


SQL真题实战(大厂真题)——来自牛客题霸
对于大厂真题的部分,需要对题目进行很好的理解,这些来源与实际项目相近的题目才是最锻炼思维能力和编程技巧的。
Part1:某音短视频
SQL1 各个视频的平均完播率
级别:简单
题目:

(uid-用户ID, video_id-视频ID, start_time-开始观看时间, end_time-结束观看时间, if_follow-是否关注, if_like-是否点赞, if_retweet-是否转发, comment_id-评论ID)

(video_id-视频ID, author-创作者ID, tag-类别标签, duration-视频时长(秒), release_time-发布时间)
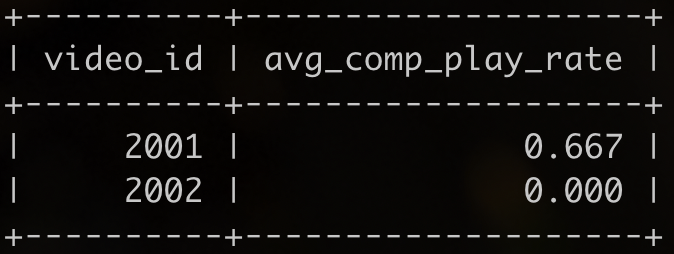
解释:
程序:
SELECT A.video_id_total AS video_id, CAST(IFNULL(video_num_need, 0) / video_num_all AS DECIMAL(10,3)) AS avg_comp_play_rate FROM (SELECT video_id AS video_id_total, COUNT(*) AS video_num_all FROM tb_user_video_log WHERE YEAR(end_time) = 2021 GROUP BY video_id) AS A LEFT JOIN (SELECT B.video_id AS video_id, B.release_time AS relsease_time, COUNT(*) AS video_num_need FROM (SELECT a.video_id AS video_id, a.start_time AS start_time, a.end_time AS end_time, b.duration AS duartion, b.release_time AS release_time, a.end_time - a.start_time AS watch_time FROM tb_user_video_log AS a INNER JOIN tb_video_info AS b ON a.video_id = b.video_id WHERE YEAR(end_time) = 2021 AND (a.end_time - a.start_time) >= b.duration) AS B GROUP BY B.video_id) AS C ON A.video_id_total = C.video_id ORDER BY avg_comp_play_rate DESC;
SQL2 平均播放进度大于60%的视频类别
级别:简单
题目:


- 播放进度=播放时长÷视频时长*100%,当播放时长大于视频时长时,播放进度均记为100%。
- 结果保留两位小数,并按播放进度倒序排序。

SELECT tag, CONCAT(ROUND(avg_play_progress * 100, 2),'%') FROM ( SELECT tag, AVG( CASE WHEN TIMESTAMPDIFF(second, b.start_time, b.end_time) >= a.duration THEN 1 ELSE TIMESTAMPDIFF(second, b.start_time, b.end_time) / a.duration END) AS avg_play_progress FROM tb_video_info AS a INNER JOIN tb_user_video_log AS b ON a.video_id = b.video_id GROUP BY a.tag) AS A WHERE A.avg_play_progress > 0.6 ORDER BY A.avg_play_progress DESC
SQL3 每类视频近一个月的转发量/率
级别:中等
用户-视频互动表tb_user_video_log



SELECT
a.tag,
SUM(CASE WHEN b.if_retweet = 1 THEN 1 ELSE 0 END) AS retweet_cnt,
ROUND(SUM(CASE WHEN b.if_retweet = 1 THEN 1 ELSE 0 END) / COUNT(*), 3) AS retweet_rate
FROM
tb_video_info AS a
INNER JOIN
tb_user_video_log AS b
ON
a.video_id = b.video_id
WHERE
TIMESTAMPDIFF(
DAY,
DATE(b.start_time),
DATE((
SELECT
MAX(start_time)
FROM tb_user_video_log))) <= 29
GROUP BY
a.tag
ORDER BY
retweet_rate DESC
SQL4 每个创作者每月的涨粉率及截止当前的总粉丝量
级别:中等
用户-视频互动表tb_user_video_log

短视频信息表tb_video_info

- 涨粉率=(加粉量 - 掉粉量) / 播放量。结果按创作者ID、总粉丝量升序排序。
- if_follow-是否关注为1表示用户观看视频中关注了视频创作者,为0表示此次互动前后关注状态未发生变化,为2表示本次观看过程中取消了关注。

# 针对每个创作者,每个月的情况 SELECT A.author AS author, A.month AS month, ROUND(fans_situation / total_play, 3) AS fans_growth_rate, SUM(fans_situation) OVER(PARTITION BY author ORDER BY month) AS total_fans FROM (SELECT b.author AS author, DATE_FORMAT(a.start_time,'%Y-%m') AS month, # 粉丝变化量 SUM( CASE WHEN a.if_follow = 1 THEN 1 WHEN a.if_follow = 2 THEN -1 ELSE 0 END) AS fans_situation, # 播放量 COUNT(*) AS total_play FROM tb_user_video_log AS a INNER JOIN tb_video_info AS b ON a.video_id = b.video_id WHERE YEAR(a.start_time) = 2021 AND YEAR(a.end_time) = 2021 GROUP BY author, month) AS A ORDER BY author, total_fans
SQL5 国庆期间每类视频点赞量和转发量
级别:较难
用户-视频互动表tb_user_video_log

