


Git版本控制器使用总结笔记01
Git为何物?
Git 是什么?大家肯定会说不就是版本控制器嘛,是的Git是目前世界上最先进的分布式版本控制系统(没有之一)。
1)那什么是版本控制器?
举个简单的例子,比如我们用Word写文章,那你一定有这样的经历:比如增加一个段落你得复制一份,你删除一个段落你又得复制一份,防止下次又要修改保留上次你要删除的段落。最后一个接一个的版本,你复制了很多版本,最后可能你自己都不知道修改了哪些?嘿嘿,然后你只能一个一个的找,太麻烦了,若是有东西帮你管理那应该多好。
2)分布式管理
你写的文章或书,你肯定会给你朋友或者其他人看,让他们给你建议并做相应的修改,然后他们用邮件或U盘再发给你,你再合并修改一下,真是麻烦,于是你想,如果有一个软件,不但能自动帮我记录每次文件的改动,还可以让朋友之间协作编辑,这样就不用自己管理一堆类似的文件了,也不需要把文件传来传去。如果想查看某次改动,只需要在软件看一眼就可以,岂不是很方便?这个软件用起来就应该像这个样子,能记录每次文件的改动:
| 版本 | 用户 | 说明 | 修改日期 |
| 1 | user1 | 增加一行内容 | 2014/4/10 10:22 |
| 2 | user2 | 修改一行内容 | 2014/4/10 13:12 |
| 3 | user3 | 删除几个字 | 2014/4/15 20:42 |
| 4 | user2 | 增加某个内容 | 2014/4/20 16:32 |
Git 的诞生
简单说:Linus开发Linux内核,需要版本控制器,于是开发了Git。下面是开发周期:
1)2005/4/3 开发;
2)2005/4/6 发布;
3)2005/4/7 管理自身;
4)2005/6/16 管理Kernel2.6.12。
大牛是怎么定义的呢?大家可以体会一下。哈哈^_^…… Git 迅速成为最流行的分布式版本控制系统,尤其是2008年,GitHub网站上线了,它为开源项目免费提供Git存储,无数开源项目开始迁移至GitHub,包括jQuery,PHP,Ruby等等。至于Git与GitHub的关系,会再下面的文章里说明。
集中管理 VS 分布式管理
Linus一直痛恨的CVS及SVN都是集中式的版本控制系统,而Git是分布式版本控制系统,集中式和分布式版本控制系统有什么区别呢? 下面我们来看看两张图:
1)集中管理
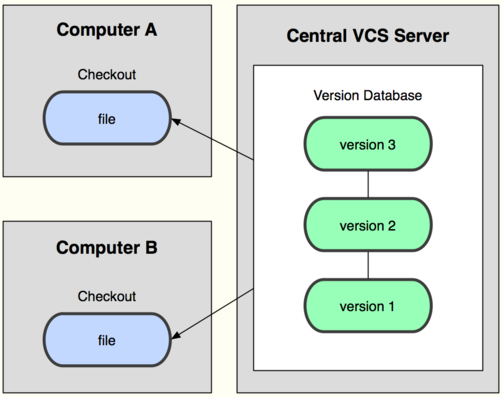
集中式版本控制系统,版本库是集中存放在中央服务器的,而干活的时候,用的都是自己的电脑,所以要先从中央服务器取得最新的版本,然后开始干活,干完活了,再把自己的活推送给中央服务器。中央服务器就好比是一个图书馆,你要改一本书,必须先从图书馆借出来,然后回到家自己改,改完了,再放回图书馆。
缺点:
集中式版本控制系统最大的毛病就是必须联网才能工作,如果在局域网内还好,带宽够大,速度够快,可如果在互联网上,遇到网速慢的话,可能提交一个10M~20M的文件就需要10分钟甚至更多时间,这还不得把人给急死啊。
2)分布式管理
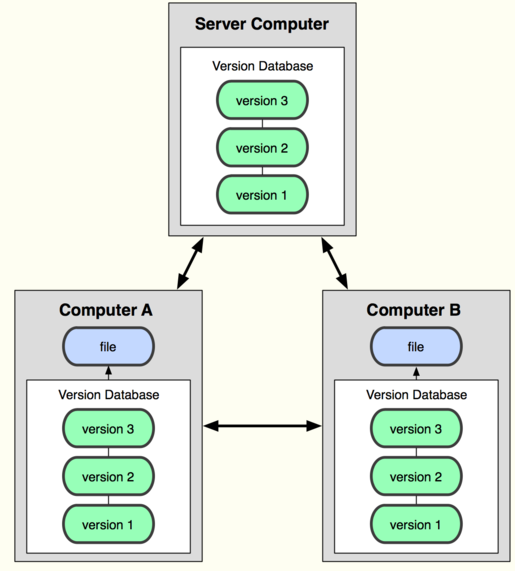
那分布式版本控制系统与集中式版本控制系统有何不同呢?首先,分布式版本控制系统没有“中央服务器”,每个人的电脑上都是一个完整的版本库,这样,你工作的时候,就不需要联网了,因为版本库就在你自己的电脑上。既然每个人电脑上都有一个完整的版本库,那多个人如何协作呢?比方说你在自己电脑上改了文件fiel,你的同事也在他的电脑上改了文件file,这时,你们俩之间只需把各自的修改推送给对方,就可以互相看到对方的修改了。
和集中式版本控制系统相比,分布式版本控制系统的安全性要高很多,因为每个人电脑里都有完整的版本库,某一个人的电脑坏掉了不要紧,随便从其他人那里复制一个就可以了。而集中式版本控制系统的中央服务器要是出了问题,所有人都没法干活了。
在实际使用分布式版本控制系统的时候,其实很少在两人之间的电脑上推送版本库的修改,因为可能你们俩不在一个局域网内,两台电脑互相访问不了,也可能今天你的同事病了,他的电脑压根没有开机。因此,分布式版本控制系统通常也有一台充当“中央服务器”的电脑,但这个服务器的作用仅仅是用来方便“交换”大家的修改,没有它大家也一样干活,只是交换修改不方便而已。如上图!
