Spring Boot随笔
- GitHub使用
- 下载Git并安装
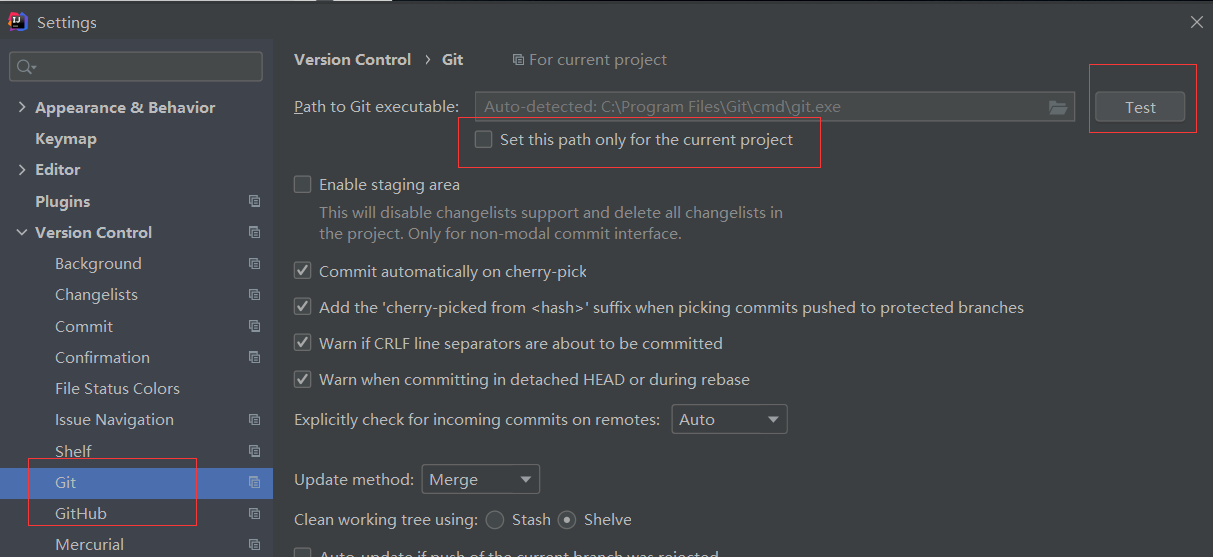
- Version Control --- Git Path to Git executable 选择Set this path only for the current project,点击test
![]()
- GitHub填写账号信息
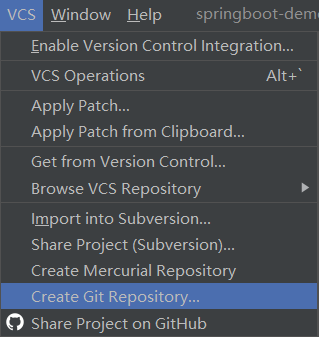
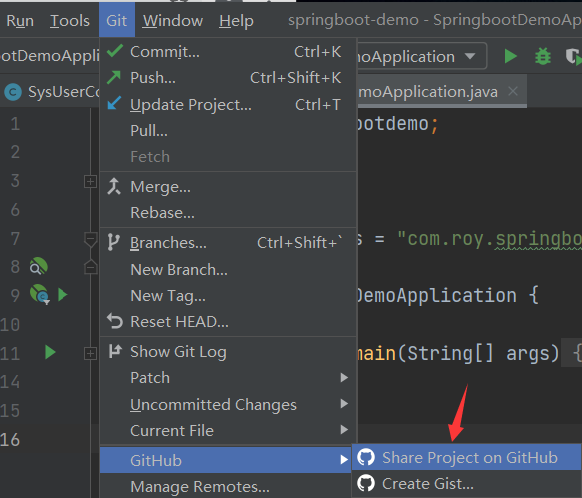
- VCS创建项目
![]()
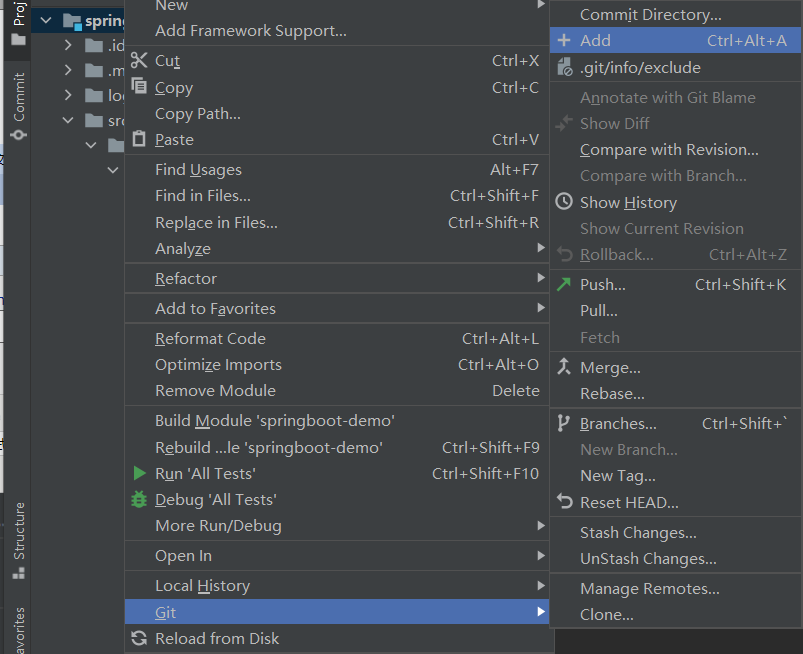
- 在项目上右键选择add
![]()
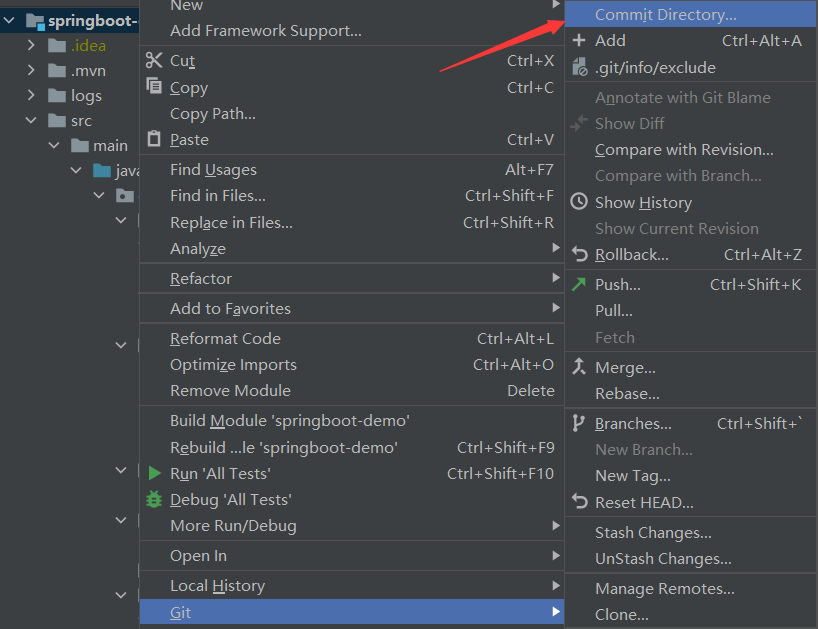
- Commint Directory
![]()
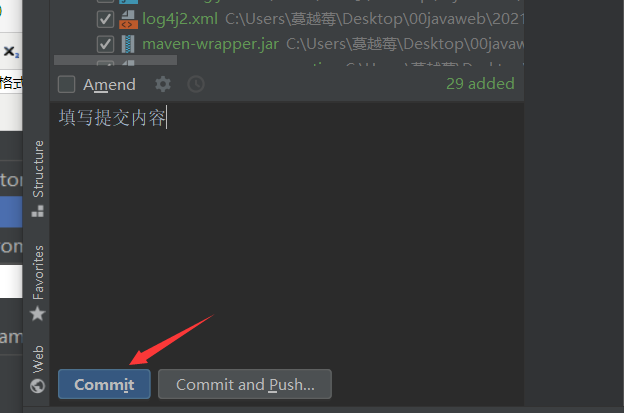
- 填写提交信息
![]()
![]()
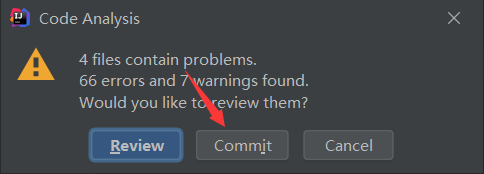
- 提交
![]()
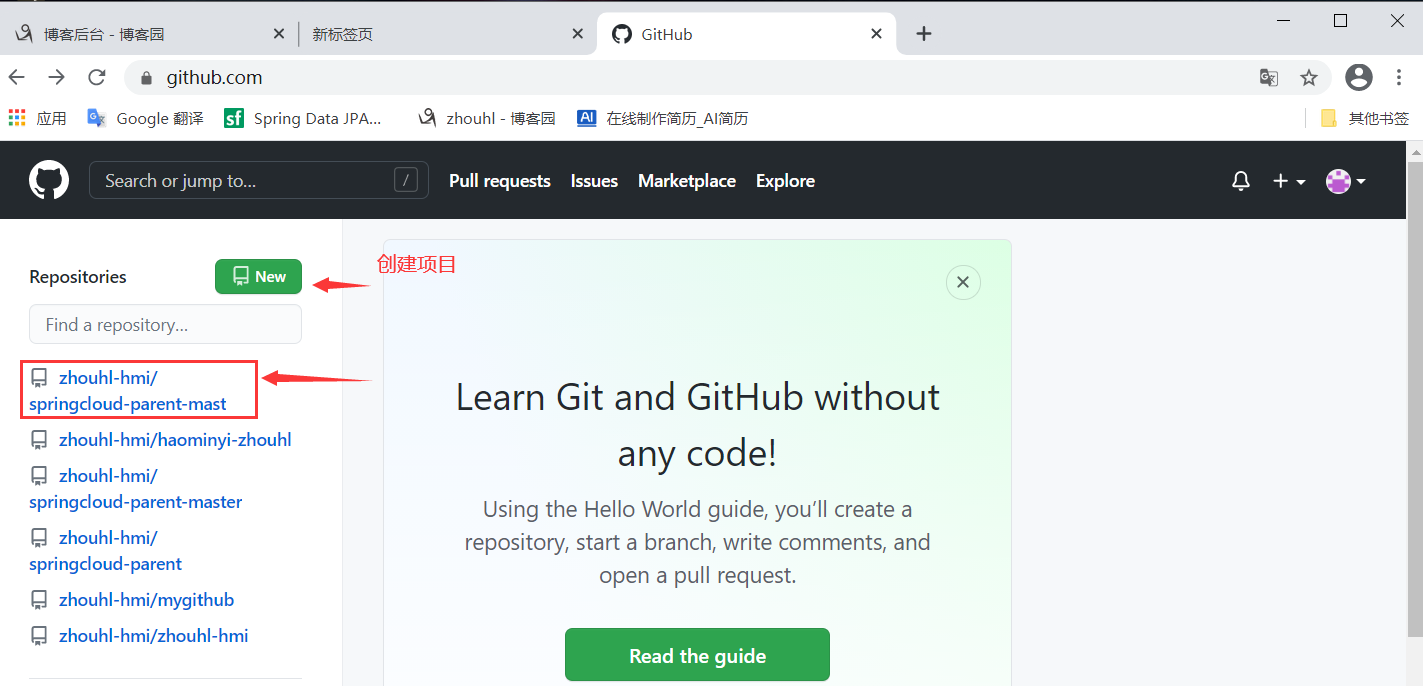
- 从GitHub官网上看已上传的项目
![]()
- 下载代码,通过URL地址
![]()
- SpringCloud
- 简介
- SpringCloud:是一套目前完整的微服务框架,它是一系列框架的有序集合。它只是将目前各家公司开发的比较成熟,经得起实际考验的服务框架组合起来,通过SpringBoot风格进行再封装屏蔽掉了复杂的配置的实现原理,最终给开发者留出了一套简单易懂,易部署和易维护的分布式系统开发工具包。它利用Spring Boot的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册,配置中心,消息总线,负载均衡,断路器,数据监控等,都可以用SpringBoot的开发风格做到一键启动和部署。
- Spring Cloud Netfix
- 通过注释,快速启动和配置应用程序中的常见模式,并通过经过测试的Netflix组件构建大型分布式系统。提供的模式包括服务发现(Eureka),断路器(Hystrix),智能路由(Zuul)和客户端负载平衡(Ribbon)。
- 注册中心:Euerka和Consul使用最为广泛。
- 断路器(Hystrix)
