整合Yolov3到UE4/Unity3D
这篇其实是前文 CUDA版Grabcut的实现 的后续,和上文一样,先放视频。
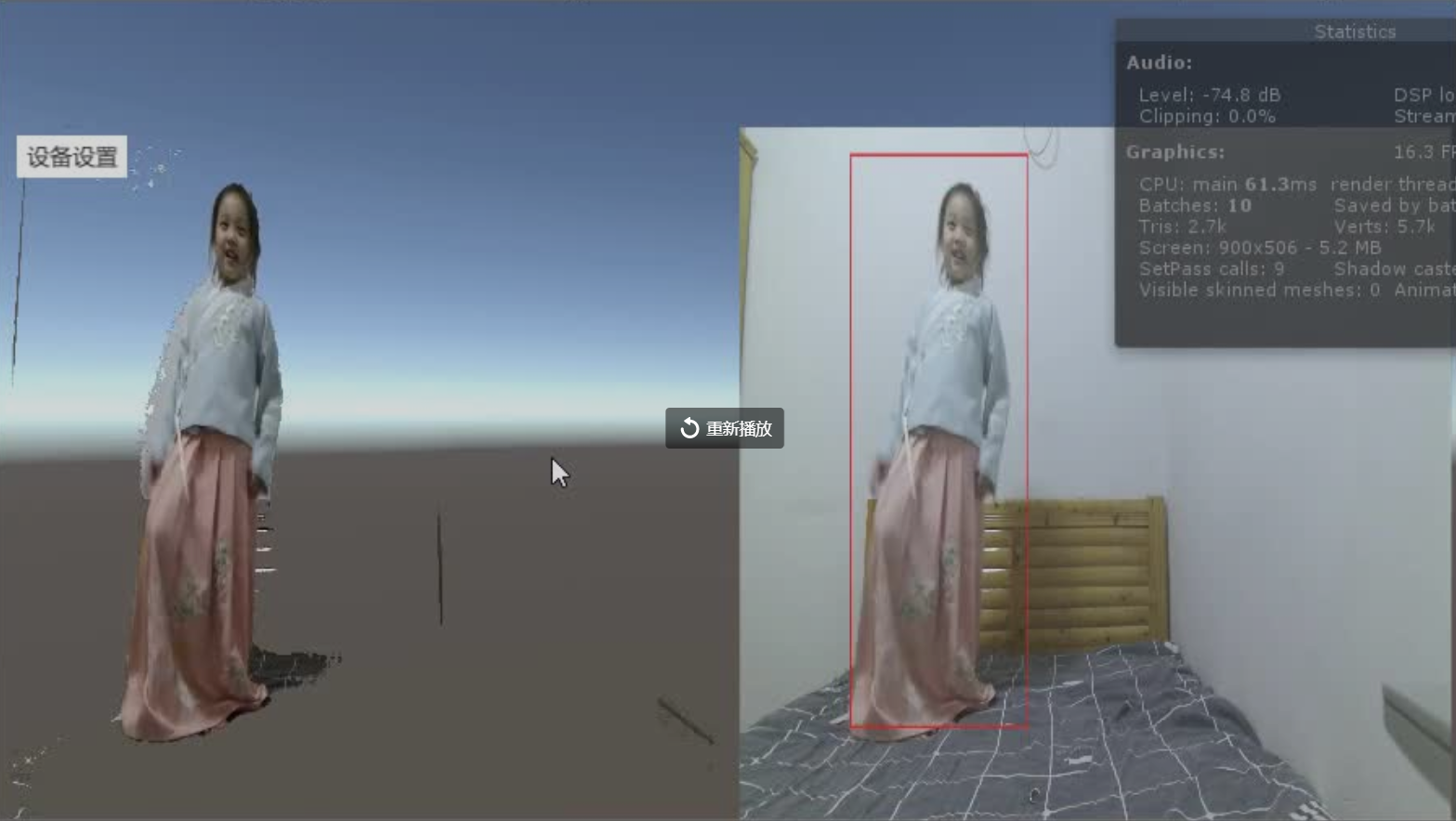
在上文用CUDA实现opencv下的grabcut后,当时问题主要是最后需要mincut需要上千次push-relabel才能得到满意结果,后改为种子点方式,不到100次就可以得到满意结果,但是种子点需要自己来画,不是很方便,因此,引入深度神经网络先用单桢计算种子点,然后根据这些确认的种子点来计算GMM,如视频这样,以很小代价成功处理1080P下的数据(上面开了录制视频与Unity编辑器占用了大量CPU)。
和前文一样,先说其中大体的实现过程。
1 对于实现yolov3的框架darknet的改造,现在darknet只能传入CPU数据进行计算,但是我们框架内部在读取摄像头后就直接丢到GPU上了,原始的YUV转RGBA都算好在GPU上,如果丢CPU数据,就要先download,然后再upload,这个操作太浪费时间并且是没必要的,我们需要改造这些接口。
2 根据一桢计算一个满意的分割图,然后根据分割图算GMM,然后根据这个GMM算后续图的mask(前景与背景变化不大的情况下), 其中grabcut的mincut里需要迭代多次push-relabel,因此这里给的分辨率需要先降采样,那么算的结果mask并不是太清晰,需要整合 CUDA加opencv复现导向滤波算法 我们才能得到满意的清晰边缘。
3 为了更高效率,我们只考虑显存直接对接方案,相比于CUDA提供的与DX11交互的例子,直接把引擎UE4/Unity3D里的Dx11上下文拿过来,然后把我们处理完后的数据给对应的DX11中,有个很大问题,摄像头30FPS就够了,游戏这块我们需要60FPS向上,在这过程中,游戏引擎的渲染线程被CUDA处理数据线程占用导致游戏会卡,就想CUDA处理线程和游戏引擎的渲染线程都去上厕所,CUDA处理线程占着厕所,游戏引擎的渲染线程就只能在外面等着,而我们要的是,渲染线程看厕所被占了,就马上去处理事情,等过会再来看看厕所是否空着了。
4 cuda端引用的dll过多,原来一些基本的蓝绿幕/深度扣像在DX11都有实现,现在的CUDA端要做成一个能方便接入的系统,提供一些高端功能,如神经网络检查是否有人在镜头内,镜头内的方位等,并且没有也不影响原来项目,类似插件模块。
相对上文的一些改变,中间因为显卡需要适配2070等20系最新显卡的原因,原来的openc4.0alpha(含cuda模块)+cuda8不能使用,于是重新编译了下opencv4.1(含cuda模块)+cuda10.1,中间有些坑,以后如果有时间就记录下,换了后也有个不好的地方,如果不是比较新的N卡驱动,就加载不了现在的cuda模块。考虑性价比,用的是yolov3-tiny框架,每桢中占比不到5ms,检测效果还行。
首先针对第一点,我们需要改进的是能直接传入的GPU方法,首先达到类似如下效果。


cv::cuda::resize(mat, netFrame, cv::Size(netWidth, netHeight), 0, 0, cv::INTER_LINEAR); image2netData_gpu(netFrame, netInput); network_predict_gpudata(net, netInput); detection *dets = get_network_boxes(net, netWidth, netHeight, cthresh, 0, 0, 1, &nboxes);
我们传入的GpuMat,直接在显卡完成缩放,转化成特征图,然后把数据丢给神经网络去计算,详细实现代码如下。
inline __global__ void image2netData(PtrStepSz<uchar4> source, float* outData, int size) { //rgbargbargba->rrrgggbbb const int idx = blockDim.x * blockIdx.x + threadIdx.x; const int idy = blockDim.y * blockIdx.y + threadIdx.y; if (idx < source.cols && idy < source.rows) { float4 color = rgbauchar42float4(source(idy, idx)); int nindex = idy * source.cols + idx; outData[nindex] = color.x; outData[size + nindex] = color.y; outData[2 * size + nindex] = color.z; } } void network_predict_gpudata(network * net, float *input) { network orig = *net; cudaMemcpy(net->input_gpu, input, net->w*net->h * sizeof(float) * 3, cudaMemcpyDeviceToDevice); net->truth = 0; net->train = 0; net->delta = 