

在 K8s 上运行 GraphScope
 本文将详细介绍:1) 如何基于 Kubernetes 集群部署 GraphScope ; 2) 背后的工作细节; 3) 如何在分布式环境中使用自己构建的 GraphScope 开发镜像。
本文将详细介绍:1) 如何基于 Kubernetes 集群部署 GraphScope ; 2) 背后的工作细节; 3) 如何在分布式环境中使用自己构建的 GraphScope 开发镜像。
本文将详细介绍:1) 如何基于 Kubernetes 集群部署 GraphScope ; 2) 背后的工作细节; 3) 如何在分布式环境中使用自己构建的 GraphScope 开发镜像。
上篇文章介绍了 GraphScope 可以很容易在单机环境下进行部署。然而在真实的工业场景中,需要处理的图数据规模十分巨大,已远远超过了单机的处理能力。因此除单机部署方式外,借助 vineyard 提供的分布式内存数据管理能力,GraphScope 也支持在 Kubernetes 集群上运行。
前置准备
在开始之前,请确保当前环境满足下述条件之一:
- Linux 系统:ubuntu18.04+ 或 centos7+;
- macOS (Big Sur) 11.2.1+。
以及具备以下依赖:
- Docker
- kubectl
- 一套可用的 K8s 环境,可以是
- 一个 K8s 集群
- 或者是 kind/minikube 之类的单机模拟集群的工具
由于 minikube 在服务暴露上与 Kubernetes 不兼容,因此本文以 Kind[1] 为例,介绍如何在本地单机构建一个虚拟 Kubernetes 集群并做部署。如果想搭建一个真实的多节点集群,可以参照 K8s 官方支持的文档[2]搭建;如果你不想手动管理一个 Kubernetes 集群,也可以选择一个经过认证的平台来托管部署服务,如 Aliyun ACK[3] 、AWS EKS[4] 等。
如果已经满足依赖并安装完 kind 之后,首先通过以下命令初始化一个本地虚拟集群:
$ kind create cluster
如果你不想手动逐个安装依赖,也可以使用 GraphScope 提供的脚本,来安装需要的依赖并初始化虚拟集群:
$ wget -O - https://raw.githubusercontent.com/alibaba/GraphScope/main/scripts/install_deps.sh | bash -s -- --k8s
脚本的执行过程会安装所需依赖并尝试检测通过 Kind 拉起 Kubernetes 集群。如果你选择不使用 Kind,也可以使用社区支持的其它工具[5]搭建 Kubernetes 群集。
完成本地虚拟化集群的拉起后,我们可以运行如下命令来查看 Kubernetes 配置是正确的:
$ kubectl get nodes NAME STATUS ROLES AGE VERSION node1 Ready <none> 5d9h v1.22.3-aliyun.1
如果上述命令报错,则说明集群并未准备就绪。请参考 Kubernetes 相关文档[6] 查看问题。
为了完整运行下文中的示例,你还需要在本机上安装 GraphScope Python 客户端。
pip3 install graphscope
通过 Python 进行集群部署
GraphScope 以 docker 镜像的方式发布引擎组件。默认情况下,如果运行 GraphScope 的机器不存在对应镜像,则会拉取当前版本的最新镜像,因此,请确保你的集群可以正常访问公共镜像仓库。
会话(session)[7] 作为 GraphScope 在客户端的入口,它管理着 GraphScope 背后的一组资源,并允许用户操作这组资源上 GraphScope 引擎的各个组件。接下来,我们可以通过会话(session) 在 Kubernetes 集群上创建一个拥有两个 Worker 节点的 GraphScope 实例:
>>> import graphscope
>>> sess = graphscope.session(num_workers=2)
>>> print(sess)
{'status': 'active', 'type': 'k8s', 'engine_hosts': 'gs-engine-jlspyc-6k8j7,gs-engine-jlspyc-mlnvb', 'namespace': 'gs-xxwczb', 'session_id': 'session_narhaktn', 'num_workers': 2}
第一次部署可能会拉取镜像,因此需要等待一段时间。部署成功后,我们可以看到当前sess的状态,以及本次实例所属的命名空间[8]等。
在命令行窗口,我们可以通过 kubectl get 命令查看当前 GraphScope 实例拉起的组件:
# 查看拉起的 Pod $ kubectl -n gs-xxwczb get pod NAME READY STATUS RESTARTS AGE coordinator-jlspyc-6d6fd7f747-9sr7x 1/1 Running 0 8m27s gs-engine-jlspyc-6k8j7 2/2 Running 0 8m23s gs-engine-jlspyc-mlnvb 2/2 Running 0 8m23s gs-etcd-jlspyc-0 1/1 Running 0 8m24s # 查看拉起的 Service $ kubectl -n gs-xxwczb get service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE coordinator-service-jlspyc NodePort 172.16.137.185 <none> 59050:32277/TCP 8m55s gs-etcd-jlspyc-0 ClusterIP 172.16.208.134 <none> 57534/TCP,58955/TCP 8m51s gs-etcd-service-jlspyc ClusterIP 172.16.248.69 <none> 58955/TCP 8m52s
Session 启动各组件的流程
