

《cgic编程 (二) — 实例 》
1.向浏览器打印信息
1.c
#include <stdio.h>
#include "cgic.h"
#include <string.h>
#include <stdlib.h>
int cgiMain() {
cgiHeaderContentType("text/html");
fprintf(cgiOut, "<HTML><HEAD>/n");
fprintf(cgiOut, "<TITLE>My First CGI</TITLE></HEAD>/n");
fprintf(cgiOut, "<BODY><H1>Hello CGIC</H1></BODY>/n");
fprintf(cgiOut, "</HTML>/n");
return 0;
}
gcc 1.c -o 1.cgi -lcgic。
将1.cgi放在/var/www/cgi-bin/中

2.获得Get请求字符串
Get请求就是我们在浏览器地址栏输入URL时发送请求的方式,或者我们在HTML中定义一个表单(form)时,把action属性设为“Get”时的工作方式;
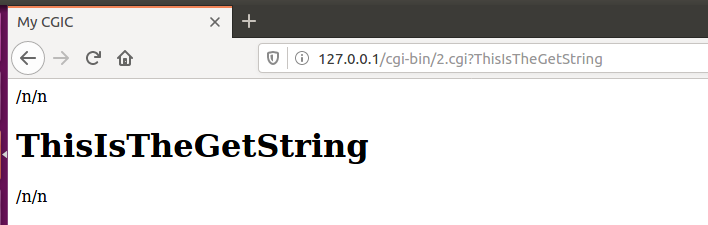
Get请求字符串就是跟在URL后面以问号“?”开始的字符串,但不包括问号。比如这样的一个请求:http://127.0.0.1/cgi-bin/out.cgi?ThisIsTheGetString
在上面这个URL中,“ThisIsTheGetString”就是Get请求字符串。
在进入我们自己编写的cgi代码之前,CGIC库已经事先把这个字符串取到了,我们可以在程序中直接获得,要做的仅仅是在你编写的cgiMain方法前面加入以下声明:
extern char *cgiQueryString;
实例:
#include <stdio.h>
#include "cgic.h"
#include <string.h>
#include <stdlib.h>
extern char *cgiQueryString;
int cgiMain() {
cgiHeaderContentType("text/html");
fprintf(cgiOut, "<HTML><HEAD>/n");
fprintf(cgiOut, "<TITLE>My CGIC</TITLE></HEAD>/n");
fprintf(cgiOut, "<BODY>");
fprintf(cgiOut, "<H1>%s</H1>",cgiQueryString);
fprintf(cgiOut, "</BODY>/n");
fprintf(cgiOut, "</HTML>/n");
return 0;
}
编译以上程序为2.cgi。
在浏览器中输入http://127.0.0.1/cgi-bin/2.cgi?ThisIsTheGetString。
3.通过html中表单访问对应的cgi
test.html
<html> <head> <title>Test</title> </head> <body> <form action="cgi-bin/out.cgi" method="get"> <input type="text" name="theText"> <input type="submit" value="Continue →"> </form> </body> </html>
将test.html放在/var/www/目录下。
点击continue
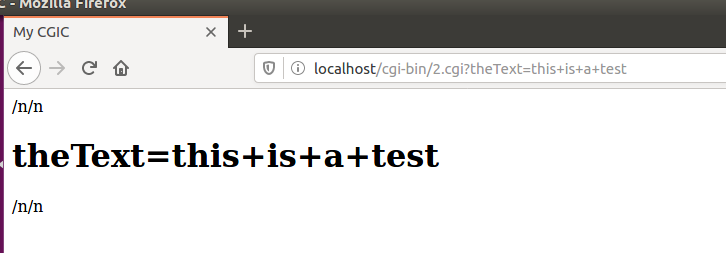
其中“+”就是空格,因为url会把空格传输的以用"+"替换。
4.反转义
浏览器在发送Get请求时,会把请求字符串进行转义操作(英文术语为: escape); 比如,我们在地址栏输入(注意最后”it’s me”中的空格):
http://localhost/~Jack/cgi-bin/out.cgi?it's me
浏览器会把它转义为:
http://localhost/~Jack/cgi-bin/out.cgi?it's%20me
在上一篇最后给出的例子中,如果在文本框内输入:it's me
浏览器最终发送的请求为:http://localhost/cgi-bin/2.cgi?theText=it%27s+me
但是最终显示为:theText=it%27s+me
通过CGIC,我们可以把这些被转义后的字符还原为我们本来的输入,这个过程就叫“反转义” (Unescape)。
整个过程分三个步骤:
1)打开cgic.c,找到这一行语句
static cgiUnescapeResultType cgiUnescapeChars(char **sp, char *cp, int len);
注意,我们要找的只是这个函数声明,不是函数定义。
2)在这个函数声明语句的上方,你会看到一个结构体定义
typedef enum {
cgiUnescapeSuccess,
cgiUnescapeMemory
} cgiUnescapeResultType;
把这几行语句复制到cgic.h文件中,并在这里把它注释掉。
同时还要删除在第一步中找到的函数声明语句中的“static”关键字。
3)我们现在就可以使用反转义函数cgiUnescapeChars了
在你自己的代码(按照惯例,还是test.c)中,加入以下声明语句即可
extern cgiUnescapeResultType cgiUnescapeChars(char **sp, char *cp, int len);
实例:
#include <stdio.h>
#include "cgic.h"
#include <string.h>
#include <stdlib.h>
extern char *cgiQueryString;
extern cgiUnescapeResultType cgiUnescapeChars(char **sp, char *cp, int len);
int cgiMain() {
char * buffer;
