
cuda入门
cuda入门
cuda c 代码分为主机代码和设备代码,cuda编译器和运行时负责从主机代码中调用设备代码。使用 __global__ 标识设备代码,使用尖括号传递如何启动设备代码得参数,代码得参数还是放在圆括号中。主机指针只能访问主机代码内存,设备指针只能访问设备代码内存。
- 设备指针可以传递给设备上执行的函数。
- 设备指针可以在设备代码中读写。
- 设备指针可以传递给主机函数。
- 主机代码不能读写设备指针。
cuda程序执行流程:
- 分配host内存,并进行数据初始化;
- 分配device内存,并从host将数据拷贝到device上;
- 调用CUDA的核函数在device上完成指定的运算;
- 将device上的运算结果拷贝到host上;
- 释放device和host上分配的内存。
上面流程中最重要的一个过程是调用CUDA的核函数来执行并行计算,kernel是CUDA中一个重要的概念,kernel是在device上线程中并行执行的函数,核函数用__global__符号声明,在调用时需要用<<<grid, block>>>来指定kernel要执行的线程数量,在CUDA中,每一个线程都要执行核函数,并且每个线程会分配一个唯一的线程号thread ID,这个ID值可以通过核函数的内置变量threadIdx来获得。
由于GPU实际上是异构模型,所以需要区分host和device上的代码,在CUDA中是通过函数类型限定词开区别host和device上的函数,主要的三个函数类型限定词如下:
__global__:在device上执行,从host中调用(一些特定的GPU也可以从device上调用),返回类型必须是void,不支持可变参数参数,不能成为类成员函数。注意用__global__定义的kernel是异步的,这意味着host不会等待kernel执行完就执行下一步。__device__:在device上执行,单仅可以从device中调用,不可以和__global__同时用。__host__:在host上执行,仅可以从host上调用,一般省略不写,不可以和__global__同时用,但可和__device__,此时函数会在device和host都编译。
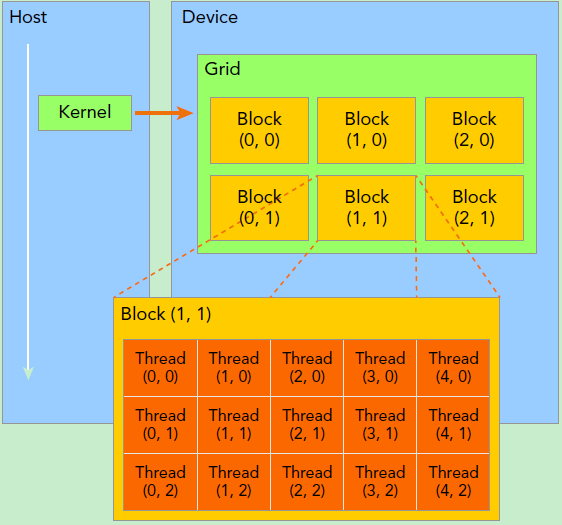
要深刻理解kernel,必须要对kernel的线程层次结构有一个清晰的认识。首先GPU上很多并行化的轻量级线程。kernel在device上执行时实际上是启动很多线程,一个kernel所启动的所有线程称为一个网格(grid),同一个网格上的线程共享相同的全局内存空间,grid是线程结构的第一层次,而网格又可以分为很多线程块(block),一个线程块里面包含很多线程,这是第二个层次。线程两层组织结构如下图所示,这是一个gird和block均为2-dim的线程组织。grid和block都是定义为dim3类型的变量,dim3可以看成是包含三个无符号整数(x,y,z)成员的结构体变量,在定义时,缺省值初始化为1。因此grid和block可以灵活地定义为1-dim,2-dim以及3-dim结构,对于图中结构(主要水平方向为x轴),定义的grid和block如下所示,kernel在调用时也必须通过执行配置<<<grid, block>>>来指定kernel所使用的线程数及结构。
cuda 程序格式
设备信息描述结构体:
/**
* CUDA device properties
*/
struct __device_builtin__ cudaDeviceProp
{
char name[256]; /**< ASCII string identifying device */
cudaUUID_t uuid; /**< 16-byte unique identifier */
char luid[8]; /**< 8-byte locally unique identifier. Value is undefined on TCC and non-Windows platforms */
unsigned int luidDeviceNodeMask; /**< LUID device node mask. Value is undefined on TCC and non-Windows platforms */
size_t totalGlobalMem; /**< Global memory available on device in bytes */
size_t sharedMemPerBlock; /**< Shared memory available per block in bytes */
int regsPerBlock; /**< 32-bit registers available per block */
int warpSize; /**< Warp size in threads */
size_t memPitch; /**< Maximum pitch in bytes allowed by memory copies */
int maxThreadsPerBlock; /**< Maximum number of threads per block */
int maxThreadsDim[3]; /**< Maximum size of each dimension of a block */
int maxGridSize[3]; /**< Maximum size of each dimension of a grid */
int clockRate; /**< Clock frequency in kilohertz */
size_t totalConstMem; /**< Constant memory available on device in bytes */
int major; /**< Major compute capability */
int minor; /**< Minor compute capability */
size_t textureAlignment; /**< Alignment requirement for textures */
size_t texturePitchAlignment; /**< Pitch alignment requirement for texture references bound to pitched memory */
int deviceOverlap; /**< Device can concurrently copy memory and execute a kernel. Deprecated. Use instead asyncEngineCount. */
int multiProcessorCount; /**< Number of multiprocessors on device */
int kernelExecTimeoutEnabled; /**< Specified whether there is a run time limit on kernels */
int integrated; /**< Device is integrated as opposed to discrete */
int canMapHostMemory; /**< Device can map host memory with cudaHostAlloc/cudaHostGetDevicePointer */
int computeMode; /**< Compute mode (See ::cudaComputeMode) */
int maxTexture1D; /**< Maximum 1D texture size */
int maxTexture1DMipmap; /**< Maximum 1D mipmapped texture size */
int maxTexture1DLinear; /**< Deprecated, do not use. Use cudaDeviceGetTexture1DLinearMaxWidth() or cuDeviceGetTexture1DLinearMaxWidth() instead. */
int maxTexture2D[2]; /**< Maximum 2D texture dimensions */
int maxTexture2DMipmap[2]; /**< Maximum 2D mipmapped texture dimensions */
int maxTexture2DLinear[3]; /**< Maximum dimensions (width, height, pitch) for 2D textures bound to pitched memory */
int maxTexture2DGather[2]; /**< Maximum 2D texture dimensions if texture gather operations have to be performed */
int maxTexture3D[3]; /**< Maximum 3D texture dimensions */
int maxTexture3DAlt[3]; /**< Maximum alternate 3D texture dimensions */
int maxTextureCubemap; /**< Maximum Cubemap texture dimensions */
int maxTexture1DLayered[2]; /**< Maximum 1D layered texture dimensions */
int maxTexture2DLayered[3]; /**< Maximum 2D layered texture dimensions */
int maxTextureCubemapLayered[2];/**< Maximum Cubemap layered texture dimensions */
int maxSurface1D; /**< Maximum 1D surface size */
int maxSurface2D[2]; /**< Maximum 2D surface dimensions */
int maxSurface3D[3]; /**< Maximum 3D surface dimensions */
int maxSurface1DLayered[2]; /**< Maximum 1D layered surface dimensions */
int maxSurface2DLayered[3]; /**< Maximum 2D layered surface dimensions */
int maxSurfaceCubemap; /**< Maximum Cubemap surface dimensions */
int maxSurfaceCubemapLayered[2];/**< Maximum Cubemap layered surface dimensions */
size_t surfaceAlignment; /**< Alignment requirements for surfaces */
int concurrentKernels; /**< Device can possibly execute multiple kernels concurrently */
int ECCEnabled; /**< Device has ECC support enabled */
int pciBusID; /**< PCI bus ID of the device */
int pciDeviceID; /**< PCI device ID of the device */
int pciDomainID; /**< PCI domain ID of the device */
int tccDriver; /**< 1 if device is a Tesla device using TCC driver, 0 otherwise */
int asyncEngineCount; /**< Number of asynchronous engines */
int unifiedAddressing; /**< Device shares a unified address space with the host */
int memoryClockRate; /**< Peak memory clock frequency in kilohertz */
int memoryBusWidth; /**< Global memory bus width in bits */
int l2CacheSize; /**< Size of L2 cache in bytes */
int persistingL2CacheMaxSize; /**< Device's maximum l2 persisting lines capacity setting in bytes */
int maxThreadsPerMultiProcessor;/**< Maximum resident threads per multiprocessor */
int streamPrioritiesSupported; /**< Device supports stream priorities */
int globalL1CacheSupported; /**< Device supports caching globals in L1 */
int localL1CacheSupported; /**< Device supports caching locals in L1 */
size_t sharedMemPerMultiprocessor; /**< Shared memory available per multiprocessor in bytes */
int regsPerMultiprocessor; /**< 32-bit registers available per multiprocessor */
int managedMemory; /**< Device supports allocating managed memory on this system */
int isMultiGpuBoard; /**< Device is on a multi-GPU board */
int multiGpuBoardGroupID; /**< Unique identifier for a group of devices on the same multi-GPU board */
int hostNativeAtomicSupported; /**< Link between the device and the host supports native atomic operations */
int singleToDoublePrecisionPerfRatio; /**< Ratio of single precision performance (in floating-point operations per second) to double precision performance */
