

CS231n笔记 Lecture 3 Loss Functions and Optimization
这一讲总体上就是引入Loss Function的概念,以及让大家对优化有一个初步的认识,和其他课程里面说的内容大同小异。
Loss function
Multiclass svm loss
multiclass svm的分类依据是,比较每个类别计算得到分数,取最大的那个作为当前的类标。该Loss鼓励的是正确的类标对应的分数应该比所有其他类标对应的分数都大至少1,否则就引入cost。具体定义如下:
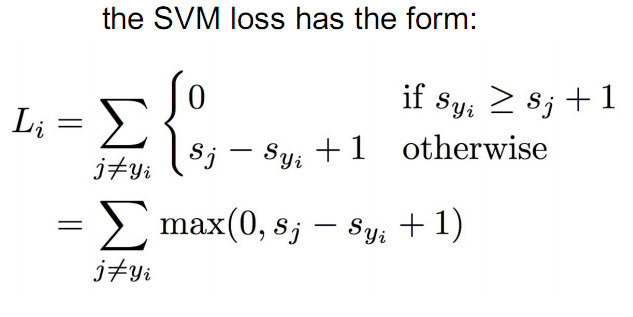
这个和svm的思想是一样的,就是说不光要分对,而且要求判断对与错的分割线之间要有一定的距离,即svm中所说的margin。
Regularization loss
一般能量项除了衡量模型在训练数据上的精确度外,还有另一个正则项用于控制模型的复杂度,防止过拟合。常见的几个正则项包括:

