
快速涨粉案例解析
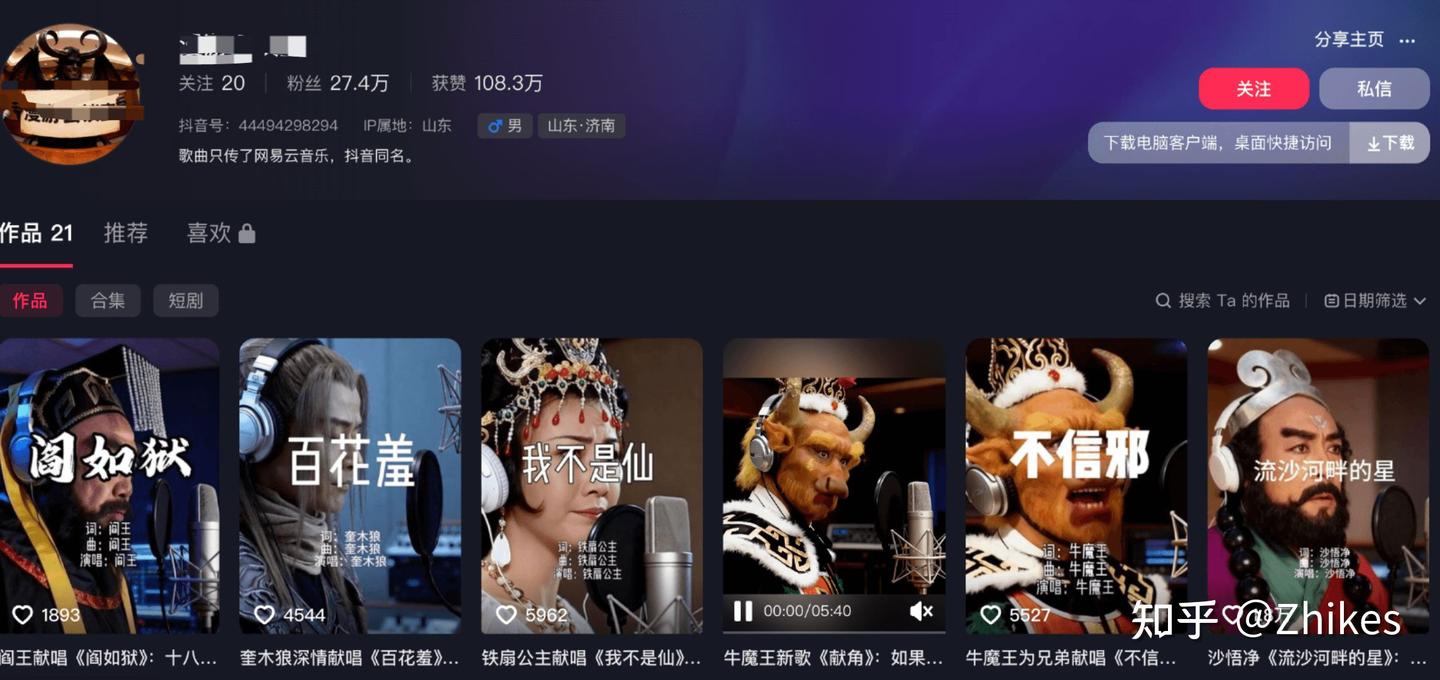
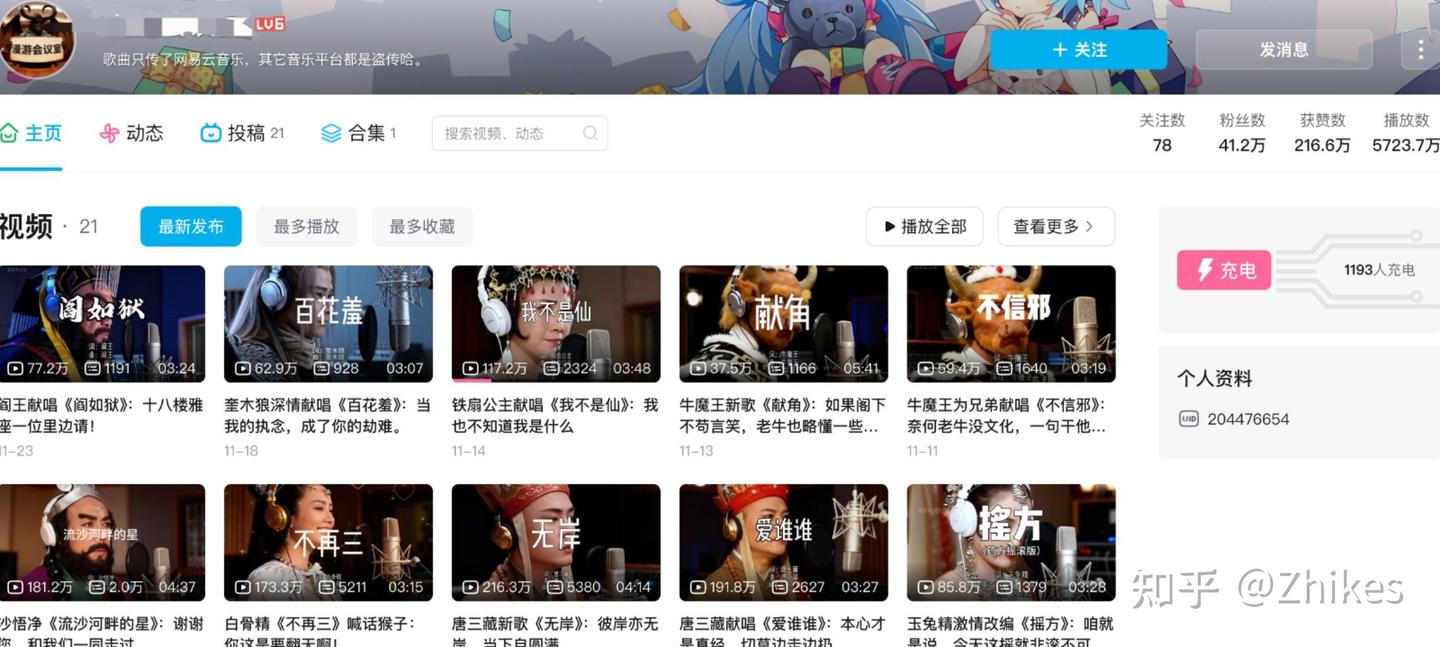
如何制作上面同款呢?下面贴上我复刻的两个示例
只需一张人物照片和一段 AI 生成的歌曲,就能快速做出生动的AI歌唱视频。以下是详细步骤。
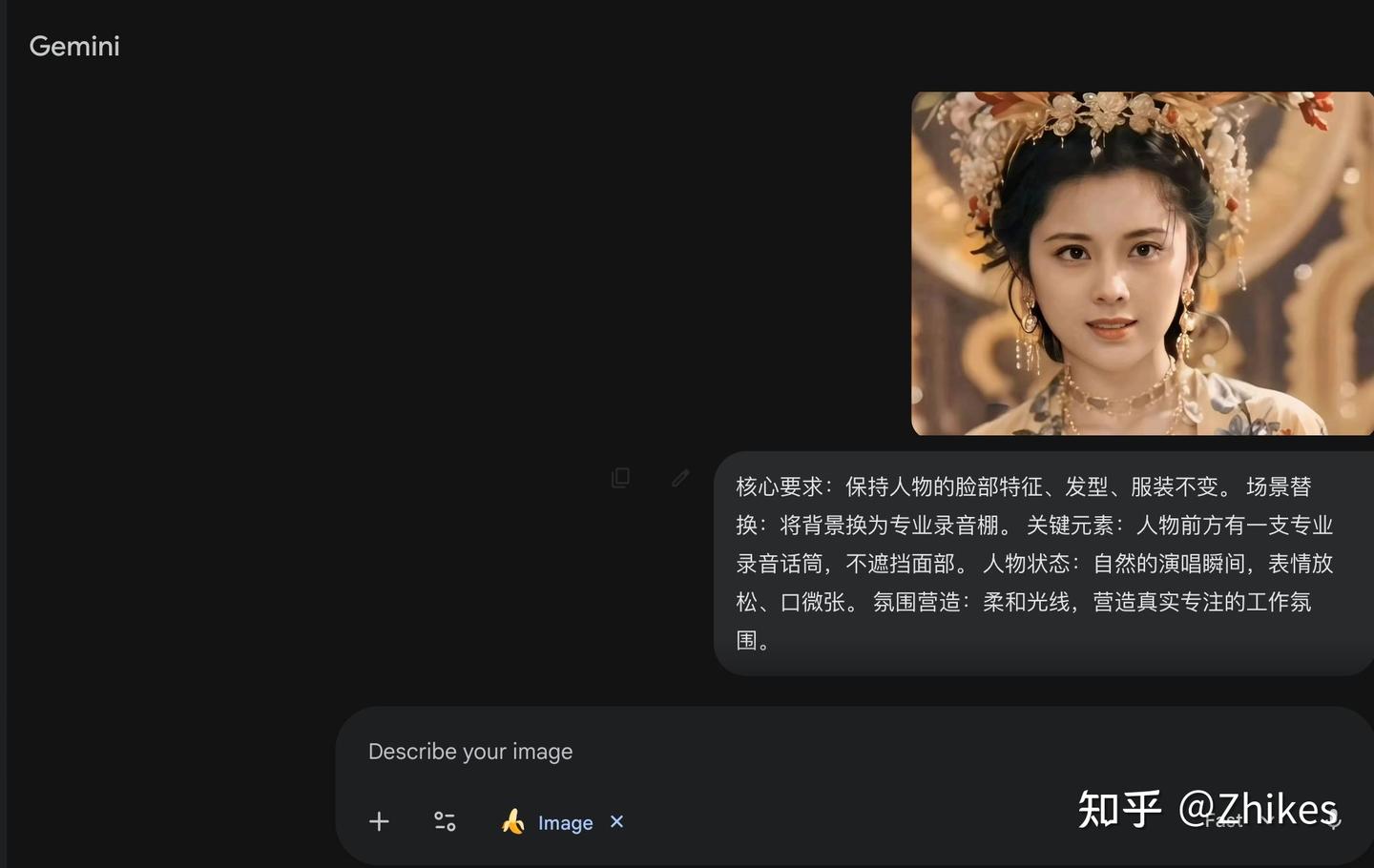
1. 生成人物带麦克风图片
先用 AIGC 工具生成一张人物在麦克风前的照片,常用工具包括 Nano Banana(Gemini)、豆包、千问等。这里以 Nano Banana 为例https://gemini.google.com/app,推荐以下提示词:
核心要求:保持人物的脸部特征、发型、服装不变。 场景替换:将背景换为专业录音棚。 关键元素:人物前方有一支专业录音话筒,不遮挡面部。 人物状态:自然的演唱瞬间,表情放松、口微张。 氛围营造:柔和光线,营造真实专注的工作氛围。
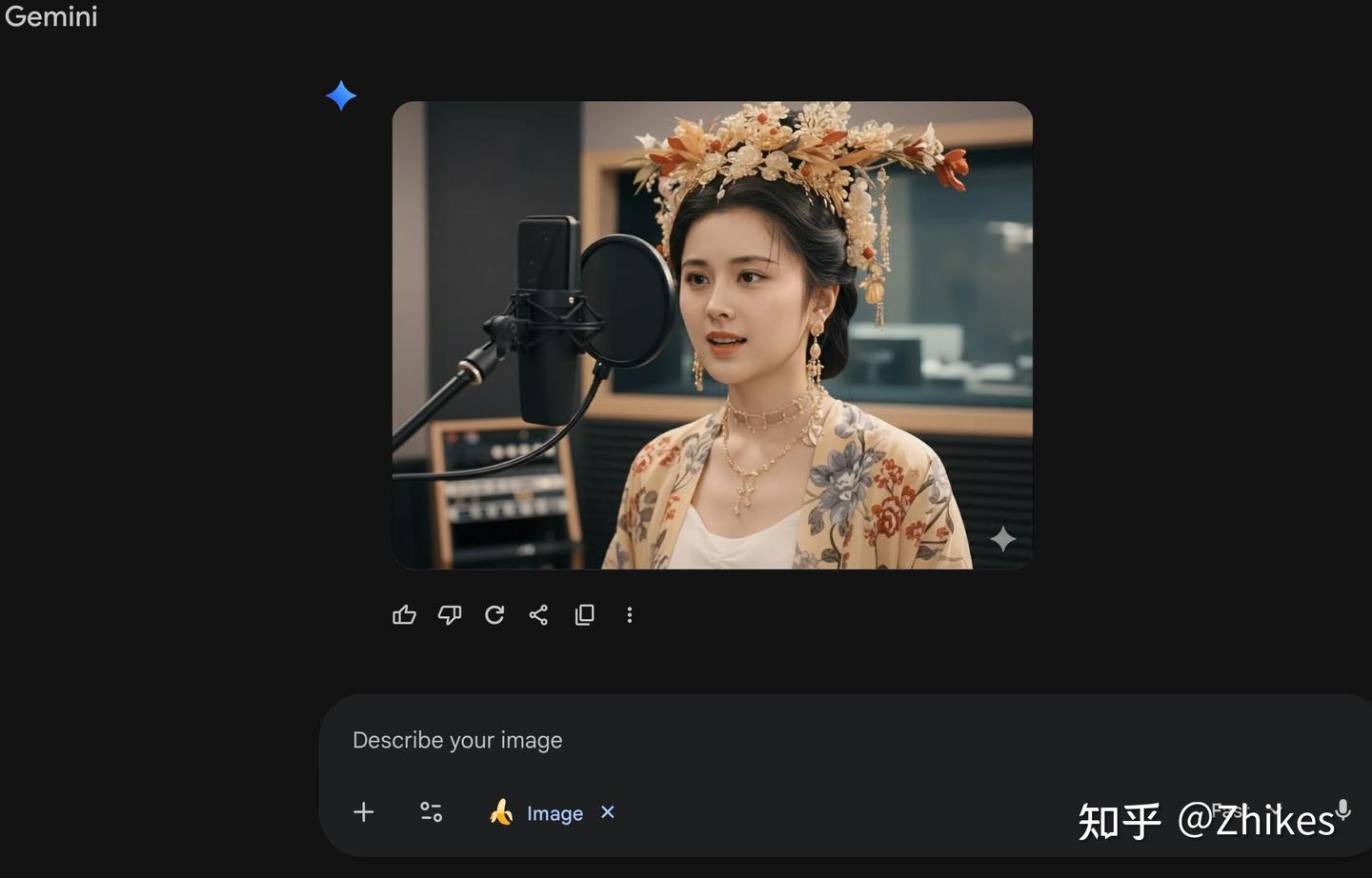