int pageableMemoryAccess; /**< Device supports coherently accessing pageable memory without calling cudaHostRegister on it */
int concurrentManagedAccess; /**< Device can coherently access managed memory concurrently with the CPU */
int computePreemptionSupported; /**< Device supports Compute Preemption */
int canUseHostPointerForRegisteredMem; /**< Device can access host registered memory at the same virtual address as the CPU */
int cooperativeLaunch; /**< Device supports launching cooperative kernels via ::cudaLaunchCooperativeKernel */
int cooperativeMultiDeviceLaunch; /**< Deprecated, cudaLaunchCooperativeKernelMultiDevice is deprecated. */
size_t sharedMemPerBlockOptin; /**< Per device maximum shared memory per block usable by special opt in */
int pageableMemoryAccessUsesHostPageTables; /**< Device accesses pageable memory via the host's page tables */
int directManagedMemAccessFromHost; /**< Host can directly access managed memory on the device without migration. */
int maxBlocksPerMultiProcessor; /**< Maximum number of resident blocks per multiprocessor */
int accessPolicyMaxWindowSize; /**< The maximum value of ::cudaAccessPolicyWindow::num_bytes. */
size_t reservedSharedMemPerBlock; /**< Shared memory reserved by CUDA driver per block in bytes */
};#include <stdio.h>
#include <cuda_runtime.h>
// 错误处理宏(自定义)
#define HANDLE_ERROR(err) (HandleError(err, __FILE__, __LINE__))
static void HandleError(cudaError_t err, const char* file, int line) {
if (err != cudaSuccess) {
printf("CUDA Error: %s in %s at line %d\n", cudaGetErrorString(err), file, line);
exit(EXIT_FAILURE);
}
}
int main() {
int deviceCount;
HANDLE_ERROR(cudaGetDeviceCount(&deviceCount)); // 获取设备数量
if (deviceCount == 0) {
printf("No CUDA devices found.\n");
return 0;
}
for (int i = 0; i < deviceCount; i++) {
cudaDeviceProp prop;
HANDLE_ERROR(cudaGetDeviceProperties(&prop, i)); // 获取设备属性
// 打印通用信息
printf("\n===== General Information for Device %d =====\n", i);
printf(" Name: %s\n", prop.name);
printf(" Compute Capability: %d.%d\n", prop.major, prop.minor);
printf(" Clock Rate (MHz): %d\n", prop.clockRate / 1000);
printf(" Device Overlap: %s\n", prop.deviceOverlap ? "Enabled" : "Disabled");
printf(" Kernel Timeout: %s\n", prop.kernelExecTimeoutEnabled ? "Enabled" : "Disabled");
// 打印内存信息
printf("\n ----- Memory Information -----\n");
printf(" Total Global Memory: %.2f GB\n", (float)prop.totalGlobalMem / (1 << 30));
printf(" Total Constant Memory: %.2f KB\n", (float)prop.totalConstMem / 1024);
printf(" Memory Pitch: %zu bytes\n", prop.memPitch);
printf(" Texture Alignment: %zu bytes\n", prop.textureAlignment);
// 打印多处理器信息
printf("\n ----- Multiprocessor Details -----\n");
printf(" Multiprocessor Count: %d\n", prop.multiProcessorCount);
printf(" Shared Mem Per Block: %zu bytes\n", prop.sharedMemPerBlock);
printf(" Registers Per Block: %d\n", prop.regsPerBlock);
printf(" Max Threads Per Block: %d\n", prop.maxThreadsPerBlock);
printf(" Max Grid Size: (%d, %d, %d)\n",
prop.maxGridSize[0], prop.maxGridSize[1], prop.maxGridSize[2]);
printf(" Warp Size: %d\n", prop.warpSize);
}
return 0;
}int main(void) {
cudaDeviceProp prop; // 修正类型声明
int dev;
// 获取当前设备ID
HANDLE_ERROR(cudaGetDevice(&dev)); // 修正API名称和参数传递
printf("ID of current CUDA device: %d\n", dev); // 修正格式字符串
// 查找计算能力1.3设备
memset(&prop, 0, sizeof(cudaDeviceProp)); // 修正memset参数
prop.major = 1; // 修正赋值符号
prop.minor = 3;
HANDLE_ERROR(cudaChooseDevice(&dev, &prop)); // 修正API名称
printf("ID of CUDA device closest to compute capability 1.3: %d\n", dev);
// 设置目标设备
HANDLE_ERROR(cudaSetDevice(dev));
return 0;
}全局内存
使用 cudaMalloc 分配,并使用参数传递的内存空间。
cuda 并行编程
多个线程组成一维的线程块 block,多个线程块组成线程格 grid,线程格最高3维。
cpu实现向量相加:
#include <stdio.h>
#define N 10
// 数组加法函数(单线程CPU版本)
void add(int *a, int *b, *c) {
int tid = 0; // 线程索引从0开始
while (tid < N) {
c[tid] = a[tid] + b[tid]; // 修正符号错误:c'étid -> c[tid]
tid += 1; // 单线程每次递增1
}
}
int main(void) {
int a[N], b[N], c[N];
// 初始化数组
for (int i = 0; i < N; i++) {
a[i] = -i; // 数组a初始化为 [0, -1, -2,...-9]
b[i] = i * i; // 数组b初始化为 [0, 1, 4,...81]
}
add(a, b, c); // 执行数组加法
// 打印结果
for (int i = 0; i < N; i++) {
printf("%d + %d = %d\n", a[i], b[i], c[i]); // 修正格式符:&d -> %d
}
return 0;
}可以通过多线程并行增加执行效率。而GPU主要用于多线程
下述代码,在主机中为向量赋值,复制到设备中进行求和,结果复制到主机中。调用核函数时尖括号中指定线程块数量,在核函数内部通过内置变量 blockIdx.x 获取当前线程块编号。blockIdx 是三维的,在图像等二维场景下更方便。线程块集合称为线程格(Grid)。
#include <stdio.h>
#include <cuda_runtime.h>
#define N 10
// 错误检查宏(需配合书中的common/book.h)
#define HANDLE_ERROR(err) (HandleError(err, __FILE__, __LINE__))
// GPU核函数(第二张图修正)
__global__ void add(int *a, int *b, int *c) {
int tid = blockIdx.x; // 使用块索引定位数据位置
if (tid < N) {
c[tid] = a[tid] + b[tid]; // 修正c'étida -> c[tid]
}
}
int main(void) {
int a[N], b[N], c[N];
int *dev_a, *dev_b, *dev_c;
// GPU内存分配(第一张图修正)
HANDLE_ERROR(cudaMalloc((void**)&dev_a, N * sizeof(int)));
HANDLE_ERROR(cudaMalloc((void**)&dev_b, N * sizeof(int)));
HANDLE_ERROR(cudaMalloc((void**)&dev_c, N * sizeof(int)));
// 初始化主机数组
for (int i = 0; i < N; i++) {
a[i] = -i; // 原图错误赋值符 == 修正为 =
b[i] = i * i; // 原图符号错误 」i -> i*i
}
// 数据拷贝到GPU(修正参数顺序)
HANDLE_ERROR(cudaMemcpy(dev_a, a, N*sizeof(int), cudaMemcpyHostToDevice));
HANDLE_ERROR(cudaMemcpy(dev_b, b, N*sizeof(int), cudaMemcpyHostToDevice));
// 启动核函数(修正执行配置)
add<<<N, 1>>>(dev_a, dev_b, dev_c); // 使用N个块,每个块1个线程
// 结果拷贝回CPU(修正参数)
HANDLE_ERROR(cudaMemcpy(c, dev_c, N*sizeof(int), cudaMemcpyDeviceToHost));
// 输出结果(修正格式符)
for (int i = 0; i < N; i++) {
printf("%d + %d = %d\n", a[i], b[i], c[i]);
}
// 释放GPU内存
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
return 0;
}上述核函数在GPU线程执行中:

不同版本GPU对线程格的维度有不同限制:
| 计算能力版本 | x维度最大值 | y维度最大值 | z维度最大值 |
|---|---|---|---|
| < 2.0 | 65535 | 65535 | 1 |
| 2.0~6.1 | 65535 | 65535 | 65535 |
| ≥7.0 | 2^31-1 | 65535 | 65535 |
动态查询:
cudaDeviceProp prop;
cudaGetDeviceProperties(&prop, 0);
printf("Max grid dimensions: [%d, %d, %d]\n",
prop.maxGridSize[0],
prop.maxGridSize[1],
prop.maxGridSize[2]);
// 根据硬件自动调整grid维度
dim3 gridDim;
gridDim.x = min(desired_x, prop.maxGridSize[0]);
gridDim.y = min(desired_y, prop.maxGridSize[1]);
gridDim.z = min(desired_z, prop.maxGridSize[2]);
kernel<<<gridDim, blockDim>>>(...);julia集计算
满足某个复数运行要求的点组成的集合
CPU
#include <stdio.h>
#include <stdlib.h>
#define DIM 1024 // 图像分辨率
// 复数结构体定义
// 复数结构体(CPU版本)
struct cuComplex {
float r; // 实部
float i; // 虚部
// 构造函数
cuComplex(float a, float b) : r(a), i(b) {}
// 计算模的平方(避免开方运算)
float magnitude2(void) {
return r * r + i * i;
}
// 复数加法运算符重载
cuComplex operator+(const cuComplex& a) {
return cuComplex(r + a.r, i + a.i);
}
// 复数乘法运算符重载((a+bi)(c+di)=ac-bd + (ad+bc)i)
cuComplex operator*(const cuComplex& a) {
