简单网站爬虫的所有技能
写在前面
刚开始看爬虫文章的时候,走了不少弯路,我希望我的文章能给你带来一些启发
文章结尾有思考题,如果独立完成了,证明你掌握了简单网站爬虫的所有技能
本文涉及到的技能
- 查看网页源代码和检查元素
- requests使用
- BeautifulSoup使用
这三招就是爬取简单网站的全部招数,跟着思路往下看
查看网页源代码和检查元素
不要觉得很简单,这两招是爬虫的基础。如果你熟悉这两招,简单网站的爬虫,你就学会了一半。
一般来说,检查元素中看到的内容都会在网页源代码中出现。今天我选取的这个例子,情况特殊,检查元素中看到的内容部分会在网页源代码中出现。
爬北京的白天和夜间温度
北京天气的网址:http://www.weather.com.cn/weather1d/101010100.shtml
下面是源代码,我会有注释的,跟着一起读一读
Talk is cheap. Show you the code
# -*- coding: utf-8 -*-
__author__ = 'duohappy'
import requests # 导入requests模块
from bs4 import BeautifulSoup # 从bs4包中导入BeautifulSoup模块
# 设置请求头
# 更换一下爬虫的User-Agent,这是最常规的爬虫设置
headers = {"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.110 Safari/537.36'}
# 需要爬取的网址
url = "http://www.weather.com.cn/weather1d/101010100.shtml"
# 发送请求,获取的一个Response对象
web_data = requests.get(url, headers=headers)
# 设置web_data.text会采用web_data.encoding指定的编码,一般情况下不需要设置,requests会自动推断
# 鉴于网页大部分都是采取utf-8编码的,所以设置一下,省去一些麻烦
web_data.encoding = 'utf-8'
