

前段时间由于项目的原因,对一个由于分页而造成性能较差的SQL进行优化,现在将优化过程中学习到关于分页优化的知识跟大家简单分享下。

分页不外乎limit,offset,在这两个关键字中,limit其实不是性能瓶颈的主要原因,如果sql中定义了比较大的limit,说明了确实有一次性取出较多数据的需求,如果不是,就需要考虑limit参数是否需要调整了。这篇文章主要以offset为优化方向,介绍高offset下的性能优化手段。业界主要使用的还是Innodb引擎,本文中的分析和方案主要针对Innodb引擎,其他存储未必适用。
查询执行原理
在开始介绍之前,我们首先写一个最简单的分页sql,并且简单介绍下查询的数据读取原理,以便后面具体解决方案中进行对比。
Query1: select * from table order by id asc limit 1000 offset 9000;
对于这个查询,我们首先来看看它的执行过程。
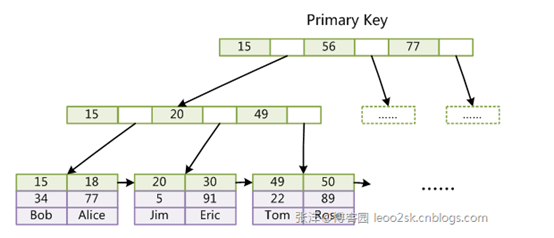
上图是一个Innodb聚簇索引的图示。由于我们的查询没有使用where子句,而且要求返回所有列,所以查询会到聚簇索引中查询。查询在数据库中的扫描过程为:
查询首先会定位到第一条合乎条件的数据,也就是(15,34,Bob)这一行。 然后,根据这个叶子节点的首部信息,可以得知这个叶子节点中有多少行的数据。 如果这个叶子节点的数据达到offset的要求,读出数据直至达到limit要求。 若这个叶子节点无法完成查询,则通过指向兄弟节点的指针,根据排序要求,往下一个兄弟节点继续查询,直到满足limit与offset要求为止。
缓存子查询
我们可以想象一下大多数用户翻页的习惯,一般来说,用户都会一页一页地翻。利用用户的这一习惯,我们可以将上一页的排序的最大/小值进行缓存,然后以此值作为查询传递到下一查询中。 还是以上面的那条sql为例,我们可以把那条sql拆成相同意义的父子查询。我们来看两条查询:
Query2: select * from table order by id limit 1000 offset 8000;
Query3: select * from table where id > (select id from test order by id limit 1 offset 8999) order by id limit 1000;
上面两条sql,2查询了8001~9000行,3查询了9001~10000行,3中的子查询返回了第9000行的id值。3无论意义还是执行过程都与1相同,唯一不同的,就是它是继承于2的。我们可以看到,它是以2的结果数据中,id最大的那条数据为基础进行查询的。也就是说,在上一页查询后,我们可以将第9000条数据的id进行缓存,当需要查询下一页数据时,我们就可以直接将id替换3的子查询。这样遍历就不需要从第1个节点开始,节省了接近9000次的遍历。 注意与缺陷:
- 需要确定sql查询时的数据顺序:数据库对表及索引的维护默认采用升序维护,但在查询使用不同的select对象时,选择的索引是不确定的,所以建议在sql中加上order by子句。
- 数据需要相对静态:如果数据在排序字段上变动频繁,如上例中取出第9000条数据的id进行缓存,但是在进行下一页查询之前,前面任意一条数据被删除,缓存的id就会失效。
覆盖索引法
在查询时,使用聚簇索引进行查询,必定会进行大量的IO。这是,可以考虑使用覆盖索引,将查询IO限定在索引中。在查询时,有时我们实际需要的并不是整行的数据,而只是其中的某几个字段,而当我们select的数据列从索引中已经可以取出,数据库就不会对总表进行查询。 比如现在需要取出资产排名第1000用户的user_id,我们只需要对assets与user_id建立联合索引,查询sql为:
Query4: select user_id from table order by assets desc limit 1 offset 999;
由于查询的where条件与返回列都在同一个索引可以满足筛选和返回的要求,查询不会再到总表中进行大量IO。 这里简单介绍一下覆盖索引优化的原理:
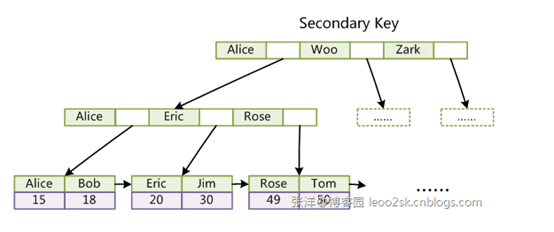
上图是一个Innodb的二级索引存储结构图。图中可以看到,二级索引的叶子节点存储的是最后一级的索引值、id、以及一个指向兄弟节点的指针。我们假设一个块存储一个叶子节点。对于sql④,需要扫描1000个user_id,如果在总表中扫描,由于每行数据占用空间大,假设一个块中能存100行,读取一个块只能扫描100个user_id,需要读取10个块才能完成;但如果将查询限定在索引中,对于上述叶子节点中的数据结构,假设一个块能存储5000个索引值,只需要读取一个块就能完成我们需要的offset 1000了。 若select的列是一个较大的数据列,如一段文本,或需要对全行数据取出时,可以通过子查询先将id查询出来,然后使用id到总表中查询。这是因为在二级索引叶子节点存储了id值,所以id就是一个天生的覆盖索引列。如上例中如果需要将全行数据取出,而不单是user_id一列,查询可以改为(深度学习可以参考:http://www.cnblogs.com/zhiqian-ali/p/4916064.html):
$ = select id from table order by assets desc limit 1 offset 999; select * from table where id = $; or select * from table a,( select id from table order by assets desc limit 1 offset 999 ) b where a.id=b.id;
反向查找法
在使用offset进行查询时,参数值的大小对查询性能的影响非常大:当offset参数较小时,查询的性能非常高;但当offset的值逐渐增长,查询的耗时开始变得不可控制,需要一个方法将高offset查询的性能进行控制。优化的方法其实很简单:在一个1000行的表中,顺着数第1000条的数据,也正是倒着数第1条的数据。我们只需要将数据进行倒序遍历,就可以将原本线性增长的查询耗时,转变为一个中间高、两头低的性能曲线了。如上述查询可优化为:
$ = select count(*) from table; select * from table order by assets desc limit 1 offset ($ - 999);
在测试反向查找法的过程中,发现耗时最高的并不是在50%的位置,而是在60%的位置。这是因为在按照索引排序的顺序进行遍历时,索引的排布顺序与磁盘读取一致。当索引比较紧凑地存储在连续的几个块时,由于磁盘预读,在一次IO中多个有效块会被读出,而反向遍历时则无法享受磁盘预读带来的IO优化。 磁盘预读的优势依赖于索引的连续排布。当索引频繁移动时,数据的连续排布无法得到保证。在决定反向遍历临界值时,需要考虑数据索引值变动的频率的影响。若重建索引的是允许的,可以定期进行索引重建,使得索引紧密排布。
反向查找法存在一个比较致命的缺陷,就是需要对表进行count的操作:要想确定反向offset参数,必须先获得总数量。对于行数量比较稳定的表,可以直接使用定时刷新的缓存值;对于不需要进行事务操作的表,可以考虑采用MyISAM引擎;而对于其他情况,目前还没找到比较好的解决方案。
总结
上述的几个方法各有优劣,没有办法选出一个解决分页性能瓶颈的万金油,需要结合实际应用场景进行一个或多个方案选用。
- 缓存子查询的方法适用于顺序翻页的场景,但要求数据在指定排序上的序号是稳定的,才能保证缓存值有效。
- 覆盖索引是一个适用性比较强的方法,与常用的利用索引优化查询性能的方案一样,它的缺点在于表修改时的性能下降,而且如果索引列的数据需要频繁更新,会导致索引排布不整齐,查询性能波动。
- 反向查找法可以对偏移量较大的查询进行优化,但需要进行较高耗时的count查询,对于count查询的优化,目前只想到缓存与使用MyISAM引擎的办法。
上述知识大部分通过网络的资料搜集,结合实验测试进行总结,并没有实际考察Mysql中的代码实现,如存在错误请帮忙订正。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号