


关于数据库分布式架构的一些想法。
最近一段时间在研究数据库的分布式部署,但是并不是所有的数据库本身都支持分布式,那么怎么办呢。
本人自己没有用过分布式的数据库,根据自己的想到一种简单分布式的架构,来进行分布式的部署。
现在先上图,
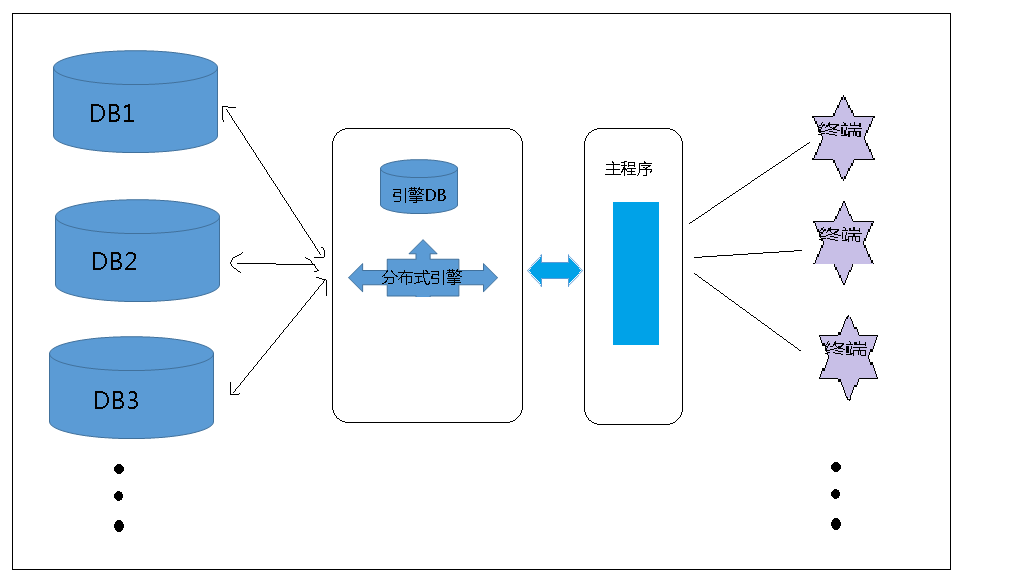
大概的想法是在数据库外面多加一次 分布式引擎和引擎数据库,来实现对多个数据库的管理,
首先我们来说一下此种方案的可行性,它是基于原来数据库的基础上在搭建平行的数据库来分摊压力,而分布式引擎的作用则是处理主程序对数据库的请求,并返回请求的结果的,
此种方案的难点和核心点在于分库,依据什么来分库会影响到最终搭建成的系统的运行效率,一个好的依据可以把原来的压力平均分摊给各个数据库(最好情况),而一个差的依据会导致压力集中到分布式引擎,导致压力剧增,运行效率和承受压力比原来还大,
在下以为分库的依据有以下几点需要注意的地方,
1.分开的数据库数据要平均,尽量每个数据库的数据量是相近的。
2. 面向客户的数据尽量是连续,即主程序一次查询出来面向客户的数据是从1个或者2个数据库就能查询出来的,也不是是1个表的数据只存在其中的一个数据库中,而是面向客户的数据只是查询分页的20条至50条直接,要尽量保证这些数据是在1个数据库就能全取出来的。
3.有业务关联性的数据最好都放在一个数据库中,比如这是一个管理系统,那么本系统的流程中的所有相关数据最好是放在一个库中。
4.关于引擎数据库最好采用NOSQL数据库,个人建议考虑Redis,引擎数据库主要存储map、索引、排序类的信息,引擎可以在引擎数据库中找到我该去哪里去数据,去哪里取数据比较快,客户关心的数据都在哪,引擎找到从哪里取数据之后,再开启线程从各个数据库把数据取出来,然后合成一个最好的结果集返回给主程序。
下面我们来说一下这个架构的各个部分的功能职责。
数据库主要的作用是增删查改,
增:新增一条数据,数据库引擎根据分库规则判断应该插入到哪个数据库。
删:数据库引擎根据 引擎数据的索引和map找到需要删除的数据,并对某个数据库进行操作。
查:数据库引擎根据条件查找 分页条数的 数据id,根据索引和map取出数据合并为一个结果集返给主程序。
改:数据库引擎根据 引擎数据的索引和map找到需要修改的数据,对某个数据库进行操作。
锁:锁加在引擎数据库上的,可以保证数据的一致性。
并发:每个请求进入到分布式引擎,然后在引擎数据库上得到map和索引ID,在各个线程去各个数据库进行操作,所以压力是在引擎数据库和引擎上,所以个人推荐引擎数据库为Redis或者其他内存上的数据库。
并不是所有的操作都需要排队等待,例如增、删,可以直接并行处理,免去了锁表的苦恼,但会导致查询的数据不是最及时准确的,但影响不大,可以接受。
事务:对数据进行一系列操作,这是在应用程序中非常常见的操作,那么如何保证数据的原子性呢,具体可以参考NOSQL的做法,或者在分布式引擎中写入事务逻辑控制。
以上是我个人的一些想法和思考,可能并不是很成熟,如果各位有补充可以在评论区留言探讨。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号