生成的图片如果带有水印,可以前往 Hugging Face 的 Lama Cleaner 去除水印
https://huggingface.co/spaces/Sanster/Lama-Cleaner-lama。该应用偶尔会因流量大无法使用,后面有空星球放个本地部署版本。
2. 创建 AI 歌曲
接下来需要创作 AI 歌词,可通过 ChatGPT、DeepSeek、Grok 等大模型来生成。以下提供两个示例模板,可根据需要替换为其他角色:
示例一:孙悟空视角
- 角色设定:填词人擅长结合古典神话与现代文化,用“孙悟空”第一人称视角创作一首现代流行歌曲。
- 核心立意:大闹天宫象征青春叛逆,金箍象征成人束缚,取经路比作人生旅程,斗战胜佛比作终成精英……歌词应在戏谑、自嘲、怀念中穿插古今隐喻。
- 格式要求:按照 Suno AI 的结构标签输出 [Intro]、[Verse]、[Pre-Chorus]、[Chorus]、[Bridge]、[Outro]。
示例二:女儿国国王视角
- 角色设定:填词人擅长“东方新国风”,以《西游记》女儿国国王的第一人称创作歌曲。
- 核心立意:她代表理想生活,质疑奋斗叙事;古典婉约中带现代清醒,用女儿国/御花园隐喻慢生活,用取经路/西天隐喻职场追梦。
- 格式要求:同样按 [Intro]、[Verse]、[Pre-Chorus]、[Chorus]、[Bridge]、[Outro] 等标签生成歌词,适当加入器乐间奏,如 [Guitar Solo]。
用这些提示词让大模型生成完整歌词后,即可前往 Suno 上传歌词。
3. Suno制作歌曲
前往 Suno 上传歌词,每日可免费生成几首歌曲。具体操作可参阅这篇详细教程https://mp.weixin.qq.com/s/Hnjx6yciv7zFTmDHg6d5OQ
4. 制作歌唱视频
此步骤需要将人物照片与AI歌曲结合生成视频。我提供了一键整合包,支持批量生成、人脸增强及视频超分。简要说明如下:
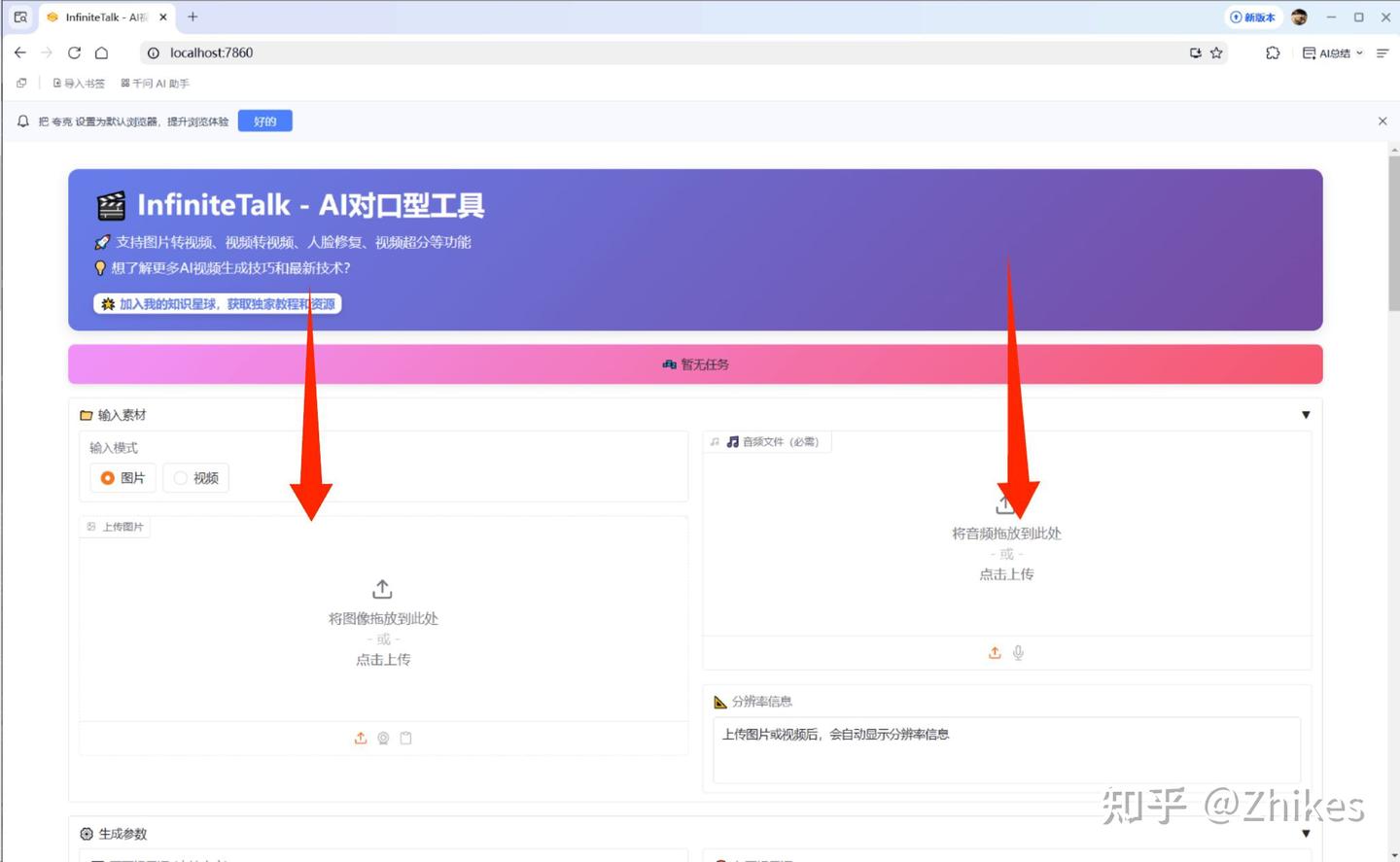
下载完一键整合包解压后点击一键启动,会自动打开如下界面
