springboot & springCloud
Build Anything with Spring Boot:Spring Boot is the starting point for building all Spring-based applications. Spring Boot is designed to get you up and running as quickly as possible, with minimal upfront configuration of Spring.
上面是引自官网的一段话,大概是说: Spring Boot 是所有基于 Spring 开发的项目的起点。Spring Boot 的设计是为了让你尽可能快的跑起来 Spring 应用程序并且尽可能减少你的配置文件。
约定优于配置(Convention over Configuration),又称按约定编程,是一种软件设计范式。
本质上是说,系统、类库或框架应该假定合理的默认值,而非要求提供不必要的配置。比如说模型中有一个名为User的类,那么数据库中对应的表就会默认命名为user。只有在偏离这一个约定的时候,例如想要将该表命名为person,才需要写有关这个名字的配置。
比如平时架构师搭建项目就是限制软件开发随便写代码,制定出一套规范,让开发人员按统一的要求进行开发编码测试之类的,这样就加强了开发效率与审查代码效率。所以说写代码的时候就需要按要求命名,这样统一规范的代码就有良好的可读性与维护性了
约定优于配置简单来理解,就是遵循约定
SpringBoot概念
Spring优缺点分析
优点:
Spring是Java企业版(Java Enterprise Edition,JEE,也称J2EE)的轻量级代替品。无需开发重量级的Enterprise Java Bean(EJB),Spring为企业级Java开发提供了一种相对简单的方法,通过依赖注入和面向切面编程,用简单的Java对象(Plain Old Java Object,POJO)实现了EJB的功能
缺点:
虽然Spring的组件代码是轻量级的,但它的配置却是重量级的。一开始,Spring用XML配置,而且是很多XML配 置。Spring 2.5引入了基于注解的组件扫描,这消除了大量针对应用程序自身组件的显式XML配置。Spring 3.0引入 了基于Java的配置,这是一种类型安全的可重构配置方式,可以代替XML。
所有这些配置都代表了开发时的损耗。因为在思考Spring特性配置和解决业务问题之间需要进行思维切换,所以编写配置挤占了编写应用程序逻辑的时间。和所有框架一样,Spring实用,但与此同时它要求的回报也不少。
除此之外,项目的依赖管理也是一件耗时耗力的事情。在环境搭建时,需要分析要导入哪些库的坐标,而且还需要分析导入与之有依赖关系的其他库的坐标,一旦选错了依赖的版本,随之而来的不兼容问题就会严重阻碍项目的开发进度
SSM整合:Spring、Spring MVC、Mybatis、Spring-Mybatis整合包、数据库驱动,引入依赖的数量繁多、容易存在版本冲突。
Spring Boot解决上述spring问题
SpringBoot对上述Spring的缺点进行的改善和优化,基于约定优于配置的思想,可以让开发人员不必在配置与逻辑 业务之间进行思维的切换,全身心的投入到逻辑业务的代码编写中,从而大大提高了开发的效率,一定程度上缩短 了项目周期。
起步依赖
起步依赖本质上是一个Maven项目对象模型(Project Object Model,POM),定义了对其他库的传递依赖,这些东西加在一起即支持某项功能。
简单的说,起步依赖就是将具备某种功能的依赖坐标打包到一起,并提供一些默认的功能。
自动配置
springboot的自动配置,指的是springboot,会自动将一些配置类的bean注册进ioc容器,我们可以需要的地方使用@autowired或者@resource等注解来使用它。
“自动”的表现形式就是我们只需要引我们想用功能的包,相关的配置我们完全不用管,springboot会自动注入这些配置bean,我们直接使用这些bean即可
springboot: 简单、快速、方便地搭建项目;对主流开发框架的无配置集成;极大提高了开发、部署效率
Spring Boot入门案例
(1)依赖管理
<!-- 所用的springBoot项目都会直接或者间接的继承spring-boot-starter-parent 1.指定项目的编码格式为UTF-8 2.指定JDK版本为1.8 3.对项目依赖的版本进行管理,当前项目再引入其他常用的依赖时就需要再指定版本号,避免版本 冲突的问题 4.默认的资源过滤和插件管理 --> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.3.4.RELEASE</version> </parent> <dependencies> <!--引入Spring Web及Spring MVC相关的依赖--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> </dependencies> <!--可以将project打包为一个可以执行的jar--> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build>
(2)启动类
/** * SpringBoot的启动类通常放在二级包中,比如:com.lagou.SpringBootDemo1Application * 因为SpringBoot项目在做包扫描,会扫描启动类所在的包及其子包下的所有内容。 */ //标识当前类为SpringBoot项目的启动类 @SpringBootApplication public class SpringBootDemo1Application { public static void main(String[] args) { //样板代码 SpringApplication.run(SpringBootDemo1Application.class,args); } }
(3)Controller
package com.lagou.controller; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; @RestController @RequestMapping("/hello") public class HelloController { @RequestMapping("/boot") public String helloBoot(){ return "Hello Spring Boot"; } }
SpringBoot 快速构建
(1)使用Spring Initializr方式构建Spring Boot项目
本质上说,Spring Initializr是一个Web应用,它提供了一个基本的项目结构,能够帮助我们快速构建一个基础的Spring Boot项目
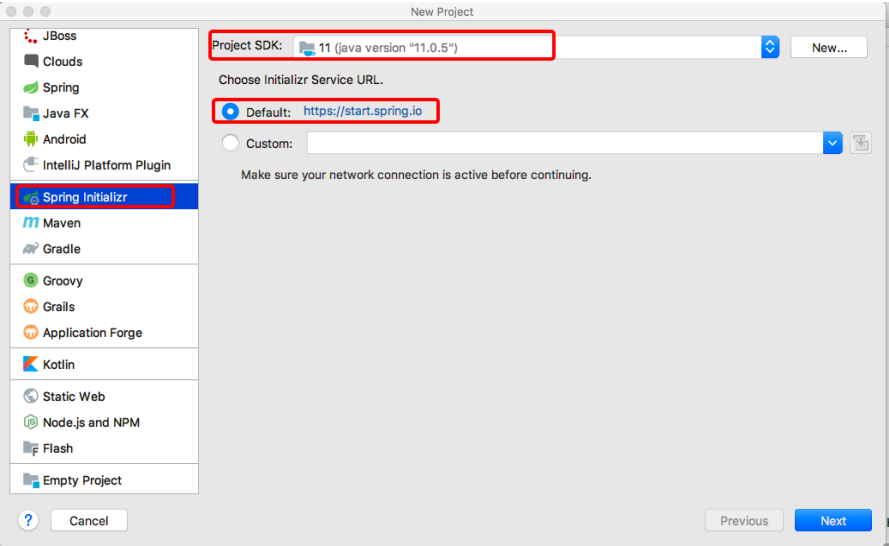

Project SDK”用于设置创建项目使用的JDK版本,这里,使用之前初始化设置好的JDK版本即可;在“Choose Initializr Service URL(选择初始化服务地址)”下使用默认的初始化服务地址“https://start.spring.io”进行Spring Boot项目创建(注意使用快速方式创建Spring Boot项目时,所在主机须在联网状态下)
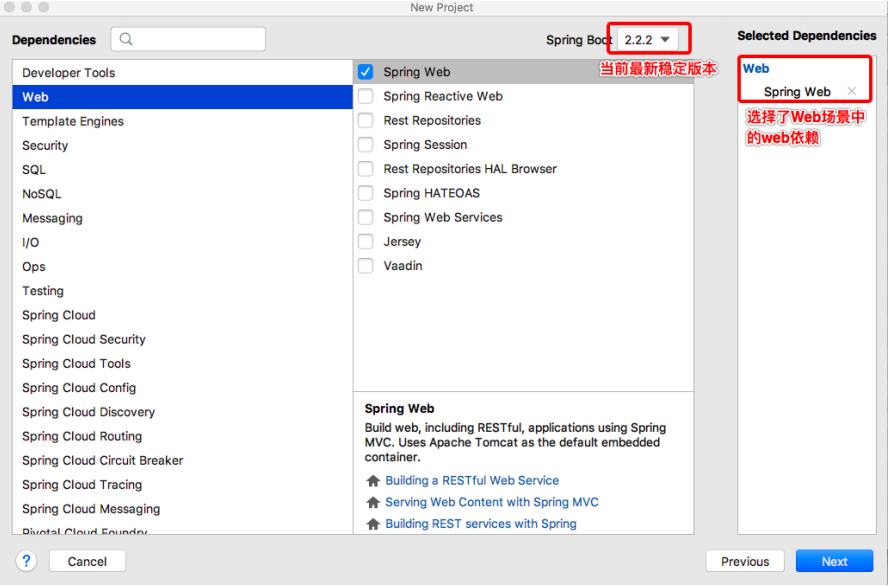
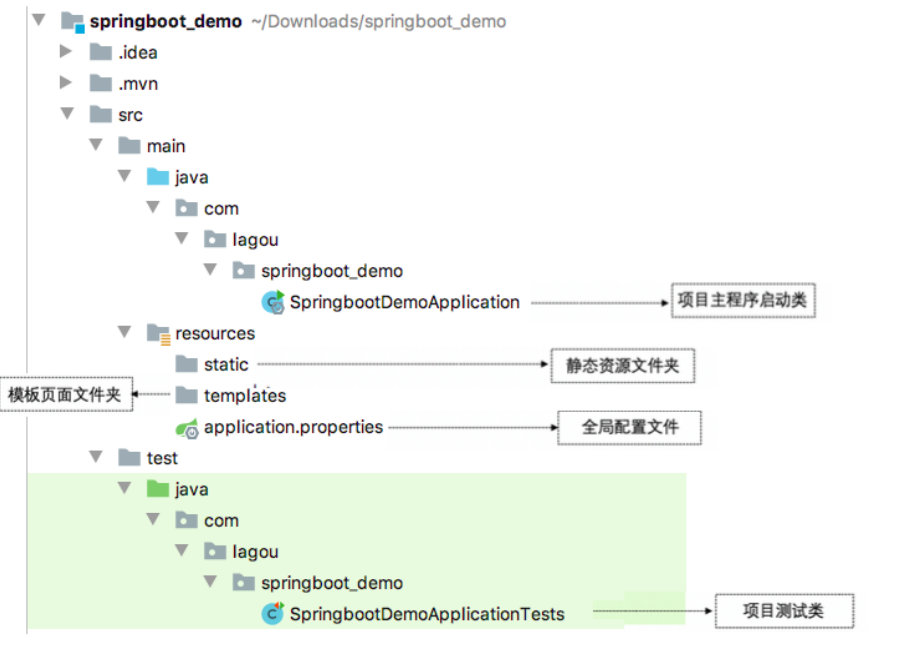
使用Spring Initializr方式构建的Spring Boot项目会默认生成项目启动类、存放前端静态资源和页面的文件夹、编写项目配置的配置文件以及进行项目单元测试的测试类
(2) 创建一个用于Web访问的Controller
com.lagou包下创建名称为controller的包,在该包下创建一个请求处理控制类HelloController,并编写一个请求处理方法 (注意:将项目启动类SpringBootDemoApplication移动到com.lagou包下)
@RestController // 该注解为组合注解,等同于Spring中@Controller+@ResponseBody注解 public class DemoController { @RequestMapping("/demo") public String demo(){ return "hello spring Boot"; } }
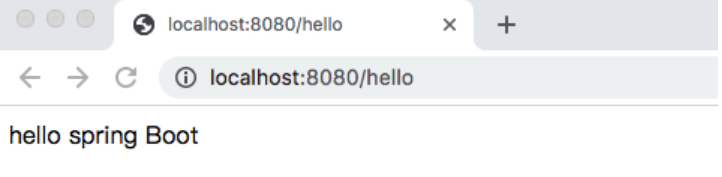
(3) 运行项目
运行主程序启动类SpringbootDemoApplication,项目启动成功后,在控制台上会发现Spring Boot项目默认启动的端口号为8080,此时,可以在浏览器上访问“http://localhost:8080/hello”
单元测试与热部署
单元测试
开发中,每当完成一个功能接口或业务方法的编写后,通常都会借助单元测试验证该功能是否正确。Spring Boot对项目的单元测试提供了很好的支持,在使用时,需要提前在项目的pom.xml文件中添加spring-boot-starter-test测试依赖启动器,可以通过相关注解实现单元测试
1.添加spring-boot-starter-test测试依赖启动器
在项目的pom.xml文件中添加spring-boot-starter-test测试依赖启动器,示例代码如下 :
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency>
注意:使用Spring Initializr方式搭建的Spring Boot项目,会自动加入spring-boot-starter-test测试依赖启动器,无需再手动添加
2.编写单元测试类和测试方法
使用Spring Initializr方式搭建的Spring Boot项目,会在src.test.java测试目录下自动创建与项目主程序启动类对应的单元测试类
package com.lagou; import com.lagou.controller.HelloController; import com.lagou.pojo.Person; import com.lagou.pojo.Product; import com.lagou.pojo.Student; import org.junit.jupiter.api.Test; import org.junit.runner.RunWith; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.context.ApplicationContext; import org.springframework.test.context.junit4.SpringRunner; /** * SpringJUnit4ClassRunner.class:Spring运行环境 * JUnit4.class:JUnit运行环境 * SpringRunner.class:Spring Boot运行环境 */ @RunWith(SpringRunner.class) //@RunWith:运行器 @SpringBootTest //标记为当前类为SpringBoot测试类,加载项目的ApplicationContext上下文环境 class Springbootdemo2ApplicationTests { /** * 需求:调用HelloController的hello方法 */ @Autowired private HelloController helloController; @Test void contextLoads() { String result = helloController.hello(); System.out.println(result); } }
热部署
在开发过程中,通常会对一段业务代码不断地修改测试,在修改之后往往需要重启服务,有些服务需要加载很久才能启动成功,这种不必要的重复操作极大的降低了程序开发效率。为此,Spring Boot框架专门提供了进行热部署的依赖启动器,用于进行项目热部署,而无需手动重启项目 。
热部署:在修改完代码之后,不需要重新启动容器,就可以实现更新。
使用步骤:
1)添加SpringBoot的热部署依赖启动器
2)开启Idea的自动编译
3)开启Idea的在项目运行中自动编译的功能
1.添加spring-boot-devtools热部署依赖启动器
在Spring Boot项目进行热部署测试之前,需要先在项目的pom.xml文件中添加spring-boot-devtools热部署依赖启动器:
<!-- 引入热部署依赖 --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-devtools</artifactId> </dependency>
由于使用的是IDEA开发工具,添加热部署依赖后可能没有任何效果,接下来还需要针对IDEA开发工具进行热部署相关的功能设置
2. IDEA工具热部署设置
选择IDEA工具界面的【File】->【Settings】选项,打开Compiler面板设置页面
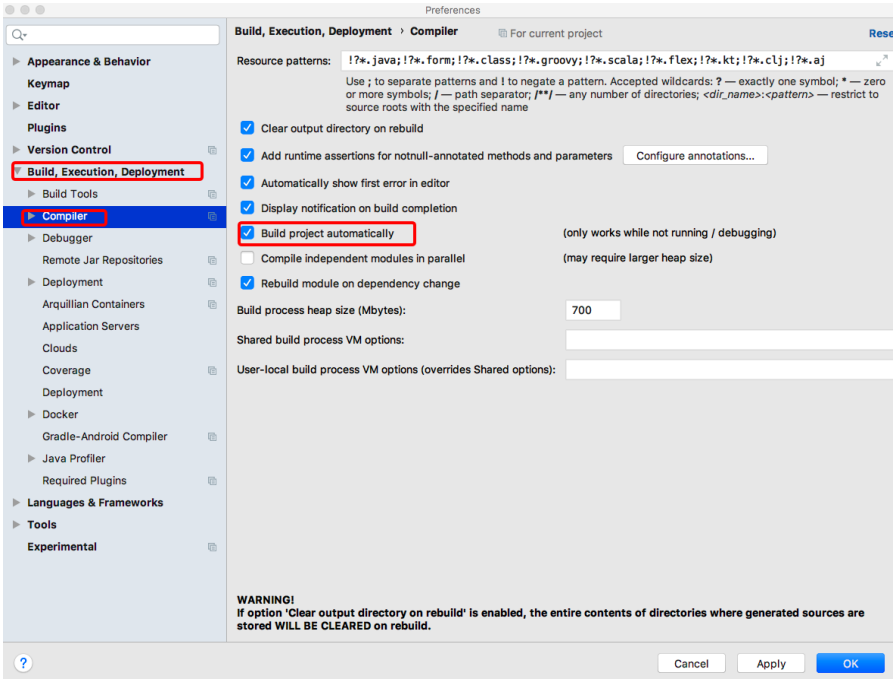
选择Build下的Compiler选项,在右侧勾选“Build project automatically”选项将项目设置为自动编译,单击【Apply】→【OK】按钮保存设置
在项目任意页面中使用组合快捷键“Ctrl+Shift+Alt+/”打开Maintenance选项框,选中并打开Registry页面,具体如图所示
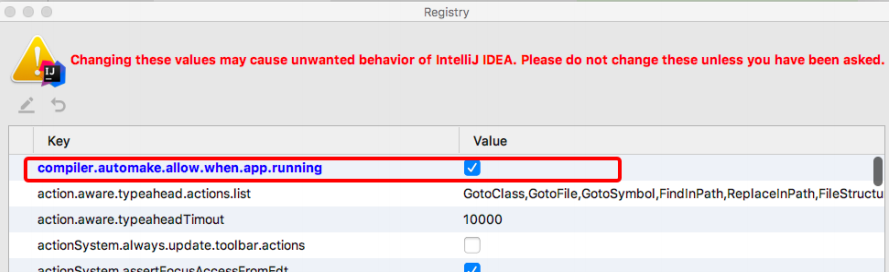
列表中找到“compiler.automake.allow.when.app.running”,将该选项后的Value值勾选,用于指定IDEA工具在程序运行过程中自动编译,最后单击【Close】按钮完成设置
全局配置文件
全局配置文件能够对一些默认配置值进行修改。Spring Boot使用一个application.properties或者application.yaml的文件作为全局配置文件,该文件存放在src/main/resource目录或者类路径的/config,一般会选择resource目录。接下来,将针对这两种全局配置文件进行讲解 :
Spring Boot配置文件的命名及其格式:
application.properties
application.yaml
application.yml
application.properties配置文件
使用Spring Initializr方式构建Spring Boot项目时,会在resource目录下自动生成一个空的application.properties文件,Spring Boot项目启动时会自动加载application.properties文件。
我们可以在application.properties文件中定义Spring Boot项目的相关属性,当然,这些相关属性可以是系统属性、环境变量、命令参数等信息,也可以是自定义配置文件名称和位置
#修改tomcat的版本号
server.port=8888
#定义数据库的连接信息 JdbcTemplate
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/lagou
spring.datasource.username=root
spring.datasource.password=wu7787879
接下来,通过一个案例对Spring Boot项目中application.properties配置文件的具体使用进行讲解
(1)先在项目的com.lagou包下创建一个pojo包,并在该包下创建两个实体类Pet和Person
public class Pet { private String type; private String name; }
@Component @ConfigurationProperties(prefix = "person") public class Person { private int id; //id private String name; //名称 private List hobby; //爱好 private String[] family; //家庭成员 private Map map; private Pet pet; //宠物 }
@ConfigurationProperties(prefix = "person")注解的作用是将配置文件中以person开头的属性值通过setXX()方法注入到实体类对应属性中
@Component注解的作用是将当前注入属性值的Person类对象作为Bean组件放到Spring容器中,只有这样才能被@ConfigurationProperties注解进行赋值
(2)打开项目的resources目录下的application.properties配置文件,在该配置文件中编写需要对Person类设置的配置属性
#自定义配置信息 person.id=1 person.name=王二麻子 person.hobby=read,write person.family=father,mather person.map.key1=value1 person.map.key2=value2 person.pet.type=dog person.pet.name=哈士奇
(3)查看application.properties配置文件是否正确,同时查看属性配置效果,打开通过IDEA工具创建的项目测试类,在该测试类中引入Person实体类Bean,并进行输出测试
@RunWith(SpringRunner.class) // 测试启动器,并加载Spring Boot测试注解 @SpringBootTest // 标记为Spring Boot单元测试类,并加载项目的ApplicationContext上下文环境 class SpringbootDemoApplicationTests { // 配置测试 @Autowired private Person person; @Test void configurationTest() { System.out.println(person); } }
(4)中文乱码问题解决
调整文件编码格式:

设置Tomcat及Http编码
#解决中文乱码
server.tomcat.uri-encoding=UTF-8
spring.http.encoding.force=true
spring.http.encoding.charset=UTF-8
spring.http.encoding.enabled=true
application.yaml配置文件
YAML文件格式是Spring Boot支持的一种JSON文件格式,相较于传统的Properties配置文件,YAML文件以数据为核心,是一种更为直观且容易被电脑识别的数据序列化格式。application.yaml配置文件的工作原理和application.properties是一样的,只不过yaml格式配置文件看起来更简洁一些。
- YAML文件的扩展名可以使用.yml或者.yaml。
- application.yml文件使用 “key:(空格)value”格式配置属性,使用缩进控制层级关系。
SpringBoot的三种配置文件是可以共存的:

这里,针对不同数据类型的属性值,介绍一下YAML
(1)value值为普通数据类型(例如数字、字符串、布尔等)
当YAML配置文件中配置的属性值为普通数据类型时,可以直接配置对应的属性值,同时对于字符串类型的属性值,不需要额外添加引号,示例代码如下
server:
port: 8080
servlet:
context-path: /hello
(2)value值为数组和单列集合
当YAML配置文件中配置的属性值为数组或单列集合类型时,主要有两种书写方式:缩进式写法和行内式写法。
其中,缩进式写法还有两种表示形式,示例代码如下
person:
hobby:
- play
- read
- sleep
或者使用如下示例形式
person:
hobby:
play,
read,
sleep
上述代码中,在YAML配置文件中通过两种缩进式写法对person对象的单列集合(或数组)类型的爱好hobby赋值为play、read和sleep。其中一种形式为“-(空格)属性值”,另一种形式为多个属性值之前加英文逗号分隔(注意,最后一个属性值后不要加逗号)。
person:
hobby: [play,read,sleep]
通过上述示例对比发现,YAML配置文件的行内式写法更加简明、方便。另外,包含属性值的中括号“[]”还可以进一步省略,在进行属性赋值时,程序会自动匹配和校对
(3)value值为Map集合和对象
当YAML配置文件中配置的属性值为Map集合或对象类型时,YAML配置文件格式同样可以分为两种书写方式:缩进式写法和行内式写法。
其中,缩进式写法的示例代码如下
person:
map:
k1: v1
k2: v2
对应的行内式写法示例代码如下
person:
map: {k1: v1,k2: v2}
在YAML配置文件中,配置的属性值为Map集合或对象类型时,缩进式写法的形式按照YAML文件格式编写即可,而行内式写法的属性值要用大括号“{}”包含。
配置文件属性值的注入
配置文件的优先级如下: 从低到高
<includes> <include>**/application*.yml</include> <include>**/application*.yaml</include> <include>**/application*.properties</include> </includes>
使用Spring Boot全局配置文件设置属性时:
如果配置属性是Spring Boot已有属性,例如服务端口server.port,那么Spring Boot内部会自动扫描并读取这些配置文件中的属性值并覆盖默认属性。
Spring Boot支持多种注入配置文件属性的方式,下面来介绍如何使用注解@ConfigurationProperties和@Value注入属性
使用@ConfigurationProperties注入属性
Spring Boot提供的@ConfigurationProperties注解用来快速、方便地将配置文件中的自定义属性值批量注入到某个Bean对象的多个对应属性中。假设现在有一个配置文件,如果使用@ConfigurationProperties注入配置文件的属性,示例代码如下:
@Component //将配置文件中所有以person开头的配置信息注入当前类中 //前提1:必须保证配置文件中person.xx与当前Person类的属性名一致 //前提2:必须保证当前Person中的属性都具有set方法 @ConfigurationProperties(prefix = "person") public class Person { private int id; //id private String name; //名称 private List hobby; //爱好 private String[] family; //家庭成员 private Map map; private Pet pet; //宠物 }
使用@Value注入属性
@Value注解是Spring框架提供的,用来读取配置文件中的属性值并逐个注入到Bean对象的对应属性中,Spring Boot框架从Spring框架中对@Value注解进行了默认继承,所以在Spring Boot框架中还可以使用该注解读取和注入配置文件属性值。使用@Value注入属性的示例代码如下
@Component public class Person { @Value("${person.id}") private int id; }
上述代码中,使用@Component和@Value注入Person实体类的id属性。其中,@Value不仅可以将配置文件的属性注入Person的id属性,还可以直接给id属性赋值,这点是@ConfigurationProperties不支持的
自定义配置
spring Boot免除了项目中大部分的手动配置,对于一些特定情况,我们可以通过修改全局配置文件以适应具体生产环境,可以说,几乎所有的配置都可以写在application.yml文件中,Spring Boot会自动加载全局配置文件从而免除我们手动加载的烦恼。但是,如果我们自定义配置文件,Spring Boot是无法识别这些配置文件的,此时就需要我们手动加载。接下来,将针对Spring Boot的自定义配置文件及其加载方式进行讲解
使用@PropertySource加载配置文件
对于这种加载自定义配置文件的需求,可以使用@PropertySource注解来实现。@PropertySource注解用于指定自定义配置文件的具体位置和名称
当然,如果需要将自定义配置文件中的属性值注入到对应类的属性中,可以使用@ConfigurationProperties或者@Value注解进行属性值注入
@Component // 自定义配置类 @PropertySource("classpath:test.properties") // 指定自定义配置文件位置和名称 @ConfigurationProperties(prefix = "test") // 指定配置文件注入属性前缀 public class MyProperties { private int id; private String name; // 省略属性getXX()和setXX()方法 // 省略toString()方法 }
使用@Configuration编写自定义配置类
在Spring Boot框架中,推荐使用配置类的方式向容器中添加和配置组件
在Spring Boot框架中,通常使用@Configuration注解定义一个配置类,Spring Boot会自动扫描和识别配置类,从而替换传统Spring框架中的XML配置文件。
当定义一个配置类后,还需要在类中的方法上使用@Bean注解进行组件配置,将方法的返回对象注入到Spring容器中,并且组件名称默认使用的是方法名,当然也可以使用@Bean注解的name或value属性自定义组件的名称
SpringBoot原理深入及源码剖析
依赖管理
问题:(1)为什么导入dependency时不需要指定版本?
在Spring Boot入门程序中,项目pom.xml文件有两个核心依赖,分别是spring-boot-starterparent和spring-boot-starter-web,关于这两个依赖的相关介绍具体如下:
1.spring-boot-starter-parent依赖
在chapter01项目中的pom.xml文件中找到spring-boot-starter-parent依赖,示例代码如下:

上述代码中,将spring-boot-starter-parent依赖作为Spring Boot项目的统一父项目依赖管理,并将项目版本号统一为2.2.2.RELEASE,该版本号根据实际开发需求是可以修改的
使用“Ctrl+鼠标左键”进入并查看spring-boot-starter-parent底层源文件,发现spring-bootstarter-parent的底层有一个父依赖spring-boot-dependencies,核心代码具体如下
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>2.2.2.RELEASE</version>
<relativePath>../../spring-boot-dependencies</relativePath>
</parent>
继续查看spring-boot-dependencies底层源文件,核心代码具体如下:
<properties> <activemq.version>5.15.11</activemq.version> ... <solr.version>8.2.0</solr.version> <mysql.version>8.0.18</mysql.version> <kafka.version>2.3.1</kafka.version> <spring-amqp.version>2.2.2.RELEASE</spring-amqp.version> <spring-restdocs.version>2.0.4.RELEASE</spring-restdocs.version> <spring-retry.version>1.2.4.RELEASE</spring-retry.version> <spring-security.version>5.2.1.RELEASE</spring-security.version> <spring-session-bom.version>Corn-RELEASE</spring-session-bom.version> <spring-ws.version>3.0.8.RELEASE</spring-ws.version> <sqlite-jdbc.version>3.28.0</sqlite-jdbc.version> <sun-mail.version>${jakarta-mail.version}</sun-mail.version> <tomcat.version>9.0.29</tomcat.version> <thymeleaf.version>3.0.11.RELEASE</thymeleaf.version> <thymeleaf-extras-data-attribute.version>2.0.1</thymeleaf-extras-dataattribute.version> ... </properties>
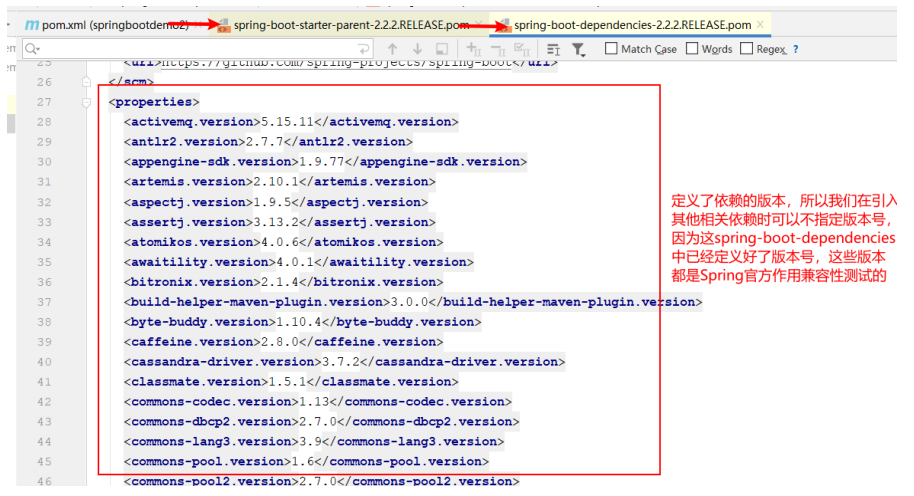
从spring-boot-dependencies底层源文件可以看出,该文件通过标签对一些常用技术框架的依赖文件进行了统一版本号管理,例如activemq、spring、tomcat等,都有与Spring Boot 2.2.2版本相匹配的版本,这也是pom.xml引入依赖文件不需要标注依赖文件版本号的原因。
需要说明的是,如果pom.xml引入的依赖文件不是 spring-boot-starter-parent管理的,那么在pom.xml引入依赖文件时,需要使用标签指定依赖文件的版本号。
(2)问题2: spring-boot-starter-parent父依赖启动器的主要作用是进行版本统一管理,那么项目运行依赖的JAR包是从何而来的?
2. spring-boot-starter-web依赖
spring-boot-starter-web依赖
查看spring-boot-starter-web依赖文件源码,核心代码具体如下
<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> <version>2.2.2.RELEASE</version> <scope>compile</scope> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-json</artifactId> <version>2.2.2.RELEASE</version> <scope>compile</scope> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-tomcat</artifactId> <version>2.2.2.RELEASE</version> <scope>compile</scope> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-validation</artifactId> <version>2.2.2.RELEASE</version> <scope>compile</scope> <exclusions> <exclusion> <artifactId>tomcat-embed-el</artifactId> <groupId>org.apache.tomcat.embed</groupId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-web</artifactId> <version>5.2.2.RELEASE</version> <scope>compile</scope> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-webmvc</artifactId> <version>5.2.2.RELEASE</version> <scope>compile</scope> </dependency> </dependencies>
从上述代码可以发现,spring-boot-starter-web依赖启动器的主要作用是提供Web开发场景所需的底层所有依赖
正是如此,在pom.xml中引入spring-boot-starter-web依赖启动器时,就可以实现Web场景开发,而不需要额外导入Tomcat服务器以及其他Web依赖文件等。当然,这些引入的依赖文件的版本号还是由spring-boot-starter-parent父依赖进行的统一管理。
有哪些starter:
https://github.com/spring-projects/spring-boot/tree/v2.1.0.RELEASE/spring-boot-project/spring-boot-starters
https://mvnrepository.com/search?q=starter
自动配置
概念:能够在我们添加jar包依赖的时候,自动为我们配置一些组件的相关配置,我们无需配置或者只需要少量配置就能运行编写的项目
问题:Spring Boot到底是如何进行自动配置的,都把哪些组件进行了自动配置?
Spring Boot应用的启动入口是@SpringBootApplication注解标注类中的main()方法,
@SpringBootApplication : SpringBoot 应用标注在某个类上说明这个类是 SpringBoot 的主配置类, SpringBoot 就应该运行这个类的 main() 方法启动 SpringBoot 应用。
下面,查看@SpringBootApplication内部源码进行分析 ,核心代码具体如下
@SpringBootApplication
public class SpringbootDemoApplication {
public static void main(String[] args) {
SpringApplication.run(SpringbootDemoApplication.class, args);
}
}
@Target({ElementType.TYPE}) //注解的适用范围,Type表示注解可以描述在类、接口、注解或枚举中
@Retention(RetentionPolicy.RUNTIME) //表示注解的生命周期,Runtime运行时
@Documented //表示注解可以记录在javadoc中
@Inherited //表示可以被子类继承该注解
@SpringBootConfiguration // 标明该类为配置类
@EnableAutoConfiguration // 启动自动配置功能
@ComponentScan(excludeFilters = { @Filter(type = FilterType.CUSTOM, classes =
TypeExcludeFilter.class),
@Filter(type = FilterType.CUSTOM, classes =
AutoConfigurationExcludeFilter.class) })
public @interface SpringBootApplication {
// 根据class来排除特定的类,使其不能加入spring容器,传入参数value类型是class类型。
@AliasFor(annotation = EnableAutoConfiguration.class)
Class<?>[] exclude() default {};
// 根据classname 来排除特定的类,使其不能加入spring容器,传入参数value类型是class的全类名字符串数组。
@AliasFor(annotation = EnableAutoConfiguration.class)
String[] excludeName() default {};
// 指定扫描包,参数是包名的字符串数组。
@AliasFor(annotation = ComponentScan.class, attribute = "basePackages")
String[] scanBasePackages() default {};
// 扫描特定的包,参数类似是Class类型数组。
@AliasFor(annotation = ComponentScan.class, attribute =
"basePackageClasses")
Class<?>[] scanBasePackageClasses() default {};
}
从上述源码可以看出,@SpringBootApplication注解是一个组合注解,前面 4 个是注解的元数据信息, 我们主要看后面 3 个注解:@SpringBootConfiguration、@EnableAutoConfiguration、@ComponentScan三个核心注解,关于这三个核心注解的相关说明具体如下:
1.@SpringBootConfiguration注解
@SpringBootConfiguration : SpringBoot 的配置类,标注在某个类上,表示这是一个 SpringBoot的配置类。
查看@SpringBootConfiguration注解源码,核心代码具体如下。
@Target({ElementType.TYPE}) @Retention(RetentionPolicy.RUNTIME) @Documented @Configuration // 配置类的作用等同于配置文件,配置类也是容器中的一个对象 public @interface SpringBootConfiguration { }
从上述源码可以看出,@SpringBootConfiguration注解内部有一个核心注解@Configuration,该注解是Spring框架提供的,表示当前类为一个配置类(XML配置文件的注解表现形式),并可以被组件扫描器扫描。由此可见,@SpringBootConfiguration注解的作用与@Configuration注解相同,都是标识一个可以被组件扫描器扫描的配置类,只不过@SpringBootConfiguration是被Spring Boot进行了重新封装命名而已
@EnableAutoConfiguration注解
@EnableAutoConfiguration :开启自动配置功能,以前由我们需要配置的东西,现在由 SpringBoot帮我们自动配置,这个注解就是 Springboot 能实现自动配置的关键。
同样,查看该注解内部查看源码信息,核心代码具体如下
// 自动配置包 @AutoConfigurationPackage // Spring的底层注解@Import,给容器中导入一个组件; // 导入的组件是AutoConfigurationPackages.Registrar.class @Import(AutoConfigurationImportSelector.class) // 告诉SpringBoot开启自动配置功能,这样自动配置才能生效。 public @interface EnableAutoConfiguration { String ENABLED_OVERRIDE_PROPERTY = "spring.boot.enableautoconfiguration"; // 返回不会被导入到 Spring 容器中的类 Class<?>[] exclude() default {}; // 返回不会被导入到 Spring 容器中的类名 String[] excludeName() default {}; }
可以发现它是一个组合注解, Spring 中有很多以 Enable 开头的注解,其作用就是借助 @Import来收集并注册特定场景相关的 Bean ,并加载到 IOC 容器。@EnableAutoConfiguration就是借助@Import来收集所有符合自动配置条件的bean定义,并加载到IoC容器。
下面,对这两个核心注解分别讲解 :
(1)@AutoConfigurationPackage注解
查看@AutoConfigurationPackage注解内部源码信息,核心代码具体如下:
@Target({ElementType.TYPE}) @Retention(RetentionPolicy.RUNTIME) @Documented @Inherited @Import({Registrar.class}) // 导入Registrar中注册的组件 public @interface AutoConfigurationPackage { }
从上述源码可以看出,@AutoConfigurationPackage注解的功能是由@Import注解实现的,它是spring框架的底层注解,它的作用就是给容器中导入某个组件类,例如@Import(AutoConfigurationPackages.Registrar.class),它就是将Registrar这个组件类导入到容器中,可查看Registrar类中registerBeanDefinitions方法,这个方法就是导入组件类的具体实现 :
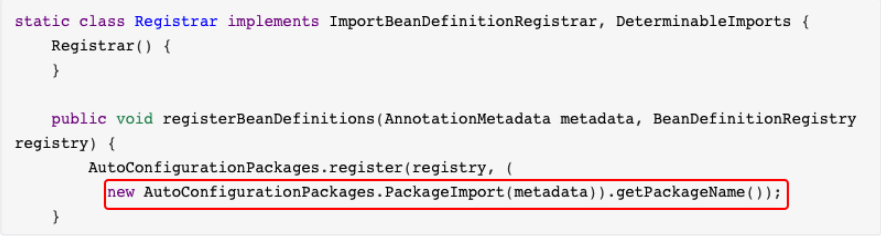
从上述源码可以看出,在Registrar类中有一个registerBeanDefinitions()方法,使用Debug模式启动项目,可以看到选中的部分就是com.lagou。也就是说,@AutoConfigurationPackage注解的主要作用就是将主程序类所在包及所有子包下的组件到扫描到spring容器中。
因此 在定义项目包结构时,要求定义的包结构非常规范,项目主程序启动类要定义在最外层的根目录位置,然后在根目录位置内部建立子包和类进行业务开发,这样才能够保证定义的类能够被组件扫描器扫描
(2)@Import({AutoConfigurationImportSelector.class})注解
将 AutoConfigurationImportSelector 这个类导入到 Spring 容器中,AutoConfigurationImportSelector 可以帮助 Springboot 应用将所有符合条件的 @Configuration配置都加载到当前 SpringBoot 创建并使用的 IOC 容器( ApplicationContext )中。
继续研究AutoConfigurationImportSelector这个类,通过源码分析这个类中是通过selectImports这个方法告诉springboot都需要导入那些组件:

深入研究loadMetadata方法

AutoConfigurationImportSelector类 getAutoConfigurationEntry方法
protected AutoConfigurationEntry getAutoConfigurationEntry(AutoConfigurationMetadata autoConfigurationMetadata, AnnotationMetadata annotationMetadata) { //判断EnabledAutoConfiguration注解有没有开启,默认开启 if (!isEnabled(annotationMetadata)) { return EMPTY_ENTRY; } //获得注解的属性信息 AnnotationAttributes attributes = getAttributes(annotationMetadata); //获取默认支持的自动配置类列表 List<String> configurations = getCandidateConfigurations(annotationMetadata, attributes); //去重 configurations = removeDuplicates(configurations); //去除一些多余的配置类,根据EnabledAutoConfiguratio的exclusions属性进行排除 Set<String> exclusions = getExclusions(annotationMetadata, attributes); checkExcludedClasses(configurations, exclusions); configurations.removeAll(exclusions); //根据pom文件中加入的依赖文件筛选中最终符合当前项目运行环境对应的自动配置类 configurations = filter(configurations, autoConfigurationMetadata); //触发自动配置导入监听事件 fireAutoConfigurationImportEvents(configurations, exclusions); return new AutoConfigurationEntry(configurations, exclusions); }
深入getCandidateConfigurations方法
这个方法中有一个重要方法loadFactoryNames,这个方法是让SpringFactoryLoader去加载一些组件的名字。