return cuComplex(r*a.r - i*a.i, r*a.i + i*a.r);
}
};
// Julia集判断函数
// 判断点(x,y)是否属于Julia集
int julia(int x, int y) {
const float scale = 1.5; // 坐标系缩放因子
// 将像素坐标映射到复平面 [-scale, scale]
float jx = scale * (float)(DIM/2 - x)/(DIM/2); // 计算复平面x坐标
float jy = scale * (float)(DIM/2 - y)/(DIM/2); // 计算复平面y坐标
cuComplex c(-0.8, 0.156); // Julia集常数c(决定形状)
cuComplex a(jx, jy); // 初始复数值z0 = (jx, jy)
// 迭代计算:z_{n+1} = z_n^2 + c
for(int i = 0; i < 200; i++) {
a = a * a + c; // 复数平方运算
if(a.magnitude2() > 1000) // 判断是否发散
return 0; // 发散点不属于Julia集
}
return 1; // 收敛点属于Julia集
}
int main(void) {
unsigned char *bitmap = (unsigned char*)malloc(DIM*DIM*4); // RGBA像素缓冲区
// 遍历所有像素点(CPU单线程循环)
for(int y = 0; y < DIM; y++) {
for(int x = 0; x < DIM; x++) {
// 计算当前点是否属于Julia集
int juliaValue = julia(x, y);
// 计算缓冲区偏移量(每个像素4字节:RGBA)
int offset = (x + y * DIM) * 4;
// 设置颜色(红色表示属于Julia集)
bitmap[offset + 0] = 255 * juliaValue; // R
bitmap[offset + 1] = 0; // G
bitmap[offset + 2] = 0; // B
bitmap[offset + 3] = 255; // A
}
}
// 此处应添加图像显示或保存代码(例如使用OpenGL/SDL库)
// bitmap.display_and_exit();
free(bitmap);
return 0;
}GPU 版
#include "../common/book.h" // CUDA错误处理头文件
#include "../common/cpu_bitmap.h" // 位图操作头文件
#define DIM 1000 // 图像分辨率
// ================= 复数结构体定义(设备端) =================
struct cuComplex {
float r; // 实部
float i; // 虚部
// 构造函数(设备端)
__device__ cuComplex(float a, float b) : r(a), i(b) {}
// 计算复数模平方(设备端)
__device__ float magnitude2(void) {
return r * r + i * i;
}
// 复数加法重载(设备端)
__device__ cuComplex operator+(const cuComplex& a) {
return cuComplex(r + a.r, i + a.i);
}
// 复数乘法重载(设备端)公式:(a+bi)(c+di) = (ac-bd) + (ad+bc)i
__device__ cuComplex operator*(const cuComplex& a) {
return cuComplex(r*a.r - i*a.i, r*a.i + i*a.r);
}
};
// ================= Julia集判定函数(设备端) =================
__device__ int julia(int x, int y) {
const float scale = 1.5;
// 坐标映射到复平面[-scale, scale]
float jx = scale * (float)(DIM/2 - x)/(DIM/2);
float jy = scale * (float)(DIM/2 - y)/(DIM/2);
cuComplex c(-0.8, 0.156); // Julia集常数
cuComplex a(jx, jy); // 初始点z0
// 迭代计算 z = z^2 + c
for(int i=0; i<200; i++){
a = a * a + c;
if(a.magnitude2() > 1000) // 发散判断
return 0;
}
return 1; // 收敛点属于集合
}
// ================= GPU核函数(全局函数) =================
__global__ void kernel(unsigned char *ptr) {
// 通过blockIdx获取二维像素坐标
int x = blockIdx.x; // 列索引(0~DIM-1)
int y = blockIdx.y; // 行索引(0~DIM-1)
int offset = x + y * gridDim.x; // 计算线性偏移(gridDim.x=DIM)
// 计算Julia集值并设置颜色(RGBA)
int juliaValue = julia(x, y);
ptr[offset*4 + 0] = 255 * juliaValue; // 红色分量
ptr[offset*4 + 1] = 0; // 绿色分量
ptr[offset*4 + 2] = 0; // 蓝色分量
ptr[offset*4 + 3] = 255; // Alpha通道
}
// ================= 主函数 =================
int main(void) {
// 1. 创建CPU位图对象(用于显示)
CPUBitmap bitmap(DIM, DIM);
unsigned char *dev_bitmap;
// 2. GPU内存分配(DIM*DIM*4字节)
HANDLE_ERROR(cudaMalloc((void**)&dev_bitmap, DIM*DIM*4));
// 3. 配置执行参数(二维线程格,第三维置1)
dim3 grid(DIM, DIM); // 创建DIM x DIM x 1的线程格
// 4. 启动核函数(每个block处理一个像素)
kernel<<<grid, 1>>>(dev_bitmap); // 每个block 1个线程
// 5. 拷贝GPU结果到CPU位图
HANDLE_ERROR(cudaMemcpy(bitmap.get_ptr(), dev_bitmap,
DIM*DIM*4, cudaMemcpyDeviceToHost));
// 6. 显示图像并释放资源
bitmap.display_and_exit();
HANDLE_ERROR(cudaFree(dev_bitmap));
return 0;
}GPU vs CPU实现对比
| 特性 | CPU版本 | GPU版本 |
|---|---|---|
| 并行方式 | 单线程双层循环 | 二维线程格并行 |
| 内存模型 | 直接访问主机内存 | 显存分配 + 主机-设备数据传输 |
| 索引计算 | x + y*DIM |
blockIdx.x/y + gridDim.x |
| 函数修饰符 | 无 | __device__/__global__ |
| 性能影响 | 受CPU单核性能限制 | 依赖GPU流处理器数量 |
线程协作
add<<<N, 1>>>(dev_a, dev_b, dev_c) 中N为线程格的规格,1为每个线程块中线程的数量。N * 1 即为并发线程数
线程块并发
// 核函数:每个线程块处理1个元素(1线程/块)
__global__ void add_block(int *a, int *b, int *c) {
int tid = blockIdx.x; // 直接使用块索引
if (tid < N) { // 边界检查
c[tid] = a[tid] + b[tid];
}
}
// 调用方式(启动N个线程块,每个块1线程)
add_block<<<N, 1>>>(dev_a, dev_b, dev_c);线程并发
// CUDA核函数定义(全局函数)
__global__ void add(int *a, int *b, int *c) {
// 获取线程ID(修正threadIdx为blockIdx以支持多块并行)
int tid = threadIdx.x; // 使用块索引代替线程索引
if (tid < N) { // 边界判断
c[tid] = a[tid] + b[tid]; // 修正字符错误:'étid → [tid]
}
}
add<<<1, N>>>(dev_a, dev_b, dev_c); | 特征 | 线程块级并发 (add_block) |
线程级并发 (add_thread) |
|---|---|---|
| 执行配置 | <<<N, 1>>> |
<<<(N+255)/256, 256>>> |
| 线程利用率 | 每个SM仅1线程运行 | 每个SM可调度数千线程 |
| 最大支持数据量 | 受限于 maxGridSize(约65k) |
理论支持 |
| 硬件资源占用 | 浪费SM计算资源 | 充分占用SM内的warp调度器 |
| 适用场景 | 小规模数据(N < 1024) | 大规模数据(N > 1e6) |
| 指令效率 | 低(线程间无warp合并) | 高(warp内指令同步执行) |
| 显存访问模式 | 随机访问(相邻块可能访问不连续地址) | 合并访问(相邻线程访问连续地址) |
| 典型性能 | 1x(基准) | 可达10x+加速 |
避免使用线程块级并发:
- Volta/Turing架构后,每个SM最多支持32个线程块
- 若使用
<<<N,1>>>,当N>32时产生排队延迟
由于硬件会对线程数和线程块最大数进行限制,所以处理大规模数据时使用线程与线程块的结合。
// 核函数:每个线程处理1个元素(多线程/块)
__global__ void add_thread(int *a, int *b, int *c) {
int tid = blockIdx.x * blockDim.x + threadIdx.x; // 计算全局索引
while (tid < N) { // <== 边界检查
c[tid] = a[tid] + b[tid];
tid += blockDim.x * gridDim.x;
}
}
// 调用方式(动态计算网格维度)
int threadsPerBlock = 256; // 推荐256/1024等2的幂
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock; // <== 保证向上取整
add_thread<<<blocksPerGrid, threadsPerBlock>>>(dev_a, dev_b, dev_c);
参考二维数组嵌套二维数组。尖括号内内容可以是数字,也可以是 dim3 结构体定义的多维数组。
共享内存
使用 __share__ 修饰的变量放入共享内存,同一线程块中的每个线程都可以访问,实现并发场景下数据共享,存在竞态条件。
// 同步操作
void __syncthreads(); // 同步线程
int all_non_zero = __syncthreads_and(predicate); // 所有线程传入参数的逻辑与的结果
int any_non_zero = __syncthreads_or(predicate); // 所有线程传入参数的逻辑或的结果
int active_threads = __syncthreads_count(predicate); // 所有线程传入参数的非零的个数向量点乘操作的GPU实现
#include "../common/book.h" // 引入CUDA错误处理宏HANDLE_ERROR
// 定义最小值宏(用于计算块数)
#define imin(a,b) (a < b ? a : b)
// 数据总长度:33 * 1024=33792
const int N = 33 * 1024;
__global__ void dot(float *a, float *b, float *c) {
// ===== 共享内存声明 =====
__shared__ float cache[256]; // 每个块256线程共享缓存(需2的幂)
// ===== 索引计算 =====
int tid = threadIdx.x + blockIdx.x * blockDim.x; // 全局线程索引
int cacheIndex = threadIdx.x; // 共享内存索引
// ===== 阶段1:跨网格累加点积 =====
float tmp = 0.0f;
while (tid < N) { // 处理超出网格大小的数据
tmp += a[tid] * b[tid]; // 计算部分点积
tid += blockDim.x * gridDim.x; // 跳跃步长=总线程数
}
cache[cacheIndex] = tmp; // 存储到共享内存
// ===== 阶段2:树状归约 =====
__syncthreads(); // 块内同步(所有线程必须到达此处)
// 归约操作(256→128→64→...→1)
for (int i = blockDim.x/2; i > 0; i /= 2) {
if (cacheIndex < i) {
cache[cacheIndex] += cache[cacheIndex + i]; // 累加相邻元素
}
__syncthreads(); // 每步归约后同步
}
// ===== 阶段3:写入全局内存 =====
if (cacheIndex == 0) {
c[blockIdx.x] = cache[0]; // 每个块输出一个结果
}
}
int main(void) {
// ===== 主机内存分配 =====
float *a = new float[N]; // 输入向量a
float *b = new float[N]; // 输入向量b
float *partial_c = new float[32]; // 部分结果缓冲区(最多32块)
// ===== 设备内存分配 =====
float *dev_a, *dev_b, *dev_partial_c;
HANDLE_ERROR(cudaMalloc((void**)&dev_a, N*sizeof(float)));
HANDLE_ERROR(cudaMalloc((void**)&dev_b, N*sizeof(float)));
HANDLE_ERROR(cudaMalloc((void**)&dev_partial_c, 32*sizeof(float)));
// ===== 初始化输入数据 =====