短视频信息表tb_video_info



SELECT B.tag AS tag, B.dt AS dt, B.sum_like_cnt_7d AS sum_like_cnt_7d, B.max_between_cnt_7d AS max_between_cnt_7d FROM (SELECT A.tag AS tag, A.dt AS dt, SUM(A.like_cnt) OVER(PARTITION BY A.tag ORDER BY A.dt ROWS 6 PRECEDING) AS sum_like_cnt_7d, MAX(A.retweet_cnt) OVER(PARTITION BY A.tag ORDER BY A.dt ROWS 6 PRECEDING) AS max_between_cnt_7d FROM (SELECT b.tag AS tag, DATE_FORMAT(a.start_time, '%Y-%m-%d') AS dt, SUM(a.if_like) AS like_cnt, SUM(a.if_retweet) AS retweet_cnt FROM tb_user_video_log AS a INNER JOIN tb_video_info AS b ON a.video_id = b.video_id WHERE DATE_FORMAT(a.start_time, '%Y-%m-%d') BETWEEN '2021-09-25' AND '2021-10-03' AND DATE_FORMAT(a.end_time, '%Y-%m-%d') BETWEEN '2021-09-25' AND '2021-10-03' GROUP BY tag, DATE_FORMAT(a.start_time, '%Y-%m-%d') ) AS A ) AS B WHERE B.dt BETWEEN '2021-10-01' AND '2021-10-03' ORDER BY B.tag DESC, B.dt ASC;
注意点:
这个题目所考察的是滑动窗口,在这种取近多少天这一类问题当中,可以根据题目的需要来对窗口函数进行设计,以本题为例
取一周之内的情况,思路可以是升序和降序排序。
1)升序:当前行往前6行
partition by tag order by dt rows 6 preceding partition by tag order by dt rows between 6 preceding and CURRENT row
2)降序:当前行往后6行
partition by tag order by dt desc rows between CURRENT row and 6 following
记住这个方式对解类似题目很有帮助。
SQL6 近一个月发布的视频中热度最高的top3视频
级别:困难
描述
现有用户-视频互动表tb_user_video_log

短视频信息表tb_video_info

(video_id-视频ID, author-创作者ID, tag-类别标签, duration-视频时长, release_time-发布时间)
- 热度=(a*视频完播率+b*点赞数+c*评论数+d*转发数)*新鲜度;
- 新鲜度=1/(最近无播放天数+1);
- 当前配置的参数a,b,c,d分别为100、5、3、2。
- 最近播放日期以end_time-结束观看时间为准,假设为T,则最近一个月按[T-29, T]闭区间统计。
- 结果中热度保留为整数,并按热度降序排序。

SELECT video_id, ROUND((100 * total_play_rate + 5 * like_num + 3 * comment_num + 2 * retweet_num) * (1 / (not_play_days + 1)),0) AS hot_index FROM (SELECT a.video_id AS video_id, # 视频完播率 AVG(CASE WHEN TIMESTAMPDIFF(SECOND, a.start_time, a.end_time) < b.duration THEN 0 WHEN TIMESTAMPDIFF(SECOND, a.start_time, a.end_time) >= b.duration THEN 1 END) AS total_play_rate, # 点赞数 SUM(a.if_like) AS like_num, # 评论数 COUNT(a.comment_id) AS comment_num, # 转发数 SUM(a.if_retweet) AS retweet_num, # 最近无播天数 DATEDIFF( ( SELECT MAX(end_time) FROM tb_user_video_log), MAX(a.end_time) ) AS not_play_days FROM tb_user_video_log AS a INNER JOIN tb_video_info AS b ON a.video_id = b.video_id WHERE DATEDIFF( ( SELECT MAX(end_time) FROM tb_user_video_log), b.release_time ) <= 29 GROUP BY a.video_id) AS A ORDER BY hot_index DESC LIMIT 3;
Part2:用户增长场景(某度信息流)
SQL7 2021年11月每天的人均浏览文章时长
级别:简单


SELECT DATE_FORMAT(in_time, '%Y-%m-%d') AS dt, ROUND(SUM(TIMESTAMPDIFF(SECOND, in_time, out_time)) / COUNT(DISTINCT uid), 1) AS avg_view_len_sec FROM tb_user_log WHERE DATE(in_time) LIKE '2021-11%' AND artical_id != '0' GROUP BY dt ORDER BY avg_view_len_sec ASC;
SQL8 每篇文章同一时刻最大在看人数
级别:中等
用户行为日志表tb_user_log


解释:10点0分10秒时,有3个用户正在浏览文章9001;11点01分0秒时,有2个用户正在浏览文章9002。
程序:
SELECT artical_id, MAX(every_time) AS max_uv FROM (SELECT artical_id, SUM(inout_num) OVER(PARTITION BY artical_id ORDER BY dt ASC, inout_num DESC) AS every_time FROM (SELECT artical_id, in_time AS dt, 1 AS inout_num FROM tb_user_log WHERE artical_id != 0 UNION ALL SELECT artical_id, out_time AS dt, -1 AS inout_num FROM tb_user_log WHERE artical_id != 0) AS A ) AS B GROUP BY artical_id ORDER BY max_uv DESC;
注意点:
在本问题中考察的是在同一时刻的处理方式,因为在同一时刻可能有人进入,也可能有人退出,因此需要用1和-1来分别表示进入和退出。并且配合使用窗口函数来实现每个时刻同时在线的人的排序。因为在窗口函数中使用的是按照标志位1和-1的从大到小排序,因此可以正好出现一个最大的值。
SUM(inout_num) OVER(PARTITION BY artical_id ORDER BY dt ASC, inout_num DESC)
SQL9 2021年11月每天新用户的次日留存率
级别:中等
用户行为日志表tb_user_log

- 次日留存率为当天新增的用户数中第二天又活跃了的用户数占比。
- 如果in_time-进入时间和out_time-离开时间跨天了,在两天里都记为该用户活跃过,结果按日期升序。

SELECT initial_time, ROUND(COUNT(DISTINCT t2.uid) / COUNT(DISTINCT t1.uid), 2) AS uv_left_rate FROM (SELECT uid, MIN(DATE(in_time)) AS initial_time FROM tb_user_log GROUP BY uid) AS t1 LEFT JOIN (SELECT DISTINCT uid, DATE(in_time) AS inout_time FROM tb_user_log UNION SELECT DISTINCT uid, DATE(out_time) AS inout_time FROM tb_user_log) AS t2 ON t1.uid = t2.uid AND t2.inout_time = DATE_ADD(t1.initial_time, INTERVAL 1 DAY) WHERE DATE_FORMAT(initial_time, '%Y-%m') = '2021-11' GROUP BY initial_time ORDER BY initial_time;
SQL10 统计活跃间隔对用户分级结果
级别:较难
用户行为日志表tb_user_log