继续点开loadFactory方法
public static List<String> loadFactoryNames(Class<?> factoryClass, @Nullable ClassLoader classLoader) { //获取出入的键 String factoryClassName = factoryClass.getName(); return (List)loadSpringFactories(classLoader).getOrDefault(factoryClassName,Collections.emptyList()); } private static Map<String, List<String>> loadSpringFactories(@Nullable ClassLoader classLoader) { MultiValueMap<String, String> result =(MultiValueMap)cache.get(classLoader); if (result != null) { return result; } else { try { //如果类加载器不为null,则加载类路径下spring.factories文件,将其中设置的 配置类的全路径信息封装 为Enumeration类对象 Enumeration<URL> urls = classLoader != null ? classLoader.getResources("META-INF/spring.factories") : ClassLoader.getSystemResources("META-INF/spring.factories"); LinkedMultiValueMap result = new LinkedMultiValueMap(); //循环Enumeration类对象,根据相应的节点信息生成Properties对象,通过传入的 键获取值,在将值切割为一个个小的字符串转化为Array,方法result集合中 while(urls.hasMoreElements()) { URL url = (URL)urls.nextElement(); UrlResource resource = new UrlResource(url); Properties properties = PropertiesLoaderUtils.loadProperties(resource); Iterator var6 = properties.entrySet().iterator(); while(var6.hasNext()) { Entry<?, ?> entry = (Entry)var6.next(); String factoryClassName = ((String)entry.getKey()).trim(); String[] var9 = StringUtils.commaDelimitedListToStringArray((String)entry.getValue()); int var10 = var9.length; for(int var11 = 0; var11 < var10; ++var11) { String factoryName = var9[var11]; result.add(factoryClassName, factoryName.trim()); } } } cache.put(classLoader, result); return result; } catch(Exception e){ e.printStackChace(); } } }
会去读取一个 spring.factories 的文件,读取不到会表这个错误,我们继续根据会看到,最终路径的长这样,而这个是spring提供的一个工具类
public final class SpringFactoriesLoader { public static final String FACTORIES_RESOURCE_LOCATION = "METAINF/spring.factories"; }
它其实是去加载一个外部的文件,而这文件是在
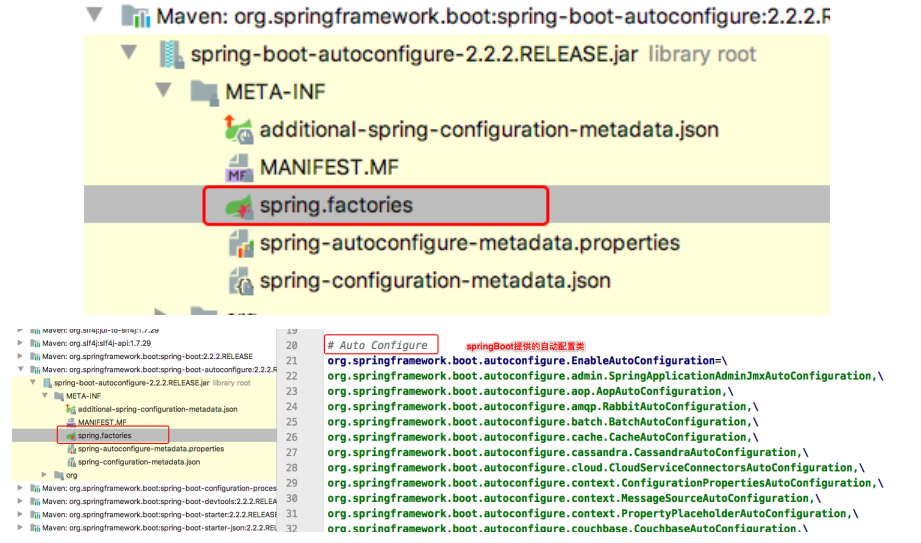
@EnableAutoConfiguration就是从classpath中搜寻META-INF/spring.factories配置文件,并将其中org.springframework.boot.autoconfigure.EnableutoConfiguration对应的配置项通过反射(Java Refletion)实例化为对应的标注了@Configuration的JavaConfig形式的配置类,并加载到IOC容器中
以刚刚的项目为例,在项目中加入了Web环境依赖启动器,对应的WebMvcAutoConfiguration自动配置类就会生效,打开该自动配置类会发现,在该配置类中通过全注解配置类的方式对Spring MVC运行所需环境进行了默认配置,包括默认前缀、默认后缀、视图解析器、MVC校验器等。而这些自动配置类的本质是传统Spring MVC框架中对应的XML配置文件,只不过在Spring Boot中以自动配置类的形式进行了预先配置。因此,在Spring Boot项目中加入相关依赖启动器后,基本上不需要任何配置就可以运行程序,当然,我们也可以对这些自动配置类中默认的配置进行更改
总结
因此springboot底层实现自动配置的步骤是:
1. springboot应用启动;
2. @SpringBootApplication起作用;
3. @EnableAutoConfiguration;
4. @AutoConfigurationPackage:这个组合注解主要是
@Import(AutoConfigurationPackages.Registrar.class),它通过将Registrar类导入到容器中,而Registrar类作用是扫描主配置类同级目录以及子包,并将相应的组件导入到springboot创建管理的容器中;
5. @Import(AutoConfigurationImportSelector.class):它通过将AutoConfigurationImportSelector类导入到容器中,AutoConfigurationImportSelector类作用是通过selectImports方法执行的过程中,会使用内部工具类SpringFactoriesLoader,查找classpath上所有jar包中的METAINF/spring.factories进行加载,实现将配置类信息交给SpringFactory加载器进行一系列的容器创建过程
@ComponentScan注解
@ComponentScan注解具体扫描的包的根路径由Spring Boot项目主程序启动类所在包位置决定,在扫描过程中由前面介绍的@AutoConfigurationPackage注解进行解析,从而得到Spring Boot项目主程序启动类所在包的具体位置
总结:
@SpringBootApplication 的注解的功能就分析差不多了, 简单来说就是 3 个注解的组合注解:
|- @SpringBootConfiguration |- @Configuration //通过javaConfig的方式来添加组件到IOC容器中 |- @EnableAutoConfiguration |- @AutoConfigurationPackage //自动配置包,与@ComponentScan扫描到的添加到IOC |- @Import(AutoConfigurationImportSelector.class) //到METAINF/spring.factories中定义的bean添加到IOC容器中 |- @ComponentScan //包扫描
SpringBoot数据访问
MyBatis 是一款优秀的持久层框架,Spring Boot官方虽然没有对MyBatis进行整合,但是MyBatis团队自行适配了对应的启动器,进一步简化了使用MyBatis进行数据的操作
因为Spring Boot框架开发的便利性,所以实现Spring Boot与数据访问层框架(例如MyBatis)的整合非常简单,主要是引入对应的依赖启动器,并进行数据库相关参数设置即可
Spring Boot整合MyBatis
(1)数据准备,数据库准备相关业务数据
(2)创建项目,引入相应的启动器
<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!--引入Spring Boot Mybatis的启动器--> <dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <version>2.1.3</version> </dependency> <!--Mysql驱动包--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <scope>runtime</scope> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> <exclusions> <exclusion> <groupId>org.junit.vintage</groupId> <artifactId>junit-vintage-engine</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <scope>test</scope> </dependency> <!-- redis依赖包 --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency> </dependencies>
(3)编写与数据库表对应的实体类
(4)编写配置文件
在application.properties配置文件中进行数据库连接配置
# MySQL数据库连接配置 spring: datasource: url: jdbc:mysql://localhost:3306/springbootdata?serverTimezone=UTC&characterEncoding=UTF-8 username: root password: 123456
注解方式整合Mybatis
(1)创建一个对t_comment表数据操作的接口CommentMapper
public interface CommentMapper { @Select("SELECT * FROM t_comment WHERE id =#{id}") public Comment findById(Integer id); }
(2)在Spring Boot项目启动类上添加@MapperScan("xxx")注解
@SpringBootApplication @MapperScan("com.lagou.mapper") public class Springboot02MybatisApplication { public static void main(String[] args) { SpringApplication.run(Springboot02MybatisApplication.class, args); } }
(3)编写测试方法
@RunWith(SpringRunner.class) @SpringBootTest class SpringbootPersistenceApplicationTests { @Autowired private CommentMapper commentMapper; @Test void contextLoads() { Comment comment = commentMapper.findById(1); System.out.println(comment); } }
打印结果:

控制台中查询的Comment的aId属性值为null,没有映射成功。这是因为编写的实体类Comment中使用了驼峰命名方式将t_comment表中的a_id字段设计成了aId属性,所以无法正确映射查询结果。
为了解决上述由于驼峰命名方式造成的表字段值无法正确映射到类属性的情况,可以在Spring Boot全局配置文件application.properties中添加开启驼峰命名匹配映射配置,示例代码如下
mybatis: configuration: map-underscore-to-camel-case: true #开启驼峰命名匹配映射
配置文件的方式整合MyBatis
第一、二步骤使用Free Mybatis plugin插件生成
(1)创建一个用于对数据库表t_article数据操作的接口ArticleMapper
@Mapper public interface ArticleMapper { public Article selectArticle(Integer id); }
(2)创建XML映射文件
resources目录下创建一个统一管理映射文件的包mapper,并在该包下编写与ArticleMapper接口方应的映射文件ArticleMapper.xml
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.lagou.mapper.ArticleMapper"> <select id="selectArticle" resultType="Article"> select * from Article </select> </mapper>
在项目中编写的XML映射文件,Spring Boot并无从知晓,所以无法扫描到该自定义编写的XML配置文件,还必须在全局配置文件application.properties中添加MyBatis映射文件路径的配置,同时需要添加实体类别名映射路径,示例代码如下
mybatis:
#配置MyBatis的xml配置文件路径
mapper-locations: classpath:mapper/*.xml
#配置XML映射文件中指定的实体类别名路径
type-aliases-package: com.lagou.base.pojo
(4)编写单元测试进行接口方法测试
@Autowired private ArticleMapper articleMapper; @Test void contextLoads2() { Article article = articleMapper.selectByPrimaryKey(1); System.out.println(article); }
打印结果:

Spring Boot整合Redis
<!-- redis依赖包 --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency>
#redis配置
#Redis服务器地址
spring.redis.host=127.0.0.1
#Redis服务器连接端口
spring.redis.port=6379
#Redis数据库索引(默认为0)
spring.redis.database=0
#连接池最大连接数(使用负值表示没有限制)
spring.redis.jedis.pool.max-active=50
#连接池最大阻塞等待时间(使用负值表示没有限制)
spring.redis.jedis.pool.max-wait=3000
#连接池中的最大空闲连接
spring.redis.jedis.pool.max-idle=20
#连接池中的最小空闲连接
spring.redis.jedis.pool.min-idle=2
#连接超时时间(毫秒)
spring.redis.timeout=5000
package com.lagou.bootmybatis.util; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.data.redis.core.RedisTemplate; import org.springframework.stereotype.Component; import java.util.concurrent.TimeUnit; @Component public class RedisUtils { @Autowired private RedisTemplate redisTemplate; /** * 读取缓存 * * @param key * @return */ public Object get(final String key) { return redisTemplate.opsForValue().get(key); } /** * 写入缓存 */ public boolean set( String key, Object value) { boolean result = false; try { redisTemplate.opsForValue().set(key, value,1, TimeUnit.DAYS); result = true; } catch (Exception e) { e.printStackTrace(); } return result; } /** * 更新缓存 */ public boolean getAndSet(final String key, String value) { boolean result = false; try { redisTemplate.opsForValue().getAndSet(key, value); result = true; } catch (Exception e) { e.printStackTrace(); } return result; } /** * 删除缓存 */ public boolean delete(final String key) { boolean result = false; try { redisTemplate.delete(key); result = true; } catch (Exception e) { e.printStackTrace(); } return result; } }
@RunWith(SpringRunner.class) @SpringBootTest class BootmybatisApplicationTests { //写入,key:1,value:mysql数据库中id为1的article记录 @Autowired private RedisUtils redisUtils; @Test void writeRedis(){ redisUtils.set("1",articleMapper.selectByPrimaryKey(1)); System.out.println("success"); } @Test void readRedis(){ Article article = (Article) redisUtils.get("1"); System.out.println(article); } }
SpringBoot视图技术
支持的视图技术
前端模板引擎技术的出现,使前端开发人员无需关注后端业务的具体实现,只关注自己页面的呈现效果即可,并且解决了前端代码错综复杂的问题、实现了前后端分离开发。Spring Boot框架对很多常用的模板引擎技术(如:FreeMarker、Thymeleaf、Mustache等)提供了整合支持
- Spring Boot不太支持常用的JSP模板,并且没有提供对应的整合配置,这是因为使用嵌入式Servlet容器的Spring Boot应用程序对于JSP模板存在一些限制 :
- 在Jetty和Tomcat容器中,Spring Boot应用被打包成war文件可以支持JSP。但Spring Boot默认使用嵌入式Servlet容器以JAR包方式进行项目打包部署,这种JAR包方式不支持JSP。
- 如果使用Undertow嵌入式容器部署Spring Boot项目,也不支持JSP模板。(Undertow 是红帽公司开发的一款基于 NIO 的高性能 Web 嵌入式服务器)
- Spring Boot默认提供了一个处理请求路径“/error”的统一错误处理器,返回具体的异常信息。使用JSP模板时,无法对默认的错误处理器进行覆盖,只能根据Spring Boot要求在指定位置定制错误页面。
- 上面对Spring Boot支持的模板引擎进行了介绍,并指出了整合JSP模板的一些限制。接下来,对其中常用的Thymeleaf模板引擎进行介绍,并完成与Spring Boot框架的整合实现
Thymeleaf
Thymeleaf是一种现代的基于服务器端的Java模板引擎技术,也是一个优秀的面向Java的XML、XHTML、HTML5页面模板,它具有丰富的标签语言、函数和表达式,在使用Spring Boot框架进行页面设计时,一般会选择Thymeleaf模板
Thymeleaf语法
在HTML页面上使用Thymeleaf标签,Thymeleaf 标签能够动态地替换掉静态内容,使页面动态展示。

上述代码中,“xmlns:th="http://www.thymeleaf.org"“ 用于引入Thymeleaf模板引擎标签,使用关键字“th”标注标签是Thymeleaf模板提供的标签,其中,“th:href”用于引入外联样式文件,“th:text”用于动态显示标签文本内容。
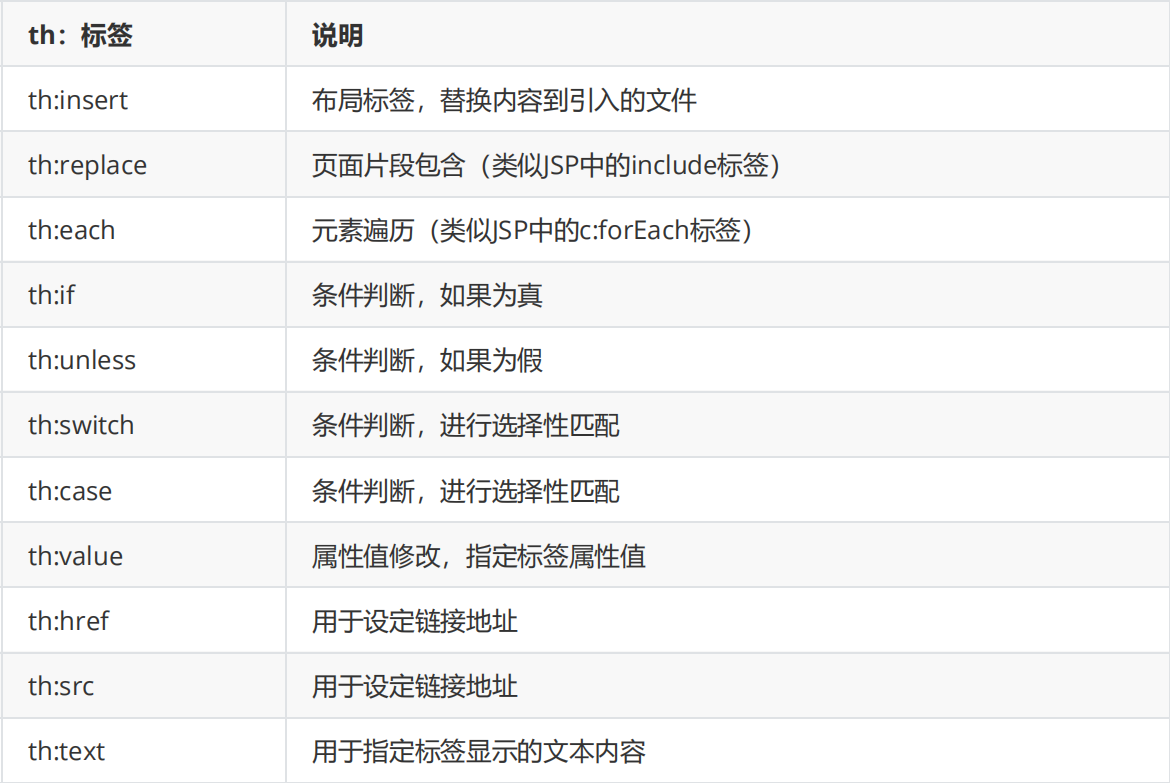
标准表达式
Thymeleaf模板引擎提供了多种标准表达式语法,在正式学习之前,先通过一张表来展示其主要语法及说明
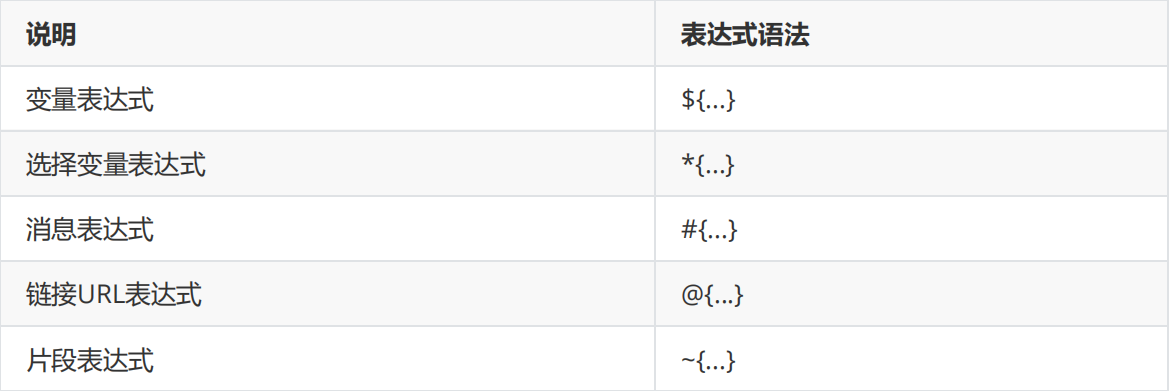
1.变量表达式 ${...}
<p th:text="${title}">这是标题</p>
# ctx:上下文对象
# vars:上下文变量
# locale:上下文区域设置
# request:(仅限Web Context)HttpServletRequest对象
# response:(仅限Web Context)HttpServletResponse对象
# session:(仅限Web Context)HttpSession对象
# servletContext:(仅限Web Context)ServletContext对象
The locale country is: <span th:text="${#locale.country}">US</sp
上述代码中,使用th:text="${#locale.country}"动态获取当前用户所在国家信息,其中标签内默认内容为US(美国),程序启动后通过浏览器查看当前页面时,Thymeleaf会通过浏览器语言设置来识别当前用户所在国家信息,从而实现动态替换
<div th:object="${book}"> <p>titile: <span th:text="*{title}">标题</span>.</p> </div>
<a th:href="@{http://localhost:8080/order/details(orderId=${o.id})}">view</a> <a th:href="@{/order/details(orderId=${o.id},pid=${p.id})}">view</a>
上述代码中,链接表达式@{...}分别编写了绝对链接地址和相对链接地址。在有参表达式中,需要按照@{路径(参数名称=参数值,参数名称=参数值...)}的形式编写,同时该参数的值可以使用变量表达式来传递动态参数值
<div th:insert="~{thymeleafDemo::title}"></div>
上述代码中,使用th:insert属性将title片段模板引用到该标签中。thymeleafDemo为模板名称,Thymeleaf会自动查找“/resources/templates/”目录下的thymeleafDemo模板,title为片段名称
基本使用
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-thymeleaf</artifactId> </dependency>
其次,在全局配置文件中配置Thymeleaf模板的一些参数。一般Web项目都会使用下列配置,示例代码如:
spring.thymeleaf.cache = true #启用模板缓存
spring.thymeleaf.encoding = UTF_8 #模板编码
spring.thymeleaf.mode = HTML5 #应用于模板的模板模式
spring.thymeleaf.prefix = classpath:/templates/ #指定模板页面存放路径
spring.thymeleaf.suffix = .html #指定模板页面名称的后缀
上述配置中,spring.thymeleaf.cache表示是否开启Thymeleaf模板缓存,默认为true,在开发过程中通常会关闭缓存,保证项目调试过程中数据能够及时响应;spring.thymeleaf.prefix指定了Thymeleaf模板页面的存放路径,默认为classpath:/templates/;spring.thymeleaf.suffix指定了Thymeleaf模板页面的名称后缀,默认为.html
完成数据的页面展示
2. 编写配置文件
# thymeleaf页面缓存设置(默认为true),开发中方便调试应设置为false,上线稳定后应保持默认 true
spring.thymeleaf.cache=false
使用“spring.thymeleaf.cache=false”将Thymeleaf默认开启的缓存设置为了false,用来关闭模板页面缓存
@Controller public class LoginController { /** * 获取并封装当前年份跳转到登录页login.html */ @RequestMapping("/toLoginPage") public String toLoginPage(Model model){ model.addAttribute("currentYear", Calendar.getInstance().get(Calendar.YEAR)); return "login"; }
<!DOCTYPE html> <html lang="en" xmlns:th="http://www.thymeleaf.org"> <head> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1,shrink-to-fit=no"> <title>用户登录界面</title> <link th:href="@{/login/css/bootstrap.min.css}" rel="stylesheet"> <link th:href="@{/login/css/signin.css}" rel="stylesheet"> </head> <body class="text-center"> <!-- 用户登录form表单 --> <form class="form-signin"> <img class="mb-4" th:src="@{/login/img/login.jpg}" width="72" height="72"> <h1 class="h3 mb-3 font-weight-normal">请登录</h1> <input type="text" class="form-control" th:placeholder="用户名" required="" autofocus=""> <input type="password" class="form-control" th:placeholder="密码" required=""> <div class="checkbox mb-3"> <label> <input type="checkbox" value="remember-me"> 记住我 </label> </div> <button class="btn btn-lg btn-primary btn-block" type="submit" >登录</button> <p class="mt-5 mb-3 text-muted">© <span th:text="${currentYear}">2019</span>-<span th:text="${currentYear}+1">2020</span></p> </form> </body> </html>
<dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.12</version> <!--只在编译阶段生效--> <scope>provided</scope> </dependency>
Spring Boot项目部署
1. 需要添加打包组件将项目中的资源、配置、依赖包打到一个jar包中;可以使用maven的 package ;
2. 部署:java -jar 包名
<build> <plugins> <!-- 打jar包时如果不配置该插件,打出来的jar包没有清单文件 --> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build>
Spring Cloud 微服务
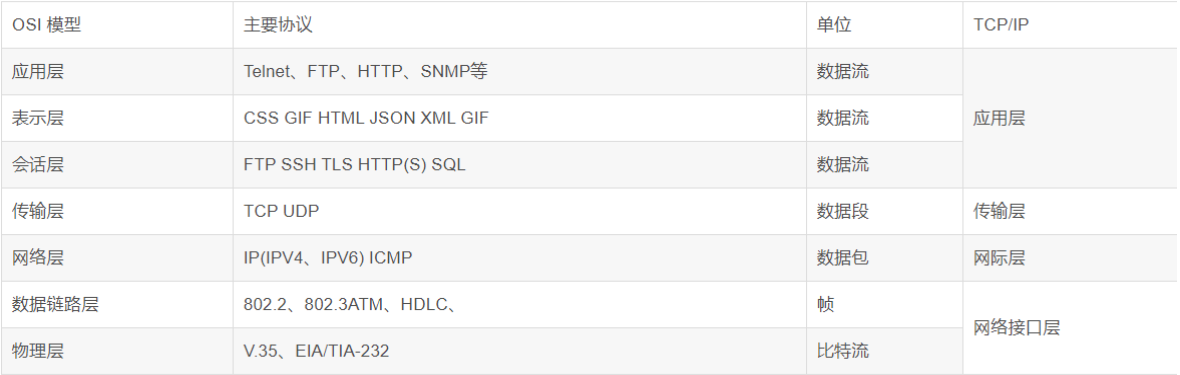
第一部分:微服务架构互联网应用架构演进微服务架构的体现思想及优缺点微服务架构的核心概念第二部分: SpringCloud概述Sping Cloud 是什么Sping Cloud 解决什么问题Sping Cloud 架构第三部分:案例准备第四部分:第一代 Spring Cloud 核⼼组件 (Spring Cloud Netflix)Eureka服务注册中心Ribbon负载均衡Hystrix熔断器Feign远程调用组件GateWay网关组件Config 分布式配置中心第五部分:第⼆代 Spring Cloud 核⼼组件(Spring Cloud Alibaba)Nacos 服务注册和配置中心Sentinel 分布式系统的流量防卫兵
微服务架构
互联网应用架构演进
随着互联网的发展,用户群体逐渐扩大,网站的流量成倍增长,常规的单体架构已无法满足请求压力和业务的快速迭代,架构的变化势在必⾏。下⾯我们就以拉勾网的架构演进为例,从最开始的单体架构分析,一步步的到现在的微服务架构。
1)单体应用架构
在诞⽣之初,拉勾的⽤户量、数据量规模都⽐较⼩,项目所有的功能模块都放在一个工程中编码、编译、打包并且部署在一个Tomcat容器中的架构模式就是单体应用架构,这样的架构既简单实 ⽤、便于维护,成本⼜低,成为了那个时代的主流架构⽅式。
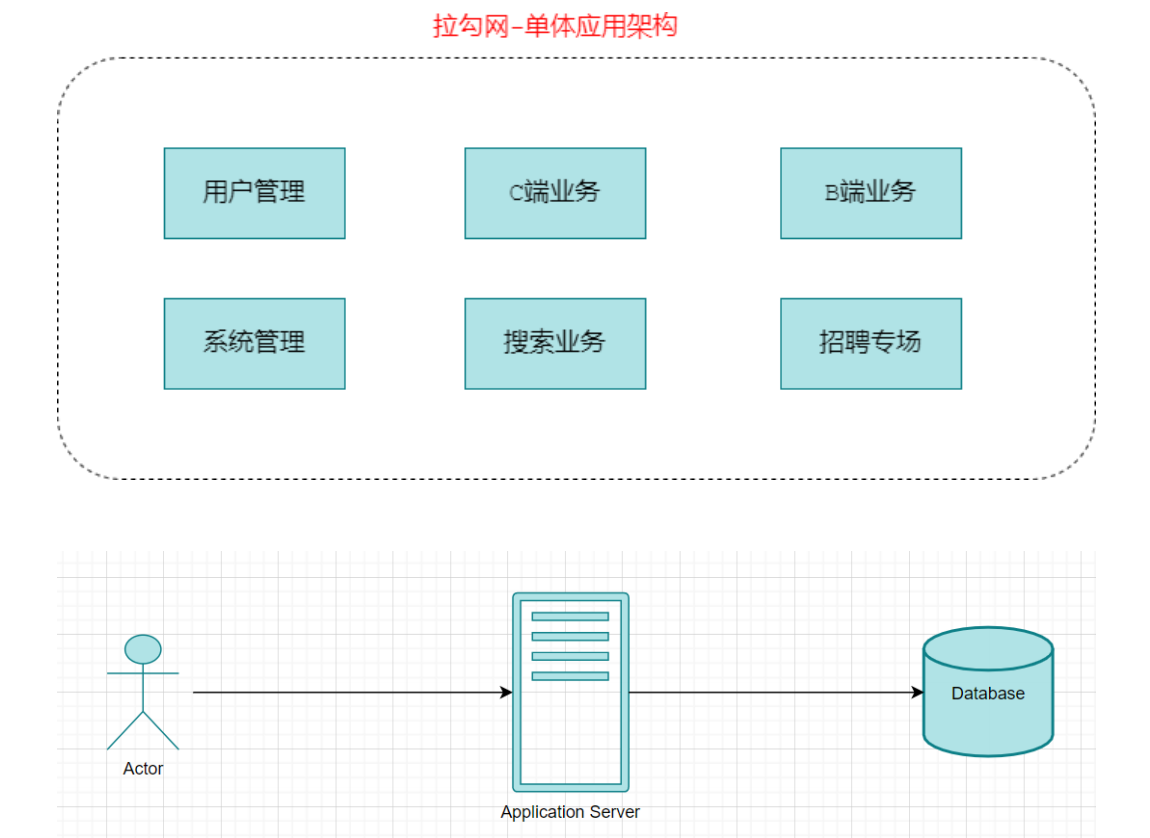
优点:
- 高效开发:项⽬前期开发节奏快,团队成员少的时候能够快速迭代
- 架构简单:MVC架构,只需要借助IDE开发、调试即可
- 易于测试:只需要通过单元测试或者浏览器完成
- 易于部署:打包成单⼀可执⾏的jar或者打成war包放到容器内启动
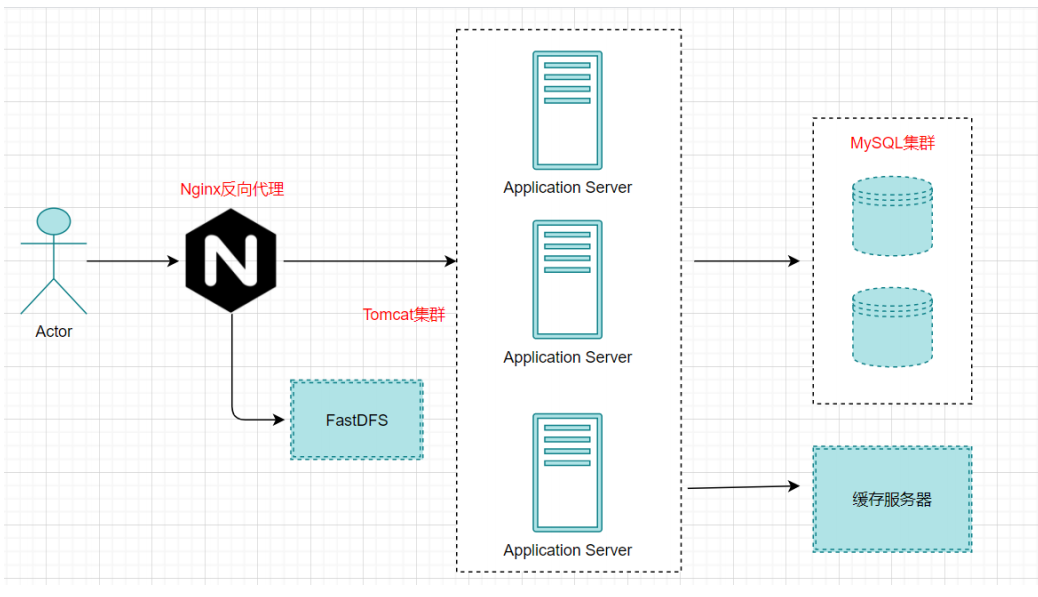
单体架构的应用比较容易部署、测试, 在项目的初期,单体应用可以很好地运行。然而,随着需求的不断增加, 越来越多的人加入开发团队,代码库也在飞速地膨胀。慢慢地,单体应用变得越来越臃肿,可维护性、灵活性逐渐降低,维护成本越来越高。
- 可靠性差: 某个应用Bug,例如死循环、内存溢出等, 可能会导致整个应用的崩溃
- 复杂性高: 以一个百万行级别的单体应用为例,整个项目包含的模块多、模块的边界模糊、 依赖关系不清晰、 代码质量参差不齐、 混乱地堆砌在一起。使得整个项目非常复杂。
- 扩展能力受限: 单体应用只能作为一个整体进行扩展,无法根据业务模块的需要进行伸缩。例如,应用中有的模块是计算密集型的,它需要强劲的CPU; 有的模块则是IO密集型的,需要更大的内存。 由于这些模块部署在一起,不得不在硬件的选择上做出妥协。
2)垂直应用架构
为了避免上⾯提到的那些问题,开始做模块的垂直划分,做垂直划分的原则是基于拉勾现有的业务特性来做,核心目标标第⼀个是为了业务之间互不影响,第⼆个是在研发团队的壮⼤后为了提⾼效率,减少组件之间的依赖。

