
duckdb索引介绍
duckdb支持的索引类型
注:duckdb在sql和语法方法更接近postgresql,其sql解析器就是使用的postgresql剥离出来的libpq_query,所以并非mysql和sqlite源,虽然它做了sqlite3兼容层,但是是为了c api能够直接复用、仅此而已。
duckdb支持两种索引:Min-Max Index (Zonemap)和Adaptive Radix Tree (ART)。
前者所有通用数据类型(general-purpose data types,也就是常用的数据类型如varchar/json/timestamp/boolean/integer/date等,非通用类型指的是set/list/array/struct等复合类型)的字段上都包含,因为duckdb是列存,所以每个列所在的块(256kb)头中维护了本块里面当前字段的最大和最小值,以便于快速过滤(列存数据结构对应的访问sdk通常支持pushdown,访问具体内容之间先做检查,便于无用功访问。除了最大最小值,通常还包括很多其它元数据如数量、唯一值数量、空值数量等,都是为了快速过滤。为什么行存没有min-max index,因为多个字段、自然没办法维护,总不能为每个字段都维护,虽然理论上可行,但是每行通常几十甚至上百个字段,一个块内没几行记录,存一下貌似效果不大),这就是Min-Max Index (Zonemap)。
ART索引主要是用于主键、唯一键的维护,当然也可以普通索引,CREATE INDEX默认创建的就是ART索引。而duckdb选择art索引的主要考虑是它是进程内OLAP,绝大部分数据都应该能够在内存,索引也按照完全cache在内存实现,所以追求内存性能最大化的考虑选择art索引而不是b+树索引。
数据有序性对zonemap的影响
和b+树索引一定程度上类似,数据越有序,索引效果越好。只不过对于列存如duckdb(doris\parquet都一样)而言,数据越有序,chunk内压缩效率越好、过滤能力也越好。而数据很随机的话,很可能zonemap中记录的是每个块都有符合条件的记录,自然zonemap效果就很差了。如下所示:
| Column type | Ordered | Storage size | Query time |
|---|---|---|---|
DATETIME |
yes | 1.3 GB | 0.6 s |
DATETIME |
no | 3.3 GB | 0.9 s |
ART索引的优化器参数
默认情况下,duckdb选择art索引与否的判断阈值是MAX(2048, 0.001 * table_cardinality),该值由参数index_scan_percentage和index_scan_max_count控制。
ART索引的限制
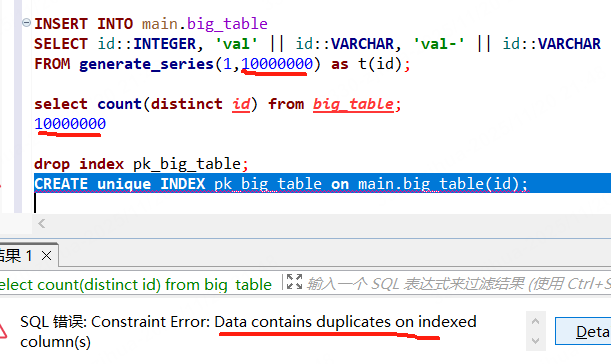
1、速度奇慢无比。如下1000w表的update 17分钟还没完成(这还是我没加唯一限制):
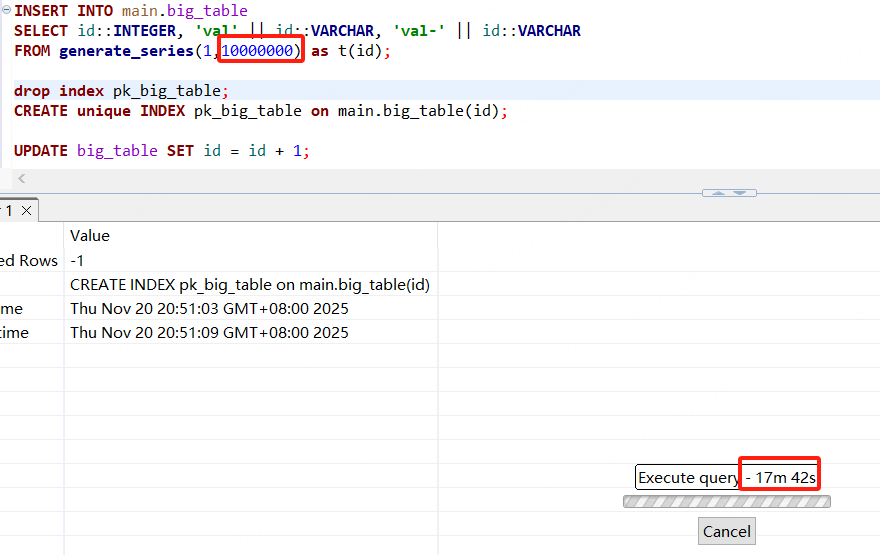
下面创建唯一索引,明明数据唯一,缺提示包含重复值。
2、单次更新不能超过duckdb vector(和chunk一个意思,可以交换用,文档中喜欢叫vector,代码中用chunk,其实代码中也有不少vector,反正一个意思)的大小(默认2048,修改需要改源码重新编译),否则唯一索引会报Duplicate key "i: 2048" violates primary key constraint.。因为duckdb按照chunk为单位进行更新,也没有维护全局索引的概念。
3、创建art索引的时候,内存必须有足够的空间容纳整个art索引,art索引最后还是持久化到磁盘的,和b+树索引没有区别,都是value-rowid对的形式。
duckdb索引内存的管理
DuckDB 通过其缓冲区管理器来注册索引内存。然而,这些索引缓冲区目前尚未由缓冲区进行管理。这意味着如果 DuckDB内存紧张,它不会销毁任何索引缓冲区。因此,索引可能会占用 DuckDB 可用内存的很大一部分,这有可能影响内存密集型查询的性能。重新附加(先分离再附加)包含索引的数据库可以减轻这种影响,因为我们是以延迟方式序列化、反序列化索引内存(选择ART索引也是因为它是纯内存索引,跟hyperdb索引一样)。在进行更改后禁用索引扫描并重新附加,能进一步降低索引对 DuckDB 可用内存的影响。
综上所述,duckdb的art索引目前是比较鸡肋的。除非业务必须要求使用主键索引,否则最好是应用层维护。
https://duckdb.org/docs/stable/sql/indexes
https://duckdb.org/docs/stable/guides/performance/indexing

 浙公网安备 33010602011771号
浙公网安备 33010602011771号