for(int i = 0; i < N; i++) {
a[i] = i; // a = [0, 1, 2,...,33791]
b[i] = i * 2; // b = [0, 2, 4,...,67582]
}
// ===== 数据传输到GPU =====
HANDLE_ERROR(cudaMemcpy(dev_a, a, N*sizeof(float), cudaMemcpyHostToDevice));
HANDLE_ERROR(cudaMemcpy(dev_b, b, N*sizeof(float), cudaMemcpyHostToDevice));
// ===== 执行核函数 =====
const int threadsPerBlock = 256;
const int blocksPerGrid = imin(32, (N + threadsPerBlock - 1)/threadsPerBlock);
dot<<<blocksPerGrid, threadsPerBlock>>>(dev_a, dev_b, dev_partial_c);
// ===== 取回结果 =====
HANDLE_ERROR(cudaMemcpy(partial_c, dev_partial_c,
blocksPerGrid*sizeof(float), cudaMemcpyDeviceToHost));
// ===== CPU端二次归约 =====
float c = 0;
for(int i = 0; i < blocksPerGrid; i++) {
c += partial_c[i]; // 汇总所有块的结果
}
// ===== 验证公式 =====
#define sum_of_squares(x) (x*(x+1)*(2*x+1)/6) // 平方和公式
printf("GPU结果: %.2f\n", c);
printf("理论值: %.2f\n", 2 * sum_of_squares((float)(N-1)));
// ===== 资源释放 =====
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_partial_c);
delete[] a;
delete[] b;
delete[] partial_c;
return 0;
}错误优化:
if (cacheIndex < i) {
cache[cacheIndex] += cache[cacheIndex + i];
__syncthreads(); // 将同步操作放入条件语句,是的某些线程无需等待同步操作(×)
}多线程中条件语句使得部分线程执行某些语句其他不执行,这叫线程发散,这种情况导致某些线程繁忙有些空闲。CUDA架构确保一个线程块中只有所有线程都执行__syncthreads();后线程才会继续执行,如果存在上述情况会导致无限等待。
常量内存
性能瓶颈通常不在gpu的计算单元,而是内存带宽。
光线追踪
想象一只眼睛从某个平面出发,所有从当前平面能“看见”的物体的颜色。
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdlib.h>
#include <math.h>
#define DIM 1024 // 定义图像尺寸
#define SPHERES 20 // 定义球体数量
#define INF 1e6 // 定义无穷大值
#define rnd(x) (x * rand() / RAND_MAX) // 随机数生成宏
// 球体数据结构(包含CPU和GPU版本)
struct Sphere {
float r, g, b; // 颜色值
float radius; // 半径
float x, y, z; // 中心坐标
// 光线碰撞检测方法(设备端)
__device__ float hit(float ox, float oy, float *n) {
float dx = ox - x; // x坐标差
float dy = oy - y; // y坐标差
// 判断光线是否在球体投影圆内
if (dx*dx + dy*dy < radius*radius) {
float dz = sqrtf(radius*radius - dx*dx - dy*dy); // 计算z方向深度
*n = dz / radius; // 存储法线方向分量
return z + dz; // 返回碰撞点z坐标(相机坐标系)
}
return -INF; // 未碰撞返回负无穷
}
};
// CUDA核函数:光线追踪计算
__global__ void kernel(Sphere *s, unsigned char *ptr) {
// 计算像素坐标
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
// 将坐标系原点移到图像中心
float ox = (x - DIM/2);
float oy = (y - DIM/2);
// 初始化颜色和最近碰撞距离
float r = 0, g = 0, b = 0;
float max_dist = -INF;
// 遍历所有球体
for(int i=0; i<SPHERES; i++) {
float n;
float t = s[i].hit(ox, oy, &n); // 计算碰撞
if(t > max_dist) { // 发现更近的碰撞
max_dist = t;
// 使用法线分量计算颜色(简单着色)
r = s[i].r * n;
g = s[i].g * n;
b = s[i].b * n;
}
}
// 将计算结果写入显存(RGBA格式)
ptr[offset*4 + 0] = (int)(r * 255); // 红色通道
ptr[offset*4 + 1] = (int)(g * 255); // 绿色通道
ptr[offset*4 + 2] = (int)(b * 255); // 蓝色通道
ptr[offset*4 + 3] = 255; // Alpha通道
}
int main(void) {
// 初始化CUDA事件(用于计时)
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
// 分配主机内存
unsigned char *bitmap = new unsigned char[DIM*DIM*4];
Sphere *temp_s = (Sphere*)malloc(sizeof(Sphere)*SPHERES);
// 随机生成球体参数
for(int i=0; i<SPHERES; i++) {
temp_s[i].r = rnd(1.0f); // 红色分量
temp_s[i].g = rnd(1.0f); // 绿色分量
temp_s[i].b = rnd(1.0f); // 蓝色分量
temp_s[i].x = rnd(2000.0f) - 500; // x坐标(-500~1500)
temp_s[i].y = rnd(2000.0f) - 1000; // y坐标(-1000~1000)
temp_s[i].z = rnd(2000.0f) - 500; // z坐标(-500~1500)
temp_s[i].radius = rnd(100.0f) + 20; // 半径(20~120)
}
// 分配设备内存
Sphere *dev_s;
unsigned char *dev_bitmap;
cudaMalloc(&dev_s, sizeof(Sphere)*SPHERES);
cudaMalloc(&dev_bitmap, DIM*DIM*4);
// 拷贝数据到设备
cudaMemcpy(dev_s, temp_s, sizeof(Sphere)*SPHERES, cudaMemcpyHostToDevice);
// 设置CUDA核执行配置
dim3 grids(DIM/16, DIM/16); // 网格配置(64x64)
dim3 threads(16, 16); // 线程块配置(16x16)
// 启动核函数
cudaEventRecord(start);
kernel<<<grids, threads>>>(dev_s, dev_bitmap);
cudaEventRecord(stop);
// 回传计算结果
cudaMemcpy(bitmap, dev_bitmap, DIM*DIM*4, cudaMemcpyDeviceToHost);
// 清理资源
free(temp_s);
cudaFree(dev_s);
cudaFree(dev_bitmap);
cudaEventDestroy(start);
cudaEventDestroy(stop);
// 这里可以添加图像显示代码(需配合图形库)
return 0;
}常量内存优化:__constant__ 和 cudaMemcpyToSymbol
// 核心修改部分(原代码基础上添加常量内存支持)
__constant__ Sphere dev_spheres[SPHERES]; // 常量内存声明
__global__ void kernel(unsigned char* ptr) {
// ...(原有像素计算逻辑不变)...
// 修改后的碰撞检测逻辑(从常量内存读取)
for(int i=0; i<SPHERES; i++){
float n;
float t = dev_spheres[i].hit(ox, oy, &n); // 从常量内存访问
// ...(后续着色逻辑不变)...
}
}
int main() {
// ...(原有初始化逻辑)...
// 修改后的内存操作(使用常量内存专用API)
cudaMemcpyToSymbol(dev_spheres, temp_s, sizeof(Sphere)*SPHERES);
// ...(原有核函数调用和清理逻辑)...
}
/*
__constant__ 修饰符:声明设备端常量内存数组
cudaMemcpyToSymbol:CUDA专用API,用于将主机数据复制到常量内存
核函数参数调整:移除Sphere指针参数(直接从常量内存访问)
内存访问优化:将高频读取的球体数据置于快速访问路径
*/特性与优势:
- 硬件级缓存:NVIDIA GPU为常量内存提供专门的片上缓存(通常64KB),支持广播机制,当所有线程访问相同地址时能实现超高带宽
- 只读优化:专为只读数据设计,适合存储光照参数、材质属性等高频访问数据
- 访问特性:
- 单次访问可被多个线程复用(适合warp内线程访问相同数据)
- 延迟低于全局内存(通过缓存机制实现)
- 对
__constant__变量的访问会被编译器特殊优化
- 使用场景:非常适合光线追踪中的场景参数、物理引擎的约束条件等需要被所有线程频繁读取的公共数据
开发注意事项:
- 容量限制:当前架构最大支持64KB常量内存
- 声明方式:必须使用
__constant__限定符 - 数据传输:必须通过
cudaMemcpyToSymbol而非普通cudaMemcpy - 访问模式:尽量让线程束内线程访问相同内存地址以获得最佳性能
事件
基于GPU内部时钟的相对时间标记,当调用cudaEventRecord(event, stream)时,会在指定流中插入一个标记点,GPU执行到此位置时记录此刻的硬件时钟值。毫秒级精度
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, 0); // 记录起始时间戳
kernel<<<...>>>(); // 执行内核
cudaEventRecord(stop, 0); // 记录结束时间戳
cudaEventSynchronize(stop); // 等待所有线程事件完成
float elapsedTime;
cudaEventElapsedTime(&elapsedTime, start, stop); // 计算时间差
cudaEventDestroy(start);
cudaEventDestroy(stop);纹理内存
纹理内存是CUDA中一种特殊的只读内存,适用于具有空间局部性的数据访问模式(如图像处理、热传导模拟等)。其核心优势在于内置的缓存机制,能够高效处理不规则的内存访问,提升数据读取速度。绑定/解绑操作需在主机端调用。
- 缓存优化:自动缓存数据,适合空间局部性访问。
- 边界处理:支持自动处理越界访问(如钳制或环绕)。
- 多种数据格式:支持浮点数、整数等,并可进行归一化处理。
// 声明纹理对象
texture<float, 2> texRef; // 2D浮点纹理
// 绑定纹理内存,指定通道描述
cudaChannelFormatDesc channelDesc = cudaCreateChannelDesc<float>();
cudaBindTexture2D(NULL, texRef, dev_data, channelDesc, width, height, pitch);
//dev_data: 设备端数据指针。
//width, height: 数据维度。
//pitch: 内存步长(字节)。
// 核函数中访问纹理
__global__ void kernel() {
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
float value = tex2D(texRef, x, y); // 读取纹理坐标(x,y)的值
}
// 解绑纹理内存
cudaUnbindTexture(texRef);热传导示例:简单的二维网格中热量从温度高的传到温度低的。极大简化后的公式:
#include <cuda_runtime.h>
#include <iostream>
// 声明2D浮点纹理引用
texture<float, 2> texTemperature;
__global__ void updateTemperature(float* newTemp, int width, int height) {
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
if (x >= width || y >= height) return;
// 从纹理内存读取周围温度值
float center = tex2D(texTemperature, x, y);
float left = tex2D(texTemperature, x-1, y);
float right = tex2D(texTemperature, x+1, y);
float top = tex2D(texTemperature, x, y-1);
float bottom = tex2D(texTemperature, x, y+1);
// 计算新温度(简化公式)
newTemp[y*width + x] = (center + left + right + top + bottom) * 0.2f;
}
int main() {
const int width = 512, height = 512;
float* dev_temp;
cudaMalloc(&dev_temp, width*height*sizeof(float));
// 初始化温度数据...
