

第九次作业
一.安装Hive
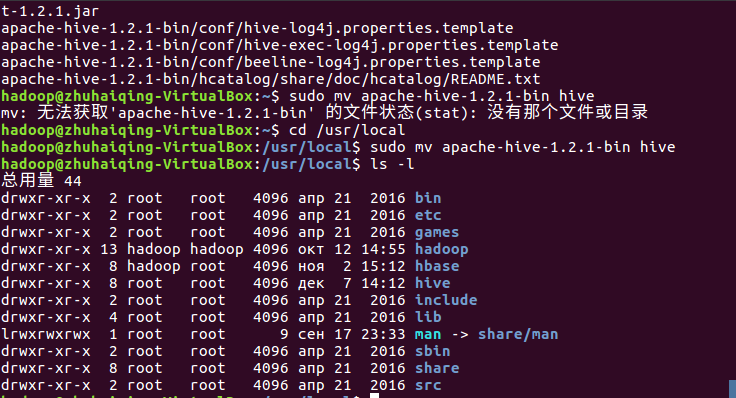
- 下载解压重命名权限
2. 配置环境变量 $HIVE_HOME

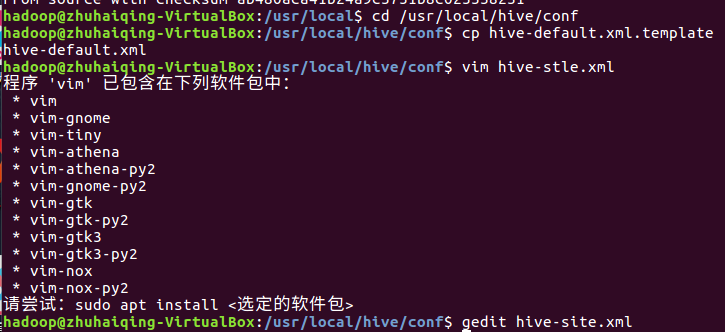
3. 修改Hive配置文件 gedit

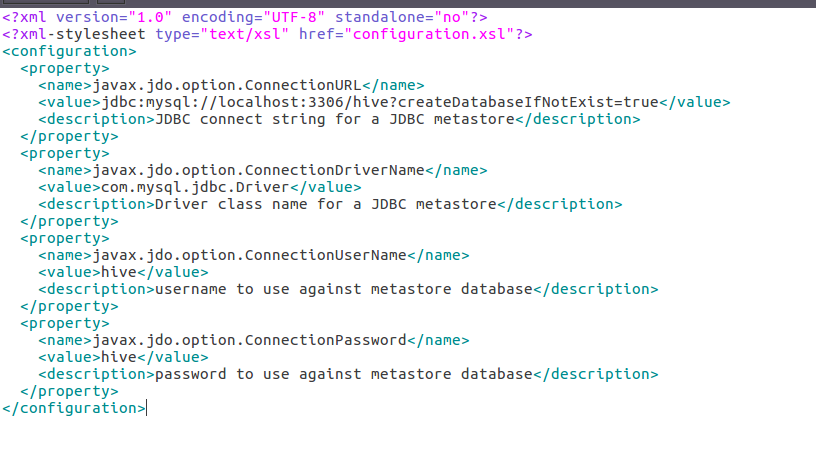
4.配置mysql驱动
a.下载合适版本的mysql jar包,拷贝到/usr/local/hive/lib目录下 ls