- 定义:在分布式环境中,许多服务依赖项中的一些必然会失败。Hystrix是一个库,通过添加延迟容忍和容错逻辑,帮助你控制这些分布式服务之间的交互。Hystrix通过隔离服务之间的访问点/停止级联失败和提供回退选项来实现这一点,所有这些都可以提高系统的整体弹性。
- 实现:每个依赖项相互隔离,当延迟发生时,它会被限制在资源中,并包含回退逻辑,该逻辑决定在依赖项中发生任何类型的故障时应作出何种响应
- feign是声明式的web service客户端,它让微服务之间的调用变得更简单了,类似controller调用service.Spring Cloud集成了Ribbon和Eureka,可在使用Feign时提供负载均衡的http客户端。
- Feign原理简述
- 启动时,程序会进行包扫描,扫描所有包下所有@FeignClient注解的类,并将这些类注入到 spring的IOC容器。当定义的Feign中的接口被调用时,通过JDK的动态代理来生成RequestTemplate.
- RequestTemplate中包含请求的所有信息,如请求参数,请求URL等。
- RequestTemplate声明Request,然后将Request交给client处理,这个client默认是JDK的HTTPUrlConnection,也可以是OKhttp/Apache的HTTPClient等。
- 最后client封装成LoadBalanceClient,结合ribbon负载均衡地发起调用。
- 常用注解
- common中的 注解
- @EnableEurekaServer //启动一个服务注册中心提供给其他应用进行对话
- @FeignClient 消息传递和容错
- 注解来声明一个Feign Client,其中value为远程调用其他服务的服务名;fallback配置回调处理类,该类是作为Feign熔断器的逻辑处理类
-
@FeignClient(value="springcloud-provider/provider/api/user",fallback = FallbackClientFactory.class)
//@FeignClient(name="runClient",url="localhost:8001")解释:value和name其实是一个属性:
- 接口提供方在注册中心。
- 如果服务提供方已经注册到注册中心了,那么name或者value的值为:服务提供方的服务名称。必须为所有客户端指定一个name或者value
- 单独的一个http接口,接口提供方没有注册到注册中心。
