
搜索引擎
一、该搜索引擎是对boost源码进行搜索,针对boost文档进行简单的搜索功能
写这个搜索引擎的原因:实现一个基于boost文档的搜索,数量太大时,可能不好实现,数量较小时,可以正常实现,并且boost库中没有一个合适的搜索功能。使用boost时,发现查一个东西不好查,所以想要自己实现一个服务器
2、项目应包含的模块
http服务器
CGI程序:(搜索客户端)
搜索服务器:
索引模块:


3、介绍一个项目时:
(1)首先应该介绍项目背景(为什么要实现这个项目)
(2)项目解决了什么问题(boost库不好用)
(3)为了解决这个问题是怎么做的,模块和模块之间的关系
4、搜索流程:
(1)访问主页:浏览器访问http服务器获取到主页的html
(2)进行搜索:
A)浏览器发送http一个get请求,【get和post的区别:get请求是通过,query_string传递请求;post请求是通过http协议中的body传递参数】【post请求中,body数据的格式是什么?具体的格式通过content_length来进行约束】,包含一个query参数把查询此传递给HTTP服务器
B)HTTP服务器收到请求之后,解析出其中的query参数,通过CGI程序包装成TCP请求,发送给搜索服务器(搜索服务器是一个TCP的服务器);
C)搜索服务器收到请求之后进行检索,得到响应数据
返回给CGI程序
D)CGI程序拿到响应数据后,根据响应数据,包装成html,返回给浏览
(3)搜索的具体流程:
A)搜索服务器对此查询进行分词,查询词可能为一句话
使用第三方库:cppjieba 结巴分词(开源的库)
B)针对每个分词结果,进行触发
核心是通过倒排索引进行实现
倒排索引:
![]()

C)、针对触发的文档结果,进行排序
排序的依据主要词出现的位置和频率
D)、根据排序后的id列表,从正排索引中获取到对应的数据,然后包装成TCP响应
boost库一点都不强大,就几个容器、几个算法
使用的第三方库:
gflags:谷歌开源的管理命令行参数配置的库
glog:谷歌开源的日志库
protobuf:谷歌开源的序列化库【序列化把一个对象(结构体,类)转化为字符串;反序列化就是将字符串转化为结构体】【(1)可以将结构体转化为char*,把结构体对应的类型理解为字符数组(局限性很大);(2)用特定的限定符分割开(分割符:header和header之间使用换行符分割,header和body之间使用空行分割header之中的键值对通过冒号分割)(不能使用空格充当分割符,若是为字符串,则不满足)】【可以使用\0和\1这样的不可见字符来分割(\0表示ASCII码值为0的,\1表示ASCII值为1的值……叫做不可见字符即正常文档中没有的字符)】【也可以使用Jason方式(类似于python中的字典】【protobuf序列化库,二进制文本字符串格式,使用二进制占用资源少,但是同样调试起来也不方便】【http是纯文本的形式,方便可读,方便进行调试】