// 绑定纹理
cudaChannelFormatDesc channelDesc = cudaCreateChannelDesc<float>();
cudaBindTexture2D(NULL, texTemperature, dev_temp, channelDesc, width, height, width*sizeof(float));
// 启动核函数
dim3 blocks(16, 16);
dim3 grids((width + blocks.x - 1)/blocks.x, (height + blocks.y - 1)/blocks.y);
updateTemperature<<<grids, blocks>>>(dev_temp, width, height);
// 解绑纹理
cudaUnbindTexture(texTemperature);
cudaFree(dev_temp);
return 0;
}原子性
atomicAdd, atomicSub, atomicExch, atomicMin, atomicMax, atomicInc, atomicDec, atomicCAS, atomicAnd, atomicOr, atomicXor
不同版本gpu支持不同指令集,nvcc -arch=sm_11 指定编译代码需要1.1版本或更高
计算频率的main函数
#include <cuda_runtime.h>
#include <stdio.h>
// 定义CUDA错误检查宏
#define HANDLE_ERROR(err) (cudaErrorCheck(err, __FILE__, __LINE__))
inline void cudaErrorCheck(cudaError_t err, const char *file, int line) {
if (err != cudaSuccess) {
printf("%s in %s at line %d\n", cudaGetErrorString(err), file, line);
exit(EXIT_FAILURE);
}
}
// 直方图核函数声明
__global__ void histo_kernel(unsigned char* buffer, long size, unsigned int* histo);
int main(void) {
// 主机内存分配
unsigned char* buffer = (unsigned char*)big_random_block(SIZE); // 生成随机测试数据
unsigned int histo[256] = {0}; // CPU端直方图结果
// 设备内存指针
unsigned char* dev_buffer = NULL; // GPU输入数据
unsigned int* dev_histo = NULL; // GPU直方图结果
// CUDA事件计时
cudaEvent_t start, stop;
HANDLE_ERROR(cudaEventCreate(&start)); // 创建开始事件
HANDLE_ERROR(cudaEventCreate(&stop)); // 创建结束事件
HANDLE_ERROR(cudaEventRecord(start, 0)); // 记录起始时间
// GPU内存分配
HANDLE_ERROR(cudaMalloc((void**)&dev_buffer, SIZE)); // 分配输入数据内存
HANDLE_ERROR(cudaMalloc((void**)&dev_histo, 256 * sizeof(int))); // 分配直方图内存
// 数据拷贝到设备
HANDLE_ERROR(cudaMemcpy(dev_buffer, buffer, SIZE, cudaMemcpyHostToDevice));
HANDLE_ERROR(cudaMemset(dev_histo, 0, 256 * sizeof(int))); // 设备内存清零
// 获取GPU设备属性
cudaDeviceProp prop;
HANDLE_ERROR(cudaGetDeviceProperties(&prop, 0));
int blocks = prop.multiProcessorCount; // 获取SM数量
// 启动核函数
dim3 grid(blocks * 2, 1); // 根据SM数量计算网格维度
dim3 threads(256, 1); // 每个块256线程
histo_kernel<<<grid, threads>>>(dev_buffer, SIZE, dev_histo);
// 记录结束时间并同步
HANDLE_ERROR(cudaEventRecord(stop, 0));
HANDLE_ERROR(cudaEventSynchronize(stop));
// 计算耗时
float elapsedTime;
HANDLE_ERROR(cudaEventElapsedTime(&elapsedTime, start, stop));
printf("Time to generate: %3.1f ms\n", elapsedTime);
// 拷贝结果回主机
HANDLE_ERROR(cudaMemcpy(histo, dev_histo, 256 * sizeof(int), cudaMemcpyDeviceToHost));
// 验证直方图总和
long histoCount = 0;
for (int i = 0; i < 256; i++) {
histoCount += histo[i]; // 累加所有bin的计数
}
printf("Histogram Sum: %ld\n", histoCount);
// 结果验证(与CPU计算对比)
for (int i = 0; i < SIZE; i++) {
histo[buffer[i]]--; // 减去每个元素的计数
}
for (int i = 0; i < 256; i++) {
if (histo[i] != 0) {
printf("数据不一致,错误发生在bin %d\n", i);
}
}
// 释放资源
HANDLE_ERROR(cudaEventDestroy(start));
HANDLE_ERROR(cudaEventDestroy(stop));
HANDLE_ERROR(cudaFree(dev_histo));
HANDLE_ERROR(cudaFree(dev_buffer));
free(buffer);
return 0;
}使用全局内存原子操作的直方图核函数:atomicAdd
相比cpu上运行的版本更慢许多,可能是因为数据竞争导致操作被串行化
// 宏定义用于控制测试数据量
#define SIZE (100 * 1024 * 1024) // 100MB大小的测试数据
// 直方图计算核函数
__global__ void histo_kernel(unsigned char *buffer, long size, unsigned int *histo)
{
// 线程全局索引计算
int i = threadIdx.x + blockIdx.x * blockDim.x;
// 步长计算(同步修改blockdim.griddim的大小写错误)
int stride = blockDim.x * gridDim.x; // 总线程数 = 块数×每块线程数
// 网格跨步循环模式(解决大数据量中的线程不足问题)
while (i < size)
{
// 原子操作统计直方图
atomicAdd(&histo[buffer[i]], 1); // 正确形式:缓冲区值作为索引
// 以步长递增跳过已处理元素(确保所有数据被覆盖)
i += stride; // 固定写法
}
}使用共享内存原子操作和全局内存原子操作的直方图核函数
为了减少大量线程在少量地址上发生竞争,需要将直方图计算分为两个阶段
- 每个线程块中线程在共享内存中计算直方图,避免每次写入操作从芯片发送到DRAM。此时更少的线程在更少的地址上发生更少竞争
- 使用共享内存保存临时直方图,同步操作保证初始化操作在线程继续前完成
- 在局部直方图中统计,并同步操作
- 将临时直方图合并到全局直方图
__global__ void histo_kernel(unsigned char* buffer, long size, unsigned int* histo)
{
// 共享内存声明(每个block分配256个int)
__shared__ unsigned int temp[256];
// 1.1 线程局部初始化共享内存
if(threadIdx.x < 256) { // 仅前256个线程执行
temp[threadIdx.x] = 0; // 初始化当前block的共享内存直方图
}
__syncthreads(); // 块内线程同步
// 1.2 计算临时直方图
// 计算全局索引和步长
int i = blockIdx.x * blockDim.x + threadIdx.x; // 全局线程索引
int offset = blockDim.x * gridDim.x; // 总线程数(步长)
// 网格跨步循环处理数据
while(i < size) {
atomicAdd(&temp[buffer[i]], 1); // 向共享内存原子累加
i += offset; // 跨步处理后续数据
}
__syncthreads(); // 确保块内所有计算完成
// 1.3 计算全局直方图
// 将共享内存结果合并到全局内存
if(threadIdx.x < 256) { // 仅前256个线程执行
atomicAdd(&histo[threadIdx.x], temp[threadIdx.x]); // 全局原子操作
}
}流
不同线程执行完全不相干的任务。
页锁定内存
malloc 分配可分页的(Pagable)主机内存, cudaHostAlloc 分配主机上的页锁定的主机内存,页锁定内存也称固定内存(Pinned Memory)或不可分页内存。操作系统不会对这块内存分页并交换到磁盘,从而确保该内存始终驻留在物理内存中。应用可以访问该内存的物理地址,因为其不会被破坏或重新定位。
进而可以通过DMA进行GPU与host间的数据复制,建议仅对 cudaMemcpy 调用的内存使用页锁定内存。
#include <cuda_runtime.h>
#include <stdio.h>
// 错误处理宏
#define HANDLE_ERROR(err) (cudaErrorCheck(err, __FILE__, __LINE__))
static void cudaErrorCheck(cudaError_t err, const char *file, int line) {
if (err != cudaSuccess) {
printf("%s in %s at line %d\n", cudaGetErrorString(err), file, line);
exit(EXIT_FAILURE);
}
}
#define SIZE (10 * 1024 * 1024) // 测试数据量:10MB
// 测试普通设备内存性能
float cuda_malloc_test(int size, bool up) {
cudaEvent_t start, stop;
int *a, *dev_a;
float elapsedTime;
// 创建计时事件(修正参数括号错误)
HANDLE_ERROR(cudaEventCreate(&start));
HANDLE_ERROR(cudaEventCreate(&stop));
// 分配主机和设备内存
a = (int*)malloc(size * sizeof(int)); // 可分页主机内存
HANDLE_ERROR(cudaMalloc(&dev_a, size * sizeof(int))); // 设备内存
// 计时开始
HANDLE_ERROR(cudaEventRecord(start, 0));
// 执行100次内存复制(修正循环括号和参数顺序)
for (int i = 0; i < 100; i++) {
if (up) // 根据up标志决定复制方向
HANDLE_ERROR(cudaMemcpy(dev_a, a, size*sizeof(int), cudaMemcpyHostToDevice));
else
HANDLE_ERROR(cudaMemcpy(a, dev_a, size*sizeof(int), cudaMemcpyDeviceToHost));
}
// 计时结束并计算
HANDLE_ERROR(cudaEventRecord(stop, 0));
HANDLE_ERROR(cudaEventSynchronize(stop));
HANDLE_ERROR(cudaEventElapsedTime(&elapsedTime, start, stop));
// 释放资源
free(a);
HANDLE_ERROR(cudaFree(dev_a));
HANDLE_ERROR(cudaEventDestroy(start));
HANDLE_ERROR(cudaEventDestroy(stop));
return elapsedTime;
}
// 测试固定内存性能
float cuda_host_alloc_test(int size, bool up) {
cudaEvent_t start, stop;
int *a, *dev_a;
float elapsedTime;
HANDLE_ERROR(cudaEventCreate(&start));
HANDLE_ERROR(cudaEventCreate(&stop));
// 分配固定主机内存
HANDLE_ERROR(cudaHostAlloc(&a, size*sizeof(int), cudaHostAllocDefault));
HANDLE_ERROR(cudaMalloc(&dev_a, size*sizeof(int)));
// 执行测试
HANDLE_ERROR(cudaEventRecord(start, 0));
for (int i = 0; i < 100; i++) {
if (up)
HANDLE_ERROR(cudaMemcpy(dev_a, a, size*sizeof(int), cudaMemcpyHostToDevice));
else
HANDLE_ERROR(cudaMemcpy(a, dev_a, size*sizeof(int), cudaMemcpyDeviceToHost));
}
HANDLE_ERROR(cudaEventRecord(stop, 0));
HANDLE_ERROR(cudaEventSynchronize(stop));
HANDLE_ERROR(cudaEventElapsedTime(&elapsedTime, start, stop));
// 释放固定内存
HANDLE_ERROR(cudaFreeHost(a));
HANDLE_ERROR(cudaFree(dev_a));
HANDLE_ERROR(cudaEventDestroy(start));
HANDLE_ERROR(cudaEventDestroy(stop));
return elapsedTime;
}
int main() {
float elapsedTime;
const float MB = (float)100*SIZE/1024/1024; // 总传输量:100次×10MB=1000MB
// 测试普通内存上行性能(Host->Device)
elapsedTime = cuda_malloc_test(SIZE, true);
printf("cudaMalloc 上行时间: %3.1f ms\n", elapsedTime);
printf("\t传输速率: %3.1f MB/s\n", MB*1000/elapsedTime);
// 测试普通内存下行性能(Device->Host)
elapsedTime = cuda_malloc_test(SIZE, false);
printf("cudaMalloc 下行时间: %3.1f ms\n", elapsedTime);
printf("\t传输速率: %3.1f MB/s\n", MB*1000/elapsedTime);