- 此处name的值为:调用客户端的名称。 name可以为注册中心的实例名称,加上url属性,name的值就与注册中心实例名称无关。
- 降级概念:代码执行失败或者降级策略开启时,可以在@FeignClient设置一个fallback属性实现这个降级策略。
- 接口提供方在注册中心。
- provider中的注解
- @EnableDiscoveryClient 表示支持服务发现
- @EnableDiscoveryClient和@EnableEnableEurekaClient共同点就是:都是能够让注册中心发现,扫描到该服务器。
- 不同点: @EnableEurekaClient只适用于Eureka作为注册中心,@EnableDiscoveryClient可以是其他注册中心。
- @EnableDiscoveryClient 表示支持服务发现
- comsumer中的注解
- @EnableEurekaClient 在spring cloud应用启动的时候,就可以把EurekaDiscoveryClient注入,继而使用NetFlix提供的Eurekaclient。
- SpringBoot项目的@SpringBootApplication注解包含了包扫描注解@ComponentScan,需要注意的是它只能扫描到和这个类的同级目录或其同级子目录。如果需要扫描自定义的目录就需要在main方法上加上@ComponentScan
- @EnableFeignClients注解表明当前应用服务(称为服务A)中有的地方想要引用其他应用服务(称为服务B)中的接口。使用basePackages属性字段去指明应用程序A在启动的时候需要扫描服务B中的标注了; 解决:服务B没有单独启动起来,而是以Jar包的形式被引入到服务A中,则服务A不会主动加载B注解的interface生成bean对象,而产生的报错。
- 简介
- SpringBoot
- 简介
- SpringBoot:是一个快速开发框架,通过MAVEN依赖的继承方式,帮助我们快速整合第三方常用框架,完全采用注解化(使用注解方式启动SpringMVC),简化XML配置,内置HTTP服务器(Tomcat,Jetty),最终以Java应用程序进行执行。
- SpringBoot和SpringCloud的关系与区别
- SpringBoot只是一个快速开发框架,使用注解简化了xml配置,内置了Servlet容器,以Java应用程序进行执行。
- SpringCloud是一系列框架的集合,可以包含SpringBoot。
- SpringBoot是微服务框架吗?