Git特点
|
1
2
3
4
5
6
7
8
9
10
11
12
|
1)分布式2)存储快照而非差异3)本地有完全的版本库,几乎所有操作都在本地4)有内在的一致性,SHA15)优秀的分支管理6)支持各种协同模式7)开源,有一些第三方软件可整合使用,几乎所有操作都是与CVS/SVN,Git 的优势1)支持离线开发,离线Repository(仓库)2)强大的分支功能,适合多个独立开发者协作3)速度块 |
为什么选择Git来控制版本,理由如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
1)快速如果你每移动一下鼠标都要等待五秒,是不是很受不了?版本控制也是一样的,每一个命令多那么几秒钟,一天下来也会浪费你不少时间。Git的操作非常快速,你可以把时间用在别的更有意义的地方。2)离线工作在没有网络的情况下如何工作?如果你用SVN或者CVS的话就很麻烦。而Git可以让你在本地做所有操作,提交代码,查看历史,合并,创建分支等等。3)回退人难免犯错。我很喜欢Git的一点就是你可以“undo”几乎所有的命令。你可以用这个功能来修正你刚刚提交的代码中的一个问题或者回滚整个代码提交操作。你甚至可以恢复一个被删除的提交,因为在后端,Git几乎不做任何删除操作。4)省心你有没有丢失过版本库?我有,而那种头疼的感觉现在还记忆犹新。而用Git的话,我就不必担心这个问题,因为任何一个人机器上的版本都是一个完整的备份。5)选择有用的代码提交当你把纽带,冰块还有西红柿一起扔进搅拌机的时候至少有两个问题。第一,搅拌过后,没有人知道之前扔进去了些什么东西。第二,你不能回退,重新把西红柿拿出来。同样的,当你提交了一堆无关的更改,例如功能A加强,新增功能B,功能C修复,想要理清这一堆代码到底干了什么是很困难的。当然,当发现功能A出问题的时候,你无法单独回滚功能A。Git可以通过创建“颗粒提交”,帮你解决这个问题。“staging area”的概念可以让你决定到底那些东西需要提交,或者更新,精确到行。6)自由选择工作方式使用Git,你可以同时和多个远程代码库连接,“rebase”而不是"merge"甚至只连接某个模块。但是你也可以选择一个中央版本库,就像SVN那样。你依然可以利用Git的其他优点。7)保持工作独立把不同的问题分开处理将有助于跟踪问题的进度。当你在为功能A工作的时候,其他人不应该被你还没有完成的代码所影响。分支是解决这个问题的办法。虽然其他的版本控制软件业有分支系统,但是Git是第一个把这个系统变得简单而快速的系统。8)随大流虽然只有死于才随着波浪前进,但是很多时候聪明的程序员也是随大流的。越来越多的公司,开源项目使用Git,包括Ruby On Rails,jQuery,Perl,Debian,Linux Kernel等等。拥有一个强大的社区是很大的优势,有很多教程、工具。 |
Git原理
|
1
2
3
4
5
|
1)四种基本类型BLOB: 每个blob代表一个(版本的)文件,blob只包含文件的数据,而忽略文件的其他元数据,如名字、路径、格式等。TREE: 每个tree代表了一个目录的信息,包含了此目录下的blobs,子目录(对应于子trees),文件名、路径等元数据。因此,对于有子目录的目录,git相当于存储了嵌套的trees。COMMIT:每个commit记录了提交一个更新的所有元数据,如指向的tree,父commit,作者、提交者、提交日期、提交日志等。每次提交都指向一个tree对象,记录了当次提交时的目录信息。一个commit可以有多个(至少一个)父commits。TAG: ag用于给某个上述类型的对象指配一个便于开发者记忆的名字, 通常用于某次commit。 |

|
1
|
2)工作区(Working Dir),提交区/暂存区(stage/index),版本库 |

Git的安装
|
1
2
3
4
5
6
7
8
|
不同的系统不同的安装命令,centos系统下直接yum就可以。[root@master-node ~]# yum install -y git安装完成后,还需要最后一步设置,在命令行输入:[root@master-node ~]#git config --global user.email "you@example.com"[root@master-node ~]#git config --global user.name "Your Name"因为Git是分布式版本控制系统,所以,每个机器都必须自报家门:你的名字和Email地址。你也许会担心,如果有人故意冒充别人怎么办?这个不必担心,首先我们相信大家都是善良无知的群众,其次,真的有冒充的也是有办法可查的。注意:git config命令的--global参数,用了这个参数,表示你这台机器上所有的Git仓库都会使用这个配置,当然也可以对某个仓库指定不同的用户名和Email地址。 |
Git常用的命令(即git + 下面的参数组成的命令):
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
add 添加文件内容至索引bisect 通过二分查找定位引入 bug 的变更branch 列出、创建或删除分支checkout 检出一个分支或路径到工作区clone 克隆一个版本库到一个新目录commit 记录变更到版本库diff 显示提交之间、提交和工作区之间等的差异fetch 从另外一个版本库下载对象和引用grep 输出和模式匹配的行init 创建一个空的 Git 版本库或重新初始化一个已存在的版本库log 显示提交日志merge 合并两个或更多开发历史mv 移动或重命名一个文件、目录或符号链接pull 获取并合并另外的版本库或一个本地分支push 更新远程引用和相关的对象rebase 本地提交转移至更新后的上游分支中reset 重置当前HEAD到指定状态rm 从工作区和索引中删除文件show 显示各种类型的对象status 显示工作区状态tag 创建、列出、删除或校验一个GPG签名的 tag 对象 |
创建版本库
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
