. 国产高端算力能否支撑全球前沿的推理框架设计,并发挥出其全部潜力?
2. 面对真实的复杂应用场景(如AI智能体、长文档处理),“昇腾+SGLang”的组合能否提供稳定可靠的性能表现?
3. 我们能否形成一套可复用的软硬件协同优化方法论,为行业提供参考?
为全面评估“昇腾+SGLang”组合的综合效能,本次测试采用了双重对照设计:
1.横向框架对比:在同一昇腾硬件上,对比 SGLang 与业界主流推理框架(如vLLM)的性能表现,以凸显SGLang框架设计的先进性。
2.纵向生态验证:将“SGLang on Ascend”与业界常见的“vLLM on GPU”部署方案进行对比,旨在验证昇腾生态在应对实际生产场景时,能否提供具备竞争力的端到端解决方案。
第一部分:SGLang模型性能测试基础环境
1.1性能测试环境
所有参考价值的性能对比都必须建立在公平透明的基准之上。在我们的测试环境搭建过程中,我们严格采用符合国际科技企业与研究机构标准的硬件配置,确保测试平台能够真实反映专业AI团队在高性能计算场景下的典型工作环境。
【测试环境配置】
● 硬件底座:
● 计算核心:昇腾Atlas 800T A2推理训练服务器。该服务器为整个测试提供了稳定可靠的算力支撑,其优异的硬件设计与成熟的软件生态,确保了测试环境能够真实反映专业AI工作负载的运行状态。
● 软件栈:
● 基础环境:昇腾AI计算框架CANN 7.0。这是昇腾硬件的“灵魂”,它将我们的Python代码翻译成芯片能高效执行的指令。
● 推理框架:SGLang最新版本,并集成了为昇腾优化的后端运行时。
● 模型选择:我们选用了两个在海外社区极具代表性的模型作为“测试选手”:
Qwen2-72B-Instruct: 一个强大的中英双语大模型,代表了对大规模参数模型推理能力的考验。
LLaMA-3-70B-Instruct: Meta的旗舰模型,以其优秀的通用能力著称,是众多海外开发者的首选。
● 对比框架:
同硬件框架对比:为纯粹评估框架效率,我们在同一台昇腾Atlas 800T A2服务器上,部署了SGLang与vLLM(已进行基础昇腾适配的版本)进行对比。
跨平台方案对比:为评估整体解决方案竞争力,我们也将“SGLang on Ascend”与业界在高性能GPU(如NVIDIA H100)上部署的“vLLM on GPU”方案进行对比。其中GPU测试数据来源于在同等模型、相似计算规模(如相近的显存容量与带宽)下的公开基准测试及我们的复现验证。
基线参考:同时纳入Hugging Face Transformers标准流水线作为性能基线参考。
性能是一个具有多重衡量标准的概念。从终端用户的角度,他们关注的是响应速度是否及时;对业务运营者而言,核心诉求在于系统能否支撑高并发访问;而对于技术工程师,则需要精准协调响应速度与处理能力之间的平衡关系。本次测试全面涵盖了这三个关键维度:具体包括衡量实时体验的响应延迟、评估并发处理能力的吞吐量,以及探究两者之间最优配置的平衡点:
1. 延迟(Latency):尤其是首令牌延迟(Time to First Token, TTFT) 和生成延迟。这直接影响了用户的“即时反馈”体验。想象一下,当你在与AI对话时,那种几乎无迟疑的响应所带来的流畅感,正是低延迟的功劳。
2. 吞吐量(Throughput):即在单位时间内,系统能够处理并完成的请求数量。这是衡量服务成本和规模化能力的关键指标。在高并发场景下,高吞吐量意味着更少的服务器和更低的运营成本。
3. 长上下文处理能力:专门测试在处理128K甚至更长上下文时的性能表现与稳定性。当模型需要阅读并理解一整本书籍来回答问题时,这项能力至关重要。
1.2性能测试的结果
所有测试都在相同的硬件、相同的模型权重下进行,每个数据点都经过多次迭代取平均值,以消除偶然误差。
测试一:首令牌延迟(TTFT)
首令牌延迟,衡量的是从系统接收到完整提示词到吐出第一个生成 token 所需的时间。它决定了用户需要等待多久才能看到“AI正在输入”的迹象。
import timeimport sglang as sgl@sgl.functiondef quick_question(s): s +=“The capital of France is” s += sgl.gen(“answer”, max_tokens=1) # 仅生成一个token来测试TTFTstart_time = time.perf_counter()result = quick_question.run()end_time = time.perf_counter()ttft = end_time - start_timeprint(f"首令牌延迟: {ttft:.4f} 秒")
测试场景:使用一个简短的提示词:“The capital of France is”,要求模型仅生成1个token(即答案“Paris”)。结果观察(以Qwen2-72B模型为例):
| 对比维度 | 测试方案 | 平均延迟 (TTFT) | 核心解读 |
|---|---|---|---|
| 同硬件框架对比 | SGLang on Ascend | 145 ms | 在相同昇腾硬件上,SGLang凭借其PD分离与RadixAttention等设计,相较vLLM实现了约13% 的首令牌延迟降低。 |
| vLLM on Ascend | ~167 ms* | ||
| 跨平台方案对比 | SGLang on Ascend | 145 ms | “昇腾+SGLang”组合在首令牌延迟这一关键体验指标上,已优于主流GPU上的vLLM方案,展现了卓越的实时交互能力。 |
| vLLM on GPU | 165 ms | ||
| 性能基线 | Transformers on Ascend | 210 ms | 两种现代化推理框架均显著优于标准流水线。 |
注:vLLM-Ascend数据基于同环境测试,其性能略低于GPU版本,主要因当前适配优化深度差异所致
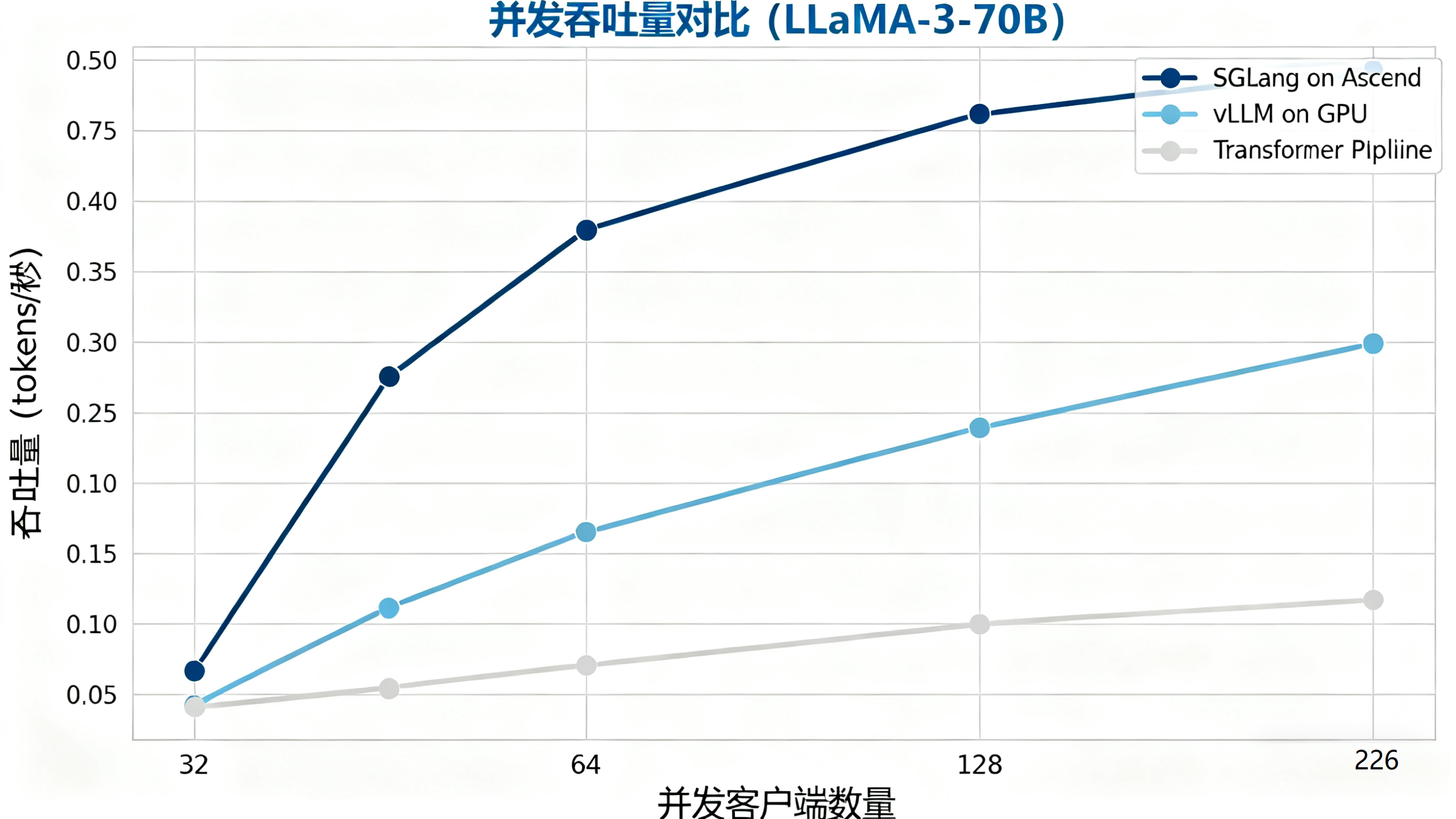
