

分布式事务的解决方案
来源:优知学院 原文地址:https://youzhixueyuan.com/solution-and-summary-of-distributed-transaction.html
分布式事务是企业集成中的一个技术难点,也是每一个分布式系统架构中都会涉及到的一个东西,特别是在这几年越来越火的微服务架构中,几乎可以说是无法避免,本文就围绕分布式事务各方面与大家进行介绍。
事务
1.1 什么是事务
数据库事务(简称:事务,Transaction)是指数据库执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成。
事务拥有以下四个特性,习惯上被称为ACID特性:
- 原子性(Atomicity):事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行。
- 一致性(Consistency):事务应确保数据库的状态从一个一致状态转变为另一个一致状态。一致状态是指数据库中的数据应满足完整性约束。除此之外,一致性还有另外一层语义,就是事务的中间状态不能被观察到(这层语义也有说应该属于原子性)。
- 隔离性(Isolation):多个事务并发执行时,一个事务的执行不应影响其他事务的执行,如同只有这一个操作在被数据库所执行一样。
- 持久性(Durability):已被提交的事务对数据库的修改应该永久保存在数据库中。在事务结束时,此操作将不可逆转。
1.2 本地事务
起初,事务仅限于对单一数据库资源的访问控制:
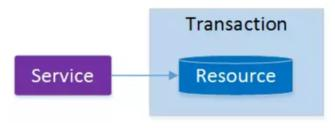
架构服务化以后,事务的概念延伸到了服务中。倘若将一个单一的服务操作作为一个事务,那么整个服务操作只能涉及一个单一的数据库资源:
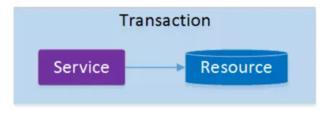
这类基于单个服务单一数据库资源访问的事务,被称为本地事务(Local Transaction)。
分布式事务
本地事务主要限制在单个会话内,不涉及多个数据库资源。但是在基于SOA(Service-Oriented Architecture,面向服务架构)的分布式应用环境下,越来越多的应用要求对多个数据库资源,多个服务的访问都能纳入到同一个事务当中,分布式事务应运而生。
最早的分布式事务应用架构很简单,不涉及服务间的访问调用,仅仅是服务内操作涉及到对多个数据库资源的访问。
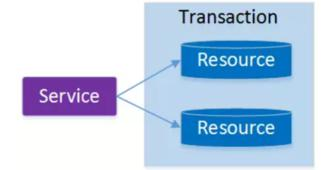
当一个服务操作访问不同的数据库资源,又希望对它们的访问具有事务特性时,就需要采用分布式事务来协调所有的事务参与者。
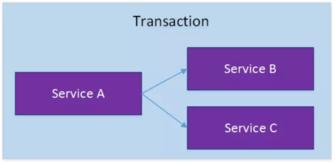
对于上面介绍的分布式事务应用架构,尽管一个服务操作会访问多个数据库资源,但是毕竟整个事务还是控制在单一服务的内部。如果一个服务操作需要调用另外一个服务,这时的事务就需要跨越多个服务了。在这种情况下,起始于某个服务的事务在调用另外一个服务的时候,需要以某种机制流转到另外一个服务,从而使被调用的服务访问的资源也自动加入到该事务当中来。下图反映了这样一个跨越多个服务的分布式事务:
如果将上面这两种场景(一个服务可以调用多个数据库资源,也可以调用其他服务)结合在一起,对此进行延伸,整个分布式事务的参与者将会组成如下图所示的树形拓扑结构。在一个跨服务的分布式事务中,事务的发起者和提交均系同一个,它可以是整个调用的客户端,也可以是客户端最先调用的那个服务。
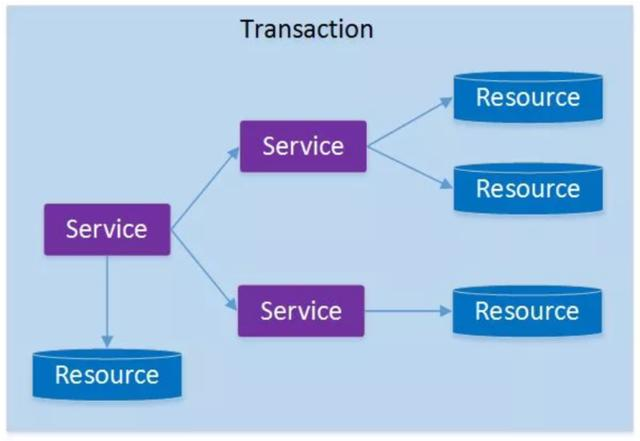
较之基于单一数据库资源访问的本地事务,分布式事务的应用架构更为复杂。
在不同的分布式应用架构下,实现一个分布式事务要考虑的问题并不完全一样,比如对多资源的协调、事务的跨服务传播等,实现机制也是复杂多变。尽管有这么多工程细节需要考虑,但分布式事务最核心的还是其 ACID 特性。因此,想要了解一个分布式事务,就先从了解它是怎么实现事务 ACID 特性开始。
下文将从两个最常见的分布式事务模型入手,着重分析分布式事务的基础共通点,即如何保证分布式事务的 ACID 特性。
分布式理论
想保证集群的ACID几乎是很难达到,或者即使能达到那么效率和性能会大幅下降,这时我们就需要引入一个新的理论原则来适应这种集群的情况,就是 CAP 原则或者叫CAP定理
CAP定理
CAP定理是由加州大学伯克利分校Eric Brewer教授提出来的,他指出WEB服务无法同时满足一下3个属性:
- 一致性:分布式环境下多个节点的数据是否强一致。
- 可用性:分布式服务能一直保证可用状态。当用户发出一个请求后,服务能在有限时间内返回结果。
- 分区容忍性:特指对网络分区的容忍性。
具体地讲在分布式系统中,在任何数据库设计中,一个Web应用至多只能同时支持上面的两个属性。显然,任何横向扩展策略都要依赖于数据分区。因此,设计人员必须在一致性与可用性之间做出选择。
BASE理论
是基于CAP定理演化而来,是对CAP中一致性和可用性权衡的结果。核心思想:即使无法做到强一致性,但每个业务根据自身的特点,采用适当的方式来使系统达到最终一致性。BASE理论指的是:
- Basically Available(基本可用)
- Soft state(软状态)
- Eventually consistent(最终一致性)
分布式事务的解决方案
分布式事务的解决方案有如下几种:
- 全局消息
- 基于可靠消息服务的分布式事务
- TCC
- 最大努力通知
方案1:全局事务(DTP模型)
全局事务基于DTP模型实现。DTP是由X/Open组织提出的一种分布式事务模型——X/Open Distributed Transaction Processing Reference Model。它规定了要实现分布式事务,需要三种角色:
-
AP:Application 应用系统 它就是我们开发的业务系统,在我们开发的过程中,可以使用资源管理器提供的事务接口来实现分布式事务。
-
TM:Transaction Manager 事务管理器
- 分布式事务的实现由事务管理器来完成,它会提供分布式事务的操作接口供我们的业务系统调用。这些接口称为TX接口。
- 事务管理器还管理着所有的资源管理器,通过它们提供的XA接口来同一调度这些资源管理器,以实现分布式事务。
- DTP只是一套实现分布式事务的规范,并没有定义具体如何实现分布式事务,TM可以采用2PC、3PC、Paxos等协议实现分布式事务。
-
RM:Resource Manager 资源管理器
- 能够提供数据服务的对象都可以是资源管理器,比如:数据库、消息中间件、缓存等。大部分场景下,数据库即为分布式事务中的资源管理器。
- 资源管理器能够提供单数据库的事务能力,它们通过XA接口,将本数据库的提交、回滚等能力提供给事务管理器调用,以帮助事务管理器实现分布式的事务管理。
- XA是DTP模型定义的接口,用于向事务管理器提供该资源管理器(该数据库)的提交、回滚等能力。
- DTP只是一套实现分布式事务的规范,RM具体的实现是由数据库厂商来完成的。
- 有没有基于DTP模型的分布式事务中间件?