什么是版本库呢?版本库又名仓库,英文名repository,你可以简单理解成一个目录,这个目录里面的所有文件都可以被Git管理起来,每个文件的修改、删除,Git都能跟踪,以便任何时刻都可以追踪历史,或者在将来某个时刻可以“还原”。所以,创建一个版本库非常简单,首先,选择一个合适的地方,创建一个空目录:第一步:创建一个仓库的目录[root@master-node /]# mkdir git_test[root@master-node /]# cd git_test/[root@master-node git_test]# pwd/git_test第二步:通过git init 命令把这个目录变成git可以管理的仓库[root@master-node git_test]# git init初始化空的 Git 版本库于 /git_test/.git/[root@master-node git_test]# ls -al总用量 12drwxr-xr-x 3 root root 4096 5月 10 13:53 .drwxr-xr-x. 19 root root 4096 5月 10 13:50 ..drwxr-xr-x 7 root root 4096 5月 10 13:53 .git瞬间Git就把仓库建好了,而且告诉你是一个空的仓库(empty Git repository),细心的读者可以发现当前目录下多了一个.git的目录,这个目录是Git来跟踪管理版本库的,没事千万不要手动修改这个目录里面的文件,不然改乱了,就把Git仓库给破坏了。也不一定必须在空目录下创建Git仓库,选择一个已经有东西的目录也是可以的。第三步:把文件添加到版本库首先这里再明确一下,所有的版本控制系统,其实只能跟踪文本文件的改动,比如TXT文件,网页,所有的程序代码等等,Git也不例外。版本控制系统可以告诉你每次的改动,比如在第5行加了一个单词“Linux”,在第8行删了一个单词“Windows”。而图片、视频这些二进制文件,虽然也能由版本控制系统管理,但没法跟踪文件的变化,只能把二进制文件每次改动串起来,也就是只知道图片从100KB改成了120KB,但到底改了啥,版本控制系统不知道,也没法知道。现在我们编写一个readme.txt文件,内容如下[root@master-node git_test]# cat readme.txtGit is veryt good toolauth :cgt一定要放到git_test目录下面,子目录也可以,放到其他地方git找不到文件。把一个文件放到Git仓库只需要两步。1)用命令git add告诉git,把文件添加到仓库[root@master-node git_test]# git add readme.txt执行上面的命令,没有任何的显示就对了。Linux的哲学思想:没有消息就是最好的消息,说明添加成功。2)用命令git commit告诉git,把文件提交到仓库[root@master-node git_test]# git commit -m "cgt write a readme file"[master(根提交) 87818f5] cgt write a readme file1 file changed, 2 insertions(+)create mode 100644 readme.txt简单解释一下git commit命令,-m后面输入的是本次提交的说明,可以输入任意内容,当然最好是有意义的,这样你就能从历史记录里方便地找到改动记录。嫌麻烦不想输入-m "xxx"行不行?确实有办法可以这么干,但是强烈不建议你这么干,因为输入说明对自己对别人阅读都很重要。实在不想输入说明的童鞋请自行Google,我不告诉你这个参数。git commit命令执行成功后会告诉你,1个文件被改动(我们新添加的readme.txt文件),插入了两行内容(readme.txt有两行内容)。为什么Git添加文件需要add,commit一共两步呢?因为commit可以一次提交很多文件,所以你可以多次add不同的文件,比如:[root@master-node git_test]# touch file1 file2 file3[root@master-node git_test]# lsfile1 file2 file3 readme.txt[root@master-node git_test]# git add file1 file2 file3[root@master-node git_test]# git commit -m "add 3 files"[master 827526e] add 3 files3 files changed, 0 insertions(+), 0 deletions(-)create mode 100644 file1create mode 100644 file2create mode 100644 file3 |
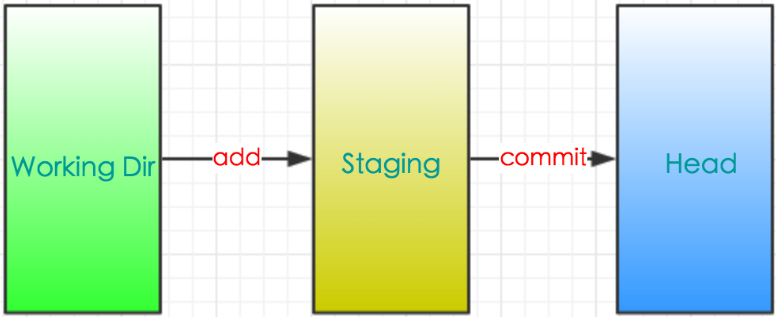
再次插足一下,说明一下git的工作流:
|
1
2
3
4
5
6
7
|
你的本地仓库由 git 维护的三棵"树"组成。第一个是你的 工作目录,它持有实际文件;第二个是 暂存区(staging),它像个缓存区域,临时保存你的改动;最后是 HEAD,它指向你最后一次提交的结果。你可以提出更改(把它们添加到暂存区),使用如下命令:git add <filename>git add *这是 git 基本工作流程的第一步;使用如下命令以实际提交改动:git commit -m "代码提交信息"现在,你的改动已经提交到了 HEAD,但是还没到你的远端仓库。 |
回滚-让去哪就去哪
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