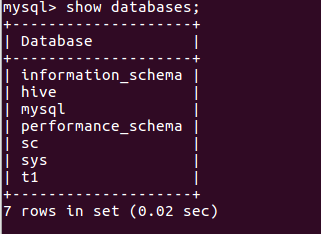
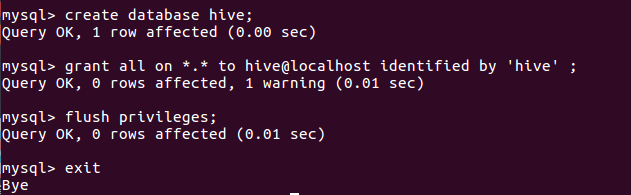
b.在mysql新建hive数据库 show databases;
c.配置mysql允许hive接入 show grants for 'hive'@'localhost';
5.启停
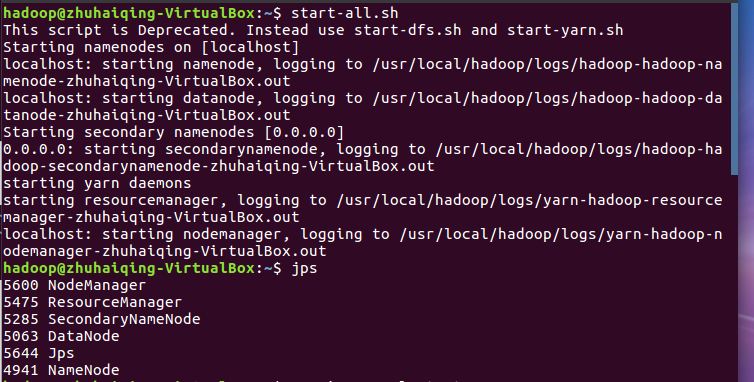
a.启动Hadoop--启动Hive--退出Hive--停止Hadoop

二、Hive操作
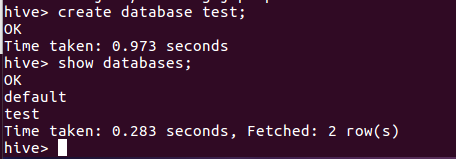
1.hive创建与查看数据库
2.mysql查看hive元数据表DBS

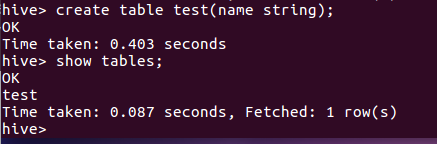
3.hive创建与查看表
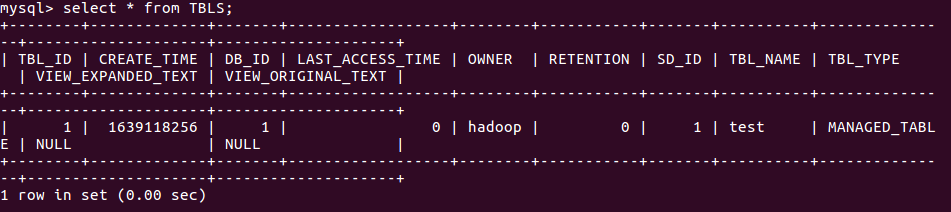
4.mysql查看hive元数据表TBLS
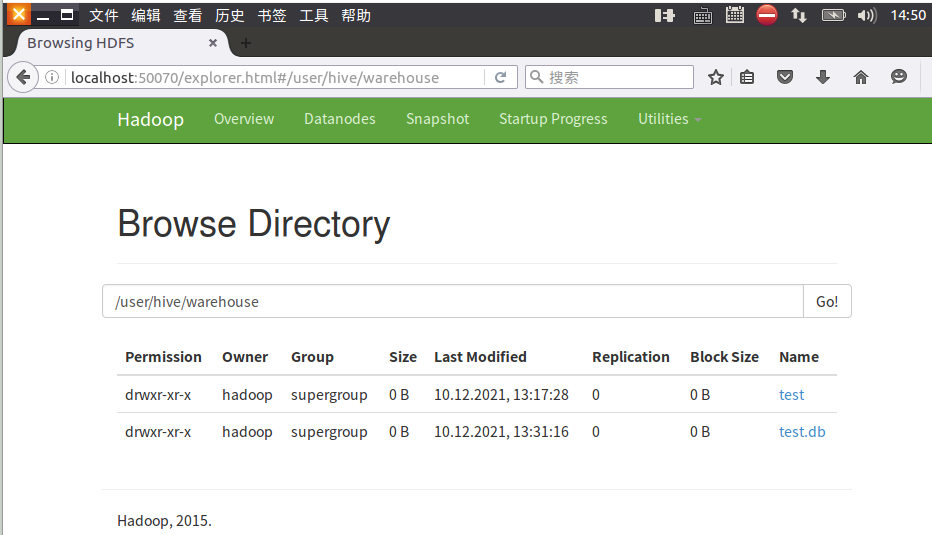
5.hdfs查看表文件位置
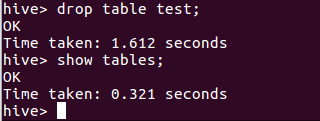
6.hive删除表
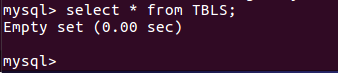
7.mysql查看hive元数据表TBLS
8.hive删除数据库