- DTP模型有啥优缺点?
方案2:基于可靠消息服务的分布式事务
这种实现分布式事务的方式需要通过消息中间件来实现。假设有A和B两个系统,分别可以处理任务A和任务B。此时系统A中存在一个业务流程,需要将任务A和任务B在同一个事务中处理。下面来介绍基于消息中间件来实现这种分布式事务。
- 在系统A处理任务A前,首先向消息中间件发送一条消息
- 消息中间件收到后将该条消息持久化,但并不投递。此时下游系统B仍然不知道该条消息的存在。
- 消息中间件持久化成功后,便向系统A返回一个确认应答;
- 系统A收到确认应答后,则可以开始处理任务A;
- 任务A处理完成后,向消息中间件发送Commit请求。该请求发送完成后,对系统A而言,该事务的处理过程就结束了,此时它可以处理别的任务了。 但commit消息可能会在传输途中丢失,从而消息中间件并不会向系统B投递这条消息,从而系统就会出现不一致性。这个问题由消息中间件的事务回查机制完成,下文会介绍。
- 消息中间件收到Commit指令后,便向系统B投递该消息,从而触发任务B的执行;
- 当任务B执行完成后,系统B向消息中间件返回一个确认应答,告诉消息中间件该消息已经成功消费,此时,这个分布式事务完成。
上述过程可以得出如下几个结论:
- 消息中间件扮演者分布式事务协调者的角色。
- 系统A完成任务A后,到任务B执行完成之间,会存在一定的时间差。在这个时间差内,整个系统处于数据不一致的状态,但这短暂的不一致性是可以接受的,因为经过短暂的时间后,系统又可以保持数据一致性,满足BASE理论。
上述过程中,如果任务A处理失败,那么需要进入回滚流程,如下图所示:
- 若系统A在处理任务A时失败,那么就会向消息中间件发送Rollback请求。和发送Commit请求一样,系统A发完之后便可以认为回滚已经完成,它便可以去做其他的事情。
- 消息中间件收到回滚请求后,直接将该消息丢弃,而不投递给系统B,从而不会触发系统B的任务B。
此时系统又处于一致性状态,因为任务A和任务B都没有执行。
上面所介绍的Commit和Rollback都属于理想情况,但在实际系统中,Commit和Rollback指令都有可能在传输途中丢失。那么当出现这种情况的时候,消息中间件是如何保证数据一致性呢?——答案就是超时询问机制。
系统A除了实现正常的业务流程外,还需提供一个事务询问的接口,供消息中间件调用。当消息中间件收到一条事务型消息后便开始计时,如果到了超时时间也没收到系统A发来的Commit或Rollback指令的话,就会主动调用系统A提供的事务询问接口询问该系统目前的状态。该接口会返回三种结果:
- 提交 若获得的状态是“提交”,则将该消息投递给系统B。
- 回滚 若获得的状态是“回滚”,则直接将条消息丢弃。
- 处理中 若获得的状态是“处理中”,则继续等待。
消息中间件的超时询问机制能够防止上游系统因在传输过程中丢失Commit/Rollback指令而导致的系统不一致情况,而且能降低上游系统的阻塞时间,上游系统只要发出Commit/Rollback指令后便可以处理其他任务,无需等待确认应答。而Commit/Rollback指令丢失的情况通过超时询问机制来弥补,这样大大降低上游系统的阻塞时间,提升系统的并发度。
下面来说一说消息投递过程的可靠性保证。 当上游系统执行完任务并向消息中间件提交了Commit指令后,便可以处理其他任务了,此时它可以认为事务已经完成,接下来消息中间件**一定会保证消息被下游系统成功消费掉!**那么这是怎么做到的呢?这由消息中间件的投递流程来保证。
消息中间件向下游系统投递完消息后便进入阻塞等待状态,下游系统便立即进行任务的处理,任务处理完成后便向消息中间件返回应答。消息中间件收到确认应答后便认为该事务处理完毕!
如果消息在投递过程中丢失,或消息的确认应答在返回途中丢失,那么消息中间件在等待确认应答超时之后就会重新投递,直到下游消费者返回消费成功响应为止。当然,一般消息中间件可以设置消息重试的次数和时间间隔,比如:当第一次投递失败后,每隔五分钟重试一次,一共重试3次。如果重试3次之后仍然投递失败,那么这条消息就需要人工干预。
有的同学可能要问:消息投递失败后为什么不回滚消息,而是不断尝试重新投递?
这就涉及到整套分布式事务系统的实现成本问题。 我们知道,当系统A将向消息中间件发送Commit指令后,它便去做别的事情了。如果此时消息投递失败,需要回滚的话,就需要让系统A事先提供回滚接口,这无疑增加了额外的开发成本,业务系统的复杂度也将提高。对于一个业务系统的设计目标是,在保证性能的前提下,最大限度地降低系统复杂度,从而能够降低系统的运维成本。
不知大家是否发现,上游系统A向消息中间件提交Commit/Rollback消息采用的是异步方式,也就是当上游系统提交完消息后便可以去做别的事情,接下来提交、回滚就完全交给消息中间件来完成,并且完全信任消息中间件,认为它一定能正确地完成事务的提交或回滚。然而,消息中间件向下游系统投递消息的过程是同步的。也就是消息中间件将消息投递给下游系统后,它会阻塞等待,等下游系统成功处理完任务返回确认应答后才取消阻塞等待。为什么这两者在设计上是不一致的呢?
