
实现CGI版本的HTTP服务器
一、通用的HTTP框架:
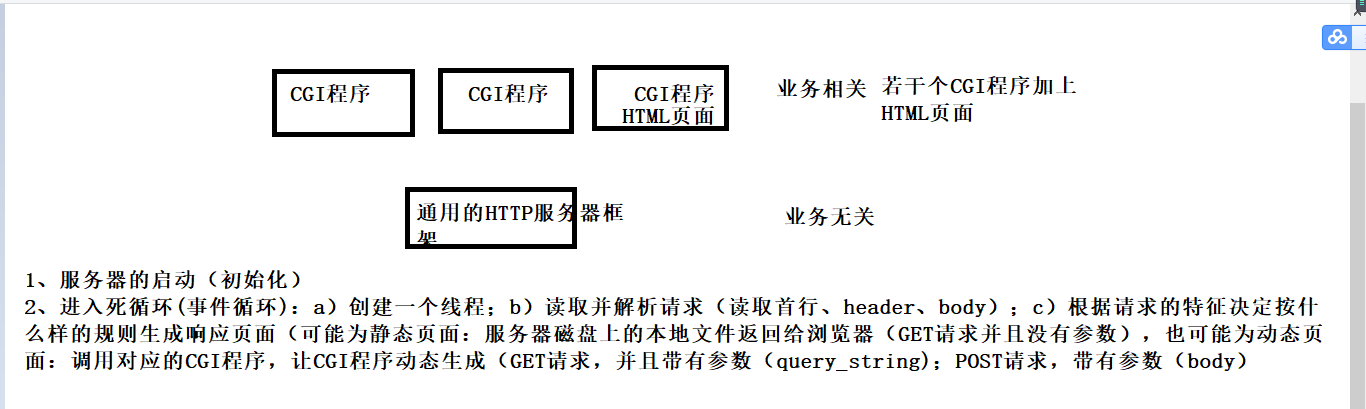
通用的HTTP服务器框架,基于TCP api,读取socket api;按照HTTP协议的格式要求,对收到的数据进行解析,生成响应数据。和具体业务无关,基于这样一个通用的服务器框架进行二次开发。

(一)流程:
1、读取并解析请求(标准的HTTP协议的请求)
HTTP协议格式(可以通过抓包工具抓取): HTTP请求是一个纯文本的协议,按照行分割。行文本的数据构成的整体的请求。a、首行用空格分割为“方法 url 版本号”。初始化完成后,可以通过换行分割取出第一行,再按照空格分割,把首行分为三个部分:方法、url、版本号,把字符串转换为一个对象(反序列化)。b、解析完首行后, 解析若干行header:header按行分割、每一行为一个具体的header项,每一行里面是一个键值对,键值对之间用冒号进行分割。按行读取数据,按冒号分割,解析出header中的key和value,key和value按照二叉搜索树或者哈希表的方式存储。存储后,可以方便的取到每一个header对应的value值。结束标志:空行。【循环的按行读取,每读完一条数据,按行解析后,读取下一行,直到读到空行,header结束。】。c、对于body部分:get请求没有body,不用处理,直接结束。如果是post请求body还会包含若干个字符串,直接对body进行读取,读取多长取决于post请求的header部分的content_length(描述了body占多少个字节),按照这些字节数进行读取。
HTTP中get方法和post方法的区别:a、get方法没有body,而post方法是有body的。2、content_length可以计算body的大小。
2、根据请求计算响应(根据收到的HTTP请求构造HTTP响应)
(1)返回一个静态页面:a、根据url找到磁盘上的文件 b、打开文件,读取文件内容,作为http响应的body

