爬取大量风景图片--python爬虫
分享源码:
from email import header
from importlib.resources import contents
import re
import urllib.request
from urllib import request
from bs4 import BeautifulSoup
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
x=0
def crawl(url):
headers={'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36'}
req=request.Request(url,headers=headers)
page=urllib.request.urlopen(req,timeout=2000)
contents=page.read()
# print(contents)
soup=BeautifulSoup(contents,'html.parser')
my_girl=soup.find_all('img')
global x
for girl in my_girl:
link=girl.get('src')
print(link)
x+=1
urllib.request.urlretrieve(link,'..\img\%s.jpg'%x)
for i in range(30):
url='https://www.tupianzj.com/meinv/mm/list_218_'+str(i+1)+'.html'
crawl(url)
print("下载完成,共下载"+str(x)+"张色图")
要享用源码
- 需要了解一点儿python的知识(比如模块,包机制什么的)和安装python编译环境,因为用的时候你需要改一下url地址,pip下载bs4,还有改一下你自己的headers
- 需要一颗爱美的心
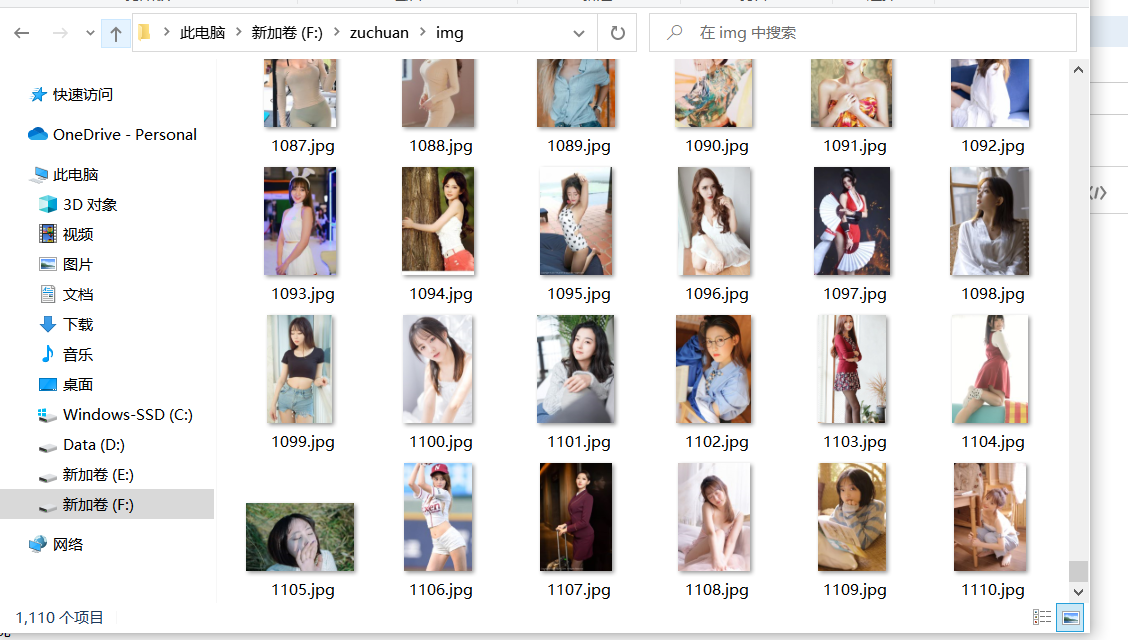
爬的也不多,1个网站,30个页面,1110张风景。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号