
面向对象第三单元博客
面向对象第三单元博客
写在前面
由于这三次作业都是迭代开发,所以从开始我们的作业便是从很简单基础出发,类本身已经足够基础,并不需要对类设计有太多别的修改。因此本文主要总结数据、容器、算法的设计
一、 实现规格的设计策略
设计策略:
-
基于规格本身出发,了解到所需要实现的功能和需要注意的细节:
- 数据内容:本次作业主要就是围绕人和信息这两大数据主体,在此之上存在了network、relation、group等,核心是network这个图结构
- 功能:要求提供各种属性查询、连通块数目统计、增删操作、最短路查询等
-
根据数据内容和功能决定类设计:
-
根据规格要求添加属性
-
根据规格要求的功能添加部分属性用于节省运算(维护中间变量):
比如group内要求实现提供查询valuesum、年龄的方差等,如果每次都通过从最底层开始计算,就会导致时间复杂度极高。因此可以采取将valuesum作为Group类管理的属性,每次添加或者删除时进行修改即可。
-
-
综合选择容器:
- 根据数据访问特征:比如会经常通过人的id去访问人这个类,通过group的id去访问Group类,因此选择访问时间复杂度为o(1)的hashmap
- 考虑数据约束特征:是否允许重复元素,是否是pair型数据,容器是否能够为空、数据选取范围
-
算法思考:
- 基于方法功能来决定算法:比如计算连通块采用并查集/dfs(如果是并查集注意压缩路径,如果是dfs注意标记,否则都会超时),计算最短路径采用dijkstra+堆优化等等。
-
异常处理:建立相应的异常类,按照后置条件抛出相应的异常。
二、 基于JML规格的测试方法和策略
1. 黑箱测试
-
简介:这是目前见到最多的版本,通过生成随机数据与别人对拍来判断程序的正确性。
-
优点:评测机书写较简单
-
缺点:无法确保程序的正确性,必须通过跑大量数据来判断。
2. junit(白盒测试的一种)
- junit简介:Junit和黑盒测试的区别就在于junit需要清楚程序内部实现,通过写代码来测试程序,关注程序的具体执行流程。
- 核心内容:主要是判断程序执行的结果是否和我们预期一致。可以通过:assertArrayEquals、assertTrue、assertNull、assertSame等来测试对象是否相等
- 编写测试类:
- @before:使用此注解的方法可以在测试类被调用之前执行,可以标注为测试开始或者设定好初始值。
- @test:是一个单元测试样例,在测试类中可多次声明,但是每个被注解为test的方法只会执行一次。
- @after:在每个@test调用之后执行,可以标注为测试结束
- @ignore:暂时不被执行的测试用例,junit将会忽略执行。
3. 形式化验证
- 构造不变式检查方法
- 根据方法的前置条件设置对象状态
- 自动检查方法后置条件:
- 为每个方法独立实现专用于测试的方法
- 专门建立一个输入-输出配对表进行对比
三、 容器选择和使用
1. 容器选择经验
容器选择主要是根据存储数据类型、数据访问特征、数据约束特性
-
数据类型:这次作业数据类型都比较基本,普通的int、char等都可以实现,但是在注意比如valuesum等是否需要采用biginteger。
-
数据访问特征:
- 经常访问:
- 遍历查询频繁:采用hashmap(hashmap底层就是用的hashset,所以可以直接使用hashmap而不是hashset),hashset
- 删除、插入频繁:hashmap
- 经常访问:
-
数据约束特征:
-
数据与数据之间是否具有逻辑关联性:比如id对应一个人或者一条信息,这种显然应该选择pair类型数据。
-