0; forward_network_gpudata(net); *net = orig; } void forward_network_gpudata(network *netp) { network net = *netp; //cuda_set_device(net.gpu_index); int i; for (i = 0; i < net.n; ++i) { net.index = i; layer l = net.layers[i]; if (l.delta_gpu) { fill_gpu(l.outputs * l.batch, 0, l.delta_gpu, 1); } l.forward_gpu(l, net); net.input_gpu = l.output_gpu; net.input = l.output; if (l.truth) { net.truth_gpu = l.output_gpu; net.truth = l.output; } } pull_network_output(netp); calc_network_cost(netp); }
这个改造比我想像中简单的多,毕竟C框架,实现都在明面上。
然后我们要根据我们设想,先根据单桢计算GMM,就是视频中点击计算GMM的button过程,如下是实现过程。
inline __global__ void setMask(PtrStepSz<uchar> source, PtrStepSz<uchar> mask, int radius, cv::Rect rect) { const int idx = blockDim.x * blockIdx.x + threadIdx.x; const int idy = blockDim.y * blockIdx.y + threadIdx.y; if (idx < source.cols && idy < source.rows) { int mmask = 0; //前景为255 if (idx > rect.x && idx < rect.x + rect.width && idy > rect.y && idy < rect.y + rect.height) { mmask = mask(idy, idx); int smask = source(idy, idx); if (smask == 3) mmask = 1; } mask(idy, idx) = mmask; } } inline __global__ void drawRect(PtrStepSz<uchar4> source, int xmin, int xmax, int ymin, int ymax, int radius, uchar4 drawColor) { const int idx = blockDim.x * blockIdx.x + threadIdx.x; const int idy = blockDim.y * blockIdx.y + threadIdx.y; if (idx < source.cols && idy < source.rows) { int4 xx = make_int4(idx, xmax, idy, ymax); int4 yy = make_int4(xmin, idx, ymin, idy); int4 xy = abs(xx - yy); //只要有一个条件满足就行(分别代表左边,右边,上边,下边) int sum = (xy.x < radius) + (xy.y < radius) + (xy.z < radius) + (xy.w < radius); float2 lr = make_float2(xy.x + xy.y, xy.z + xy.w); float2 rl = make_float2(xmax - xmin, ymax - ymin); if (sum > 0 && length(lr - rl) < radius) { source(idy, idx) = drawColor; } } } #if MRDNN //深度学习下自动计算一桢 vector<PersonBox> boxs; int num = detect->checkImage(grabCutTempFrame, 0.3f, boxs); if (num > 0) { GpuMat halfCutTemp = GpuMat(grabCutHeight, grabCutWidth, CV_8UC4); GpuMat halfTemp = GpuMat(grabCutHeight, grabCutWidth, CV_8UC3); GpuMat resultMask = GpuMat(grabCutHeight, grabCutWidth, CV_8UC1); cv::Mat cpuResult, cpuHalfCutTemp; cv::cuda::resize(grabCutTempFrame, halfCutTemp, cv::Size(grabCutWidth, grabCutHeight), 0, 0, cv::INTER_LINEAR, cvCudaStream); //自己实现,避免引入opencv_cudafilters410/opencv_cudaarithm410,加起来快七百M