首先,上游系统和消息中间件之间采用异步通信是为了提高系统并发度。业务系统直接和用户打交道,用户体验尤为重要,因此这种异步通信方式能够极大程度地降低用户等待时间。此外,异步通信相对于同步通信而言,没有了长时间的阻塞等待,因此系统的并发性也大大增加。但异步通信可能会引起Commit/Rollback指令丢失的问题,这就由消息中间件的超时询问机制来弥补。
那么,消息中间件和下游系统之间为什么要采用同步通信呢?
异步能提升系统性能,但随之会增加系统复杂度;而同步虽然降低系统并发度,但实现成本较低。因此,在对并发度要求不是很高的情况下,或者服务器资源较为充裕的情况下,我们可以选择同步来降低系统的复杂度。 我们知道,消息中间件是一个独立于业务系统的第三方中间件,它不和任何业务系统产生直接的耦合,它也不和用户产生直接的关联,它一般部署在独立的服务器集群上,具有良好的可扩展性,所以不必太过于担心它的性能,如果处理速度无法满足我们的要求,可以增加机器来解决。而且,即使消息中间件处理速度有一定的延迟那也是可以接受的,因为前面所介绍的BASE理论就告诉我们了,我们追求的是最终一致性,而非实时一致性,因此消息中间件产生的时延导致事务短暂的不一致是可以接受的。
方案3:最大努力通知(定期校对)
最大努力通知也被称为定期校对,其实在方案二中已经包含,这里再单独介绍,主要是为了知识体系的完整性。这种方案也需要消息中间件的参与,其过程如下:
- 上游系统在完成任务后,向消息中间件同步地发送一条消息,确保消息中间件成功持久化这条消息,然后上游系统可以去做别的事情了;
- 消息中间件收到消息后负责将该消息同步投递给相应的下游系统,并触发下游系统的任务执行;
- 当下游系统处理成功后,向消息中间件反馈确认应答,消息中间件便可以将该条消息删除,从而该事务完成。
上面是一个理想化的过程,但在实际场景中,往往会出现如下几种意外情况:
- 消息中间件向下游系统投递消息失败
- 上游系统向消息中间件发送消息失败
对于第一种情况,消息中间件具有重试机制,我们可以在消息中间件中设置消息的重试次数和重试时间间隔,对于网络不稳定导致的消息投递失败的情况,往往重试几次后消息便可以成功投递,如果超过了重试的上限仍然投递失败,那么消息中间件不再投递该消息,而是记录在失败消息表中,消息中间件需要提供失败消息的查询接口,下游系统会定期查询失败消息,并将其消费,这就是所谓的“定期校对”。
如果重复投递和定期校对都不能解决问题,往往是因为下游系统出现了严重的错误,此时就需要人工干预。
对于第二种情况,需要在上游系统中建立消息重发机制。可以在上游系统建立一张本地消息表,并将 任务处理过程 和 向本地消息表中插入消息 这两个步骤放在一个本地事务中完成。如果向本地消息表插入消息失败,那么就会触发回滚,之前的任务处理结果就会被取消。如果这量步都执行成功,那么该本地事务就完成了。接下来会有一个专门的消息发送者不断地发送本地消息表中的消息,如果发送失败它会返回重试。当然,也要给消息发送者设置重试的上限,一般而言,达到重试上限仍然发送失败,那就意味着消息中间件出现严重的问题,此时也只有人工干预才能解决问题。
对于不支持事务型消息的消息中间件,如果要实现分布式事务的话,就可以采用这种方式。它能够通过重试机制+定期校对实现分布式事务,但相比于第二种方案,它达到数据一致性的周期较长,而且还需要在上游系统中实现消息重试发布机制,以确保消息成功发布给消息中间件,这无疑增加了业务系统的开发成本,使得业务系统不够纯粹,并且这些额外的业务逻辑无疑会占用业务系统的硬件资源,从而影响性能。
因此,尽量选择支持事务型消息的消息中间件来实现分布式事务,如RocketMQ。
方案4:TCC(两阶段型、补偿型)
TCC即为Try Confirm Cancel,它属于补偿型分布式事务。顾名思义,TCC实现分布式事务一共有三个步骤:
- Try:尝试待执行的业务
- 这个过程并未执行业务,只是完成所有业务的一致性检查,并预留好执行所需的全部资源
- Confirm:执行业务
- 这个过程真正开始执行业务,由于Try阶段已经完成了一致性检查,因此本过程直接执行,而不做任何检查。并且在执行的过程中,会使用到Try阶段预留的业务资源。
- Cancel:取消执行的业务
- 若业务执行失败,则进入Cancel阶段,它会释放所有占用的业务资源,并回滚Confirm阶段执行的操作。
下面以一个转账的例子来解释下TCC实现分布式事务的过程。
假设用户A用他的账户余额给用户B发一个100元的红包,并且余额系统和红包系统是两个独立的系统。
-
Try
- 创建一条转账流水,并将流水的状态设为交易中
- 将用户A的账户中扣除100元(预留业务资源)
- Try成功之后,便进入Confirm阶段
- Try过程发生任何异常,均进入Cancel阶段
-