- 用户等级标准简化为:忠实用户(近7天活跃过且非新晋用户)、新晋用户(近7天新增)、沉睡用户(近7天未活跃但更早前活跃过)、流失用户(近30天未活跃但更早前活跃过)。
- 假设今天就是数据中所有日期的最大值。
- 近7天表示包含当天T的近7天,即闭区间[T-6, T]。

SELECT user_grade, ROUND(COUNT(*) / ( SELECT COUNT(*) FROM (SELECT uid, CASE WHEN DATEDIFF(today, out_time) < 7 AND DATEDIFF(today, in_time) >= 7 THEN '忠实用户' WHEN DATEDIFF(today, in_time) < 7 THEN '新晋用户' WHEN DATEDIFF(today, out_time) >= 7 AND DATEDIFF(today, in_time) < 30 THEN '沉睡用户' WHEN DATEDIFF(today, out_time) >= 30 THEN '流失用户' END AS user_grade FROM (SELECT a.uid AS uid, b.in_time AS in_time, b.out_time AS out_time, b.today AS today FROM tb_user_log AS a LEFT JOIN (SELECT uid, MIN(DATE(in_time)) AS in_time, MAX(DATE(out_time)) AS out_time, (SELECT MAX(DATE(out_time)) FROM tb_user_log) AS today FROM tb_user_log GROUP BY uid) AS b ON a.uid = b.uid) AS A GROUP BY uid) AS B ), 2) AS ratio FROM (SELECT uid, CASE WHEN DATEDIFF(today, out_time) < 7 AND DATEDIFF(today, in_time) >= 7 THEN '忠实用户' WHEN DATEDIFF(today, in_time) < 7 THEN '新晋用户' WHEN DATEDIFF(today, out_time) >= 7 AND DATEDIFF(today, in_time) < 30 THEN '沉睡用户' WHEN DATEDIFF(today, out_time) >= 30 THEN '流失用户' END AS user_grade FROM (SELECT a.uid AS uid, b.in_time AS in_time, b.out_time AS out_time, b.today AS today FROM tb_user_log AS a LEFT JOIN (SELECT uid, MIN(DATE(in_time)) AS in_time, MAX(DATE(out_time)) AS out_time, (SELECT MAX(DATE(out_time)) FROM tb_user_log) AS today FROM tb_user_log GROUP BY uid) AS b ON a.uid = b.uid) AS A GROUP BY uid) AS B GROUP BY user_grade ORDER BY ratio DESC
这个题目感觉写的有些复杂了,可以优化,待过几天空闲了去优化一下它。
SQL11 每天的日活数及新用户占比
级别:较难
用户行为日志表tb_user_log

- 新用户占比=当天的新用户数÷当天活跃用户数(日活数)。
- 如果in_time-进入时间和out_time-离开时间跨天了,在两天里都记为该用户活跃过。
- 新用户占比保留2位小数,结果按日期升序排序。

2021年11月1日有3个用户活跃,其中1个新用户,新用户占比0.33;
程序:
SELECT t1.dt AS dt, t1.all_people AS dau, IFNULL(ROUND(t2.new_people / t1.all_people, 2), 0) AS uv_new_ratio FROM (SELECT dt AS dt, COUNT(DISTINCT uid) AS all_people FROM (SELECT a.uid AS uid, DATE(a.in_time) AS dt FROM tb_user_log AS a UNION ALL SELECT b.uid AS uid, DATE(b.out_time) AS dt FROM tb_user_log AS b) AS D GROUP BY dt) AS t1 LEFT JOIN (SELECT in_time AS dt, COUNT(in_time) AS new_people FROM (SELECT C.uid AS uid, DATE(C.in_time) AS in_time, DATE(C.out_time) AS out_time, DATE(B.in_time) AS inital_time FROM tb_user_log AS C LEFT JOIN (SELECT uid, in_time, out_time FROM (SELECT uid, in_time, out_time, RANK() OVER(PARTITION BY uid ORDER BY in_time, out_time) AS rnk FROM tb_user_log) AS A WHERE rnk = 1) AS B ON C.uid = B.uid) AS C WHERE in_time = inital_time GROUP BY in_time ORDER BY in_time ASC) AS t2 ON t1.dt = t2.dt
SQL12 连续签到领金币
级别:困难
用户行为日志表tb_user_log

- artical_id-文章ID代表用户浏览的文章的ID,特殊情况artical_id-文章ID为0表示用户在非文章内容页(比如App内的列表页、活动页等)。注意:只有artical_id为0时sign_in值才有效。
- 从2021年7月7日0点开始,用户每天签到可以领1金币,并可以开始累积签到天数,连续签到的第3、7天分别可额外领2、6金币。
- 每连续签到7天后重新累积签到天数(即重置签到天数:连续第8天签到时记为新的一轮签到的第一天,领1金币)

SELECT uid AS uid, DATE_FORMAT(dt, '%Y%m') AS month, SUM(coin_day) AS coin FROM (SELECT uid AS uid, dt AS dt, CASE WHEN MOD(RANK() OVER(PARTITION BY uid, rnk_day ORDER BY dt), 7) = 0 THEN 7 WHEN MOD(RANK() OVER(PARTITION BY uid, rnk_day ORDER BY dt), 7) = 3 THEN 3 ELSE 1 END AS coin_day FROM (SELECT uid AS uid, dt AS dt, DATE_SUB(dt, INTERVAL RANK() OVER(PARTITION BY uid ORDER BY dt) DAY) AS rnk_day FROM (SELECT uid AS uid, DATE(in_time) AS dt FROM tb_user_log WHERE artical_id = 0 AND sign_in = 1 AND DATE(in_time) BETWEEN '2021-07-07' AND '2021-10-31' GROUP BY uid, dt) AS a ) AS b ) AS c GROUP BY uid, month ORDER BY uid, month
注意点:
对于这种连续多少天会发生什么事的问题,注意是连续的,可以用到一个技巧
DATE_SUB(dt, INTERVAL RANK() OVER(PARTITION BY uid ORDER BY dt) DAY)
对于这样而言,如果是连续的,则使用DATE_SUB之后会产生一个一模一样的日期,这样就可以判断出连续了多少天。
Part3:电商场景(某东商城)
SQL13 SQL13 计算商城中2021年每月的GMV
级别:简单
现有订单总表tb_order_overall