cgiHeaderContentType("text/html");
fprintf(cgiOut, "<HTML><HEAD>/n");
fprintf(cgiOut, "<TITLE>My CGI</TITLE></HEAD>/n");
fprintf(cgiOut, "<BODY>");
cgiUnescapeChars(&buffer, cgiQueryString, strlen(cgiQueryString));
fprintf(cgiOut, "<H1>%s</H1>",buffer);
fprintf(cgiOut, "</BODY>/n");
fprintf(cgiOut, "</HTML>/n");
free(buffer);
return 0;
}
值得注意的是,buffer的存储空间是cgiUnescapeChars帮你分配的,但最后要由你自己来释放(free),这一点千万不可忘记。
讲一下为什么不得不用这种hacker的方式来完成该任务,而CGIC不显式提供?
CGIC 的出发点是,我们平时只需要解析请求中的键值对,比如:”?q=nice&client=IE”,当我们在服务端查询“q”的值时,我们就能得到 “nice”。CGIC有一族函数帮助我们完成这个任务,比如cgiFormString(以后会讲到)。在解析这种请求格式的时候,如果我们提供的参数值含有被转义的字符,那么CGIC就会在内部调用cgiUnescapeChars完成反转义。
但是,有时候我们会发送非常复杂的Get请求字符串,但并不是“键-值”对的格式。这就需要直接使用cgiUnescapeChars进行反转义了。
例如:假设我们有个服务端cgi程序chat.cgi,这是个网络聊天机器人(也许你可以开发自己的Web版MSN机器人、QQ机器人)。如果我们发送如下请求:
http://127.0.0.1/cgi-bin/chat.cgi?"this is a cgi user"
那么chat.cgi就会把“this is a cgi user”当做你对它说的话,经过处理,它会回复一段语句。为了方便,我们并没有写成“键-值”对的形式。这个时候被我们hack的cgiUnescapeChars就能派上用场了。
5.获取请求中的参数值
我们在提交一个表单(form)时,怎样把表单内的值提取出来呢?
比如下面这个表单:
<form action="cgi-bin/5.cgi" method="POST">
<input type="text" name="name" />
<input type="text" name="number" />
<input type="submit" value="Submit" />
</form>
当5.cgi收到请求时,需要把输入框”name”和输入框”number”内的值提取出来。而且不管form中的action是GET还是POST,都要有效。
5.c实例:
#include <stdio.h>
#include "cgic.h"
#include <string.h>
#include <stdlib.h>
int cgiMain() {
char name[241];
char number[241];
FILE *fp;
cgiHeaderContentType("text/html");
fprintf(cgiOut, "<HTML><HEAD>/n");
fprintf(cgiOut, "<TITLE>My CGI</TITLE></HEAD>/n");
fprintf(cgiOut, "<BODY>");
cgiFormString("name", name, 241);
cgiFormString("number", number, 241);
fprintf(cgiOut, "<H1>%s</H1>",name);
fprintf(cgiOut, "<H1>%s</H1>",number);
fprintf(cgiOut, "</BODY>/n");
fprintf(cgiOut, "</HTML>/n");
fp = fopen("./test.txt", "w+");
if(fp == NULL)
{
perror("open test.txt:");
}
fwrite(name, strlen(name), 1, fp);
fwrite(number, strlen(number), 1, fp);
fclose(fp);
return 0;
}
在test.txt就能看到从浏览器输入的数据了。
6.实现文件上传
#include<stdio.h>
#include<string.h>
#include<unistd.h>
#include<fcntl.h>
#include<sys/stat.h>
#include"cgic.h"
#define BufferLen 1024
int cgiMain(void){
cgiFilePtr file;
int targetFile;
mode_t mode;
char name[128];
char fileNameOnServer[64];
char contentType[1024];
char buffer[BufferLen];
char *tmpStr=NULL;
int size;
int got,t;
cgiHeaderContentType("text/html");
//取得html页面中file元素的值,应该是文件在客户机上的路径名
if (cgiFormFileName("file", name, sizeof(name)) !=cgiFormSuccess) {
fprintf(stderr,"could not retrieve filename/n");
goto FAIL;
}
cgiFormFileSize("file", &size);
//取得文件类型,不过本例中并未使用
cgiFormFileContentType("file", contentType, sizeof(contentType));