rgba2bgr_gpu(halfCutTemp, halfTemp, cudaStream); halfTemp.download(cpuHalfCutTemp, cvCudaStream); cudaStreamSynchronize(cudaStream); //选择一个边框 cv::Rect rectangle; rectangle.width = boxs[0].width*grabCutWidth; rectangle.height = boxs[0].height*grabCutHeight; rectangle.x = boxs[0].centerX*grabCutWidth - rectangle.width / 2; rectangle.y = boxs[0].centerY*grabCutHeight - rectangle.height / 2; //用opencv的方式来计算mask,因为opencv本身用八向,切割的边缘更清晰 cv::Mat bgModel, fgModel; cv::grabCut(cpuHalfCutTemp, cpuResult, rectangle, bgModel, fgModel, 3, cv::GC_INIT_WITH_RECT); //显示为3的就是GC_PR_FGD, resultMask.upload(cpuResult, cvCudaStream); //根据resultMask与rectangle构建grabCut->mask setMask_gpu(resultMask, grabCut->mask, 1, rectangle, cudaStream); //显示边框 uchar4 drawColor = make_uchar4(128, 0, 0, 255); cv::Rect rectangle2; rectangle2.width = boxs[0].width*width; rectangle2.height = boxs[0].height*height; rectangle2.x = boxs[0].centerX*width - rectangle2.width / 2; rectangle2.y = boxs[0].centerY*height - rectangle2.height / 2; drawRect_gpu(grabCutRectFrame, rectangle2, 3, drawColor, cudaStream); //GpuMat的析构函数会调用,可以不用手动调用 release halfCutTemp.release(); halfTemp.release(); resultMask.release(); } #endif
里面用的opencv本身提供的grabcut来算mask,因为单桢他用的八方向的,边缘清晰度更好,分割效果更好,然后用们上一篇的实现根据他的mask来计算GMM的值,然后每桢用这个GMM与push-relabel算的一张低分辨率下的mask,正好用来做导向滤波的引导图,经过CUDA加opencv复现导向滤波算法 的处理,就能得到边缘清晰的扣图效果。
其中算k-means/GMM的这个过程可以看上文,和前文不一样的是,原来k-means计算整张图所有点,这个k-means只计算其中确定的前景与背景,需要针对上文的updateCluster修改如下,让计算过程可以针对种子点模式。
//把source所有收集到一块gridDim.x*gridDim.y块数据上。 template<int blockx, int blocky, bool bSeed> __global__ void updateCluster(PtrStepSz<uchar4> source, PtrStepSz<uchar> clusterIndex, PtrStepSz<uchar> mask, float4* kencter, int* kindexs) { __shared__ float3 centers[blockx*blocky][CUDA_GRABCUT_K2]; __shared__ int indexs[blockx*blocky][CUDA_GRABCUT_K2]; const int idx = blockDim.x * blockIdx.x + threadIdx.x; const int idy = blockDim.y * blockIdx.y + threadIdx.y; const int threadId = threadIdx.x + threadIdx.y * blockDim.x; #pragma unroll CUDA_GRABCUT_K2 for (int i = 0; i < CUDA_GRABCUT_K2; i++) { centers[threadId][i] = make_float3(0.f); indexs[threadId][i] = 0; } __syncthreads(); if (idx < source.cols && idy < source.rows) { //所有值都放入共享centers int index = clusterIndex(idy, idx); uchar umask = mask(idy, idx); if (!bSeed || (bSeed && checkObvious(umask))) { bool bFg = checkFg(umask); int kindex = bFg ? index : (index + CUDA_GRABCUT_K); float4 color = rgbauchar42float4(source(idy, idx)); centers[threadId][kindex] = make_float3(color); indexs[threadId][kindex] = 1; } __syncthreads(); //每个线程块进行二分聚合,每次操作都保存到前一半数组里,直到最后保存在线程块里第一个线程上(这块比较费时,0.1ms) for (uint stride = blockDim.x*blockDim.y / 2; stride > 0; stride >>= 1) { //int tid = (threadId&(stride - 1)); if (threadId < stride)//stride 2^n { #pragma unroll CUDA_GRABCUT_K2 for (int i = 0; i < CUDA_GRABCUT_K2; i++) { centers[threadId][i] += centers[threadId + stride][i]; indexs[threadId][i] += indexs[threadId + stride][i]; } } //if (stride > 32) __syncthreads(); } //每块的第一个线程集合,把共享centers存入临时显存块上kencter if (threadIdx.x == 0 && threadIdx.y == 0) { int blockId = blockIdx.x + blockIdx.y * gridDim.x; #pragma unroll CUDA_GRABCUT_K2 for (int i = 0; i < CUDA_GRABCUT_K2; i++) { int id = blockId * 2 * CUDA_GRABCUT_K + i; kencter[id] = make_float4(centers[0][i], 0.f); kindexs[id] = indexs[0][i]; } } } }
其中bSeed为true表明是计算种子点模式,类似还需要修改updateGMM方法实现,种子点模式下,可以增加手动选择前景与背景,如graphcut类似。
这样,主要实现就算完成了,接下来,我们整合进引擎,公司主要使用UE4,我一般来说测试功能更喜欢用Unity3D,对于我测试功能来说,UI与逻辑编写方便与编译快是我需要的,所以主要以Unity3D讲解,后面会简单说下与UE4的对接,其实对接部分,unity3d要编写原生插件才能拿到Unity3D的DX11上下文,以及要写C++/C#的转接层,对于对接部分来说,UE4明显编写更舒服。
就如前面所说,要让CUDA处理数据的线程不占着引擎渲染线程,需要的是一个能在CUDA与DX11不同线程安全访问的显存设计,遗憾的是我没找到(有知道CUDA与DX11有类似DX11之间共享显存能有锁访问类似设计的告诉一声),但是在我前文 UE4/Unity3D中同时捕获多高清摄像头的高效插件 里我们知道DX11本身之间有共享显存锁访问机制,根据这个,我重新整理了下思路,先声明一个独立的DX11上下文,在这个上下文中有共享纹理,这个DX11的共享纹理与CUDA本身绑定,并且CUDA在处理数据线程中占着这个DX11上下文,等CUDA处理完线程就丢给这个DX11的共享纹理,然后再让游戏引擎UE4/Unity3D的渲染线程的DX11上下文去访问这个DX11的共享纹理,这样用一个独立的DX11做中转,也能达到我们需要的效果。
如下是CUDA与DX11交互的主要代码,其中DX11之间用锁共享访问的逻辑请看 UE4/Unity3D中同时捕获多高清摄像头的高效插件这个链接里,相关代码在这不贴了,这样就避免在CUDA中处理完后还download到内存中,然后在游戏中把内存数据upload在对应引擎的显存上,这样太浪费并且低效。
//一块CUDA与DX11绑定的资源 struct Dx11CudaResource { //cuda资源 cudaGraphicsResource *cudaResource = nullptr; //cuda具体资源 cudaArray *cuArray = nullptr; //对应DX11纹理 ID3D11Texture2D *texture = nullptr; //对应CPU数据 uint8_t *cpuData = nullptr; }; //表明一个DX11上下文的共享显存 struct MGDLL_EXPORT GpuSharedResource { public: ID3D11Texture2D* texture = nullptr; HANDLE sharedHandle = nullptr; bool bGpuUpdate = false; public: //申请一块共享显存,mc表示一个Dx11上下文章 bool restart(class MainCompute* mc, int