

sql刷题错题整理
牛客SQL专项练习
1.
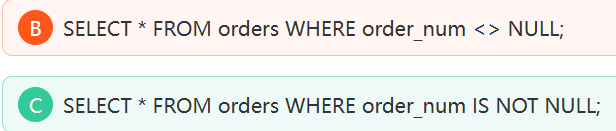
在MySQL中不能使用 = NULL 或 != NULL 等比较运算符在列中查找 NULL 值 。要用IS NULL 或 IS NOT NULL才会进行NULL值或非NULL值得查找。
2.

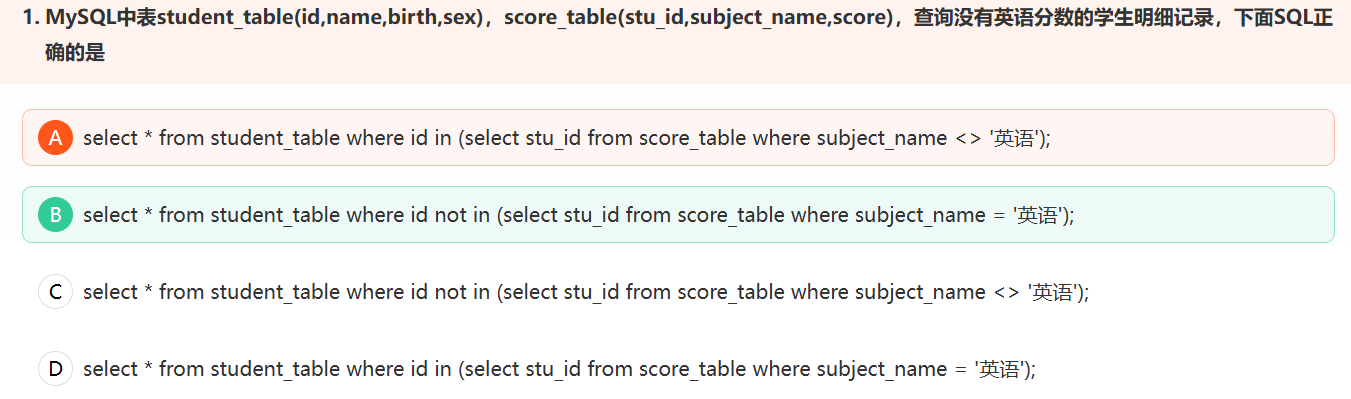
4.

此题考查数据库事务的原子性、一致性、隔离性和持久性。A选项,事务是最小的执行单位,不允许分割;B选项,执行事务前后,数据保持一致,对同一数据读取的结果相同;C选项,一个事务被提交后对数据库中数据的改变是持久的。
5.

外键字段(B选项):
外键字段经常用于表与表之间的连接查询。在外键字段上建立索引可以大大提高表连接操作的效率。是最常见的索引类型之一。
主键字段(C选项):
主键是表中记录的唯一标识。数据库会自动在主键上建立索引。主键索引可以加快基于主键的查询和表连接。
Where子句中的字段(D选项):
Where子句用于数据过滤,是查询优化的重点。经常出现在Where条件中的字段建立索引可以显著提升查询性能。特别是在大表中更能体现索引的价值
A选项错误原因:
Select子句中的字段主要用于结果集的显示。这些字段不参与查询条件的过滤和表的连接。在这些字段上建立索引对查询性能提升不明显。反而会增加插入和更新操作的开销。
6.

B选项,选取σ、投影π是专门的关系运算符;C选项,与∧、或∨是逻辑关系运算符;D选项,选取σ、投影π是专门的关系运算符,非¬是逻辑关系运算符。
7.