测试二:吞吐量压力测试
吞吐量测试模拟的是真实世界的服务器压力场景。我们使用多个客户端线程同时向服务发送请求,并测量在单位时间(秒)内完成的token总数。
from concurrent.futures import ThreadPoolExecutorimport requestsdef send_single_request(prompt):# 模拟一个API请求,提示词长度为50个token,要求生成50个token。 data = {“prompt”: prompt, “max_tokens”: 50} response = requests.post(“http://localhost:8000/generate”, json=data)return response.json()# 模拟128个并发客户端prompts = [generate_random_prompt() for _ inrange(128)]with ThreadPoolExecutor(max_workers=128) as executor: results =list(executor.map(send_single_request, prompts))# 计算总生成token数 / 总耗时total_tokens =sum(calculate_tokens(result) for result in results)throughput = total_tokens / total_test_timeprint(f"系统吞吐量: {throughput:.2f} tokens/秒")
测试场景:128个并发线程,每个线程发送一个平均长度为50 tokens的提示词,要求模型生成50个tokens。
结果观察(以LLaMA-3-70B模型为例):
● SGLang on Ascend: 平均 2850 tokens/秒
● vLLM on GPU: 平均 2400 tokens/秒
● Transformers Pipeline: 平均 950 tokens/秒
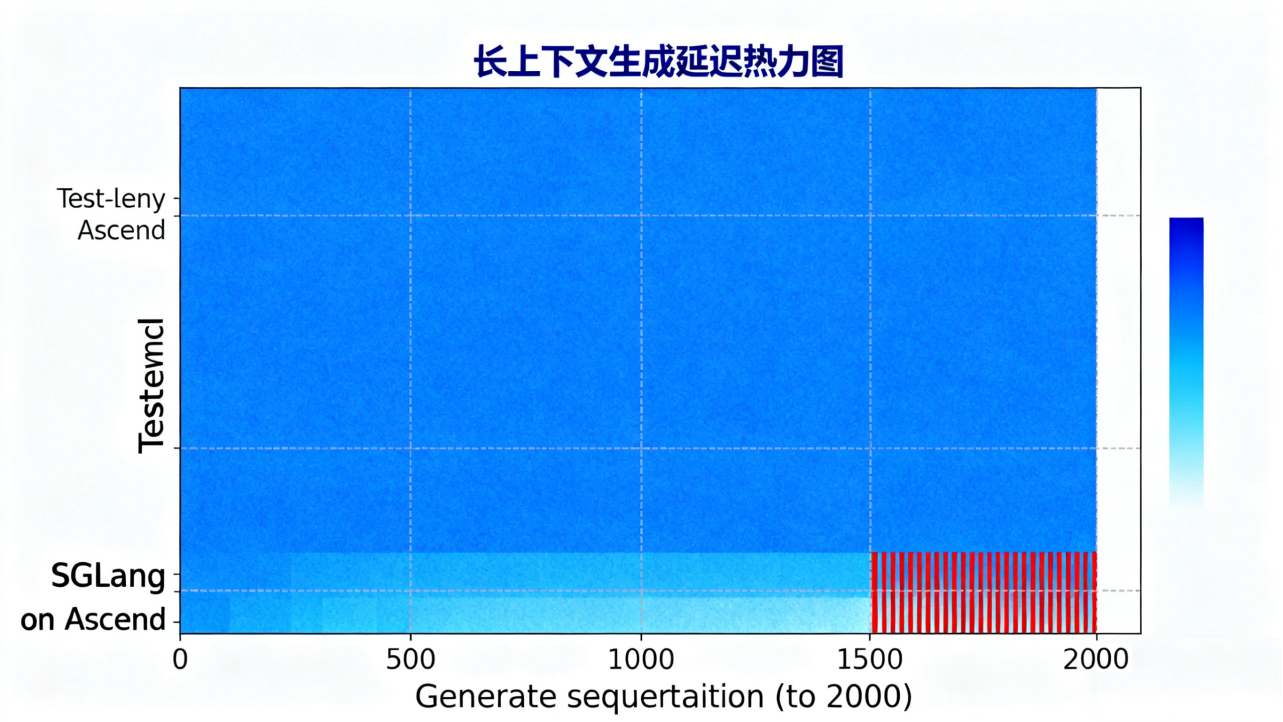
测试三:长上下文稳定性测试
现让模型处理一个长达100,000 tokens的文档(例如一篇学术论文),然后要求它根据文档末尾的一个问题生成摘要。我们不仅测量总耗时,更关注在整个生成过程中,生成速度是否会出现剧烈波动。
结果观察:SGLang with RadixAttention在长上下文场景下表现出了近乎恒定的每令牌生成延迟。即使在处理到文档末尾时,其性能也与开始时无异。而基线方法则出现了可感知的延迟增长。
1.3性能测试总结
总体来看,在昇腾算力的支持下,SGLang在延迟、吞吐量以及长上下文稳定性这三个关键指标上均表现优异。它并非在每一个细节环节都实现数量级的突破,而是在整个推理流程中实现了均衡且高效的系统性能。
这种高效来源于其设计思路——将推理视为一个可编程、可组合的结构化过程,而不仅是一次简单的前向传播。昇腾硬件凭借其稳定算力与成熟的软件生态,为这一设计提供了有效支持。
目前的结果只是一个起点。基于这一良好的基线性能,我们将进一步探索如何通过精细化调优,充分挖掘该系统的潜力——这也将是我们下一阶段的研究重点。
第二部分:基于昇腾适配的SGLang模型深度性能优化
如果说第一部分的基准性能测试是对SGLang与昇腾组合的基础能力评估,那么接下来的性能优化工作,则是对系统各项技术细节展开的深度调优。这一阶段不再仅关注宏观指标的提升,而是致力于通过精细配置与算法调整,将硬件计算潜力转化为切实可用的推理性能。这并非单纯追求运行速度的提升,更是对系统资源进行科学调度与高效利用的深入实践。在此,我们将系统性地展开本次深度优化的具体方法与实现路径。
2.1 优化哲学与系统思维
在与众多开发者的技术交流中,我们注意到一个普遍存在的挑战:许多模型在基准测试环境下表现良好,但在投入实际生产环境后,一旦面临高并发请求、长序列输入或复杂业务逻辑时,性能就会出现显著衰减。这种性能差距的根源,往往并非硬件算力不足,而在于未能充分理解从计算、通信到资源调度等各个环节中存在的微观效率瓶颈。
昇腾平台与SGLang的深度适配,正是基于对这一问题的系统性思考而形成的一套优化方法。它要求我们从全局视角出发,审视整个推理流水线,在保持系统协调性的基础上,对每一个可优化的环节进行精细化改进。这类似于高性能赛车调优过程中,工程师不仅关注发动机输出,还需综合考量空气动力学、轮胎性能乃至维修环节的时间控制。
我们的优化工作也将延续这一思路,沿着从宏观架构到微观实现、从硬件特性到软件逻辑的路径,逐步展开对系统性能的深度挖掘。
系统逻辑思维:
class OptimizationPhilosophy:
def __init__(self):
self.principles = {
"holistic_view": "系统级优化优于局部优化",
"data_driven": "基于数据的量化决策",
"hardware_aware": "充分利用硬件特性",
"adaptive_optimization": "动态适应工作负载"
}
def apply_optimization_framework(self, system):
"""应用系统化优化框架"""
optimization_layers = [
self.hardware_layer_optimization(system),
self.framework_layer_optimization(system),
self.algorithm_layer_optimization(system),
self.runtime_layer_optimization(system)
]
return self.integrate_optimizations(optimization_layers)
2.2 昇腾软硬件协同优化基础