// 测试固定内存上行性能
elapsedTime = cuda_host_alloc_test(SIZE, true);
printf("cudaHostAlloc 上行时间: %3.1f ms\n", elapsedTime);
printf("\t传输速率: %3.1f MB/s\n", MB*1000/elapsedTime);
// 测试固定内存下行性能
elapsedTime = cuda_host_alloc_test(SIZE, false);
printf("cudaHostAlloc 下行时间: %3.1f ms\n", elapsedTime);
printf("\t传输速率: %3.1f MB/s\n", MB*1000/elapsedTime);
return 0;
}CUDA 流
事件概念中record函数的第二个参数就是用于指定插入事件的流 Stream
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventRecord(start, 0);CUDA流表示一个以指定顺序执行的GPU操作队列,可以添加核函数启动、内存复制、事件启动结束等操作,操作的添加顺序就是他们的执行顺序。可以将流视为一个GPU上的任务,且任务可以并行执行。
API:
cudaStreamCreate(&stream); // 创建流对象
cudaStreamDestroy(stream); // 释放流资源
cudaMemcpyAsync(..., stream);
kernel<<<grid, block, sharedMem, stream>>>();
cudaStreamSynchronize(stream); // 等待流完成
cudaDeviceSynchronize(); // 等待所有流
cudaHostAlloc() // 分配固定内存单个CUDA流
仅当使用多个流时才显现出流的威力
- 选择支持设备重叠功能的设备,这种GPU在执行一个cuda核函数同时还能在设备和主机间复制数据
- 主机上
cudaHostMalloc分配页锁定内存,使用cudaMemcpy复制数据 - 在kernel函数执行前后,将数据分块在设备和主机间复制
- 使用
cudaMemcpyAsync复制,将操作放入stream流中 - 因为是异步执行,主机代码无法确定函数的执行进度
- 流中的代码按照加入流的顺序执行
- kernel 的尖括号中可增加一个流参数,这是核函数就是异步执行的
- 使用
- 使用
cudaStreamSynchronize(stream)等待异步执行的流完成
#include <cuda_runtime.h>
#include <stdio.h>
#include <stdlib.h>
// 错误检查宏
#define HANDLE_ERROR(err) (HandleError(err, __FILE__, __LINE__))
static void HandleError(cudaError_t err, const char* file, int line) {
if (err != cudaSuccess) {
printf("%s in %s at line %d\n", cudaGetErrorString(err), file, line);
exit(EXIT_FAILURE);
}
}
// 常量定义
#define N (1024 * 1024) // 单个数据块大小
#define FULL_DATA_SIZE (N*20) // 总数据量:20个块
// 核函数,内容不重要
__global__ void process_kernel(int *a, int *b, int *c) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < N) {
// 示例计算:相邻元素的均值滤波
int idx1 = (idx + 1) % 256;
int idx2 = (idx + 2) % 256;
float as = (a[idx] + a[idx1] + a[idx2]) / 3.0f;
float bs = (b[idx] + b[idx1] + b[idx2]) / 3.0f;
c[idx] = (as + bs) / 2;
}
}
int main() {
// 设备检测
cudaDeviceProp prop;
int devID;
HANDLE_ERROR(cudaGetDevice(&devID));
HANDLE_ERROR(cudaGetDeviceProperties(&prop, devID));
if (!prop.deviceOverlap) {
printf("设备不支持流重叠,无法加速\n");
return 0;
}
// 计时事件
cudaEvent_t start, stop;
HANDLE_ERROR(cudaEventCreate(&start));
HANDLE_ERROR(cudaEventCreate(&stop));
// 创建CUDA流(核心对象)
cudaStream_t stream;
HANDLE_ERROR(cudaStreamCreate(&stream));
// 主机内存分配(固定内存)
int *host_a, *host_b, *host_c;
HANDLE_ERROR(cudaHostAlloc(&host_a, FULL_DATA_SIZE*sizeof(int), cudaHostAllocDefault));
HANDLE_ERROR(cudaHostAlloc(&host_b, FULL_DATA_SIZE*sizeof(int), cudaHostAllocDefault));
HANDLE_ERROR(cudaHostAlloc(&host_c, FULL_DATA_SIZE*sizeof(int), cudaHostAllocDefault));
// 设备内存分配
int *dev_a, *dev_b, *dev_c;
HANDLE_ERROR(cudaMalloc(&dev_a, N*sizeof(int)));
HANDLE_ERROR(cudaMalloc(&dev_b, N*sizeof(int)));
HANDLE_ERROR(cudaMalloc(&dev_c, N*sizeof(int)));
// 初始化数据
for (int i=0; i<FULL_DATA_SIZE; i++) {
host_a[i] = rand() % 256;
host_b[i] = rand() % 256;
}
// 开始计时
HANDLE_ERROR(cudaEventRecord(start, 0));
// 分块处理(流式并行核心)
for (int i=0; i<FULL_DATA_SIZE; i+=N) {
// 异步内存复制(主机->设备)
HANDLE_ERROR(cudaMemcpyAsync(dev_a, host_a+i, N*sizeof(int),
cudaMemcpyHostToDevice, stream));
HANDLE_ERROR(cudaMemcpyAsync(dev_b, host_b+i, N*sizeof(int),
cudaMemcpyHostToDevice, stream));
// 启动核函数(指定流)
dim3 block(256);
dim3 grid((N + block.x -1)/block.x);
process_kernel<<<grid, block, 0, stream>>>(dev_a, dev_b, dev_c);
// 异步内存复制(设备->主机)
HANDLE_ERROR(cudaMemcpyAsync(host_c+i, dev_c, N*sizeof(int),
cudaMemcpyDeviceToHost, stream));
}
// 流同步等待所有操作完成
HANDLE_ERROR(cudaStreamSynchronize(stream));
// 停止计时
HANDLE_ERROR(cudaEventRecord(stop, 0));
HANDLE_ERROR(cudaEventSynchronize(stop));
float elapsedTime;
HANDLE_ERROR(cudaEventElapsedTime(&elapsedTime, start, stop));
printf("总耗时: %.1f ms\n", elapsedTime);
// 资源释放
HANDLE_ERROR(cudaFreeHost(host_a));
HANDLE_ERROR(cudaFreeHost(host_b));
HANDLE_ERROR(cudaFreeHost(host_c));
HANDLE_ERROR(cudaFree(dev_a));
HANDLE_ERROR(cudaFree(dev_b));
HANDLE_ERROR(cudaFree(dev_c));
HANDLE_ERROR(cudaStreamDestroy(stream));
HANDLE_ERROR(cudaEventDestroy(start));
HANDLE_ERROR(cudaEventDestroy(stop));
return 0;
}多个CUDA流
实现流水线效果

#include <cuda_runtime.h>
#include <stdio.h>
#include <stdlib.h>
#define N (1024 * 1024) // 每个数据块大小
#define FULL_DATA_SIZE (N*20) // 总数据量:20个块
// 错误检查宏
#define HANDLE_ERROR(err) (HandleError(err, __FILE__, __LINE__))
static void HandleError(cudaError_t err, const char* file, int line) {
if (err != cudaSuccess) {
printf("%s in %s at line %d\n", cudaGetErrorString(err), file, line);
exit(EXIT_FAILURE);
}
}
// 示例核函数(数据滤波处理)
__global__ void kernel(int* a, int* b, int* c) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < N) {
c[idx] = (a[idx] + b[idx]) / 2; // 简单均值计算
}
}
int main() {
// 设备能力检测
cudaDeviceProp prop;
int whichDevice;
HANDLE_ERROR(cudaGetDevice(&whichDevice));
HANDLE_ERROR(cudaGetDeviceProperties(&prop, whichDevice));
if (!prop.deviceOverlap) {
printf("设备不支持流重叠,无法加速\n");
return 0;
}
// 计时事件
cudaEvent_t start, stop;
HANDLE_ERROR(cudaEventCreate(&start));
HANDLE_ERROR(cudaEventCreate(&stop));
// 创建两个流
cudaStream_t stream0, stream1;
HANDLE_ERROR(cudaStreamCreate(&stream0));
HANDLE_ERROR(cudaStreamCreate(&stream1));
// 分配页锁定主机内存(固定内存)
int *host_a, *host_b, *host_c;
HANDLE_ERROR(cudaHostAlloc(&host_a, FULL_DATA_SIZE*sizeof(int), cudaHostAllocDefault));
HANDLE_ERROR(cudaHostAlloc(&host_b, FULL_DATA_SIZE*sizeof(int), cudaHostAllocDefault));
HANDLE_ERROR(cudaHostAlloc(&host_c, FULL_DATA_SIZE*sizeof(int), cudaHostAllocDefault));
// 初始化数据
for(int i=0; i<FULL_DATA_SIZE; i++) {
host_a[i] = rand() % 256;
host_b[i] = rand() % 256;
}
// 分配设备内存(双流双缓冲)
int *dev_a0, *dev_b0, *dev_c0; // 流0使用的设备内存
int *dev_a1, *dev_b1, *dev_c1; // 流1使用的设备内存
HANDLE_ERROR(cudaMalloc(&dev_a0, N*sizeof(int)));
HANDLE_ERROR(cudaMalloc(&dev_b0, N*sizeof(int)));
HANDLE_ERROR(cudaMalloc(&dev_c0, N*sizeof(int)));
HANDLE_ERROR(cudaMalloc(&dev_a1, N*sizeof(int)));
HANDLE_ERROR(cudaMalloc(&dev_b1, N*sizeof(int)));
HANDLE_ERROR(cudaMalloc(&dev_c1, N*sizeof(int)));
// 开始计时
HANDLE_ERROR(cudaEventRecord(start, 0));
// 流式并行处理主循环
for(int i=0; i<FULL_DATA_SIZE; i+=N*2) {
//==== 流0处理第i个数据块 ====//
// 异步拷贝输入数据(Host->Device)
HANDLE_ERROR(cudaMemcpyAsync(dev_a0, host_a+i, N*sizeof(int),
cudaMemcpyHostToDevice, stream0));
HANDLE_ERROR(cudaMemcpyAsync(dev_b0, host_b+i, N*sizeof(int),
cudaMemcpyHostToDevice, stream0));
// 启动核函数
dim3 block(256);
dim3 grid((N + block.x -1)/block.x);
kernel<<<grid, block, 0, stream0>>>(dev_a0, dev_b0, dev_c0);
// 异步拷贝输出数据(Device->Host)
HANDLE_ERROR(cudaMemcpyAsync(host_c+i, dev_c0, N*sizeof(int),
cudaMemcpyDeviceToHost, stream0));
//==== 流1处理第i+1个数据块 ====//
// 异步拷贝输入数据(Host->Device)
HANDLE_ERROR(cudaMemcpyAsync(dev_a1, host_a+i+N, N*sizeof(int),
cudaMemcpyHostToDevice, stream1));
HANDLE_ERROR(cudaMemcpyAsync(dev_b1, host_b+i+N, N*sizeof(int),
cudaMemcpyHostToDevice, stream1));
// 启动核函数
kernel<<<grid, block, 0, stream1>>>(dev_a1, dev_b1, dev_c1);
// 异步拷贝输出数据(Device->Host)
HANDLE_ERROR(cudaMemcpyAsync(host_c+i+N, dev_c1, N*sizeof(int),
cudaMemcpyDeviceToHost, stream1));
}
// 同步所有流
HANDLE_ERROR(cudaStreamSynchronize(stream0));
HANDLE_ERROR(cudaStreamSynchronize(stream1));
// 停止计时
HANDLE_ERROR(cudaEventRecord(stop, 0));
HANDLE_ERROR(cudaEventSynchronize(stop));
