

高性能计算基础
高性能计算基础
测试环境:Debian 12
编译器:gcc-15.1 clang++-18
1 性能评估指标和测试工具
1.1 关注性能的原因
2005年前后,单个CPU的计算能力达到饱和。与之相关的因素在于:
CPU核心频率停止增长。CPU核心频率受制于多种因素,重要因素之一就是功耗。如果CPU频率按照2005年前提升趋势保持不变,那么今天的CPU每平方毫米的功耗可能比将火箭送入太空的大型喷气发动机还要高。
然而,封装在单个芯片中晶体管数量一致在增长。在芯片无法提升到更高的频率情况下:
- 设计人员必须将多个处理器内核放在同一个芯片上,而不是让处理器变得更大。这些内核的计算能力会随着内核数量的增加而增加,前提是程序员知道如何恰当地使用它们。
- 更多的晶体管对处理器进行了各种非常先进的增强,这些增强可用于提高性能,同样要求程序员知道如何正确使用它们。
1.2 程序的性能
效率(Efficiency)和性能(performance)的区别:
- 高效的程序不会让可用的资源闲置。
- 高效的程序不会浪费资源左不必要的工作。
- 性能总是与一些指标有关。最常见的就是速度。
- 效率反映了计算资源的利用率,是实现良好性能的方式之一。
性能指标:
- 吞吐量(throughput)指标
- 功耗指标
- 实时应用性能(尾部延时 tail latency)
- 上下文环境
如何编写高性能应用程序:
- 选择正确的算法
- 有效利用CPU资源
- 有效使用内存
- 避免不必要的计算
- 有效地使用并发和多线程
- 有效地使用编程语言,避免低效率
- 衡量性能和解释结果
总体上可总结为:有效地使用硬件;有效地使用编程语言;有效地使用编译器来生成最高效代码;获取良好的量化性能数据。
1.3 性能基准测试
1.3.1 C++计时器
- std::chrono::system_clock
1.3.2 高分辨率计时器
- clock_gettime:要测量CPU时间,必须使用特定于操作系统的系统调用。在Linux和其他POSIX兼容系统上,开源使用clock_gettime()调用来访问硬件高分辨率计时器。
- 实时时钟:CLOCK_REALTIME
- 测量当前程序使用的CPU时间:CLOCK_PROCESS_CPUTIME_ID
- 测量调用线程使用的时间:CLOCK_THREAD_CPUTIME_ID
测试代码:
#include <chrono> #include <future> #include <iostream> #include <memory> #include <random> #include <vector> using std::chrono::duration_cast; using std::chrono::milliseconds; using std::chrono::system_clock; using std::cout; using std::endl; using std::minstd_rand; using std::unique_ptr; using std::vector; double duration(timespec a,timespec b) { return a.tv_sec-b.tv_sec+1e-9*(a.tv_nsec-b.tv_nsec); } int main() { timespec rt0,ct0,tt0; clock_gettime(CLOCK_REALTIME,&rt0); clock_gettime(CLOCK_PROCESS_CPUTIME_ID,&ct0); clock_gettime(CLOCK_THREAD_CPUTIME_ID,&tt0); constexpr double X =1e6; double s = 0; double s1 =0; //std::this_thread::sleep_for(std::chrono::seconds(1)); auto f = std::async(std::launch::async,[&]{ for(double x = 0; x<X; x+=0.1) { s+=sin(x); } }); for(double x =0;x<X;x+=0.1) s1 += sin(x); f.wait(); timespec rt1,ct1,tt1; clock_gettime(CLOCK_REALTIME,&rt1); clock_gettime(CLOCK_PROCESS_CPUTIME_ID,&ct1); clock_gettime(CLOCK_THREAD_CPUTIME_ID,&tt1); cout<<"Real time:"<<duration(rt1,rt0)<<"s, CPU time:"<<duration(ct1,ct0)<<"s, Thread time:"<<duration(tt1,tt0)<<"s"<<endl; return 0; }
1.4 性能分析
1.4.1 perf性能分析器
此性能分析器使用硬件性能计数器和基于时间采样,因此不需要对代码进行任何检测。运行该性能分析器最简单的方法是手机整个程序的计数器值。下图是用perf stat命令完成的。
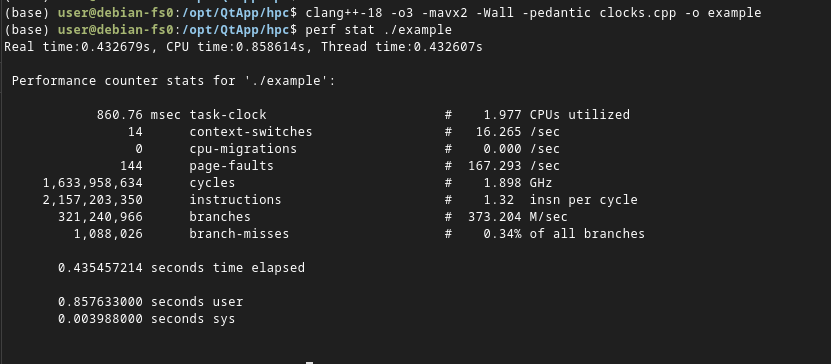
本示例中,程序运行860ms,并执行了超过21亿条指令(instruction)。还显示了page-faults(页面错误)和branches(分支)
也可以执行:
perf stat -e cycles,instructions,branches,branch-misses,cache-references,cache-misses ./example
输出:
Real time:0.522098s, CPU time:0.933204s, Thread time:0.411307s Performance counter stats for './example': 1,646,305,868 cycles 2,155,999,666 instructions # 1.31 insn per cycle 320,999,448 branches 1,070,837 branch-misses # 0.33% of all branches 66,777,267 cache-references 79,258 cache-misses # 0.119 % of all cache refs 0.524856154 seconds time elapsed 0.936146000 seconds user 0.000000000 seconds sys
- cycles:周期时间,为CPU频率的倒数。为了进行准确的性能分析和基础测试,建议禁用省电模式和其他可能导致CPU时间变化的功能。
- instruction:指令计数器,测量已执行的处理器指令数。该CPU每个周期平均执行1.31条指令。
- branches:分支,即条件指令,每个if语句和每个带条件的for循环都将至少生成这些指令之一。
- branch-misses:分支未命中,目前,从性能的角度来看,这是一个成本很高且不受欢迎的事件。
- cache-references:缓存引用,统计的是CPU从内存中获取某些数据所需的次数。
- cache-misses:根据处理器和内存的状态,这种获取可能非常快,也非常慢。对于非常慢的,计入cache-misses(缓存未命中)。缓存未命中也是一个成本很高的事件。
编译代码后:
clang++-18 -g -o3 -mavx2 -Wall -pedantic clocks.cpp -o example
可以使用perf record录制性能分析样本:
perf record ./example
然后使用perf report 分析样本
perf report
1.4.2 Google Performance性能分析器
安装:
sudo apt-get install google-perftools libgoogle-perftools-dev
Google CPU性能分析器可以使用硬件性能计数器,还需要代码的链接时检测。要准备用于性能分析的代码,必须将其与性能分析器库链接(-lprofiler)。编译指令如下:
clang++-18 -g -o3 -mavx2 -Wall -pedantic ./clocks.cpp -lprofiler -o example
获取分析数据:
CPUPROFILE=prof.data CPUPROFILE_FREQUENCY=1000 ./example
采样交互模式使用性能分析器:
google-pprof ./example prof.data
输出:
sing local file ./example. Using local file prof.data. Welcome to pprof! For help, type 'help'. (pprof) text Total: 160 samples 50 31.2% 31.2% 116 72.5% main 30 18.8% 50.0% 30 18.8% do_sin 24 15.0% 65.0% 24 15.0% reduce_sincos 18 11.2% 76.2% 18 11.2% do_cos 14 8.8% 85.0% 44 27.5% main::$_0::operator 13 8.1% 93.1% 13 8.1% __sin_fma 7 4.4% 97.5% 7 4.4% libc_feholdsetround_sse_ctx 3 1.9% 99.4% 3 1.9% do_sincos 1 0.6% 100.0% 1 0.6% libc_feresetround_sse_ctx 0 0.0% 100.0% 44 27.5% __gthread_once (pprof)
查看用执行时间百分比注释的所有函数的摘要信息:
(pprof) text --lines Total: 160 samples 33 20.6% 20.6% 99 61.9% main /opt/QtApp/hpc/./clocks.cpp:41 17 10.6% 31.2% 17 10.6% main /opt/QtApp/hpc/./clocks.cpp:40 9 5.6% 36.9% 39 24.4% main::$_0::operator /opt/QtApp/hpc/./clocks.cpp:36 8 5.0% 41.9% 8 5.0% do_sin ./math/../sysdeps/ieee754/dbl-64/s_sin.c:144 7 4.4% 46.2% 7 4.4% libc_feholdsetround_sse_ctx ./math/../sysdeps/x86/fpu/fenv_private.h:416 7 4.4% 50.6% 7 4.4% reduce_sincos ./math/../sysdeps/ieee754/dbl-64/s_sin.c:165 6 3.8% 54.4% 6 3.8% do_sin ./math/../sysdeps/ieee754/dbl-64/s_sin.c:129 5 3.1% 57.5% 5 3.1% __sin_fma ./math/../sysdeps/x86_64/fpu/multiarch/s_sin-fma.c:201 5 3.1% 60.6% 5 3.1% do_cos ./math/../sysdeps/ieee754/dbl-64/s_sin.c:114 5 3.1% 63.8% 5 3.1% main::$_0::operator /opt/QtApp/hpc/./clocks.cpp:34 (pprof)