优点
- 系统拆分实现了流量分担,解决了并发问题
- 可以针对不同模块进⾏优化
- ⽅便⽔平扩展,负载均衡,容错率提⾼
- 系统间相互独⽴,互不影响,新的业务迭代时更加⾼效
- 服务之间相互调⽤,如果某个服务的端⼝或者ip地址发⽣改变,调⽤的系统得⼿动改变
- 搭建集群之后,实现负载均衡⽐较复杂,如:内⽹负载,在迁移机器时会影响调⽤⽅的路 由,导致线上故障
- 服务之间调⽤⽅式不统⼀,基于 httpclient 、 webservice ,接⼝协议不统⼀
- 服务监控不到位:除了依靠端⼝、进程的监控,调⽤的成功率、失败率、总耗时等等这些监 控指标是没有的
3)SOA应用架构
在做了垂直划分以后,模块随之增多,维护的成本在也变⾼,⼀些通⽤的业务和模块重复的越来越多,为了解决上⾯提到的接⼝协议不统⼀、服务⽆法监控、服务的负载均衡,引⼊了阿⾥巴巴开源的Dubbo ,⼀款⾼性能、轻量级的开源Java RPC框架,可以和Spring框架无缝集成。它提供了三⼤核⼼能⼒:⾯向接⼝的远程⽅法调⽤,智能容错和负载均衡,以及服务⾃动注册和发现。
SOA (Service-Oriented Architecture),即面向服务的架构。根据实际业务,把系统拆分成合适的、独立部署的模块,模块之间相互独立(通过Webservice/Dubbo等技术进行通信)。
优点:分布式、松耦合、扩展灵活、可重用。
缺点:服务抽取粒度较大、服务调用方和提供方耦合度较高(接口耦合度)

4)微服务应用架构
微服务架构可以说是SOA架构的一种拓展,这种架构模式下它拆分粒度更小、服务更独立。把应用拆分成为一个个微小的服务,不同的服务可以使用不同的开发语言和存储,服务之间往往通过Restful等轻量级通信。微服务架构关键在于微小、独立、轻量级通信。
微服务是在 SOA 上做的升华粒度更加细致,微服务架构强调的⼀个重点是业务需要彻底的组件化和服务化
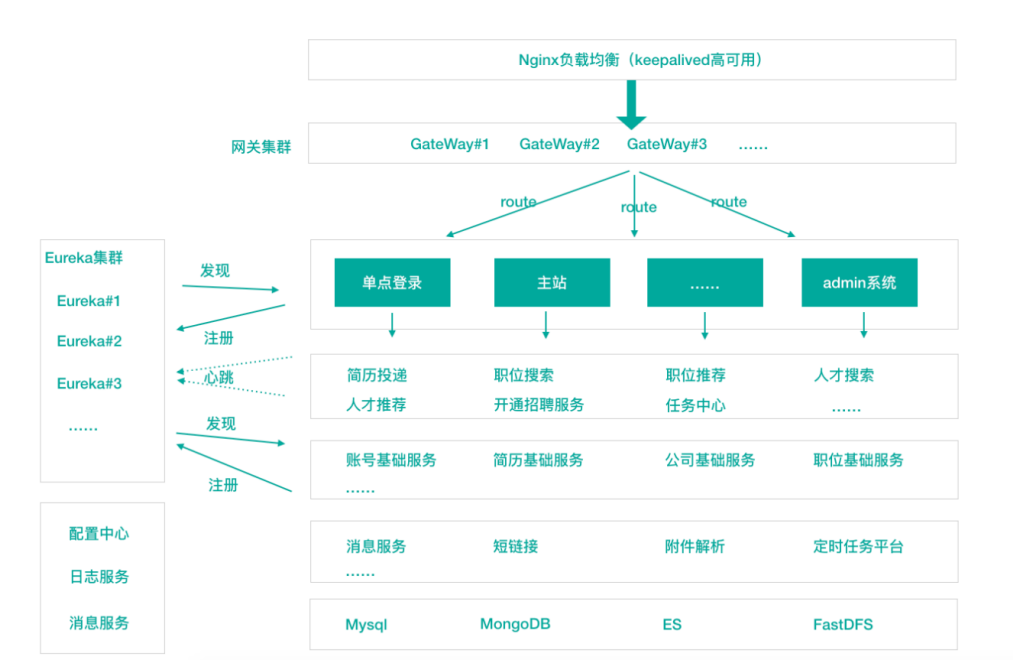
微服务架构和SOA架构很明显的一个区别就是服务拆分粒度的不同,但是对于拉勾的架构发展来说,我们所看到的SOA阶段其实服务拆分粒度相对来说已经比较细了(超前哦!),所以上述拉勾SOA到拉勾微服务,从服务拆分上来说变化并不大,只是引入了相对完整的新一代Spring Cloud微服务技术。自然,上述我们看到的都是拉勾架构演变的阶段结果,每一个阶段其实都经历了很多变化,拉勾的服务拆分其实也是走过了从粗到细,并非绝对的一步到位。
微服务架构体现的思想及优缺点
微服务架构设计的核心思想就是“微”,拆分的粒度相对比较小,这样的话单一职责、开发的耦合度就会降低、微小的功能可以独立部署扩展、灵活性强,升级改造影响范围小。
- 微服务很小,便于特定业务功能的聚焦
- 微服务很小,每个微服务都可以被一个小团队单独实施(开发、测试、部署上线、运维),团队合作一定程度解耦,便于实施敏捷开发
- 微服务很小,便于重用和模块之间的组装
- 微服务很独立,那么不同的微服务可以使用不同的语言开发,松耦合
- 微服务架构下,我们更容易引入新技术
- 微服务架构下,分布式复杂难以管理,当服务数量增加,管理将越加复杂;
- 微服务架构下,分布式链路跟踪难等;
微服务架构中的核心概念
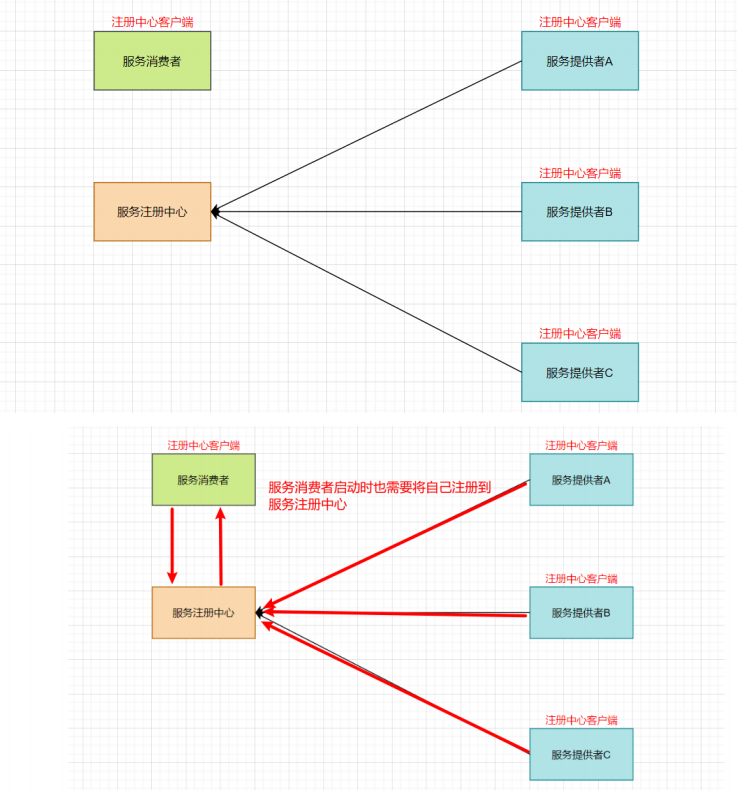
- 服务注册:服务提供者将所提供服务的信息(服务器IP和端口、服务访问协议等)注册/登记到注册中心
- 服务发现:服务消费者能够从注册中心获取到较为实时的服务列表,然后根究一定的策略选择一个服务访问
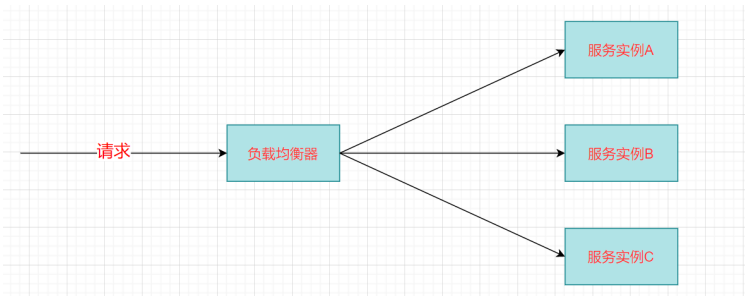
- 负载均衡
负载均衡即将请求压力分配到多个服务器(应用服务器、数据库服务器等),以此来提高服务的性能、可靠性
- 熔断
熔断即断路保护。微服务架构中,如果下游服务因访问压力过大而响应变慢或失败,上游服务为了保护系统整体可用性,可以暂时切断对下游服务的调用。这种牺牲局部,保全整体的措施就叫做熔断。