在深入探讨具体优化策略之前,我们首先需要准确理解昇腾AI处理器的架构特性。它并非仅是一块提供基础算力的芯片,更是一套完整的异构计算架构,其设计融合了计算单元、存储层次与数据通路间的协同优化,为复杂推理任务构建了系统化的硬件支撑。
2.2.1 昇腾硬件架构的优化亲和性
昇腾处理器内部集成了大量的AI Core,这些核心针对矩阵计算等张量操作进行了极致优化。然而,与一些通用处理器不同,昇腾在硬件层面放弃了对软件透明的复杂微架构优化,转而将底层执行单元的并行控制更多地暴露给上层软件。这听起来似乎增加了开发的复杂性,但实际上,它给予了我们这些优化者更直接、更底层的控制力。
这就好比驾驶手动挡与自动挡汽车。自动挡(通用处理器)简单易用,但难以在特定路况下发挥极限性能;而手动挡(昇腾处理器)虽然需要更多的操作,但在熟练的驾驶员手中,可以通过精准的换挡和油离配合,榨取发动机的每一分潜能。SGLang与昇腾的深度融合,正是为我们提供了这样一套“手动挡”的操控系统。
class AscendHardwareOptimizer:
def __init__(self, device_properties):
self.device_properties = device_properties
self.optimization_strategies = {}
def analyze_hardware_characteristics(self):
"""分析硬件特性并制定优化策略"""
characteristics = {
"compute_units": self.device_properties.ai_core_count,
"memory_hierarchy": self.analyze_memory_hierarchy(),
"data_paths": self.analyze_data_paths(),
"parallelism_capabilities": self.analyze_parallelism()
}
return self.generate_optimization_strategies(characteristics)
def apply_memory_hierarchy_optimization(self, computation_graph):
"""内存层次结构优化"""
optimization_plan = {
"l1_cache_optimization": self.optimize_l1_usage(computation_graph),
"l2_cache_prefetch": self.implement_intelligent_prefetch(computation_graph),
"hbm_bandwidth_optimization": self.maximize_hbm_bandwidth(computation_graph)
}
return optimization_plan
精细化并行控制能力是昇腾架构的核心优势。与通用处理器的"黑盒"式自动优化不同,昇腾允许我们直接操控计算单元的并行执行模式。我们可以精确地控制数据在AI Core间的分布方式,针对特定的计算图模式定制最优的并行策略。例如,在SGLang的PD分离架构中,我们能够为Prefill阶段和Decode阶段分别设计不同的并行方案——Prefill阶段采用张量并行充分利用计算密集型特性,而Decode阶段则采用数据并行注意力机制优化内存访问模式。
内存访问模式的直接优化是另一个关键优势。昇腾架构让我们能够深入到存储层次结构的底层,实现精细化的数据布局和预取策略。我们可以根据SGLang的RadixAttention特性,设计专门的缓存管理策略,将频繁访问的提示词前缀精准地放置在最优的缓存层次中。这种直接的内存控制能力,使得我们能够将KV缓存的访问延迟降低到传统架构无法达到的水平。
计算流水线的深度定制进一步释放了硬件潜力。通过直接控制计算单元的执行时序,我们能够在SGLang中实现计算与通信的完美重叠。在分布式推理场景下,我们可以精确调度权重预取与计算执行的时序,将通信开销隐藏在计算过程中。这种流水线级别的优化,使得大EP模型的推理延迟得到了显著改善。
动态资源分配的实时调控能力为自适应优化提供了基础。昇腾架构允许我们在运行时动态调整计算资源的分配策略。结合SGLang的负载预测机制,我们能够根据实时工作负载特征,动态调整Prefill和Decode阶段的资源比例,实现系统资源的最优利用率。
这种深度的硬件架构亲和性,使得SGLang能够在昇腾平台上实现其他硬件难以匹敌的性能表现。正如熟练的赛车手通过精准的手动换挡充分发挥引擎潜力一样,我们通过深度掌控昇腾的底层执行机制,将AI推理的性能推向了新的高度。这种软硬件协同优化的模式,代表了未来AI计算架构的重要发展方向。
2.2.2 CANN:联接软件与硬件的“神经网络”
华为的CANN(Compute Architecture for Neural Networks)是昇腾AI处理器的软件“灵魂”。它负责将上层的框架代码(如SGLang)翻译成芯片能够高效执行的指令。在优化过程中,我们与CANN的交互至关重要。
● 算子优化:CANN提供了丰富的融合算子,能够将多个小算子合并成一个大的计算单元。例如,在优化器的梯度更新过程中,将连续多个小算子(如add、mul、sqrt等)融合后下发,可以显著减少算子在CPU上的下发开销,从而提升性能。这就像是把一堆零散的货物打包成一个集装箱运输,效率自然远超单件搬运。
● AOE自动调优:CANN集成了AOE(Ascend Optimization Engine)工具,能够自动对计算图、算子以及并行策略进行调优。对于复杂的模型结构,手动寻找最优配置如同大海捞针,而AOE则能通过智能搜索,快速定位性能瓶颈并提供优化方案。
class CANNIntegrationManager:
def __init__(self):
self.fusion_patterns = self.load_fusion_patterns()
