

OO第三单元总结
一、设计策略
第一次作业
第一次作业比较简单,要求通过给定的JML规格实现自己的类,包括Person类与Network类以及四个异常类。
1. 异常类实现
异常类需要记录该异常的总发生次数和该id导致的发生次数,故新建一个Count类,其中有一个HashMap<Integer, Integer> 存id与异常的发生次数,一个sum记录总的异常发生次数。在每个异常类中静态实例化一个Count类,即可保证对不同id引起的同一异常都可通过同一个count实例计数。
2. 容器选择
- Person类:acquaintance与value是一一对应的,故使用ArrayLIst存acquaintance和value,使用ArrayList需要注意对acquaintance和value的操作必须同步,不然会有错误。实际上,这里使用HashMap更好,不过当时没怎么想,直接就写了。
- Network类:使用ArrayList存people。
3. 具体实现
由于是第一次作业,以为一定要按照JML的规格来写,导致很多方法并未优化,而是完全按照JML规格来写。当时写完还沾沾自喜,以为很简单,殊不知这是一个大坑。
Network类中的isCircle()的方法使用bfs方法,queryBlockSum()方法也使用O(n^2)的实现,导致了之后的超时。
第二次作业
第二次作业较第一次作业,新增了Group类与Message类以及相关的异常类。其中异常类的实现与第一次上面相同,不再赘述。
1. 容器选择
- Person类:由于每个人的id不一样,故使用HashMap<Integer, Person> 存acquaintance,使用HashMap<Integer, Integer> 存value。此外,由之后的方法可知,使用ArrayList存messages。
- Group类:使用HashMap<Integer, Person>存people。
- Network类:使用HashMap<Integer, Person>存people,HashMap<Integer, Group>存groups,HashMap<Integer, Message>存messages。
2. 具体实现
吸取了第一次作业的教训,第二次作业对一些复杂度高的方法实现了优化。
- Network类
- isCircle():采用了并查集算法,新建一个属性HashMap<Integer, Integer> 记录父节点,新建一个属性count记录并查集个数,新建一个方法union()合并两个并查集,新建一个方法find()寻找一个节点的根节点。判断isCircle()只需判断两个节点的根节点是否为同一个点。
- queryBlockSum():同上,只需要返回count的值即为并查集个数。
- Group类
- getValueSum():定义了一个属性valueSum,在加入人的时候新增,删除人的时候减去,返回valueSum/people.size()。这个方法存在一个bug,即新成员在加入时与一些人没有联系,加入之后有联系,这样一来就会导致valueSum的不准确。
- getAgeVar(),getAgeMean(),getValueSum():并未优化,在本次作业中未出现问题,第三次作业导致超时。
第三次作业
第三次作业相较于第二次作业,新增了三个Message的子类EmojiMessage类、NoticeMessage类、RedEnvelopeMessage类,以及相应的异常类。
1. 容器选择
- Person类:由于每个人的id不一样,故使用HashMap<Integer, Person> 存acquaintance,使用HashMap<Integer, Integer> 存value。此外,由之后的方法可知,使用ArrayList存messages。
- Group类:使用HashMap<Integer, Person>存people。
- Network类:使用HashMap<Integer, Person>存people,HashMap<Integer, Group>存groups,HashMap<Integer, Message>存messages,ArrayList存emojiIdList,HashMap<Integer, Integer>存emojiHeatLIst。
2. 具体实现
与第二次相同的方法不再赘述。
- Network类
- deleteColdEmoji():这里需要注意不能在遍历HashMap时删除,而是等遍历完成后一起删除。
- sendIndirectMessage():新建一个Edge类,存起点的id,终点的id,两点之间边的权重。本质是两点之间的最短路径问题,采用堆优化的Dijkstra算法,避免超时。
基于JML规格来设计测试的方法和策略