- SpringBoot只是一个快速开发框架,算不上微服务框架。
- SpringCloud+SpringBoot实现微服务开发。具体的来说是,SpringCloud具备微服务开发的核心技术:RPC远程调用技术;SpringBoot的web组件默认集成了SpringMVC,可以实现HTTP+JSON的轻量级传输,编写微服务接口,所以SpringCloud依赖SpringBoot框架实现微服务开发。
- 简介
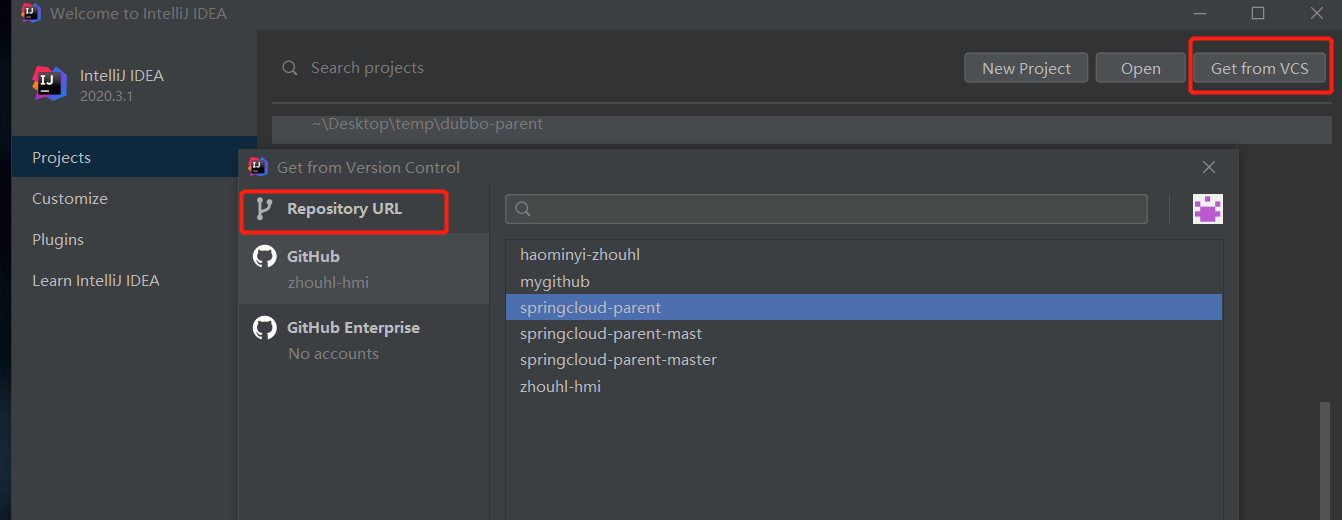
- 微服务-dubbo
- 生产者消费者调用关系 Dubbo Architecture
- 橘黄色线 init 初始化;蓝色 async 异步;绿色 sync 同步;
- Provider 暴露服务的服务提供方
- Consumer 调用远程服务的服务消费方
- Registry 提供注册与调用服务的注册中心;官方推荐使用Zookeeper注册中心
- Monitor 统计服务的调用次数和调用时间的监控中心
- 关系图如下:
![]()
- zookeeper启动,在Windows PowerShell里输入:
-
PS D:\test\zookeeper-3.3.6\bin> ./zkServer.cmd
-
d:\test\zookeeper-3.3.6\bin\zkServer.cmd
- 配置MAVEN环境变量
- 变量名:MAVEN_HOME 变量值: D:\javapro\apache-maven-3.6.3
- path: %MAVEN_HOME%\bin\
- 生产者消费者调用关系 Dubbo Architecture
- 基于token的鉴权机制
- 流程
- 用户使用用户名密码来请求服务器
- 服务器进行验证用户的信息
- 服务器通过验证发送给用户一个token
- 客户端存储token,并在每次请求时附送上这个token值
- 服务器验证token值,并返回数据
- 流程
- Api文档
- 背景:
- 前后端分离,前后端需要对数据内容进行交流
- 解决方案:
- API数据接口文档就是给前端响应格式统一的内容
- 后端将数据结构解释给前端用的方式
- Excel
- markdown
- word
- 手写版Api文档
-
#编写api文档 查询全部用户信息 http://localhost:8082/demo_back/api/sysuser?flag=1 参数: 无 请求模式: GET 返回格式: json对象 { "code":"1000", [1000代表成功,2000代表失败] "msg":"成功", [成功或者失败] "data":[ { "id":1, [主键,整数] "name":"hmi", [姓名,string] "code":"612523188", [身份证号码,18位字符串] "sex":'M' [性别,字符,M男 F女 U未知] }, { "id":2, [主键,整数] "name":"zhl", [姓名,string] "code":"612523199", [身份证号码,18位字符串] "sex":'M' [性别,字符,M男 F女 U未知] } ] }
- swagger(嵌入在web项目专门用来给前端解释调用方法的)
- 背景:
- 跨域
- 问题背景:前后端分离,会存在跨域问题:http协议为了保证自身的安全,三不同中有一个不同,就不能相互调用
- 协议不同,http://a 去调用https://a
- 端口不同,http://a 去调用http://a:8080
- 域名不同,http://a:8080 去调用http://b:8080
- 解决方案:
- Nginx服务,反向代理
- JSONP: http协议允许通过<script src="http://xxx:9989/aaa.do">,所以利用jsonp的方式对后端进行访问,后端要配合前端进行数据传递,传递时,必须将数据套在前端的jsonp指明的函数名内
-
const dataInit=function(){ $.ajax({ url:'http://localhost:8082/demo_back/api/sysuser/test2', data:{flag:1}, type:'GET', dataType:'JSONP', jsonp:"callback", success:dataInitCallBack }) }
-
