

转载请注明出处:https://www.cnblogs.com/zhizaixingzou/p/10023948.html
目录

1. 序列化
1.1. 序列化的使用
1.1.1. Java序列化机制
所谓序列化,乃是一种编码方式。
Java序列化API为处理对象序列化提供了一个标准机制。

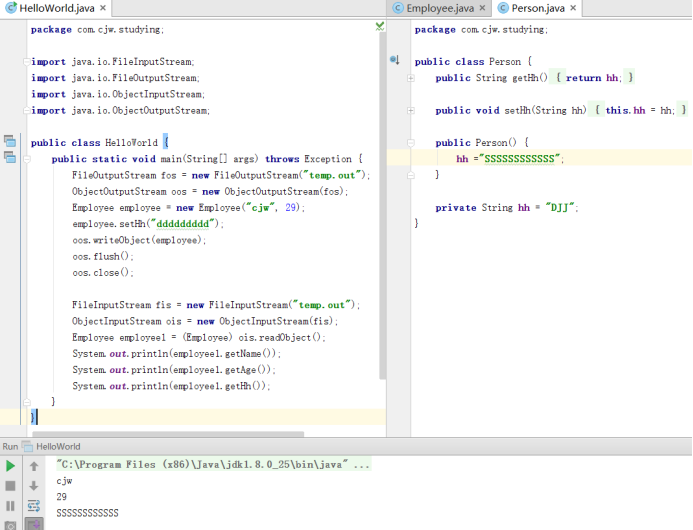
1)需要被序列化的类Employee需要实现Serializable接口,该接口是个标记接口。
2)反序列化时,直接使用字节将Employee对象还原出来的。
3)反序列化时,必须确保该读取程序的classpath中包含有Employee.class,哪怕读取程序中并未出现Employee类(读取得到的是Object类),否则会抛出ClassNotFoundException。
4)如果仅仅只是让某个类实现Serializable接口,而没有其它任何处理的话,则就是使用默认序列化机制。使用默认机制,在序列化对象时,不仅会序列化当前对象本身,还会对该对象引用的其它对象也进行序列化(前提是也实现了Serializable接口),同样地,这些其它对象引用的另外对象也将被序列化,以此类推。所以,如果一个对象包含的成员变量是容器类对象,而这些容器所含有的元素也是容器类对象,那么这个序列化的过程就会较复杂,开销也较大。
5)被写对象的类型是String,或数组,或Enum(枚举类型都会默认继承类java.lang.Enum,而该类实现了Serializable接口),或Serializable,那么就可以对该对象进行序列化,否则将抛出NotSerializableException。
6)serialVersionUID一致才能反序列化成功,反序列化端少了字段,反序列化正常,只是多序列化的字段不在最终对象里。反序列化端多了字段,反序列化也正常,只是多出的字段都使用对象类型的默认值。
7)被声明为transient的成员变量不会被序列化,反序列化时用类型默认值。
8)序列化时可以写入多个对象,反序列化时可以按对应的顺序读取这些对象。
9)写对象时,如果将它类型转换为父类,序列化时依旧还是保留本类,反序列化时依旧需要在classpath中有本类存在才行,否则抛出异常ClassNotFoundException。
SerialTest st = new SerialTest();
oos.writeObject((parent)st);
10)如果序列化类的父类没有实现序列化接口,那么反序列化时对应的父类值由它的无参数构造函数决定。
11)序列化的是对象的状态,即它的成员变量才会保存,不会序列化静态变量。持久化的数据均为存在于堆中的数据,static类型的数据存在于方法区中,不能被持久化。
1.1.2. 可选的序列化定制:实现Serializable接口
如果我们想要更改存储数据的方式,比如说在对象中含有一些敏感信息,在存储、获取它们之前我们要进行加密、解密。或者,序列化类中实现transient修饰的成员变量的序列化:

1)它是通过反射实现的,也就是ObjectInputStream调用readObject的时候,会调用待序列化对象的对应私有方法。
2)还有其他三个方法,可供我们定制自己的序列化反序列化过程:
private void readObjectNoData() throws ObjectStreamException
用于初始化反序列化对象,当发生一些情况导致反序列化对象不能获得数据时调用。
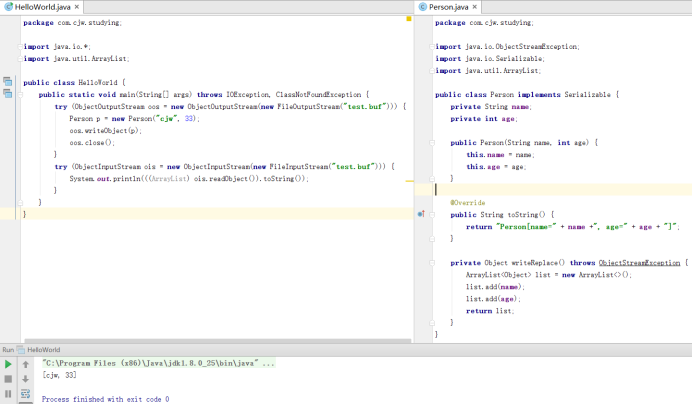
ANY-ACCESS-MODIFIER Object writeReplace() throws ObjectStreamException
如果序列化类实现了该方法,则在序列化时,会先调用writeReplace方法,并使用它返回的对象替换当前对象写入流中。该方法返回的对象,必须是可序列化的。一旦实现了writeReplace就不再需要writeObject和readObject了,它们会被忽略。
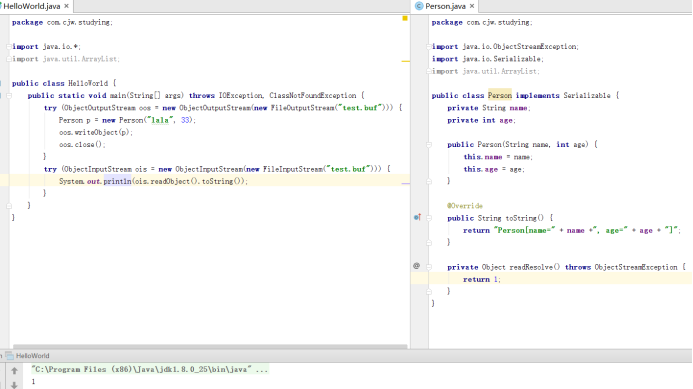
ANY-ACCESS-MODIFIER Object readResolve() throws ObjectStreamException
首先调用默认的readObject得到对象,如果该方法存在则调用该方法,通过this访问到刚才反序列化得到的对象的内容,并处理得到自己想要的任意一个对象,可以是非原始类的,并最为最终的实例返回。常用于单例和枚举值的恢复。
1.1.3. 强制的序列化定制:实现Externalizable接口
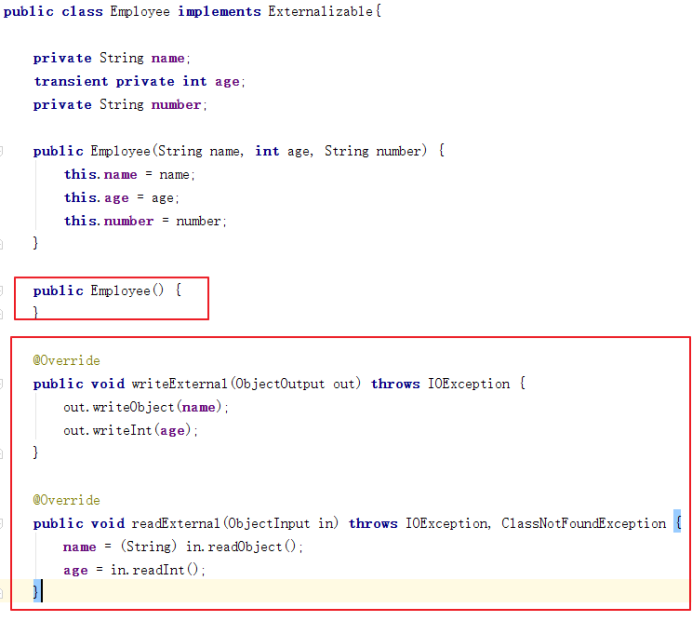
1)Externalizable继承于Serializable,当使用该接口时,序列化的细节需要由程序员去完成,而非使用默认的序列化机制。
2)反序列化过程会调用类的无参构造器(须为public)创建一个新对象,然后再将被保存对象的字段的值分别填充到新对象中。
3)对应的两个方法内的对应的方法与writeObject和readObject一样的,效率更高些。
1.2. 序列化后的字节序列解读
1)实现的序列化类如下:

2)对应的字节序列及解读如下:
AC ED: STREAM_MAGIC. 声明使用了序列化协议.
00 05: STREAM_VERSION. 序列化协议版本.
0x73: TC_OBJECT. 声明这是一个新的对象.
0x72: TC_CLASSDESC. 声明这里开始一个新Class。
00 0A: Class名字的长度.
53 65 72 69 61 6c 54 65 73 74: SerialTest,Class类名.
05 52 81 5A AC 66 02 F6: SerialVersionUID, 序列化ID,如果没有指定,
则会由算法随机生成一个8byte的ID.
0x02: 标记号. 该值声明该对象支持序列化。
00 02: 该类所包含的域个数。
0x49: 域类型. 49 代表"I", 也就是Int.
00 07: 域名字的长度.
76 65 72 73 69 6F 6E: version,域名字描述.
0x4C: 域的类型.
00 03: 域名字长度.
63 6F 6E: 域名字描述,con
0x74: TC_STRING. 代表一个new String.用String来引用对象。
00 09: 该String长度.
4C 63 6F 6E 74 61 69 6E 3B: Lcontain;, JVM的标准对象签名表示法.
0x78: TC_ENDBLOCKDATA,对象数据块结束的标志
0x72: TC_CLASSDESC. 声明这个是个新类.
00 06: 类名长度.
70 61 72 65 6E 74: parent,类名描述。
0E DB D2 BD 85 EE 63 7A: SerialVersionUID, 序列化ID.
0x02: 标记号. 该值声明该对象支持序列化.
00 01: 类中域的个数.
0x49: 域类型. 49 代表"I", 也就是Int.
00 0D: 域名字长度.
70 61 72 65 6E 74 56 65 72 73 69 6F 6E: parentVersion,域名字描述。
0x78: TC_ENDBLOCKDATA,对象块结束的标志。
0x70: TC_NULL, 说明没有其他超类的标志。.
00 00 00 0A: 10, parentVersion域的值.
00 00 00 42: 66, version域的值.
0x73: TC_OBJECT, 声明这是一个新的对象.
0x72: TC_CLASSDESC声明这里开始一个新Class.
00 07: 类名的长度.
63 6F 6E 74 61 69 6E: contain,类名描述.
FC BB E6 0E FB CB 60 C7: SerialVersionUID, 序列化ID.
0x02: Various flags. 标记号. 该值声明该对象支持序列化
00 01: 类内的域个数。
0x49: 域类型. 49 代表"I", 也就是Int..
00 0E: 域名字长度.
63 6F 6E 74 61 69 6E 56 65 72 73 69 6F 6E: containVersion, 域名字描述.
0x78: TC_ENDBLOCKDATA对象块结束的标志.
0x70:TC_NULL,没有超类了。
00 00 00 0B: 11, containVersion的值.
3)序列化字节序列里的内容总结:
首先会有序列化协议的标识和协议版本。
不同的对象会有标识分隔。
序列化类名及serialVersionUID、域名及其类型和值。
父类和祖先类、引用成员的信息。
1.3. 序列化的概念
Java序列化是指把Java对象转换为字节序列的过程,而Java反序列化是指把字节序列恢复为Java对象的过程。
序列化又称串行化。
1.4. 序列化的需求场景
1)通过序列化把Java对象转换为字节序列以便可以在网络上传送两进程间的消息,也可以在RMI时用到。
2)Java对象的生命周期不会比JVM长,为了在JVM停止后继续用,需要将对象持久化。
3)对象的深度克隆。
1.5. 理解serialVersionUID
1.5.1. serialVersionUID的作用
Java的序列化机制是通过判断序列化类的serialVersionUID来验证序列化类本身的版本一致性的。也就是说,在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地序列化类的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就抛出异常java.io.InvalidCastException。
如果序列化端和反序列化端serialVersionUID不一致,那么会报类似下面的异常:

即抛出java.io.InvalidCastException异常,同时指明本地类的serialVersionUID和字节流里的serialVersionUID的具体值,可以看到不一致的情况。
1.5.2. serialVersionUID的指定
当实现java.io.Serializable接口的类(序列化类)没有显式地指定一个serialVersionUID的时候,Java序列化机制会根据编译的Class文件自动生成一个serialVersionUID,这种情况下,如果Class文件没有发生变化,即使增加空格、换行、增加注释等等,就算再同一编译器编译多次,serialVersionUID也不会变化的。
但是,我们建议在序列化类中都应该显示地指定一个serialVersionUID,因为若非如此,JVM会基于Class文件,根据自己的算法生成一个,不同的JVM算法不同,生成的serialVersionUID也不同,导致同一个类在反序列化端的不可读,如最常见的就是客户端JVM生成的对象传到了服务端JVM就不能反序列化了。(不显示指定,那么字段新增或减少都会生成不同的serialVersionUID,相反,指定后增加或减少字段都不影响反序列化)
serialVersionUID有两种显示的生成方式:
一是默认的1L,比如:private static final long serialVersionUID = 1L
二是根据类名、接口名、成员方法及属性等来生成一个64位的哈希字段,比如:
private static final long serialVersionUID = xxxxL
64位的哈希字段serialVersionUID的生成有两种方式:
1)利用JDK的bin目录下的serialver.exe工具
比如对于Address.class,执行命令:
E:\workspace\target\classes>serialver Address
Address: static final long serialVersionUID = -687991492884005033L;
该方法是根据类名、接口名、成员方法及属性等来生成哈希字段的。
2)借助IntelliJ IDEA
先在设置窗口,勾选如下选项:
File->Settings->Editor->Inspections->Java->Serialization issues->Serializable class without ’serialVersionUID’
然后,在目标类上Alt+Enter:

回车后自动生成:
private static final long serialVersionUID = -4942861438344653366L;
1.6. Kryo序列化框架
1.6.1. 下载
http://search.maven.org/#search%7Cga%7C1%7Ccom.esotericsoftware.kryo
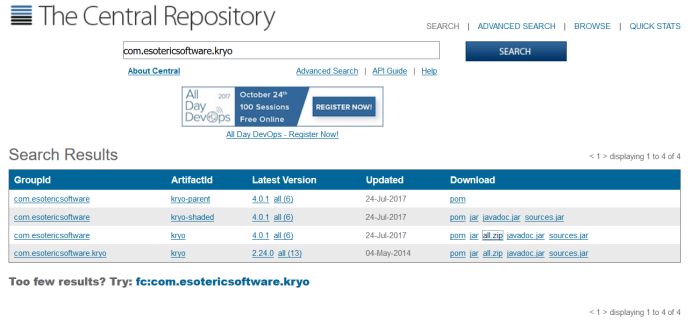
1.6.2. 引入项目

1.7. FAQ
1.7.1. 如果父类可序列化,但你不需要继承类为可序列化
如果你不希望继承类为可序列化,那么你需要实现自己的 writeObject() 和readObject() 方法,并且需要抛出NotSerializableException 异常。
1.8. 参考资料
http://www.importnew.com/24490.html
http://www.cnblogs.com/redcreen/articles/1955307.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号