python基础入门(八)
python基础入门(八)
一、数据类型内置方法之字典
dict()
字典中K值一般为字符串,只有是不可变数据类型就行。
字典中,K:V键值对是无序的。
1、按k取值(不推荐使用)
l1 = {'name': 'jason', 'pwd': 123, 'hobby': 'read'}
print(l1['name']) # jason
print(l1['phone']) # KeyError: 'phone',K值不存在会直接报错
2、按内置方法get取值(推荐使用)
get()
l1 = {'name': 'jason', 'pwd': 123, 'hobby': 'read'}
print(l1.get('name')) # jason
print(l1.get('age')) # None, k值不存在不会报错
print(l1.get('name', '没有哟 嘿嘿嘿'))
# jason 键存在的情况下获取对应的值
print(l1.get('age', '没有哟 嘿嘿嘿'))
# 键不存在默认返回None,可以通过第二个参数自定义
3、修改值数据
l1 = {'name': 'jason', 'pwd': 123, 'hobby': 'read'}
l1['name'] = 'kevin' # 修改K值对应的V值
print(l1)
# 输出结果:{'name': 'kevin', 'pwd': 123, 'hobby': 'read'}
# 键在则为修改
l1['age'] = 21
print(l1)
# 输出结果:{'name': 'jason', 'pwd': 123, 'hobby': 'read', 'age': 21}
# 键不在则为新增
4、删除数据
pop()
l1 = {'name': 'jason', 'pwd': 123, 'hobby': 'read'}
l1.pop('name')
print(l1) # 输出结果:{'pwd': 123, 'hobby': 'read'},弹出整个键值对
res = l1.pop('name'),定义变量
print(res) # jason 接收弹出的键值
5、统计字典中键值对的个数
len()
l1 = {'name': 'jason', 'pwd': 123, 'hobby': 'read'}
print(len(l1))
# 3 统计字典中键值对的个数
6、字典三剑客
keys()
l1 = {'name': 'jason', 'pwd': 123, 'hobby': 'read'}
print(l1.keys())
# dict_keys(['name', 'pwd', 'hobby']) 一次性获取字典所有的键
values()
print(l1.values())
# dict_values(['jason', 123, 'read']) 一次性获取字典所有的值
items()
print(l1.items())
# dict_items([('name', 'jason'), ('pwd', 123), ('hobby', 'read')])
# 一次性获取字典的键值对数据
用for循环也能获取字典的键值对数据,但远不如items()快捷
l1 = {'name': 'jason', 'pwd': 123, 'hobby': 'read'}
for i in l1.items():
k, v = i
print(k, v)
# name jason
# pwd 123
# hobby read
7、补充说明
- 快速生成值相同的字典
fromkeys()
print(dict.fromkeys(['name', 'pwd', 'hobby'], 123))
# {'name': 123, 'pwd': 123, 'hobby': 123}
#()中前面部分为键,逗号后面为相同的值
- 当第二个公共值是可变类型的时候,通过任何一个键修改都会影响所有
append()
res = dict.fromkeys(['name', 'pwd', 'hobby'], [])
res['name'].append('jason')
res['pwd'].append(123)
res['hobby'].append('study')
print(res)
#{'name': ['jason', 123, 'study'], 'pwd': ['jason', 123, 'study'], 'hobby': ['jason', 123, 'study']}
# fromkeys()后面是空的数列[] , append()给一个键增加值会给所有的键增加相同的值
setdefault()
user_dict = {
'username': 'jason',
'password': 123,
'hobby': ['read', 'music', 'run']
}
res = user_dict.setdefault('username','tony')
print(user_dict, res)
# {'username': 'jason', 'password': 123, 'hobby': ['read', 'music', 'run']} jason
# username键存在则V值不修改,结果是键对应的值
res = user_dict.setdefault('age',123)
print(user_dict, res)
# {'username': 'jason', 'password': 123, 'hobby': ['read', 'music', 'run'], 'age': 123} 123
# age键不存在则新增键值对,结果是新增的值
popitem()
# 弹出键值对 后进先出
#pop()需指定弹出某个键,popitem()随机弹出,后进先出
eg:
l1 = {'name': 'jason', 'pwd': 123, 'hobby': 'read'}