# 得到网页源代码
content = web_data.text
# 使用lxml解析器来创建Soup对象
soup = BeautifulSoup(content, 'lxml')
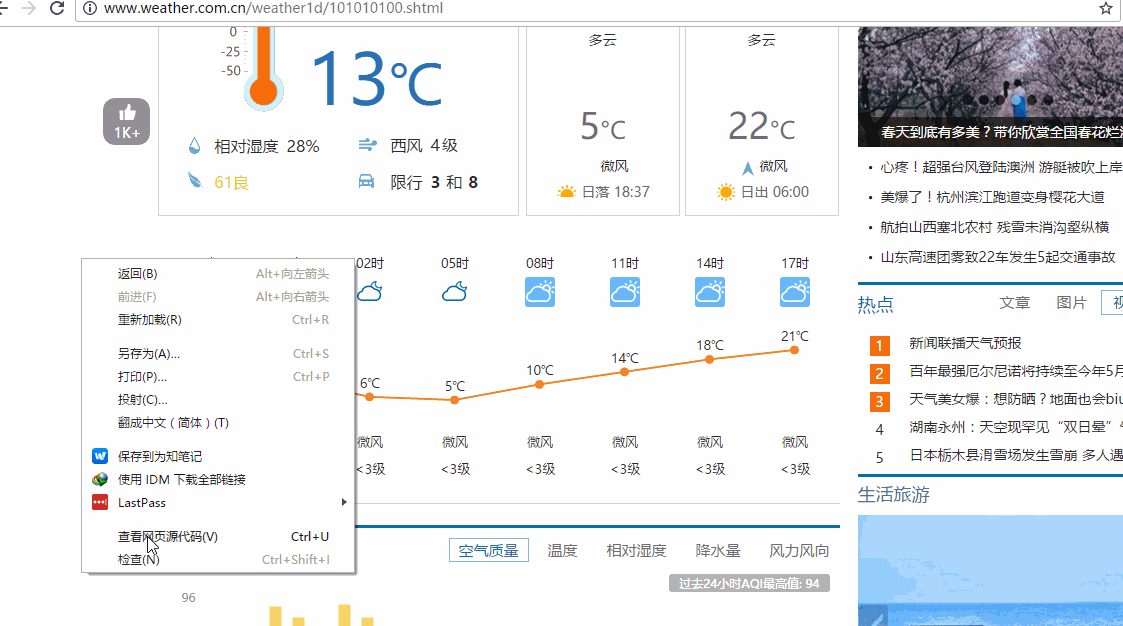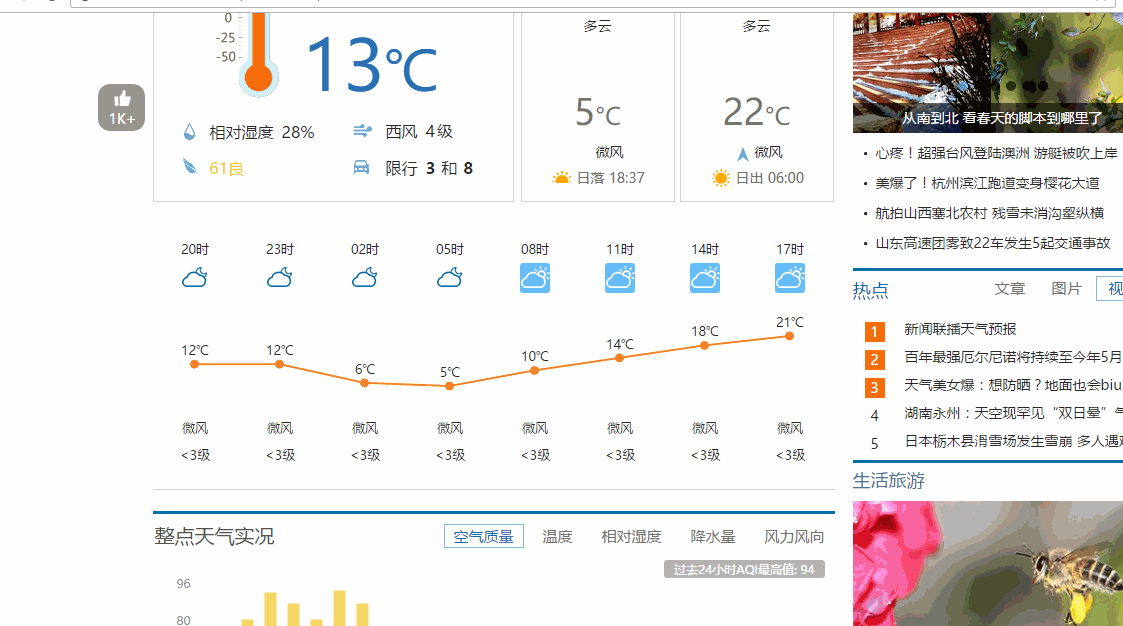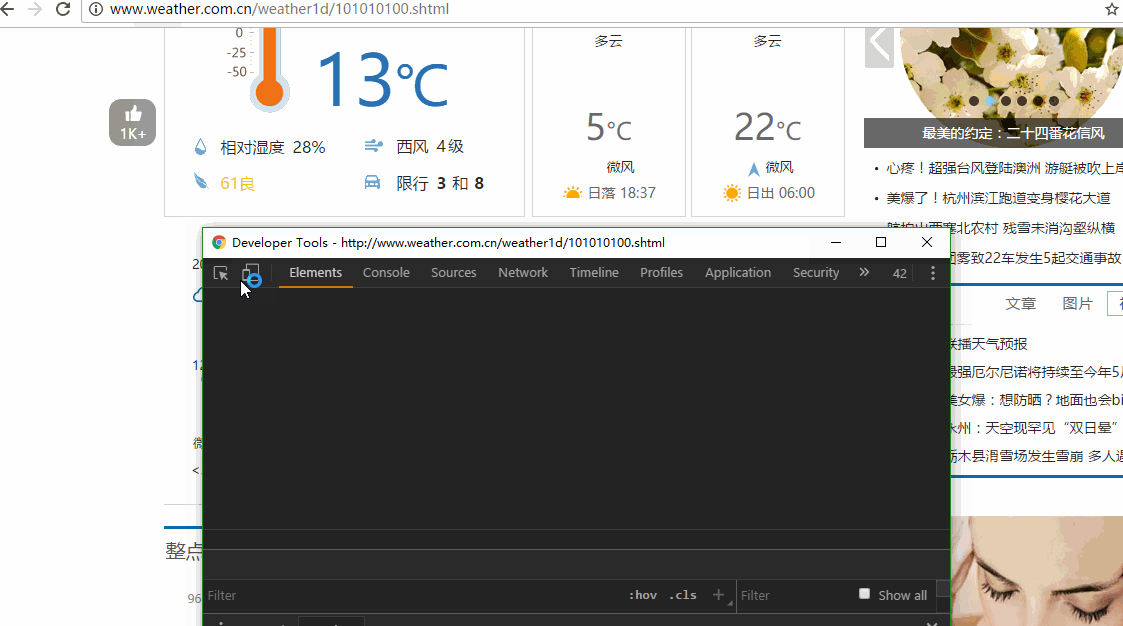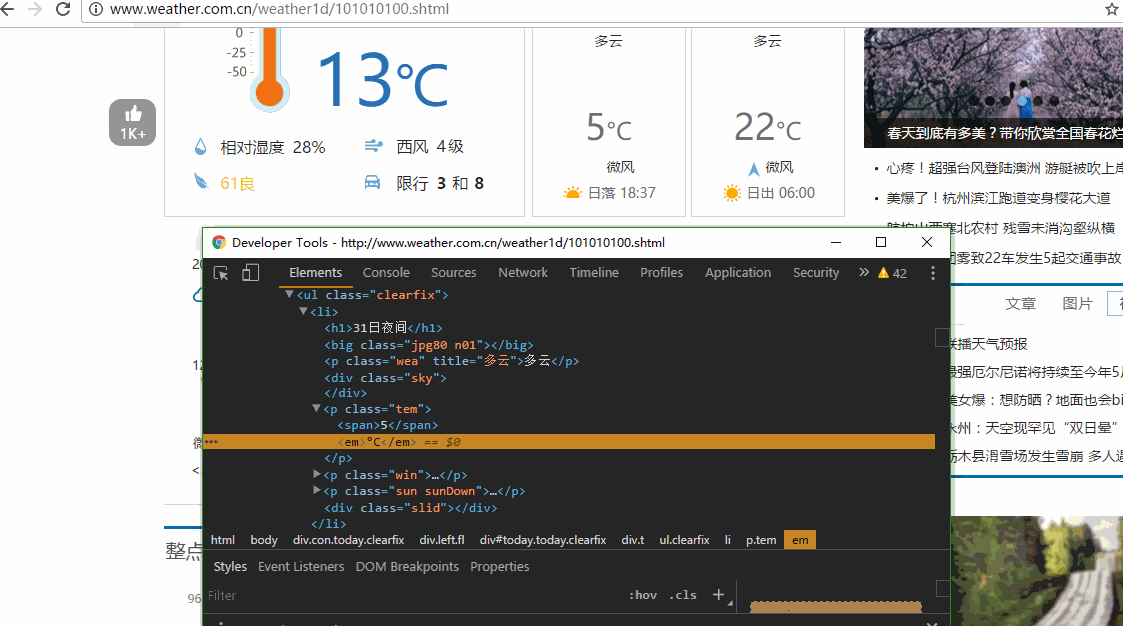
# 为什么要创建一个Soup对象,还记得浏览器中的检查元素功能嘛
# Soup对象可以方便和浏览器中检查元素看到的内容建立联系,下面会有动画演示
# 使用css selector语法,获取白天和夜间温度,下面有动画演示
tag_list = soup.select('p.tem span')
# tag_list[0]是一个bs4.element.Tag对象
# tag_list[0].text获得这个标签里的文本
day_temp = tag_list[0].text
night_temp = tag_list[1].text
print('白天温度为{0}℃\n晚上温度为{1}℃'.format(day_temp, night_temp))
- "Soup对象可以方便和浏览器中检查元素看到的内容建立联系"是什么意思?
简单点解释就是检查元素看到的样子和Soup对象中元素的样子差不多(这只是简单的理解)

- css seletor语法
值得提出的是当搜索'p.tem em'时,刚好有2个匹配的对象,分别对应白天温度和夜间温度,这一点非常重要,如果匹配个数大于或者小于2,那么说明你的css selector写错了

爬多个城市的白天和夜间温度
搜索不同的城市天气,观察网址的变化。
观察网址的变化是爬虫中最重要的本领之一