性能分析器通常使用调用图(call graph)来呈现此信息:调用方(caller)和被调用方(callee)是图中的节点。在这个图中我们可以了解在每个函数和代码行上执行了多少时间,还可以知道每个调用链花了多少时间。
google-pprof --pdf ./example prof.data >prof.pdf
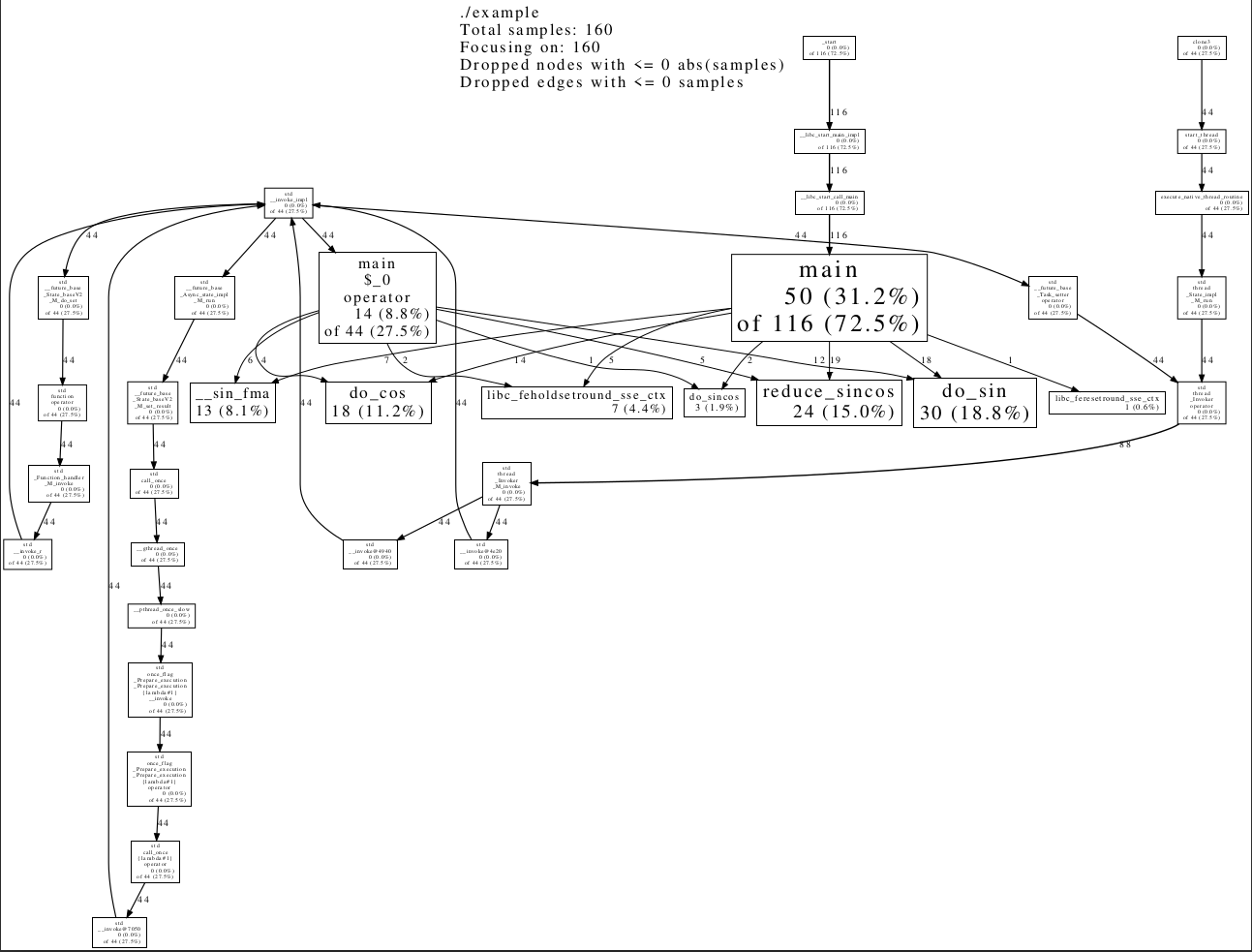
1.4.3 收集性能数据的方法(微基准测试)
- 微基准测试的基础知识:微基准测试 (micro-benchmark)一种对函数进行调用并测量结果,也就是运行一小段代码并测量其性能。
- 微基准测试工具:Google Benchmark。
Google Benchmark安装:
sudo apt install libbenchmark-dev
Google Benchmark用法:
#include <benchmark/benchmark.h> #include <string> #include <sstream> #include <vector> #include <cmath> // 示例1:测试不同的字符串拼接方法 static void BM_StringPlusOperator(benchmark::State& state) { for (auto _ : state) { std::string result; for (int i = 0; i < state.range(0); ++i) { result += "hello"; } benchmark::DoNotOptimize(result); } } // 正确的参数设置方式 BENCHMARK(BM_StringPlusOperator)->RangeMultiplier(2)->Range(1, 1024); static void BM_StringAppend(benchmark::State& state) { for (auto _ : state) { std::string result; for (int i = 0; i < state.range(0); ++i) { result.append("hello"); } benchmark::DoNotOptimize(result); } } BENCHMARK(BM_StringAppend)->RangeMultiplier(2)->Range(1, 1024); static void BM_StringStream(benchmark::State& state) { for (auto _ : state) { std::stringstream ss; for (int i = 0; i < state.range(0); ++i) { ss << "hello"; } std::string result = ss.str(); benchmark::DoNotOptimize(result); } } BENCHMARK(BM_StringStream)->RangeMultiplier(2)->Range(1, 1024); // 示例2:测试向量操作性能 static void BM_VectorPushBack(benchmark::State& state) { for (auto _ : state) { std::vector<int> vec; vec.reserve(state.range(0)); for (int i = 0; i < state.range(0); ++i) { vec.push_back(i); } benchmark::DoNotOptimize(vec); } } BENCHMARK(BM_VectorPushBack)->RangeMultiplier(2)->Range(8, 1024); static void BM_VectorEmplaceBack(benchmark::State& state) { for (auto _ : state) { std::vector<int> vec; vec.reserve(state.range(0)); for (int i = 0; i < state.range(0); ++i) { vec.emplace_back(i); } benchmark::DoNotOptimize(vec); } } BENCHMARK(BM_VectorEmplaceBack)->RangeMultiplier(2)->Range(8, 1024); // 示例3:带有复杂计算的测试 static void BM_ComplexCalculation(benchmark::State& state) { const