sofa:百度开源的RPC框架
ctemplate:谷歌开源的html渲染的框架
cppjieba:中文分词库
使用码云:git clone
5、注意:这里实现时,将公共代码放在common中,其他几个代表需要实现的几个模块;front表示前端代码;建立符号链接ln -s ~/third_part将其放在项目目录下
6、索引模块
(1)实现一个索引制作程序
输入:boost所有文档(html)
输出:索引文件(包含了格式化的正排和倒排),后面由搜索服务器进行加载(加载到内存中,直接由搜索服务器从内存中绑定服务器)。
(2)实现索引反解工具:输入:索引文件;输出:把索引文件中的内容进行更加直观更加格式化的输出,方便肉眼进行测试。
(3)实现一个静态库:静态库帮助我们完成公共代码的组织。和索引相关的核心操作都放到静态库中。
索引制作的流程:1)遍历所有需要处理的html,对html进行去标签。把所有文件去标签之后的结果组织到一个文件(raw_input)中,方便后续处理(python);2)读取并分析raw_input文件,制作正排和倒排(cpp)
实现去标签(python html去标签)
c++标准库不支持遍历目录的操作
二、执行过程
1、下载第三方库,链接:https://gitee.com/HGtz2222/ThirdPartLibForCpp.git
2、目录的含义:
server:搜索服务器
client:搜索客户端,即CGI程序
index:
common:公共代码【处理字符串的代码;处理暂停词表的代码;文件相关的类(将文件直接写入,将文件读出来)
ConvertToProto遍历的是内存结构,构造的是proto结构;ConvertFromProto遍历的是proto结构,构造的是内存结构;双方进行格式上的转换即可;保存的信息是相同的,只不过转换成需要的格式。
front:和前端相关的代码,包括html
ln -s ~third_part 和引入的库建立链接
(1)测试gflags和glog这两个库的用法
a、
测试使用第三方库:test_gflags

输入一个参数,另外两个参数是默认值。可以通过配置的形式,告诉使用者执行过程中要使用的ip地址和端口号;解决了参数特别多的时候的配置问题。
b、测试使用 test_glog

此时只打印了error日志,因为欸之本体仍然在log目录下

蓝色的为符号链接(符号链接指向日志文件的内容),白色的为日志文件;可以打开main.ERROR等直接查看日志文件
也可以将这两个库封装在base.h中
1、实现搜索引擎相关的内容
(1)打开index目录,进入索引模块
A、
输入:boost所有文档(html)