- 用户将购物车中多件商品一起下单时,订单总表会生成一个订单(但此时未付款,status-订单状态为0,表示待付款);
- 当用户支付完成时,在订单总表修改对应订单记录的status-订单状态为1,表示已付款;
- 若用户退货退款,在订单总表生成一条交易总金额为负值的记录(表示退款金额,订单号为退款单号,status-订单状态为2表示已退款)。

SELECT month, GWV FROM (SELECT DATE_FORMAT(event_time, '%Y-%m') AS month, SUM(total_amount) AS GWV FROM (SELECT a.event_time AS event_time, a.total_amount AS total_amount FROM tb_order_overall AS a WHERE a.status = 0 AND YEAR(a.event_time) = 2021 GROUP BY event_time, total_amount UNION ALL SELECT b.event_time AS event_time, b.total_amount AS total_amount FROM tb_order_overall AS b WHERE b.status = 1 AND YEAR(b.event_time) = 2021 GROUP BY event_time, total_amount) AS A GROUP BY month) AS B WHERE GWV > 100000 ORDER BY GWV ASC
SQL14 统计2021年10月每个退货率不大于0.5的商品各项指标
级别:中等
现有用户对展示的商品行为表tb_user_event

- 商品点展比=点击数÷展示数;
- 加购率=加购数÷点击数;
- 成单率=付款数÷加购数;退货率=退款数÷付款数,
- 当分母为0时整体结果记为0,结果中各项指标保留3位小数,并按商品ID升序排序。

SELECT product_id AS product_id, ROUND(click_num / show_num, 3) AS ctr, ROUND(add_num / click_num, 3) AS cart_rate, ROUND(pay_num / add_num, 3) AS payment_rate, ROUND(refund_num / pay_num, 3) AS refund_rate FROM (SELECT product_id AS product_id, # 展示数 COUNT(product_id) AS show_num, # 加购数 SUM(if_cart) AS add_num, # 点击数 SUM(if_click) AS click_num, # 付款数 SUM(if_payment) AS pay_num, # 退款数 SUM(if_refund) AS refund_num FROM tb_user_event WHERE event_time LIKE '2021-10%' GROUP BY product_id) AS A ORDER BY product_id
SQL15 某店铺的各商品毛利率及店铺整体毛利率
级别:中等
商品信息表tb_product_info

订单总表tb_order_overall


场景逻辑说明:
-
用户将购物车中多件商品一起下单时,订单总表会生成一个订单(但此时未付款,status-订单状态为0表示待付款),在订单明细表生成该订单中每个商品的信息;
-
当用户支付完成时,在订单总表修改对应订单记录的status-订单状态为1表示已付款;
-
若用户退货退款,在订单总表生成一条交易总金额为负值的记录(表示退款金额,订单号为退款单号,status-订单状态为2表示已退款)。

(SELECT
'店铺汇总' AS product_id,
CONCAT(
ROUND((1 - SUM(c.in_price * a.cnt) / SUM(a.price * a.cnt)) * 100, 1), '%'
) AS profit_rate
FROM
tb_order_detail AS a
LEFT JOIN
tb_order_overall AS b
ON
a.order_id = b.order_id
LEFT JOIN
tb_product_info AS c
ON
a.product_id = c.product_id
WHERE
DATE(b.event_time) >= '2021-10-01'
AND
b.status = 1
AND
c.shop_id = 901)
UNION ALL
(SELECT
c.product_id AS product_id,
CONCAT(
ROUND((1 - SUM(c.in_price * a.cnt) / SUM(a.price * a.cnt)) * 100, 1), '%'
) AS profit_rate
FROM
tb_order_detail AS a
LEFT JOIN
tb_order_overall AS b
ON
a.order_id = b.order_id
LEFT JOIN
tb_product_info AS c
ON
a.product_id = c.product_id
WHERE
DATE(b.event_time) >= '2021-10-01'
AND
b.status = 1
AND
c.shop_id = 901
GROUP BY
c.product_id
HAVING
REPLACE(profit_rate, '%', '') > 24.9
ORDER BY
c.product_id)
SQL16 零食类商品中复购率top3高的商品
级别:中等
商品信息表tb_product_info

订单总表tb_order_overall


-
用户将购物车中多件商品一起下单时,订单总表会生成一个订单(但此时未付款, status-订单状态-订单状态为0表示待付款),在订单明细表生成该订单中每个商品的信息;
-
当用户支付完成时,在订单总表修改对应订单记录的status-订单状态-订单状态为1表示已付款;
-
若用户退货退款,在订单总表生成一条交易总金额为负值的记录(表示退款金额,订单号为退款单号,订单状态为2表示已退款)。

SELECT
C.product_id,
ROUND(COUNT(DISTINCT B.uid) / (COUNT(DISTINCT C.uid)), 3) AS repurchase_rate
FROM
(SELECT
c.product_id AS product_id,
b.uid AS uid
FROM
tb_order_detail AS a
LEFT JOIN
tb_order_overall AS b
ON
a.order_id = b.order_id
LEFT JOIN
tb_product_info AS c
ON
a.product_id = c.product_id
WHERE
c.tag = '零食'
AND
b.status = 1
GROUP BY
c.product_id,
b.uid) AS C
LEFT JOIN
(SELECT
product_id,
uid
FROM
(SELECT
c.product_id AS product_id,
b.uid AS uid,
COUNT(b.uid) AS all_cust
FROM
tb_order_detail AS a
LEFT JOIN
tb_order_overall AS b
ON
a.order_id = b.order_id
LEFT JOIN
tb_product_info AS c
ON
a.product_id = c.product_id
WHERE
c.tag = '零食'
AND
b.status = 1
AND
TIMESTAMPDIFF(DAY,
DATE(b.event_time),
(SELECT MAX(DATE(event_time)) FROM tb_order_overall)) < 90
GROUP BY
c.product_id,
b.uid) AS A
WHERE
A.all_cust >= 2) AS B
ON
C.product_id = B.product_id
GROUP BY
C.product_id
ORDER BY
repurchase_rate DESC, C.product_id
LIMIT 3;
SQL17 10月的新户客单价和获客成本
级别:较难
商品信息表tb_product_info