是否允许重复元素:由于这次涉及到大量的查询动作以及统计数目,所以最好不要用允许重复元素的。
-
容器是否能够为空:这次作业允许容器为空,所以常见的数据结构如hashmap、arraylist等都是可以使用的。
-
容器内数据是否要求有序:
由于hashmap等数据都是无序的(容器内部数据排列顺序和插入先后的顺序没有关系),但是在message内的信息管理需要是有序的,所以可以采用队列、列表、treeset进行管理。
-
2. 容器使用经验
-
hashmap系列
这个数据结构是我用得最多并且最容易出错的结构。主要容易出错的地方就是注意到操作元素可能不存在于hashmap内
例如以下代码(节选自addmessage)
else { if (message instanceof EmojiMessage) { //把它添加到emojiMlist内 int emojiID = ((EmojiMessage) message).getEmojiId(); if (!emojiMlist.containsKey(emojiID)) { HashMap<Integer, Message> map1 = new HashMap<>(); emojiMlist.put(emojiID, map1); } emojiMlist.get(emojiID).put(message.getId(), message); } messages.put(message.getId(), message); }// emojiMlist <emojiId,<id,message> >private HashMap<Integer, HashMap<Integer, Message>> emojiMlist; //<emojiId,<id,message> >message.emojiId = emojiId 这个是emojiMlist的定义这段代码的意思就是:emojiMlist内一种emoji(用emojiID来区分)对应的是所有使用过该emoji的信息以及信息id。如果当某信息属于emojimessage,那么就把该信息放入所对应的hashmap中。因此我选择了
emojiMlist.get(emojiID).put(message.getId(), message);来表达,获取到该emojiID对应的hashmap然后将新的信息put进去,但是没有考虑到可能事先该emojiID在emojiMlist内并没有对应的hashmap,就会导致空指针异常。
-
优先队列
这个容器是被用来实现dijkstra的堆优化算法的,可以说是非常方便。不过应该注意到priqueue是小根堆(C++是大根堆)
while (!priQueue.isEmpty()) { TwoTuple tuple1 = priQueue.poll();//取出并且弹出 int dis = tuple1.getFirst(); int id = tuple1.getSecond(); if (pic.containsKey(id) && pic.get(id) < dis) { continue;//是否已经出堆 } else { MyPerson person = (MyPerson) getPerson(id); for (int personID : person.getAcquaintance().keySet()) { MyPerson person1 = (MyPerson) getPerson(personID); if (!pic.containsKey(personID) || dis + person.queryValue(getPerson(personID)) < pic.get(personID)) { pic.put(personID, dis + person.queryValue(person1)); TwoTuple tuple2 = new TwoTuple(pic.get(personID), personID); priQueue.offer(tuple2); //添加一个 } } } if (id == id2) { break; }//如果检索到id2,代表查找最短路成功,可以直接退出 }