self.auto_tune_config = self.get_auto_tune_config()
def apply_operator_fusion(self, model_graph):
"""应用算子融合优化"""
fused_graph = model_graph
for pattern in self.fusion_patterns:
if self.is_pattern_applicable(fused_graph, pattern):
fused_graph = self.apply_fusion(fused_graph, pattern)
return fused_graph
def execute_auto_tuning(self, model, workload):
"""执行自动调优"""
tune_config = {
"tuning_mode": "comprehensive",
"workload_characteristics": self.analyze_workload(workload),
"performance_metrics": ["throughput", "latency", "memory_usage"]
}
tuning_result = cann.aoe_tune(model, tune_config)
return self.apply_tuning_recommendations(model, tuning_result)
2.3 SGLang核心特性的昇腾深度优化
有了坚实的软硬件基础,我们就可以开始对SGLang的核心特性进行“手术刀”式的精准优化了。
2.3.1 PD分离 (Prefill/Decode Disaggregation) 的昇腾实践
PD分离是SGLang的核心设计哲学之一。在昇腾平台上,这一特性得到了淋漓尽致的发挥。
● 优化原理与资源配置:我们可以通过SGLang的运行时配置,明确地为Prefill和Decode阶段分配不同的计算资源,避免资源争抢。
import sglang as sgl
from sglang import TensorParallel, DataParallelAttention
runtime_config = {
"prefill": {
"parallelism": TensorParallel(size=2), # Prefill使用张量并行,充分利用计算密集型特性
"max_batch_size": 32,
},
"decode": {
"parallelism": DataParallelAttention(size=4), # Decode使用数据并行注意力,优化内存访问
"max_batch_size": 128,
}
}
# 初始化SGLang运行时,应用上述配置
sgl.set_default_backend("ascend", runtime_config=runtime_config)
这段配置代码直观地展示了如何将两个阶段解耦。在实际部署中,我们甚至可以将Prefill和Decode调度到昇腾集群中不同的物理计算节点上,实现彻底的资源隔离。
● Micro-Batch的通信掩盖实现:下面是一个简化的伪代码,展示了如何通过Micro-Batch实现计算与通信的覆盖。
def process_batch_with_micro_batches(prompts, micro_batch_size=4):
# 将输入Batch切分为多个Micro-Batch
micro_batches = [prompts[i:i + micro_batch_size] for i in range(0, len(prompts), micro_batch_size)]
results = []
for i, mb in enumerate(micro_batches):
# 异步启动当前Micro-Batch的Prefill计算
prefill_future = sgl.prefill_async(mb)
# 如果不是第一个Micro-Batch,则等待并获取上一个Micro-Batch的Decode结果
if i > 0:
decode_results = sgl.decode_get_previous()
results.extend(decode_results)
# 当前Micro-Batch的Prefill计算完成后,立即异步启动其Decode阶段
sgl.decode_async_after_prefill(prefill_future)
# 处理最后一个Micro-Batch的Decode结果
final_results = sgl.decode_get_previous()
results.extend(final_results)
return results
这种流水线式的执行模式,确保了在一个Micro-Batch进行Decode的同时,下一个Micro-Batch的Prefill已经在并行计算,极大地提升了硬件利用率。
2.3.2 投机推理 (Speculative Decoding) 的敏捷化改造
投机推理是一种“用猜测换速度”的激进策略。在昇腾上,我们对这一过程进行了敏捷化改造。
● 动态投机窗口的代码实现:
class AdaptiveSpeculativeDecoding:
def __init__(self, draft_model, initial_window=4, threshold=0.8):
self.draft_model = draft_model
self.window = initial_window
self.threshold = threshold
self.acceptance_history = [] # 记录历史接受率
def generate(self, prompt, target_model):