订单总表tb_order_overall

订单明细表tb_order_detail


SELECT ROUND(AVG(total_amount), 1) AS avg_amount, ROUND(AVG(true_price - total_amount), 1) AS avg_cost FROM (SELECT a.uid AS uid, a.event_time AS event_time, a.total_amount AS total_amount, b.price AS price, b.cnt AS cnt, # 找到客户第一次购物的时间,使用窗口函数 ROW_NUMBER() OVER(PARTITION BY a.uid ORDER BY a.event_time) AS rnk, # 计算消费金额 SUM(b.price * b.cnt) OVER(PARTITION BY b.order_id) AS true_price FROM tb_order_overall AS a LEFT JOIN tb_order_detail AS b ON a.order_id = b.order_id WHERE a.status = 1 ) AS A WHERE rnk = 1 AND DATE_FORMAT(event_time, '%Y-%m') = '2021-10'
SQL18 店铺901国庆期间的7日动销率和滞销率
级别:困难

订单总表tb_order_overall

订单明细表tb_order_detail

- 动销率定义为店铺中一段时间内有销量的商品占当前已上架总商品数的比例(有销量的商品/已上架总商品数)。
- 滞销率定义为店铺中一段时间内没有销量的商品占当前已上架总商品数的比例。(没有销量的商品/已上架总商品数)。
- 只要当天任一店铺有任何商品的销量就输出该天的结果,即使店铺901当天的动销率为0。

SELECT
dt,
sale_rate,
1 - sale_rate as unsale_rate
FROM
(SELECT
dt,
ROUND(MIN(sale_pid_cnt) / COUNT(all_pid), 3) AS sale_rate
FROM
(SELECT
dt,
COUNT(DISTINCT IF(shop_id != 901, NULL, product_id)) AS sale_pid_cnt
FROM (SELECT
DISTINCT DATE(event_time) as dt
FROM tb_order_overall
WHERE DATE(event_time) BETWEEN '2021-10-01' AND '2021-10-03'
) as t_dates
LEFT JOIN (
SELECT DISTINCT DATE(event_time) as event_dt, product_id
FROM tb_order_overall AS a
JOIN tb_order_detail AS b
ON a.order_id = b.order_id
) as t_dt_pid ON DATEDIFF(dt,event_dt) BETWEEN 0 AND 6
LEFT JOIN tb_product_info USING(product_id)
GROUP BY dt
) as t_dt_901_pid_cnt
LEFT JOIN (
-- 店铺901每个商品上架日期
SELECT DATE(release_time) as release_dt, product_id as all_pid
FROM tb_product_info
WHERE shop_id=901
) as t_release_dt ON dt >= release_dt # 当天店铺901已上架在售的商品
GROUP BY dt
) as t_dt_sr;
这个题老做不对,参考了一个大神的
Part4:出行场景(某滴打车)
SQL19 2021年国庆在北京接单3次及以上的司机统计信息
级别:简单
用户打车记录表tb_get_car_record


-
用户提交打车请求后,在用户打车记录表生成一条打车记录,order_id-订单号设为null;
-
当有司机接单时,在打车订单表生成一条订单,填充order_time-接单时间及其左边的字段,start_time-开始计费的上车时间及其右边的字段全部为null,并把order_id-订单号和order_time-接单时间(end_time-打车结束时间)写入打车记录表;若一直无司机接单,超时或中途用户主动取消打车,则记录end_time-打车结束时间。
-
若乘客上车前,乘客或司机点击取消订单,会将打车订单表对应订单的finish_time-订单完成时间填充为取消时间,其余字段设为null。
-
当司机接上乘客时,填充订单表中该start_time-开始计费的上车时间。
-
当订单完成时填充订单完成时间、里程数、费用;评分设为null,在用户给司机打1~5星评价后填充。

SELECT city, ROUND(AVG(order_num), 3) AS avg_order_num, ROUND(AVG(income_num), 3) AS avg_income FROM (SELECT a.city AS city, COUNT(*) AS order_num, SUM(b.fare) AS income_num FROM tb_get_car_record AS a LEFT JOIN tb_get_car_order AS b ON a.order_id = b.order_id WHERE DATE(b.order_time) BETWEEN '2021-10-01' AND '2021-10-07' AND a.city = '北京' GROUP BY b.driver_id ) AS A WHERE order_num >= 3 GROUP BY city
SQL20 有取消订单记录的司机平均评分
级别:简单
现有用户打车记录表tb_get_car_record

打车订单表tb_get_car_order

-
用户提交打车请求后,在用户打车记录表生成一条打车记录,order_id-订单号设为null;
-
当有司机接单时,在打车订单表生成一条订单,填充order_time-接单时间及其左边的字段,start_time-开始计费的上车时间及其右边的字段全部为null,并把order_id-订单号和order_time-接单时间(end_time-打车结束时间)写入打车记录表;若一直无司机接单,超时或中途用户主动取消打车,则记录end_time-打车结束时间。
-
若乘客上车前,乘客或司机点击取消订单,会将打车订单表对应订单的finish_time-订单完成时间填充为取消时间,其余字段设为null。
-
当司机接上乘客时,填充订单表中该start_time-开始计费的上车时间。
-
当订单完成时填充订单完成时间、里程数、费用;评分设为null,在用户给司机打1~5星评价后填充。