l1.popitem()
print(l1) # {'name': 'jason', 'pwd': 123}
二、数据类型内置方法之元组
tuple()
支持for循环的数据类型都可以转成元组,元组的索引不会改变绑定的地址。
1、索引取值
l1 = (1,2,3,4,5)
print(l1[1]) # 输出结果:2
2、切片操作
L1 = (1,2,3,4,5,6,7,8)
print(L1[0:5])
# (1, 2, 3, 4, 5),索引切割0到4的数据值
print(L1[:])
# (1, 2, 3, 4, 5, 6, 7, 8),不写数字就默认都要,相当于[],输出L1所有的值
3、间隔、方向
L1 = (1,2,3,4,5,6,7,8)
print(L1[::-1])
# (8, 7, 6, 5, 4, 3, 2, 1) 从右往左取值(全部),[::-1]只说明方向未规定范围
4、统计元组内数据值的个数
len()
l1 = (1, 2, 3, 4, 5)
print(len(l1)) # 输出结果:5
5、统计元组内某个数据值出现的次数
count()
t1 = (11, 22, 33, 44, 55, 66)
print(t1.count(11))
# 1 ,11在t1里只出现了1次
6、统计元组内指定数据值的索引值
t1 = (11, 22, 33, 44, 55, 66)
print(t1.index(22))
# 1 ,在t1中索引,22在1的位置
- 当元组里只有一个数据值的时候,我们一定要在数据值后面加一个逗号。否则,括号里是什么数据类型就是什么数据类型。
l1 = (1)
print(type(l1)) # 输出结果:<class 'int'>
l1 = (1,) # 这里就加了一个逗号,数据类型就发生了变化
print(type(l1)) # 输出结果:<class 'tuple'>
- 元组内索引绑定的内存地址不能被修改(注意区分数据类型可变还是不可变)
- 元组不能新增或删除数据
三、数据类型内置方法之集合
set()
- 集合内数据必须是不可变类型(整型、浮点型、字符串、元组)
- 集合内数据也是无序的,没有索引的概念
- 遇到去重和关系运算这两种需求的时候才应该考虑使用集合
1、去重
集合直接打印就可以得到去重的结果,但无法保留原先数据的排列顺序。
l1 = {1, 2, 3, 3, 4, 3, 2, 3, 4, 1, 3, 4, 3, 4, 5, 5}
print(l1) # 输出结果:{1, 2, 3, 4, 5}
2、关系运算
s与l是两个账号,模拟这两个账号共同好友的情况
s = {'jason', 'oscar', 'kevin', 'ricky', 'gangdan', 'biubiu'}
l = {'kermit', 'tony', 'gangdan'}
print(s & l) # 两个的共同好友
print(s | l) # 所有的名字
print(s - l) # 第一组数据独有的名字
print(s ^ l) # 在两组数据中没有同时出现的数据
- 父集、子集
s = {'jason', 'oscar', 'kevin', 'ricky', 'gangdan', 'biubiu'}
l = {'kevin', 'jason', 'gangdan'}
print(s > l)# true,s包含l,s是l的父集
print(s < l)# False,l不能包含s,l是s的子集
四、字符编码理论
解码、字符编码、编码的概念
-
解码
当我们打开文本文件时,计算机会根据文件的类型,对文件进行一些处理。比如,将一个txt文件由二进制转换为人类可以读懂的文字,这个过程被称为解码。
bytes类型数据.decode()
-
字符编码
在解码过程中,计算机要依赖于一些规则,将指定的二进制位解码为指定的字符。
eg:0110 0001被解码为 小写英文字母 a 。
这个规则被称为字符编码。字符编码有很多种,而前面的例子中用到的编码叫做 ASCII 编码,它是最早产生的字符编码。
-
编码
字符串.encode()
当然,从字符转换为二进制位也要使用字符编码,而这个过程被称为编码。
字符编码发展史
-
阶段一:一家独大
美国科学家在设计字符编码的时,只考虑了使用英语的场景,发明的ASCII编码使用8个二进制位来表达一个字符,只支持现代英语和其他西欧语言,不支持汉语等语言。
部分ASCII对照表:
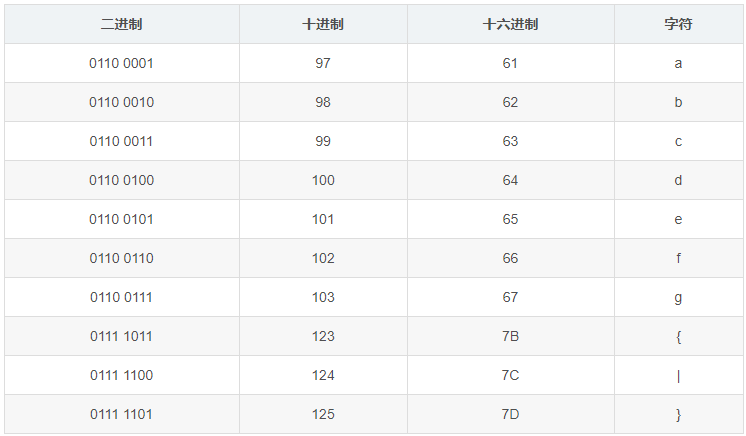
-
阶段二:群雄割据
为了让计算机识别中文字符,中国科学家发明了GBK字符编码,该字符编码使用16位二进制位(但有些生僻字还是不支持),且仅支持英语和汉语。
另一方面,世界上很多国家为了支持本国的语言,各自发明了字符编码。
eg:日本的Shift_JIS、韩国的Euc-kr等。
尽管有如此多的字符编码,但没有一个是通用的,它们大多都只支持本国语言和英语。
-
阶段三:天下归一
为了实现对所有语言的支持,国际组织ISO制定了Unicode字符编码,也叫万国码。支持各国语言,使用16~32位二进制位来对应一个字符。
现代计算机都使用Unicode字符编码,之前的如GBK等编码可以转换为Unicode编码。
UTF是针对Unicode实现的一种可变长度字符编码,比Unicode更加精简,给出了字符保存的编码规则。这些编码中最常用、应用最广的就是utf-8,使用的位数不固定,最小为8位。
至此,utf-8编码成了最流行的字符编码,我们在开发中也应该尽量使用utf-8编码。
python2与python3差异
-
python2默认的编码是ASCII编码,但是开发过程中可能会输入其他语言,但ASCII编码只能支持英语,这时便会出现乱码。解决方法:
方法一、文件头 # encoding:utf8 方法二、字符串前面加u u'你好啊'python3默认的编码是utf系列(unicode)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号