Confirm
- 向B用户的红包账户中增加100元
- 将流水的状态设为交易已完成
- Confirm过程发生任何异常,均进入Cancel阶段
- Confirm过程执行成功,则该事务结束
-
Cancel
- 将用户A的账户增加100元
- 将流水的状态设为交易失败
在传统事务机制中,业务逻辑的执行和事务的处理,是在不同的阶段由不同的部件来完成的:业务逻辑部分访问资源实现数据存储,其处理是由业务系统负责;事务处理部分通过协调资源管理器以实现事务管理,其处理由事务管理器来负责。二者没有太多交互的地方,所以,传统事务管理器的事务处理逻辑,仅需要着眼于事务完成(commit/rollback)阶段,而不必关注业务执行阶段。
TCC全局事务必须基于RM本地事务来实现全局事务
TCC服务是由Try/Confirm/Cancel业务构成的, 其Try/Confirm/Cancel业务在执行时,会访问资源管理器(Resource Manager,下文简称RM)来存取数据。这些存取操作,必须要参与RM本地事务,以使其更改的数据要么都commit,要么都rollback。
这一点不难理解,考虑一下如下场景:
假设图中的服务B没有基于RM本地事务(以RDBS为例,可通过设置auto-commit为true来模拟),那么一旦[B:Try]操作中途执行失败,TCC事务框架后续决定回滚全局事务时,该[B:Cancel]则需要判断[B:Try]中哪些操作已经写到DB、哪些操作还没有写到DB:假设[B:Try]业务有5个写库操作,[B:Cancel]业务则需要逐个判断这5个操作是否生效,并将生效的操作执行反向操作。
不幸的是,由于[B:Cancel]业务也有n(0<=n<=5)个反向的写库操作,此时一旦[B:Cancel]也中途出错,则后续的[B:Cancel]执行任务更加繁重。因为,相比第一次[B:Cancel]操作,后续的[B:Cancel]操作还需要判断先前的[B:Cancel]操作的n(0<=n<=5)个写库中哪几个已经执行、哪几个还没有执行,这就涉及到了幂等性问题。而对幂等性的保障,又很可能还需要涉及额外的写库操作,该写库操作又会因为没有RM本地事务的支持而存在类似问题。。。可想而知,如果不基于RM本地事务,TCC事务框架是无法有效的管理TCC全局事务的。
反之,基于RM本地事务的TCC事务,这种情况则会很容易处理:[B:Try]操作中途执行失败,TCC事务框架将其参与RM本地事务直接rollback即可。后续TCC事务框架决定回滚全局事务时,在知道“[B:Try]操作涉及的RM本地事务已经rollback”的情况下,根本无需执行[B:Cancel]操作。
换句话说,基于RM本地事务实现TCC事务框架时,一个TCC型服务的cancel业务要么执行,要么不执行,不需要考虑部分执行的情况。
TCC事务框架应该提供Confirm/Cancel服务的幂等性保障
一般认为,服务的幂等性,是指针对同一个服务的多次(n>1)请求和对它的单次(n=1)请求,二者具有相同的副作用。
在TCC事务模型中,Confirm/Cancel业务可能会被重复调用,其原因很多。比如,全局事务在提交/回滚时会调用各TCC服务的Confirm/Cancel业务逻辑。执行这些Confirm/Cancel业务时,可能会出现如网络中断的故障而使得全局事务不能完成。因此,故障恢复机制后续仍然会重新提交/回滚这些未完成的全局事务,这样就会再次调用参与该全局事务的各TCC服务的Confirm/Cancel业务逻辑。
既然Confirm/Cancel业务可能会被多次调用,就需要保障其幂等性。 那么,应该由TCC事务框架来提供幂等性保障?还是应该由业务系统自行来保障幂等性呢? 个人认为,应该是由TCC事务框架来提供幂等性保障。如果仅仅只是极个别服务存在这个问题的话,那么由业务系统来负责也是可以的;然而,这是一类公共问题,毫无疑问,所有TCC服务的Confirm/Cancel业务存在幂等性问题。TCC服务的公共问题应该由TCC事务框架来解决;而且,考虑一下由业务系统来负责幂等性需要考虑的问题,就会发现,这无疑增大了业务系统的复杂度。
作者:大闲人柴毛毛
链接:https://juejin.im/post/5aa3c7736fb9a028bb189bca
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
下面我们分别来看4种模式(AT、TCC、Saga、XA)的分布式事务实现。
AT模式
AT 模式是一种无侵入的分布式事务解决方案。
阿里seata框架,实现了该模式。
在 AT 模式下,用户只需关注自己的“业务 SQL”,用户的 “业务 SQL” 作为一阶段,Seata 框架会自动生成事务的二阶段提交和回滚操作。