SELECT * FROM
(SELECT
driver_id,
ROUND(AVG(grade), 1) AS avg_grade
FROM
tb_get_car_order
WHERE
driver_id IN
(SELECT
driver_id
FROM
(SELECT
driver_id,
SUM(
CASE
WHEN start_time IS NULL
THEN 1
ELSE 0
END
) AS cancle_cnt
FROM tb_get_car_order
WHERE DATE_FORMAT(order_time, '%Y-%m') = '2021-10'
GROUP BY driver_id
HAVING cancle_cnt > 0) AS t1)
GROUP BY driver_id
ORDER BY driver_id) AS t2
UNION
SELECT
'总体' AS driver_id,
ROUND(AVG(grade), 1) AS avg_grade
FROM
tb_get_car_order
WHERE
driver_id IN
(SELECT
driver_id
FROM
(SELECT
driver_id,
SUM(
CASE
WHEN start_time IS NULL
THEN 1
ELSE 0
END
) AS cancle_cnt
FROM tb_get_car_order
WHERE DATE_FORMAT(order_time, '%Y-%m') = '2021-10'
GROUP BY driver_id
HAVING cancle_cnt > 0) AS t1)
GROUP BY '总体';
SQL21 每个城市中评分最高的司机信息
级别:中等
用户打车记录表tb_get_car_record

打车订单表tb_get_car_order

-
用户提交打车请求后,在用户打车记录表生成一条打车记录,order_id-订单号设为null;
-
当有司机接单时,在打车订单表生成一条订单,填充order_time-接单时间及其左边的字段,start_time-开始计费的上车时间及其右边的字段全部为null,并把order_id-订单号和order_time-接单时间(end_time-打车结束时间)写入打车记录表;若一直无司机接单,超时或中途用户主动取消打车,则记录end_time-打车结束时间。
-
若乘客上车前,乘客或司机点击取消订单,会将打车订单表对应订单的finish_time-订单完成时间填充为取消时间,其余字段设为null。
-
当司机接上乘客时,填充订单表中该start_time-开始计费的上车时间。
-
当订单完成时填充订单完成时间、里程数、费用;评分设为null,在用户给司机打1~5星评价后填充。

SELECT city, driver_id, avg_grade, avg_order_num, avg_mileage FROM (SELECT city, driver_id, ROUND(AVG(grade_situation), 1) AS avg_grade, ROUND(COUNT(order_id) / COUNT(DISTINCT dt), 1) AS avg_order_num, ROUND(SUM(mileage) / COUNT(DISTINCT dt), 3) AS avg_mileage, DENSE_RANK() OVER(PARTITION BY city ORDER BY AVG(grade_situation) DESC) AS rnk FROM (SELECT a.city, b.driver_id, # 计算评分 b.grade AS grade_situation, # 计算订单 b.order_id, DATE(b.order_time) AS dt, # 计算里程 b.mileage FROM tb_get_car_record AS a LEFT JOIN tb_get_car_order AS b ON a.order_id = b.order_id) AS A GROUP BY city, driver_id) AS B WHERE rnk = 1 ORDER BY avg_order_num
SQL22 国庆期间近7日日均取消订单量
级别:中等
现有用户打车记录表tb_get_car_record

打车订单表tb_get_car_order

场景逻辑说明:
-
用户提交打车请求后,在用户打车记录表生成一条打车记录,order_id-订单号设为null;
-
当有司机接单时,在打车订单表生成一条订单,填充order_time-接单时间及其左边的字段,start_time-开始计费的上车时间及其右边的字段全部为null,并把order_id-订单号和order_time-接单时间(end_time-打车结束时间)写入打车记录表;若一直无司机接单,超时或中途用户主动取消打车,则记录end_time-打车结束时间。
-
若乘客上车前,乘客或司机点击取消订单,会将打车订单表对应订单的finish_time-订单完成时间填充为取消时间,其余字段设为null。
-
当司机接上乘客时,填充订单表中该start_time-开始计费的上车时间。
-
当订单完成时填充订单完成时间、里程数、费用;评分设为null,在用户给司机打1~5星评价后填充。

SELECT dt, ROUND(finish_num, 2) AS finish_num_7d, ROUND(cancel_num, 2) AS cancel_num_7d FROM (SELECT dt, AVG(SUM(start_situation_1)) OVER(ORDER BY dt ROWS 6 PRECEDING) AS finish_num, AVG(SUM(start_situation_2)) OVER(ORDER BY dt ROWS 6 PRECEDING) AS cancel_num FROM (SELECT DATE(order_time) AS dt, CASE WHEN start_time IS NULL THEN 0 ELSE 1 END AS start_situation_1, CASE WHEN start_time IS NULL THEN 1 ELSE 0 END AS start_situation_2 FROM tb_get_car_order) AS A GROUP BY dt) AS B WHERE dt BETWEEN '2021-10-01' AND '2021-10-03' ORDER BY dt
注意点:
是本文中SQL5和SQL8思路的结合来进行求解。
SQL23 工作日各时段叫车量、等待接单时间和调度时间
级别:较难
用户打车记录表tb_get_car_record

打车订单表tb_get_car_order

场景逻辑说明:
-
用户提交打车请求后,在用户打车记录表生成一条打车记录,订单号-order_id设为null;
-
当有司机接单时,在打车订单表生成一条订单,填充接单时间-order_time 及其左边的字段,上车时间-start_time及其右边的字段全部为null,并把订单号-order_id和接单时间-order_time(end_time-打车结束时间)写入打车记录表;若一直无司机接单,超时或中途用户主动取消打车,则记录打车结束时间-end_time。
-
若乘客上车前,乘客或司机点击取消订单,会将打车订单表对应订单的finish_time-订单完成时间填充为取消时间,其余字段设为null。
-
当司机接上乘客时,填充订单表中该订单的start_time-上车时间。
-
当订单完成时填充订单完成时间、里程数、费用;评分设为null,在用户给司机打1~5星评价后填充。
-
不同时段定义:早高峰 [07:00:00 , 09:00:00)、工作时间 [09:00:00 , 17:00:00)、晚高峰 [17:00:00 , 20:00:00)、休息时间 [20:00:00 , 07:00:00)
-
时间区间左闭右开(即7:00:00算作早高峰,而9:00:00不算做早高峰)
-
从开始打车到司机接单为等待接单时间,从司机接单到上车为调度时间。