使用第1步中生成的人物带麦克风图片,使用第3步suno制作的AI原创歌曲。
提示词选择女人在唱歌就行,显存交换系数按照提示填,比例和画质按照你的需求以及显卡显存选择即可。
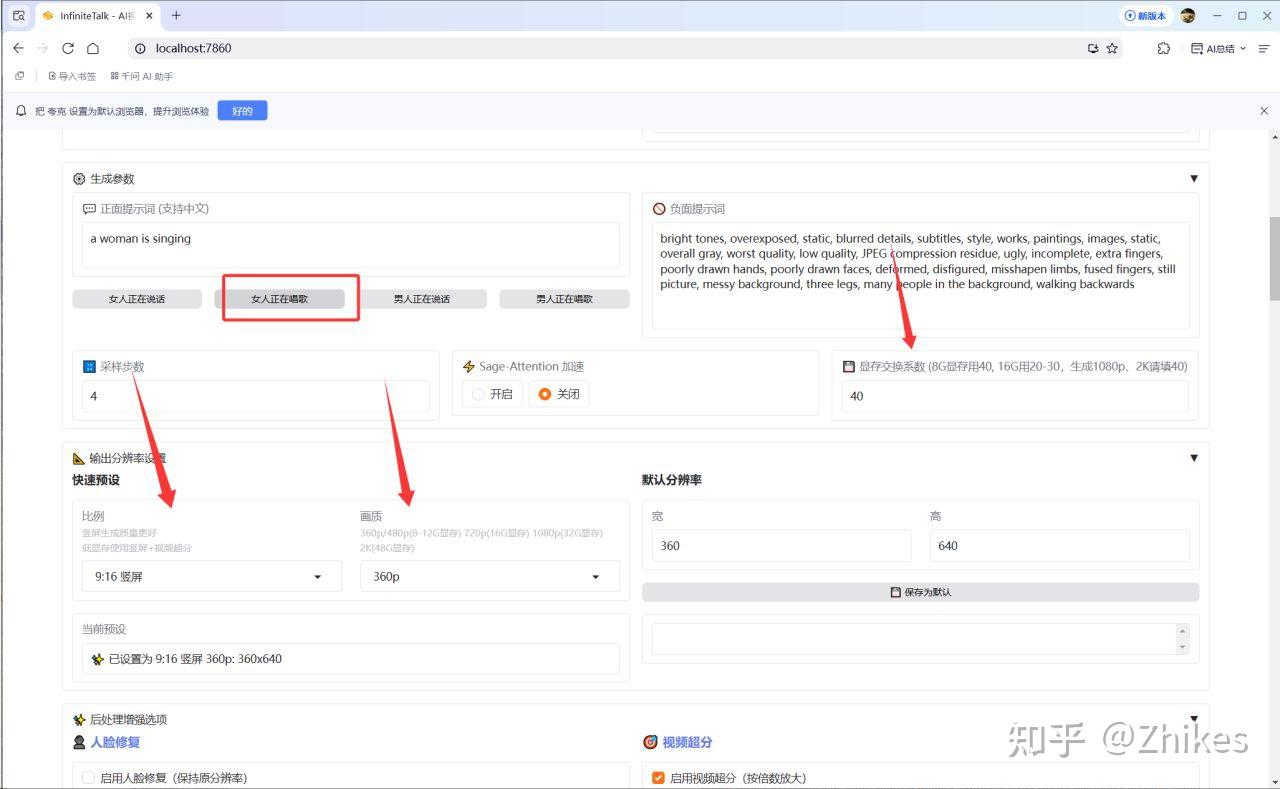
人脸修复,和视频超分。人脸修复一般情况下不建议勾选,勾选视频超分即可。
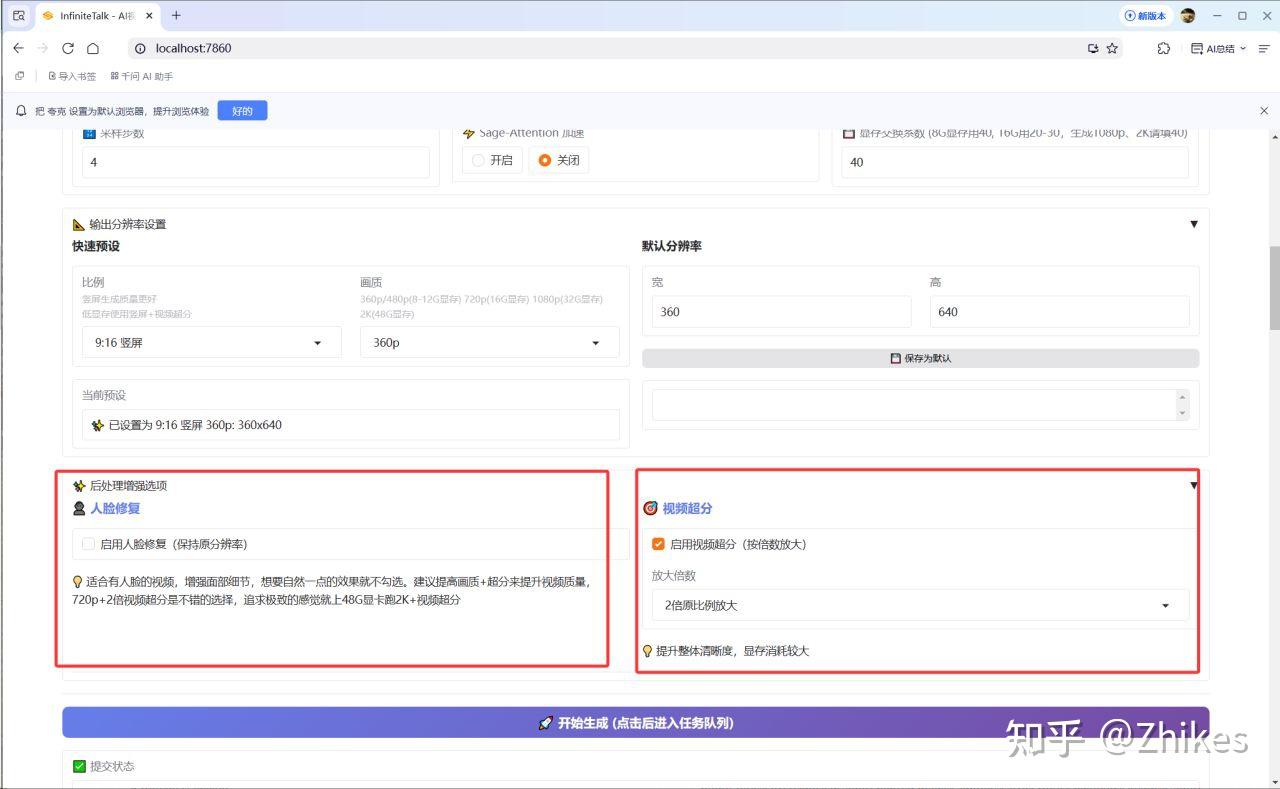
然后点击开始生成,就这么简单,等上七七四十九秒就好了。
点击完开始生成,你可以继续提交任务,人物会排队执行。
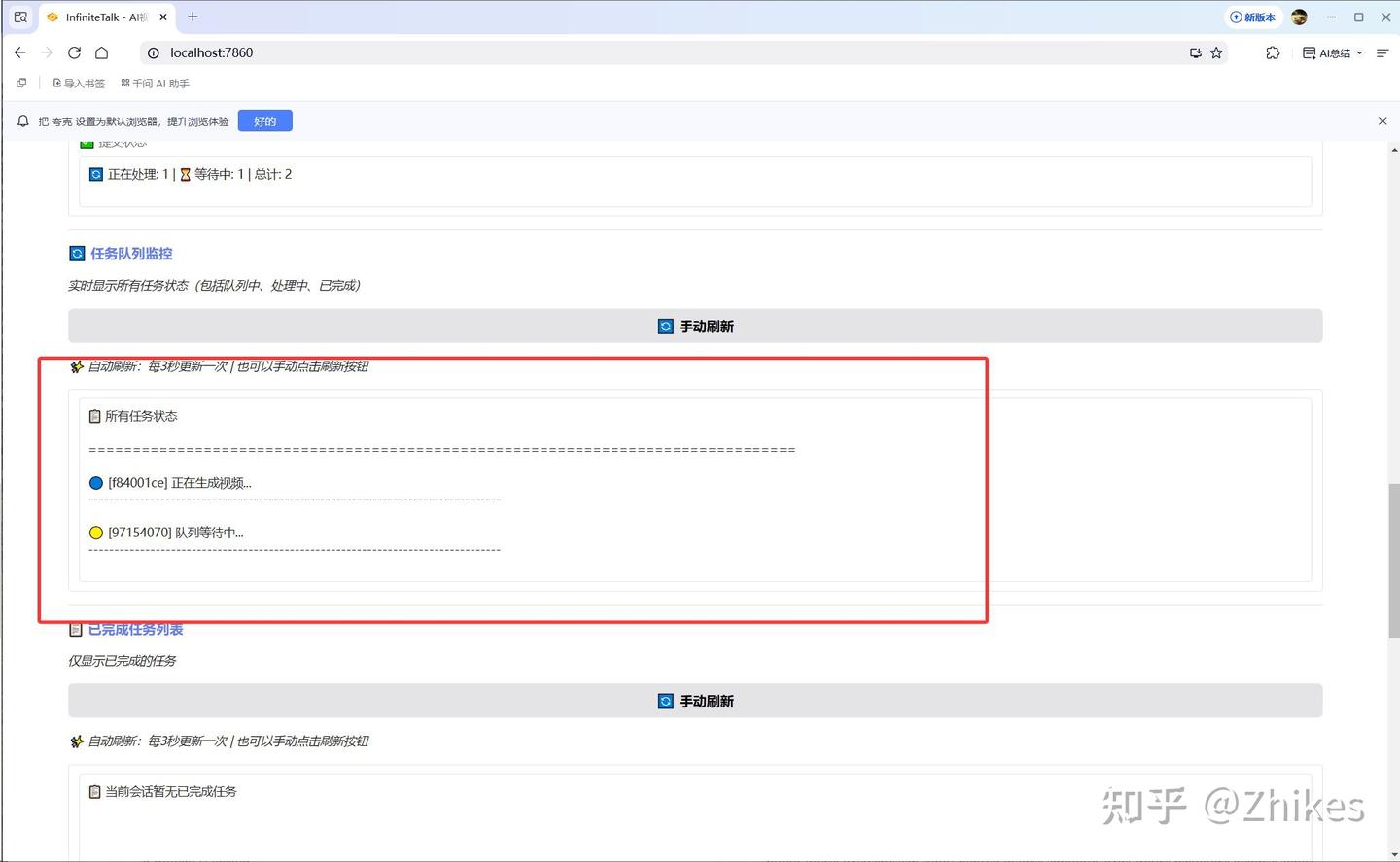
顶部有批量任务执行情况
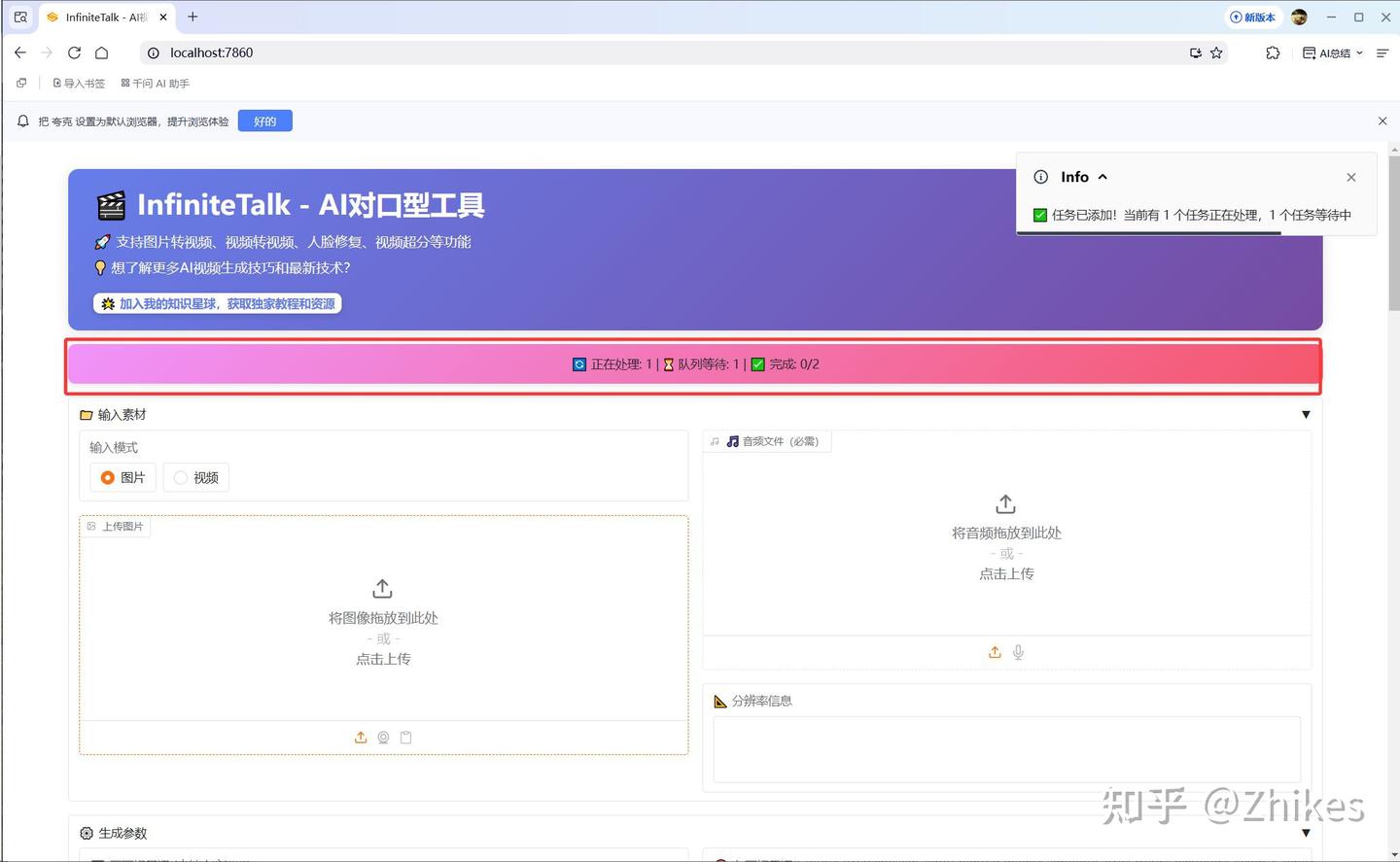
下面也有任务队列监控,可以看到当前任务进行到哪一步,以及所有任务的执行情况
一件整合包,公众号[InnoTechX]发送: 对口型工具
- 显存建议:
- 8–12 GB 显卡:选择 360p 或 480p;
- 16 GB:可选 720p;