(2)返回一个动态生成页面:随着请求过程中传递的参数不同,得到的结果也有所差异。搜索结果页是动态生成的,搜索两个不同的参数,get请求带有的参数不同,导致生成的页面不同,页面的格式是差不多的,但是页面的内容会随着参数的变化而不同。【方案很多:CGI(通用网关接口):CGI可以理解为一种协议或者标准,能够使用一种通用的方式动态生成页面:a、创建一对匿名管道(进行双向通信,一个管道只能单向通信);
b、创建子进程;
c、对于子进程来说:1‘、设定若干的环境变量(传递请求、方法、content_length以及query_string(get请求中url最后的参数));2’、进行重定向(把标准输入、标准输出重定向到管道上;再尝试写数据到标准输出,并没有写到标准输出上,而是写到了管道上。从标准输入读数据是从管道读,而不是键盘)3‘、进程程序替换(服务器磁盘上对应的CGI程序)CGI程序就完成具体的页面生成的动作,负责动态生成页面,不同的场景下,生成动态页面的规则不同,CGI程序也就不一样。替换之后子进程就去执行另外一个程序,cgi程序通过标准输入读取到需要的信息,把生成的页面通过标准输出来返回。【cgi最大的优点就是“解耦和”(通用)(按照cgi的标准进行开发,把底层的框架和上层的cji业务程序分开,可以很好 的配合)a、通用的http服务器框架和cgi程序解耦和;b、cgi程序只要能访问标准输入、标准输出、环境变量即可,减低了开发网站的门槛,让cgi程序可以使用任何编程语言来实现(只要该语言可以从标准输入或标准输出读写数据就可以是一个CGI程序)】【cgi的缺点:要求收到一个请求就要创建一个子进程,开销大、成本高、性能比较差;当请求很多时,可能造成卡顿或者崩溃。】
d、对于父进程来说:1’、把http请求的body部分写到管道中; 2‘、进程等待(等待子进程结束,并且对子进程进行回收)

main函数中进行简单的判定(参数校验),然后调用初始化函数,在初始化函数里面使用线程创建函数,在线程入口函数中调用HandlerRequest函数完成具体的请求过程(1、读取并解析请求(反序列化)(此处定义一个结构体http_server.h描述对象;2、静/动态方式生成页面;3、把生成结果写会到客户端);在HandlerRequest函数添加一个读取首行的操作ReadLine函数……
3、把响应写会客户端(得到的HTTP响应字符串写回到客户端),每次请求传递的参数不同,根据不同的参数计算结果也就不同。
HTTP响应的格式:纯文本的,按照行分割。构造一个响应时:a、构造首行“版本号 状态码 状态码描述符”b、若干行header,以键值对的方式组织,每个header占一行,若干个header后以空行结尾。c、body部分:html格式
把变量定义到一个结构体中,放在一个头文件里:
Request结构体:把空格和问号替换\0

在返回404错误页面中,用html标签构造body部分
3、验证结果:
(1)运行服务器端的代码(make)后启动服务器(./http_server 0 9090)
(2)开启另一个窗口,通过netstat -anp | grep 9090,查看进程的信息

通过上面的结果可以发现这是一个listen状态,协议是tcp。
关闭防火墙:切换到root用户:service firewalld stop
(3)通过浏览器访问服务器:http://ip地址/9090
首先浏览器给服务器发送了一个http请求,把index.html打开,把内容读出来
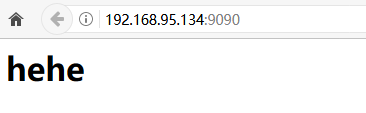
在这个程序编译过程中我们遇到了一些问题:比如
a、浏览器访问时输出的是乱码:在gdk下一个汉字两个字节;在utf-8下是不确定的,utf-8是变长编码【urlencode和urldecode】:即需要统一所有的编码格式【在末行模式下输入set fileencoding可以查看字符串模式。
在代码中插入代码让其自行对字符串进行解析:(1)首先在百度控制台(F12)中,打开head,找到这段html代码(说明字符集是utf-8),添加到自己的代码(Handler404)中(把返回的页面中添加这句代码)

b、在编译运行时输出两次请求的内容。第二次输出时url_path为:/favicon.ico:favicon.ico这个文件表示一个logo、网站的图标。浏览器在访问任何一个文件时都会顺便访问一个logo。
创建一个wwwroot文件夹,在里面创建一个html文件,如果想要访问这个html文件,则在HandlerFilePath中构造这个路径
在shell下:ctrl+insert复制;shift+insert粘贴。
4、返回图片文件:
mkdir image 放入图片:进入root用户下,输入rz -E
将文件重命名为i.jpg
在浏览器中访问:

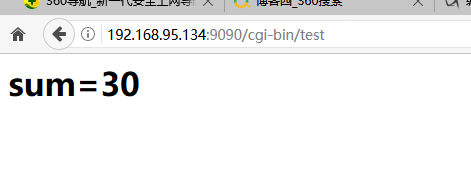
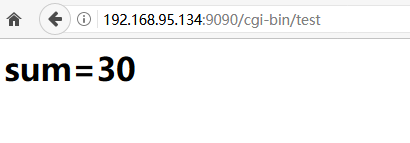
5、在wwwroot目录下创建一个cgi-bin目录,返回两个数字相加的结果:

结果:
先启动服务器

添加俩个按钮分别表示两个数字,输入数字后相加(w3c----查找表单----写入form元素表示输入
在index.html中构造自己版本的html,实现简单的加减法运算:http://192.168.95.134:9090/cgi-bin/index.html
问题:
(1)函数定义放在.h文件里有什么后果,应该怎么办是正确的
将函数定义写在一个文件里面,在两个.c文件中分别调用这个头文件,把两个.c文件放在一起编译生成可执行文件,链接会出现错误,说明一个函数在两个地方被重复定义【因为都包含了同一个头文件,include引用头文件是在进行文本替换,相当于把头文件的文本替换到了函数的定义中,造成了重复定义。】这就是主张把函数定义(放在.h文件)和函数声明(放在.c文件)中的原因;【解决方式:避免重复定义的问题。加上static使得函数只在当前编译单元内部有效,使得两个编译单元可以有一个同名函数。不会被当作重复定义。】
但是把函数定义放在一个文件中也是有好处的,比如使用方便,是需要包含一个头文件就可以了。
(2)、函数定义与声明分开避免重复定义的问题:
既想把函数定义放到头文件里面,又想避免重复定义的问题:在函数前面加上关键字static,表示只在当前编译文件内部生效。
遇到的问题:
如何将多个文件写在一个makefile底下,合并成一个文件,使用一条make指令执行?
vim中常见的快捷键的使用:
图片如何显示在自己的程序中:安装rz
一、演示1:两个数字相加test.c:
输入网址访问:http://192.168.95.135:9090/cgi-bin/test
演示2:使用C语言操作mysql数据库(mysql提供了C语言的API,可以直接调用)
(1)在wwwroot目录下创建文件select.c从数据库中查找信息
(2)增删查改基本语句的使用:
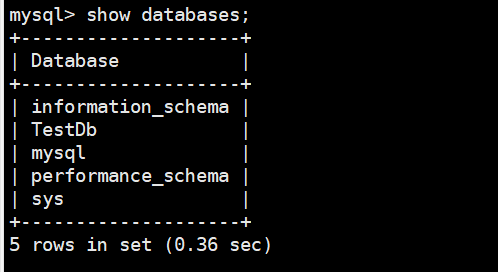
A、打开数据库的客户端,mysql -u root -p:登录mysql。查看有哪些数据库:show databases;
B、切换到数据库,进入TestDb:use TestDb;

C、插入:
(3)在select.c中编写代码完毕后,运行./select,遇到了错误:

错误的原因:select语句拼写错误,导致不能正常去数据库中进行查询。
(4)启动服务器后,通过cgi程序查询数据库:若是不加一个参数?a=1,是一个静态文件的分支,不能触发cgi程序
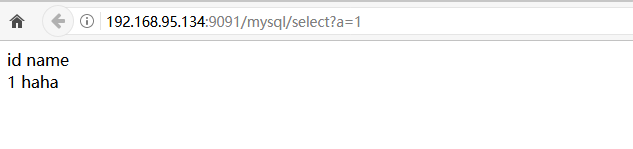
业务一:
写一个插入数据库的cgi程序,使用户可以通过浏览器插入要插入的数据
启动服务器后:

业务2:
实现一个展示博客,github,作品链接的网站(这部分才是一个具有业务场景的项目)【完全静态页面就可以】resume/index.html
可以将一个部署在云服务器上的项目转换成二维码,(网上搜索二维码,将网址贴入进行转换即可)
<html>
<head>
<meta http-equiv="Content-Type" content="text/html;charset=utf-8">//防止乱码
</head>
<h1>花的简历 </h1>
<a href="https://mp.csdn.net/postedit/80760834">我的博客</a>//超链接
<a href="">我的github</a>
<a href="">我的作品</a>
</html>
输入:IP地址:端口号/resume/index.html即可进行访问:可将此部署到云服务器上之后,生成一个二维码
![]()
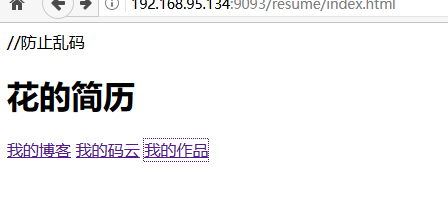
此时只能显示一个简单的页面,极其不美观
2、美化:
方案一:搜索网站免费模板
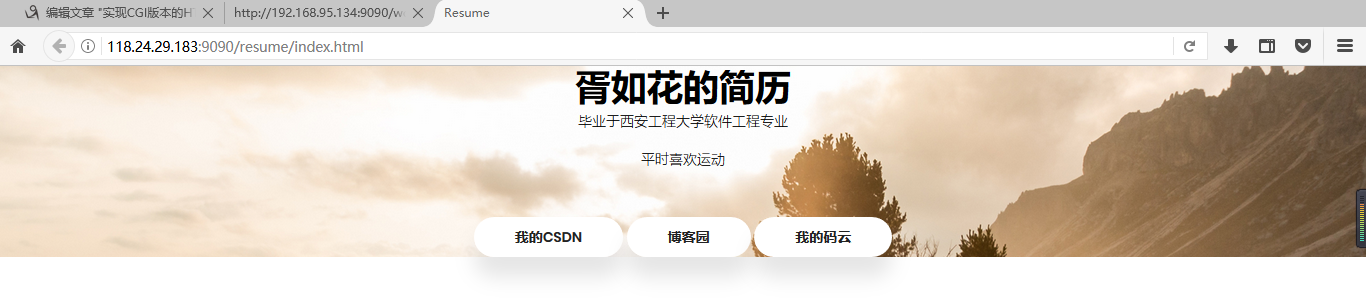
项目二:
访问世界时间:
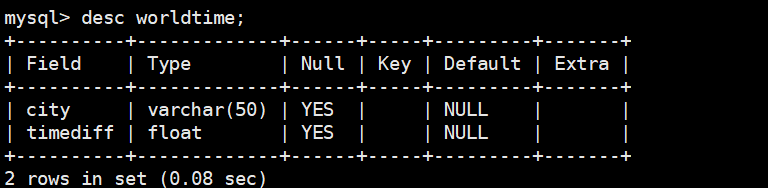
1、数据库:数据表
包含两列:(1)城市名称;(2)城市时差(相对于北京时间)
2、步骤:
(1)实现一个主页(静态的页面),主页中包含一个输入框和一个提交按钮,在输入框中输入要查看的城市,按下提交,就会给服务器发送HTTP请求;
(2)服务器收到HTTP查询请求后,根据得到的城市名称,查询数据库,获取到时差
(3)获取到当前的时刻,和时差进行计算,得到对方城市的当前时间
(4)构造一个响应的页面,把时间填充到页面中
在数据库中插入世界上的国家名字对应的编码,和时差;在wwwroot目录下创建的worldtime目录下创建一个worldtime.c文件,生成CGI程序,并且借助这个CGI程序完成后面的计算。
查询数据库,把查询的结果进行简单的计算,计算的过程中,主要是要理解计算方法:得到的时间是小时,把小时换算成秒,再去加等上当前的秒数,再将其转换成格式化的时间,再将其输出成html的格式。
启动服务器后,输入http://192.168.95.134:9092/worldtime/wordtime%EF%BC%9Fcity=%E8%A5%BF%E5%AE%89进行查询
三、用到的其他工具:链接数据库:通过cgi程序操作数据库
在mysql中添加cgi程序:select.c:从数据库中查找一些信息:
1、C语言操作MySQL:提供了C语言风格的API
(1)安装mysql的客户端服务器:
通过yum install mysql安装mysql实际上是安装的两个程序:
a、mysql-client:命令行中敲入的mysql语句【服务器启动完毕后,再
启动客户端,才能正确的进入命令行界面,进行操作】
b、mysql-server:服务器执行真实的sql语句操作
(2)安装mysql的C语言开发包:yum list | grep mysql
yum install mysql-devel[包含了一组mysql的头文件及mysql的库文件(c风格的代码)]【libodb-mysql-devel]
验证是否安装成功: cd /usr/include/mysql/
ll若是显示头文件则安装成功
ll mysql/:可以查看mysql下包含的库[mysql能正常运行包含的动态库][函数的定义需要引用动态库文件,才能够真正的执行代码;只有拥有头文件和动态库文件,才能说明安装成功,如果没有则安装失败。
2、mysql如何使用C语言操纵mysql呢?
在mysql中添加cgi程序:select.c:从数据库中查找一些信息:
编译时需要加上动态库的名字-lmysqlclient
3、mysql
mysql -uroot -p输入密码
查看有哪些数据库:show databases;
查看表:show tables;
查看表结构:desc 表名;
查看表中的内容:select * from 表名
删除表:delete from 表名 where 语句
插入:insert into 表名
查看数据库的连接信息:ps aux | grep mysqld
![]()