//目前文件存在于系统临时文件夹中,通常为/tmp,通过该命令打开临时文件。临时文件的名字与用户文件的名字不同,所以不能通过路径/tmp/userfilename的方式获得文件
if (cgiFormFileOpen("file", &file) != cgiFormSuccess) {
fprintf(stderr,"could not open the file/n");
goto FAIL;
}
t=-1;
//从路径名解析出用户文件名
while(1){
tmpStr=strstr(name+t+1,"//");
if(NULL==tmpStr)
tmpStr=strstr(name+t+1,"/");//if "//" is not path separator, try "/"
if(NULL!=tmpStr)
t=(int)(tmpStr-name);
else
break;
}
strcpy(fileNameOnServer,name+t+1);
mode=S_IRWXU|S_IRGRP|S_IROTH;
//在当前目录下建立新的文件,第一个参数实际上是路径名,此处的含义是在cgi程序所在的目录(当前目录))建立新文件
targetFile=open(fileNameOnServer,O_RDWR|O_CREAT|O_TRUNC|O_APPEND,mode);
if(targetFile<0){
fprintf(stderr,"could not create the new file,%s/n",fileNameOnServer);
goto FAIL;
}
//从系统临时文件中读出文件内容,并放到刚创建的目标文件中
while (cgiFormFileRead(file, buffer, BufferLen, &got) ==cgiFormSuccess){
if(got>0)
write(targetFile,buffer,got);
}
cgiFormFileClose(file);
close(targetFile);
goto END;
FAIL:
fprintf(stderr,"Failed to upload");
return 1;
END:
printf("File /"%s/" has been uploaded",fileNameOnServer);
return 0;
}
假设该文件存储为upload.c,则使用如下命令编辑:
gcc -Wall upload.c cgic.c -o upload.cgi
编译完成后把upload.cgi复制到你部署cgi程序的目录(通常命名为cgi-bin)。
正式部署时,请务必修改用open创建新文件那一行代码。把open的第一个参数设置为目标文件在服务器上存储的绝对路径,或者相对于cgi程序的相对路径。本例中,出于简单考虑,在cgi程序所在目录下创建新文件。
测试用的HTML代码:
<form target="_blank" method="post" action="cgi-bin/upload.cgi">
<input name="file" type="file" />
<input name="submit" type="submit" />
</form>
程序要有权限在cgi-bin目录下创建文件(因为此例把文件上传到cgi-bin目录下)。
那么如何控制上传文件的大小呢?因为你有时会不允许用户上传太大的文件。
通过分析cgic.c的源代码,我们发现它定义了一个变量cgiContentLength,表示请求的长度。但我们需要首先判断这是一个上传文件的请求,然后才能根据cgiContentLength来检查用户是否要上传一个太大的文件。
cgic.c 的main函数中进行了一系列if-else判断来检查请求的类型,首先确定这是一个post请求,然后确定数据的编码方式为 “multipart/form-data”,这个判断通过之后,就要开始准备接收数据了。所以我们要在接收数据开始之前使用 cgiContentLength判断大小,如果超过标准,就立即返回,不允许继续操作。
下面贴出修改后代码片段(直接修改cgic.c的源代码即可):
else if (cgiStrEqNc(cgiContentType, "multipart/form-data")) {
#ifdef CGICDEBUG
CGICDEBUGSTART
fprintf(dout, "Calling PostMultipartInput/n");
CGICDEBUGEND
#endif
//我的代码
//UpSize:文件长度上限值,以byte为单位,UpSize是一个int变量,因为cgiContentLength的类型为int
if(cgiContentLength>UpSize){
cgiHeaderContentType("text/html");
printf("File too large!/n");
cgiFreeResources();
return -1;
}
//我的代码结束
if (cgiParsePostMultipartInput() != cgiParseSuccess) {
#ifdef CGICDEBUG
CGICDEBUGSTART
fprintf(dout, "PostMultipartInput failed/n");
CGICDEBUGEND
#endif
cgiFreeResources();
return -1;
}
#ifdef CGICDEBUG
CGICDEBUGSTART
fprintf(dout, "PostMultipartInput succeeded/n");
CGICDEBUGEND
#endif
}
变量UpSize表示文件大小的上限。在cgic.c的main中找到相关代码,并修改成上面这样即可。你可以在cgic.c中定义UpSize,也可以在刚才完成的upload.c中定义,然后在cgic.c中用extern方式引用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号