MySQL的三种日志
MySQL我们常见的日志有以下三种
1.binlog
2.redo log
3.undo log
一、binlog
binlog应该是日常中听的最多的关于mysql中的log。那么什么是binlog呢?
binlog是用于记录数据库表结构和表数据变更的二进制日志,比如insert、update、delete、create、truncate等等操作,不会记录select、show操作,因为没有对数据本身发生变更。
binlog文件长什么样子呢?
使用mysqlbinlog命令可以查看。
binlog会记录下每条变更的sql语句,还有执行开始时间,结束时间,事务id等等信息。
如何查看binlog是否打开,如果没打开怎么设置?
使用命令show variables like '%log_bin%'; 查看binlog是否打开。

如果像上图一样,没有开启binlog,那怎么开启呢?
我们需要找到my.cnf配置文件,增加下面配置(mysql版本5.7):
# 打开binlog
log-bin=mysql-bin
# 选择ROW(行)模式
binlog-format=ROW
修改后,重启mysql,配置生效。
binlog日志的几种模式
1.row 行模式
日志中会记录每一行数据被修改的形式,然后在slave端再对相同的数据进行修改
优点:在row level模式下,bin-log中可以不记录执行的sql语句的上下文相关的信息,仅仅只需要记录那一条被修改。所以rowlevel的日志内容会非常清楚的记录下每一行数据修改的细节。不会出现某些特定的情况下的存储过程或function,以及trigger的调用和触发无法被正确复制的问题
缺点:row level,所有的执行的语句当记录到日志中的时候,都将以每行记录的修改来记录,会产生大量的日志内容。
2. Statement 模式(默认)
每一条会修改数据的sql都会记录到master的bin-log中。slave在复制的时候sql进程会解析成和原来master端执行过的相同的sql来再次执行
优点:statement level下的优点首先就是解决了row level下的缺点,不需要记录每一行数据的变化,减少bin-log日志量,节约IO,提高性能,因为它只需要在Master上锁执行的语句的细节,以及执行语句的上下文的信息。
缺点:由于只记录语句,所以,在statement level下 已经发现了有不少情况会造成MySQL的复制出现问题,主要是修改数据的时候使用了某些定的函数或者功能的时候会出现。
3.mixed模式
MySQL会根据执行的每一条具体的sql语句来区分对待记录的日志格式,也就是在Statement和Row之间选择一种。如果sql语句确实就是update或者delete等修改数据的语句,那么还是会记录所有行的变更。
行模式和语句模式的区别
1.语句模式:
100万条记录
只需1条delete * from test;就可以删除100万条记录
2.row模式
100万条记录
记录100万条删除命令
企业场景如何选择binlog模式
1、互联网公司,使用MySQL的功能相对少(存储过程、触发器、函数)
选择默认的语句模式,Statement Level(默认)
2、公司如果用到使用MySQL的特殊功能(存储过程、触发器、函数)
则选择Mixed模式
3、公司如果用到使用MySQL的特殊功能(存储过程、触发器、函数)又希望数据最大化一直,此时最好选择Row level模式
查看binlog模式
show global variables like '%binlog_format%';
在线修改
SET GLOBAL binlog_format = 'ROW';
或修改配置文件,重启生效
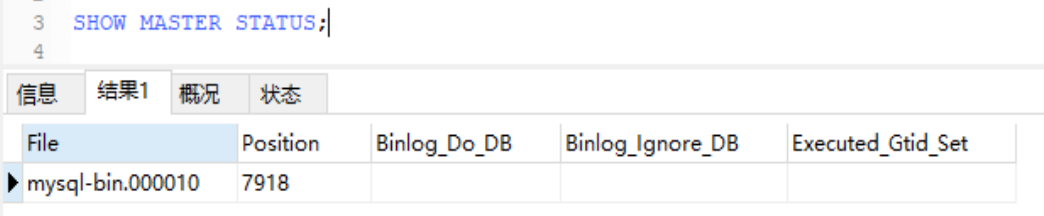
执行SHOW MASTER STATUS;
可以查看当前写入的binlog文件名。
binlog用来干嘛的呢?