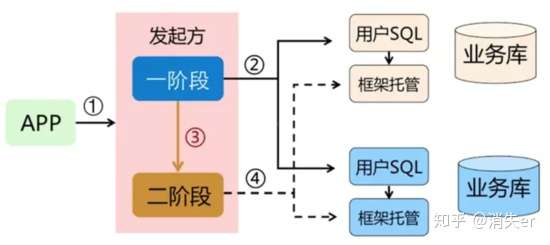
AT 模式如何做到对业务的无侵入 :
- 一阶段:
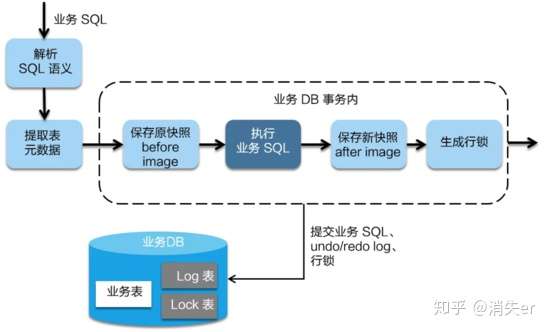
在一阶段,Seata 会拦截“业务 SQL”,首先解析 SQL 语义,找到“业务 SQL”要更新的业务数据,在业务数据被更新前,将其保存成“before image”,然后执行“业务 SQL”更新业务数据,在业务数据更新之后,再将其保存成“after image”,最后生成行锁。以上操作全部在一个数据库事务内完成,这样保证了一阶段操作的原子性。
- 二阶段提交:
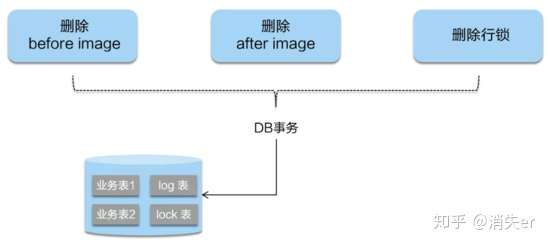
二阶段如果是提交的话,因为“业务 SQL”在一阶段已经提交至数据库, 所以 Seata 框架只需将一阶段保存的快照数据和行锁删掉,完成数据清理即可。
- 二阶段回滚:
二阶段如果是回滚的话,Seata 就需要回滚一阶段已经执行的“业务 SQL”,还原业务数据。回滚方式便是用“before image”还原业务数据;但在还原前要首先要校验脏写,对比“数据库当前业务数据”和 “after image”,如果两份数据完全一致就说明没有脏写,可以还原业务数据,如果不一致就说明有脏写,出现脏写就需要转人工处理。
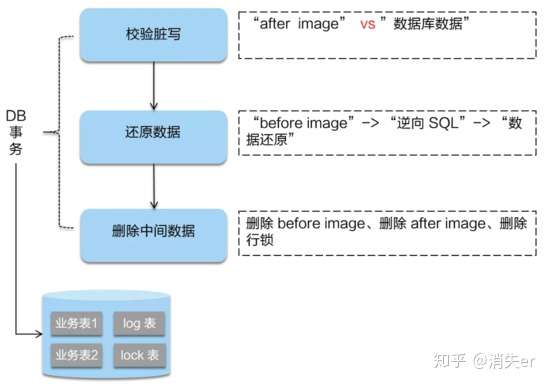
AT 模式的一阶段、二阶段提交和回滚均由 Seata 框架自动生成,用户只需编写“业务 SQL”,便能轻松接入分布式事务,AT 模式是一种对业务无任何侵入的分布式事务解决方案。
TCC 模式
TCC 模式需要用户根据自己的业务场景实现 Try、Confirm 和 Cancel 三个操作;事务发起方在一阶段执行 Try 方式,在二阶段提交执行 Confirm 方法,二阶段回滚执行 Cancel 方法。
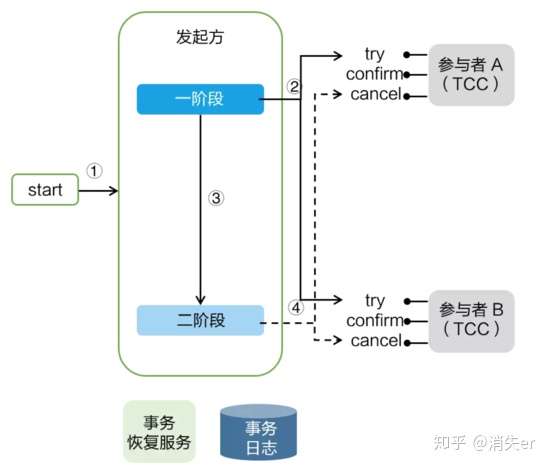
TCC 三个方法描述:
- Try:资源的检测和预留;
- Confirm:执行的业务操作提交;要求 Try 成功 Confirm 一定要能成功;
- Cancel:预留资源释放;
TCC 的实践经验
蚂蚁金服TCC实践,总结以下注意事项:
➢业务模型分2阶段设计
➢并发控制
➢允许空回滚
➢防悬挂控制
➢幂等控制
1 TCC 设计 - 业务模型分 2 阶段设计:
用户接入 TCC ,最重要的是考虑如何将自己的业务模型拆成两阶段来实现。
以“扣钱”场景为例,在接入 TCC 前,对 A 账户的扣钱,只需一条更新账户余额的 SQL 便能完成;但是在接入 TCC 之后,用户就需要考虑如何将原来一步就能完成的扣钱操作,拆成两阶段,实现成三个方法,并且保证一阶段 Try 成功的话 二阶段 Confirm 一定能成功。

如上图所示,Try 方法作为一阶段准备方法,需要做资源的检查和预留。在扣钱场景下,Try 要做的事情是就是检查账户余额是否充足,预留转账资金,预留的方式就是冻结 A 账户的 转账资金。Try 方法执行之后,账号 A 余额虽然还是 100,但是其中 30 元已经被冻结了,不能被其他事务使用。
二阶段 Confirm 方法执行真正的扣钱操作。Confirm 会使用 Try 阶段冻结的资金,执行账号扣款。Confirm 方法执行之后,账号 A 在一阶段中冻结的 30 元已经被扣除,账号 A 余额变成 70 元 。
如果二阶段是回滚的话,就需要在 Cancel 方法内释放一阶段 Try 冻结的 30 元,使账号 A 的回到初始状态,100 元全部可用。
用户接入 TCC 模式,最重要的事情就是考虑如何将业务模型拆成 2 阶段,实现成 TCC 的 3 个方法,并且保证 Try 成功 Confirm 一定能成功。相对于 AT 模式,TCC 模式对业务代码有一定的侵入性,但是 TCC 模式无 AT 模式的全局行锁,TCC 性能会比 AT 模式高很多。
2 TCC 设计 - 允许空回滚:
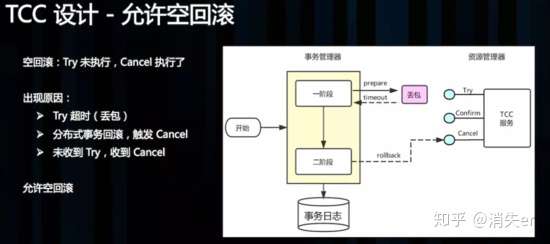
Cancel 接口设计时需要允许空回滚。在 Try 接口因为丢包时没有收到,事务管理器会触发回滚,这时会触发 Cancel 接口,这时 Cancel 执行时发现没有对应的事务 xid 或主键时,需要返回回滚成功。让事务服务管理器认为已回滚,否则会不断重试,而 Cancel 又没有对应的业务数据可以进行回滚。
3 TCC 设计 - 防悬挂控制:
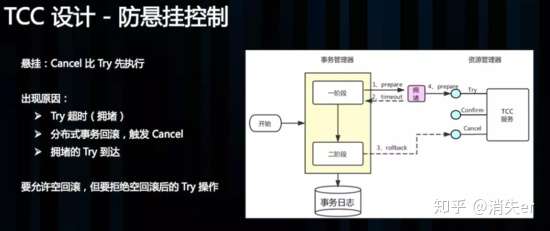