int size = state.range(0); std::vector<double> data(size); for (int i = 0; i < size; ++i) { data[i] = i * 0.1; } for (auto _ : state) { double sum = 0.0; for (int i = 0; i < size; ++i) { sum += std::sin(data[i]) * std::cos(data[i]); } benchmark::DoNotOptimize(sum); } } BENCHMARK(BM_ComplexCalculation)->RangeMultiplier(4)->Range(64, 4096); // 示例4:使用自定义计数器 static void BM_MatrixMultiplication(benchmark::State& state) { const int n = state.range(0); for (auto _ : state) { // 简化版的矩阵乘法,避免大量内存分配影响测试结果 double sum = 0.0; for (int i = 0; i < n; ++i) { for (int j = 0; j < n; ++j) { for (int k = 0; k < n; ++k) { sum += i * k + j * k; // 模拟计算 } } } benchmark::DoNotOptimize(sum); // 正确的计数器设置方式 state.counters["FLOPs"] = benchmark::Counter( static_cast<double>(2 * n * n * n), benchmark::Counter::kIsRate ); state.counters["MatrixSize"] = n; } } // 使用ArgsProduct测试多个参数组合 BENCHMARK(BM_MatrixMultiplication)->Args({10})->Args({20})->Args({30}); // 示例5:简单的循环测试(无参数) static void BM_EmptyLoop(benchmark::State& state) { for (auto _ : state) { // 空循环,测试基准开销 } } BENCHMARK(BM_EmptyLoop); // 示例6:内存访问模式测试 static void BM_MemoryAccess(benchmark::State& state) { const int size = state.range(0); std::vector<int> data(size, 1); for (auto _ : state) { int sum = 0; // 顺序访问 for (int i = 0; i < size; ++i) { sum += data[i]; } benchmark::DoNotOptimize(sum); } } BENCHMARK(BM_MemoryAccess)->Arg(1000)->Arg(10000)->Arg(100000); // 示例7:使用模板的基准测试 template<typename T> static void BM_TemplateTest(benchmark::State& state) { for (auto _ : state) { T result = T(); for (int i = 0; i < state.range(0); ++i) { result += static_cast<T>(i); } benchmark::DoNotOptimize(result); } } // 注册模板测试 BENCHMARK_TEMPLATE(BM_TemplateTest, int)->Range(1, 1000); BENCHMARK_TEMPLATE(BM_TemplateTest, double)->Range(1, 1000); BENCHMARK_TEMPLATE(BM_TemplateTest, float)->Range(1, 1000); BENCHMARK_MAIN();
编译:
clang++-18 -O3 -I/usr/local/include -L/usr/local/lib ./test_benchmark.cpp -lbenchmark -lpthread -o benchmark_example
如果能看到输出的性能测试结果,就说明 Google Benchmark 库已经成功安装并可以正常工作了:
./benchmark_example 2025-09-23T23:12:40-10:00 Running ./benchmark_example Run on (4 X 3900 MHz CPU s) CPU Caches: L1 Data 32 KiB (x4) L1 Instruction 32 KiB (x4) L2 Unified 256 KiB (x4) L3 Unified 6144 KiB (x1) Load Average: 0.12, 0.44, 0.45 ***WARNING*** CPU scaling is enabled, the benchmark real time measurements may be noisy and will incur extra overhead. ***WARNING*** Library was built as DEBUG. Timings may be affected. ----------------------------------------------------------------------- Benchmark Time CPU Iterations ----------------------------------------------------------------------- BM_StringPlusOperator/1 14.8 ns 14.8 ns 41141692 BM_StringPlusOperator/2 23.5 ns 23.5 ns 27457916 BM_StringPlusOperator/4 75.6 ns 75.6 ns 8516886 BM_StringPlusOperator/8 133 ns 133 ns 4835163 BM_StringPlusOperator/16 228 ns 228 ns 2924758 BM_StringPlusOperator/32 368 ns 368 ns 1816380 BM_StringPlusOperator/64 700 ns 700 ns 905954 BM_StringPlusOperator/128 1245 ns 1245 ns 525369 BM_StringPlusOperator/256 2319 ns 2318 ns 291399 BM_StringPlusOperator/512 4341 ns 4341 ns 159391 BM_StringPlusOperator/1024 8428 ns 8428 ns 77097 BM_StringAppend/1 10.8 ns 10.8 ns 62091856 BM_StringAppend/2 18.6 ns 18.6 ns 36557304 BM_StringAppend/4 67.9 ns 67.9 ns 9695255 BM_StringAppend/8 126 ns 126 ns 5336449 BM_StringAppend/16 214 ns 214 ns 3143867 BM_StringAppend/32 379 ns 379 ns 1824693 BM_StringAppend/64 681 ns 681 ns 935922 BM_StringAppend/128 1202 ns 1202 ns 549609
1.4.4 案例解析
- 测试代码
#include <benchmark/benchmark.h> #include <memory> #include <cstring> bool compare_int(const char* s1,const char* s2) { char c1,c2; for(int i1=0,i2=0;;++i1,++i2) { c1=s1[i1];c2=s2[i2]; if(c1!=c2) return c1>c2; } } void BM_loop_int(benchmark::State& state) { const unsigned int N = state.range(0); std::unique_ptr<char[]>s(new char[2*N]); ::memset(s.get(),'a',2*N*sizeof(char)); s[2*N-1] =0; const char* s1 = s.get(),*s2=s1+N; for(auto _:state){ benchmark::DoNotOptimize(compare_int(s1,s2)); } state.SetItemsProcessed(N*state.iterations()); } BENCHMARK(BM_loop_int)->Arg(1<<20); BENCHMARK_MAIN();
- 编译指令:
clang++-18 -g -O3 -mavx2 -Wall -pedantic -I/usr/local/include -L/usr/local/lib ./10_compare_mbm.cpp -lbenchmark -lpthread -lrt -lm -o 10_compare_mbm
- 输出:
./10_compare_mbm 2025-09-23T23:31:56-10:00 Running ./10_compare_mbm Run on (4 X 3900 MHz CPU s) CPU Caches: L1 Data 32 KiB (x4) L1 Instruction 32 KiB (x4) L2 Unified 256 KiB (x4) L3 Unified 6144 KiB (x1) Load Average: 0.06, 0.68, 0.72 ***WARNING*** CPU scaling is enabled, the benchmark real time measurements may be noisy and will incur extra overhead. ***WARNING*** Library was built as DEBUG. Timings may be affected. ------------------------------------------------------------------------------ Benchmark Time CPU Iterations UserCounters... ------------------------------------------------------------------------------ BM_loop_int/1048576 641864 ns 641837 ns 1055 items_per_second=1.63371G/s