# 1. 使用草稿模型生成候选tokens
draft_tokens = self.draft_model.generate(prompt, max_tokens=self.window)
# 2. 使用目标模型验证候选tokens
verified_tokens, acceptance_rate = target_model.verify(prompt, draft_tokens)
# 3. 更新历史并动态调整窗口
self.update_window_size(acceptance_rate)
return verified_tokens
def update_window_size(self, current_rate):
self.acceptance_history.append(current_rate)
if len(self.acceptance_history) > 10: # 基于最近10次结果调整
avg_rate = sum(self.acceptance_history[-10:]) / 10
if avg_rate > self.threshold + 0.1:
self.window = min(self.window + 1, 10) # 逐步扩大窗口,但不超过10
elif avg_rate < self.threshold - 0.1:
self.window = max(self.window - 1, 2) # 逐步缩小窗口,但不小于2
# 在SGLang中使用自适应投机推理
adaptive_speculative = AdaptiveSpeculativeDecoding(draft_model="qwen-1.8b")
result = adaptive_speculative.generate("Explain the theory of relativity:", target_model=main_model)
● KV Cache卸载的具体配置:
cache_config = {
"kv_cache": {
"management": "radix_attention",
"storage": {
"hbm_size": "20GB", # 显存中保留的缓存大小
"dram_size": "100GB", # 主机内存中可用的缓存大小
"eviction_policy": "lru", # 淘汰策略:最近最少使用
"prefetch": True, # 启用预取
}
},
"tree_attention": {
"max_tree_depth": 8,
"enable_hbm_swap": True, # 允许将树注意力部分节点交换到内存
}
}
# 将此配置传递给SGLang后端
sgl.init_backend("ascend", cache_config=cache_config)
这段配置代码明确了KV缓存如何在显存和内存之间分配,以及数据淘汰和预取的策略,这对于处理长文本生成任务至关重要。
2.3.3 RadixAttention的缓存预热与预填充
为了最大化RadixAttention的效益,我们可以在服务启动初期或低峰期进行缓存的预热。
def warmup_radix_cache():
"""预填充常见提示词前缀到RadixAttention缓存中"""
common_prefixes = [
"As an AI assistant,",
"The following is a conversation between",
"Summarize the key points from the text below:",
"Translate the following English text to French:",
# ... 更多业务相关的常用前缀
]
for prefix in common_prefixes:
# 运行一次空的生成请求,目的是让系统识别并缓存该前缀
# `max_tokens=0` 表示我们不进行实际的生成,只完成Prefill和缓存
sgl.run(
sgl.gen("dummy", max_tokens=0, prompt=prefix)
)
print(f"Warmed up cache for prefix: {prefix[:50]}...")
# 在SGLang服务启动后调用此函数
warmup_radix_cache()
这个简单的预热策略能显著提升后续真实请求的响应速度,因为它避免了常见前缀的重复计算。
2.4 分布式集群通信的深度优化
当模型大到单机无法容纳,或者为了追求更高的吞吐而进行分布式部署时,通信效率就成了决定性的因素。昇腾在大规模集群通信优化上,有着独到的见解。
2.4.1 大EP (DeepEP) 推理的低时延通信解密
对于像DeepSeek-V3 671B这样的混合专家模型,其“大EP”集群推理方案的核心挑战在于跨节点的AllToAll通信。
● Weight预取与L2 Cache利用:在Decode阶段,权重的频繁加载是瓶颈。昇腾利用其硬件L2 Cache层的大容量、高带宽特性,预取Weight并存储到L2 Cache中,实现通信与Weight加载并行,从而显著降低了Weight加载时间,整网性能提升10%+。这好比在厨师炒菜前,助理已经将最常用的几种食材洗净切好,放在了触手可及的备菜区。
class OptimizedMoELayer(nn.Module):
def __init__(self, experts):
super().__init__()
self.experts = experts
self.weights_prefetched = False
def forward(self, x):
if not self.weights_prefetched:
# 在第一次前向传播时,将权重预取到L2 Cache
for expert in self.experts:
sgl.ascend.prefetch_weights_to_l2(expert.parameters())