public class ResponseJsonUtil { public static void writeJson(HttpServletRequest request,HttpServletResponse response,Object params) { String callback=request.getParameter("callback"); PrintWriter out; try { out = response.getWriter(); out.write(callback+"("+JSON.toJSONString(params)+")"); out.close(); } catch (IOException e) { e.printStackTrace(); } } TestServlet中的调用 //调用通用跨域响应工具进行结果响应时 ResponseJsonUtil.writeJson(request, response, rdto);
- springcloud的网关也可以解决
- 后端在代码中给响应对象中添加允许跨域的需求
- 在servlet中进行处理,或者在过滤器中添加,这样可以一劳永逸
-
// 工具类中的统一返回,跨域处理 response.addHeader("Access-Control-Allow-Origin", "*"); response.addHeader("Access-Control-Allow-Headers", "X-Token"); response.addHeader("Access-Control-Allow-Credentials", "true"); response.addHeader("Access-Control-Allow-Methods", "GET,POST,PUT,DELETE,OPTIONS"); response.addHeader("Access-Control-Max-Age", "3600"); - 在vue中可以使用axios设置解决
- 在springboot中的controller中增加注解
@CrossOrigin
- 问题背景:前后端分离,会存在跨域问题:http协议为了保证自身的安全,三不同中有一个不同,就不能相互调用
- UUID
- UUID是通用唯一识别码的缩写,是一种软件建构的标准,亦为开放软件基金会组织在分布式计算机领域的一部分。其目的,是让分布式系统中的所有元素,都能有唯一的辨识信息,而不需要通过中央控制端来做辨识信息的指定。如此一来,每个人都可以创建不与其他人冲突的UUID。在这种情况下,就不需考虑数据库创建时的名称重复问题。目前最广泛的UUID,是微软公司的全局唯一标识符(GUID),而其他重要的应用,则有Linux ext2/ext3文件系统、LUKS加密分区、GNOME/KDE/Mac OS X等等。另外我们也可以在e2fsprogs包中的UUID库找到实现。
- MD5加密
- 数据加密的基本过程就是对原来为明文的文件或数据按某种加密算法进行处理,使其成为一段不可读的代码,通常称为“密文”,通过这种途径来达到保护原始数据的目的。通过解密方法或秘钥,经过解密过程,可以将密文还原成可读的原文。
- md5加密是我们常用的一种加密算法,可以对明文进行处理产生一个128位(16字节)的散列值,为了便于展示和读取一般将128位的二进制数转换成32位16进制数。通常用在密码存储和文件的完整性校验上。
- 正则表达式
-
//手机号正则
public static String PHONE_REGSTR = "^[1][0-9]{10}$";- ^:匹配字符串开始
- [1]:表示第一个数字为1
- [0-9]{10}:[0-9]表示0到9的数字,{10}表示10个
- $:匹配字符串结尾
-
//密码正则
public static String PASSWORD_REGSTR = "^([A-Z]|[a-z]|[0-9]|[_]){6,10}$";- 意思是:密码由大写字母、小写字母、0-9的数字、下划线组成,长度为6-10位;
- 就是长度为6~10的仅由字母、数字、下划线组成的字符串。
-
- Redis
- Redis是一个开源的、基于内存的数据结构存储器,可以用作数据库、缓存和消息中间件。
- redis通常用来存储key-value结构的数据,业务上可以存储短信的验证码,所以redis也支持有效时间内的存储(到期自动删除数据)
- 数据画像,通过你注册的手机号、网卡号、身份证号...来唯一确定你在这个网站中的信息主键
- 检查redis是否在后台运行的方法:ps -ef | grep redis 显示有关redis的所有有关的进程。
- service redisd start 启动redisd
- service redisd stop 关闭redisd
- 注解
- @EnableCaching注解
- 是spring framework中的注解驱动的缓存管理功能。
- 当在配置类(@Configuration)上使用@EnableCaching注解时,会触发一个post processor,这会扫描每一个spring bean,查看是否已经存在注解对应的缓存。如果找到了,就会自动创建一个代理拦截方法调用,使用缓存的bean执行处理。