- 解析:
每个Google Benchmark基准测试程序都必须包含该库头文件<benchmark/benchmark.h>。BM_loop_int首先设置运行代码的输入数据,本示例中,代码的输入是字符串,所以需要分配和初始化字符串。函数退出时要清理初始化数据,本例中使用std::unique_ptr对象的析构函数执行。
BENCHMARK指定要传递给基准测试fixture的任何参数的地方。影响基准测试的参数和其他选项将使用重载的箭头运算符传递。
代码清单中没有main函数,而是使用宏BENCHMARK_MAIN()。用来完成设置基准测试环境、注册基准测试和执行它们所有必要的工作。
benchmark::DoNotOptimize()包装函数的作用类似使用volatile,用于确保编译器不会优化对compare_int()的整个调用。实际上并没关闭任何优化,特别是括号里面的代码照常优化。
编译时需要指定Google Benchmark 头文件和库文件路,Google Benchmark库libbenchmark库以及若干额外的库。
一旦被调用,基准测试程序会打印关于正在运行的系统的信息,然后执行每个已注册的fixture。
每个基准测试fixture和一组参数都将得到一行输出。该报告包括基准测试循环主体单次执行的平均实时时间和平均CPU时间、循环执行次数以及附加到报告中的让其他统计信息(本例中时比较函数每秒处理的字符数,每个超过1.6G个字符)。
这些数据在每次运行中相差多少,如果使用正确的命令行参数启用统计信息收集,则基准测试库可以为我们计算出结果。例如,每重复基准测试10次并报告结果,则运行的基准测试将如下所示:
./10_compare_mbm --benchmark_repetitions=10 --benchmark_report_aggregates_only=true 2025-09-24T00:04:08-10:00 Running ./10_compare_mbm Run on (4 X 3900 MHz CPU s) CPU Caches: L1 Data 32 KiB (x4) L1 Instruction 32 KiB (x4) L2 Unified 256 KiB (x4) L3 Unified 6144 KiB (x1) Load Average: 0.06, 0.03, 0.09 ***WARNING*** CPU scaling is enabled, the benchmark real time measurements may be noisy and will incur extra overhead. ***WARNING*** Library was built as DEBUG. Timings may be affected. ------------------------------------------------------------------------------------- Benchmark Time CPU Iterations UserCounters... ------------------------------------------------------------------------------------- BM_loop_int/1048576_mean 485082 ns 485056 ns 10 items_per_second=2.18225G/s BM_loop_int/1048576_median 458741 ns 458722 ns 10 items_per_second=2.28596G/s BM_loop_int/1048576_stddev 52421 ns 52414 ns 10 items_per_second=211.207M/s BM_loop_int/1048576_cv 10.81 % 10.81 % 10 items_per_second=9.68%
如此,我们可以对子串比较函数的不同变体进行基准测试,并找出哪个变体最快。
2 CPU流水线、推测窒息和分支优化
2.1 指令级并行(ILP, instruction-level parallelism)
只要操作数已经在寄存器中,处理器就可以一次执行若干个操作。当然,可以执行的操作数量是有限的,因为处理器能够进行整数计算的执行单元有限。尽管如此,通过在一次迭代中添加越来越多的指令来尝试将CPU推向极限是有益的。
如下两个迭代执行时间是差不多的:
//迭代一 for(size_t i =0;i<N;++i) { a1 +=p1[i]+p2[i]; } //迭代二 for(size_t i =0;i<N;++i) { a1 +=p1[i]+p2[i]; a2 +=p1[i]*p2[i]; a3 +=p1[i]<<2; a4 +=p2[i]-p1[i]; a5 +=(p2[i]<<2)*p2[i]; a6 +=(p2[i]-3)*p1[i]; }
测试代码如下:
#include <benchmark/benchmark.h> #include <vector> void BM_add(benchmark::State& state) { srand(1); const unsigned int N = state.range(0); std::vector<unsigned long> v1(N),v2(N); for(size_t i=0;i<N;++i) { v1[i]=rand(); v2[i]=rand(); } unsigned long* p1= v1.data(); unsigned long* p2 = v2.data(); for([[maybe_unused]]auto _:state) { unsigned long a1 =0; for(size_t i =0;i<N;++i) { a1 +=p1[i]+p2[i]; } benchmark::DoNotOptimize(a1); benchmark::ClobberMemory(); } state.SetItemsProcessed(N*state.iterations()); } void BM_ILP(benchmark::State& state) { srand(1); const unsigned int N = state.range(0); std::vector<unsigned long> v1(N),v2(N); for(size_t i=0;i<N;++i) { v1[i]=rand(); v2[i]=rand(); } unsigned long* p1= v1.data(); unsigned long* p2 = v2.data(); for([[maybe_unused]]auto _:state) { unsigned long a1 =0,a2=0,a3=0,a4=0,a5=0,a6=0; for(size_t i =0;i<N;++i) { a1 +=p1[i]+p2[i]; a2 +=p1[i]*p2[i]; a3 +=p1[i]<<2; a4 +=p2[i]-p1[i]; a5 +=(p2[i]<<2)*p2[i]; a6 +=(p2[i]-3)*p1[i]; } benchmark::DoNotOptimize(a1); benchmark::DoNotOptimize(a2); benchmark::DoNotOptimize(a3); benchmark::DoNotOptimize(a4); benchmark::DoNotOptimize(a5); benchmark::DoNotOptimize(a6); benchmark::ClobberMemory(); } state.SetItemsProcessed(N*state.iterations()); } void BM_mutiply(benchmark::State& state) { srand(1); const unsigned int N = state.range(0); std::vector<unsigned long> v1(N),v2(N); for(size_t i=0;i<N;++i) { v1[i]=rand(); v2[i]=rand(); } unsigned long* p1= v1.data(); unsigned long* p2 = v2.data(); for([[maybe_unused]]auto _:state) { unsigned long a1 =0; for(size_t i =0;i<N;++i) { a1 +=p1[i]*p2[i]; } benchmark::DoNotOptimize(a1); benchmark::ClobberMemory(); } state.SetItemsProcessed(N*state.iterations()); } BENCHMARK(BM_add)->Arg(1<<22); BENCHMARK(BM_ILP)->Arg(1<<22); BENCHMARK(BM_mutiply)->Arg(1<<22); BENCHMARK_MAIN();
输出:
./superscalar 2025-09-24T19:48:37-10:00 Running ./superscalar Run on (4 X 3900 MHz CPU s) CPU Caches: L1 Data 32 KiB (x4) L1 Instruction 32 KiB (x4) L2 Unified 256 KiB (x4) L3 Unified 6144 KiB (x1) Load Average: 0.01, 0.08, 0.18 ***WARNING*** CPU scaling is enabled, the benchmark real time measurements may be noisy and will incur extra overhead. ***WARNING*** Library was built as DEBUG. Timings may be affected. ----------------------------------------------------------------------------- Benchmark Time CPU Iterations UserCounters... ----------------------------------------------------------------------------- BM_add/4194304 5793066 ns 5792942 ns 100 items_per_second=724.037M/s BM_ILP/4194304 8123805 ns 8122965 ns 88 items_per_second=516.351M/s BM_mutiply/4194304 5256256 ns 5256241 ns 100 items_per_second=797.966M/s