# -*- coding: utf-8 -*-
__author__ = 'duohappy'
import requests
from bs4 import BeautifulSoup
headers = {"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.110 Safari/537.36'}
# 建立城市和网址特殊部分的对应关系
weather_code = {'北京':'101010100','上海':'101020100','深圳':'101280601', '广州':'101280101', '杭州':'101210101'}
city = input('请输入城市名:') # 仅仅能输入北京,上海,广州,深圳,杭州
url = "http://www.weather.com.cn/weather1d/{}.shtml".format(weather_code[city])
web_data = requests.get(url, headers=headers)
web_data.encoding = 'utf-8'
content = web_data.text
soup = BeautifulSoup(content, 'lxml')
tag_list = soup.select('p.tem span')
day_temp = tag_list[0].text
night_temp = tag_list[1].text
print('白天温度为{0}℃\n晚上温度为{1}℃'.format(day_temp, night_temp))
思考题
如果做完了,需要有人给你看看代码,可以给我发邮件,:)
-
如何爬取今日实时温度?
了解检查元素和查看网页源代码的差异 -
如何爬取7日天气?
仔细看看网页源代码里有哪些意外的信息
有了requests+bs4两大利器,简单网站的爬虫你就学的差不多了
写在后面
如果有任何的建议或者批评,请不吝赐教,欢迎交流,:)
写出生活

 浙公网安备 33010602011771号
浙公网安备 33010602011771号