悬挂的意思是:Cancel 比 Try 接口先执行,出现的原因是 Try 由于网络拥堵而超时,事务管理器生成回滚,触发 Cancel 接口,而最终又收到了 Try 接口调用,但是 Cancel 比 Try 先到。按照前面允许空回滚的逻辑,回滚会返回成功,事务管理器认为事务已回滚成功,则此时的 Try 接口不应该执行,否则会产生数据不一致,所以我们在 Cancel 空回滚返回成功之前先记录该条事务 xid 或业务主键,标识这条记录已经回滚过,Try 接口先检查这条事务xid或业务主键如果已经标记为回滚成功过,则不执行 Try 的业务操作。
4 TCC 设计 - 幂等控制:

幂等性的意思是:对同一个系统,使用同样的条件,一次请求和重复的多次请求对系统资源的影响是一致的。因为网络抖动或拥堵可能会超时,事务管理器会对资源进行重试操作,所以很可能一个业务操作会被重复调用,为了不因为重复调用而多次占用资源,需要对服务设计时进行幂等控制,通常我们可以用事务 xid 或业务主键判重来控制。
saga模式
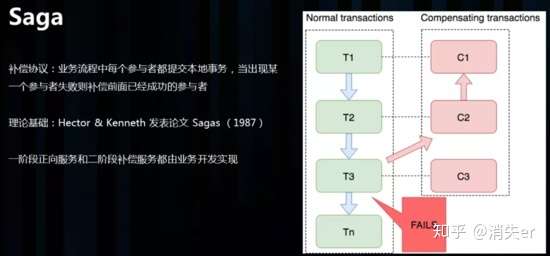
Saga 理论出自 Hector & Kenneth 1987发表的论文 Sagas。
saga模式的实现,是长事务解决方案。
Saga 是一种补偿协议,在 Saga 模式下,分布式事务内有多个参与者,每一个参与者都是一个冲正补偿服务,需要用户根据业务场景实现其正向操作和逆向回滚操作。
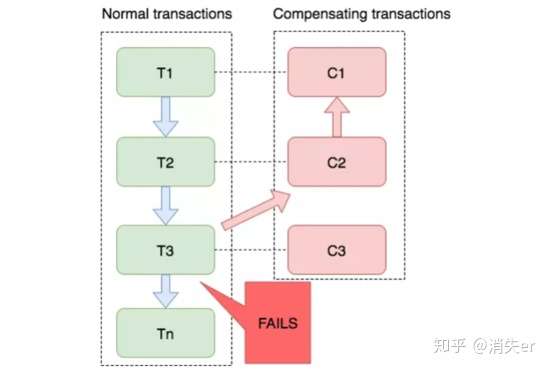
如图:T1~T3都是正向的业务流程,都对应着一个冲正逆向操作C1~C3
分布式事务执行过程中,依次执行各参与者的正向操作,如果所有正向操作均执行成功,那么分布式事务提交。如果任何一个正向操作执行失败,那么分布式事务会退回去执行前面各参与者的逆向回滚操作,回滚已提交的参与者,使分布式事务回到初始状态。
Saga 正向服务与补偿服务也需要业务开发者实现。因此是业务入侵的。
Saga 模式下分布式事务通常是由事件驱动的,各个参与者之间是异步执行的,Saga 模式是一种长事务解决方案。
Saga 模式使用场景
Saga 模式适用于业务流程长且需要保证事务最终一致性的业务系统,Saga 模式一阶段就会提交本地事务,无锁、长流程情况下可以保证性能。
事务参与者可能是其它公司的服务或者是遗留系统的服务,无法进行改造和提供 TCC 要求的接口,可以使用 Saga 模式。
Saga模式的优势是:
- 一阶段提交本地数据库事务,无锁,高性能;
- 参与者可以采用事务驱动异步执行,高吞吐;
- 补偿服务即正向服务的“反向”,易于理解,易于实现;
缺点:Saga 模式由于一阶段已经提交本地数据库事务,且没有进行“预留”动作,所以不能保证隔离性。后续会讲到对于缺乏隔离性的应对措施。
与TCC实践经验相同的是,Saga 模式中,每个事务参与者的冲正、逆向操作,需要支持:
- 空补偿:逆向操作早于正向操作时;
- 防悬挂控制:空补偿后要拒绝正向操作
- 幂等
XA模式
XA是X/Open DTP组织(X/Open DTP group)定义的两阶段提交协议,XA被许多数据库(如Oracle、DB2、SQL Server、MySQL)和中间件等工具(如CICS 和 Tuxedo)本地支持 。
X/Open DTP模型(1994)包括应用程序(AP)、事务管理器(TM)、资源管理器(RM)。
XA接口函数由数据库厂商提供。XA规范的基础是两阶段提交协议2PC。
JTA(Java Transaction API) 是Java实现的XA规范的增强版 接口。
在XA模式下,需要有一个[全局]协调器,每一个数据库事务完成后,进行第一阶段预提交,并通知协调器,把结果给协调器。协调器等所有分支事务操作完成、都预提交后,进行第二步;第二步:协调器通知每个数据库进行逐个commit/rollback。
其中,这个全局协调器就是XA模型中的TM角色,每个分支事务各自的数据库就是RM。
MySQL 提供的XA实现(https://dev.mysql.com/doc/refman/5.7/en/xa.html )
XA模式下的 开源框架有atomikos,其开发公司也有商业版本。
XA模式缺点:事务粒度大。高并发下,系统可用性低。因此很少使用。
AT、TCC、Saga、XA模式分析
四种分布式事务模式,分别在不同的时间被提出,每种模式都有它的适用场景
- AT 模式是无侵入的分布式事务解决方案,适用于不希望对业务进行改造的场景,几乎0学习成本。
- TCC 模式是高性能分布式事务解决方案,适用于核心系统等对性能有很高要求的场景。
- Saga 模式是长事务解决方案,适用于业务流程长且需要保证事务最终一致性的业务系统,Saga 模式一阶段就会提交本地事务,无锁,长流程情况下可以保证性能,多用于渠道层、集成层业务系统。事务参与者可能是其它公司的服务或者是遗留系统的服务,无法进行改造和提供 TCC 要求的接口,也可以使用 Saga 模式。