第一,用于主从复制。一般在公司中做一主二从的结构时,就需要master节点打开binlog日志,从机订阅binlog日志的信息,因为binlog日志记录了数据库数据的变更,所以当master发生数据变更时,从机也能随着master节点的数据变更而变更,做到主从复制的效果。
第二,用于数据恢复。因为binlog记录了数据库的变更,所以可以用于数据恢复。我们看到上面图中有个字段叫Position,这个参数是用于记录binlog日志的指针。当我们需要恢复数据时,只要指定--start-position和--stop-position,或者指定--start-datetime和--stop-datetime,那么就可以恢复指定区间的数据。
sync_binlog参数(取值范围0-N)
0:不去强制要求,由系统自行判断何时写入磁盘;
1:每次commit的时候都要将binlog写入磁盘;
N:每N个事务,才会将binlog写入磁盘。
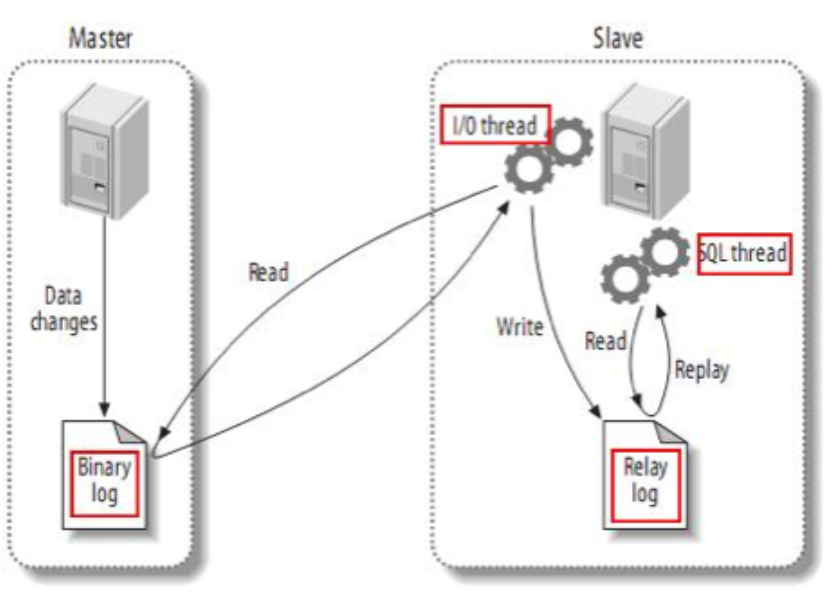
二、redo log
redo log又称重做日志文件,用于记录事务操作的变化,记录的是数据修改之后的值,不管事务是否提交都会记录下来。在实例和介质失败(media failure)时,redo log文件就能派上用场,如数据库掉电,InnoDB存储引擎会使用redo log恢复到掉电前的时刻,以此来保证数据的完整性。
1. redo日志文件名
每个InnoDB存储引擎至少有1个重做日志文件组(group),每个文件组至少有2个重做日志文件,如默认的ib_logfile0和ib_logfile1。
2. 影响redo log参数
innodb_log_file_size:指定每个redo日志大小,默认值48MB
innodb_log_files_in_group:指定日志文件组中redo日志文件数量,默认为2
innodb_log_group_home_dir:指定日志文件组所在路劲,默认值./,指mysql的数据目录datadir
innodb_mirrored_log_groups:指定日志镜像文件组的数量,默认为1,此功能属于未实现的功能,在5.6版本中废弃,在5.7版本中删除了。
假设有一条update语句:
UPDATE `user` SET `name`='刘德华' WHERE `id`='1';
我们想象一下mysql修改数据的步骤,肯定是先把id
='1'的数据查出来,然后修改名称为'刘德华'。再深层一点,mysql是使用页作为存储结构,所以MySQL会先把这条记录所在的页加载到内存中,然后对记录进行修改。但是我们都知道mysql支持持久化,最终数据都是存在于磁盘中。
假设需要修改的数据加载到内存中,并且修改成功了,但是还没来得及刷到磁盘中,这时数据库宕机了,那么这次修改成功后的数据就丢失了。
为了避免出现这种问题,MySQL引入了redo log。

如图所示,当执行数据变更操作时,首先把数据也加载到内存中,然后在内存中进行更新,更新完成后写入到redo log buffer中,然后由redo log buffer在写入到redo log file中。
redo log file记录着xxx页做了xxx修改,所以即使mysql发生宕机,也可以通过redo log进行数据恢复,也就是说在内存中更新成功后,即使没有刷新到磁盘中,但也不会因为宕机而导致数据丢失。
redo log与事务机制是如何配合工作的?
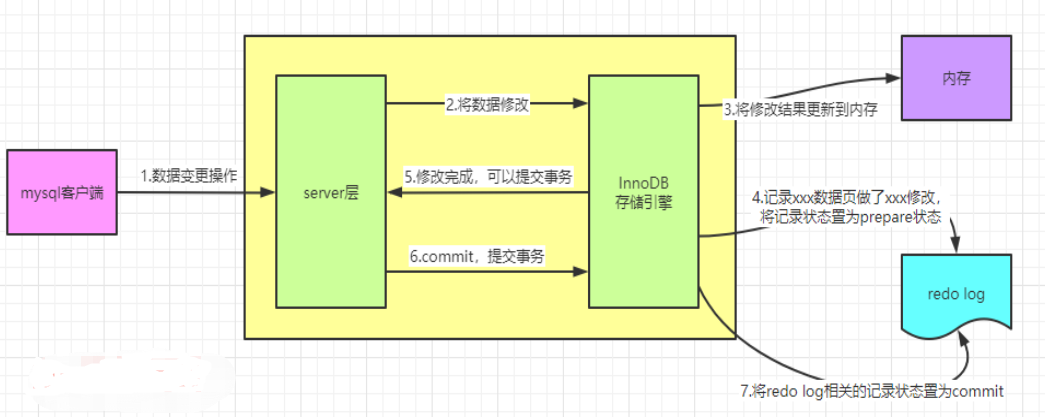
如图所示:
第1-3步骤就是把数据变更,然后写入到内存中。
第4步记录到redo log中,然后把记录置为prepare(准备)状态。
第5,6步提交事务,提交事务之后,第7步把记录状态改成commit(提交)状态。
保证了事务与redo log的一致性。
binlog和redo log都可以数据恢复,有什么区别?