float elapsedTime;
HANDLE_ERROR(cudaEventElapsedTime(&elapsedTime, start, stop));
printf("总耗时: %.1f ms\n", elapsedTime);
// 释放资源
HANDLE_ERROR(cudaFreeHost(host_a));
HANDLE_ERROR(cudaFreeHost(host_b));
HANDLE_ERROR(cudaFreeHost(host_c));
HANDLE_ERROR(cudaFree(dev_a0));
HANDLE_ERROR(cudaFree(dev_b0));
HANDLE_ERROR(cudaFree(dev_c0));
HANDLE_ERROR(cudaFree(dev_a1));
HANDLE_ERROR(cudaFree(dev_b1));
HANDLE_ERROR(cudaFree(dev_c1));
HANDLE_ERROR(cudaStreamDestroy(stream0));
HANDLE_ERROR(cudaStreamDestroy(stream1));
HANDLE_ERROR(cudaEventDestroy(start));
HANDLE_ERROR(cudaEventDestroy(stop));
return 0;
}经测试发现,并没有太快。要从GPU任务调度角度去看
GPU 工作调度原理
从用户的角度不同流是独立的,但CPU角度:一个或多个引擎执行复制操作,一个引擎执行核函数;这些引擎彼此独立操作队列中元素。
上一个多流任务的调度如下: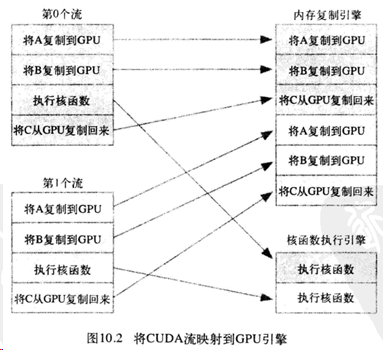
其中一号流的任务要在零号流的操作全部接收后才可以开始,依赖关系如下: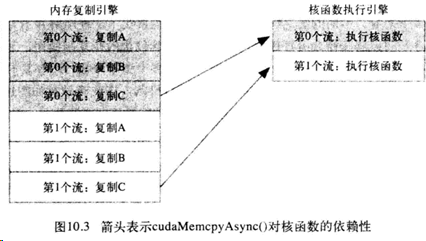
分析可知执行时间线如下: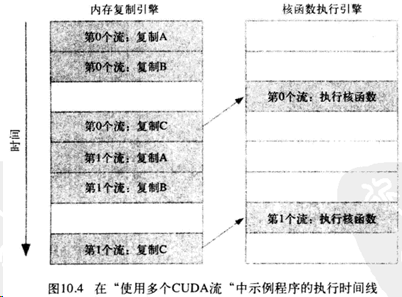
优化后的执行时间线,通常应该使用宽度优先或轮询方式将工作分配到流: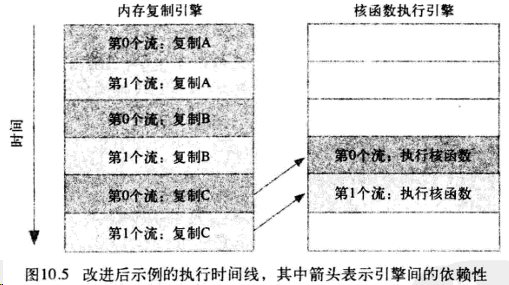
for(int i=0; i<FULL_DATA_SIZE; i += N*2) {
//==== 流0处理第i个数据块 ====//
// 异步传输输入数据(Host->Device)
HANDLE_ERROR(cudaMemcpyAsync(dev_a0, host_a + i, N*sizeof(int), cudaMemcpyHostToDevice, stream0));
HANDLE_ERROR(cudaMemcpyAsync(dev_b0, host_b + i, N*sizeof(int), cudaMemcpyHostToDevice, stream0));
//==== 流1处理第i+1个数据块 ====//
// 异步传输输入数据(Host->Device)
HANDLE_ERROR(cudaMemcpyAsync(dev_a1, host_a + i + N, N*sizeof(int), cudaMemcpyHostToDevice, stream1));
HANDLE_ERROR(cudaMemcpyAsync(dev_b1, host_b + i + N, N*sizeof(int), cudaMemcpyHostToDevice, stream1));
// 启动核函数(流0)
dim3 block(256);
dim3 grid((N + block.x -1)/block.x);
kernel<<<grid, block, 0, stream0>>>(dev_a0, dev_b0, dev_c0);
// 启动核函数(流1)
kernel<<<grid, block, 0, stream1>>>(dev_a1, dev_b1, dev_c1);
// 异步传输输出数据(Device->Host)
HANDLE_ERROR(cudaMemcpyAsync(host_c + i, dev_c0, N*sizeof(int), cudaMemcpyDeviceToHost, stream0));
// 异步传输输出数据(Device->Host)
HANDLE_ERROR(cudaMemcpyAsync(host_c + i + N, dev_c1, N*sizeof(int), cudaMemcpyDeviceToHost, stream1));
}多GPU
零拷贝
使用 cudaHostAlloc() 分配页锁定内存时使用参数 cudaHostAllocDefault 获得默认的固定内存。使用 cudaHostAllocMapped 参数分配的内存类似,除了用于主机与GPU间内存复制还可以实现:cuda核函数直接访问这种类型主机内存,由于不需要复制到GPU,也称为零拷贝。
#include <stdio.h>
#include <cuda_runtime.h>
// 错误处理宏
#define HANDLE_ERROR(err) (cudaErrorCheck(err, __FILE__, __LINE__))
// 核函数声明
__global__ void dot(float* a, float* b, float* partial_c);
/**************************************
* 常规CUDA内存分配测试函数
* size: 要分配的内存大小
* return: 计算耗时(毫秒)
**************************************/
float malloc_test(int size) {
cudaEvent_t start, stop; // CUDA事件计时器
float *a, *b, *partial_c; // 主机端指针
float *dev_a, *dev_b, *dev_partial_c; // 设备端指针
float elapsedTime, C = 0;
// 创建CUDA事件
HANDLE_ERROR(cudaEventCreate(&start));
HANDLE_ERROR(cudaEventCreate(&stop));
// 主机内存分配
a = (float*)malloc(size * sizeof(float));
b = (float*)malloc(size * sizeof(float));
partial_c = (float*)malloc(blockPerGrid * sizeof(float));
// 设备内存分配
HANDLE_ERROR(cudaMalloc(&dev_a, size * sizeof(float)));
HANDLE_ERROR(cudaMalloc(&dev_b, size * sizeof(float)));
HANDLE_ERROR(cudaMalloc(&dev_partial_c, blockPerGrid * sizeof(float)));
// 初始化主机数据
for(int i = 0; i < size; i++) {
a[i] = 1.0f;
b[i] = 1.0f;
}
// 启动计时器
HANDLE_ERROR(cudaEventRecord(start, 0));
// 数据拷贝到设备
HANDLE_ERROR(cudaMemcpy(dev_a, a, size * sizeof(float), cudaMemcpyHostToDevice));
HANDLE_ERROR(cudaMemcpy(dev_b, b, size * sizeof(float), cudaMemcpyHostToDevice));
// 启动核函数
dot<<<blockPerGrid, threadsPerBlock>>>(dev_a, dev_b, dev_partial_c);
// 拷贝结果回主机
HANDLE_ERROR(cudaMemcpy(partial_c, dev_partial_c, blockPerGrid * sizeof(float), cudaMemcpyDeviceToHost));
// 停止计时
HANDLE_ERROR(cudaEventRecord(stop, 0));
HANDLE_ERROR(cudaEventSynchronize(stop));
HANDLE_ERROR(cudaEventElapsedTime(&elapsedTime, start, stop));
// CPU端结果汇总
for(int i = 0; i < blockPerGrid; i++) {
C += partial_c[i];
}
// 释放资源
free(a); free(b); free(partial_c);
cudaFree(dev_a); cudaFree(dev_b); cudaFree(dev_partial_c);
cudaEventDestroy(start); cudaEventDestroy(stop);
printf("Value calculated: %f\n", C);
return elapsedTime;
}
/**************************************
* 零拷贝内存测试函数
* 使用cudaHostAlloc分配可映射内存
**************************************/
float cuda_host_alloc_test(int size) {
cudaEvent_t start, stop;
float *a, *b, *partial_c;
float *dev_a, *dev_b, *dev_partial_c;
float elapsedTime, C = 0;
// 创建事件
HANDLE_ERROR(cudaEventCreate(&start));
HANDLE_ERROR(cudaEventCreate(&stop));
// 分配可映射的写合并内存
HANDLE_ERROR(cudaHostAlloc(&a, size * sizeof(float),
cudaHostAllocMapped | cudaHostAllocWriteCombined));
HANDLE_ERROR(cudaHostAlloc(&b, size * sizeof(float),
cudaHostAllocMapped | cudaHostAllocWriteCombined));
HANDLE_ERROR(cudaHostAlloc(&partial_c, blockPerGrid * sizeof(float),
cudaHostAllocMapped));
// 获取设备指针
HANDLE_ERROR(cudaHostGetDevicePointer(&dev_a, a, 0));
HANDLE_ERROR(cudaHostGetDevicePointer(&dev_b, b, 0));
HANDLE_ERROR(cudaHostGetDevicePointer(&dev_partial_c, partial_c, 0));
// 数据初始化
for(int i = 0; i < size; i++) {
a[i] = 1.0f;
b[i] = 1.0f;
}
// 启动核函数
HANDLE_ERROR(cudaEventRecord(start, 0));
dot<<<blockPerGrid, threadsPerBlock>>>(dev_a, dev_b, dev_partial_c);
HANDLE_ERROR(cudaEventRecord(stop, 0));
HANDLE_ERROR(cudaEventSynchronize(stop));
// 结果汇总
for(int i = 0; i < blockPerGrid; i++) {
C += partial_c[i];
}
// 释放资源
cudaFreeHost(a); cudaFreeHost(b); cudaFreeHost(partial_c);
cudaEventDestroy(start); cudaEventDestroy(stop);
printf("Value calculated: %f\n", C);
return elapsedTime;
}
/**************************************
* 核函数实现(点积计算)
* 使用共享内存优化
**************************************/
__global__ void dot(float* a, float* b, float* partial_c) {
__shared__ float cache[threadsPerBlock]; // 共享内存缓存
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int cacheIndex = threadIdx.x;
// 计算局部和
float temp = 0;
while(tid < N) {
temp += a[tid] * b[tid];
tid += blockDim.x * gridDim.x;
}
// 存储到共享内存
cache[cacheIndex] = temp;
__syncthreads();
// 归约求和
int i = blockDim.x / 2;
while(i != 0) {
if(cacheIndex < i) {
cache[cacheIndex] += cache[cacheIndex + i];
}
__syncthreads();
i /= 2;
}
// 存储块结果
if(cacheIndex == 0) {
partial_c[blockIdx.x] = cache[0];
}
}
/**************************************
* 主函数
**************************************/
int main() {
cudaDeviceProp prop;
int deviceID;
cudaGetDevice(&deviceID);
cudaGetDeviceProperties(&prop, deviceID);
// 检查设备支持
if(!prop.canMapHostMemory) {
printf("Device does not support mapped memory!\n");
return 0;
}
// 设置设备标志
cudaSetDeviceFlags(cudaDeviceMapHost);
// 运行测试
float time1 = malloc_test(N);
float time2 = cuda_host_alloc_test(N);
printf("cudaMalloc Time: %.2f ms\n", time1);
printf("Zero-Copy Time: %.2f ms\n", time2);
return 0;
}程序满足“仅读写一次”的约束条件,使用零拷贝内存时获得性能提升。
使用多个GPU
每个GPU都需要由一个不同的CPU线程控制
#include <stdio.h>
#include <cuda_runtime.h>
// 宏定义(需补充完整错误处理实现)
#define HANDLE_ERROR(err) (cudaErrorCheck(err, __FILE__, __LINE__))
#define N (1024 * 1024) // 默认数据规模
#define threadsPerBlock 256 // 每个块线程数
#define blockPerGrid (N/threadsPerBlock) // 总块数
// 错误处理宏实现示例
#define cudaErrorCheck(err, file, line) \
if(err != cudaSuccess) { \
printf("CUDA Error: %s in %s at line %d\n", cudaGetErrorString(err), file, line); \
exit(EXIT_FAILURE); \
}
// 线程管理函数原型(需根据实际线程库实现)
void start_thread(pthread_t* thread, void* (*func)(void*), void* arg);
