
HTTP协议及WWW服务应用
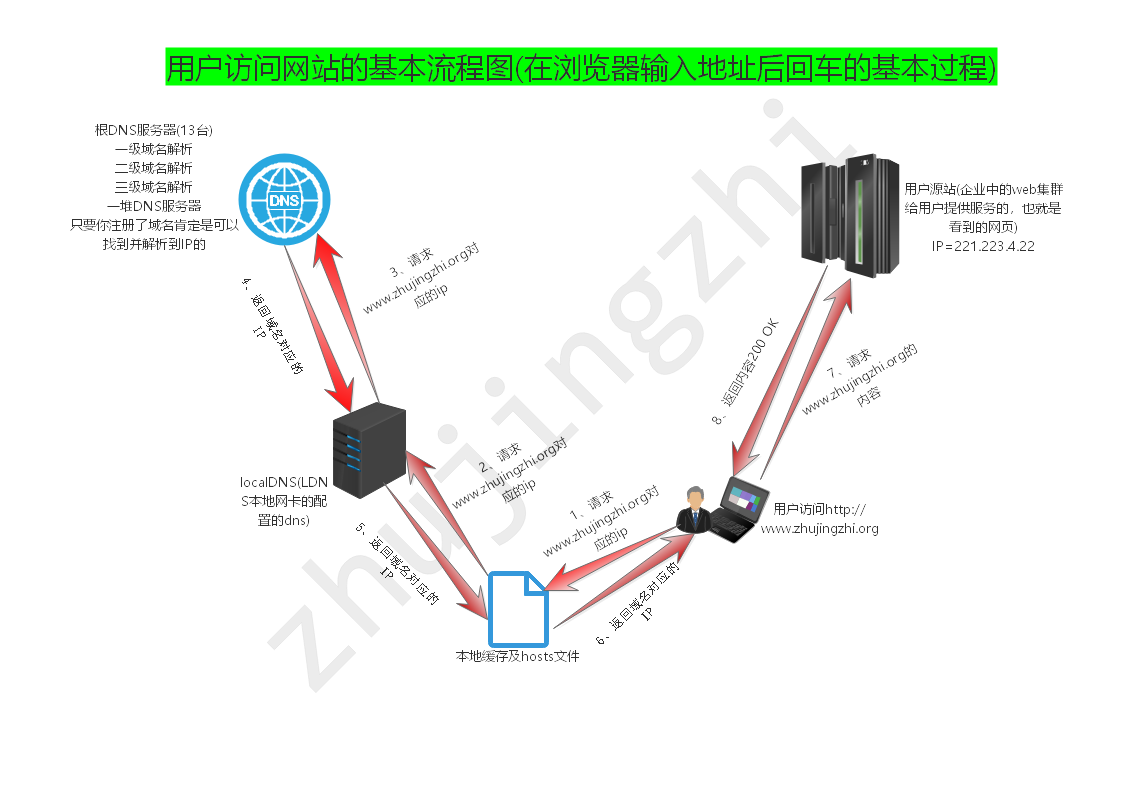
一、用户访问网站的流程图
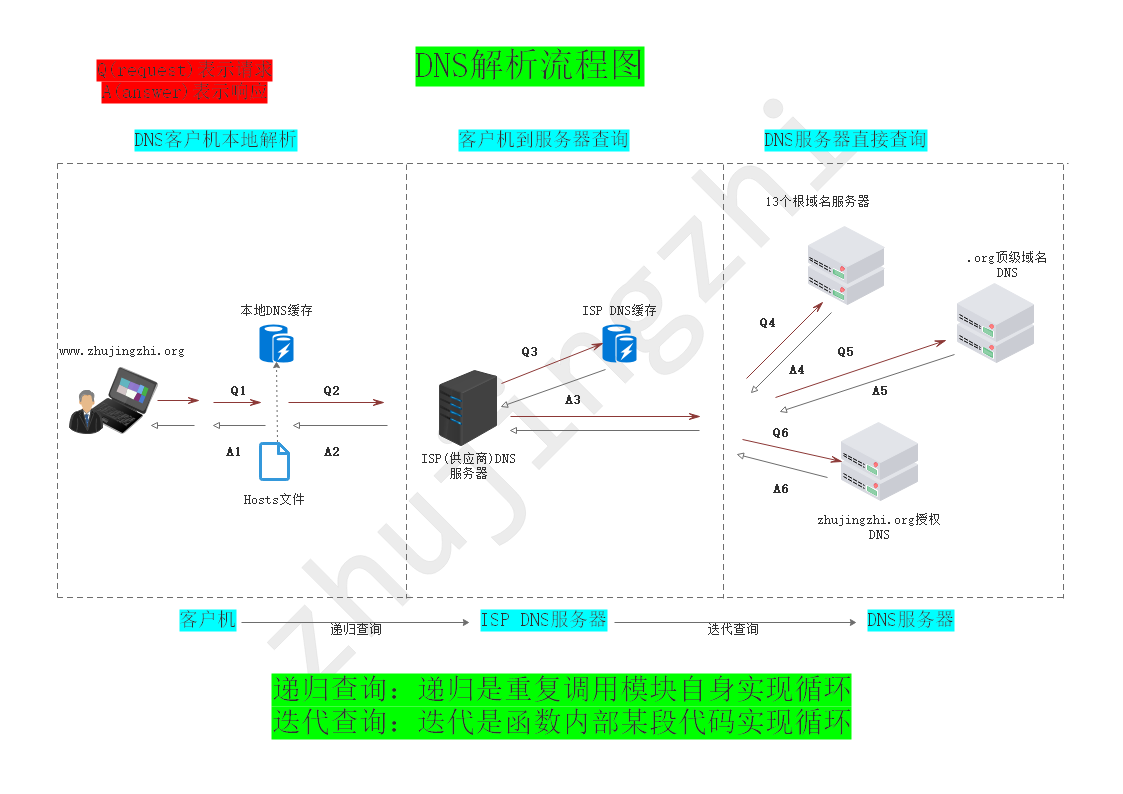
二、DNS解析的流程图
三、用户访问网站的基本流程原理阐述
① 用户在浏览器中输入请求的地址回车
② 先找本地的缓存和Hosts文件,有解析的对应IP直接返回个客户端IP地址
③ 本地和hosts都没有找网卡配置的LDNS缓存,有解析的对应IP直接返回个客户端IP地址
④ LDNS缓存没有找DNS服务器(包括根域,顶级域),有解析的对应IP直接返回个客户端IP地址
⑤ 客户端拿到IP请求网站服务器这里面包含(TCP连接三次捂手,http请求连接)
⑥ 网站服务器返回内容给客户端这里面包含(http响应报文,TCP四次挥手)
四、DNS解析的原理阐述
① 用户在浏览器中输入请求的地址回车
② 先找本地的缓存和Hosts文件,有解析的对应IP直接返回个客户端IP地址
③ 本地和hosts都没有找网卡配置的LDNS缓存,有解析的对应IP直接返回个客户端IP地址
④ LDNS缓存没有 找DNS根服务器(13台,根服务器会有自己的调度算法应答,根服务器没有整个域名的解析结记录,只有顶级域的域名org/com等)
⑤ 因为根服务器没有整个域名解析的记录只有顶级域的,所有他会告诉LDNS去找顶级域 .org的服务器,这样LDNS就拿到了org的地址
⑥ 因为客户要的是整个的域名解析地址,所以还要请求顶级域的下一级的服务器,顶级域会把下一级的DNS服务器地址给LDNS
⑦ LDNS会拿着这个地址请求 zhujingzhi域名的授权DNS,这个DNS域名服务商做好解析的服务器(这台服务器上肯定有设置好的www的解析记录,不然是不能访问的)
⑧ LDNS会拿到这个解析的IP返回给客户端,并且会在本地缓存写入一份,客户端也会在本地的缓存存一份
五、什么是HTTP协议与WWW服务
① HTTP协议,全称HyperText Transfer Protocol,中文名字叫超文本传输协议,是互联网中最常用的一种网络协议。它有很多的应用,但是最流行的就是用于Web浏览器和Web服务器之间的通讯,即WWW应用或Web应用
② WWW,全称World Wide Web,常称为Web,中文名字万维网,它是目前互联网最受欢迎的信息服务形式。HTTP协议的WWW服务应用默认的端口是80,另外还有一个加密的WWW服务应用https 默认端口是443,主要用于和钱有关的业务