解释:订单9017打车开始于11点整,属于工作时间,等待时间30秒,调度时间为1分40秒,示例数据中工作时间打车订单就一个,平均等待时间0.5分钟,平均调度时间1.7分钟。
程序:
SELECT period AS period, COUNT(*) AS get_car_num, ROUND(AVG(TIMESTAMPDIFF(SECOND, event_time, order_time)) / 60, 1) AS avg_wait_time, ROUND(AVG(TIMESTAMPDIFF(SECOND, order_time, start_time)) / 60, 1) AS avg_dispatch_time FROM (SELECT order_id, event_time, order_time, start_time, hour_time, CASE WHEN hour_time >= 7 AND hour_time < 9 THEN '早高峰' WHEN hour_time >= 9 AND hour_time < 17 THEN '工作时间' WHEN hour_time >= 17 AND hour_time < 20 THEN '晚高峰' ELSE '休息时间' END AS period FROM (SELECT # 订单号 a.order_id AS order_id, # 三个重要的时间 a.event_time AS event_time, b.order_time AS order_time, b.start_time AS start_time, # 日期 DATE(a.event_time) AS day_time, # 判断是星期几 WEEKDAY(a.event_time) AS week_day, HOUR(a.event_time) AS hour_time FROM tb_get_car_record AS a LEFT JOIN tb_get_car_order AS b ON a.order_id = b.order_id) AS A WHERE week_day IN (0, 1, 2, 3, 4)) AS B GROUP BY period ORDER BY get_car_num
SQL24 各城市最大同时等车人数
级别:较难


场景逻辑说明:
-
用户提交打车请求后,在用户打车记录表生成一条打车记录,订单号-order_id设为null;
-
当有司机接单时,在打车订单表生成一条订单,填充接单时间-order_time及其左边的字段,上车时间及其右边的字段全部为null,并把订单号和接单时间(打车结束时间)写入打车记录表;若一直无司机接单、超时或中途用户主动取消打车,则记录打车结束时间。
-
若乘客上车前,乘客或司机点击取消订单,会将打车订单表对应订单的订单完成时间-finish_time填充为取消时间,其余字段设为null。
-
当司机接上乘客时,填充打车订单表中该订单的上车时间start_time。
-
当订单完成时填充订单完成时间、里程数、费用;评分设为null,在用户给司机打1~5星评价后填充。

SELECT city AS city, MAX(wait_situation) AS max_wait_uv FROM (SELECT city, dt, situation, SUM(situation) OVER(PARTITION BY city, DATE(dt) ORDER BY dt ASC, situation DESC) AS wait_situation FROM (# 开始等车 SELECT a.city AS city, a.event_time AS dt, 1 AS situation FROM tb_get_car_record AS a LEFT JOIN tb_get_car_order AS b ON a.order_id = b.order_id WHERE DATE_FORMAT(event_time, '%Y-%m') = '2021-10' UNION ALL # 停止等车 SELECT c.city AS city, CASE WHEN d.start_time IS NULL THEN d.finish_time ELSE d.start_time END AS dt, -1 AS situation FROM tb_get_car_record AS c LEFT JOIN tb_get_car_order AS d ON c.order_id = d.order_id WHERE DATE_FORMAT(c.event_time, '%Y-%m') = '2021-10') AS A ORDER BY city, DATE(dt)) AS B GROUP BY city ORDER BY max_wait_uv ASC, city ASC
注意点:
又是同一时间点的问题,用固定的方法来解决。
Part5:某宝店铺分析(电商模式)


程序:
SELECT style_id, COUNT(*) AS SPU_num FROM product_tb GROUP BY style_id ORDER BY SPU_num DESC
SQL26 某宝店铺的实际销售额与客单价
级别:简单


程序:
SELECT SUM(sales_price) AS sales_total, ROUND(SUM(sales_price) / COUNT(DISTINCT user_id), 2) AS per_trans FROM sales_tb
SQL27 某宝店铺折扣率
级别:中等

程序:
SELECT ROUND(SUM(a.sales_price) * 100 / SUM(a.sales_num * b.tag_price), 2) FROM sales_tb AS a LEFT JOIN product_tb AS b ON a.item_id = b.item_id
SQL28 某宝店铺动销率与售罄率
级别:较难

程序:
SELECT b.style_id, ROUND(SUM(a.sales_num) * 100 / (SUM(DISTINCT(b.inventory)) - SUM(a.sales_num)), 2), ROUND(SUM(a.sales_price) * 100 / SUM(DISTINCT(b.tag_price * b.inventory)), 2) FROM sales_tb AS a LEFT JOIN product_tb AS b ON a.item_id = b.item_id WHERE DATE(a.sales_date) >= '2021-11-01' GROUP BY b.style_id
SQL29 某宝店铺连续2天及以上购物的用户及其对应的天数
级别:较难

程序1:使用DENSE_RANK来进行排序,感觉这样是不严谨的但是做出来了
SELECT user_id, max_dense_rnk FROM (SELECT user_id AS user_id, MAX(dense_rnk) AS max_dense_rnk FROM (SELECT sales_date AS sales_date, user_id AS user_id, DENSE_RANK() OVER(PARTITION BY user_id ORDER BY sales_date) AS dense_rnk FROM sales_tb WHERE DATE(sales_date) >= '2021-11-01') AS A GROUP BY user_id) AS B WHERE max_dense_rnk >= 2 GROUP BY user_id
程序2:套模板来做
SELECT user_id, COUNT(rnk_day) AS days_count FROM (SELECT sales_date, user_id, DATE_SUB(sales_date, INTERVAL RANK() OVER(PARTITION BY user_id ORDER BY sales_date) DAY) AS rnk_day FROM (SELECT sales_date AS sales_date, user_id AS user_id FROM sales_tb WHERE DATE(sales_date) >= '2021-11-01' GROUP BY sales_date, user_id) AS A ) AS B GROUP BY user_id HAVING days_count >= 2
Part6:牛客直播课分析(在线教育行业)
SQL30 牛客直播转换率
级别:简单