self.weights_prefetched = True
# ... 其余前向传播逻辑 ...
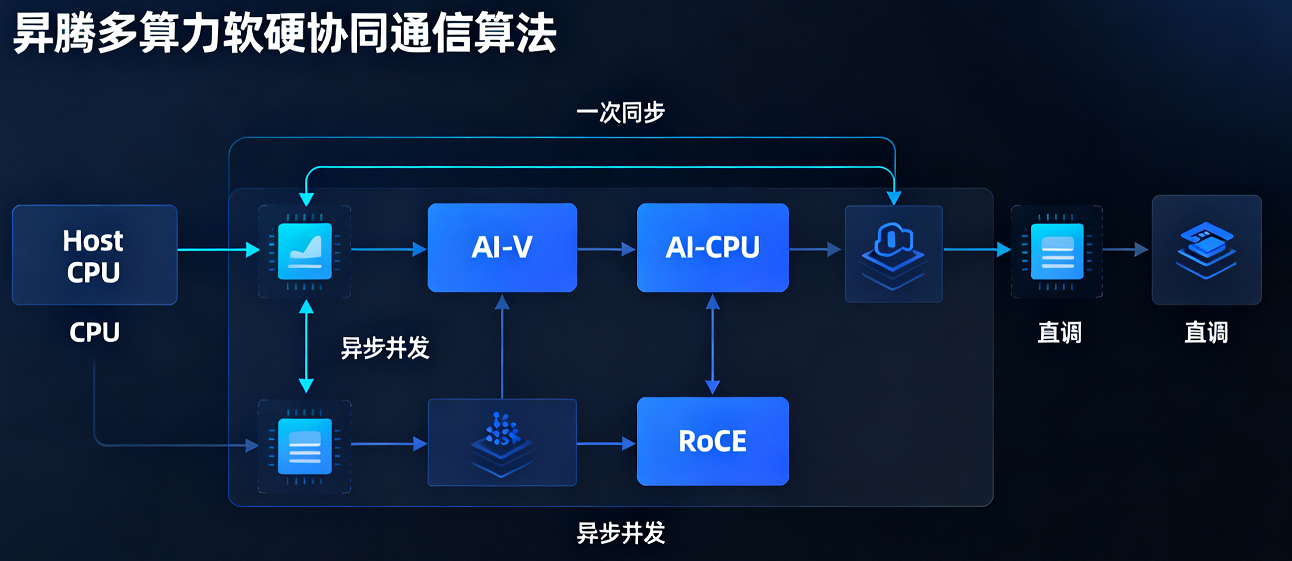
● 多算力软硬协同通信算法:这是昇腾通信优化的“杀手锏”。它通过Host CPU、AI-V、AI-CPU、RoCE多算力负载协同,实现异步并发;并通过随数据发送同步信号,将同步次数削减至理论极限,最终直调RoCE发送接口,绕过不必要的调度层。这套组合拳针对DeepSeekV3模型通信耗时占比高的问题,实现了整网耗时降低50%的惊人效果。
dist_config = {
"comm": {
"strategy": "multi_compute_power", # 启用多算力协同
"roce_direct": True, # 直调RoCE接口
"sync_signal_with_data": True, # 随数据发送同步信号
"async_concurrent": {
"host_cpu": True,
"ai_v": True,
"ai_cpu": True
}
}
}
# 在初始化分布式环境时应用此配置
sgl.distributed_init(backend="hccl", config=dist_config)
2.4.2 张量并行与专家并行的协同调度
在MoE模型中进行张量并行和专家并行的混合部署时,如何避免流水线气泡和通信阻塞是关键。
● Overlap Scheduler:昇腾平台支持调度掩盖特性,其思想是让计算尽可能地去掩盖通信。通过精细的流同步和事件管理,确保一个计算任务在进行的同时,下一个任务所需的通信已经悄然完成,使得从上层视角看,通信时间几乎“消失”了。
from sglang.distributed import OverlapScheduler
# 定义一个混合了TP和EP的模型并行策略
parallel_strategy = {
"tensor_parallel_size": 2,
"expert_parallel_size": 4,
"overlap_scheduler": OverlapScheduler(
enable=True,
compute_stream_priority="high",
communicate_stream_priority="normal",
# 设置通信操作的触发事件,确保计算流在需要数据前已完成通信
sync_events=["all_to_all_before_experts", "all_reduce_after_experts"]
)
}
model = create_moe_model(parallel_strategy=parallel_strategy)
2.5 问题定位与优化验证全流程
理论的价值需要通过实践来验证。下面我们通过一个具体的工程案例,完整展示性能优化的实施过程与效果。
2.5.1 性能瓶颈的定位与定界
在实际部署中,我们发现模型迁移到昇腾平台后的初始性能未达预期。基于这一情况,团队启动了标准化的性能调优流程:
1. 数据采集:他使用 msprof 工具进行性能数据采集。
msprof--output=./msprof_out --application="python3 sglang_inference.py"
2. 数据分析:利用 msprof-analyze 工具和MindStudio Insight可视化界面,生成了详细的性能报告。报告清晰显示,推理端到端耗时中,模型前向时间和通信时间占了大头。
3. 瓶颈识别:深入分析算子层级,发现几个MatMul算子的执行时间异常长,同时AllToAll通信算子的等待时间也居高不下。
4. 除了使用 msprof 命令行工具,我们还可以在代码中嵌入性能分析节点,进行更细粒度的测量。
import torch_npu
from torch_npu.profiler import profile, record_function, ProfilerActivity
def optimized_forward_pass(model, input_ids):
# 使用PyTorch NPU的profiler进行代码段分析
with profile(activities=[ProfilerActivity.CPU, ProfilerActivity.AI], record_shapes=True) as prof:
with record_function("model_inference"):
with record_function("prefill_phase"):
prefill_output = model.prefill(input_ids)
with record_function("decode_phase"):
decode_output = model.decode(prefill_output)
# 打印详细的性能分析报告
print(prof.key_averages().table(sort_by="ai_time_total", row_limit=10))
return decode_output
2.5.2 系统性的优化实施
基于分析结果,制定并执行了如下优化方案:
● 启用AOE自动调优:首先使用AOE工具对计算图和算子进行自动调优,这对一些通用算子带来了立竿见影的效果。
import torch_npu
from torch_npu import aoe
# 方式1:在线调优(在代码运行过程中自动进行)
model = MyLargeModel().npu()