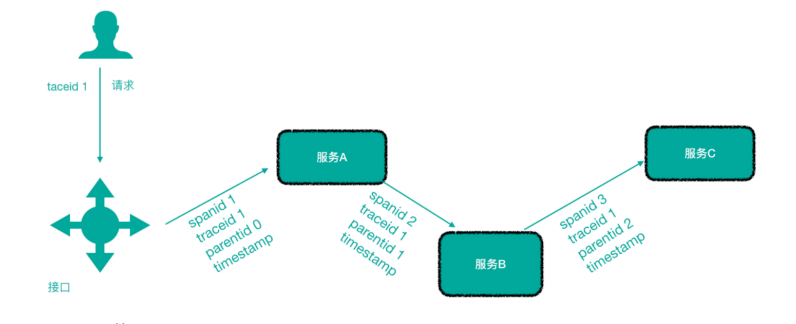
- 链路追踪
微服务架构越发流行,一个项目往往拆分成很多个服务,那么一次请求就需要涉及到很多个服务。不同的微服务可能是由不同的团队开发、可能使用不同的编程语言实现、整个项目也有可能部署在了很多服务器上(甚至百台、千台)横跨多个不同的数据中心。所谓链路追踪,就是对一次请求涉及的很多个服务链路进行日志记录、性能监控
- API 网关
微服务架构下,不同的微服务往往会有不同的访问地址,客户端可能需要调用多个服务的接口才能完成一个业务需求,如果让客户端直接与各个微服务通信可能出现:
1)客户端需要调用不同的url地址,增加了维护调用难度
2)在一定的场景下,也存在跨域请求的问题(前后端分离就会碰到跨域问题,原本我们在后端采用Cors就能解决,现在利用网关,那么就放在网关这层做好了)
3)每个微服务都需要进行单独的身份认证
那么,API网关就可以较好的统一处理上述问题,API请求调用统一接入API网关层,由网关转发请求。API网关更专注在安全、路由、流量等问题的处理上(微服务团队专注于处理业务逻辑即可),它的功能比如
1)统一接入(路由)
2)安全防护(统一鉴权,负责网关访问身份认证验证,与“访问认证中心”通信,实际认证业务逻辑交移“访问认证中心”处理)
3)黑白名单(实现通过IP地址控制禁止访问网关功能,控制访问)
4)协议适配(实现通信协议校验、适配转换的功能)
5)流量管控(限流)
6)长短链接支持
7)容错能力(负载均衡)
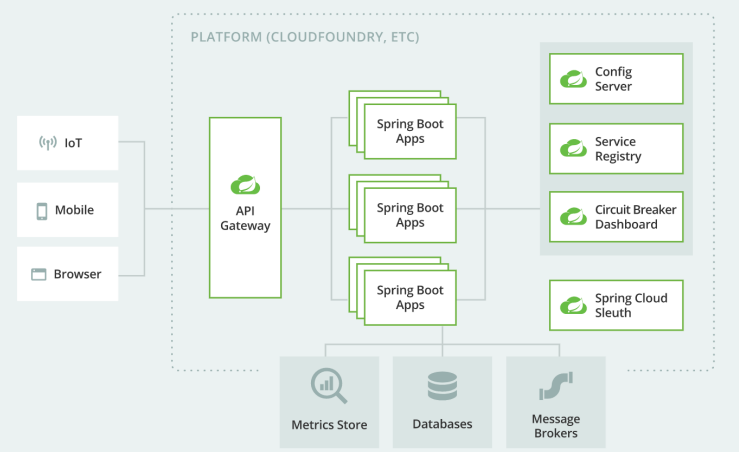
Spring Cloud 综述
Spring Cloud 是什么
Spring Cloud是一系列框架的有序集合。它利用Spring Boot的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、消息总线、负载均衡、断路器、数据监控等,都可以用 Spring Boot的开发风格做到一键启动和部署。Spring Cloud并没有重复制造轮子,它只是将目前各家公司开发的比较成熟、经得起实际考验的服务框架组合起来,通过Spring Boot风格进行再封装屏蔽掉了复杂的配置和实现原理,最终给开发者留出了一套简单易懂、易部署和易维护的分布式系统开发工具包。
Spring Cloud 解决什么问题
Spring Cloud 规范及实现意图要解决的问题其实就是微服务架构实施过程中存在的一些问题,比如微服务架构中的服务注册发现问题、网络问题(比如熔断场景)、统一认证安全授权问题、负载均衡问题、链路追踪等问题。
Distributed/versioned configuration (分布式/版本化配置)
Service registration and discovery (服务注册和发现)
Routing (智能路由)
Service-to-service calls (服务调用)
Load balancing (负载均衡)
Circuit Breakers (熔断器)
Global locks (全局锁)
Leadership election and cluster state ( 选举与集群状态管理)
Distributed messaging (分布式消息传递平台)
Spring Cloud 架构
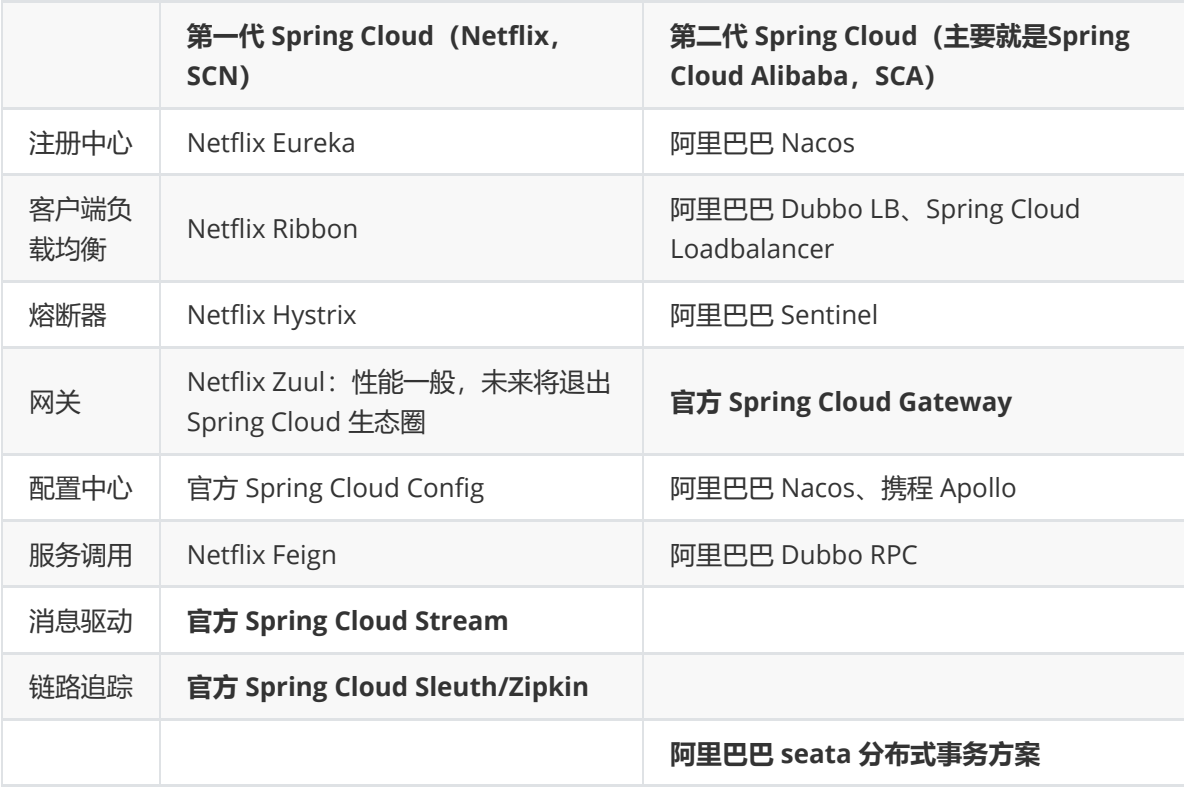
Spring Cloud 核心组件
Spring Cloud 生态圈中的组件,按照发展可以分为第一代 Spring Cloud组件和第二代 Spring Cloud组件。
Spring Cloud 体系结构(组件协同工作机制)
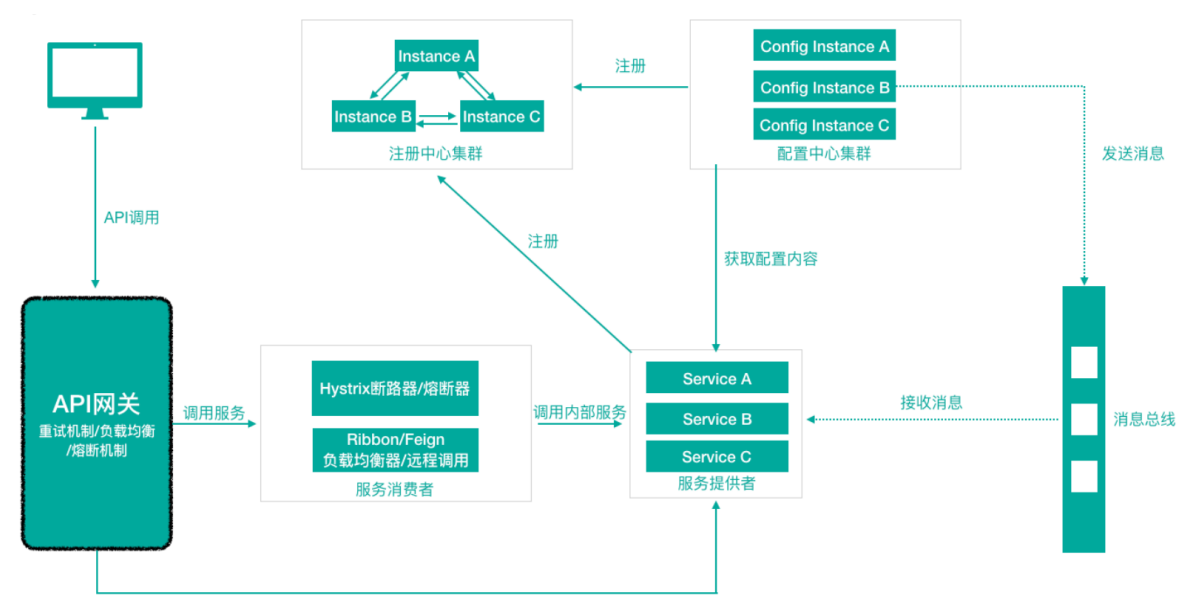
Spring Cloud中的各组件协同工作,才能够支持一个完整的微服务架构。比如
- Spring Cloud中的各组件协同工作,才能够支持一个完整的微服务架构。比如
- 注册中心负责服务的注册与发现,很好将各服务连接起来
- API网关负责转发所有外来的请求
- 断路器负责监控服务之间的调用情况,连续多次失败进行熔断保护。
- 配置中心提供了统一的配置信息管理服务,可以实时的通知各个服务获取最新的配置信息
Spring Cloud 与 Dubbo 对比
Dubbo是阿里巴巴公司开源的一个高性能优秀的服务框架,基于RPC调用,对于目前使用率较高的Spring Cloud Netflix来说,它是基于HTTP的,所以效率上没有Dubbo高,但问题在于Dubbo体系的组件不全,不能够提供一站式解决方案,比如服务注册与发现需要借助于Zookeeper等实现,而Spring Cloud Netflix则是真正的提供了一站式服务化解决方案,且有Spring大家族背景。
前些年,Dubbo使用率高于SpringCloud,但目前Spring Cloud在服务化/微服务解决方案中已经有了非常好的发展趋势。
Spring Cloud 与 Spring Boot 的关系
Spring Cloud 只是利用了Spring Boot 的特点,让我们能够快速的实现微服务组件开发,否则不使用Spring Boot的话,我们在使用Spring Cloud时,每一个组件的相关Jar包都需要我们自己导入配置以及需要开发人员考虑兼容性等各种情况。所以Spring Boot是我们快速把Spring Cloud微服务技术应用起来的一种方式。
案例准备
案例说明
本部分我们按照普通方式模拟一个微服务之间的调用,后续我们将一步步使用Spring Cloud的组件对案例进行改造。


案例数据库环境准备
商品信息表:
CREATE TABLE products( id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(50), #商品名称 price DOUBLE, flag VARCHAR(2), #上架状态 goods_desc VARCHAR(100), #商品描述 images VARCHAR(400), #商品图片 goods_stock INT, #商品库存 goods_type VARCHAR(20) #商品类型 );
案例工程
我们基于SpringBoot来构造工程环境,我们的工程模块关系如下所示:
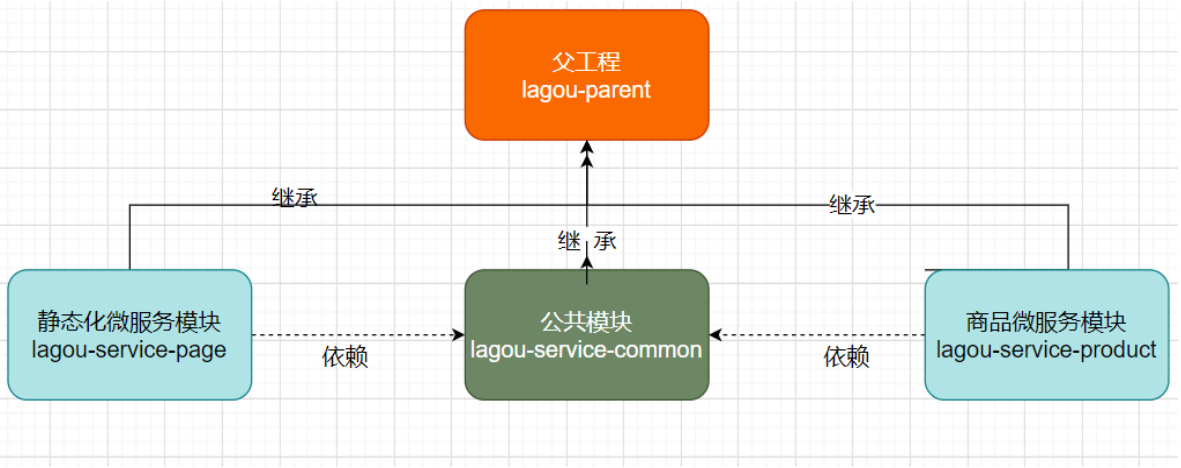
父工程 lagou-parent
在Idea中新建module,命名为lagou-parent
pom.xml
<!--spring boot 父启动器依赖--> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.1.6.RELEASE</version> </parent> <dependencyManagement> <dependencies> <!--SCN--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-dependencies</artifactId> <version>Greenwich.RELEASE</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <dependencies> <!--web依赖--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!--日志依赖--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-logging</artifactId> </dependency> <!--测试依赖--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <!--lombok工具--> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.4</version> <scope>provided</scope> </dependency> <!-- Actuator可以帮助你监控和管理Spring Boot应用--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency> <!--热部署--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-devtools</artifactId> <optional>true</optional> </dependency> <!--引入Jaxb,开始--> <dependency> <groupId>com.sun.xml.bind</groupId> <artifactId>jaxb-core</artifactId> <version>2.2.11</version> </dependency> <dependency> <groupId>javax.xml.bind</groupId> <artifactId>jaxb-api</artifactId> </dependency> <dependency> <groupId>com.sun.xml.bind</groupId> <artifactId>jaxb-impl</artifactId> <version>2.2.11</version> </dependency> <dependency> <groupId>org.glassfish.jaxb</groupId> <artifactId>jaxb-runtime</artifactId> <version>2.2.10-b140310.1920</version> </dependency> <dependency> <groupId>javax.activation</groupId> <artifactId>activation</artifactId> <version>1.1.1</version> </dependency> <!--引入Jaxb,结束--> </dependencies> <build> <plugins> <!--编译插件--> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <configuration> <source>11</source> <target>11</target> <encoding>utf-8</encoding> </configuration> </plugin> <!--打包插件--> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <executions> <execution> <goals> <goal>repackage</goal> </goals> </execution> </executions> </plugin> </plugins> </build>
公共组件微服务
1) 在公共组件微服务中引入数据库驱动及mybatis-plus
<dependencies> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>3.3.2</version> </dependency> <!--pojo持久化使用--> <dependency> <groupId>javax.persistence</groupId> <artifactId>javax.persistence-api</artifactId> <version>2.2</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <scope>runtime</scope> </dependency> </dependencies>
2) 生成数据库实体类:com.lagou.common.pojo.Products
@Data @Table(name = "products") public class Products { @Id private long id; private String name; private double price; private String flag; private String goodsDesc; private String images; private long goodsStock; private String goodsType; }
商品微服务
商品微服务是服务提供者,页面静态化微服务是服务的消费者
创建商品微服务lagou-service-product,继承lagou-parent
1)在商品微服务的pom文件中,引入公共组件坐标
<dependency> <groupId>com.zhf</groupId> <artifactId>lagou-service-common</artifactId> <version>1.0-SNAPSHOT</version> </dependency>
2)在yml文件中配置端口、应用名、数据库连接等信息
server: port: 9200 #微服务的集群环境中,通常会为每一个微服务叠加。 spring: application: name: lagou-service-goods datasource: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:3306/springcloud_lagou?useUnicode=true&characterEncoding=utf8&serverTimezone=UTC username: root password: 123456
3) Mapper接口开发
/** * 现在使用的Mybatis-plus组件,该组件是Mybatis的加强版 * 能够与SpringBoot进行非常友好的整合,对比Mybatis框架只有使用便捷的改变 * 没有具体功能的改变 * 具体使用:让具体的Mapper接口继承BaseMapper即可 */ public interface ProductMapper extends BaseMapper<Products> { }
4) serive层开发
@Service public class ProductServiceImpl implements ProductService { @Autowired private ProductMapper productMapper; @Override public Products queryById(Integer id) { return productMapper.selectById(id); } }
5) controller层开发
@RestController @RequestMapping("/product") public class ProductController { @Autowired private ProductService productService; @GetMapping("/query/{id}") public Products queryById(@PathVariable Integer id){ return productService.queryById(id); } }
6) 启动类
@SpringBootApplication //@EnableEurekaClient //将当前项目作为Eureka Client注册到Eureka Server ,只能在Eureka环境中使用 @EnableDiscoveryClient //也是将当前项目表示为注册中心的客户端,向注册中心进行注册,可以在所有的服务注册中心环境下使用 @MapperScan("com.lagou.product.mapper") public class ProductApplication { public static void main(String[] args) { SpringApplication.run(ProductApplication.class, args); } }
页面静态化微服务
1) 在pom文件中,引入公共组件依赖
<parent> <artifactId>lagou-parent</artifactId> <groupId>com.lagou</groupId> <version>1.0-SNAPSHOT</version> </parent> <modelVersion>4.0.0</modelVersion> <artifactId>lagou-service-product</artifactId> <dependencies> <dependency> <groupId>com.lagou</groupId> <artifactId>lagou-service-common</artifactId> <version>1.0-SNAPSHOT</version> </dependency> </dependencies>
2)在yml文件中配置端口、应用名、数据库连接等信息
server: port: 9100 # 后期该微服务多实例,端口从9100递增(10个以内) Spring: application: name: lagou-service-page datasource: driver-class-name: com.mysql.jdbc.Driver url: jdbc:mysql://localhost:3306/lagou?useUnicode=true&characterEncoding=utf8&serverTimezone=UTC username: root password: wu7787879
3) 编写PageController,在PageController中调用商品微服务对应的URL
package com.lagou.page.controller; import com.lagou.common.pojo.Products; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.http.ResponseEntity; import org.springframework.web.bind.annotation.PathVariable; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; import org.springframework.web.client.RestTemplate; @RestController @RequestMapping("/page") public class PageController { @Autowired private RestTemplate restTemplate; @GetMapping("/getData/{id}") public Products findDataById(@PathVariable Integer id){ Products products = restTemplate.getForObject("http://localhost:9000/product/query/"+id, Products.class); System.out.println("从lagou-service-product获得product对象:"+products); return products; } }
4) 编写启动类,注入RestTemplate
package com.lagou.page; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cloud.client.circuitbreaker.EnableCircuitBreaker; import org.springframework.cloud.client.discovery.EnableDiscoveryClient; import org.springframework.cloud.client.loadbalancer.LoadBalanced; import org.springframework.cloud.openfeign.EnableFeignClients; import org.springframework.context.annotation.Bean; import org.springframework.web.client.RestTemplate; import java.awt.print.Pageable; @SpringBootApplication public class PageApplication { public static void main(String[] args) { SpringApplication.run(PageApplication.class,args); } //像容器中注入一个RestTemplate,封装了HttpClient @Bean public RestTemplate restTemplate(){ return new RestTemplate(); } }
第 4 节 案例代码问题分析
我们在页面静态化微服务中使用RestTemplate调用商品微服务的商品状态接口时(Restful API 接口)。在微服务分布式集群环境下会存在什么问题呢?怎么解决?
存在的问题:
1)在服务消费者中,我们把url地址硬编码到代码中,不方便后期维护。
2)服务提供者只有一个服务,即便服务提供者形成集群,服务消费者还需要自己实现负载均衡。
3)在服务消费者中,不清楚服务提供者的状态。
4)服务消费者调用服务提供者时候,如果出现故障能否及时发现不向用户抛出异常页面?
5)RestTemplate这种请求调用方式是否还有优化空间?能不能类似于Dubbo那样玩?
6)这么多的微服务统一认证如何实现?
7)配置文件每次都修改好多个很麻烦!?
8)....
上述分析出的问题,其实就是微服务架构中必然面临的一些问题:
1)服务管理:自动注册与发现、状态监管
2)服务负载均衡
3)熔断
4)远程过程调用
5)网关拦截、路由转发
6)统一认证
7)集中式配置管理,配置信息实时自动更新
这些问题,Spring Cloud 体系都有解决方案,后续我们会逐个学习。
从形式上来说,Feign一个顶三,Feign = RestTemplate + Ribbon + Hystrix
第一代 Spring Cloud 核心组件
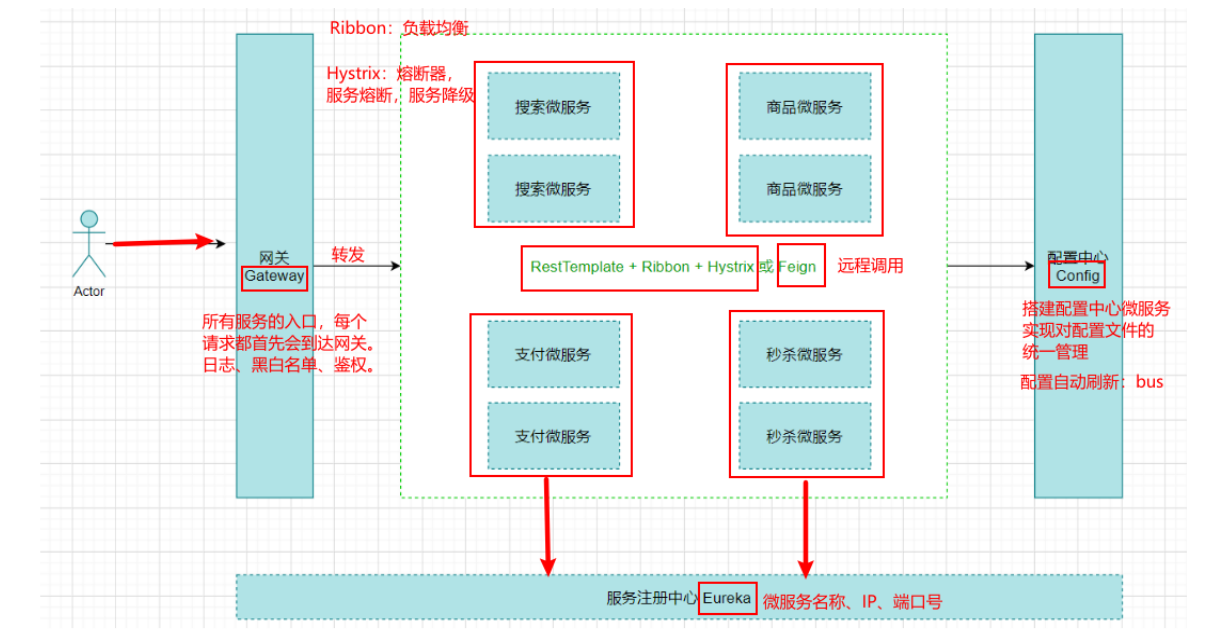
Eureka服务注册中心
关于服务注册中心
注意:服务注册中心本质上是为了解耦服务提供者和服务消费者。
服务消费者 --> 服务提供者
服务消费者 --> 服务注册中心 --> 服务提供者
对于任何一个微服务,原则上都应存在或者支持多个提供者(比如商品微服务部署多个实例),这是由微服务的分布式属性决定的。
更进一步,为了支持弹性扩、缩容特性,一个微服务的提供者的数量和分布往往是动态变化的,也是无法预先确定的。因此,原本在单体应用阶段常用的静态LB机制就不再适用了,需要引入额外的组件来管理微服务提供者的注册与发现,而这个组件就是服务注册中心。
注册中心实现原理
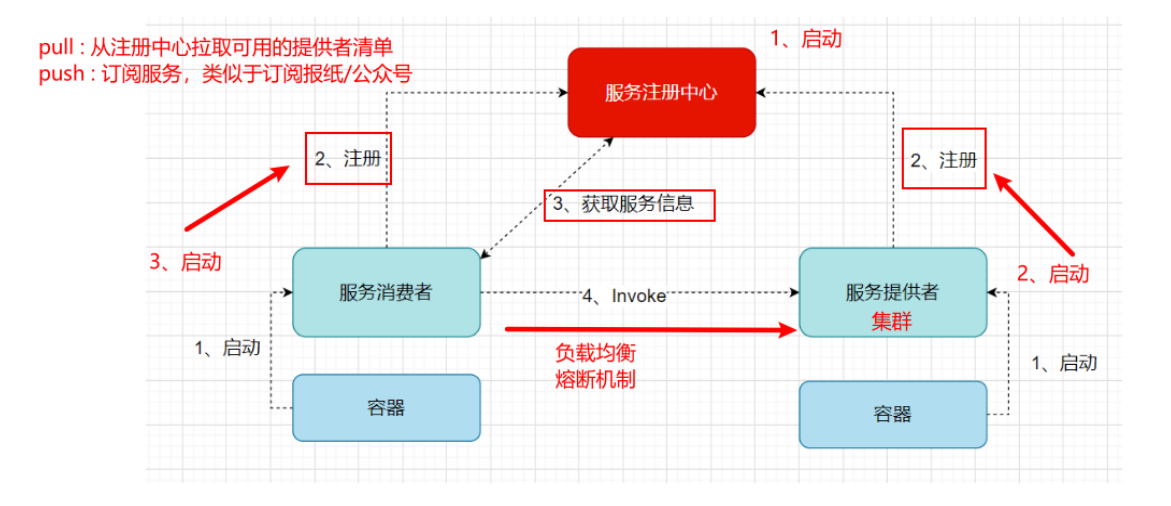
分布式微服务架构中,服务注册中心用于存储服务提供者地址信息、服务发布相关的属性信息,消费者通过主动查询和被动通知的方式获取服务提供者的地址信息,而不再需要通过硬编码方式得到提供者的地址信息。消费者只需要知道当前系统发布了那些服务,而不需要知道服务具体存在于什么位置,这就是透明化路由。
分布式微服务架构中,服务注册中心用于存储服务提供者地址信息、服务发布相关的属性信息,消
费者通过主动查询和被动通知的方式获取服务提供者的地址信息,而不再需要通过硬编码方式得到提供
者的地址信息。消费者只需要知道当前系统发布了那些服务,而不需要知道服务具体存在于什么位置,
这就是透明化路由。
1)服务提供者启动
2)服务提供者将相关服务信息主动注册到注册中心
3)服务消费者获取服务注册信息:
pull模式:服务消费者可以主动拉取可用的服务提供者清单
push模式:服务消费者订阅服务(当服务提供者有变化时,注册中心也会主动推送更新后的服务清单给消费者
4)服务消费者直接调用服务提供者
另外,注册中心也需要完成服务提供者的健康监控,当发现服务提供者失效时需要及时剔除;
主流服务中心对比
Zookeeper
Dubbo + Zookeeper
Zookeeper它是一个分布式服务框架,是Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。
简单来说zookeeper本质 = 存储 + 监听通知。
Zookeeper 用来做服务注册中心,主要是因为它具有节点变更通知功能,只要客户端监听相关服务节点,服务节点的所有变更,都能及时的通知到监听客户端,这样作为调用方只要使用ZSookeeper 的客户端就能实现服务节点的订阅和变更通知功能了,非常方便。另外,Zookeeper可用性也可以,因为只要半数以上的选举节点存活,整个集群就是可用的,最少节点数为3。
Eureka
由Netflix开源,并被Pivatal集成到SpringCloud体系中,它是基于 RestfulAPI 风格开发的服务注册与发现组件。
Consul
Consul是由HashiCorp基于Go语言开发的支持多数据中心分布式高可用的服务发布和注册服务软件, 采用Raft算法保证服务的一致性,且支持健康检查。
Nacos
Nacos是一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。简单来说Nacos 就是 注册中心 + 配置中心的组合,帮助我们解决微服务开发必会涉及到的服务注册 与发现,服务配置,服务管理等问题。Nacos 是 Spring Cloud Alibaba 核心组件之一,负责服务注册与发现,还有配置。

