
Hadoop演进与Hadoop生态
1.了解对比Hadoop不同版本的特性,可以用图表的形式呈现。
Hadoop是一个能对大量数据进行分布式处理的软件框架,并且是以一种可靠、高效、可伸缩的方式进行处理的,它具有以下几个方面的特性。
·高可靠性
采用冗余数据存储方式,即使一个副本发生故障,其他副本也可以保证正常对外提供服务。
·高效性
作为并行分布式计算平台,Hadoop采用分布式存储和分布式处理两大核心技术,能够高效的处 理PB级数据。
·高可扩展性
Hadoop的设计目标是可以高效稳定地运行在廉价的计算机集群上,可以扩展到数以千计的计算 机节点上。
·高容错性
采用冗余数据存储方式,自动保存数据的多个副本,并且能够自动将失败的任务进行重新分配。
·成本低
Hadoop采用廉价的计算机集群,成本比较低,普通用户也很容易用自己的PC搭建Hadoop运 行环境。
·运行在Linux平台上
Hadoop是基于Java语言开发的,可以较好地运行在Linux平台上。
·支持多种编程语言
Hadoop上的应用程序也可以使用其他语言编写,如C++。
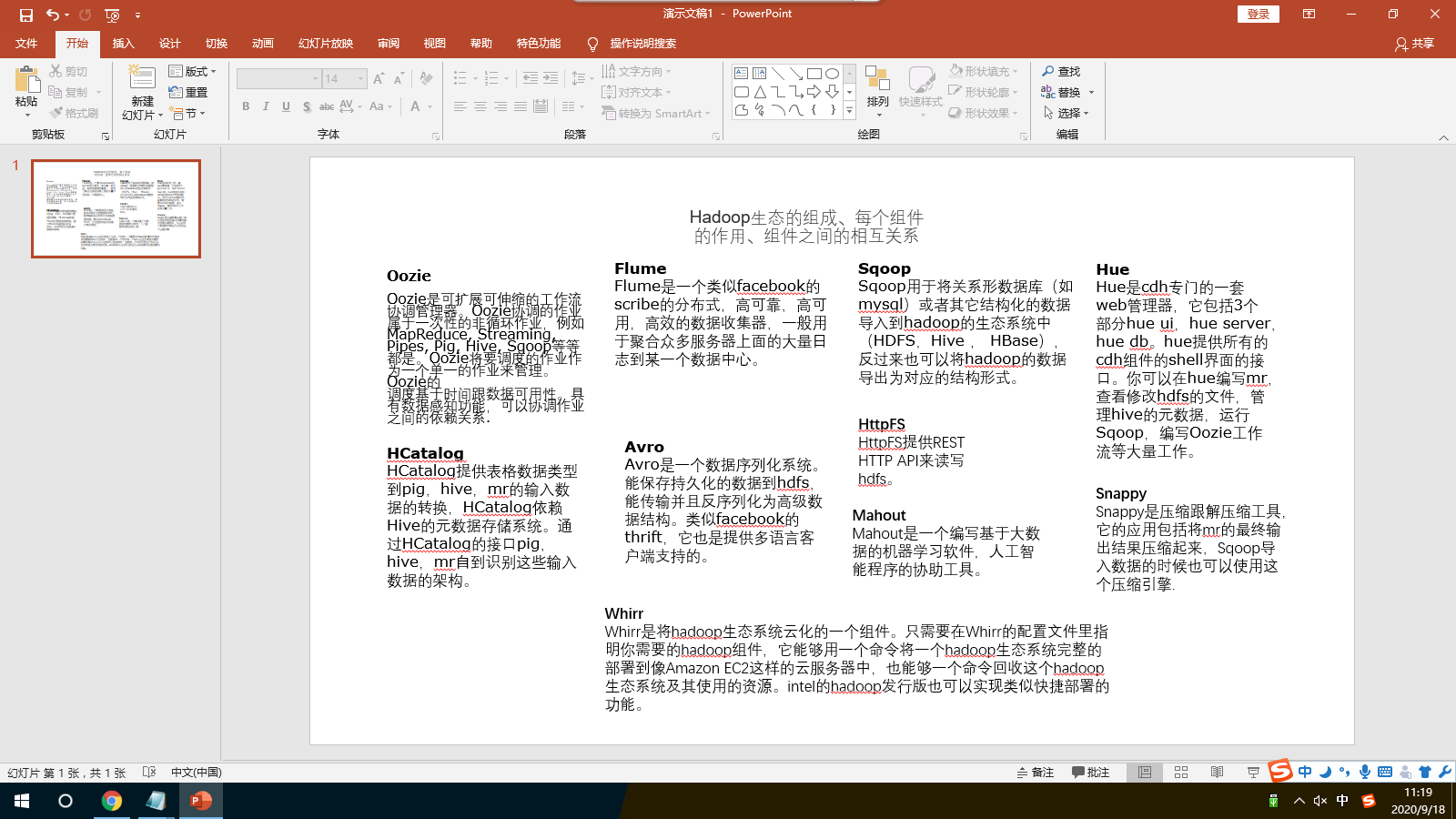
2.Hadoop生态的组成、每个组件的作用、组件之间的相互关系,以图例加文字描述呈现。
3.官网学习Hadoop的安装与使用,用文档的方式列出步骤与注意事项。
目的
本文档介绍了如何设置和配置单节点Hadoop安装,以便您可以使用Hadoop MapReduce和Hadoop分布式文件系统(HDFS)快速执行简单的操作。
先决条件
支持平台
支持GNU / Linux作为开发和生产平台。Hadoop在具有2000个节点的GNU / Linux集群上得到了证明。
Windows也是受支持的平台,但是以下步骤仅适用于Linux。要在Windows上设置Hadoop,请参见wiki页面。
必备软件
Linux所需的软件包括:
必须安装Java™。HadoopJavaVersions中描述了推荐的Java版本。
如果要使用可选的启动和停止脚本,则必须安装ssh并且必须运行sshd才能使用管理远程Hadoop守护程序的Hadoop脚本。另外,建议也安装pdsh以便更好地进行ssh资源管理。
安装软件
如果您的群集没有必需的软件,则需要安装它。
例如在Ubuntu Linux上:
$ sudo apt-get install ssh
$ sudo apt-get install pdsh
下载
要获得Hadoop发行版,请从Apache下载镜像之一下载最新的稳定版本。
准备启动Hadoop集群
解压缩下载的Hadoop发行版。在发行版中,编辑文件etc / hadoop / hadoop-env.sh以定义一些参数,如下所示:
#设置为Java安装的根目录
导出JAVA_HOME = / usr / java / latest
尝试以下命令:
$ bin / hadoop
这将显示hadoop脚本的用法文档。
现在,您可以以三种支持的模式之一启动Hadoop集群:
本地(独立)模式
伪分布式模式
全分布式模式
独立运行
默认情况下,Hadoop被配置为在非分布式模式下作为单个Java进程运行。这对于调试很有用。
下面的示例复制解压缩的conf目录以用作输入,然后查找并显示给定正则表达式的每个匹配项。输出被写入给定的输出目录。
$ mkdir输入
$ cp etc / hadoop / *。xml输入
$ bin / hadoop jar share / hadoop / mapreduce / hadoop-mapreduce-examples-3.2.1.jar grep输入输出'dfs [az。] +'
$ cat输出/ *

 浙公网安备 33010602011771号
浙公网安备 33010602011771号