实现一个insertcgi向数据库中插入数据insert.c
重新实现一个makefile,并且编译
总结:
一个通用的HTTP框架和上层各种各样的CGI程序【可能为一个,也可能为多个】,构成了一个完整的体系,通用的HTTP框架是业务无关的,CGI程序是业务相关的。
框架部分:(1)服务器的初始化:构造一个多线程版本的TCP服务器
(2)循环处理请求
a、对首行进行解析(解析出方法,url、url_path、query_string);
b、对header进行解析(只保留了Content-Length)
c、根据方法和参数的情况决定是返回静态页面还是动态生成页面
d、对于静态页面,格局url_path,打开对应的文件,根据文件内容构造HTTP响应就可以了
e、对于动态页面,需要按照CGI的规则生成动态页面
(3)CGI:标准(协议)
好处:服务器框架部分和业务逻辑部分进行解耦和(搭配任意变成语言实现任意场景)
缺点:CGI需要创建子进程并进行程序替换(非常消耗性能)
具体步骤:
创建父子进程,各自具有不同的逻辑:
创建一对匿名管道,用于父子进程的交互
父进程:a、如果是POST请求就把body部分放到管道中
b、父进程就可以尝试从管道中读取子进程返回的结果了
c、父进程需要构造出HTTP响应的完整格式,其中首行和header都是父进程自己搞定的。body部分则是子进程计算完成的
d、父进程进行进程等待(waitpid)
子进程:
a、设置环境变量(因为后面一旦进行程序替换,原有的变量都没有了,只能通过环境变量来保存必要的结果)
b、获取到CGI程序对应的路径
c、进程程序替换
CGI程序:
a、从环境变量中获取到必要的信息,最终得到当前请求的参数(query_string/body)
b、根据具体的业务逻辑(参数)进行计算
c、拼装最终响应结果(HTTP中的body部分)
重要技巧:如果要生成HTML非常复杂,把HTML这部分代码放到一个文件中,而不是直接放到.c文件中,CGI程序运行过程中读取HTML文件,把其中不需要动态变化的部分直接写到标准输出中;把其中需要变化的部分,根据需要进行占位符的替换。
六、测试:
1、 利用 linux命令 Top、Free查看服务器的资源使用情况。
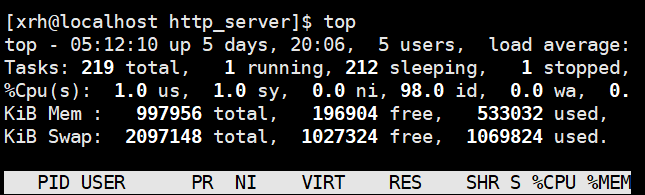
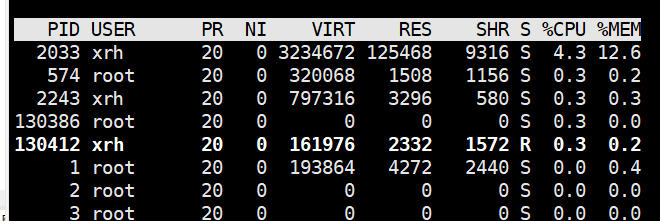
第一行top分别为:当前时间;系统运行天数;使用者个数;系统负载的平均值,后面的三个值分别为1分钟前、5分钟前、15分钟前进程的平均数,这个数值超过 CPU 数目时,说明负载过高
第二行Tasks分别为:进程总数;运行进程数;睡眠进程数;被停止的进程数;被复原的进程数
第三行CPU(s)分别为:cpu使用率;
第四行Mem分别为:总内存;已用内存;空闲内存;缓冲使用中内存
第五行(Swap):类似第四行,但反映着交换分区(Swap)的使用情况。交换分区(Swap)被频繁使用,可以看作物理内存不足而造成的
free:
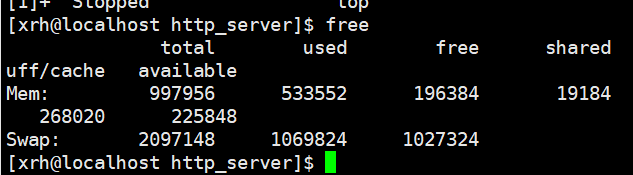
free命令参数:
-t 显示total行;
-b,-k,-m显示单位分别为B,KB,MB
-s,实时更新,如:free -m -s2(每2秒更新一次,显示单位Mb)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号