前面已经创建了一个readme.txt文件,现在我们对他进行一些改动操作。[root@master-node git_test]# cat readme.txtGit is veryt good toolauth :cgtdate:2016-5-10执行git status[root@master-node git_test]# git status# 位于分支 master# 尚未暂存以备提交的变更:# (使用 "git add <file>..." 更新要提交的内容)# (使用 "git checkout -- <file>..." 丢弃工作区的改动)## 修改: readme.txt#修改尚未加入提交(使用 "git add" 和/或 "git commit -a")git status命令可以让我们时刻掌握仓库当前的状态,上面的命令告诉我们,readme.txt被修改过了,但还没有准备提交的修改。虽然Git告诉我们readme.txt被修改了,但如果能看看具体修改了什么内容,自然是很好的。比如你第二天上班时,已经记不清上次怎么修改的readme.txt,所以,需要用git diff这个命令看看,然后add之后在看一下status,是显示要commit的文件,现在再回想一下那个工作流图[root@master-node git_test]# git diffdiff --git a/readme.txt b/readme.txtindex b7cffdb..43b7253 100644--- a/readme.txt+++ b/readme.txt@@ -1,2 +1,3 @@Git is veryt good toolauth :cgt+date:2016-5-10[root@master-node git_test]# git add readme.txt[root@master-node git_test]# git status# 位于分支 master# 要提交的变更:# (使用 "git reset HEAD <file>..." 撤出暂存区)## 修改: readme.txt接下来进行commit操作[root@master-node git_test]# git commit -m "add date"[master de00305] add date1 file changed, 1 insertion(+)提交之后,在查看status[root@master-node git_test]# git status# 位于分支 master无文件要提交,干净的工作区 |
版本的回退
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
|
现在,你已经学会了修改文件,然后把修改提交到Git版本库,现在,再练习一次,修改readme.txt文件如下:[root@master-node git_test]# cat readme.txtGit is veryt good toolauth :cgtdate:2016-5-10version:1[root@master-node git_test]# git add readme.txt[root@master-node git_test]# git commit -m "version"[master 8b7d4ee] version1 file changed, 1 insertion(+)目前我们已经提交了三次,暂时你还能记住,但是在实际工作中我们是记不住的,不然要版本控制系统干什么。版本控制系统肯定有某个命令可以告诉我们历史记录,在Git中,我们用git log命令查看:[root@master-node git_test]# git logcommit 8b7d4eebe4e03809162f8193d6b2338926896ab4Author: caoxiaojian <1099415469@qq.com>Date: Tue May 10 14:59:16 2016 +0800versioncommit de003058c91312f695b57f42724f826f6ef42f17Author: caoxiaojian <1099415469@qq.com>Date: Tue May 10 14:52:10 2016 +0800add datecommit 827526ee243c93bfaf8f4f2f9dc22d31325cb47aAuthor: caoxiaojian <1099415469@qq.com>Date: Tue May 10 14:23:08 2016 +0800add 3 filescommit 87818f5454a2bc41cfbeca4b923a510d11fe72acAuthor: caoxiaojian <1099415469@qq.com>Date: Tue May 10 14:19:08 2016 +0800cgt write a readme filegit log 显示从最近到最远的提交日志,我们可以看到四次提交,最近的一次是version,上一次是date,最早的一次是cgt write a readme file 。如果嫌输出的信息太多,可以使用--pretty=oneline[root@master-node git_test]# git log --pretty=oneline8b7d4eebe4e03809162f8193d6b2338926896ab4 versionde003058c91312f695b57f42724f826f6ef42f17 add date827526ee243c93bfaf8f4f2f9dc22d31325cb47a add 3 files87818f5454a2bc41cfbeca4b923a510d11fe72ac cgt write a readme file需要友情提示的是,你看到的一大串8b7d4eebe4e03809162f8193d6b2338926896ab4类似的是commit id(版本号),和SVN不一样,Git的commit id不是1,2,3……递增的数字,而是一个SHA1计算出来的一个非常大的数字,用十六进制表示,而且你看到的commit id和我的肯定不一样,以你自己的为准。为什么commit id需要用这么一大串数字表示呢?因为Git是分布式的版本控制系统,后面我们还要研究多人在同一个版本库里工作,如果大家都用1,2,3……作为版本号,那肯定就冲突了。