\(L_1\) 和 \(L_2\)
\(L_1\)鼓励稀疏,\(L_2\)试图将对结果的影响散步到W的每一项中- spread out the effects, 所以会鼓励更平均的结果。
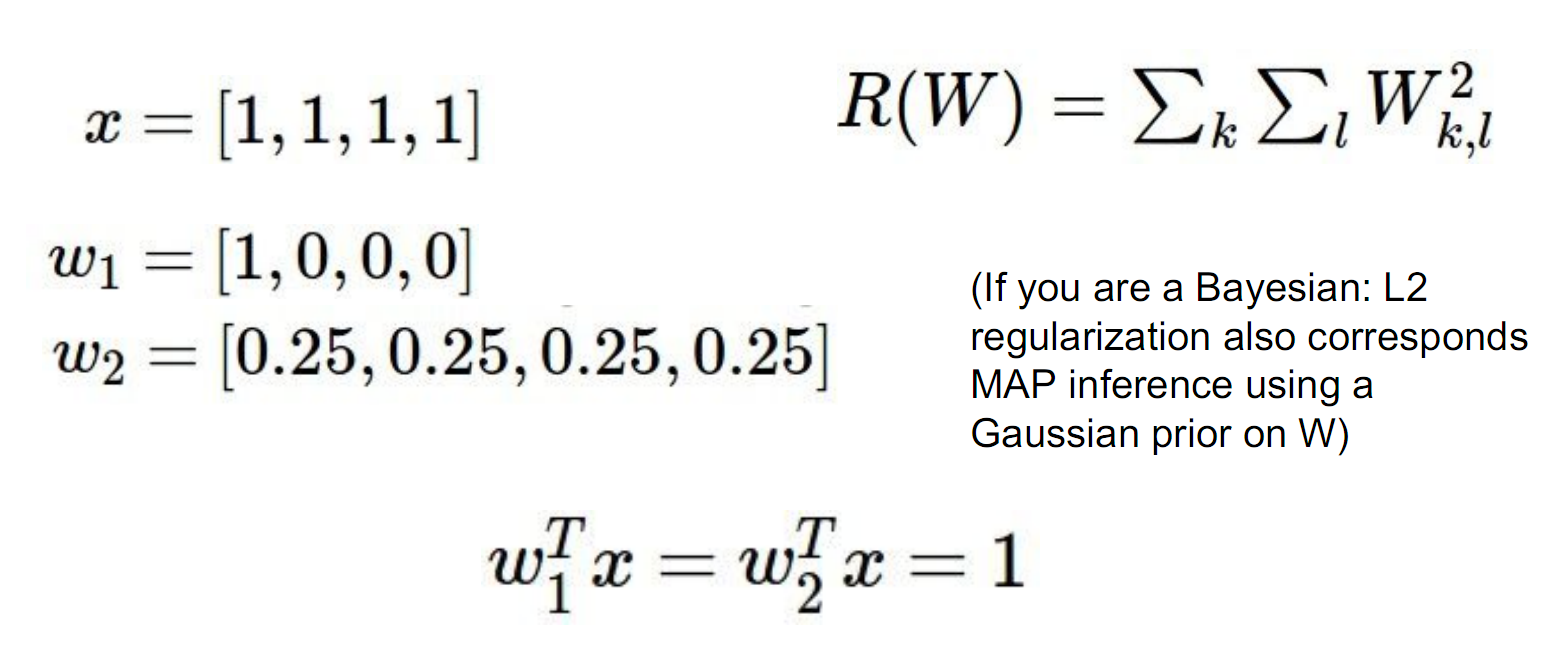
不过在这个例子上,\(L_2\)会选择\(w_2\),\(L_1\)在\(w_1\)和\(w_2\)上是一样的,但是我们可以构造出来一些其他的\(w_2\),使得\(w_1\)的\(L_1\)比\(w_2\)的小。
Softmax classifier
这个是在deep learning里面非常常见的一个分类器,总体思想就是把每个类别的分数做一个指数映射,然后再做一个归一化,得到一个在各个类别上的概率分布。
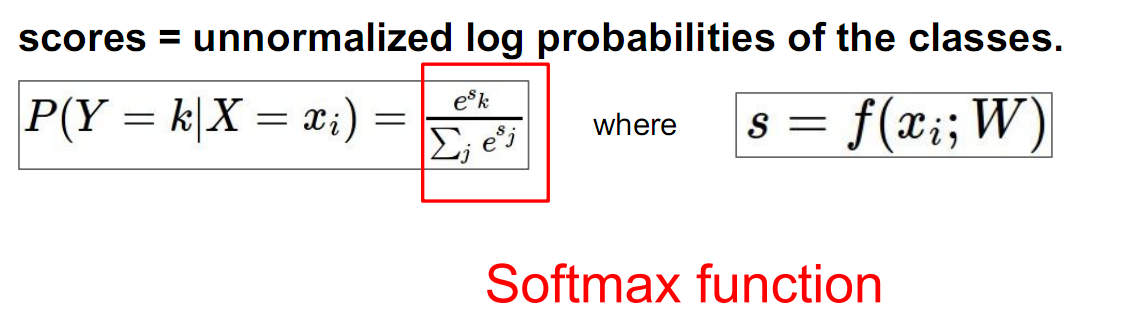
Loss定义为目标类别所计算得到的概率的负对数,又称为交叉熵loss (cross-entropy loss):
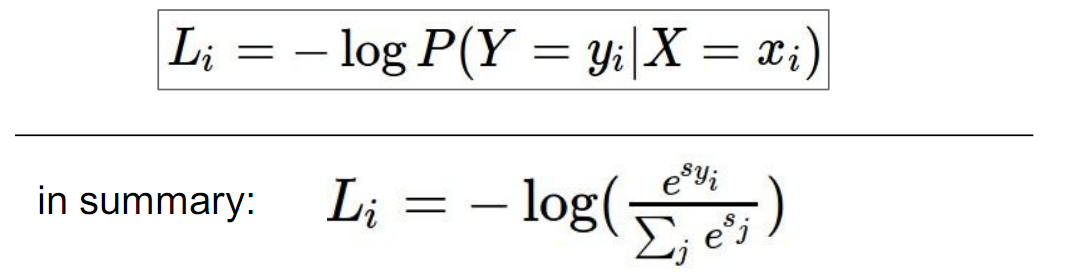
如果目标类别计算得到的概率接近1,那么Loss就接近0;否则Loss就会是一个正数。
一些验证
在训练模型之前,可以根据Loss function的特点对方法进行一些验证,提早发现bug。
- multiclass svm loss
初始每个类别的分数都差不多,然后加上一个margin 1, 那么对于某一个样本来说,它的loss大概为 (C - 1), 即除了正确类别外的所有其他类别。 - Softmax classifier loss
初始的loss应该接近\(log(C)\),其中C为类别个数,因为初始时,每个类别的概率应该接近1/C。
Loss function的对比与定义
整个模型的loss是将每个训练样本的loss加起来取平均,并加上正则项。
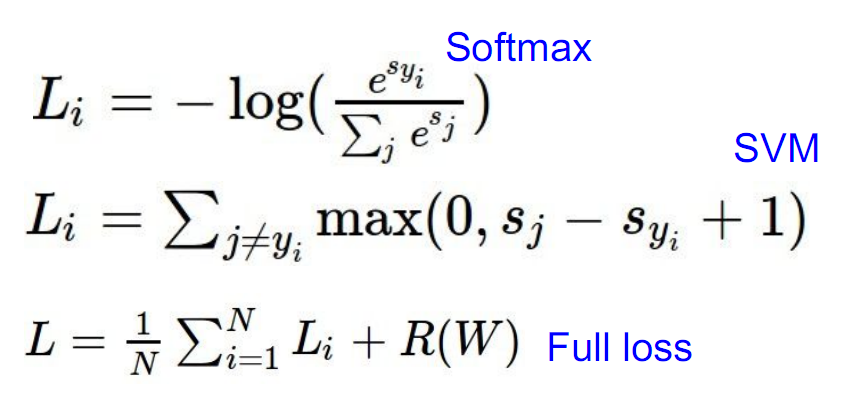
Optimization
梯度的计算
- Numerical gradient
![]()
直接从数学性质出发计算梯度,这样需要对W的每一维都进行计算,耗时。 - Analytic gradient
可以直接通过偏微分得到梯度的解析解,从而可以一次性求出W的梯度。 - 可以用Numerical gradient来验证程序实现的Analytic gradient是否正确

Gradient descent 梯度下降
每次将W按照负梯度方向前进一点点,那么Loss值就会下降一点点,直到收敛为止。
stochastic gradient descent
如果用普通的gradient descent,需要遍历整个训练集去计算Loss,很费时。所以使用一种叫minibatch的策略,每次只计算部分样本的loss, 用来估算W的真实梯度。
传统方法vs卷积神经网络
图像特征
- 颜色直方图, 比如把hue值进行离散化放到bin里。
- HOG, histogram of oriented gradients, 关注的是边朝向。
- Bag of Words 随机从图像中采样得到patch,聚类,得到codebook of "visual" words, 然后对于某一张图像,可以计算每个visual word的数量,对应文本里面的bag of words。
ConvNets
直接把原始像素喂给网络。
两者的区别在于,前一种是使用固定的方法提取图像特征,然后喂给比如线性分类器,在训练的时候只去更新线性分类器的参数,而图像特征已经是固定了的;后者则是通过更新整个网络的参数,图像的特征以及分类器的参数是一起变化的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号