

Python爬虫
目录
Python Spider
Talk is cheap.Show me the code!
第一章 爬虫入门
用户与网络的沟通本质是数据交换,而爬虫做的是不断获取网络的数据以供用户使用!
1.1 爬虫概述
爬虫是一种按一定规则自动采集抓取万维网信息(网页信息)的程序或脚本
1.1.1 爬虫原理
- 爬虫别名
- 网络爬虫又叫
网络蜘蛛、网页蜘蛛、网络机器人、网页追逐者(FOAF)
- 网络爬虫又叫
- 爬虫原理
- 爬虫好似蜘蛛在蛛网上循环往复、周而复始爬来爬去,以获得互联网的网页信息
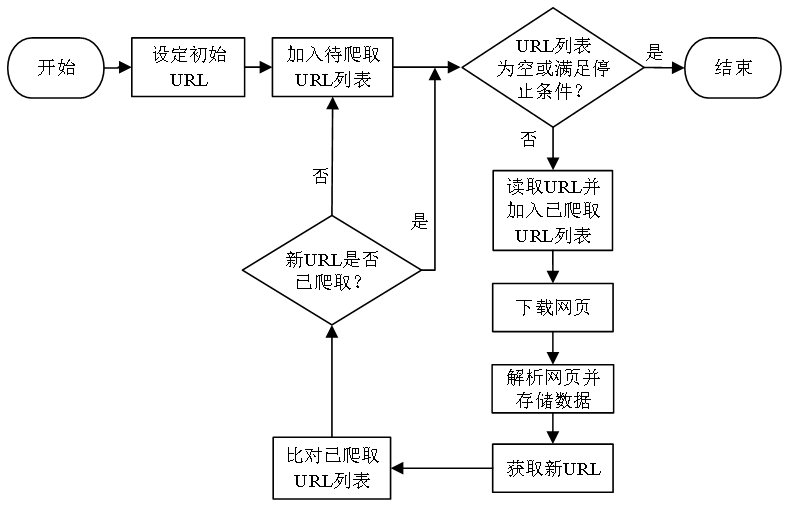
- 爬虫图示
![image]()
- (1)先设定一个或若干个初始网页的URL,将初始URL加入待爬取URL列表
- (2)从待爬取列表逐个读取URL,并将URL加入已爬取URL列表中,然后下载网页
- (3)解析已下载网页,提取所需数据和新URL,并存储提取的数据
- (4)将新URL与已爬列表比对,检查是否已爬,若未爬将其放入待爬末尾等待读取
- (5)如此往复,直到待爬URL列表为空或满足设定终止条件,最终实现遍历网页
- 爬取地址
- 爬取地址:
URN、URL、URI,URI=URN+URL,建议用URI代替URL
- 爬取地址:
1.1.2 爬虫分类
- 按系统结构和工作原理的不同进行爬虫分类
- 通用网络爬虫(又称全网爬虫):根据网络爬虫基本原理实现,如:搜索引擎
- 聚焦网络爬虫:经过滤处理只选择爬取特定网页,如:预先定义要爬的相关网页
- 增量式网络爬虫:实时监测网站数据更新,只爬取有更新的网页和新产生的网页
- 深层网络爬虫:爬取不能通过静态链接获取的信息,如:用户注册后才显示的网页
1.1.3 爬虫应用
- 搜索引擎内置爬虫程序
Google的Googlebot爬虫、百度的Baiduspider爬虫、必应的Bingbot爬虫
- 企业用户新建爬虫程序
- 企业用户因要采集和分析数据,所以企业用户会新建爬虫程序,如:爬取用户信息
- 普通用户新建爬虫程序
- 普通用户因要采集自己关注的主题,所以普通用户会新建爬虫程序,如:爬取论文
1.2 爬虫流程
爬虫的流程分为首先爬取网页,接着解析网页,最后存储数据
1.2.1 爬取网页
- 爬取网页的库:
urllib(内置)、requests、selenium - 爬取网页指爬虫向服务器发送请求获取网页源代码,服务器返回含所需数据的响应
1.2.2 解析网页
- 解析网页的库:
beautifulsoup4、lxml、正则表达式(非库) - 解析网页指据网页结构分析源代码从中提取数据,它使杂乱数据变清晰以处理分析
1.2.3 存储数据
- 解析网页提取数据后要将数据存储以便后续使用
- 可将数据存储到
JSON文件、CSV文件、MySQL数据库、MongoDB数据库
1.3 爬虫协议
爬虫协议主要指Robots协议,它是互联网世界的道德规范,用于规范相关爬虫准则
1.3.1 Robots协议
Robots协议(又称爬虫协议)全称是网络爬虫排除标准Robots协议可让网站管理者设置是否允许爬虫程序自动获取网站信息Robots协议允许在网站根目录放robots.txt文件,让爬虫访问网站时来检查
1.3.2 robots.txt文件简介
- 知乎robots文件
- 淘宝robots文件
- 有道翻译robots文件
robots.txt文件中表明了哪些链接允许、那些连接不允许爬虫程序获取robots.txt文件若存在爬虫按文件规定来访问,若无访问没被保护的网页robots.txt文件会在爬虫程序访问网站时,首先检查该网站根目录下是否存在
1.3.3 robots.txt文件详解
User-agent: Googlebot-Image,表示针对谷歌图片爬虫Disallow: /*?guide*,表示禁止爬取网站中所有包含guide的网址Disallow: /appview/,表示禁止爬取网站根目录的appview文件夹下的文件Allow: /search-special,表示允许爬取根目录以search-special开头的文件夹
1.3.4 爬虫准则
- 爬虫问题
- 若所爬数据用于个人或科学研究基本不违法,但用于转载或商业可能会犯法
- 爬取数据时要遵守
Robots协议和控制请求网页的速度及尊重网站的知识产权
- 爬虫避坑
- 爬虫应避免以下场景:著作权、商业秘密、个人隐私、不正当竞争、侵入计算机
- 爬虫道德
-
有才无德是小人,有德无才是君子,德才兼备乃圣人也!
-
1.4 爬虫环境
爬虫要能正常运行必须提前搭建好其环境,即Python运行环境
1.4.1 原生Python+Pycharm(PC)
- 原生Python
- Python官网下载
原生Python在官网下载后按部安装即可,采用了极简主义的设计理念
- Pycharm(PC)
- Pycharm官网下载
Pycharm在官网下载后按部安装即可,它是Jetbrains旗下的Python编辑器
- 两者注意事项
- 要根据
原生python版本下载对应Pycharm版本 原生Python必须集成在Pycharm中,才能被Pycharm使用
- 要根据
1.4.2 原生Python+Anaconda+Pycharm(PC)
- Anaconda
- Anaconda官网下载
Anaconda在官网下载后按部安装即可,它是一个开源的Python发行版本
- Pycharm 常识
Pycharm中Python源文件扩展名为.py- 可用拖入、粘贴、导入放到项目文件夹根目录下的方式,实现文件导入
PyCharm
- Pycharm 虚拟环境
Pycharm中的Virtualenv是一个虚拟环境管理器,它可以创建多个虚拟环境Virtualenv为不同项目提供独立Python运行环境,以解决不同项目多版本冲突Virtualenv安装所需包时会自动安装到该虚拟环境下,不会影响其他的项目环境
- 三者注意事项
- 可用虚拟环境设置是
原生Python还是Anaconda集成在Pycharm中
- 可用虚拟环境设置是

 浙公网安备 33010602011771号
浙公网安备 33010602011771号