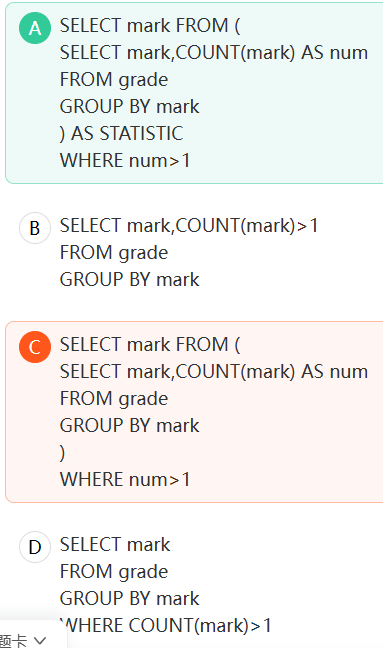
B选项,只是将所有数据出现的次数显示出来,不符题意;C选项,创建临时表的步骤中缺少“AS 临时表”这一部分;D选项,where子句不能与聚合函数一起使用。
解题思路: 从老表里按分数进行分组(group by)并统计count形成一张新表,AS STATISTIC就是建立一张临时的表。从新表里找num大于1的,并呈现它。
8.
+------+------+--------+
| id | name | weight |
+------+------+--------+
| 1 | A1 | 49 |
| 2 | A2 | 65 |
| 3 | B3 | 55 |
| 4 | T1 | 60 |
| 5 | G2 | 43 |
| 6 | C0 | 55 |
+------+------+--------+
还有一张比赛信息表(game),字段依次为:id、球员id、进球数目
+------+-----------+-------+
| id | person_id | count |
+------+-----------+-------+
| 1 | 3 | 10 |
| 2 | 1 | 24 |
| 3 | 6 | 9 |
| 4 | 1 | 2 |
| 5 | 2 | 11 |
| 6 | 5 | 23 |
| 7 | 3 | 15 |
| 8 | 2 | 16 |
| 9 | 4 | 5 |
| 10 | 1 | 3 |
+------+-----------+-------+
查找进球数超过25,体重小于50的球员信息:
select info.id,info.name,info.weight,sum(game.count) as total
from (game inner join info on game.person_id = info.id)
where info.weight < 50 group by info.name having sum(game.count) > 25;
看起来连接表的时候,大表放前面。
代码执行顺序:先执行join连接表。再执行where筛选资料。再group by对资料进行分组。然后是having对分组后的结果再做一次筛选。最后呈现属性。
思路是:想好要呈现什么属性,属性中会用聚合函数sum(),先把表连接起来。第一个容易筛选的条件先用where筛掉。一个基本的查找已经形成。前面用了聚合函数,后面用group分类。还有一个条件必须在聚合后才能筛选,后面再用having来补就行。
注意:1.group by需要写在where后面。写在前面则会报错。2.由于有聚合函数,所以必须要出现group by。对于聚合之后的结果的筛选则需要用having来筛选。3.不可以用别名列来作为聚合后的列名来进行筛选操作。上述代码中having后的筛选不是写total而是sum(game.count)。
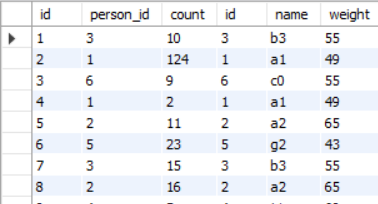
可以看到,大表放前面。对于符合连接条件的小表的数据会再次出现连接到大表后面。
9.有一张工资表salaries,示例数据如下:
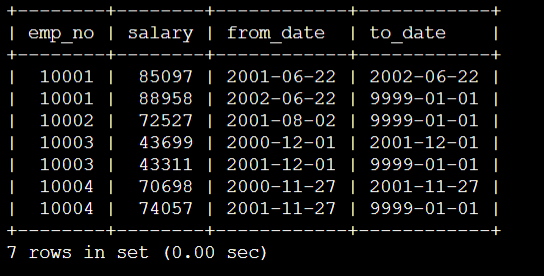

正确的MySQL查询语句是:
A.SELECT AVG(salary) AS avg_salary FROM salaries WHERE to_date = '9999-01-01' AND salary NOT IN (SELECT MAX(salary) FROM salaries) AND salary NOT IN (SELECT MIN(salary) FROM salaries);
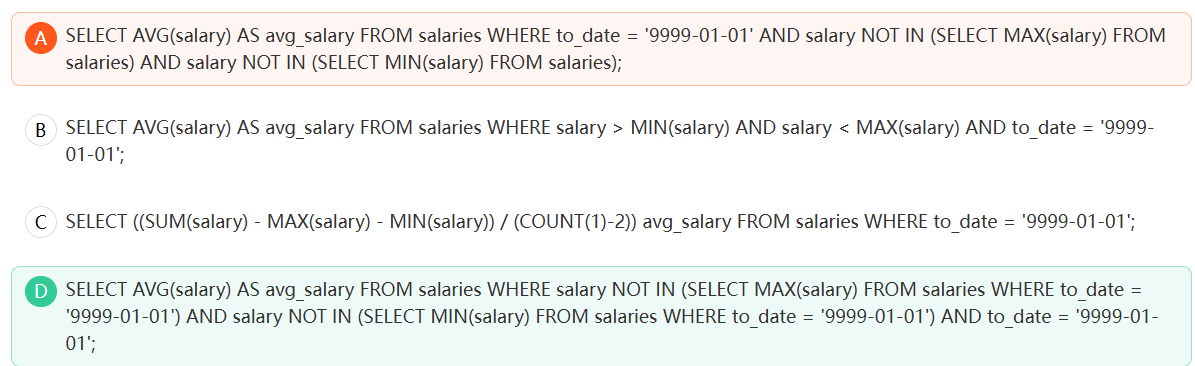
- 第一个是在职员工的筛选,必须是 to_date = '9999-01-01',这个条件同样要在最大最小的查询中使用;
- 第二个就是最大最小值可能不止一个,所以在计算个数的时候不一定是减2。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号