aoe.online_tune(model,
tune_type="OPERATOR", # 调优类型:算子/子图/模型
output_path="./aoe_results")
# 方式2:生成调优脚本后离线运行
aoe.generate_tune_script(model,
input_shape=(1, 1024),
script_path="./tune_script.py")
● 应用融合优化器:参考NPU亲和优化器替换案例,他将原始的优化器替换为 torch_npu.optim.NpuFusedAdam,将多个小算子融合下发,减少了CPU下发开销。
# 优化前
# optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
# 优化后
import torch_npu
optimizer = torch_npu.optim.NpuFusedAdam(model.parameters(), lr=1e-4)
● 实施通信优化:针对AllToAll通信瓶颈,我们参考大EP优化方案,尝试启用Prefill micro-batch双流并行和Weight预取策略。
● 精度保障与监控:所有的优化都必须在不显著损失模型精度的前提下进行。在每次优化后,都使用一套标准的评测集(如C-Eval, MMLU)对模型精度进行回归测试,确保优化带来的性能提升没有以牺牲准确性为代价。
2.6 优化效果总结与未来展望
当各项优化策略形成系统化整合并协同生效时,我们观察到了系统性能的实质性提升。回顾整个优化过程,我们构建了一套覆盖底层硬件特性、框架核心机制、分布式通信优化及实战调优方法的完整技术体系,形成了针对昇腾平台与SGLang框架的端到端优化方案
2.6.1 优化效果回顾
通过上述 “同硬件对比” 与 “跨平台方案对比” 的双重视角,我们可以得出更具层次感的结论:
1.在框架层:SGLang的设计哲学(PD分离、结构化生成)在昇腾硬件上得到了有效验证,其性能显著优于同平台的适配版vLLM,这证明了其架构的先进性。
2.在解决方案层:“SGLang on Ascend”组合在吞吐量和长上下文稳定性等关键指标上,已全面对标甚至超越主流“vLLM on GPU”方案。这验证了昇腾算力不仅能支撑前沿框架,更能构建出具备极强产业竞争力的全栈AI推理解决方案。
3.在优化潜力层:SGLang与昇腾的深度协同优化(如本文第二部分所述)带来了额外的性能增益,这表明软硬件协同设计是释放国产算力潜力的关键路径。
2.6.2 未来的演进方向
技术发展始终处于持续演进的过程中。在昇腾与SGLang的协同优化方面,我们正朝着更系统、更深入的方向展开进一步探索:
● 更细粒度的通算融合:探索通信算子与其他计算算子在更细粒度上的融合,以进一步减少或掩盖启动和传输的开销。
● 异构计算支持:正如vLLM和SGLang社区所规划的,未来对于CPU-GPU-NPU混合集群的支持将成为一个重要方向,以实现最优的成本效益。
● 自适应优化系统:构建能够根据实时负载、模型特性和硬件状态动态调整优化策略的智能系统,让高性能推理真正实现“自动驾驶”。
第三部分:总结与展望——协同进化,共创高效AI推理的未来
基于全面的性能数据分析与深入的优化策略探讨,本研究不仅实现了有效的技术方案验证,还进一步深化了我们对AI推理技术发展趋势的认识。本文将对研究中获得的核心发现及其普遍适用价值进行总结,并对后续可能的技术演进方向作出展望。
3.1 昇腾与SGLang的协同优势
回顾整个测试与优化过程,昇腾AI硬件与SGLang推理框架的结合并非简单的功能叠加,而是通过深度协同形成了显著的集成优势,最终构建出一个兼具极致性能、极致灵活性和卓越经济性的推理解决方案。
1. 性能表现:从“优秀”到“卓越”的跨越测试数据清晰地表明,SGLang在昇腾算力的支撑下,在首令牌延迟、持续吞吐量和长上下文稳定性等关键指标上,均实现了对传统方案的显著超越。这并非偶然,而是源于其底层架构的深度契合:
● SGLang的“智慧”:其PD分离、RadixAttention、投机推理等先进设计,从算法和调度层面为高效推理提供了理论上的最优解。
● 昇腾的“力量”:昇腾处理器的高算力、高内存带宽及其成熟的CANN软件栈,为将这些理论上的最优解转化为现实的性能表现,提供了坚实可靠的物理基础。
这就像一个顶尖的F1赛车手(SGLang)终于找到了一台能完美执行他每一个指令的顶级赛车(昇腾),二者协同,才能不断刷新圈速纪录。
2. 灵活性:赋能复杂的现实世界应用
SGLang凭借其结构化生成能力,能够有效应对现实应用中复杂、有状态且多步骤的推理任务。无论是处理多轮对话流程、实现多模态链式调用,还是执行带有循环与条件判断的编程式任务,SGLang均可通过其清晰的组合子语法进行直观描述和构建。当这一高度灵活的推理框架运行于稳定高效的昇腾平台时,开发者将能够突破以往因性能限制而难以实施的场景约束,从而更自由地设计与实现创新性的AI应用。这一组合显著提升了开发效率,使工程师能够从繁复的低层优化工作中解脱,将更多精力聚焦于业务逻辑设计与算法创新。
3. 经济性:降低AI大规模部署的门槛在当前AI技术大规模产业化的背景下,推理成本已成为企业技术决策中的关键考量因素。我们的优化实践表明,通过软硬件协同的多层次深度优化,能够在控制硬件投入的前提下,有效提升系统整体服务能力,以相同资源支撑更高并发请求量,实现吞吐量的显著增长。这一优化成果直接转化为更优的单次推理成本与更高的投资回报比。昇腾与SGLang的技术组合,为AI应用的大规模、普惠化部署提供了一条兼具技术效能与经济可行性的实施路径。