输出:索引文件(包含了格式化的正排索引和倒排索引),后面由搜索服务器进行加载(把数据提前分析好做成结构化的数据之后,由搜索服务器进行加载(免去了对数据分析的问题)。加载到内存中,直接由搜索服务器从内存中绑定服务器)。【直接用select也能完成类似的操作,但是在这里我们不使用,因为数据库完成的比较慢,数据库访问的数据都保存在磁盘上,数据库访问的文件不是一个普通文件,而是对应一个结构化的文件,各种各样的数据结构导致在磁盘的写的速度越来越慢,所以这些搜索内容尽可能在内存上完成。】【正排索引到后来会组织成一个数组,按照下标组合数据是很快的,倒排索引会组织成一个哈希表,按照哈希表来查数据也是很快】【冯诺依曼体系结构,访问内存就是比访问磁盘快。】
B、实现一个索引制作程序:
实现索引制作工具:index_builder.cc
1)实现索引反解工具:输入:索引文件;输出:把索引文件中的内容进行更加直观更加格式化的输出,方便肉眼进行测试。index_dump.cc
2)实现一个静态库:静态库帮助我们完成公共代码的组织。和索引相关的核心操作都放到静态库中。index.cc
索引制作的流程:1)遍历所有需要处理的html,对html进行去标签。把所有文件去标签之后的结果组织到一个文件(raw_input)中,方便后续处理(python);
实现去标签(百度python html去标签---赋值粘贴即可
下载boost库的文档,并将其放在data目录下的input目录下)
在python目录中创建一个pre_work.py预处理命令(将input下的内容引入该文件中并进行去标签)
c++标准库不支持遍历目录的操作
用到的指令:粘贴---->在粘贴模式下(:set paste)---进行粘贴
快速调整空格----》先选中要被调整的代码---》进行一个等号操作
awk:擅长处理行文本文件
awk -F '\3' '{print NF}' raw_input:查看是否每次执行按照\3分割
2)读取并分析raw_input文件,制作正排和倒排(cpp)
依赖一个前置动作protobuf库【索引需要把结构化的数据保存在序列里面,相当于序列化,搜索服务器需要解析这里面的内容,加载到内存之中,相当于反序列化】
A、如何使用protobuf:
创建protobuf目录,该目录下创建几个文件,其中main.cc基于hellomsg完成一次序列化和反序列化
3)索引的结构如何定义

找到index目录下的cpp目录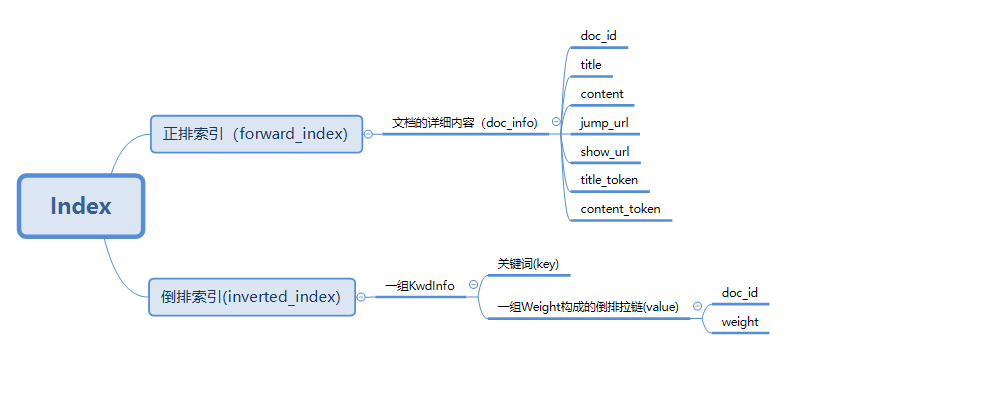
,创建文件index.proto,创建index.h并且描述里面的内容(索引结构,运用protobuf完成序列化)
wc -l查看文件中的行数
ifndef 这种防止头文件被重复多次引用的方式,不建议使用,原因:(1)没有# pragma once写起来简单;(2)ifndef后面需要加上宏的名字,如果有两个相同的名字在不同的文件下,定义宏的名字如果定义成一样的就会导致第一个文件才会被引用,而第二个文件被屏蔽掉了【宏的名字一冲突,可能导致出错】
