

torch 显存分析
参考:https://zhuanlan.zhihu.com/p/677203832
理论分析
最近做算法,遇到奇怪的事情,模型很小,占用显存很大,于是打算分析下。
显存主要有:
- 模型参数(parameters)
- 前向传播:执行模型的前向传播,产生中间激活值(intermediate activations);
- 后向传播:执行模型的后向传播,产生梯度(gradients);
- 梯度更新:执行模型参数的更新,第一次执行的时候产生优化器状态(optimizer states)。
计算模型参数:
total = sum([param.nelement() for param in net.parameters()])
print('Number of parameter: % .4fM' % (total / 1e6))
显存占用(设参数量是N):
- 模型参数:4N(默认torch.float32占4字节)
- 中间激活值:取决于模型的层数和每层的输出大小。
- 梯度的显存占用:梯度的数量与参数数量相同,所以是4N。
- 优化器状态:SGD是4N,AdamW是8N(存储一阶矩估计和二阶矩估计)
分析方法1:torch.profiler
执行代码
from torch.profiler import profile, record_function, ProfilerActivity
def trace_handler(prof: torch.profiler.profile):
prof.export_chrome_trace(f"visual_mem.json")
prof.export_memory_timeline(f"visual_mem.html", device="cuda:0")
with profile(activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA],
schedule=torch.profiler.schedule(
wait=1, # 前1步不采样
warmup=1, # 第1步作为热身,不计入结果
active=3, # 采集后面3步的性能数据
repeat=1), # 重复1轮
# on_trace_ready=torch.profiler.tensorboard_trace_handler('./log'), # 保存日志以供 TensorBoard 可视化
on_trace_ready=trace_handler,
profile_memory=True, # 分析内存分配
record_shapes=True,
with_stack=True # 记录操作的调用堆栈信息
) as prof:
for step, (x0, x1, y) in enumerate(train_dataloader):
prof.step()
if step >= 5:
break