PS:http协议的www应用是B/S架构(浏览器和服务端通讯,擅长广域网) ssh、rsync等都是C/S架构的(客户端和服务端通讯,擅长局域网)
六、HTTP协议的请求方法
在每个HTTP通讯中,每个HTTP请求报文都会包含一个请求的方法,告诉服务端要做什么操作
常用的HTTP请求方法
| HTTP方法 | 作用描述 |
| GET | 客户端请求指定资源信息,服务器返回指定资源 |
| HEAD | 只请求响应报文中的HTTP首部 |
| POST | 将客户端的数据提交到服务器 |
| PUT | 从客户端向服务器传送的数据取代指定的文档内容 |
| DELETE | 请求服务器删除Request-URL所标识的资源 |
| MOVE | 请求服务器将指定的页面移至另一个网络地址 |
七、HTTP协议的状态码
HTTP状态码(HTTP Status Code)是用来表示Web服务器响应http请求状态的数字代码
不同范围的状态码及作用
| 状态码范围 | 作用描述 |
| 100-199 | 用于指定客户端相应的某些动作 |
| 200-299 | 用于表示请求成功 |
| 300-399 | 用于已经移动的文件并且常被包含在定位头信息中指定新的地址信息 |
| 400-499 | 用于指出客户端的错误 |
| 500-599 | 用于指出服务端的错误 |
生产环境常用状态码及作用
| 状态代码 | 详细描述说明 |
| 200 - OK | 服务器成功返回网页 |
| 301 - Moved Permanently | 永久跳转,所有请求的网页将永久跳转到被设定好的新位置 |
| 403 - Forbidden | 禁止访问,这个请求是合法的,但是服务器做了设置没有权限访问该网页 |
| 404 - Not Found | 服务器找不到客户端请求的指定页面,可能是客户端请求的资源缺失导致的 |
| 500 - Internal Server Error | 内部服务器错误,服务器遇到了意料不到的错误,不能完成客户端请求 |
| 502 - Bad Gateway | 坏的网关,一般是代理服务器请求后端服务时,后端服务不可用,一般为反向代理服务器下面的节点导致的问题 |
| 503 - Server Unavailable | 服务当前不可用,因为服务器超载或者停机维护,或者反向代理服务器后面没有可以提供服务的节点 |
| 504 - Gateway TimeOut | 网关超时,一般是网关代理服务器请求后端服务时,后端服务没有在特定的时间内完成处理 |