- XA模式是分布式强一致性的解决方案,但性能低而使用较少。
常见的分布式事务解决方案
1.基于XA协议的两阶段提交
XA是一个分布式事务协议,由Tuxedo提出。XA中大致分为两部分:事务管理器和本地资源管理器。其中本地资源管理器往往由数据库实现,比如Oracle、DB2这些商业数据库都实现了XA接口,而事务管理器作为全局的调度者,负责各个本地资源的提交和回滚。XA实现分布式事务的原理如下:
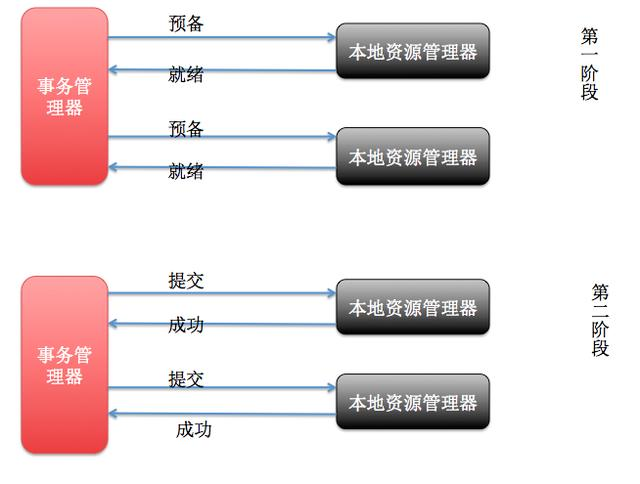
总的来说,XA协议比较简单,而且一旦商业数据库实现了XA协议,使用分布式事务的成本也比较低。但是,XA也有致命的缺点,那就是性能不理想,特别是在交易下单链路,往往并发量很高,XA无法满足高并发场景。XA目前在商业数据库支持的比较理想,在mysql数据库中支持的不太理想,mysql的XA实现,没有记录prepare阶段日志,主备切换回导致主库与备库数据不一致。许多nosql也没有支持XA,这让XA的应用场景变得非常狭隘。
2.消息事务+最终一致性
所谓的消息事务就是基于消息中间件的两阶段提交,本质上是对消息中间件的一种特殊利用,它是将本地事务和发消息放在了一个分布式事务里,保证要么本地操作成功成功并且对外发消息成功,要么两者都失败,开源的RocketMQ就支持这一特性,具体原理如下:
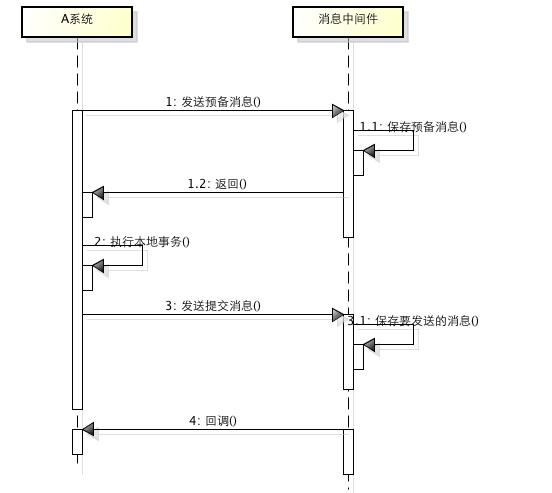
1、A系统向消息中间件发送一条预备消息
2、消息中间件保存预备消息并返回成功
3、A执行本地事务
4、A发送提交消息给消息中间件
通过以上4步完成了一个消息事务。对于以上的4个步骤,每个步骤都可能产生错误,下面一一分析:
- 步骤一出错,则整个事务失败,不会执行A的本地操作
- 步骤二出错,则整个事务失败,不会执行A的本地操作
- 步骤三出错,这时候需要回滚预备消息,怎么回滚?答案是A系统实现一个消息中间件的回调接口,消息中间件会去不断执行回调接口,检查A事务执行是否执行成功,如果失败则回滚预备消息
- 步骤四出错,这时候A的本地事务是成功的,那么消息中间件要回滚A吗?答案是不需要,其实通过回调接口,消息中间件能够检查到A执行成功了,这时候其实不需要A发提交消息了,消息中间件可以自己对消息进行提交,从而完成整个消息事务
基于消息中间件的两阶段提交往往用在高并发场景下,将一个分布式事务拆成一个消息事务(A系统的本地操作+发消息)+B系统的本地操作,其中B系统的操作由消息驱动,只要消息事务成功,那么A操作一定成功,消息也一定发出来了,这时候B会收到消息去执行本地操作,如果本地操作失败,消息会重投,直到B操作成功,这样就变相地实现了A与B的分布式事务。原理如下:
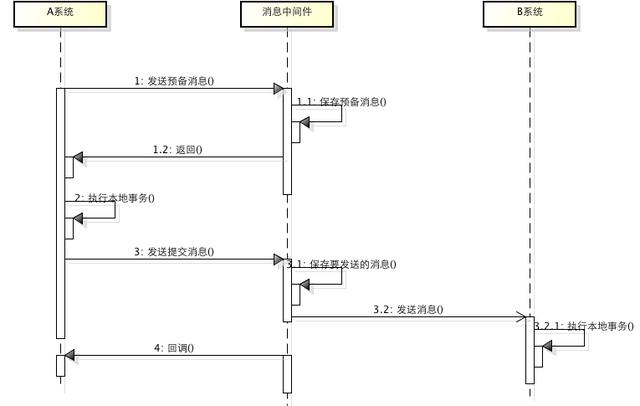
虽然上面的方案能够完成A和B的操作,但是A和B并不是严格一致的,而是最终一致的,我们在这里牺牲了一致性,换来了性能的大幅度提升。当然,这种玩法也是有风险的,如果B一直执行不成功,那么一致性会被破坏,具体要不要玩,还是得看业务能够承担多少风险。
3.TCC 模型
TCC(Try-Confirm-Cancel)分布式事务模型相对于 XA 等传统模型,其特征在于它不依赖资源管理器(RM)对分布式事务的支持,而是通过对业务逻辑的分解来实现分布式事务。
TCC 模型认为对于业务系统中一个特定的业务逻辑,其对外提供服务时,必须接受一些不确定性,即对业务逻辑初步操作的调用仅是一个临时性操作,调用它的主业务服务保留了后续的取消权。如果主业务服务认为全局事务应该回滚,它会要求取消之前的临时性操作,这就对应从业务服务的取消操作。而当主业务服务认为全局事务应该提交时,它会放弃之前临时性操作的取消权,这对应从业务服务的确认操作。每一个初步操作,最终都会被确认或取消。
因此,针对一个具体的业务服务,TCC 分布式事务模型需要业务系统提供三段业务逻辑:
初步操作 Try:完成所有业务检查,预留必须的业务资源。
确认操作 Confirm:真正执行的业务逻辑,不作任何业务检查,只使用 Try 阶段预留的业务资源。因此,只要 Try 操作成功,Confirm 必须能成功。另外,Confirm 操作需满足幂等性,保证一笔分布式事务有且只能成功一次。
取消操作 Cancel:释放 Try 阶段预留的业务资源。同样的,Cancel 操作也需要满足幂等性。
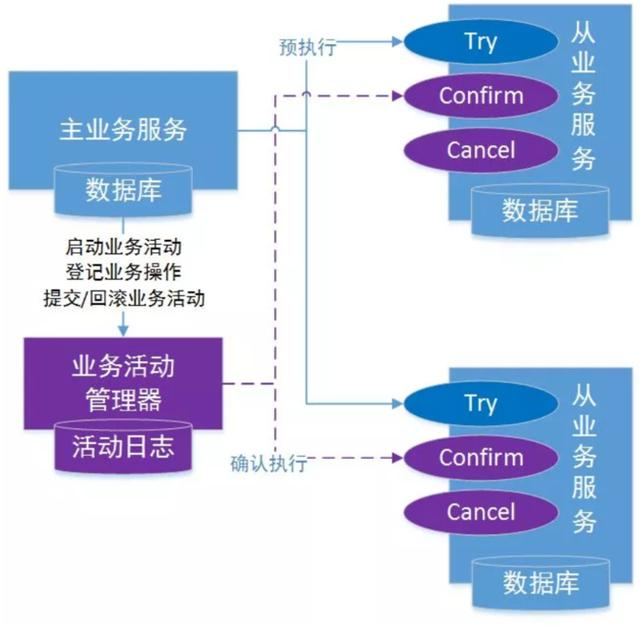
TCC 分布式事务模型包括三部分:
1.主业务服务:主业务服务为整个业务活动的发起方,服务的编排者,负责发起并完成整个业务活动。
2.从业务服务:从业务服务是整个业务活动的参与方,负责提供 TCC 业务操作,实现初步操作(Try)、确认操作(Confirm)、取消操作(Cancel)三个接口,供主业务服务调用。