四、 性能问题
这次性能问题来源无非三种:
-
容器选择不当:
选择了arraylist类容器,导致查询时只能通过遍历,时间复杂度高,不如选择hashmap。
-
未能实现维护中间数据:
例如在作业10中mygroup类的方法getAgeVar(求年龄方差),有的人直接按照规格所给出的公式进行计算,每次都会浪费大量的计算资源。不妨在类中管理agepowsum(年龄平方和)、agesum(年龄总值),在添加、删减人的时候进行修改,这样时间复杂度将会降低。
public int getAgeVar() { int size = map.size(); if (size == 0) { return 0; } else { int mean = getAgeMean(); return (agepowsum - 2 * agesum * mean + size * mean * mean) / size; } } -
算法选择、算法优化不到位:
这次的主要算法难点在于iscircle(判断是否连通)和sendIndirectMessage(寻找最短路径)。
- iscircle:备选算法有并查集和DFS,但是并查集注意到一边查找一边压缩路径,这样可以有利于下一次查找(优化为o(1))。
- sendIndirectMessage:采用dijkstra+堆优化(堆优化的代码在讲述priqueue已经提到),单纯用dijkstra很难全部通过强测。
五、 架构设计和模型构建
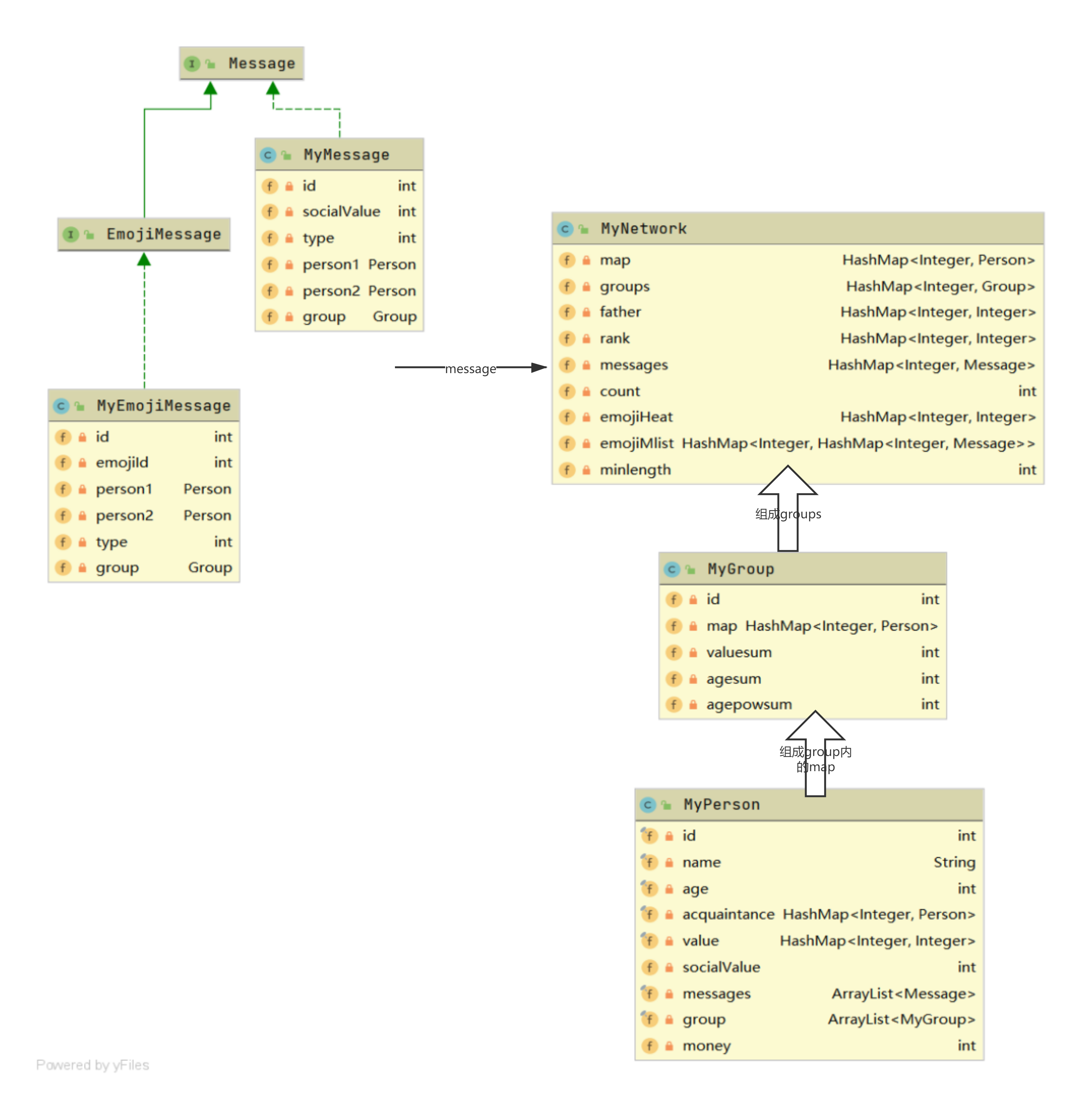
很惭愧的是,我的架构设计完全是根据规格来,除去少部分中间数据和共性方法外,并没有其他的增减。不过对于这三次作业来说,规格给出的架构设计已经完全可以覆盖了。
六、 bug分析
bug集中出现在第一次作业,因为当时对算法不太了解,并且自认为2s已经足够,所以采用了最低级的dfs。只能说尽可能优化就优化吧,不要寄希望于自己的代码能抗住强测的数据。
七、 心得体会
-
关于规格:
最开始接触规格时,觉得枯燥无味且废话很多。明明一句很简单的话,要用科学严谨的话表达出来就是好几行,十分考验人的耐心。后来发现规格内容和我要写的代码相差无几时,我便直接机械地将jml翻译成Java代码,也不考虑规格背后的含义。这就导致写到最后根本不知道自己写了什么,只是jml的搬运工罢了。最后在debug和检查自己代码的时候又不得不返回去分析某个方法jml规定到底该干什么,浪费了很多的时间。
我的总结就是,在书写java代码之前,可以先笼统地了解jml规格里面的需求,明白(可以简记批注在代码旁边),综合考虑设计自己的数据结构、算法和容器,然后再对照着jml规格仔细书写即可。
-
关于评测:
永远不要相信自己的代码!!第一次作业自以为写了dfs就可以安然无恙,实际上翻大车了qaq,能优化的尽量优化。会写评测机的尽量写了,因为jml的细节真的挺多的,不会写评测机也应该借别人的和别人对拍(在这里衷心感谢和我对拍的好同学,属于是救命恩人了)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号