CAP定理又称CAP原则,指的是在一个分布式系统中,Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),最多只能同时三个特性中的两个,三者不可兼得。
P:分区容错性:分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性或可用性的服务(一定的要满足的)
C:数据一致性:all nodes see the same data at the same time
A:高可用:Reads and writes always succeed
CAP不可能同时满足三个,要么是AP,要么是CP
服务注册中心组件 Eureka
服务注册中心的一般原理、对比了主流的服务注册中心方案,目光聚焦Eureka。
- Eureka 基础架构
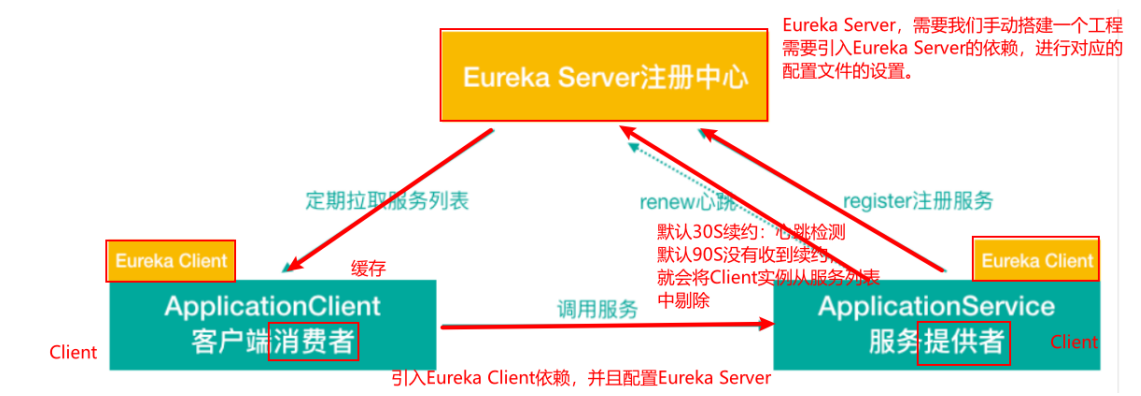
Eureka 交互流程及原理

Eureka 包含两个组件:Eureka Server 和 Eureka Client,Eureka Client是一个Java客户端,用于简化与Eureka Server的交互;Eureka Server提供服务发现的能力,各个微服务启动时,会通过Eureka Client向Eureka Server 进行注册自己的信息(例如网络信息),Eureka Server会存储该服务的信息;
搭建单例Eureka Server服务注册中心
1. 单实例Eureka Server—>访问管理界面
2. 服务提供者(商品微服务注册到集群)
3. 服务消费者(页面静态化微服务注册到Eureka/从Eureka Server获取服务信息)
4. 完成调用
<dependencyManagement> <dependencies> <!--SCN--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-dependencies</artifactId> <version>Greenwich.RELEASE</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement>
<dependencies> <!--Eureka server依赖--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-eureka-server</artifactId> </dependency> </dependencies>
注意:在父工程的pom文件中手动引入jaxb的jar,因为Jdk9之后默认没有加载该模块,Eureka Server使用到,所以需要手动导入,否则EurekaServer服务无法启动
<!--引入Jaxb,开始 : 在父工程的pom文件中手动引入jaxb的jar,因为Jdk9之后默认没有加载该模块,Eureka Server使用到,所以需要手动导入,否则EurekaServer服务无法启动--> <dependency> <groupId>com.sun.xml.bind</groupId> <artifactId>jaxb-core</artifactId> <version>2.2.11</version> </dependency> <dependency> <groupId>javax.xml.bind</groupId> <artifactId>jaxb-api</artifactId> </dependency> <dependency> <groupId>com.sun.xml.bind</groupId> <artifactId>jaxb-impl</artifactId> <version>2.2.11</version> </dependency> <dependency> <groupId>org.glassfish.jaxb</groupId> <artifactId>jaxb-runtime</artifactId> <version>2.2.10-b140310.1920</version> </dependency> <dependency> <groupId>javax.activation</groupId> <artifactId>activation</artifactId> <version>1.1.1</version> </dependency> <!--引入Jaxb,结束-->
server: port: 9301 spring: application: name: lagou-cloud-eureka eureka: client: #Eureka server本身也是eureka的一个客户端,因为在集群下需要与其他eureka server进行数据的同步 service-url: #定义eureka server url,如果是集群情况下defaultZone设置为集群下的别的Eureka Server的地址,多个地址使用“,”隔开 defaultZone: http://LagouCloudEurekaServerA:9300/eureka register-with-eureka: true # 表示是否向Eureka中心注册自己的信息,因为自己就是Eureka Server所以不进行注册,默认为true fetch-registry: true # 是否查询/拉取Eureka Server服务注册列表,默认为true instance: #hostname: localhost # 当前eureka实例的主机名 #使用ip注册,否则会使用主机名注册了(此处考虑到对老版本的兼容,新版本经过实验都是ip) prefer-ip-address: true #自定义实例显示格式,加上版本号,便于多版本管理,注意是ip-address,早期版本是ipAddress instance-id: ${spring.cloud.client.ip-address}:${spring.application.name}:${server.port}:@project.version@
package com.zhf.eureka; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer; @SpringBootApplication //表示当前项目为Eureka Server @EnableEurekaServer public class EurekaApplication { public static void main(String[] args) { SpringApplication.run(EurekaApplication.class, args); } }
5、访问http://127.0.0.1:9200,如果看到如下页面(Eureka注册中心后台),则表明EurekaServer发布成功
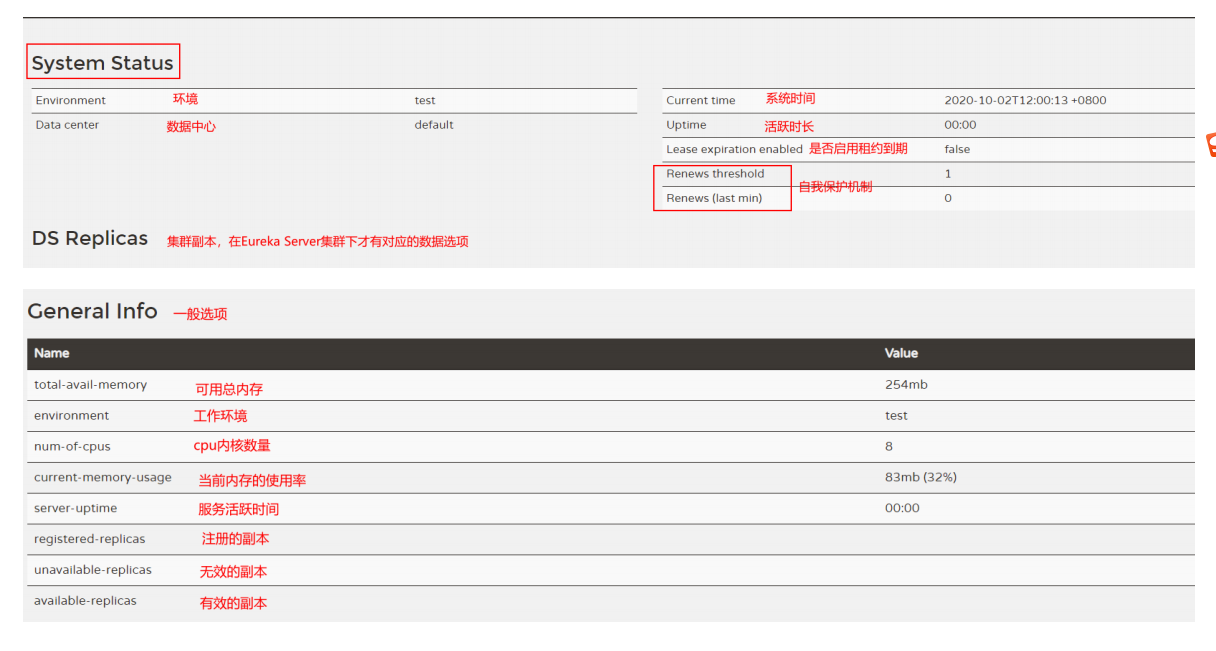
6、商品微服务和页面静态化微服务注册到Eureka
pom文件中添加Eureka Client依赖
<!--Eureka client--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-eureka-client</artifactId> </dependency>
yml配置Eureka服务端信息
eureka: client: #Eureka server本身也是eureka的一个客户端,因为在集群下需要与其他eureka server进行数据的同步 service-url: #定义eureka server url,如果是集群情况下defaultZone设置为集群下的别的Eureka Server的地址,多个地址使用“,”隔开 defaultZone: http://localhost:9300/eureka,http://localhost:9301/eureka register-with-eureka: true # 表示是否向Eureka中心注册自己的信息,因为自己就是Eureka Server所以不进行注册,默认为true fetch-registry: true # 是否查询/拉取Eureka Server服务注册列表,默认为true instance: #hostname: localhost # 当前eureka实例的主机名 #使用ip注册,否则会使用主机名注册了(此处考虑到对老版本的兼容,新版本经过实验都是ip) prefer-ip-address: true #自定义实例显示格式,加上版本号,便于多版本管理,注意是ip-address,早期版本是ipAddress instance-id: ${spring.cloud.client.ip-address}:${spring.application.name}:${server.port}:@project.version@
修改启动类
@SpringBootApplication @EnableDiscoveryClient //@EnableEurekaClient public class PageApplication { public static void main(String[] args) { SpringApplication.run(PageApplication.class,args); } //像容器中注入一个RestTemplate,封装了HttpClient @Bean @LoadBalanced //启动请求的负载均衡 public RestTemplate restTemplate(){ return new RestTemplate(); } }
搭建Eureka Server 高可用集群
在互联网应用中,服务实例很少有单个的。
如果EurekaServer只有一个实例,该实例挂掉,正好微服务消费者本地缓存列表中的服务实例也不可用,那么这个时候整个系统都受影响。
在生产环境中,我们会配置Eureka Server集群实现高可用。Eureka Server集群之中的节点通过点对点(P2P)通信的方式共享服务注册表。我们开启两台 Eureka Server 以搭建集群。
由于是在个人计算机中进行测试很难模拟多主机的情况,Eureka配置server集群时需要执行host地址。 所以需要修改个人电脑中host地址:
win10操作系统下:C:\Windows\System32\drivers\etc\host
127.0.0.1 LagouCloudEurekaServerA 127.0.0.1 LagouCloudEurekaServerB
将lagou-cloud-eureka复制一份为lagou-cloud-eureka9201
1、修改 lagou-cloud-eureka-server 工程中的yml配置文件
9200:
server: port: 9200 spring: application: name: lagou-cloud-eureka eureka: client: #Eureka server本身也是eureka的一个客户端,因为在集群下需要与其他eureka server进行数据的同步 service-url: #定义eureka server url,如果是集群情况下defaultZone设置为集群下的别的Eureka Server的地址,多个地址使用“,”隔开 defaultZone: http://LagouCloudEurekaServerB:9201/eureka register-with-eureka: true # 表示是否向Eureka中心注册自己的信息,因为自己就是Eureka Server所以不进行注册,默认为true fetch-registry: true # 是否查询/拉取Eureka Server服务注册列表,默认为true instance: #hostname: localhost # 当前eureka实例的主机名 #使用ip注册,否则会使用主机名注册了(此处考虑到对老版本的兼容,新版本经过实验都是ip) prefer-ip-address: true #自定义实例显示格式,加上版本号,便于多版本管理,注意是ip-address,早期版本是ipAddress instance-id: ${spring.cloud.client.ip-address}:${spring.application.name}:${server.port}:@project.version@
9201:
server: port: 9201 spring: application: name: lagou-cloud-eureka eureka: client: #Eureka server本身也是eureka的一个客户端,因为在集群下需要与其他eureka server进行数据的同步 service-url: #定义eureka server url defaultZone: http://LagouCloudEurekaServerA:9200/eureka register-with-eureka: true # 表示是否向Eureka中心注册自己的信息,因为自己就是Eureka Server所以不进行注册,默认为true fetch-registry: true # 是否查询/拉取Eureka Server服务注册列表,默认为true instance: #hostname: localhost # 当前eureka实例的主机名 #使用ip注册,否则会使用主机名注册了(此处考虑到对老版本的兼容,新版本经过实验都是ip) prefer-ip-address: true #自定义实例显示格式,加上版本号,便于多版本管理,注意是ip-address,早期版本是ipAddress instance-id: ${spring.cloud.client.ip-address}:${spring.application.name}:${server.port}:@project.version@
商品微服务:
server: port: 9200 #微服务的集群环境中,通常会为每一个微服务叠加。 spring: application: name: lagou-service-goods datasource: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:3306/springcloud_lagou?useUnicode=true&characterEncoding=utf8&serverTimezone=UTC username: root password: 123456 eureka: client: #Eureka server本身也是eureka的一个客户端,因为在集群下需要与其他eureka server进行数据的同步 service-url: #定义eureka server url,如果是集群情况下defaultZone设置为集群下的别的Eureka Server的地址,多个地址使用“,”隔开 defaultZone: http://localhost:9300/eureka,http://localhost:9301/eureka register-with-eureka: true # 表示是否向Eureka中心注册自己的信息,因为自己就是Eureka Server所以不进行注册,默认为true fetch-registry: true # 是否查询/拉取Eureka Server服务注册列表,默认为true instance: #hostname: localhost # 当前eureka实例的主机名 #使用ip注册,否则会使用主机名注册了(此处考虑到对老版本的兼容,新版本经过实验都是ip) prefer-ip-address: true #自定义实例显示格式,加上版本号,便于多版本管理,注意是ip-address,早期版本是ipAddress instance-id: ${spring.cloud.client.ip-address}:${spring.application.name}:${server.port}:@project.version@
页面静态化微服务:(配置和上面类似,只是服务名和端口号不一样)
服务消费者调用服务提供者
改造页面静态化微服务:之前是直接通过RestTemplate写死URL进行调用,现在通过Eureka方式进行调用。
@RestController @RequestMapping("/page") public class PageController { @Autowired private RestTemplate restTemplate; @Autowired private DiscoveryClient discoveryClient; @RequestMapping("/getData/{id}") public Products findDataById(@PathVariable Integer id){ //1.获得Eureka中注册的lagou-service-product实例集合 List<ServiceInstance> instances = discoveryClient.getInstances("lagouservice-product"); //2.获得实例集合中的第一个 ServiceInstance instance = instances.get(0); //3.根据实例信息拼接IP地址 String host = instance.getHost(); int port = instance.getPort(); String url = "http://"+host+":"+port+"/product/query/"+id; //4.调用 Products products = restTemplate.getForObject(url, Products.class); System.out.println("从lagou-service-product获得product对象:"+products); return products; } }
Eureka细节详解
Eureka元数据详解
Eureka的元数据有两种:标准元数据和自定义元数据。
标准元数据:主机名、IP地址、端口号等信息,这些信息都会被发布在服务注册表中,用于服务之间的调用。
自定义元数据:可以使用eureka.instance.metadata-map配置,符合KEY/VALUE的存储格式。这些元数据可以在远程客户端中访问。
类似于
instance: #使用ip注册,否则会使用主机名注册了(此处考虑到对老版本的兼容,新版本经过实验都是ip) prefer-ip-address: true #自定义实例显示格式,加上版本号,便于多版本管理,注意是ip-address,早期版本是ipAddress instance-id: ${spring.cloud.client.ipaddress}:${spring.application.name}:${server.port}:@project.version@ metadata-map: ip: 192.168.200.128 port: 10000 user: YuanJing pwd: 123456
我们可以在程序中可以使用DiscoveryClient 获取指定微服务的所有元数据信息
package com.lagou.page.controller; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.cloud.client.ServiceInstance; import org.springframework.cloud.client.discovery.DiscoveryClient; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; import java.util.List; import java.util.Map; import java.util.Set; @RestController @RequestMapping("/metadata") public class MetadataController { @Autowired private DiscoveryClient discoveryClient; @RequestMapping("show") public String showMetadata(){ String result = ""; List<ServiceInstance> instances = discoveryClient.getInstances("lagouservice-page"); for (ServiceInstance instance:instances) { //获取服务元数据 Map<String, String> metadata = instance.getMetadata(); Set<Map.Entry<String, String>> entries = metadata.entrySet(); for (Map.Entry<String,String> entry : entries){ String key = entry.getKey(); String value = entry.getValue(); result+="key:"+key+",value:"+value; } } return result; } }
Eureka客户端详解
服务提供者(也是Eureka客户端)要向EurekaServer注册服务,并完成服务续约等工作
服务注册详解(服务提供者)
1)当我们导入了eureka-client依赖坐标,配置Eureka服务注册中心地址
2)服务在启动时会向注册中心发起注册请求,携带服务元数据信息
3)Eureka注册中心会把服务的信息保存在Map中。
服务续约详解(服务提供者)
服务每隔30秒会向注册中心续约(心跳)一次(也称为报活),如果没有续约,租约在90秒后到期,然后服务会被失效。每隔30秒的续约操作我们称之为心跳检测
Eureka Client :30S续约一次,在Eureka Server更新自己的状态 (Client端进行配置)
Eureka Server:90S还没有进行续约,将该微服务实例从服务注册表(Map)剔除 (Client端进行配置)
Eureka Client: 30S拉取服务最新的注册表并缓存到本地 (Client端进行配置)
往往不需要我们调整这两个配置
#向Eureka服务中心集群注册服务 eureka: instance: # 租约续约间隔时间,默认30秒 lease-renewal-interval-in-seconds: 30 # 租约到期,服务时效时间,默认值90秒,服务超过90秒没有发生心跳,EurekaServer会将服务从列 表移除 lease-expiration-duration-in-seconds: 90
获取服务列表(服务注册表)详解(服务消费者)
每隔30秒服务会从注册中心中拉取一份服务列表,这个时间可以通过配置修改。往往不需要我们调整
#向Eureka服务中心集群注册服务 eureka: client: # 每隔多久拉取一次服务列表 registry-fetch-interval-seconds: 30
1)服务消费者启动时,从 EurekaServer服务列表获取只读备份,缓存到本地
2)每隔30秒,会重新获取并更新数据
3)每隔30秒的时间可以通过配置eureka.client.registry-fetch-interval-seconds修改
Eureka服务端详解
服务下线:
1)当服务正常关闭操作时,会发送服务下线的REST请求给EurekaServer。
2)服务中心接受到请求后,将该服务置为下线状态
失效剔除:
Eureka Server会定时(间隔值是eureka.server.eviction-interval-timer-in-ms,默认60s)进行检查,如果发现实例在在一定时间(此值由客户端设置的eureka.instance.lease-expiration-duration-inseconds定义,默认值为90s)内没有收到心跳,则会注销此实例。
自我保护机制:
自我保护模式正是一种针对网络异常波动的安全保护措施,使用自我保护模式能使Eureka集群更加的健壮、稳定的运行。
自我保护机制的工作机制是:如果在15分钟内超过85%的客户端节点都没有正常的心跳,那么Eureka就认为客户端与注册中心出现了网络故障,Eureka Server自动进入自我保护机制,此时会出现以下几种情况:
1. Eureka Server不再从注册列表中移除因为长时间没收到心跳而应该过期的服务。
2. Eureka Server仍然能够接受新服务的注册和查询请求,但是不会被同步到其它节点上,保证当前节点依然可用。
3. 当网络稳定时,当前Eureka Server新的注册信息会被同步到其它节点中。
因此Eureka Server可以很好的应对因网络故障导致部分节点失联的情况,而不会像ZK那样如果有一半不可用的情况会导致整个集群不可用而变成瘫痪。
为什么会有自我保护机制?
默认情况下,如果Eureka Server在一定时间内(默认90秒)没有接收到某个微服务实例的心跳,Eureka Server将会移除该实例。但是当网络分区故障发生时,微服务与Eureka Server之间无法正常通信,而微服务本身是正常运行的,此时不应该移除这个微服务,所以引入了自我保护机制。
服务中心页面会显示如下提示信息
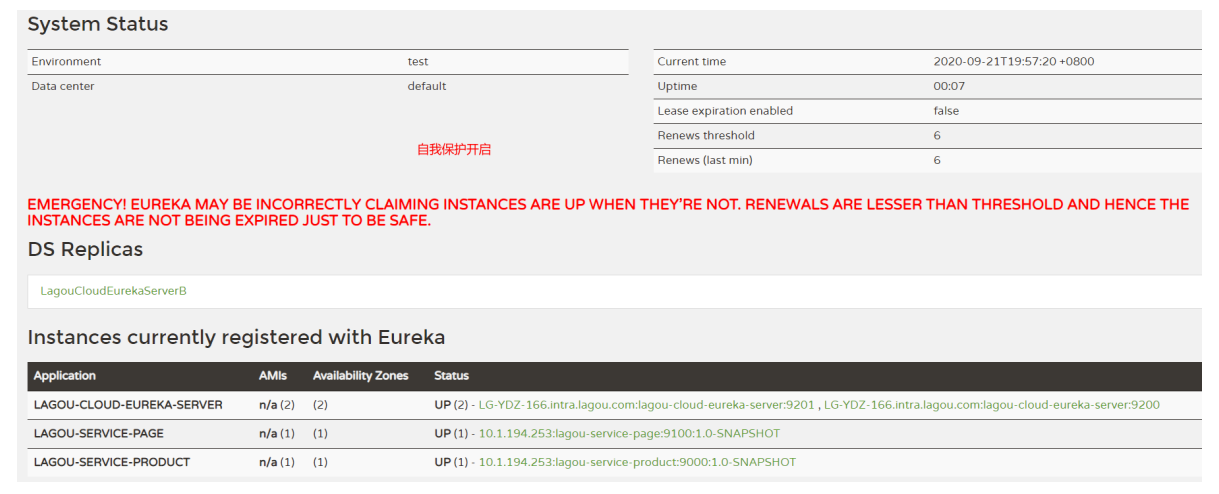
我们在单机测试的时候很容易满足心跳失败比例在 15 分钟之内低于 85%,这个时候就会触发 Eureka的保护机制,一旦开启了保护机制(默认开启),则服务注册中心维护的服务实例就不是那么准确了,此时我们通过修改Eureka Server的配置文件来关闭保护机制,这样可以确保注册中心中不可用的实例被及时的剔除(不推荐)。
eureka: server: enable-self-preservation: false # 关闭自我保护模式(缺省为打开)
经验:建议生产环境打开自我保护机制
Ribbon负载均衡
关于负载均衡
负载均衡一般分为服务器端负载均衡和客户端负载均衡
所谓服务器端负载均衡,比如Nginx、F5这些,请求到达服务器之后由这些负载均衡器根据一定的算法将请求路由到目标服务器处理。
所谓客户端负载均衡,比如我们要说的Ribbon,服务消费者客户端会有一个服务器地址列表,调用方在请求前通过一定的负载均衡算法选择一个服务器进行访问,负载均衡算法的执行是在请求客户端进行。
Ribbon是Netflix发布的负载均衡器。Eureka一般配合Ribbon进行使用,Ribbon利用从Eureka中读取到服务信息,在调用服务提供者提供的服务时,会根据一定的算法进行负载。