width, int height, DXGI_FORMAT format = DXGI_FORMAT_R8G8B8A8_UNORM); void release(); }; bool GpuSharedResource::restart(MainCompute* mc, int width, int height, DXGI_FORMAT format) { SafeRelease(texture); bool result = mc->CreateTextureBuffer(nullptr, width, height, format, &texture, false, true); sharedHandle = MainCompute::GetSharedHandle(texture); bGpuUpdate = false; return result; } void GpuSharedResource::release() { SafeRelease(texture); } //Dx11CudaResource 表示Cuda与Dx11联接二方的资源 //GpuSharedResource 表示共享纹理与句柄,MainCompute为对应DX11上下文包装 inline bool registerCudaResource(Dx11CudaResource& cudaDx11, GpuSharedResource& sharedResource, MainCompute* mc, int width, int height) { if (cudaDx11.cudaResource != nullptr && cudaDx11.texture != nullptr) { cudaGraphicsUnregisterResource(cudaDx11.cudaResource); cudaDx11.cudaResource = nullptr; } bool bInit = sharedResource.restart(mc, width, height); if (bInit) { cudaDx11.texture = sharedResource.texture; auto result = cudaGraphicsD3D11RegisterResource(&cudaDx11.cudaResource, cudaDx11.texture, cudaGraphicsRegisterFlagsNone); if (result != cudaSuccess) { LogMessage(warn, "cudaGraphicsD3D11RegisterResource fails."); } } return bInit; } //把CUDA资源复制给DX11纹理 inline void gpuMat2D3dTexture(cv::cuda::GpuMat frame, Dx11CudaResource& cudaResource, cudaStream_t stream) { if (cudaResource.texture != nullptr) { //cuda map dx11,资源数组间map cudaGraphicsMapResources(1, &cudaResource.cudaResource, stream); //map单个资源 cudaGraphicsSubResourceGetMappedArray(&cudaResource.cuArray, cudaResource.cudaResource, 0, 0); //从cuda显存里把数据复制给dx11注册的cuda显存里 cudaMemcpy2DToArray(cudaResource.cuArray, 0, 0, frame.ptr(), frame.step, frame.cols * sizeof(int32_t), frame.rows, cudaMemcpyDeviceToDevice); //cuda unmap dx11 cudaGraphicsUnmapResources(1, &cudaResource.cudaResource, stream); } } //复制GPU处理后的扣像线程给共享显存,通过锁访问,避免和引擎的游戏线程一起访问这块显存 if (dataType & KeyingGPU) { CComPtr<IDXGIKeyedMutex> pDX11Mutex = nullptr; auto hResult = keyingRc.texture->QueryInterface(__uuidof(IDXGIKeyedMutex), (LPVOID*)&pDX11Mutex); DWORD dresult = pDX11Mutex->AcquireSync(0, 0); if (dresult == WAIT_OBJECT_0) { gpuMat2Texture(keying, resultOpFrame); } dresult = pDX11Mutex->ReleaseSync(1); keyingRc.bGpuUpdate = true; } //dx11共享显存把结果丢给游戏引擎的纹理 //d3ddevice 游戏引擎的dx11上下文 //texture 游戏引擎的纹理 //sharedHandle