R语言--数据预处理
一、日期时间、字符串的处理
日期
Date: 日期类,年与日
POSIXct: 日期时间类,精确到秒,用数字表示
POSIXlt: 日期时间类,精确到秒,用列表表示
Sys.date(), date(), difftime(), ISOdate(), ISOdatetime()
#得到当前日期时间
(d1=Sys.Date()) #日期 年月日
(d3=Sys.time()) #时间 年月日时分秒 通过format输出指定格式的时间
(d2=date()) #日期和时间 年月日时分秒 "Fri Aug 20 11:11:00 1999"
myDate=as.Date('2007-08-09')
class(myDate) #Date
mode(myDate) #numeric
#日期转字符串
as.character(myDate)
birDay=c('01/05/1986','08/11/1976') #
dates=as.Date(birDay,'%m/%d/%Y') #向量化运算,对向量进行转换
dates
# %d 天 (01~31)
# %a 缩写星期(Mon)
# %A 星期(Monday)
# %m 月份(00~12)
# %b 缩写的月份(Jan)
# %B 月份(January)
# %y 年份(07)
# %Y 年份(2007)
# %H 时
# %M 分
# %S 秒
td=Sys.Date()
format(td,format='%B %d %Y %s')
format(td,format='%A,%a ')
format(Sys.time(), '%H %h %M %S %s')
#日期转换成数字
as.integer(Sys.Date()) #自1970年1月1号至今的天数
as.integer(as.Date('1970-1-1')) #0
as.integer(as.Date('1970-1-2')) #1
sdate=as.Date('2004-10-01')
edate=as.Date('2010-10-22')
days=edate-sdate
days #时间类型相互减,结果显示相差的天数
ws=difftime(Sys.Date(),as.Date('1956-10-12'),units='weeks') #可以指定单位
#把年月日拼成日期
(d=ISOdate(2011,10,2));class(d) #ISOdate 的结果是POSIXct
as.Date(ISOdate(2011,10,2)) #将结果转换为Date
ISOdate(2011,2,30) #不存在的日期 结果为NA
#批量转换成日期
years=c(2010,2011,2012,2013,2014,2015)
months=1
days=c(15,20,21,19,30,3)
as.Date(ISOdate(years,months,days))
#提取日期时间的一部分
p=as.POSIXlt(Sys.Date())
p=as.POSIXlt(Sys.time())
Sys.Date()
Sys.time()
p$year + 1900 #年份需要加1900
p$mon + 1 #月份需要加1
p$mday
p$hour
p$min
p$sec
字符串处理
nchar() 、length()
paste()、outer()
substr()、strsplit()
sub()、gsub()、grep()、regexpr()、grepexpr()
1 #字符串 2 x='hello\rwold\n' 3 4 cat(x) #woldo hello遇到\r光标移到头接着打印wold覆盖了之前的hell变成woldo 5 print(x) # 6 #字符串长度 7 nchar(x) #字符串长度 8 length(x) #1 向量中元素的个数 9 10 #字符串拼接 11 board=paste('b',1:4,sep='-') #"b-1" "b-2" "b-3" "b-4" 12 board 13 14 mm=paste('mm',1:3,sep='-') #"mm-1" "mm-2" "mm-3" 15 mm 16 17 outer(board,mm,paste,sep=':') #向量的外积 18 #[,1] [,2] [,3] 19 #[1,] "b-1:mm-1" "b-1:mm-2" "b-1:mm-3" 20 #[2,] "b-2:mm-1" "b-2:mm-2" "b-2:mm-3" 21 #[3,] "b-3:mm-1" "b-3:mm-2" "b-3:mm-3" 22 #[4,] "b-4:mm-1" "b-4:mm-2" "b-4:mm-3" 23 24 25 #拆分提取 26 board 27 substr(board,3,3) #子串 28 strsplit(board,'-',fixed=T) #拆分 29 30 #修改 31 sub('-','.',board,fixed=T) #修改指定字符 32 board 33 mm #"mm-1" "mm-2" "mm-3" 34 sub('m','p',mm) #替换第一个匹配项 "pm-1" "pm-2" "pm-3" 35 gsub('m','p',mm) #替换全部匹配项 "pp-1" "pp-2" "pp-3" 36 37 38 #查找 39 mm=c(mm, 'mm4') #"mm-1" "mm-2" "mm-3" "mm4" 40 mm 41 grep('-',mm) #1 2 3 向量中1,2,3包含'-' 42 43 regexpr('-',mm) #匹配成功会返回位置信息,没有找到则返回-1
二、数据预处理
保证数据质量
准确性
完整性
一致性
冗余性
时效性
...
1、提取有效数据,需要业务人员配合(主观),及相关的技术手段保障
2、了解数据定义,统一对数据定义的理解
...
数据集成 : 对多数据源进行整合
数据转换 :
数据清洗 : 异常数据,缺失数据
数据约简 : 提炼,行,列
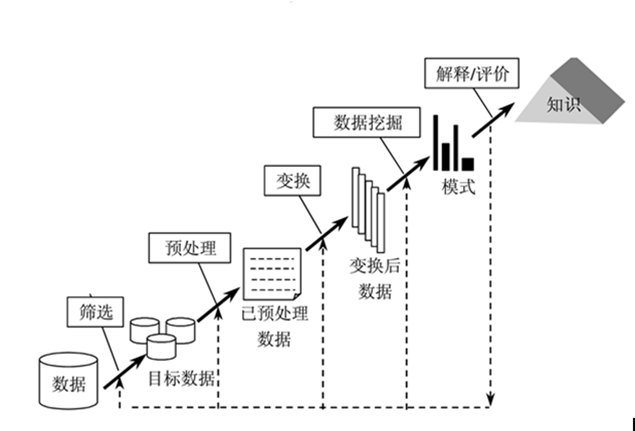
三、数据集成
通过merge对数据进行集成
1 #数据集成 2 #merge pylr::join (包::函数) 3 (customer = data.frame(Id=c(1:6),State=c(rep("北京",3),rep("上海",3)))) 4 (ol = data.frame(Id=c(1,4,6,7),Product=c('IPhone','Vixo','mi','Note2'))) 5 6 7 merge(customer,ol,by=('Id')) #inner join 8 merge(customer,ol,by=('Id'),all=T) # full join 9 merge(customer,ol,by=('Id'),all.x=T) # left outer join 左链接,左边数据都在 10 merge(customer,ol,by=('Id'),all.y=T) # right outer join 右链接,右边数据都在 11 12 13 #union 去重 在df1 和df2 有相同的列名称下 14 (df1=data.frame(id=seq(0,by=3,length=5),name=paste('Zhang',seq(0,by=3,length=5)))) 15 (df2=data.frame(id=seq(0,by=4,length=4),name=paste('Zhang',seq(0,by=4,length=4)))) 16 17 rbind(df1,df2) 18 19 merge(df1,df2,all=T) #去重,不使用by 20 21 merge(df1,df2,by=('id')) #重名的列会被更改显示
四、数据转换
构造属性
规范化(极差化、标准化)
离散化
改善分布

 浙公网安备 33010602011771号
浙公网安备 33010602011771号