- @EnableCaching注解
- 报错类问题
- 报错提示:
- Caused by: org.yaml.snakeyaml.error.YAMLException: java.nio.charset.MalformedInputException: Input l
- 解决方案:
- 修改yml的编码格式为utf-8
- 报错提示:
springboot:redis报错io.lettuce.core.RedisCommandExecutionException: ERR Client sent AUTH, but no passw
- 解决方案:
-
给redis设置密码
1、命令窗口,进入到redis所在的目录下
2、然后输入 redis-cli 回车
3、输入 config set requirepass 123456 回车
123456就是密码
-
-
redis-cli是一个redisserver的客户端 redis-cli命令功能: 用于连接redis-server服务器端 redis-cli命令的语法格式: redis-cli [参数] -----常用参数说明------ -h:服务器主机名称 -p:服务器端口 -a:连接到服务器时使用的密码 -r:执行指定命令N次 -n:数据库编号 --csv:以csv格式输出 -
redis-cli是一个redisserver的客户端 redis-cli命令功能: 用于连接redis-server服务器端 redis-cli命令的语法格式: redis-cli [参数] -----常用参数说明------ -h:服务器主机名称 -p:服务器端口 -a:连接到服务器时使用的密码 -r:执行指定命令N次 -n:数据库编号 --csv:以csv格式输出 - 查看redis的版本
-
[root@bogon src]# ./redis-server -v
----------------------------测试方式-------------------------------- cd 进入redis目录,执行./src/redis-server ./redis.conf 【注意在原来的会话窗口中】 ./redis-cli -h 127.0.0.1 -a abcdef@123456 进入redis客户端后,通过set key value ex 120进行新增,ex表示该key存在120秒后自动删除
- 报错提示:
- 常见消息中间件
- Kafka
- Kafka是由Apache软件基金会开发的一个开源流处理平台,用Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中所有动作流数据。由于其高吞吐量的特性,Kafka经常被用来存储项目日志。
- Kafka
- Apache Druid
- 什么是德鲁伊?
- Apache Druid是一个实时分析数据库,旨在对大型数据集进行快速的切片和切分分析("OLAP"查询)。Druid最常用作数据库,以支持对实时接收,快速查询性能和高正常运行时间很重要的用例。因此,Druid通常用于分析应用程序的GUI供电,或用作需要快速聚合的高并发API的后端。德鲁伊最适合面向事件的数据。
- 访问方式
- http://localhost:9001/druid/
- 什么是德鲁伊?
- 常用注解
@ConfigurationProperties注解的作用是:当某个Spring Boot项目引入此Maven项目,并且此Spring Boot项目的application.yml文件中有path的的配置时,path中的值将以此配置的值作为最终值。
FileConfig文件
@ConfigurationProperties(prefix="sd.upload")
@Component
public class FileConfig {
private String path;
public String getPath() {
return path;
}
public void setPath(String path) {
this.path = path;
}
}
application-dev.yml文件
#项目自己的配置
sd:
upload:
path: /usr/local/upload
配置swagger类
- swagger2的访问地址:http://localhost:9001/swagger-ui.html
- 注解@swagger2的作用:使用swagger2构建restful接口测试;优点:可以生成文档形式的api并提供给不同的团队