CUDA那边的游戏引擎dx11上下文里共享纹理的句柄 void copySharedToTexture(ID3D11Device * d3ddevice, HANDLE & sharedHandle, ID3D11Texture2D * texture) { if (!d3ddevice) return; CComPtr<ID3D11DeviceContext> d3dcontext = nullptr; //ID3D11DeviceContext* d3dcontext = nullptr; d3ddevice->GetImmediateContext(&d3dcontext); if (!d3dcontext) return; if (sharedHandle && texture) { CComPtr<ID3D11Texture2D> pBuffer = nullptr; HRESULT hr = d3ddevice->OpenSharedResource(sharedHandle, __uuidof(ID3D11Texture2D), (void**)(&pBuffer)); if (FAILED(hr) || pBuffer == nullptr) { LogMessage(error, "open shared texture error."); return; } CComPtr<IDXGIKeyedMutex> pDX11Mutex = nullptr; auto hResult = pBuffer->QueryInterface(__uuidof(IDXGIKeyedMutex), (LPVOID*)&pDX11Mutex); if (FAILED(hResult) || pDX11Mutex == nullptr) { LogMessage(error, "get IDXGIKeyedMutex failed."); return; } DWORD result = pDX11Mutex->AcquireSync(1, 0); if (result == WAIT_OBJECT_0 && pBuffer) { d3dcontext->CopyResource(texture, pBuffer); } result = pDX11Mutex->ReleaseSync(0); } }
让照上文这个顺序,先声明一个独立的DX11上下文,里面生成对应共享纹理,CUDA先绑定这边资源与这个DX11的共享纹理,等CUDA处理完数据,然后把数据复制到这个绑定的DX11共享资源上,这一步,通过锁知道游戏引擎的渲染线程是否在访问,如果在访问,就放弃,继续向下执行,而游戏引擎也通过锁安全访问这个CUDA的计算结果,然后带给UE4呈现,不会给游戏引擎本身带来延迟。注意显存泄漏的问题,Gpumat我们不需要多管,但是这里我们自己声明的,需要注意释放,注册CUDA与DX11资源后面再次注册是要先取消,否则显存泄漏。
现在越来越多数据密集计算,大部分适合GPU算,现在显卡的显存也越来越大,完全可把数据加载到显存,不同的流计算不同的部分,最后统一计算呈现效果,把CPU从数据密集处理中脱离出来,专注逻辑处理。
整个完整过程就差不多了,最后就是CUDA模块与相关引用的dll确实过大,可能有些情况原来的DX11模块就完全能处理,并且A卡暂时还用不了CUDA,所以这块设计成一个插件模块,所有的DLL放入一个文件夹中,如果不要,直接去掉这个文件夹,相关功能自动使用DX11处理,如果检测到有这个文件夹,就先检测是否能成功加载,然后确认是否使用CUDA模块来处理这个功能。
整个实现非常简单,对于这个需求也完全足够了。如下,先定义插件层与工厂类。
template<typename T> class ImageFactory { public: virtual T *create(int type) = 0; }; template<typename T> class PluginManager { public: static PluginManager<T>& getInstance() { static PluginManager m_instance; return m_instance; }; ~PluginManager() { //Release(); }; private: //static PluginManager<T>* instance; PluginManager() {}; private: std::vector<ImageFactory<T>*> factorys; std::vector<T*> models; public: //注册生产类 void registerFactory(ImageFactory<T>* vpf, int type) { if (type >= factorys.size()) factorys.resize(type + 1); factorys[type] = vpf; }; //产生一个实体 T* createModel(int type) { if (type >= factorys.size()) return nullptr; ImageFactory<T>* factory = factorys[type]; T* model = factory->create(type); models.push_back(model); return model; }; void Release() { for (T* model : models) { SafeDelete(model); } models.empty(); for (ImageFactory<T>* factory : factorys) { SafeDelete(factory); } factorys.empty(); } }; void registerFactory(ImageFactory<VideoProcess>* factory, int type) { PluginManager<VideoProcess>::getInstance().registerFactory(factory, type); }
然后在CUDA层定义相应的实现接口与加载是否满足加载的API。
class CudaVideoProcessFactory :public ImageFactory<VideoProcess> { public: CudaVideoProcessFactory() {}; ~CudaVideoProcessFactory() {}; public: virtual VideoProcess* create(int type) override; }; extern "C" GUDLL_EXPORT void registerFactory(); extern "C" GUDLL_EXPORT bool bCanLoad(); VideoProcess * CudaVideoProcessFactory::create(int type) { VideoProcess * vp = new VideoProcessCuda(); return vp; } void registerFactory() { registerFactory(new CudaVideoProcessFactory(), Cuda); registerFactory(new CudaComputePipeFactory(), Cuda); } bool bCanLoad() { int count = cv::cuda::getCudaEnabledDeviceCount(); if (count > 0) { int deviceId = 0; auto device = cv::cuda::DeviceInfo::DeviceInfo(deviceId); bool compation = device.isCompatible(); if (compation) { //cv::cuda::setDevice(deviceId); } return true; } return false; }
最后是在插件层根据定义的目录结构加载CUDA层。
inline HINSTANCE LoadGPUCompuate() { //HINSTANCE hdll = nullptr; typedef bool(*bCanLoad)(); typedef void(*registerfactory)(); hdll = LoadLibraryEx(L"GPUCompute.dll", nullptr, LOAD_WITH_ALTERED_SEARCH_PATH); if (hdll == nullptr) { //DWORD error_id = GetLastError(); //LogMessage(error, to_string(error_id).c_str()); wchar_t sz[512] = { 0 }; HMODULE ihdll = GetModuleHandle(L"ImageUtility.dll"); ::GetModuleFileName(ihdll, sz, 512); ::PathRemoveFileSpec(sz); ::PathAppend(sz, L"GPUCompute"); SetDllDirectory(sz);//SetCurrentDirectory(sz); hdll = LoadLibraryEx(L"GPUCompute.dll", nullptr, LOAD_WITH_ALTERED_SEARCH_PATH); //error_id = GetLastError(); //LogMessage(error, to_string(error_id).c_str()); } if (hdll) { bCanLoad bcd = (bCanLoad)GetProcAddress(hdll, "bCanLoad"); if (bcd()) { registerfactory rf = (registerfactory)GetProcAddress(hdll, "registerFactory"); if (rf) rf(); } else { FreeLibrary(hdll); hdll = nullptr; } } return hdll; }
这样就能根据需求确定是否要加载CUDA与深度神经网络模块,后面改成caffe这样也是适用的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号