9.mysql查看hive元数据表DBS
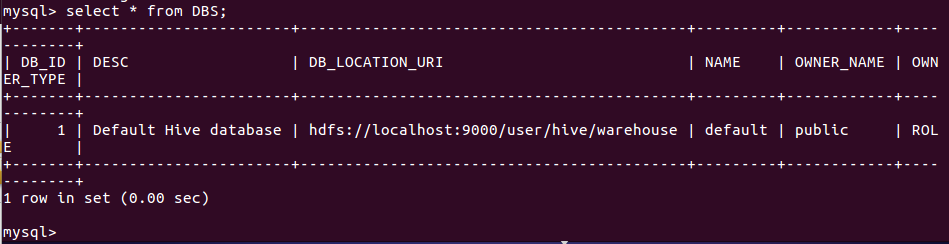
三、hive进行词频统计
0. 为什么要使用Hive?
操作接口采用类SQL语法,提供快速开发的能力。避免了去写MapReduce,减少开发人员的学习成本。功能扩展很方便。
Ø 可扩展
Hive可以自由的扩展集群的规模,一般情况下不需要重启服务。
Ø 延展性
Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
Ø 容错
良好的容错性,节点出现问题SQL仍可完成执行。
1.准备txt文件
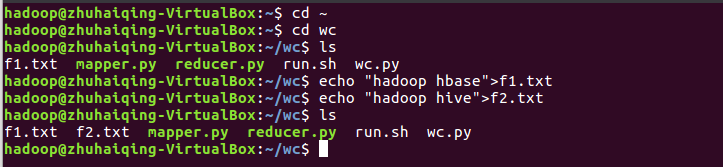
2.启动hadoop,启动hive

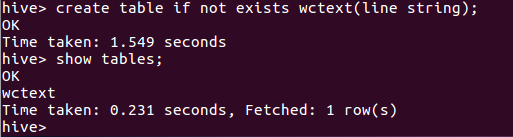
3.创建并查看文本表 create table
4.导入文件的数据到文本表中 load data local inpath


5.分割文本 split


6.行转列explode
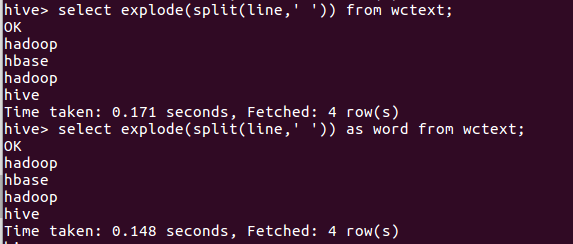
7.统计词频group by
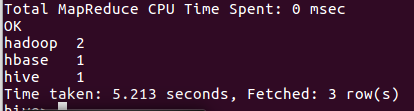
四、期末大作业开始准备 期末大作业sc.docx
- 学生课程分数sc.text
- hdfs
- HBASE
- MapReduce
- Hive

 浙公网安备 33010602011771号
浙公网安备 33010602011771号