

统计学习二:2.感知机代码实现
通过上文可知感知机模型的基本原理,以及算法的具体流程。本文实现了感知机模型算法的原始形式,通过对算法的具体实现,我们可以对算法有进一步的了解。具体代码可以在我的github上查看。
代码
#!/usr/bin/python3
# -*- coding:utf-8 -*-
import copy
import numpy as np
# learning step
ETA = 1
weight = [1, 2]
bias = -1000
training_data = []
testing_data = []
def general_data(count):
'''
随机生成数据点及标签,选择80%的数据为训练数据,20%的数据为测试数据
param: count: total data count
return: nothing
'''
# 用于生成标签使用的weight和bias值,实际在训练后得到的weight和bias值可能和它们不同
weight_correct = [3, 5]
bias_correct = -1000
# 随机生成count个点,点横纵坐标的值在[0, 300]之间
tmparray = np.random.randint(low = 0, high = 300, size = (count, 2))
# 计算和设置标签
total_data = []
for x in tmparray:
y = x[0] * weight_correct[0] + x[1] * weight_correct[1] + bias_correct
if y > 0:
total_data.append([[x[0], x[1]], 1])
else:
total_data.append([[x[0], x[1]], -1])
# 选择训练数据和测试数据
global training_data, testing_data
cnt = int(len(total_data) - (len(total_data) * 0.2))
training_data = copy.deepcopy(total_data[0:cnt])
testing_data = copy.deepcopy(total_data[cnt:len(total_data)])
def update(item):
'''
利用误分类点进行参数的更新
param: item: 误分类点
return: nothing
'''
global weight, bias, history
weight[0] = weight[0] + ETA * item[1] * item[0][0]
weight[1] = weight[1] + ETA * item[1] * item[0][1]
bias = bias + ETA * item[1]
def cal(item):
'''
计算损失,返回结果为正说明分类正确,返回结果为负说明分类错误
param: item: 一个实例
return: result: 损失
'''
result = 0
for i in range(len(item[0])):
result += weight[i] * item[0][i]
result += bias
result *= item[1]
return result
def check(data):
'''
判断传入的数据集中有无误分类点,并进行训练,返回结果标记
param: data: 训练数据集
return: flag: True, 训练集中无误分类点
False, 训练集中有误分类点
'''
flag = True
for item in data:
if cal(item) < 0:
update(item)
flag = False
return flag
def train(data):
'''
利用训练集训练模型
param: data: 训练集
return: noting
'''
# 最多利用训练集进行一千次训练
for i in range(1000):
if check(data):
break
else:
#显示模型参数更新过程
print("Training times:", i)
print(weight, bias)
def test(data):
'''
测试模型的分类效果,返回准确率
param: data: 测试集
return: accuracy
'''
correct = 0
for item in data:
if cal(item) > 0:
correct += 1
return correct / len(data)
if __name__ == "__main__":
general_data(1000)
train(training_data)
accuracy = test(testing_data)
print("The accuracy is ", accuracy)
测试结果
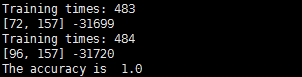
通过测试结果我们可以看到,模型在第484次训练后结束,获得的模型参数与我们生成数据时的参数相差很大。但测试结果为1.0,这说明这个模型同样具有较好的分类效果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号