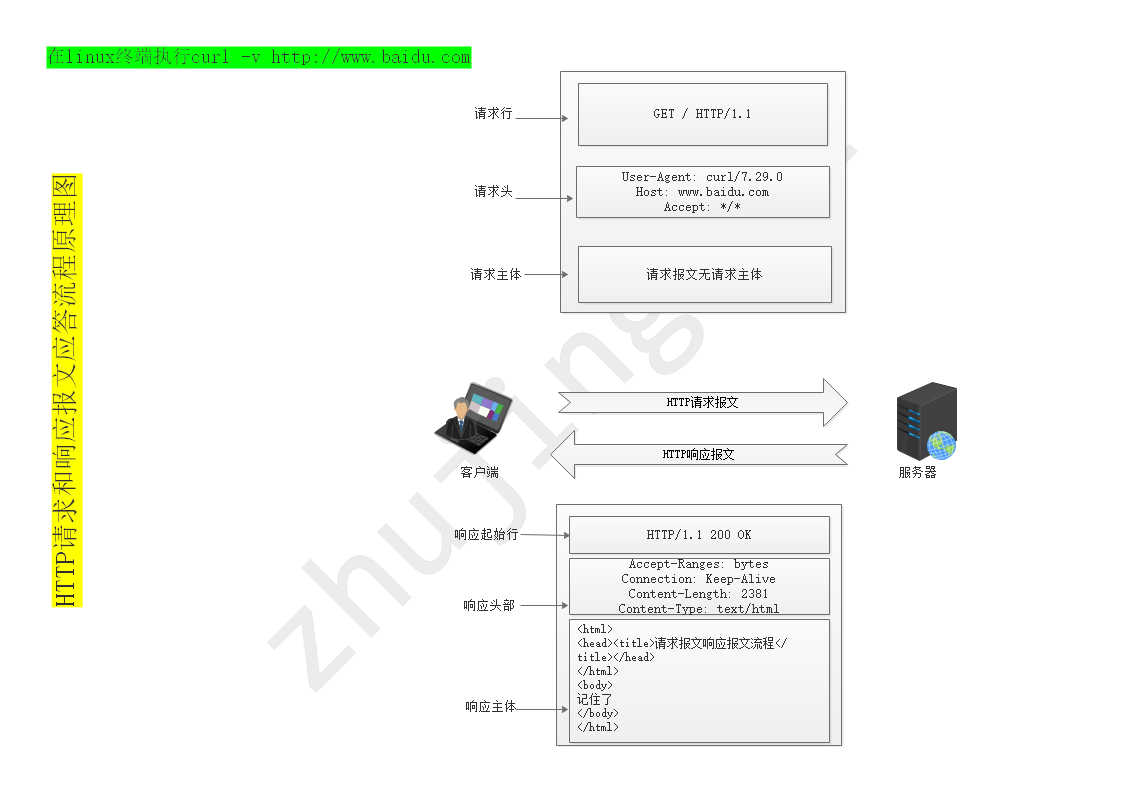
八、HTTP报文(数据包)请求报文和响应报文
① 请求报文(Request Message)
HTTP请求报文是由请求行,请求的头部(header)、空行和请求报文主体几部分组成
HTTP请求报文内部说明
| 报文格式 | 报文信息 |
| 请求行 | 请求方法和URL协议版本(GET /index.html HTTP/1.1) |
| 请求头 | 字段名1:值1(Accept-Language:zh-cn) |
| 空行 | 空白无内容(表示请求头部的信息结束了) |
| 请求报文主体 | GET方法没有请求报文主体,Post方法才有 |
② 响应报文(Reponse Message)
HTTP响应报文是由起始行、响应头部(header)、空行和响应报文主体几部分组成,和HTTP请求报文类似
HTTP响应报文内部说明
| 报文格式 | 报文信息 |
| 起始行 | 协议及版本号 数字状态码 状态信息(HTTP/1.1 200 OK) |
| 响应头部 | 字段1:值1(Content-Length:78) |
| 空行 | 空白无内容(表示请求头部的信息结束了) |
| 响应报文主体 |
<html> <head><title>zhujingzhi</title></head> <body> I am zhujingzhi </body> </html> |
请求报文和响应报文应答原理图
九、HTTP协议请求的具体工作流程
① 客户在浏览器输入要访问的地址
② Web浏览器请求DNS服务器把域名解析成IP(这个就是DNS的解析原理)
③ Web浏览器将端口号 80 从访问地址中解析出来
④ Web浏览器通过解析后的IP和端口与Web服务器之间建立一条TCP连接(TCP3次捂手)
⑤ 建立TCP连接后,Web浏览器向Web服务器发送一条HTTP请求报文
⑥ Web服务器响应并读取浏览器的请求信息,然后返回一条HTTP的响应报文
⑦ Web服务器关闭http连接,关闭TCP连接(TCP四次挥手),web浏览器显示内容
十、静态网页
核心特点
① 程序在客户端浏览器解析,不需要读取后端的数据库,因此性能和效率很高
② 因为没有后端数据库的支持,所以和用户的交互性较差,能实现的功能很少
③ 网页内容不变,容易被搜索引擎收录
④ 在URL中一般不会出现“?”和“&”符号
静态网页的架构思想