3.业务活动管理器:业务活动管理器管理控制整个业务活动,包括记录维护 TCC 全局事务的事务状态和每个从业务服务的子事务状态,并在业务活动提交时调用所有从业务服务的 Confirm 操作,在业务活动取消时调用所有从业务服务的 Cancel 操作。
一个完整的 TCC 分布式事务流程如下:
- 主业务服务首先开启本地事务;
- 主业务服务向业务活动管理器申请启动分布式事务主业务活动;
- 然后针对要调用的从业务服务,主业务活动先向业务活动管理器注册从业务活动,然后调用从业务服务的 Try 接口;
- 当所有从业务服务的 Try 接口调用成功,主业务服务提交本地事务;若调用失败,主业务服务回滚本地事务;
- 若主业务服务提交本地事务,则 TCC 模型分别调用所有从业务服务的 Confirm 接口;若主业务服务回滚本地事务,则分别调用 Cancel 接口;
- 所有从业务服务的 Confirm 或 Cancel 操作完成后,全局事务结束。
TCC模型小结
所谓的TCC编程模式,也是两阶段提交的一个变种。TCC提供了一个编程框架,将整个业务逻辑分为三块:Try、Confirm和Cancel三个操作。以在线下单为例,Try阶段会去扣库存,Confirm阶段则是去更新订单状态,如果更新订单失败,则进入Cancel阶段,会去恢复库存。总之,TCC就是通过代码人为实现了两阶段提交,不同的业务场景所写的代码都不一样,复杂度也不一样,因此,这种模式并不能很好地被复用。
消息事务+最终一致性
所谓的消息事务就是基于消息中间件的两阶段提交,本质上是对消息中间件的一种特殊利用,它是将本地事务和发消息放在了一个分布式事务里,保证要么本地操作成功成功并且对外发消息成功,要么两者都失败,开源的RocketMQ就支持这一特性,具体原理如下:
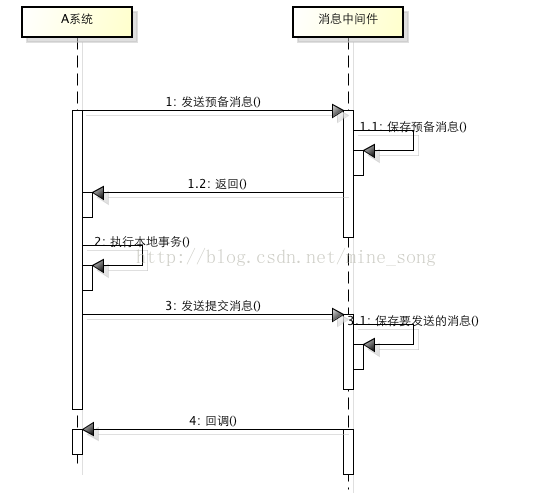
1、A系统向消息中间件发送一条预备消息
2、消息中间件保存预备消息并返回成功
3、A执行本地事务
4、A发送提交消息给消息中间件
通过以上4步完成了一个消息事务。对于以上的4个步骤,每个步骤都可能产生错误,下面一一分析:
- 步骤一出错,则整个事务失败,不会执行A的本地操作
- 步骤二出错,则整个事务失败,不会执行A的本地操作
- 步骤三出错,这时候需要回滚预备消息,怎么回滚?答案是A系统实现一个消息中间件的回调接口,消息中间件会去不断执行回调接口,检查A事务执行是否执行成功,如果失败则回滚预备消息
- 步骤四出错,这时候A的本地事务是成功的,那么消息中间件要回滚A吗?答案是不需要,其实通过回调接口,消息中间件能够检查到A执行成功了,这时候其实不需要A发提交消息了,消息中间件可以自己对消息进行提交,从而完成整个消息事务
基于消息中间件的两阶段提交往往用在高并发场景下,将一个分布式事务拆成一个消息事务(A系统的本地操作+发消息)+B系统的本地操作,其中B系统的操作由消息驱动,只要消息事务成功,那么A操作一定成功,消息也一定发出来了,这时候B会收到消息去执行本地操作,如果本地操作失败,消息会重投,直到B操作成功,这样就变相地实现了A与B的分布式事务。原理如下:
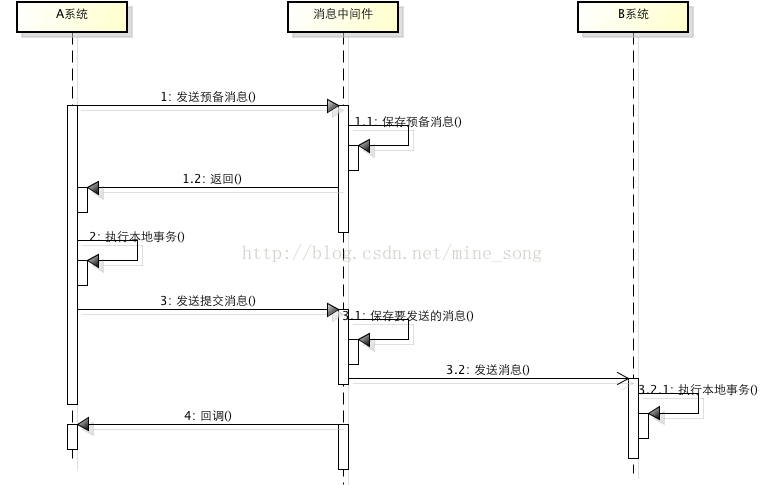
虽然上面的方案能够完成A和B的操作,但是A和B并不是严格一致的,而是最终一致的,我们在这里牺牲了一致性,换来了性能的大幅度提升。当然,这种玩法也是有风险的,如果B一直执行不成功,那么一致性会被破坏,具体要不要玩,还是得看业务能够承担多少风险。
分布式事务总结
分布式事务,本质上是对多个数据库的事务进行统一控制,按照控制力度可以分为:不控制、部分控制和完全控制。不控制就是不引入分布式事务,部分控制就是各种变种的两阶段提交,包括上面提到的消息事务+最终一致性、TCC模式,而完全控制就是完全实现两阶段提交。部分控制的好处是并发量和性能很好,缺点是数据一致性减弱了,完全控制则是牺牲了性能,保障了一致性,体用哪种方式,最终还是取决于业务场景。作为技术人员,一定不能忘了技术是为业务服务的,不要为了技术而技术,针对不同业务进行技术选型也是一种很重要的能力!
参考地址
分布式事务?No, 最终一致性: https://zhuanlan.zhihu.com/p/25933039
聊聊分布式事务,再说说解决方案: https://www.cnblogs.com/savorboard/p/distributed-system-transaction-consistency.html
分布式事务的4种模式: https://zhuanlan.zhihu.com/p/78599954

 浙公网安备 33010602011771号
浙公网安备 33010602011771号