

第3次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC
2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
3.学习完成第0周至第4周的课程内容,并完成各周作业
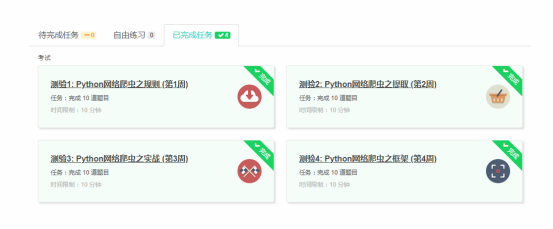
4.提供图片或网站显示的学习进度,证明学习的过程。
5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
早先我有学习过Python课程,但是学的过程囫囵吞枣,基础实在一般,这次在鄂老师的推荐下学习了嵩天老师的《Python网络爬虫及信息提取》,让我对python有了更好的理解。
在开始的时候,嵩天老师分别在视频中指导我们安装了Requests库、Beautiful Soup库和Scrapy框架等,这些都是爬取数据时的基础。
requests库内分七个函数,分别为request、get、head、post、put、patch、delete。其中最经常使用的是get和head,其余的函数因为更改对象是服务器网址上的内容,所以不能够经常被使用到。而request函数更像是一个概括,是一种可以代替剩下六种使用方法的一个函数。requests库有两种对象,分别是response和request。response对象包含爬虫返回的内容。同时,我还学习了patch和put的区别,采用PATCH,仅向URL提交UserName的局部更新请求,节省网络带宽。采用PUT,必须将所有20个字段一并提交到URL。而网络爬虫,“盗亦有道”,在爬取网页数据时,我们也应遵守Rebots协议。
Beautiful Soup库是解析、遍历、维护“标签树”的功能库,也叫bs4。bs4库提供了5种基本元素和3种遍历功能。其中,tag是最常用的,任何存在于HTML的语法标签都可以用soup.<tag>方法访问获得,当存在多个对应内容时,只返回第一个。同时,我也学到了HTML的基本格式和遍历规则。信息标记分为三种格式:XML(可扩展性好、但繁琐),JSON(信息有类型、适合做程序处理、较简洁),YAML(无类型、可读性好)。
第三周课程主要学习了正则表达式,正则表达式“一行胜千言”,它的作用是用来简洁表达一组字符串。Re库有多种表示类型,re库采用raw string类型表示正则表达式,例如’[1-9]\d{5}’可用r’[1-9]\d{5}’表示,string类型则表示为’[1-9]\\d{5}’。Re库的函数调用有两种方式,一种是直接加上方法名调用,还有一种是先将函数编译成正则表达式对象,再用正则表达式对象调用函数。这里还学习了Match对象,Match是一次匹配后的结果,但是可以包括很多信息。第四周主要学习了Scrapy框架,这是一个帮助用户实现专业网络爬虫的功能组件集合。和requests库比较起来,Scripy框架更专业,它更注重于爬虫结构,并发性好、性能也较好,适应于大型爬取信息的需求,但是入门更难。
嵩天老师的教学方法是先给学生讲授概念性的知识,再通过实战演练让我们加深记忆。让我留下深刻印象的是学习正则表达式的时候,因为需要记忆知识点有点多,所以我遇见了一些问题。正则表达式语法由字符和操作符组成,我自己写了一些例子,在开始的时候多次碰到关于“/”与“\”写错了的事情,这一方面是自己键盘使用习惯问题,一方面也是自己对这两个符号的理解不够透彻。经过摸索学习我总结了以下内容:“/”是分隔符号,/一般用于正则表达的开始和结束,“\”用于在中途使用,起转义作用;并且如果一个“\”后出现一个字符,并且不是可以转义的字符,那么“\”及其后面的字符不会被转义。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号