void end_thread(pthread_t thread);
// 数据结构:封装多GPU计算参数
typedef struct DataStruct {
int deviceID; // GPU设备ID
int size; // 当前设备处理的数据量
float *a; // 输入缓冲区A指针
float *b; // 输入缓冲区B指针
float returnValue; // 计算结果存储
} DataStruct;
/***************************************
* 核函数:并行点积计算(含共享内存优化)
* size: 数据量
* dev_a, dev_b: 设备端输入数组
* dev_partial_c: 设备端部分和输出
***************************************/
__global__ void dot(int size, float* dev_a, float* dev_b, float* dev_partial_c) {
__shared__ float cache[threadsPerBlock]; // 共享内存缓存
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int cacheIndex = threadIdx.x;
float temp = 0;
// 计算局部点积和
while(tid < size) {
temp += dev_a[tid] * dev_b[tid];
tid += blockDim.x * gridDim.x;
}
cache[cacheIndex] = temp;
__syncthreads();
// 归约求和(树形归约法)
int i = blockDim.x / 2;
while(i != 0) {
if(cacheIndex < i) {
cache[cacheIndex] += cache[cacheIndex + i];
}
__syncthreads();
i /= 2;
}
if(cacheIndex == 0) {
dev_partial_c[blockIdx.x] = cache[0];
}
}
/***************************************
* GPU计算线程函数
* pvoidData: 包含计算参数的DataStruct指针
***************************************/
void* routine(void* pvoidData) {
DataStruct* data = (DataStruct*)pvoidData;
float *a, *b, *partial_c;
float *dev_a, *dev_b, *dev_partial_c;
float c = 0;
int size = data->size;
// 设置当前线程使用的GPU设备
HANDLE_ERROR(cudaSetDevice(data->deviceID));
// 主机内存分配
a = data->a;
b = data->b;
partial_c = (float*)malloc(blockPerGrid * sizeof(float));
// 设备内存分配
HANDLE_ERROR(cudaMalloc((void**)&dev_a, size * sizeof(float)));
HANDLE_ERROR(cudaMalloc((void**)&dev_b, size * sizeof(float)));
HANDLE_ERROR(cudaMalloc((void**)&dev_partial_c, blockPerGrid * sizeof(float)));
// 数据传输:主机->设备
HANDLE_ERROR(cudaMemcpy(dev_a, a, size * sizeof(float), cudaMemcpyHostToDevice));
HANDLE_ERROR(cudaMemcpy(dev_b, b, size * sizeof(float), cudaMemcpyHostToDevice));
// 启动核函数计算点积
dot<<<blockPerGrid, threadsPerBlock>>>(size, dev_a, dev_b, dev_partial_c);
// 取回部分和结果
HANDLE_ERROR(cudaMemcpy(partial_c, dev_partial_c,
blockPerGrid * sizeof(float), cudaMemcpyDeviceToHost));
// CPU端结果汇总
for(int i = 0; i < blockPerGrid; i++) {
c += partial_c[i];
}
// 资源释放
free(partial_c);
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_partial_c);
data->returnValue = c; // 存储计算结果
return 0;
}
/***************************************
* 主函数
***************************************/
int main() {
int deviceCount;
float *a, *b;
// 获取CUDA设备数量
HANDLE_ERROR(cudaGetDeviceCount(&deviceCount));
if(deviceCount < 2) {
printf("需要至少2个CUDA设备,当前检测到%d个\n", deviceCount);
return -1;
}
// 分配主机内存
a = (float*)malloc(N * sizeof(float));
b = (float*)malloc(N * sizeof(float));
for(int i = 0; i < N; i++) {
a[i] = 1.0f;
b[i] = 1.0f;
}
// 初始化多GPU任务结构
DataStruct data[2];
data[0].deviceID = 0; // 第一个GPU
data[0].size = N/2; // 分配半数数据
data[0].a = a; // 指向数组起始位置
data[0].b = b;
data[1].deviceID = 1; // 第二个GPU
data[1].size = N/2;
data[1].a = a + N/2; // 指向后半段数据
data[1].b = b + N/2;
// 创建计算线程(假设start_thread为自定义线程创建函数)
pthread_t thread;
start_thread(&thread, routine, &data[0]); // 创建线程处理第一个GPU
routine(&data[1]); // 主线程处理第二个GPU
end_thread(thread); // 等待子线程完成
// 汇总并显示结果
printf("计算结果: %f\n", data[0].returnValue + data[1].returnValue);
// 资源释放
free(a);
free(b);
return 0;
}可移动的固定内存
通过可移动的固定内存使多个GPU共享固定内存。
相关API
/*
内存分配优化
cudaHostAllocPortable:使固定内存可在不同设备/线程间共享
cudaHostAllocMapped:创建零拷贝内存,GPU可直接访问
*/
cudaHostAlloc(&a, N*sizeof(float), cudaHostAllocPortable | cudaHostAllocMapped);
/*
设备指针获取
将主机固定内存映射到设备地址空间
多GPU环境下需确保已设置当前设备
*/
cudaHostGetDevicePointer(&dev_a, data->a, 0);
/*
设备上下文管理
避免重复设置设备0的上下文
确保每个线程管理自己的设备上下文
*/
if(data->deviceID != 0) {
cudaSetDevice(data->deviceID);
cudaSetDeviceFlags(cudaDeviceMapHost);
}
/*
异步操作支持
可移动内存支持异步内存拷贝(cudaMemcpyAsync)
需配合CUDA流实现计算/传输重叠
*/
dot<<<..., cudaStreamNonBlocking>>>(); // 可结合流使用性能优化:
- 内存对齐:使用
cudaHostAllocWriteCombined提升写入性能 - 负载均衡:根据GPU算力动态分配数据量
- 流式处理:使用多个CUDA流隐藏内存延迟
- 统一寻址:在Pascal+架构启用
cudaDeviceMapHost+cudaHostAllocMapped
#include <stdio.h>
#include <cuda_runtime.h>
#include <pthread.h>
#define HANDLE_ERROR(err) (cudaErrorCheck(err, __FILE__, __LINE__))
#define N (1024 * 1024) // 数据规模
#define threadsPerBlock 256 // 块内线程数
#define blockPerGrid (N/threadsPerBlock)
// 数据结构封装(支持多GPU参数传递)
typedef struct {
int deviceID; // GPU设备ID
size_t offset; // 数据偏移量
size_t size; // 处理数据量
float* a; // 输入数组A(可移动固定内存)
float* b; // 输入数组B(可移动固定内存)
float returnValue; // 计算结果存储
} DataStruct;
// 核函数:带共享内存优化的点积计算
__global__ void dot(float* a, float* b, float* partial_c, int size) {
__shared__ float cache[threadsPerBlock];
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int cacheIndex = threadIdx.x;
float temp = 0;
while(tid < size) {
temp += a[tid] * b[tid];
tid += blockDim.x * gridDim.x;
}
cache[cacheIndex] = temp;
__syncthreads();
// 归约求和优化
for(int i = blockDim.x/2; i>0; i>>=1) {
if(cacheIndex < i)
cache[cacheIndex] += cache[cacheIndex + i];
__syncthreads();
}
if(cacheIndex == 0)
partial_c[blockIdx.x] = cache[0];
}
// GPU计算线程函数(关键修改点)
void* routine(void* pvoidData) {
DataStruct* data = (DataStruct*)pvoidData;
float *partial_c, *dev_partial_c;
float *dev_a, *dev_b;
// 设备上下文设置(避免重复设置)
if(data->deviceID != 0) { // 主线程已设置设备0
HANDLE_ERROR(cudaSetDevice(data->deviceID));
HANDLE_ERROR(cudaSetDeviceFlags(cudaDeviceMapHost));
}
// 获取设备指针(零拷贝关键)
HANDLE_ERROR(cudaHostGetDevicePointer(&dev_a, data->a, 0));
HANDLE_ERROR(cudaHostGetDevicePointer(&dev_b, data->b, 0));
// 分配临时设备内存
HANDLE_ERROR(cudaMalloc(&dev_partial_c, blockPerGrid * sizeof(float)));
partial_c = (float*)malloc(blockPerGrid * sizeof(float));
// 启动核函数
dot<<<blockPerGrid, threadsPerBlock>>>(dev_a + data->offset,
dev_b + data->offset,
dev_partial_c,
data->size);
// 取回部分和
HANDLE_ERROR(cudaMemcpy(partial_c, dev_partial_c,
blockPerGrid * sizeof(float),
cudaMemcpyDeviceToHost));
// CPU端结果汇总
float c = 0;
for(int i=0; i<blockPerGrid; i++)
c += partial_c[i];
// 资源释放
free(partial_c);
HANDLE_ERROR(cudaFree(dev_partial_c));
data->returnValue = c;
return 0;
}
int main() {
int deviceCount;
float *a, *b;
// 1. 设备兼容性检查
HANDLE_ERROR(cudaGetDeviceCount(&deviceCount));
if(deviceCount < 2) {
printf("需要至少2个支持CUDA 1.0+的设备,当前检测到%d个\n", deviceCount);
return -1;
}
// 2. 设备属性验证(支持内存映射)
cudaDeviceProp prop;
for(int i=0; i<2; i++) {
HANDLE_ERROR(cudaGetDeviceProperties(&prop, i));
if(!prop.canMapHostMemory) {
printf("设备%d不支持内存映射\n", i);
return -1;
}
}
// 3. 分配可移动固定内存(关键修改)
HANDLE_ERROR(cudaSetDevice(0)); // 主线程设置设备0
HANDLE_ERROR(cudaSetDeviceFlags(cudaDeviceMapHost));
HANDLE_ERROR(cudaHostAlloc(&a, N*sizeof(float),
cudaHostAllocPortable | cudaHostAllocMapped));
HANDLE_ERROR(cudaHostAlloc(&b, N*sizeof(float),
cudaHostAllocPortable | cudaHostAllocMapped));
// 初始化数据
for(int i=0; i<N; i++) {
a[i] = 1.0f;
b[i] = 1.0f;
}
// 4. 任务分配(多GPU数据分割)
DataStruct data[2] = {
{0, 0, N/2, a, b, 0}, // GPU0处理前半数据
{1, N/2, N/2, a, b, 0} // GPU1处理后半数据
};
// 5. 创建计算线程
pthread_t thread;
pthread_create(&thread, NULL, routine, &data[0]); // 子线程处理GPU0
routine(&data[1]); // 主线程处理GPU1
pthread_join(thread, NULL);
// 6. 结果汇总
printf("计算结果: %f\n", data[0].returnValue + data[1].returnValue);
// 7. 释放可移动固定内存
HANDLE_ERROR(cudaFreeHost(a));
HANDLE_ERROR(cudaFreeHost(b));
return 0;
}通过可移动固定内存解决了多GPU环境下的两个关键问题:
- 跨线程内存访问性能下降
- 异步操作失败问题

 浙公网安备 33010602011771号
浙公网安备 33010602011771号