现在开始回滚,准备把readme.txt回退到上一个版本,也就是“date”的那个版本,怎么做呢?首先,Git必须知道当前版本是哪个版本,在Git中,用HEAD表示当前版本,也就是最新的提交3628164...882e1e0(注意我的提交ID和你的肯定不一样),上一个版本就是HEAD^,上上一个版本就是HEAD^^,当然往上100个版本写100个^比较容易数不过来,所以写成HEAD~100。回滚,我们可以使用git reset这个命令[root@master-node git_test]# git reset --hard HEAD^HEAD 现在位于 de00305 add date[root@master-node git_test]# cat readme.txtGit is veryt good toolauth :cgtdate:2016-5-10可以看出,他没有version那行,说明回滚成功。再来看git log[root@master-node git_test]# git logcommit de003058c91312f695b57f42724f826f6ef42f17Author: caoxiaojian <1099415469@qq.com>Date: Tue May 10 14:52:10 2016 +0800add datecommit 827526ee243c93bfaf8f4f2f9dc22d31325cb47aAuthor: caoxiaojian <1099415469@qq.com>Date: Tue May 10 14:23:08 2016 +0800add 3 filescommit 87818f5454a2bc41cfbeca4b923a510d11fe72acAuthor: caoxiaojian <1099415469@qq.com>Date: Tue May 10 14:19:08 2016 +0800cgt write a readme file没有了之前的version,那我要怎么才能恢复呢,回你的终端上,看看version的commit id,我们找到了:8b7d4eebe4e03809162f8193d6b2338926896ab4 version,执行恢复。恢复的时候ID不需要写全部的。[root@master-node git_test]# git reset --hard 8b7d4eebe4HEAD 现在位于 8b7d4ee version[root@master-node git_test]# cat readme.txtGit is veryt good toolauth :cgtdate:2016-5-10version:1 |
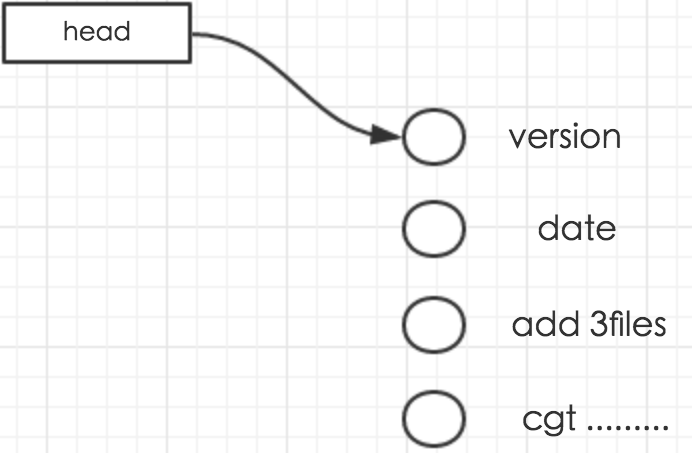
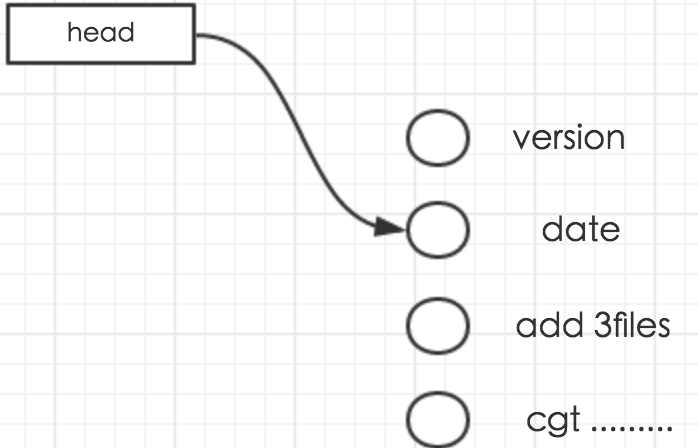
回滚原理解析:
Git的版本回退速度非常快,因为Git在内部有个指向当前版本的HEAD指针,当你回退版本的时候,Git仅仅是把HEAD从当前的version,指到date
回滚后
|
1
2
3
4
5
6
7
8
9
|
然后顺便把工作区的文件更新了。所以你让HEAD指向哪个版本号,你就把当前版本定位在哪。到了这里肯定有童鞋要问,那我要是不知道我前面的ID了,我去哪里回滚,我是不是该收拾工位回滚到家中了,git早就替你想好了,可以使用git reflog,把之前的ID都显示出来[root@master-node git_test]# git reflog8b7d4ee HEAD@{0}: reset: moving to 8b7d4eebe4de00305 HEAD@{1}: reset: moving to HEAD^8b7d4ee HEAD@{2}: commit: versionde00305 HEAD@{3}: commit: add date827526e HEAD@{4}: commit: add 3 files87818f5 HEAD@{5}: commit (initial): cgt write a readme file |
工作区和暂存区
不知道你是不是理解了我之前说的那个工作流,咱们这里再来啰嗦一遍。
Git和其他版本控制系统如svn不同之处是有暂存区的概念
先弄清楚这几个名次
工作区:
就是在你的电脑里能看到的目录,比如咱们创建的git_test
版本库:
工作区中有一个隐藏目录.git(之前已经给童鞋们提到过这个文件),它不算工作区,而是git的版本库。
git的版本库里面存放了很多的东西,其中最重要的就是称为stage(index)的暂存区,还有git为我们自动创建的第一个分支master,以及指向master的一个指针叫head。
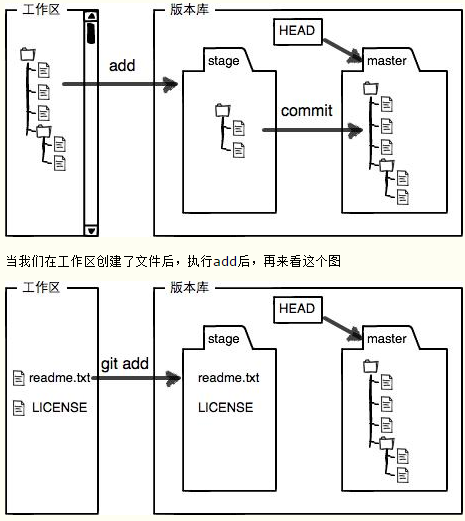
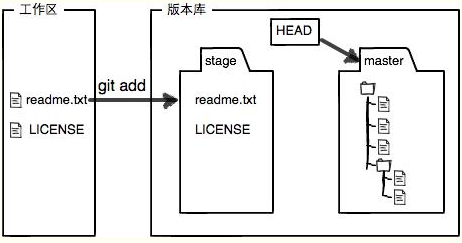
当我们在工作区创建了文件后,执行add后,再来看这个图
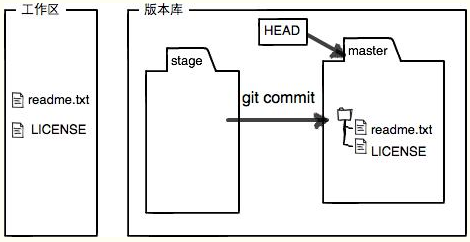
当你执行commit后,暂存区的内容就没有
管理修改
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
|