通过理论课的学习和查阅相关的资料,主要了解接触了OpenJML、JMLUnitNG、JUnit和对拍等测试方法。
OpenJML
OpenJML最基本的功能是对JML规格的完整性进行检查,包括类型检查、变量可见性与可写性的检查等。可利用命令行通过以下语句使用OpenJML对指定的类进行检查。
openjml [-check] options files
JMLUnitNG
JMLUnitNG是用于带有JML规格的Java代码的自动化单元测试生成工具,主要是生成边界数据进行测试。
JUnit
JUnit是一个Java语言的单元测试框架,并且IDEA集成了JUnit作为单元测试的工具,使用起来相比OpenJML和JMLUnitNG更加方便。因此,我在本单元作业中重点利用JUnit进行了单元测试,通过编写测试类,手动构造基本的样例进行基本功能的检查。通过JUnit单元测试,可以在一定程度上测试代码的正确性,但在实际使用过程中也有一些弊端,例如,手动构造的样例无法覆盖所有可能的情况,而且随着功能的增加,编写测试类的代码量也越来越大,由此可见,测试代码的正确性并非易事。
对拍
在之前的作业中,已经使用过对拍的方法进行测试,通过“自动生成数据 + 对不同实现方法的代码输出进行对比”的方法是一个高效而且相对省力的测试方法,对于本单元的作业也是如此。其中,数据生成的策略分为两种,一种是随机生成所有的指令,另一种是先执行多个ap和ar指令,构造基本的关系网络,再随机生成其他指令。随机的策略更多地测试各种异常,而构造的策略则可以更多地测试与Group和Message相关的指令。
容器选择和使用经验
从本单元的作业可以看出,不能简单的按照JML规格来用数组存数据,而应该考虑到增、删、改、查等操作再合理的选用容器。对于经常需要查操作的数据,我们应该采用HashMap,而对于经常需要增操作且有序的数据来说,我们应该采用ArrayList。
本次作业中的属性大多需要多次查操作,故使用HashMap,Person类中的messages与Network类中的emojiIdList需适合ArrayList。
性能分析
由于三次作业是迭代的,故选用第三次作业来进行性能分析。
- Group类
- getValueSum():如果简单的遍历两遍people,则复杂度为O(n^2),会导致超时,这也是我第三次作业错误。为了避免这样的情况,我们应该采用遍历一遍people,再遍历一遍person的acquaintance,相对于peop来说,acquaintance明显是更小的,复杂度一般为O(an)。其中a为acquaintance的平均大小。数据集越大,其性能差越明显。
- getAgeMean():若先遍历people取得所有人的年龄和再求年龄平均数,复杂度为O(n)。正确做法应该是新增一个属性ageSum记录年龄和,当增、删时ageSum也相应增删,返回ageSum/people.size(),复杂度为O(1)。
- getAgeVar():若先遍历people再求年龄方差,复杂度为O(n)。正确做法应该是新增一个属性age2Sum年龄平方和,当增删时age2Sum也相应增删,返回(age2Sum - 2 * ageSum * getAgeMean() +people.size() * getAgeMean() * getAgeMean()) / people.size(),复杂度为O(1)。
- Network类
- isCircle()、queryBlockSum():若按JML的规格实现,则复杂度为O(n^2),采用并查集算法,可将复杂度降为O(n)。
- sendIndirectMessage():若使用传统的Dijistra算法,则复杂度为O(n^2),采用堆优化的Dijistra算法,可将复杂度降为O(nlogn)
架构设计
整体架构
由于三次作业是迭代的,故只给出第三次作业的架构。
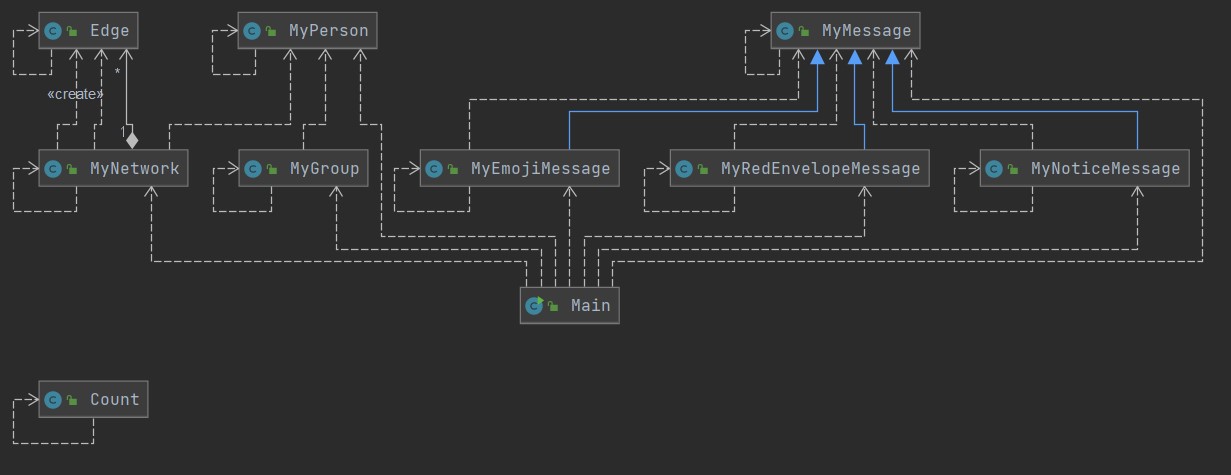
本次作业的架构基本与官方接口一致,并未有太大的改动。由于实现异常类的需求而新增了一个Count类,由于第三次作业的最短路径需求,新增了一个Edge类,其余基本都是实现官方的接口。
图模型构建与维护
图模型的构建包括了添加人、添加关系、添加组、添加消息。
图模型的维护包括了添加人到组、从组中删除人、发送消息、删除不常用表情、发送间接消息。
为了优化,构建的图模型中还有并查集和Dijistra操作。
并查集算法:增加了HashMap存的father属性以及并查集个数count,find()方法用于寻找节点的根节点,union()用以联合两个节点所在的并查集。
Dijistra算法:增加了HashMap存的edges属性,表示了节点和与节点相连的边的关系。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号