程序:
SELECT course_id, course_name, ROUND((SUM(if_sign) / SUM(if_vm)) * 100, 2) AS sign_rate FROM (SELECT a.course_id AS course_id, a.course_name AS course_name, b.if_sign AS if_sign, b.if_vw AS if_vm FROM course_tb AS a INNER JOIN behavior_tb AS b ON a.course_id = b.course_id) AS A GROUP BY course_id, course_name ORDER BY course_id
SQL31 牛客直播开始时各直播间在线人数
级别:中等


程序:
SELECT a.course_id AS course_id, a.course_name AS course_name, COUNT(DISTINCT(b.user_id)) AS online_num FROM course_tb AS a INNER JOIN attend_tb AS b ON a.course_id = b.course_id WHERE TIME(b.in_datetime) <= '19:00:00' AND TIME(b.out_datetime) >= '19:00:00' GROUP BY a.course_id, a.course_name ORDER BY a.course_id
SQL32 牛客直播各科目平均观看时长
级别:中等


程序:
SELECT a.course_name AS course_name, ROUND(AVG(TIMESTAMPDIFF(MINUTE, b.in_datetime, b.out_datetime)), 2) AS avg_Len FROM course_tb AS a INNER JOIN attend_tb AS b ON a.course_id = b.course_id GROUP BY a.course_name ORDER BY avg_Len DESC
SQL33 牛客直播各科目出勤率
级别:较难


程序:
SELECT a.course_id AS course_id, course_name AS course_name, ROUND(SUM(CASE WHEN online_time >= 10 THEN 1 ELSE 0 END) / all_sign * 100, 2) AS attend_rate FROM (SELECT user_id, course_id, SUM(TIMESTAMPDIFF(MINUTE, in_datetime, out_datetime)) AS online_time FROM attend_tb GROUP BY user_id, course_id) AS a LEFT JOIN course_tb AS b ON a.course_id = b.course_id LEFT JOIN (SELECT course_id, SUM(if_sign) AS all_sign FROM behavior_tb GROUP BY course_id ) AS c ON b.course_id = c.course_id GROUP BY a.course_id, course_name ORDER BY a.course_id
SQL34 牛客直播各科目同时在线人数
级别:较难

程序:
SELECT c.course_id, c.course_name, MAX(num_situation) AS max_num FROM (SELECT course_id, dt, SUM(situation) OVER(PARTITION BY course_id ORDER BY dt ASC, situation DESC) AS num_situation FROM (SELECT course_id AS course_id, in_datetime AS dt, 1 AS situation FROM attend_tb UNION ALL SELECT course_id AS course_id, out_datetime AS dt, -1 AS situation FROM attend_tb) AS a ) AS b INNER JOIN course_tb AS c ON b.course_id = c.course_id GROUP BY c.course_id, c.course_name ORDER BY c.course_id
Part7:某乎问答(内容行业)
SQL35 某乎问答11月份日人均回答量
级别:简单


SELECT answer_date, ROUND(COUNT(issue_id) / COUNT(DISTINCT author_id), 2) AS per_num FROM answer_tb GROUP BY answer_date
SQL36 某乎问答高质量的回答中用户属于各级别的数量
级别:中等


SELECT level_cut, COUNT(level_cut) AS num FROM (SELECT CASE WHEN b.author_level BETWEEN 5 AND 6 THEN '5-6级' WHEN b.author_level BETWEEN 3 AND 4 THEN '3-4级' WHEN b.author_level BETWEEN 1 AND 2 THEN '1-2级' END AS level_cut FROM answer_tb AS a LEFT JOIN author_tb AS b ON a.author_id = b.author_id WHERE a.char_len >= 100) AS A GROUP BY level_cut ORDER BY num DESC
SQL37 某乎问答单日回答问题数大于等于3个的所有用户
级别:中等

SELECT answer_date, author_id, COUNT(issue_id) AS answer_cnt FROM answer_tb GROUP BY answer_date, author_id HAVING COUNT(issue_id) >= 3 ORDER BY answer_date ASC, author_id ASC
SQL38 某乎问答回答过教育类问题的用户里有多少用户回答过职场类问题
级别:中等


SELECT COUNT(DISTINCT author_id) FROM (SELECT A.author_id AS author_id, A.issue_type AS issue_type1, B.issue_type AS issue_type2 FROM (SELECT a.author_id, a.issue_id, b.issue_type FROM answer_tb AS a LEFT JOIN issue_tb AS b ON a.issue_id = b.issue_id) AS A LEFT JOIN (SELECT a.author_id, a.issue_id, b.issue_type FROM answer_tb AS a LEFT JOIN issue_tb AS b ON a.issue_id = b.issue_id WHERE b.issue_type = 'Education') AS B ON A.author_id = B.author_id) AS C WHERE issue_type1 = 'Career' AND issue_type2 = 'Education'
SQL39 某乎问答最大连续回答问题天数大于等于3天的用户及其对应等级
级别:较难

SELECT author_id, author_level, COUNT(diff_day) AS day_cnt FROM (SELECT author_id, author_level, diff_day FROM (SELECT author_id, answer_date, author_level, DATE_SUB(answer_date, INTERVAL RANK() OVER(PARTITION BY author_id ORDER BY answer_date) DAY) AS diff_day FROM (SELECT a.author_id, a.answer_date, b.author_level FROM answer_tb AS a LEFT JOIN author_tb AS b ON a.author_id = b.author_id GROUP BY a.author_id, a.answer_date, b.author_level) AS A ) AS B ) AS C GROUP BY author_id, author_level, diff_day HAVING day_cnt >= 3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号