effective C++:一个类包含了其他类的对象叫做组合,包含表示has-a,public继承表示is-a;protect继承和private继承,实际工程软件设计中没有意义,C++以后出现的变成语言中规定派生文件和包含文件都没有私有继承和保护继承,都是公有继承。组合和继承是不同场景下的语义。
单例模式:设计模式中的一种【设计模式是指,一些经典常见的问题,大佬们给出解决方案,不会的人照着大佬的往上套】【如何实现单例模式及线程安全的单例模式?】
将index.cc中的字符串切分函数Split放到公共模块中组织,在common目录中(其他模块可能遇到的公共代码),新建一个util.hpp存放代码
在目录test.jieba中创建文件demo.cc站贴上从jieba分词上复制过来的代码,检测是否能正常运行
B:倒排索引(在文件index.cc中):拿着doc_info去更新inverted_index;在doc_info中包含了很多的分词结果,这里面的每个分词结果都对应inverted_index里的KwdInfo的每一个关键词上,每一个关键词都涉及到一组weight,一组weight里面要根据关键词拿到对应 的vector;然后根据当前文档的信息构造新的weight,插入倒排拉链(vecto)里面。
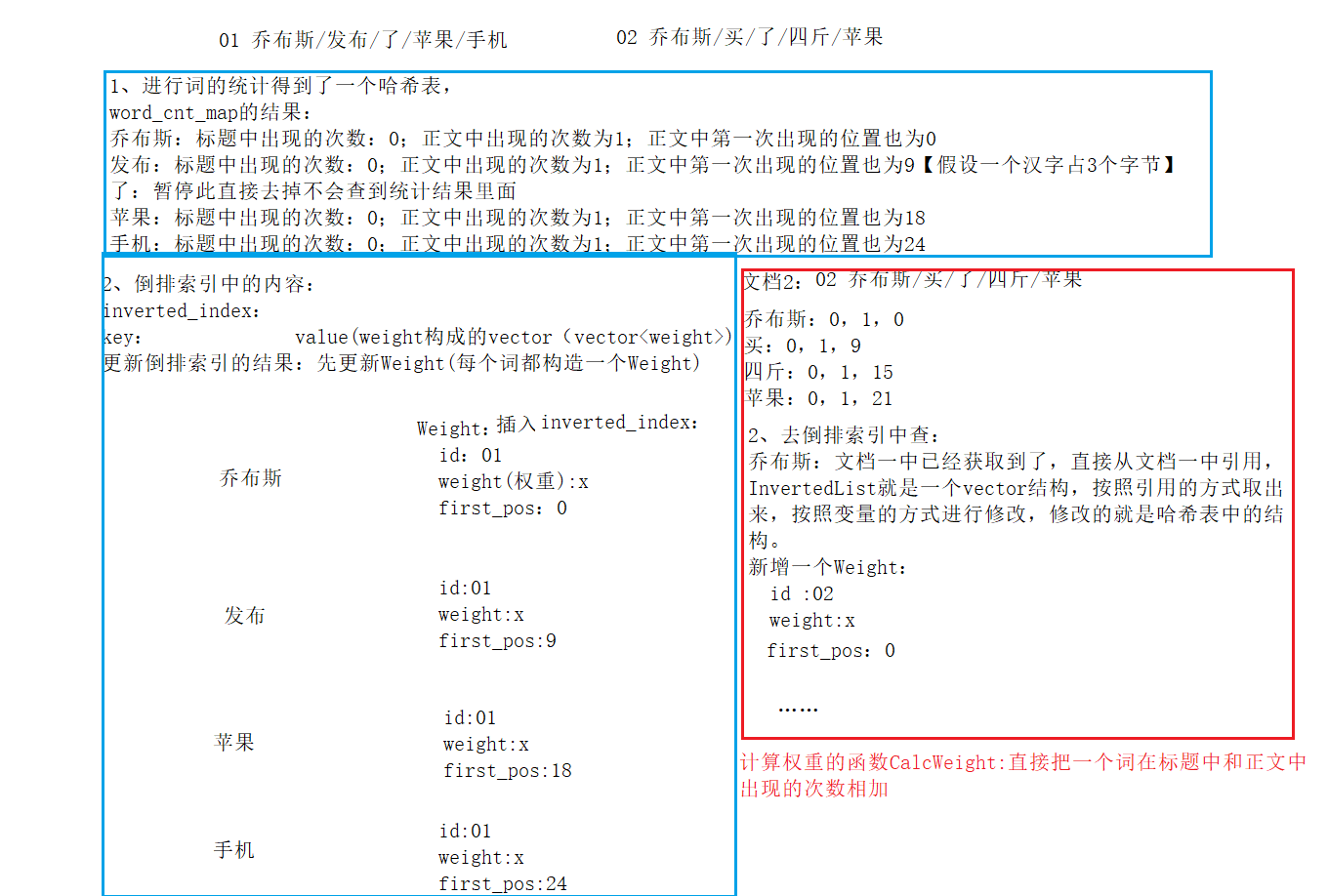
整体更新过程(完全对应index.cc里面的代码):先去遍历文档,再去统计词,这个词就是统计之后的结果。拿着这个词到倒排索引中查哈希,查找这个词对应的vector,获取到这个vector,直接把这个构造的新的weight插入到原有的vector之后。inverted_index中词的个数和vector的个数都会越来越多。
执行可执行文件:/home/xrh/SouSuoYinQin/class.302_dev/index/bin ./index_builder
(2)创建目录bin,保存二进制可执行程序的目录
(3)创建cpp放c++的代码
(4)创建data 存放依赖的数据
(5)创建log 存放日志
(6)创建python存放python代码
去标签、去换行后得到一个raw_input文件;再处理raw_input文件
三、搜索服务器模块:调用索引模块具体的检索过程
搜索服务器完成了搜索的具体流程
输入:查询词
输出:若干个搜索结果:标题,描述,展示url,点击url
1、TCP服务器,基于RPC