- @Configuration注解,使此类作为一个配置类存在,作用等同于Spring 的applicationContext.xml文件
- @EnableSwagger2注解,开启这个配置
- @Api()用于类,标识这个类是swagger的资源
- @ApiOperation()用于方法;表示一个http请求的操作
- @ApiImplicitParam()用于方法;表示单独的请求参数
例如以下代码:
@ApiImplicitParam(name="SysUser",value = "用户信息实体",required = true,dataType = "SysUser",paramType = "path")
- name:参数名
- value:参数的具体意义,作用。
- required:参数是否必填
- dataType:参数的数据类型
- paramType:查询参数类型,这里有几种形式:
- path 以地址的形式提交数据
- query 直接跟参数完成自动映射赋值
- body 以流的形式提交 仅支持POST
- header 参数在request headers里边提交
- form 以form表单的形式提交 仅支持POST
JPA注解
- mybatis和Hibernate的不同
- Mybatis不完全是一个ORM框架,因为MyBatis需要程序员自己编写Sql语句,不过mybatis可以通过XML或者注解方式灵活配置要运行的sql语句,并将java对象和sql语句映射生成最终执行的sql,最后将sql执行的结果再映射生成java对象。
-
- Hibernate对象/关系映射能力强,数据库无关性好,对于关系模型要求高的软件(例如需求固定的定制化软件)如果用hibernate开发可以节省很多代码,提高效率。
- orm框架
- 提供了JDBC的简化操作,无缝对接数据源/连接池技术
- orm框架实现mybatis ,hibernate(通过方言的定义可以自动生成不同数据库适用的SQL语句),如果有跨库的业务(原本使用MySQL,因为业务瓶颈问题升级为Oracle/DB2)
- JPA规范
- 全称Java Persistence API ,可以通过注解或者XML描述【对象-关系表】之间的映射关系,并将实体对象持久化到数据库中
- JPA是一套ORM规范,Hibernate实现了JPA规范
- Spring Data JPA 可以理解为JPA规范的再次封装抽象,底层还是使用了Hibernate的JPA技术实现
-
@Entity @Table(name="JPA_USER") - @Entity 表明该类(UserEntity)为一个实体类,它默认对应数据库中的表名是user_entity,可以写成Entity(name="xwj_user")或者@Entity @Table(name="xwj_user",schema="test")
- @Table 当实体类与其映射的数据库表名不同名时需要使用 @Table注解说明,该标注与@Entity注解并列使用,置于实体类声明语句之前,可写于单独语句行,也可与声明语句同行。
- Table注解的常用选项是name,用于指明数据库的表名。
- Table注解还有两个选项catalog和schema用于设置表所属的数据库目录或模式,通常为数据库名。
-
@Id @GeneratedValue(strategy = GenericArrayType.IDENTITY) - @Id 指定表的主键
- @GeneratedValue JPA通用策略生成器
- 通过annotation来映射hibernate实体的,基于annotation的hibernate主键标识为@Id
- 其生成规则是由@GeneratedValue设定的。这里的@Id和@GeneratedValue都是JPA的标准用法。
- JPA提供的四种标准用法为TABLE,SEQUENCE,IDENTITY,AUTO
- TABLE:使用一个特定的数据库表格来保存主键
- SEQUENCE: 根据底层数据库的序列来生成主键,条件是数据库支持序列。
- IDENTITY: 主键由数据库自动生成(主要是自动增长型)
- AUTO:主键由程序控制
-
@Column(name="jname")
- @Column 用来标识实体类中属性与数据表中字段的对应关系
- name 定义了被标注字段在数据库表中所对应字段的名称
-
@Query("from JUser where age > ?1 ") - @Query注解查询适用于所查询的数据无法通过关键字查询得到结果的查询。这种查询可以摆脱像关键字查询那样的约束,将查询直接在相应的接口方法中声明,结构更为清晰,这是Spring Data的实现
- ?1 是占位符,需要和方法中所传递的参数顺序一致。从1开始
- @Query不支持insert操作
-
报错类问题