为什么Git比其他版本控制系统设计得优秀,因为Git跟踪并管理的是修改,而非文件。你会问,什么是修改?比如你新增了一行,这就是一个修改,删除了一行,也是一个修改,更改了某些字符,也是一个修改,删了一些又加了一些,也是一个修改,甚至创建一个新文件,也算一个修改。为什么说Git管理的是修改,而不是文件呢?我们还是做实验。第一步,对readme.txt做一个修改,第二步,添加到暂存区。第三步,查看状态[root@master-node git_test]# cat readme.txtGit is veryt good toolauth :cgtdate:2016-5-10version:1modify----------1[root@master-node git_test]# git add readme.txt[root@master-node git_test]# git status# 位于分支 master# 要提交的变更:# (使用 "git reset HEAD <file>..." 撤出暂存区)## 修改: readme.txt#第四步,再次编辑readme.txt,然后直接commit,再次查看status[root@master-node git_test]# cat readme.txtGit is veryt good toolauth :cgtdate:2016-5-10version:1modify----------1modify----------2[root@master-node git_test]# git commit -m "modify"[master 766baac] modify1 file changed, 1 insertion(+)[root@master-node git_test]# git status# 位于分支 master# 尚未暂存以备提交的变更:# (使用 "git add <file>..." 更新要提交的内容)# (使用 "git checkout -- <file>..." 丢弃工作区的改动)## 修改: readme.txt#修改尚未加入提交(使用 "git add" 和/或 "git commit -a")发现第二次的修改没有commit,那是因为你没有add提交后,用git diff HEAD -- readme.txt命令可以查看工作区和版本库里面最新版本的区别:[root@master-node git_test]# git diff HEAD -- readme.txtdiff --git a/readme.txt b/readme.txtindex 4416460..07c12e7 100644--- a/readme.txt+++ b/readme.txt@@ -3,3 +3,4 @@ auth :cgtdate:2016-5-10version:1modify----------1+modify----------2 |
撤销修改
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
|
编辑了readme,[root@master-node git_test]# cat readme.txtGit is veryt good toolauth :cgtdate:2016-5-10version:1modify----------1modify----------2caoxiaojian is xiaojianjian已经编辑完成,忽然发现了问题,最后一行,道出了笔者的心声。既然已经发现错误,那就很容易纠正它,你可以删除掉最后一行,手动把文件恢复到上一个版本的状态,如果用git status查看一下,[root@master-node git_test]# git status# 位于分支 master# 尚未暂存以备提交的变更:# (使用 "git add <file>..." 更新要提交的内容)# (使用 "git checkout -- <file>..." 丢弃工作区的改动)## 修改: readme.txt#修改尚未加入提交(使用 "git add" 和/或 "git commit -a")你可以发现上面提示你使用 "git checkout -- <file>..." 丢弃工作区的改动,那我们执行下[root@master-node git_test]# git checkout -- readme.txt[root@master-node git_test]# cat readme.txtGit is veryt good toolauth :cgtdate:2016-5-10version:1modify----------1已经回来了。命令git checkout -- readme.txt意思就是,把readme.txt文件在工作区的修改全部撤销,这里有两种情况:一种是readme.txt自修改后还没有被放到暂存区,现在,撤销修改就回到和版本库一模一样的状态;一种是readme.txt已经添加到暂存区后,又作了修改,现在,撤销修改就回到添加到暂存区后的状态。总之,就是让这个文件回到最近一次git commit或git add时的状态。git checkout -- file命令中的--很重要,没有--,就变成了“切换到另一个分支”的命令,我们在后面的分支管理中会再次遇到git checkout命令。刚刚咱们没有将修改提交到暂存区,那假如你提交到了呢??????你说咋整呢?????是不是吓尿了????[root@master-node git_test]# cat readme.txtGit is veryt good toolauth :cgtdate:2016-5-10version:1modify----------1caoxiaojian is xiaojianjian[root@master-node git_test]# git add readme.txt[root@master-node git_test]# git status# 位于分支 master# 要提交的变更:# (使用 "git reset HEAD <file>..." 撤出暂存区)# 修改: readme.txt你要是聪明的话,你应该已经知道要怎么做了。。。。对是的,就是你想的那样。[root@master-node git_test]# git reset HEAD readme.txt重置后撤出暂存区的变更:M readme.txt[root@master-node git_test]# git status# 位于分支 master# 尚未暂存以备提交的变更:# (使用 "git add <file>..." 更新要提交的内容)# (使用 "git checkout -- <file>..." 丢弃工作区的改动)## 修改: readme.txt#修改尚未加入提交(使用 "git add" 和/或 "git commit -a")已经退出了暂存区。你可能要问,那要是已经commit了呢??你小子胆子还真不小啊,教你一招,之前不是讲过回滚嘛,直接回滚。不过这个也是有条件的,就是你还没有把自己的本地版本库推送到远程。Git是一个分布式版本控制,他还有远程版本库,一旦你提交到远程版本库,那你就可以git go home |