(1)RPC:远程过程调用【客户端想要做一件事情,客户端就调用一个本地的函数,本地的函数在函数内部就会完成和服务器通信的内容,把相关的内容发送服务器,再在服务器上调用一个对应的函数,由服务器上的函数完成对应的计算过程,并且把结果教回给客户端,相当于是由RPC框架,封装了网络通信的过程,从而简化了客户端的代码开发。使客户端不需要关系网络通信的细节,只要调用一个本地的函数就相当于请求了一次服务器,服务器上的函数获取到了结果。
RPC框架中需要关注的点:
A、
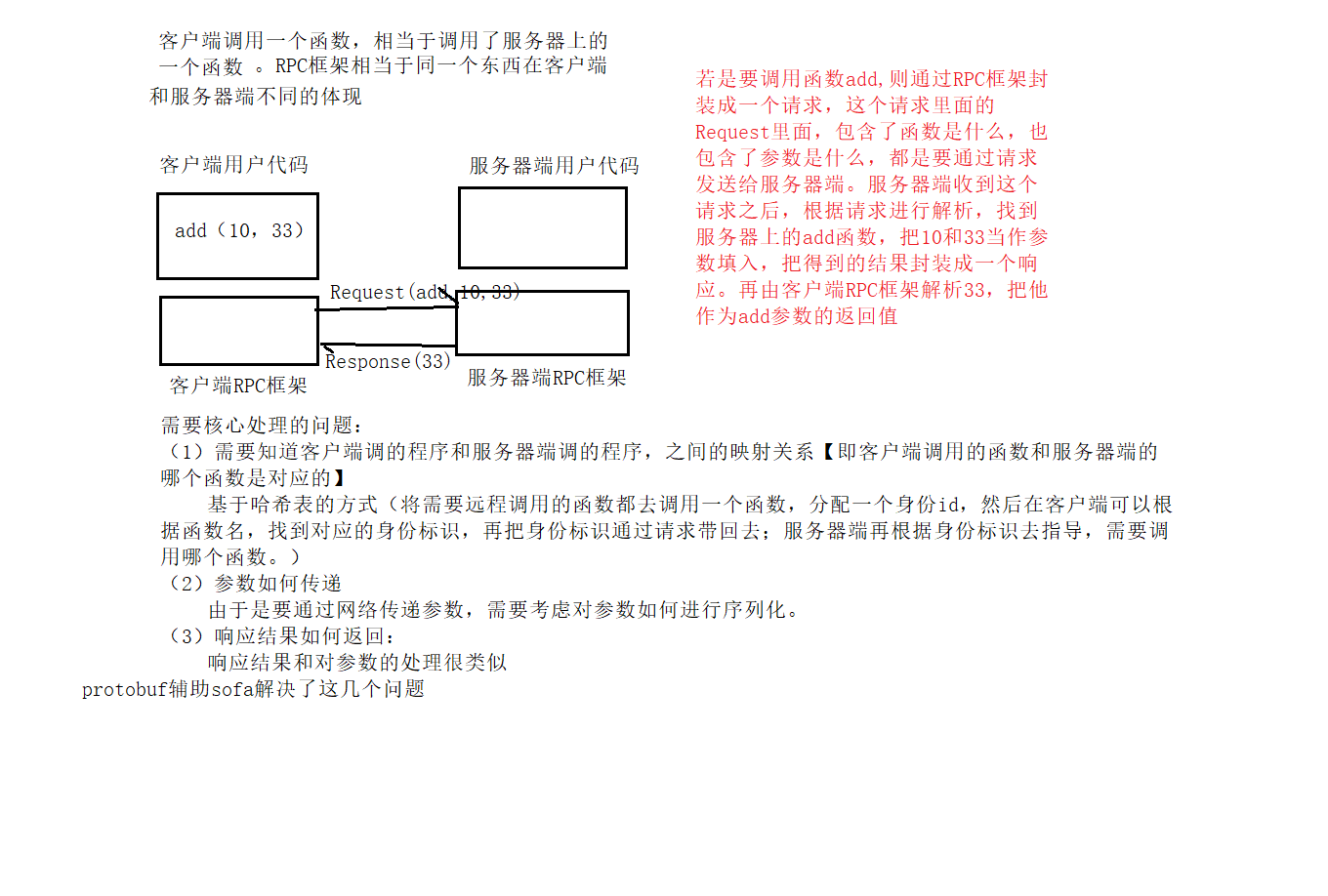
在proto结构中定义了service DocServerAPI,生成两个类:(1)DocServerAPI:供服务器使用;(2)DocServerAPI_Stub:供客户端使用;预期的效果就是:在客户端调用DocServerAPI_Stub::函数,就会自动调用到服务器端DocServerAPI:的函数【但是实际上服务器如何处理这个函数的动作是需要用户自己实现的,需要用户自己定义一个DocServerAPI的子类,在子类中重写函数。也就是用户自定制的add的执行过程(基于多态:框架提供好了,有些需要自定制的,需要继承框架中的代码,以框架中的代码为基类,继承得到的结果,再次加入注册框架之中,由框架自动调用自定制代码)】。
现在server目录中基于RPC方法写一个程序【bin下放可执行程序】;因为基于protobuf,则在该目录下创建一个文件server.proto(包含了如何定制一个通信协议:主要定义出RPC服务器需要定义出哪些RPC函数);创建一个文件server_main.cc:
如果被断开链接的一方没有进行close()操作,会产生大量的CLOSE_WAIT,这是一个bug,需要修复,说明四次挥手没挥完。
TIME_WAIT:谁主动断开链接谁进入这个状态,为了收到重传的FIN,服务器上也可能会产生大量的TIME_WAIT状态,说名在这个场景下是服务器端主动断开链接,就会产生大量的TIME_WAIT状态。每一个TIME_WAIT都是一个TCP链接,产生大量TIME_WAIT状态可能会导致服务器连不上,操作系统需要管理这个链接,进行描述和组织;对于链接也需要先链接,再组织,所以大量的TIME_WAIT意味着需要很多的内存资源去进行维护;其二:每个TIME_WAIT都占有一个TCP连接,每个TCP连接都是一个五元组(源IP,源端口号,目的IP,目的端口号,协议号),一个连接占用一个五元组:如果源IP、源端口号是固定的,但是目的IP、目的端口号(即客户端的IP和端口号)可能出现重用,再次访问这个IP和端口号会产生失败,连接建立不上,因为这个五元组已经被TIME_WAIT占用了。为了解决这个问题:我们可以(1)修改操作系统内核中的配置,让TIME_WAIT的时间短一点,默认两份中,我们可以把时间调整的更短;(2)sockopt里面有一个选项REUSEADDR可以让我们重用TIME_WAIT:保证客户端下次再用相同的五元组进行连接的时候,可以正常进行连接。
sofa是百度开源的RPC框架,一个中文的详细文档
