
python re正则表达式
目录
正则表达式
re
正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
正则表达式是所有的语言都可以使用。
字符组:
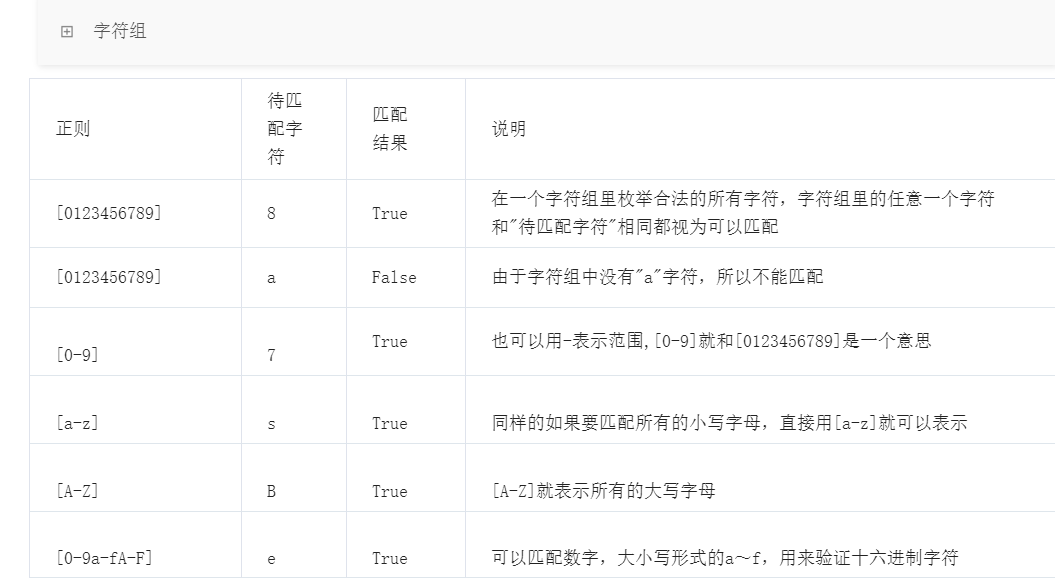
字符:

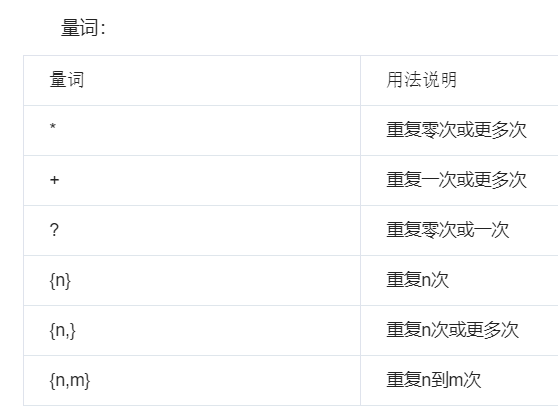
量词
量词必须跟在正则符号的后面,量词只能够限制紧挨着它的那一个正则符号。
分组()
有多个正则符号需要重复多次的时候或者当成一个整体进行操作,那么就可以进行分组。
贪婪匹配
只要满足满足匹配的要求,结果都会匹配出来,我们把这样的匹配叫做贪婪匹配。
note:在匹配的时候默认是贪婪匹配。
取消贪婪匹配
可以在量词的后面加上一个?就可以将贪婪匹配变成非贪婪匹配。
re模块
re 模块使 Python 语言拥有全部的正则表达式功能。
re.findall
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
语法:
re.findall(pattern, string, flags=0) # or pattern.findall(string[, pos[, endpos]])
Example:
import re
res = re.findall('a','zhuang jason tank')
if res:
print(res)
re.search
re.search 扫描整个字符串并返回第一个成功的匹配。
语法:
re.search(pattern, string, flags=0)
案例:
import re
res= re.search('a','zhuang ason ank')
if res:
print(res.group())
re.macth
从字符串的开头开始匹配,匹配到一个或多个返回匹配对象,没有匹配到返回None。
note:
1. 多行情况下,只会从头开始匹配,不会匹配多行的开头。
语法:
re.match(pattern, string, flags=0)
说明:
pattern:正则表达式
string:被匹配的字符串
flags:用于控制正则表达式的匹配方式。如:是否区分大小写,多行匹配等。
https://docs.python.org/zh-cn/3/library/re.html
案例:
import re
res = re.match('z','zhuang')
print(res) # <re.Match object; span=(0, 1), match='z'>
print(res.group()) # z
res2 = re.match('a','zhuang')
print(res2) # None
print(res2.group()) # AttributeError: 'NoneType' object has no attribute 'group'

 浙公网安备 33010602011771号
浙公网安备 33010602011771号