with record_function("## data ##"):
x0, x1, y = x0.to(device), x1.to(device), y.to(device)
with record_function("## forward ##"):
preds = model(x0, x1)
with record_function("## backward ##"):
loss = criterion(preds, y)
optimizer.zero_grad()
loss.backward()
with record_function("## optimizer ##"):
optimizer.step()
问题待解决:tensorboard没有显示出数据。
直接打开html,显示如下:
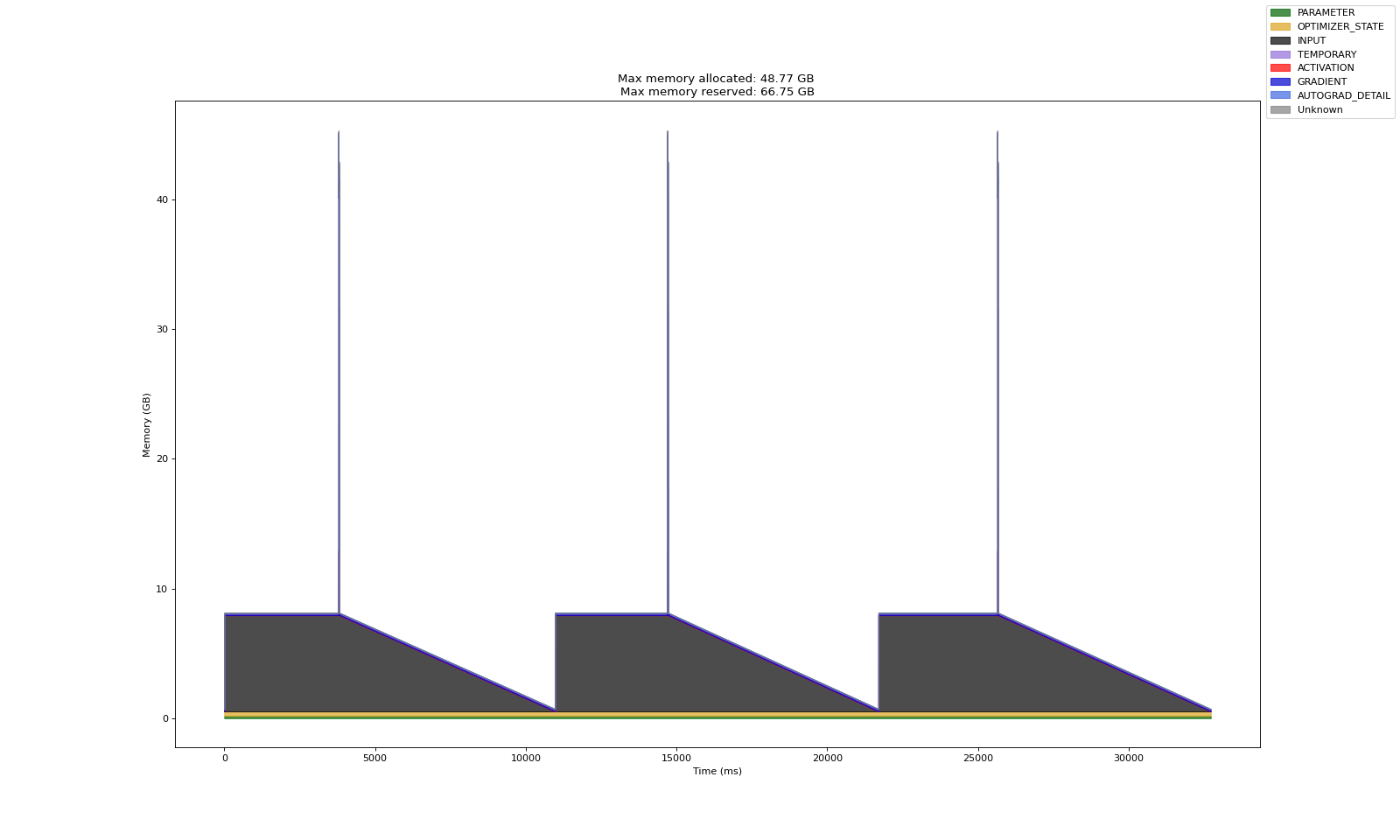
发现1:parameter, optimizer_stater, input的大小正常
发现2:有尖峰值,但是看不清是那类数据。(估计是activation和autograd_detail)
发现3:gradient, autograd_detail有什么区别? GRADIENT 是最终计算得到的梯度值,而 AUTOGRAD_DETAIL 是自动微分过程中用于存储中间计算结果和梯度计算图(compute graph)。两者在内存使用上有所区别,GRADIENT 更直接地与模型参数更新相关,而 AUTOGRAD_DETAIL 则是梯度计算过程中的一个辅助部分。
分析方法2:SnapshotAPI
代码执行
torch.cuda.memory._record_memory_history(max_entries=100000)
for step, (x0, x1, y) in enumerate(train_dataloader):
if step >= 8:
break
x0, x1, y = x0.to(device), x1.to(device), y.to(device)
preds = model(x0, x1)
loss = criterion(preds, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
torch.cuda.memory._dump_snapshot('visual_mem.pickle')
torch.cuda.memory._record_memory_history(enabled=None)
将pickle文件拖拽到浏览器(如chrome)网址:https://pytorch.org/memory_viz 中。
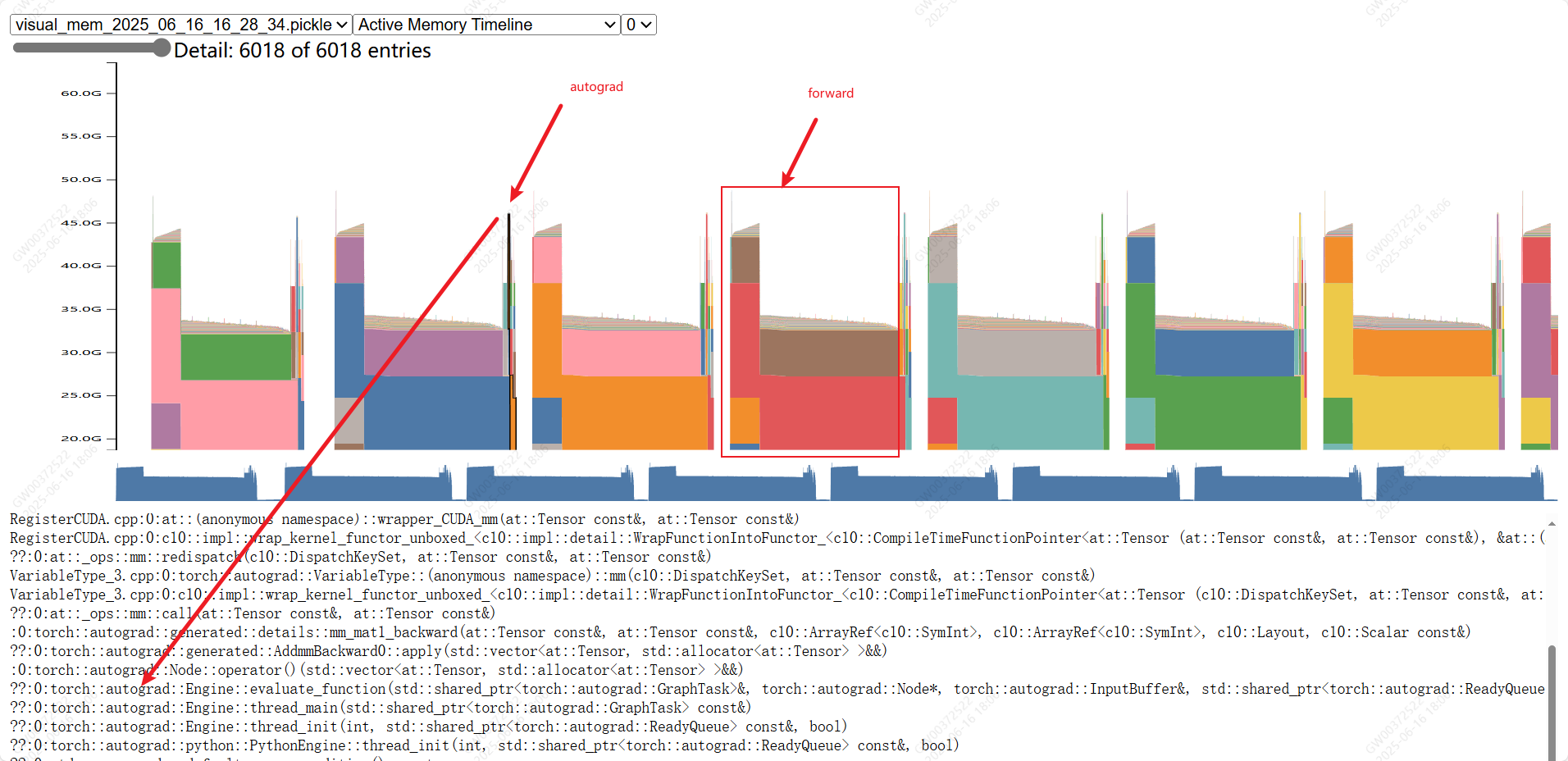
发现:大部分是前向传播占用的显存(中间激活值);以及autograd_detail占用的显存。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号