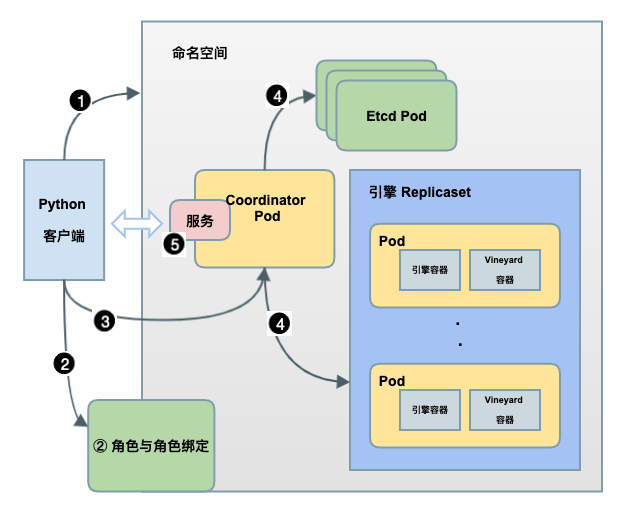
Session 启动流程
如上图所示,在这个 sess = graphscope.session(num_workers=2) 语句背后,GraphScope 拉起各个组件的流程如下:
-
① 默认情况下,当创建会话(session)时,该方法会为此后使用的每个 Kubernetes 对象,包括 Pod,Role 等创建一个单独的命名空间。当用户关闭会话(session)时,整个命名空间都会被删除。
-
② 命名空间创建完成后,后续的拉起过程是通过默认的服务账号[9]使用 Kubernetes API 完成的,由于默认的服务账号不具备读取 Pod 的权限,因此我们在客户端创建命名空间后,在对应的命名空间内使用 RBAC API 创建了一个具备操作 Pod、ReplicaSet 等对象的角色[10],此后将其绑定到默认服务账号中。这使得 GraphScope 创建的容器可以访问所属命名空间下的其他 kubernetes 对象。
-
③ 之后客户端会拉起 Coordinator Pod,作为 GraphScope 后端服务的总入口,通过 GRPC 与客户端通信,并管理着图分析引擎(GAE)、 图查询引擎(GIE),图学习引擎(GLE)的生命周期。
-
④ Coordinator Pod 拉起后,会根据客户端传入的会话(session)参数,在当前命名空间下拉起服务端组件,包括 1) 一组运行 Etcd 的 Pod,负责图数据元信息的同步;2) 一组运行图计算引擎和 Vineyard 容器的 ReplicaSet 对象。
-
⑤ 最后,GraphScope Coordinator 使用 Kubernetes Service[11] 对外(客户端)暴露服务,目前支持 NodePort 和 LoadBalancer 两种模式,具体的配置细节可参考下面的参数详情。
Session 的参数
Session 可以接收一系列参数用于定制集群的配置。例如,k8s_gs_image 参数可以定义引擎 Pod 使用的镜像、timeout_seconds 参数定义创建集群的超时时间等,一些常用参数的含义、默认值如下,全部参数细节可参考文档[12]。
| 参数 | 描述 | 默认值 |
|---|---|---|
| addr | 用于连接已有的 GraphScope 集群,通常结合 Helm 部署方式使用 | None |
| k8s_namespace | 指定命名空间,如果存在,则在该命名空间内部署 GraphScope 实例,否则创建一个新的命名空间 | None |
| k8s_gs_image | 引擎 Pod 镜像 | registry.cn-hongkong.aliyuncs.com/graphscope/graphscope:tag |
| k8s_image_pull_policy | 拉取镜像的策略,可选项是 'IfNotPresent' 和 'Always' | IfNotPresent |
| k8s_service_type | 服务暴露类型,可选项是 'NodePort' 和 'LoadBalancer' | NodePort |
| num_workers | 引擎 Pod 数量 | 2 |
| show_log | 客户端是否输出日志信息 | False |
| log_level | 日志信息等级,可选项是 'INFO' 和 'DEBUG' | 'INFO' |
| timeout_seconds | 创建集群的超时时间 | 600 |
在上述参数中,通常需要注意的是 k8s_service_type,你可以参考以下介绍选择适合你的服务类型:
-
NodePort 类型作为将外部流量导入 Kubernetes 服务最原始的方式,正如其名字所示,它会在对应 Kubernetes 节点上开放一个特定端口 (范围 30000 ~ 32767),任何发送到该端口的流量均会转发给对应的服务 (即 GraphScope 中的 Coordinator 服务),因此如果使用 NodePort 类型,请确保 Python 客户端所在的机器可与 Kubernetes 集群节点进行通信;
-
LoadBalancer 类型是暴露服务到 Internet 的标准方式,但是目前默认部署的 Kubernetes 集群通常不具备 LoadBalancer 的能力,你需要自己手动部署,可以参考 METALLB[13]。此外,诸如 Aliyun ACK 或 AWS EKS 等经过认证的平台通常直接提供 LoadBalancer 的能力,此时也要注意该方式下的 GraphScope 会为每一个实例请求 LoadBalancer 分配一个单独的 IP 地址,这个过程是收费的。
离线部署
基于 Kubernetes 离线部署 GraphScope 涉及两部分:服务端和客户端部分。