删除文件
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
先创建文件,后add,在commit,然后删除工作区的文件[root@master-node git_test]# cat test.txtqwertyuiop[adfghjjljhfdgscvxz[root@master-node git_test]# git add test.txt[root@master-node git_test]# git commit -m "del test"[master 63d3bf7] del test1 file changed, 3 insertions(+)create mode 100644 test.txt[root@master-node git_test]# rm -rf test.txt[root@master-node git_test]# git status# 位于分支 master# 尚未暂存以备提交的变更:# (使用 "git add/rm <file>..." 更新要提交的内容)# (使用 "git checkout -- <file>..." 丢弃工作区的改动)## 修改: readme.txt# 删除: test.txt#修改尚未加入提交(使用 "git add" 和/或 "git commit -a")现在你有两个选择,一是确实要从版本库中删除该文件,那就用命令git rm删掉,并且git commit:[root@master-node git_test]# git rm test.txtrm 'test.txt'[root@master-node git_test]# git commit -m "remove test.txt"[master 5f04ee2] remove test.txt1 file changed, 3 deletions(-)delete mode 100644 test.txt现在文件就从版本库中彻底的删除了。命令git rm用于删除一个文件。如果一个文件已经被提交到版本库,那么你永远不用担心误删,但是要小心,你只能恢复文件到最新版本,你会丢失最近一次提交后你修改的内容。另一种情况是删错了,因为版本库里还有呢,所以可以很轻松地把误删的文件恢复到最新版本:使用git checkout -- test.txtgit checkout其实是用版本库里的版本替换工作区的版本,无论工作区是修改还是删除,都可以“一键还原”。 |
远程仓库
|
1
2
3
4
5
6
7
8
9
10
11
12
|
可以使用github给我们提供的服务,作为我们的一个远程仓库。但是需要做一下的设置。由于你的本地Git仓库和GitHub仓库之间的传输是通过SSH加密的,所以我们首先生成秘钥。第1步:创建SSH Key。在用户主目录下,看看有没有.ssh目录,如果有,再看看这个目录下有没有id_rsa和id_rsa.pub这两个文件,如果已经有了,可直接跳到下一步。如果没有,打开Shell(Windows下打开Git Bash),创建SSH Key:ssh-keygen -t rsa -C "youremail@example.com"你需要把邮件地址换成你自己的邮件地址,然后一路回车,使用默认值即可,由于这个Key也不是用于军事目的,所以也无需设置密码。如果一切顺利的话,可以在用户主目录里找到.ssh目录,里面有id_rsa和id_rsa.pub两个文件,这两个就是SSH Key的秘钥对,id_rsa是私钥,不能泄露出去,id_rsa.pub是公钥,可以放心地告诉任何人。第2步:添加公钥到你的登陆GitHub,打开“Account settings”,“SSH Keys”页面,然后将你的key添加上。为什么GitHub需要SSH Key呢?因为GitHub需要识别出你推送的提交确实是你推送的,而不是别人冒充的,而Git支持SSH协议,所以,GitHub只要知道了你的公钥,就可以确认只有你自己才能推送。 |
添加远程库
你原本在本地已经创建了一个Git仓库,现在又想在github上也创建一个仓库,让这两个仓库可以远程同步。这样github的仓库既可以作为备份,又可以让其他人通过该仓库来协作。
第一步:创建一个新的仓库repository
右上角有个➕,然后现在new repository
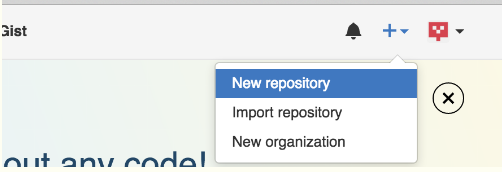
然后进入创建页面
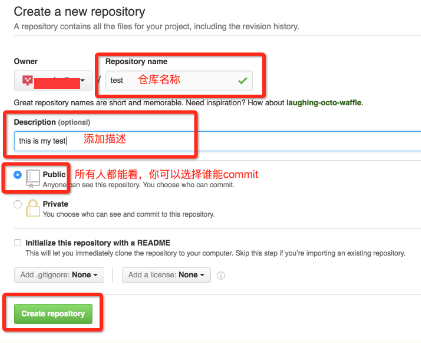
仓库内容的提交

接下来咱们看如何使用
本地没有仓库的情况下,要先创建仓库。
[root@master-node ~]# mkdir /test
[root@master-node ~]# cd /test
使用git init 创建定义仓库
[root@master-node ~]# git init
Initialized empty Git repository in C:/Program Files/Git/test/.git/
[root@master-node ~]# ls -al
total 8
drwxr-xr-x 1 cgt 197121 0 五月 16 06:11 ./
drwxr-xr-x 1 cgt 197121 0 五月 16 06:11 ../
drwxr-xr-x 1 cgt 197121 0 五月 16 06:11 .git/
在仓库中创建一个文件,然后add commit
[root@master-node ~]# echo "# test " >> README.md
[root@master-node ~]# git add README.md
warning: LF will be replaced by CRLF in README.md.