四、搜索客户端模块:
创建文件夹client,基于RPC框架完成客户端发送请求的操作:客户端和服务器端需要使用同样的协议进行连接,我们可以使用符号链接,将server里面的server.ptoto引入:ln -s ../../server/cpp/server.proto;直接把文件建立符号链接,说明服务器端一旦修改文件内容,客户端自动就更新了,不需要客户端再拷贝一份,解决了文件更新的稳定性。
客户端不需要向服务器端一样写一个类,只需要对RPC框架进行远程调用即可【增加了超时控制、有支持异步返回的机制,有压缩机制】
衡量一个服务器好坏的指标:(1)吞吐量:一次能对多少个服务器请求进行处理;(2)在单位并发量的情况下,的响应时间是多少。【sofa的文档里面有百度的测试工程师的测试文档】
错误:服务器端产生了段错误:
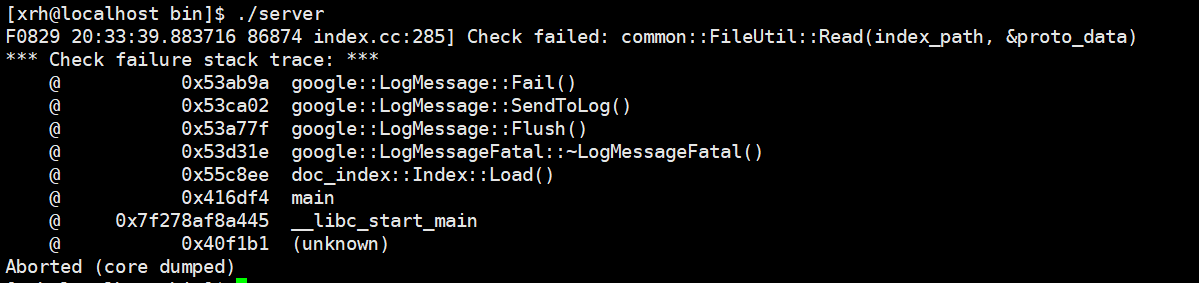
在server目录下定义一个doc_searcher.cc 文件,表示服务器端的业务代码,包含了搜索过程中的全部重要流程
在server目录下使用ln -s ../index/data/output index把output目录链接到成index,就可以通过bin目录下的index访问链接,访问到做好的索引。
2、filesystem:boost库中帮助完成文件系统的相关概念
3、在client_main.cc中构造search_page.html中的html标签;在bin目录下写一个test.sh的shell文件,将要敲的命令写到一个文件中,定义环境遍量,设置环境变量。
4、cout会将结果打印到屏幕上,CGI程序会把标准输出重定向到管道里面,导致往标准输出写的日志都通过管道直接写到浏览器上。
5、
运行shell脚本:产生错误

错误的原因:
创建front目录放置和前端相关的内容,如将客户端的结果链接进去:ln -s ../client/bin cgi-bin;此时的cgi-bin目录下就是cgi程序;再将front目录通过链接的方式链接到http服务器的根目录下,找到wwwroot的根目录,再此创建符号链接
五、、RPC框架中涉及到的相关概念:
(1)服务器端:
RpcServer::
RpcServerOptions:
DocServerAPI:对应服务器端执行的代码
RpcController:管理网络通信的细节【如获取对端的IP地址和端口号】
(2)客户端:
RpcClient:对应RpcServer
RpcChannel:描述了建立的连接
DocServerAPI_Stub:描述了要调用哪个Rpc函数【类似于socket中的connect……】
RpcController:管理网络通信的细节


 浙公网安备 33010602011771号
浙公网安备 33010602011771号