3 现代内存架构、访问模式以及对算法和数据结构设计的影响
4 多线程和并发工作原理
5 锁、无锁和无等待及并发数据结构的基础知识
5.1 锁
5.2 无锁
5.3 无等待
5.4 并发数据结构基础知识
使用多线程的并发程序需要线程安全的数据结构。线程安全的数据结构是指:如果一个数据结构可以被多个线程同时使用而且没有任何数据竞争(线程之间共享),那么它就是线程安全的:
- 把标准抬的很高,例如:没有一个STL容器被认为是线程安全的。
- 带来的性能成本非常高。
- 通常是不必要的,没必要因此多花成本。
- 最重要的是,在许多情况下完全用不上
对象被一个线程单独占用时不需要线程安全。
只要线程不修改对象,那么许多数据结构在多线程代码中使用是安全的。用例:std::shared_ptr,当复制共享指针时,复制的对象不会被修改,它通过const应用被传递给新指针的构造函数,同时对象中的引用计数必须递增。意味着复制的来源发送了变化。在这种情况下共享指针是线程安全的,但也有性能成本。
线程安全的最高级别通常称为强线程安全保证(strong thread safety guarantee):提供此保证的对象可以被多个线程并发使用而不会导致数据竞争或其他未定义行为。
下一个级别称为弱线程安全保证(weak thread safety guarantee):意味着,首先,只要所有线程都被限制为只读访问(调用类的const成员函数),那么提供该保证的对象就可以同时被多个线程访问。其次,人后线程只要可以独占访问一个对象,即可对其执行任何有效操作,而不管其他线程同时在做什么。
- 线程安全(thread-safe):提供强线程安全保证的类称为线程安全(thread-safe)。
- 线程兼容(thread compatible):仅提供弱线程保证的类被称为线程兼容(thread compatible)。大多数STL容器提供这样的保证:如果某个容器是一个线程本地容器,则可以安任何有效方式使用它;如果某个容器对象是共享的,则只能调用const成员函数。
- 线程对立(thread-hostile):根本不提供任何保证的类被称为线程对立(thread-hostile)。
6 线程安全的数据结构(并发数据结构)
6.1 最好的线性安全性
最好的解决方案是在每个线程上维护本地计数并且只增加共享计数一次。
对比如下伪代码(注:第二种写法由于第一种):
写法一:
std::atomic<unsigned log> count; //在某个线程上 for(...counting loop...) { if(...found...) { count.fetch_add(1,std::memory_order_relaxed); } }
写法二:
unsigned long count; std::mutex M; //在某个线程上 unsigned long local_count =0; for(...counting loop...) { if(...found...) { ++local_count; } } std::lock_guard<std::mutex> L(M); count +=local_count;
6.2 线程安全栈
C++标准库提供了std::stack容器。所有的C++容器都提供弱线程安全保证:一个只读容器可以被多个线程安全访问。也就是只要没有线程调用任何非const方法,任何数量的线程都可以同时调用任何const方法。
当至少有一个线程正在修改占,而我们需要更强的保证。最直接的方法是利用互斥锁保护类的每个成员函数。这可以在应用程序级别完成,但这种实现不强制线程安全,容易出错,也难于调试,因为锁与容器无关联。
所以,更好的选择就是使用我们自己的栈类包装。
#include <stack> #include <mutex> #include <optional> #include <benchmark/benchmark.h> template<typename T> class mt_stack{ private: std::stack<T> s_; std::mutex l_; public: mt_stack() = default; std::optional<T> pop() { std::lock_guard g(l_); if(s_.empty()) { return std::optional<T>(std::nullopt); }else{ std::optional<T> res(std::move(s_.top())); s_.pop(); return res; } } void push(const T& v) { std::lock_guard g(l_); s_.push(v); } };
7 C++标准中的并发编程特性
8 零拷贝
9 编译器优化基础知识
10 高性能编程设计总结

 浙公网安备 33010602011771号
浙公网安备 33010602011771号