- 32 GB:可选 1080p;
- 48 GB:可选 2K。
- 电脑显卡不太好的,选太高分辨率容易显存 OOM,可勾选“视频超分”提升画质,其实生成出来也差不多。
- 操作步骤:上传带麦克风的照片 → 上传歌曲音频 → 选择画质 → 开始生成。若想画面更真实,可只勾选“视频超分”,不勾选人脸修复。
- 电脑显卡不太好的,可以使用云算力,包成功。建议用仙宫云镜像,显卡配置灵活,云算力使用界面和本地部署的一键包功能都是一样的,云算力上面的显卡更强,我放了更大的模型,综合来看,效果更好。通过邀请链接注册仙宫云账号:https://www.xiangongyun.com/register/TGGT23,然后使用镜像:https://www.xiangongyun.com/image/detail/d241d6e6-5ef3-4b95-8c6b-006d5e1b46da?r=TGGT23,仙宫云如何使用这部分也有类似教程:AI换脸教程:手机、电脑都能用的云端部署方法
4. 想折腾的进阶玩家
上述整合包基于开源项目 InfiniteTalk https://github.com/MeiGen-AI/InfiniteTalk,但是没有批量生成、人脸增强及视频超分这几个部分,这几个部分是我添加的功能。可以尝试自己本地搭建。
1. 创建 conda 环境并安装 pytorch 和 xformers
conda create -n multitalk python=3.10
conda activate multitalk
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu121
pip install -U xformers==0.0.28 --index-url https://download.pytorch.org/whl/cu121
2. Flash-attn 安装:
pip install misaki[en]
pip install ninja
pip install psutil
pip install packaging
pip install wheel
pip install flash_attn==2.7.4.post1
3. 其他依赖项
pip install -r requirements.txt conda install -c conda-forge librosa
4. FFmeg 安装
conda install -c conda-forge ffmpeg
模型下载
使用 huggingface-cli 下载模型:
huggingface-cli download Wan-AI/Wan2.1-I2V-14B-480P --local-dir ./weights/Wan2.1-I2V-14B-480P
huggingface-cli download TencentGameMate/chinese-wav2vec2-base --local-dir ./weights/chinese-wav2vec2-base
huggingface-cli download TencentGameMate/chinese-wav2vec2-base model.safetensors --revision refs/pr/1 --local-dir ./weights/chinese-wav2vec2-base
huggingface-cli download MeiGen-AI/InfiniteTalk --local-dir ./weights/InfiniteTalk
下载完模型发现你的磁盘暴涨200G,嘿嘿了老铁
使用 Gradio 运行
python app.py \ --ckpt_dir weights/Wan2.1-I2V-14B-480P \ --wav2vec_dir 'weights/chinese-wav2vec2-base' \ --infinitetalk_dir weights/InfiniteTalk/single/infinitetalk.safetensors \ --num_persistent_param_in_dit 0 \ --motion_frame 9
最后发现以你的显存运行不起来,嘿嘿,还是别折腾了吧!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号