在高并发,高访问量的场景下做架构优化,涉及的关键环节就是把动态网页转换成静态网页,而不直接请求数据库和动态服务器,并且可以把静态内容推送到前端缓存或者CDN中提供服务,这样就可以提升用户的体验,节约服务器和维护成本。
十一、动态网页
核心特点
① 在URL中一定会出现“?”和“&”符号,因为有这些符号所以不容易被搜索引擎收录(这就是关于搜索引擎的蜘蛛原理了)
② 网页一般以数据库技术为基础,大大降低了网站的维护工作
③ 用户交互性好,实现的功能比较多 如:注册、登录等
④ 程序在服务端解析,因此,会消耗大量的CPU和内存、I/O资源,并且多数还要读取数据库服务
动态网页的架构思想
一般来说,静态网页的性能效率是动态网页的10~30倍,且动态网页的效率很差,并发能力较低,在高并发场景中,应尽可能的转换成静态网页,动静转换几乎是所以高并发网站必备的架构思想,此外动态转静态也要根据业务需求设计,例如,对于更新频繁的网站如果设计不好,就有可能会产生数据不一致的情况,即用户看到的不是最新的内容,而是静态的内容
十二、伪静态网页
伪静态就是通过某些技术(如:rewrite)把动态网页的URL地址伪装成静态的URL地址,实际上还是动态网页
核心特点
① 利用rewrite技术将动态网页伪装成静态网页
② 便于搜索引擎的录入,提升用户的体验
③ 访问性能没有提升,并且转换静态会消耗资源,因此性能会下降
④ 尽可能的将动态转换为静态
⑤ 并发量不是很大或者动态更新过于频繁的时候,用rewrite实现伪静态也是不错的
⑥ 伪静态实现的过程一般是由产品提出需求,开完运维共同完成
十三、网站访问流量的度量之IP访问量
IP(独立的IP)即Internet Protocol ,这里指的是独立的IP数,独立的IP数是指不同IP地址的计算机访问网站时被计算的总次数,独立IP数是衡量网站流量的一个重要的指标,一般一天内相同IP地址的客户端访问网站页面只被计算一次,记录独立IP的时间可以为一天也可以是一个月,目前的标准是一天。
一个局域网的所有客户端去访问一个网站,那这个网站记录的就是一个IP,为什么会这样呢?原因就是因为公司采用的是局域网共享上网的,即通过路由器NAT地址转换上网,每个计算机在局域网都有不一样的IP地址,但是在外网上,就必须都要由路由器把每个私网地址转换成路由器接口的固定公网IP。(可以使用防护墙映射多个IP)
计算机通过ADSL拨号上网,每次重拨号都会换一个IP地址进行访问
十四、网站访问流量的度量之PV访问量
PV(Page View) 中文名:网页浏览,即页面的浏览量或者点击量,不管客户端是不是相同,IP是不是相同,用户的每次访问都会被记入一个PV,具体的方法就是客户端发送请求,服务端处理请求给客户端返回即一个PV(打开页面即PV,有可能强制刷新页面也会记入一个PV)