第一:redo log是在InnoDB存储引擎层产生,而binlog是MySQL数据库的上层产生的,并且二进制日志不仅仅针对INNODB存储引擎,MySQL数据库中的任何存储引擎对于数据库的更改都会产生二进制日志。
第二:两种日志记录的内容形式不同。MySQL的binlog是逻辑日志,其记录是对应的SQL语句。而innodb存储引擎层面的重做日志是物理日志。
第三:两种日志与记录写入磁盘的时间点不同,二进制日志只在事务提交完成后进行一次写入。而innodb存储引擎的重做日志在事务进行中不断地被写入,并日志不是随事务提交的顺序进行写入的。
二进制日志仅在事务提交时记录,并且对于每一个事务,仅在事务提交时记录,并且对于每一个事务,仅包含对应事务的一个日志。而对于innodb存储引擎的重做日志,由于其记录是物理操作日志,因此每个事务对应多个日志条目,并且事务的重做日志写入是并发的,并非在事务提交时写入,其在文件中记录的顺序并非是事务开始的顺序。
第四:binlog不是循环使用,在写满或者重启之后,会生成新的binlog文件,redo log是循环使用。
第五:binlog可以作为恢复数据使用,主从复制搭建,redo log作为异常宕机或者介质故障后的数据恢复使用。
redo log是恢复在内存更新后,还没来得及刷到磁盘的数据。
binlog是存储所有数据变更的情况,理论上只要记录在binlog上的数据,都可以恢复。
举个例子,假如不小心整个数据库的数据被删除了,能使用redo log文件恢复数据吗?
不可以使用redo log文件恢复,只能使用binlog文件恢复。因为redo log文件不会存储历史所有的数据的变更,当内存数据刷新到磁盘中,redo log的数据就失效了,也就是redo log文件内容是会被覆盖的。
binlog又是在什么时候记录的呢?
答:在提交事务的时候。

三、undo log
undo log的作用主要用于回滚,mysql数据库的事务的原子性就是通过undo log实现的。我们都知道原子性是指对数据库的一系列操作,要么全部成功,要么全部失败。
undo log主要存储的是数据的逻辑变化日志,比如说我们要insert
一条数据,那么undo log就会生成一条对应的delete日志。简单点说,undo log记录的是数据修改之前的数据,因为需要支持回滚。
那么当需要回滚时,只需要利用undo log的日志就可以恢复到修改前的数据。
undo log另一个作用是实现多版本控制(MVCC),undo记录中包含了记录更改前的镜像,如果更改数据的事务未提交,对于隔离级别大于等于read commit的事务而言,不应该返回更改后数据,而应该返回老版本的数据。
补充1:MVCC是什么?有什么作用?
MVCC 的英文全称是 Multiversion Concurrency Control ,中文意思是多版本并发控制技术。原理是,通过数据行的多个版本管理来实现数据库的并发控制,简单来说就是保存数据的历史版本。可以通过比较版本号决定数据是否显示出来。读取数据的时候不需要加锁可以保证事务的隔离效果。
作用:
1.解决读写之间阻塞的问题,通过 MVCC 可以让读写互相不阻塞,读不相互阻塞,写不阻塞读,这样可以提升数据并发处理能力。
2.降低了死锁的概率,这个是因为 MVCC 采用了乐观锁的方式,读取数据时,不需要加锁,写操作,只需要锁定必要的行。
3.解决了一致性读的问题,当我们朝向某个数据库在时间点的快照是,只能看到这个时间点之前事务提交更新的结果,不能看到时间点之后事务提交的更新结果。
补充2:慢日志
几个配置参数:
slow_query_log 慢查询开启状态(1开启,0关闭)
slow_query_log_file 慢查询日志存放的位置(这个目录需要 MySQL 的运行帐号的可写权限,一般设置为 MySQL 的数据存放目录),log-slow-queries(5.6之前版本)
long_query_time 查询超过多少秒才记录
log_queries_not_using_indexes:未使用索引的查询也被记录到慢查询日志中(可选项)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号