python 使用正则表达式
在python中 正则的操作在 re 模块中
常用方法
import re
# 第一个参数 匹配规则 第二个参数 需要匹配的字符串
# re.match()
# re.search() 只对字符串查询一次 返回值类型 都是 re.Match 不同点 match 是从头开始 一旦匹配失败 返回None search 是在整个字符串中查找
# re.findall() 得到所有匹配到的字符串 放入列表中
# re.finditer() 查找所有的匹配到的字符的下标 返回一个可迭代对象
# re.fullmatch() 需要完全匹配
re.Match 类
m = re.search('h','hello')
print(m.pos,m.endpos) # 返回的是 字符串长度 0 5
print(m.span()) # 返回的开始 和 结束下标 (0, 1)
print(m.group()) # 返回的是 得到的字符串 h 可以传参 组 以() 分离的正则规则
m.groupdict() # 获得分组组成的字典 (?P<xxx>*) xxx 和其匹配的字符
re.compile 方法的使用
m = re.search('h','hello')
print(m) # <re.Match object; span=(0, 1), match='h'>
x = re.compile('h') # 正则规则
print(x.search('hello')) #<re.Match object; span=(0, 1), match='h'>
正则替换
# 第一个参数是正则表达式
# 第二个参数 是新字符或者函数
# 第三个参数 是要替换的字符串
t = 'hfasifh49594asf329'
print(re.sub(r'\d', 'x', t)) # hfasifhxxxxxasfxxx
def text(x):
y = int(x.group(0))
y *=2
return str(y)
print(re.sub(r'\d', text, t)) # 所有的数字乘2 hfasifh81810188asf6418
贪婪模式和非贪婪模式
# 在python中 默认是贪婪模式 尽可能的多匹配 *
m = re.search('h.*l','hello')
print(m) # <re.Match object; span=(0, 4), match='hell'>
# 懒惰模式 尽可能的少匹配 ?
n = re.search('h.?l','hello')
print(n) # <re.Match object; span=(0, 3), match='hel'>
正则表达式
数字 和 字母 表示其自身
| 字符 |
描述 |
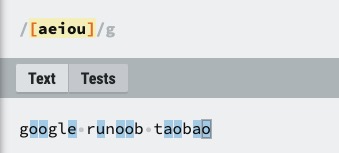
| [ABC] |
匹配 [...] 中的所有字符,例如 [aeiou] 匹配字符串 "google runoob taobao" 中所有的 e o u a 字母。![img]() |
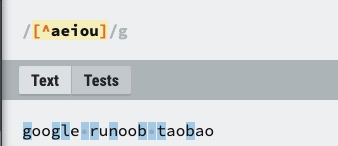
| [^ABC] |
匹配除了 [...] 中字符的所有字符,例如 [^aeiou] 匹配字符串 "google runoob taobao" 中除了 e o u a 字母的所有字母。![img]() |
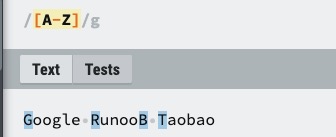
| [A-Z] |
[A-Z] 表示一个区间,匹配所有大写字母,[a-z] 表示所有小写字母。![img]() |
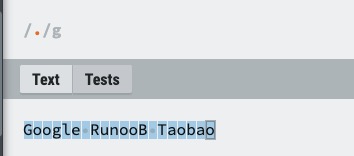
| . |
匹配除换行符(\n、\r)之外的任何单个字符,相等于 [^\n\r]。![img]() |
很多字母前面加 \ 会有特殊含义
| 字符 |
描述 |
| \cx |
匹配由x指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 'c' 字符。 |
| \f |
匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n |
匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r |
匹配一个回车符。等价于 \x0d 和 \cM。 |
| \s |
匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。注意 Unicode 正则表达式会匹配全角空格符。 |
| \S |
匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \t |
匹配一个制表符。等价于 \x09 和 \cI。 |
| \v |
匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
| \d |
匹配数字 等价[0-9] |
| \D |
匹配非数字 等价[ ^0-9 ] |
| \w |
表示数字 字母 及 _ 下划线 |
| \W |
非数字字母下划线 |
大部分标点符号都有特殊含义 如果 要使用 在前面加上 转义字符 \
| 特别字符 |
描述 |
| $ |
匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 '\n' 或 '\r'。要匹配 $ 字符本身,请使用 $。 |
| ( ) |
标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 ( 和 )。 |
| * |
匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 *。 |
| + |
匹配前面的子表达式一次或多次。要匹配 + 字符,请使用 +。 |
| . |
匹配除换行符 \n 之外的任何单字符。要匹配 . ,请使用 . 。 |
| [ |
标记一个中括号表达式的开始。要匹配 [,请使用 [。 |
| ? |
匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,请使用 ?。 |
| \ |
将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, 'n' 匹配字符 'n'。'\n' 匹配换行符。序列 '\' 匹配 "",而 '(' 则匹配 "("。 |
| ^ |
匹配输入字符串的开始位置,除非在方括号表达式中使用,当该符号在方括号表达式中使用时,表示不接受该方括号表达式中的字符集合。要匹配 ^ 字符本身,请使用 ^。 |
| { |
标记限定符表达式的开始。要匹配 {,请使用 {。 |
| | |
指明两项之间的一个选择。要匹配 |,请使用 |。 |
修饰符
| 修饰符 |
含义 |
描述 |
| i |
ignore - 不区分大小写 |
将匹配设置为不区分大小写,搜索时不区分大小写: A 和 a 没有区别。 |
| g |
global - 全局匹配 |
查找所有的匹配项。 |
| m |
multi line - 多行匹配 |
使边界字符 ^ 和 $ 匹配每一行的开头和结尾,记住是多行,而不是整个字符串的开头和结尾。 |
| s |
特殊字符圆点 . 中包含换行符 \n |
默认情况下的圆点 . 是 匹配除换行符 \n 之外的任何字符,加上 s 修饰符之后, . 中包含换行符 \n。 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号