十五、网站访问流量的度量之UV访问量
UV(Unique Visitor) 即独立访客,同一台客户端(PC或者移动端)访问网站被计算为一个访客,一天内相同的客户端访问同一个网站只计算一次UV UV一般是以客户端的Cookie等技术作为统计数据的,实际上统计会有误差。
考虑到一台客户端可能会有多个人使用,因此UV实际上并不是一定是独立的自然人访问。
十六、怎么对网站IP\PV\UV进行计算
IP的计算
① 分析web服务器的访问日志,对相同的IP进行去重,这个不是很准确
② 在web网站末尾嵌入JS等统计的代码,网站全部打开,IP传给统计IP的服务器,这种方法一般被第三方的统计公司或者内部开发日志分析程序时使用
③ 使用统计工具,谷歌的统计(GA)
PV的计算
① 分析Web服务的访问日志(需要排除js、css及各种图片的日志信息),只计算HTML PHP等页面的数量
② 在web网站末尾嵌入JS等统计的代码,网站全部打开,访问数量传给统计PV的服务器,这种方法一般被第三方的统计公司或者内部开发日志分析程序时使用
③ 使用统计工具,谷歌的统计(GA)
UV的计算
① 通过客户端的HTTP的请求报文分析(分析客户端报文的相同信息,不是很准确的方法)
② 通过Cookie鉴别(这个方法也有问题,就是为了安全,客户端关闭的Cookie功能,那么这个方法就不准确了)
上面的方法只能得打近似的UV ,而不是准确的数量
PS:UV的计算相对于IP和PV来说 不但麻烦,而且要开发比较复杂的程序才能得到想要的结果,一般企业市场及运营人员可能比较关注UV的数量
十七、并发连接
什么是并发连接,并发连接就是网站服务器在单位时间内能够处理的最大连接数(1秒钟正在处理的连接,正在关闭的连接,正在建立的连接的总和)
-------------------------------------------
个性签名:在逆境中要看到生活的美,在希望中别忘记不断奋斗
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!
万水千山总是情,打赏一分行不行,所以如果你心情还比较高兴,也是可以扫码打赏博主,哈哈哈(っ•̀ω•́)っ✎⁾⁾!


也可以关注我的微信公众号,不定时更新技术文章(kubernetes,Devops,Python)等


 浙公网安备 33010602011771号
浙公网安备 33010602011771号