服务端: GraphScope 的服务端部分包含 Etcd 镜像和引擎镜像,其中引擎镜像部分默认会使用 registry.cn-hongkong.aliyuncs.com/graphscope/graphscope 中的镜像,并且每个 GraphScope 发布的版本均会包含一个镜像,例如 v0.11.0 版本对应的镜像是 registry.cn-hongkong.aliyuncs.com/graphscope/graphscope:0.11.0 ,因此若想离线部署 GraphScope,只需要满足相关 Kubernetes 节点存在对应版本的镜像即可,镜像地址如下:
- 引擎镜像:
registry.cn-hongkong.aliyuncs.com/graphscope/graphscope:0.11.0 - Etcd 镜像:
quay.io/coreos/etcd:v3.4.13
具体的,你可以在有网的环境预下载对应镜像,通过 scp 等命令传到集群并载入,命令参考如下:
# 有网环境 下载镜像 docker pull registry.cn-hongkong.aliyuncs.com/graphscope/graphscope:0.11.0 # 通过 docker save 命令将镜像压缩成文件 docker save registry.cn-hongkong.aliyuncs.com/graphscope/graphscope:0.11.0 > gs0.11.0.image # 传输文件到集群 scp gs0.11.0.image <host>:</path/gs0.11.0.image> # 通过 docker load 命令在集群上载入镜像 docker load < gs0.11.0.image
同样 Etcd 镜像也可以用使用该方式进行预导入。
客户端: 你可以直接通过 PYPI[14] 选择你需要 GraphScope 客户端并下载对应环境的 whl 包。下载完成后,通过如下命令安装:
pip3 install ./graphscope_client-0.11.0-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
构建自定义开发镜像
上面提到,每个 GraphScope 发布的版本均会包含一个镜像,而如果你希望从源码构建一个镜像,可以使用如下命令:
$ git clone https://github.com/alibaba/GraphScope.git && cd GraphScope $ make graphscope-image build graphscope/graphscope:<GIT_SHORT_SHA>
此时一个使用当前代码空间 Git Commit 信息作为标签的 Docker 镜像将被构建出来。接下来便可以通过 k8s_gs_image 参数使用该镜像。
>>> import graphscope >>> sess = graphscope.session(k8s_gs_image='graphscope/graphscope:<GIT_SHORT_SHA>')
结语
作为一款可在云原生环境下高效地处理超大规模数据的图计算引擎,本文重点介绍了如何基于 Kubernetes 环境部署 GraphScope,同时,本文也详细介绍了 GraphScope 在 Kubernetes 上部署的背后细节,以及如何构建并运行自定义镜像。此外 GraphScope 也支持以 Helm[15] 的方式进行部署,届时可以允许客户端连接到一个已经部署好的服务,我们也会在后续的文章中详细介绍这一部分。最后真诚的欢迎大家使用 GraphScope ,并点击阅读原文反馈遇到的任何问题。
参考资料
[1]Kind: https://kind.sigs.k8s.io/docs/
[2]K8s 官方支持的文档: https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/
[3]Aliyun ACK: https://www.aliyun.com/product/kubernetes
[4]AWS EKS: https://aws.amazon.com/eks/?nc1=h_ls
[5]其它工具: https://kubernetes.io/docs/tasks/tools/
[6]Kubernetes 相关文档: https://kubernetes.io/docs/setup/
[7]会话(session): https://graphscope.io/docs/reference/session.html
[8]命名空间: https://kubernetes.io/zh/docs/concepts/overview/working-with-objects/namespaces/
[9]服务账号: https://kubernetes.io/zh/docs/tasks/configure-pod-container/configure-service-account/
[10]角色: https://kubernetes.io/zh/docs/reference/access-authn-authz/rbac/
[11]Kubernetes Service: https://kubernetes.io/zh/docs/concepts/services-networking/service/
[12]文档: https://graphscope.io/docs/reference/session.html
[13]METALLB: https://metallb.universe.tf/
[14]PYPI: https://pypi.org/project/graphscope-client/#files
[15]Helm: https://helm.sh/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号