The file will have its original line endings in your working directory.
[root@master-node ~]# git commit -m "first commit"
[master (root-commit) 7eeb945] first commit
warning: LF will be replaced by CRLF in README.md.
The file will have its original line endings in your working directory.
1 file changed, 1 insertion(+)
create mode 100644 README.md
至此,提交到本地的head中。也就是本地仓库中,然后从本地仓库向远程仓库提交。
使用remote关联一个远程库,add是定义一个远程的名称,默认一般使用origin,后面跟的是远程仓库的名称
[root@master-node ~]# git remote add origin git@github.com:caoxiaojian/test.git
把本地库的内容推送到远程,实际上是将本地的当前分支master,推送到远程
[root@master-node ~]# git push -u origin master
Warning: Permanently added the RSA host key for IP address '192.30.252.128' to the list of known hosts.
Counting objects: 3, done.
Writing objects: 100% (3/3), 210 bytes | 0 bytes/s, done.
Total 3 (delta 0), reused 0 (delta 0)
To git@github.com:caoxiaojian/test.git
* [new branch] master -> master
Branch master set up to track remote branch master from origin.
由于远程库是空的,我们第一次推送master分支时,加上了-u参数,Git不但会把本地的master分支内容推送的远程新的master分支,还会把本地的master分支和远程的master分支关联起来,在以后的推送或者拉取时就可以简化命令。
再次修改README.md
[root@master-node ~]# echo "# this is my test file " >> README.md
[root@master-node ~]# git add README.md
warning: LF will be replaced by CRLF in README.md.
The file will have its original line endings in your working directory.
[root@master-node ~]# git commit -m "2 commit"
[master warning: LF will be replaced by CRLF in README.md.
The file will have its original line endings in your working directory.
80bc0e7] 2 commit
warning: LF will be replaced by CRLF in README.md.
The file will have its original line endings in your working directory.
1 file changed, 1 insertion(+)
[root@master-node ~]# git push origin master
Warning: Permanently added the RSA host key for IP address '192.30.252.120' to the list of known hosts.
Counting objects: 3, done.
Writing objects: 100% (3/3), 257 bytes | 0 bytes/s, done.
Total 3 (delta 0), reused 0 (delta 0)
To git@github.com:caoxiaojian/test.git
7eeb945..80bc0e7 master -> master
到github下面对应的仓库里查看
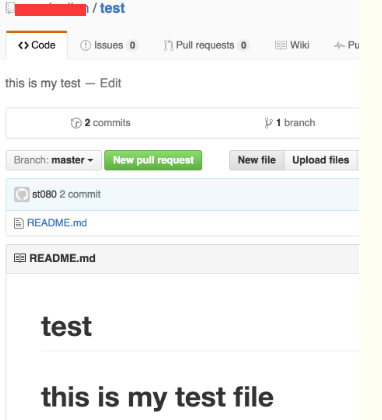
每次本地提交后,只要有必要,就可以使用命令git push origin master推送最新修改
克隆远程库
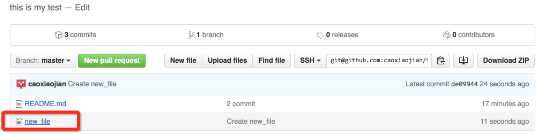
在刚创建的仓库中创建新文件

创建文件

创建完成后可以看见你的新文件
因为之前已经创建了test这个本地仓库,所以先删除,然后再clone
[root@master-node ~]# rm -rf /test/
[root@master-node ~]# git clone git@github.com:caoxiaojian/test.git
Cloning into 'test'...
Warning: Permanently added the RSA host key for IP address '192.30.252.121' to the list of known hosts.
remote: Counting objects: 9, done.
remote: Compressing objects: 100% (4/4), done.
remote: Total 9 (delta 0), reused 6 (delta 0), pack-reused 0
Receiving objects: 100% (9/9), done.
Checking connectivity... done.
[root@master-node ~]# cd /test/
test (master)
[root@master-node ~]# ls
new_file README.md
test (master)
[root@master-node ~]# cat new_file
make a new file for clone test
分支管理
分支在实际中有什么用呢?假设你准备开发一个新功能,但是需要两周才能完成,第一周你写了50%的代码,如果立刻提交,由于代码还没写完,不完整的代码库会导致别人不能干活了。如果等代码全部写完再一次提交,又存在丢失每天进度的巨大风险。
现在有了分支,就不用怕了。你创建了一个属于你自己的分支,别人看不到,还继续在原来的分支上正常工作,而你在自己的分支上干活,想提交就提交,直到开发完毕后,再一次性合并到原来的分支上,这样,既安全,又不影响别人工作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号