-
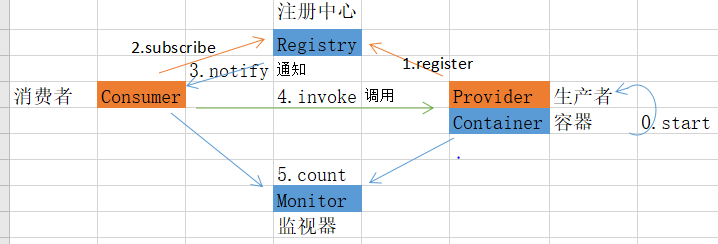
无效的源发行版:11和无效的目标发行版:11
- 产生原因:IDEA这里默认是11,我本地jdk装的1.8,如果不改就会出现下面的报错
![]()
-
解决方法
-
发布项目时报错:
Error:java:无效的源发行版:11
报错原因:
编译时的jdk版本与发布版本不符导致。检查下图几处版本是否一致。
- File→Project Structure→Project→Project SDK
- File→Project Structure→Modules
Error:java:无效的目标发行版:11
报错原因:
编译器中的jdk版本不符。- File→Settings→Build,Execution,Deployment→Java Complier
以上全部修改一致后,顺利发布。
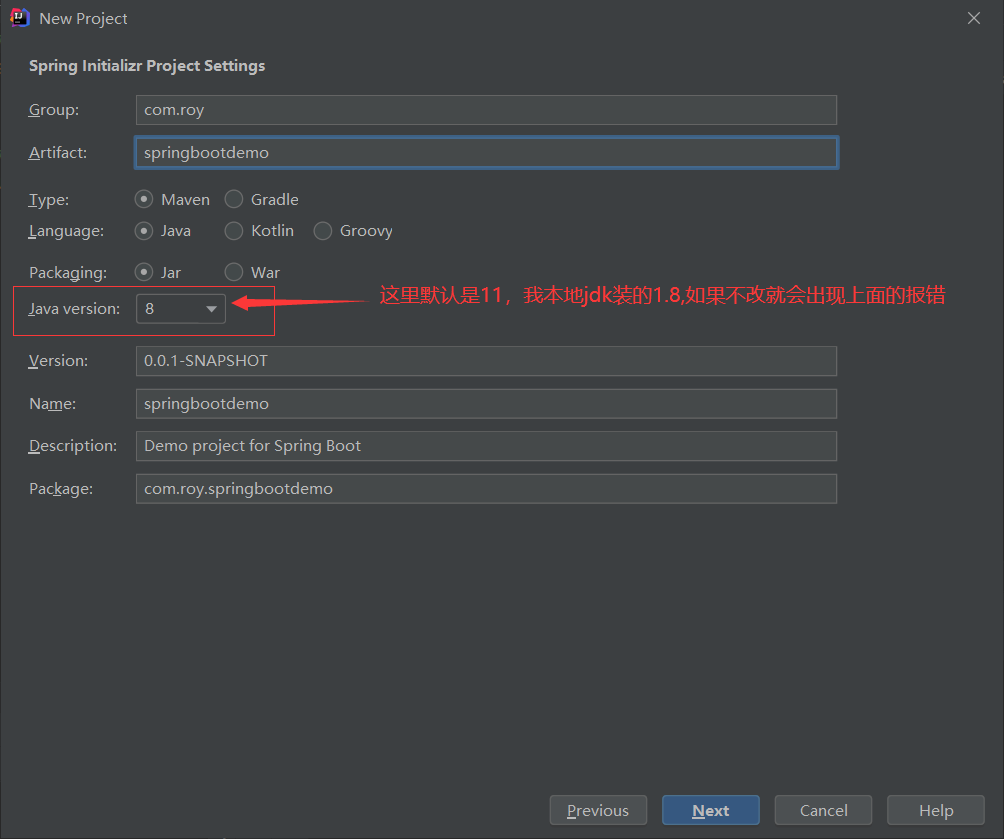
2. 解决Cannot resolve plugin org.apache.maven.plugins:maven-resources-plugin:3.2.0报错
- 解决方案一
- 先删除本地仓库D:\javapro\maven_jar里面的文件
- 执行maven的clean
- 选中爆红的文件,双击install,就可进行下载安装,如果没有成功则是网速不好,建议切换网络。
- 解决方案二
- 下载并将这两个文件直接放到maven_jar里
![]()
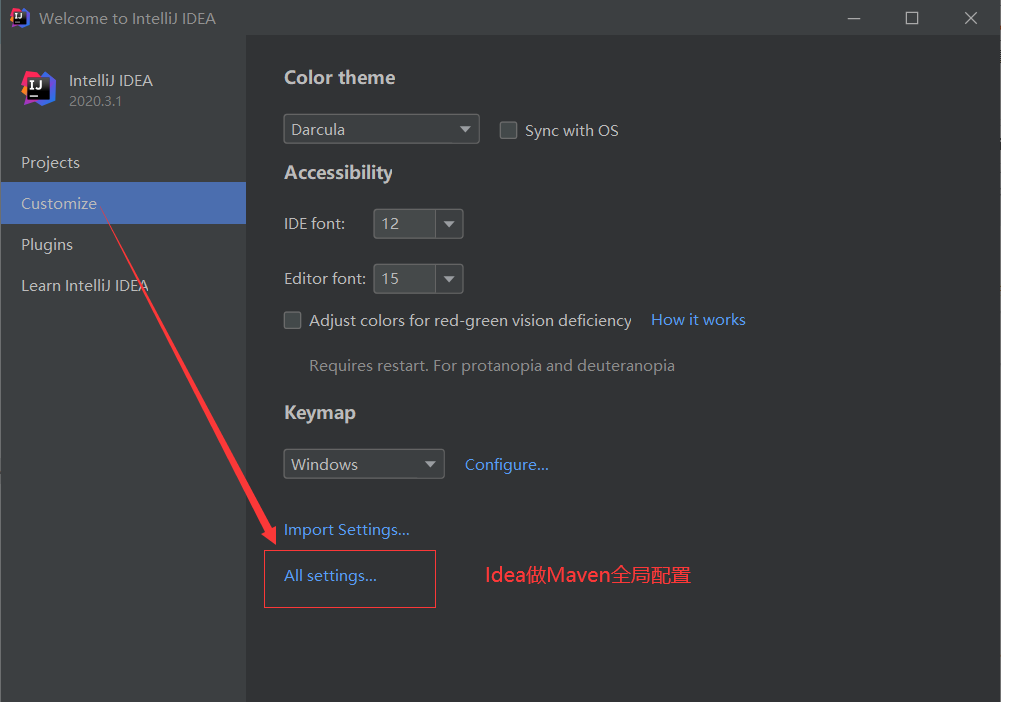
- 2020.3.1版本Idea中Maven全局配置

- Spring Boot的核心组件
- pom.xml:项目依赖
- Spring Boot框架需要的依赖主要有两个
- spring-boot-starter-web 此依赖包含的内容有:Spring的核心组件、Spring MVC、内置Web容器以及其他与Web开发相关的组件。
- spring-boot-starter-test 此依赖主要包含对一些测试框架的集成,比如JUint、AssertJ、Mockito、Hamcrest、JSONAssert和Spring Test等。
- spring-boot-starter-parent,此依赖主要包含对资源的过滤以及对插件的识别。在实际的开发过程中可以使用自己的父项目作为依赖来替代此依赖。
- Spring Boot框架需要的依赖主要有两个
- DemoApplication:Spring Boot项目的启动类
- 主要包含一个@SpringBootAppliaction注解和一个Spring Boot的核心类SpringApplication
- 其中@SpringBootApplication是一个组合注解,它主要组合了三个注解:
- @SpringBootConfiguration:此注解标注的类可以作为Spring Boot的配置类,相当于Spring 的xml配置文件,即Java配置的方式。
- @EnableAutoConfiguration:启动Spring Boot的自动配置。
- @ComponentScan:扫描与启动类同包或者级别较低的包中的类中的注解,并使其生效。
- 其中@SpringBootApplication是一个组合注解,它主要组合了三个注解:
- 主要包含一个@SpringBootAppliaction注解和一个Spring Boot的核心类SpringApplication
- application.yml文件:Spring Boot的文件配置
- DemoApplicationTests :Spring Boot项目默认生成的测试类,可以使用Spring Boot集成的测试框架进行功能测试。
- 整合MyBatis
- 第一步:创建Spring Boot项目后,打开pom.xml,添加2个依赖:mybatis-spring-boot-starter和mysql-connector-java
- 注意:resources文件需要在pom文件中添加配置,才能在Maven能够在指定的目录中找到mapper映射文件并进行打包。
- 第二步:在application.yml文件中配置数据源datasource
- 第三步:在application.yml文件中配置mapper映射文件
- 第四步:配置mapper接口的位置。第一种是使用@MapperScan注解标注mapper接口类所在的package;第二种是在mapper接口上使用@Mapper注解标注
- 第五步:编写mapper中的SQL映射语句,启动项目测试。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号