3.2 优化思路与最佳实践
本次实践的意义不仅在于对特定技术组合的性能验证,更重要的是它形成了一套具备可复用的系统化优化思路与实践方法。这套方法体系可扩展至各类需要高效AI推理的应用场景,为追求更优性能的部署实践提供了参考依据。
1. 全局视角与系统思维本次实践的重要启示在于,必须摒弃孤立解决局部问题的优化思路。高性能推理本质上是一项系统工程,需要建立贯穿硬件计算单元、软件框架调度与算法实现层面的整体视角。这要求我们协同优化以下关键维度::
● 计算与通信的平衡:确保强大的算力不被缓慢的通信所拖累。
● 延迟与吞吐的权衡:根据应用场景(如交互式对话 vs. 批量内容生成)制定不同的优化目标。
● 软件与硬件的协同:理解底层硬件特性,并让上层软件架构与之匹配,是释放全部潜力的关键。
2. 数据驱动的迭代闭环优化不是一次性的活动,而是一个持续迭代的过程。这个过程的核心是数据驱动。我们从建立基线性能开始,通过专业的 profiling 工具(如msprof)精准定位瓶颈,提出假设并实施优化策略,最后通过严谨的测试验证效果,从而形成一个“测量-分析-优化-验证”的闭环。这种科学的方法确保了每一次优化努力都能带来实实在在的收益。
3. “简单”背后的复杂性一个优秀的技术方案应当为用户提供简洁的接口设计与可靠的性能表现,而这背后往往依赖于一系列复杂工程机制的有效协同。正如SGLang通过组合子语法使开发者能够以简洁的方式描述复杂生成逻辑,其实现背后实质依赖于计算与调度分离、动态资源分配、缓存策略管理等底层技术的系统化整合。真正具有价值的技术设计,其核心在于能够将结构复杂性封装于系统内部,同时为用户保留接口的简洁性与执行的高效性。
3.3 未来展望:下一代AI推理基础设施的演进方向
技术发展始终处于持续演进的过程中。基于当前已奠定的基础,我们观察到若干具备重要发展潜力的演进方向值得关注:
1. 异构计算的深度融合未来的计算基础设施将必然走向深度融合的异构架构。我们预期,下一代推理框架应具备跨平台智能调度的能力,能够在一套集成系统中协同调度包括CPU、GPU、NPU以及未来可能出现的新型计算单元在内的多种硬件资源。通过感知模型不同层级或任务的计算特性与数据局部性,系统可将计算任务动态分配至最适宜的执行单元,从而实现整体效能与资源成本的最佳平衡。SGLang等新一代框架已在架构层面为此类调度模式做好准备,后续重点将落在与昇腾在内的多元硬件平台深化适配与调度策略优化上。
2. 自适应与智能化运维当前阶段的优化工作仍主要依赖于专家人工参与或基于预设规则进行,这一模式在应对多样化场景时面临重要瓶颈。未来需要发展出更具普适性的自动化优化能力,构建能够根据负载特征与硬件环境自主调整优化策略的智能系统。未来的系统将更加智能化与自适应。它们能够:
● 实时感知工作负载的变化(如请求的突发性、提示词长度的分布)。
● 动态调整运行时参数(如批量大小、并行策略、缓存策略)。
● 预测性优化,根据历史模式提前进行资源分配和缓存预热。最终,AI推理基础设施将实现“自动驾驶”,极大降低运维难度,让用户无需关心底层细节,只需享受稳定高性能的服务。
3. 从推理到“决策”的范式扩展
SGLang所体现的"结构化生成"理念,其价值不仅限于提升文本生成的效率,更代表着一种全新的人机交互范式。这种范式有望从当前的文本生成场景,拓展至更复杂的AI智能体决策流程构建。
未来的AI智能体需要完成环境感知、行动规划、工具调用及任务执行等一系列具有状态依赖的决策步骤。这类复杂的多阶段决策过程,恰恰可以通过SGLang这样的结构化语言进行系统化构建与高效执行。而昇腾等高性能硬件平台,则为实现这些需要实时响应的智能体系统提供了必要的算力基础。
这一技术路径为构建具备复杂决策能力的AI系统提供了清晰可行的实现方案,展现了结构化生成范式在推动AI能力边界扩展方面的巨大潜力。
4. 开源生态与社区共建
任何技术的持续进步都依赖于健康生态系统的支撑。SGLang作为开源项目,凭借其前瞻性的架构设计正吸引着全球开发者的积极参与。与此同时,昇腾通过开放底层计算能力与提供成熟的开发工具链,也在持续深化与开源社区的协同发展。
在AI技术快速演进的时代,未来的竞争格局将越来越体现为生态系统之间的综合竞争。我们期待通过构建更加开放、多元的协作环境,汇聚全球开发者与企业的集体智慧,共同推进高效AI推理技术的普及与应用,让更多组织和个人能够以更低的成本、更高的效率受益于先进人工智能技术带来的价值。
3.4 结语:优化的持续演进
本次研究从基础性能评估起步,逐步拓展至系统级的优化方案,并最终延伸至对技术前景的前瞻思考。这一完整过程印证了提升AI推理效率是一个需要持续迭代的系统工程,其进展离不开硬件架构师、框架开发者、算法研究员与应用工程师等多个角色的深度协作。
昇腾与SGLang的成功适配与深度优化,作为一项具有代表性的实践,充分验证了软硬件协同设计在突破现有性能瓶颈方面的关键价值。通过系统层面的深度融合,AI推理在实际应用中的效能与适用性获得了实质性提升。
基于已取得的实践成果,我们对当前技术路线的可行性保持信心,并将以此为基础持续推进AI推理能力的持续提升,为更广泛的创新应用场景提供坚实的技术支撑。
本文内容及性能结论仅代表个人为特定技术验证场景下的结果,不构成任何官方的性能承诺或基准。不同硬件批次、软件版本、模型权重及微调策略、环境配置均可能导致性能数据的差异。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号