Ribbon高级应用
需求:
复制商品微服务9001,在9000和9001编写Controller,返回服务实例端口。
Page微服务中通过负载均衡策略调用lagou-service-product的controller
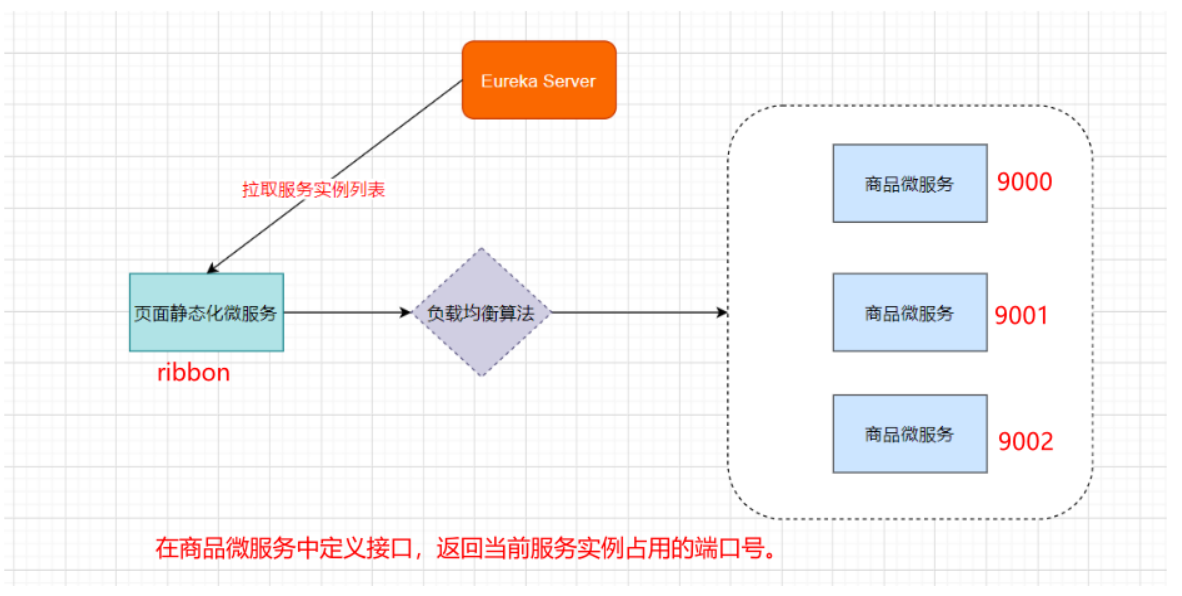
在微服务中使用Ribbon不需要额外导入依赖坐标,微服务中引入过eureka-client相关依赖,会自动引入Ribbon相关依赖坐标。
代码中使用如下,在RestTemplate上添加对应注解即可
@SpringBootApplication @EnableDiscoveryClient public class PageApplication { public static void main(String[] args) { SpringApplication.run(PageApplication.class,args); } //像容器中注入一个RestTemplate,封装了HttpClient @Bean @LoadBalanced //启动请求的负载均衡 public RestTemplate restTemplate(){ return new RestTemplate(); } }
创建lagou-serivce-product-9001微服务,创建ServerConfigController,定义方法返回当前微服务所使用的容器端口号
修改服务提供者api返回值,返回当前实例的端口号,便于观察负载情况
@RestController @RequestMapping("/service") public class ServiceInfoController { @Value("${server.port}") private String port; @GetMapping("/port") public String getPort(){ return port; } }
在页面静态化微服务中调用lagou-server-product下的资源路径:http://lagou-server-product/server/query
@RequestMapping("/getPort")
public String getProductServerPort(){
String url = "http://lagou-service-product/server/query";
return restTemplate.getForObject(url,String.class);
}
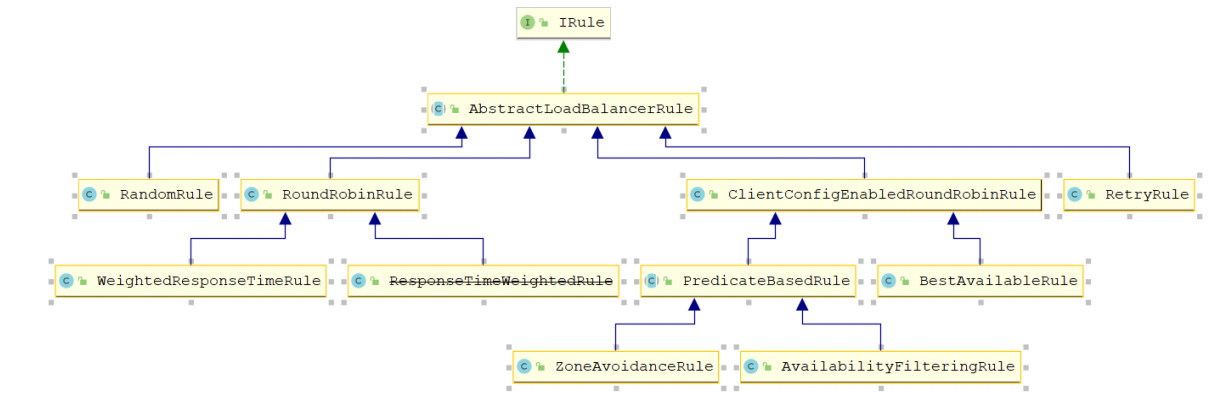
Ribbon负载均衡策略
Ribbon内置了多种负载均衡策略,内部负责复杂均衡的顶级接口为 com.netflix.loadbalancer.IRule ,接口简介:
/* * * Copyright 2013 Netflix, Inc. * * Licensed under the Apache License, Version 2.0 (the "License"); * you may not use this file except in compliance with the License. * You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. * */ package com.netflix.loadbalancer; /** * Interface that defines a "Rule" for a LoadBalancer. A Rule can be thought of * as a Strategy for loadbalacing. Well known loadbalancing strategies include * Round Robin, Response Time based etc. * * @author stonse * */ public interface IRule{ /* * choose one alive server from lb.allServers or * lb.upServers according to key * * @return choosen Server object. NULL is returned if none * server is available */ public Server choose(Object key); public void setLoadBalancer(ILoadBalancer lb); public ILoadBalancer getLoadBalancer(); }
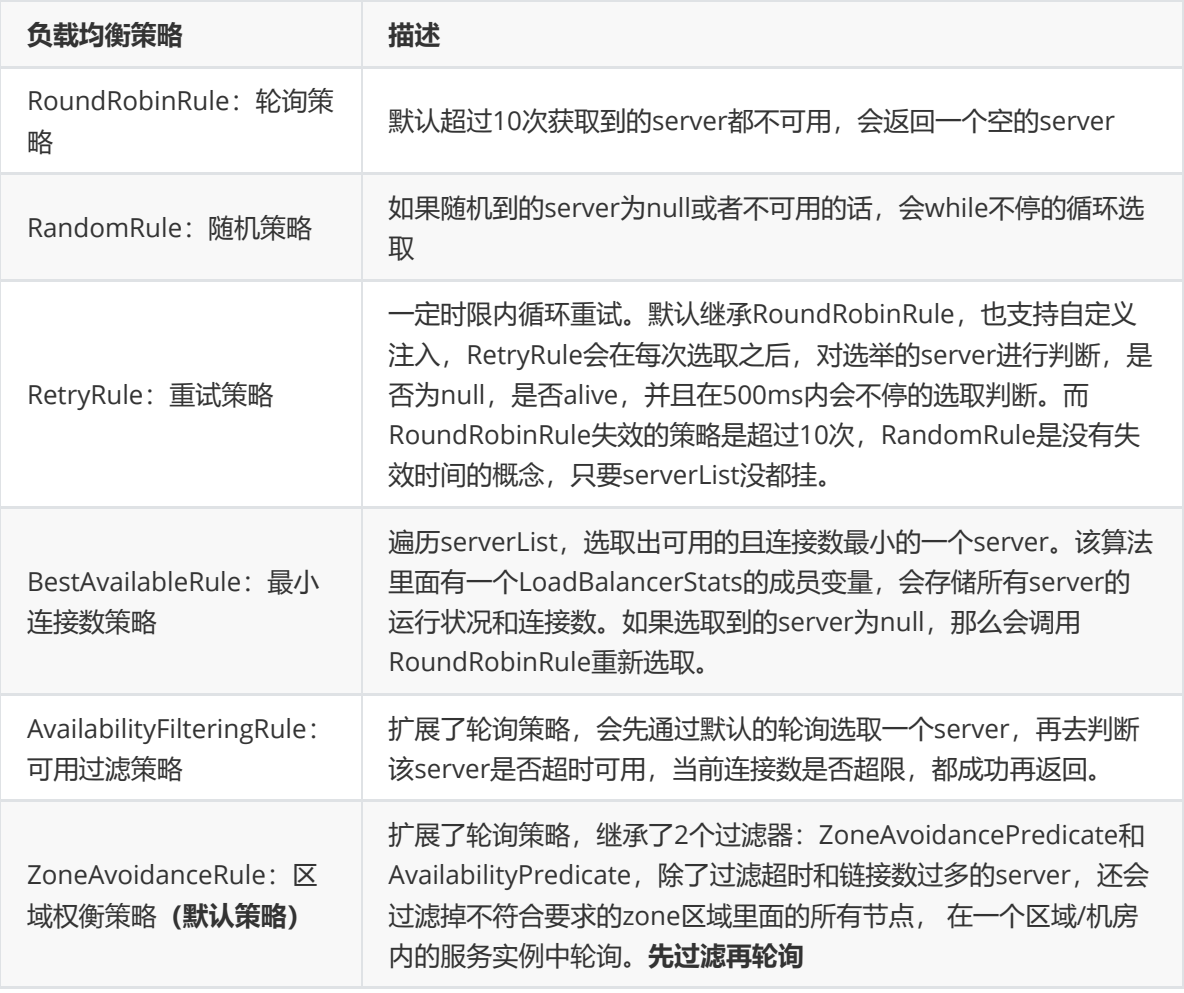
修改负载均衡策略:
#针对的被调用方微服务名称,不加就是全局生效 lagou-service-product: ribbon: NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule #随机策略 lagou-service-product: ribbon: NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RoundRobinRule #轮询策略
Ribbon核心源码剖析
Ribbon工作原理:
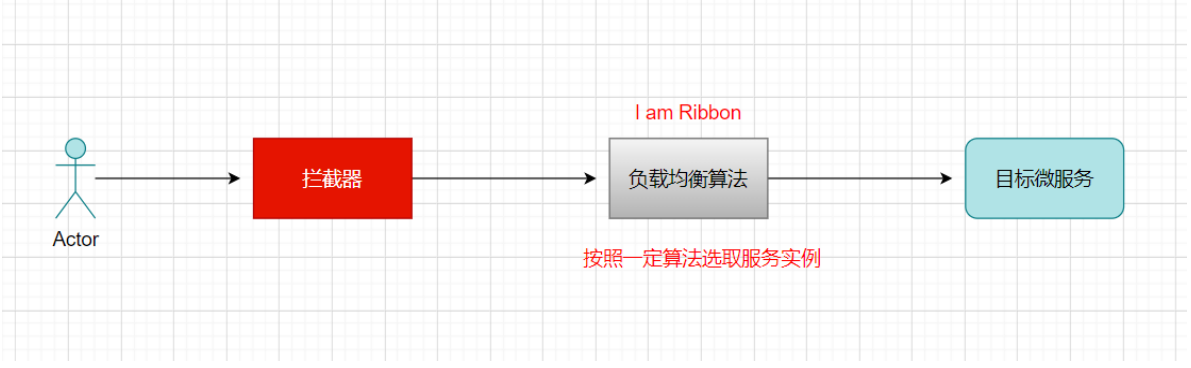
老规矩:SpringCloud充分利用了SpringBoot的自动装配特点,找spring.factories配置文件
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\org.springframework.cloud.netflix.ribbon.RibbonAutoConfiguration
LoadBalancerAutoConfiguration 类中配置
装配验证:

自动注入:

注入restTemplate定制器:
为retTemplate对象设置loadBalancerInterceptor

到这里,我们明白,添加了注解的RestTemplate对象会被添加一个拦截器LoadBalancerInterceptor,该拦截器就是后续拦截请求进行负载处理的。
Hystrix熔断器
属于一种容错机制
微服务中的雪崩效应
当山坡积雪内部的内聚力抗拒不了它所受到的重力拉引时,便向下滑动,引起大量雪体崩塌,人们把这种自然现象称作雪崩。
微服务中,一个请求可能需要多个微服务接口才能实现,会形成复杂的调用链路。
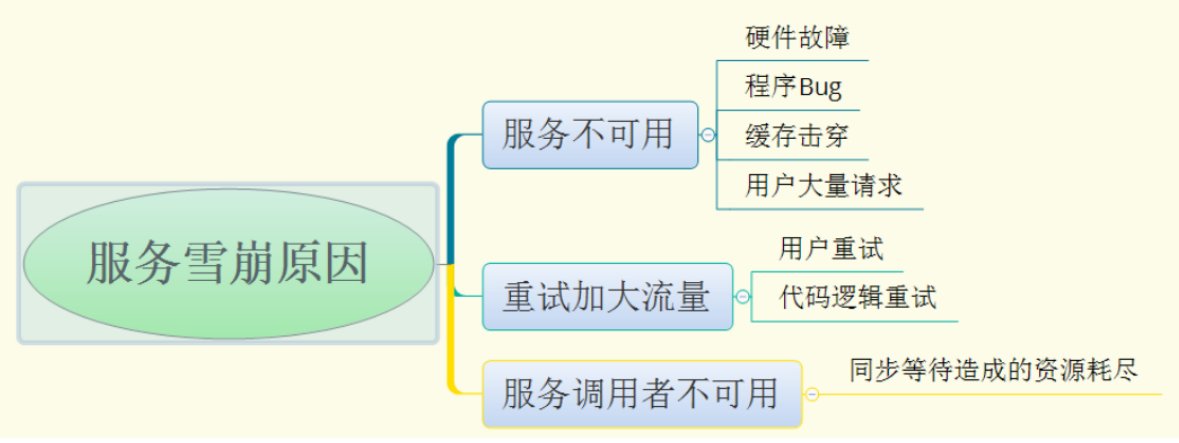
服务雪崩效应:是一种因“服务提供者的不可用”(原因)导致“服务调用者不可用”(结果),并将不可用逐渐放大的现象。
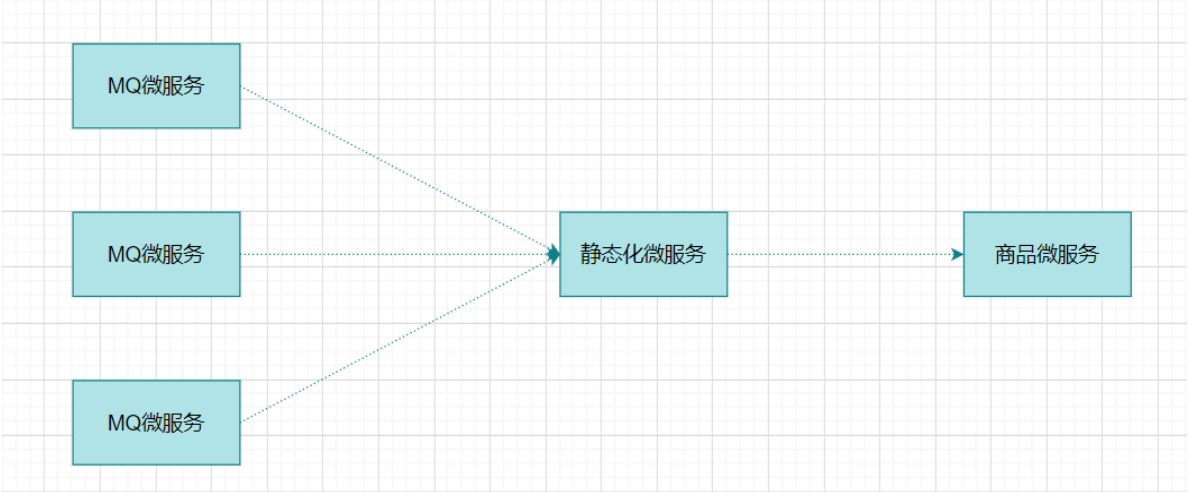
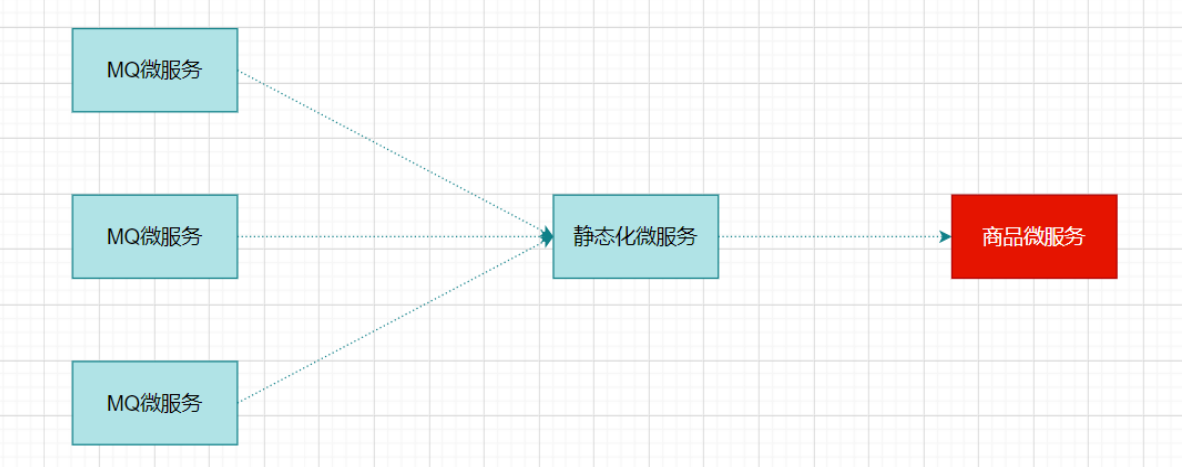
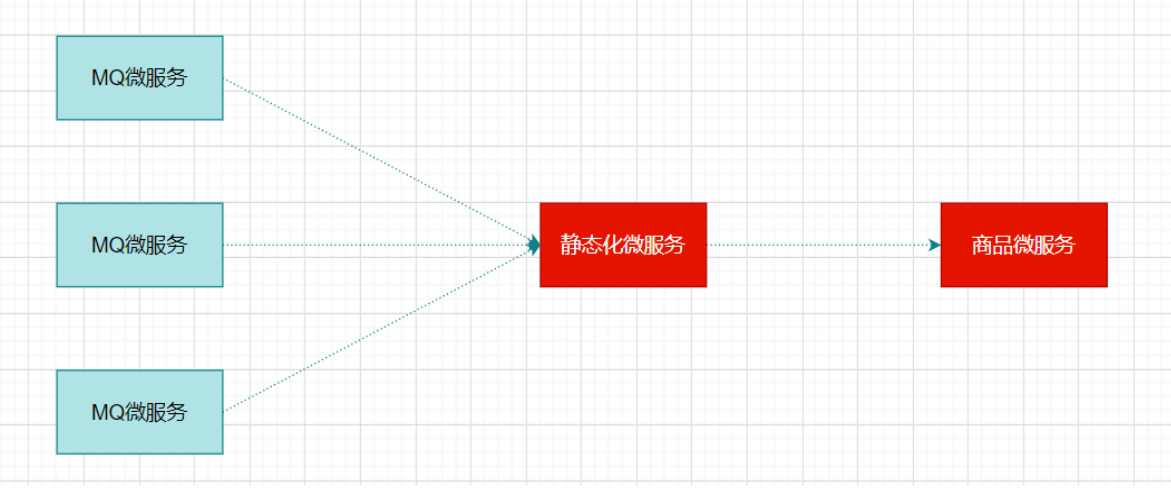
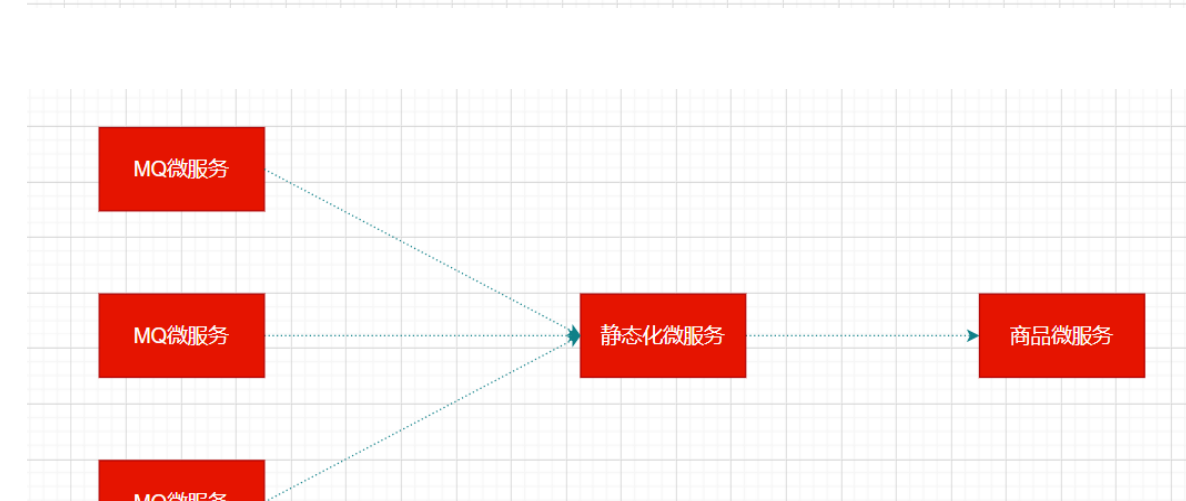
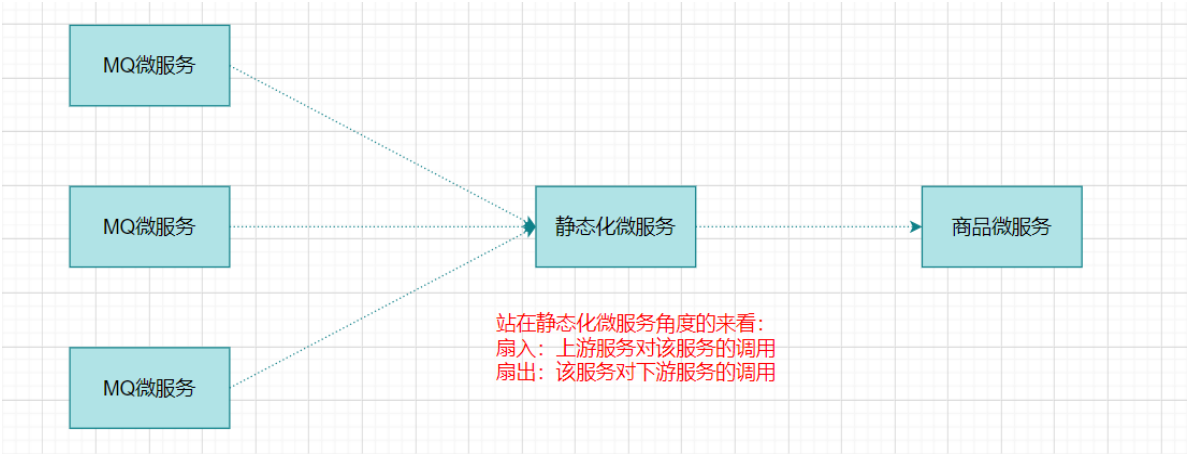
扇入:代表着该微服务被调用的次数,扇入大,说明该模块复用性好
扇出:该微服务调用其他微服务的个数,扇出大,说明业务逻辑复杂
扇入大是一个好事,扇出大不一定是好事
在微服务架构中,一个应用可能会有多个微服务组成,微服务之间的数据交互通过远程过程调用完成。这就带来一个问题,假设微服务A调用微服务B和微服务C,微服务B和微服务C又调用其它的微服务,这就是所谓的“扇出”。如果扇出的链路上某个微服务的调用响应时间过长或者不可用,对微服务A的调用就会占用越来越多的系统资源,进而引起系统崩溃,所谓的“雪崩效应”。
如图中所示,最下游商品微服务响应时间过长,大量请求阻塞,大量线程不会释放,会导致服务器资源耗尽,最终导致上游服务甚至整个系统瘫痪。
形成原因:
服务雪崩的过程可以分为三个阶段:
1. 服务提供者不可用
2. 重试加大请求流量
3. 服务调用者不可用
服务雪崩的每个阶段都可能由不同的原因造成:
雪崩效应解决方案
从可用性可靠性着想,为防止系统的整体缓慢甚至崩溃,采用的技术手段;
下面,我们介绍三种技术手段应对微服务中的雪崩效应,这三种手段都是从系统可用性、可靠性角度出发,尽量防止系统整体缓慢甚至瘫痪。
服务熔断
熔断机制是应对雪崩效应的一种微服务链路保护机制。我们在各种场景下都会接触到熔断这两个字。高压电路中,如果某个地方的电压过高,熔断器就会熔断,对电路进行保护。股票交易中,如果股票指数过高,也会采用熔断机制,暂停股票的交易。同样,在微服务架构中,熔断机制也是起着类似的作用。当扇出链路的某个微服务不可用或者响应时间太长时,熔断该节点微服务的调用,进行服务的降级,快速返回错误的响应信息。当检测到该节点微服务调用响应正常后,恢复调用链路。
注意:
1)服务熔断重点在“断”,切断对下游服务的调用
2)服务熔断和服务降级往往是一起使用的,Hystrix就是这样。
服务降级
通俗讲就是整体资源不够用了,先将一些不关紧的服务停掉(调用我的时候,给你返回一个预留的值,也叫做兜底数据),待渡过难关高峰过去,再把那些服务打开。
服务降级一般是从整体考虑,就是当某个服务熔断之后,服务器将不再被调用,此刻客户端可以自己准备一个本地的fallback回调,返回一个缺省值,这样做,虽然服务水平下降,但好歹可用,比直接挂掉要强。
服务限流
服务降级是当服务出问题或者影响到核心流程的性能时,暂时将服务屏蔽掉,待高峰或者问题解决后再打开;但是有些场景并不能用服务降级来解决,比如秒杀业务这样的核心功能,这个时候可以结合服务限流来限制这些场景的并发/请求量
限流措施也很多,比如
- 限制总并发数(比如数据库连接池、线程池)
- 限制瞬时并发数(如nginx限制瞬时并发连接数)
- 限制时间窗口内的平均速率(如Guava的RateLimiter、nginx的limit_req模块,限制每秒的平均速率)
- 限制远程接口调用速率、限制MQ的消费速率等
Hystrix简介
[来自官网]Hystrix(豪猪),宣言“defend your application”是由Netflix开源的一个延迟和容错库,用于隔离访问远程系统、服务或者第三方库,防止级联失败,从而提升系统的可用性与容错性。Hystrix主要通过以下几点实现延迟和容错。
包裹请求:使用HystrixCommand包裹对依赖的调用逻辑。 页面静态化微服务方法(@HystrixCommand 添加Hystrix控制)
跳闸机制:当某服务的错误率超过一定的阈值时,Hystrix可以跳闸,停止请求该服务一段时间。
资源隔离:Hystrix为每个依赖都维护了一个小型的线程池(舱壁模式)。如果该线程池已满, 发往该依赖的请求就被立即拒绝,而不是排队等待,从而加速失败判定。
监控:Hystrix可以近乎实时地监控运行指标和配置的变化,例如成功、失败、超时、以及被拒绝的请求等。
回退机制:当请求失败、超时、被拒绝,或当断路器打开时,执行回退逻辑。回退逻辑由开发人员自行提供,例如返回一个缺省值。
自我修复:断路器打开一段时间后,会自动进入“半开”状态(探测服务是否可用,如还是不可用,再次退回打开状态)。
Hystrix应用
熔断处理
目的:商品微服务长时间没有响应,服务消费者—>页面静态化微服务快速失败给用户提示
引入依赖:服务消费者工程(静态化微服务)中引入Hystrix依赖坐标(也可以添加在父工程中)
<!--熔断器Hystrix--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-hystrix</artifactId> </dependency>
开启熔断:服务消费者工程(静态化微服务)的启动类中添加熔断器开启注解
@EnableCircuitBreaker
/** * 注解简化写法 * @SpringCloudApplication = @SpringBootApplication+@EnableDiscoveryClient+@EnableCircuitBreaker */ @SpringBootApplication @EnableDiscoveryClient //@EnableEurekaClient @EnableCircuitBreaker // 开启熔断 public class PageApplication { public static void main(String[] args) { SpringApplication.run(PageApplication.class,args); } @Bean @LoadBalanced//Ribbon负载均衡 public RestTemplate restTemplate(){ return new RestTemplate(); } }
定义服务降级处理方法:业务方法上使用@HystrixCommand的fallbackMethod属性关联到服务降级处理方法
/** * 模拟服务超时,熔断处理 * 针对熔断处理,Hystrix默认维护一个线程池,默认大小为10。 * * @return */ @HystrixCommand( //只有是在@HystrixCommand中定义了threadPoolKey,就意味着开启了舱壁模式(线程隔离),该方法就会自己维护一个线程池。 threadPoolKey = "getProductServerPort2", //默认所有的请求共同维护一个线程池,实际开发:每个方法维护一个线程池 //每一个属性对应的都是一个HystrixProperty threadPoolProperties = { @HystrixProperty(name = "coreSize", value = "1"),//并发线程数 @HystrixProperty(name = "maxQueueSize", value = "20")//默认线程队列值是-1,默认不开启 }, //超时时间的设置 commandProperties = { //设置请求的超时时间,一旦请求超过此时间那么都按照超时处理,默认超时时间是1S @HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "2000") } ) @GetMapping("/loadProductServicePort2") public String getProductServerPort2() { return productFeign.getPort(); }
商品微服务模拟超时操作
@RestController @RequestMapping("/server") public class ServerConfigController { @Value("${server.port}") private String serverPort; @RequestMapping("/query") public String findServerPort(){ try { Thread.sleep(10000); } catch (InterruptedException e) { e.printStackTrace(); } return serverPort; } }
降级处理
配置@HystrixCommand注解,定义降级处理方法
/** * 服务降级演示:是在服务熔断之后的兜底操作 */ @HystrixCommand( //超时时间的设置 commandProperties = { //设置请求的超时时间,一旦请求超过此时间那么都按照超时处理,默认超时时间是1S @HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "2000"), //统计窗口时间的设置 @HystrixProperty(name = "metrics.rollingStats.timeInMilliseconds",value = "8000"), //统计窗口内的最小请求数 @HystrixProperty(name = "circuitBreaker.requestVolumeThreshold",value = "2"), //统计窗口内错误请求阈值的设置 50% @HystrixProperty(name = "circuitBreaker.errorThresholdPercentage",value = "50"), //自我修复的活动窗口时间 @HystrixProperty(name = "circuitBreaker.sleepWindowInMilliseconds",value = "3000") },//设置回退方法 fallbackMethod = "getProductServerPortFallBack" ) @GetMapping("/loadProductServicePort3") public String getProductServerPort3() { return productFeign.getPort(); } /** * 定义回退方法,当请求出发熔断后执行,补救措施 * 注意: * 1.方法形参和原方法保持一致 * 2.方法的返回值与原方法保持一致 */ public String getProductServerPortFallBack(){ return "-1"; }
Hystrix舱壁模式
即:线程池隔离策略
如果不进行任何设置,所有熔断方法使用一个Hystrix线程池(10个线程),那么这样的话会导致问题,这个问题并不是扇出链路微服务不可用导致的,而是我们的线程机制导致的,如果方法A的请求把10个线程都用了,方法2请求处理的时候压根都没法去访问B,因为没有线程可用,并不是B服务不可用。
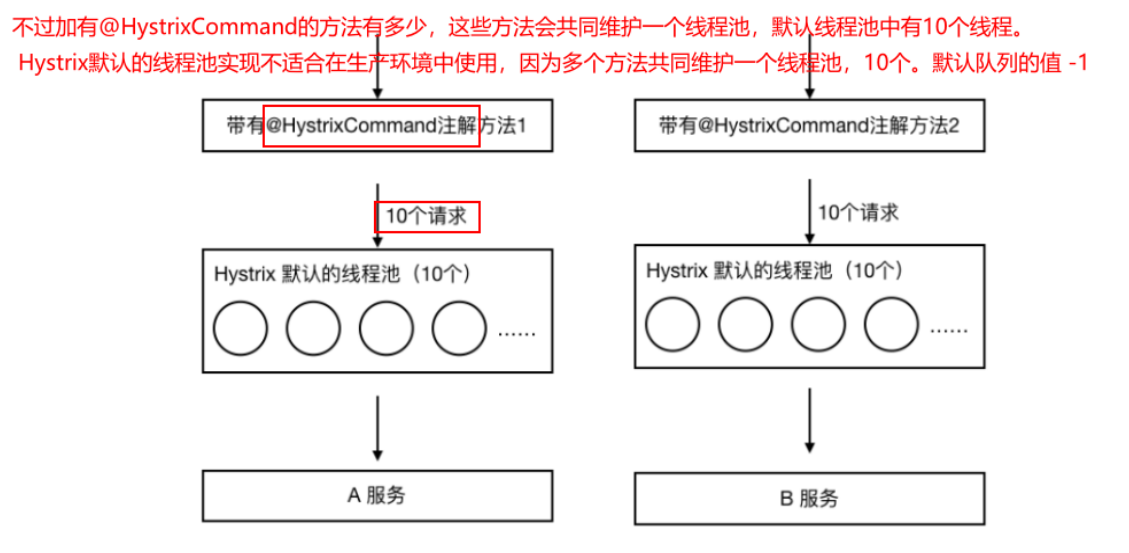
为了避免问题服务请求过多导致正常服务无法访问,Hystrix 不是采用增加线程数,而是单独的为每一个控制方法创建一个线程池的方式,这种模式叫做“舱壁模式",也是线程隔离的手段。
Hystrix工作流程与高级应用
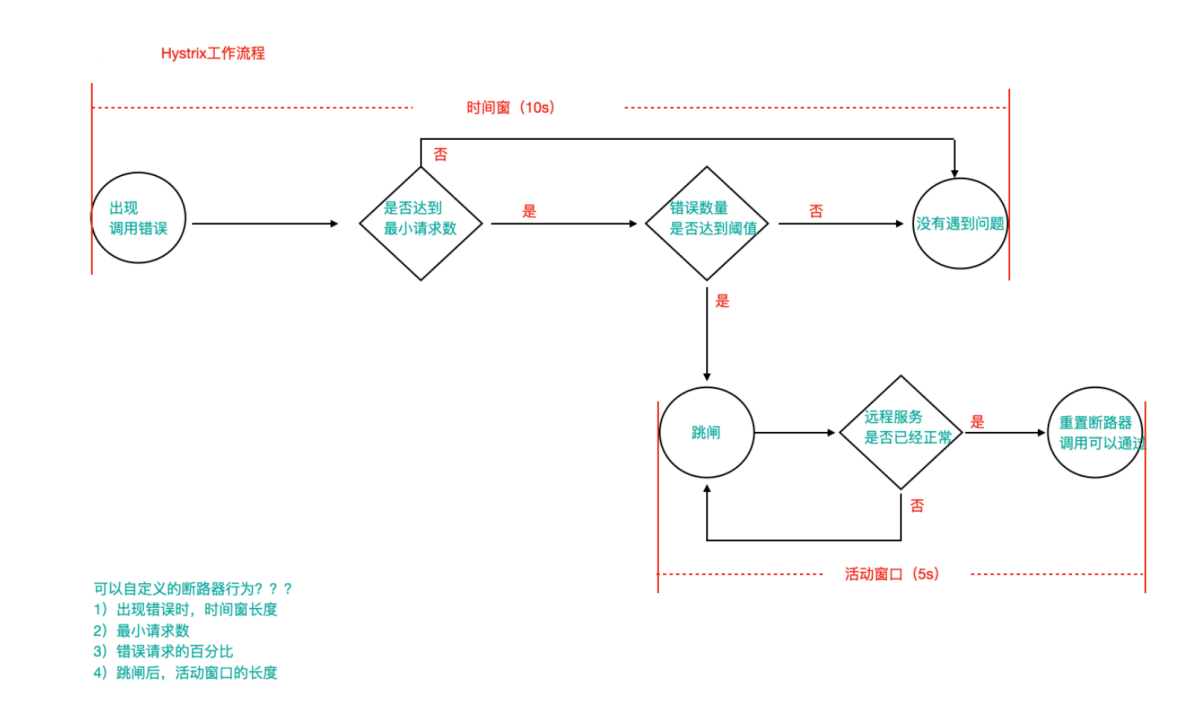
1)当调用出现问题时,开启一个时间窗(10s)
2)在这个时间窗内,统计调用次数是否达到最小请求数?
如果没有达到,则重置统计信息,回到第1步
如果达到了,则统计失败的请求数占所有请求数的百分比,是否达到阈值?
如果达到,则跳闸(不再请求对应服务)
如果没有达到,则重置统计信息,回到第1步
3)如果跳闸,则会开启一个活动窗口(默认5s),每隔5s,Hystrix会让一个请求通过,到达那个问题服务,看是否调用成功,如果成功,重置断路器回到第1步,如果失败,回到第3步
/** * 8秒钟内,请求次数达到2个,并且失败率在50%以上,就跳闸 * 跳闸后活动窗口设置为3s */ @HystrixCommand( commandProperties = { //统计窗口时间的设置 @HystrixProperty(name = "metrics.rollingStats.timeInMilliseconds",value = "8000"), //统计窗口内的最小请求数 @HystrixProperty(name = "circuitBreaker.requestVolumeThreshold",value = "2"), //统计窗口内错误请求阈值的设置 50% @HystrixProperty(name = "circuitBreaker.errorThresholdPercentage",value = "50"), //自我修复的活动窗口时间 @HystrixProperty(name = "circuitBreaker.sleepWindowInMilliseconds",value = "3000") } )
我们上述通过注解进行的配置也可以配置在配置文件中:
# 配置熔断策略: hystrix: command: default: circuitBreaker: # 强制打开熔断器,如果该属性设置为true,强制断路器进入打开状态,将会拒绝所有的请求。 默认false关闭的 forceOpen: false # 触发熔断错误比例阈值,默认值50% errorThresholdPercentage: 50 # 熔断后休眠时长,默认值5秒 sleepWindowInMilliseconds: 3000 # 熔断触发最小请求次数,默认值是20 requestVolumeThreshold: 2 execution: isolation: thread: # 熔断超时设置,默认为1秒 timeoutInMilliseconds: 5000
基于springboot的健康检查观察跳闸状态(自动投递微服务暴露健康检查细节)
# springboot中暴露健康检查等断点接口 management: endpoints: web: exposure: include: "*" endpoint: health: show-details: always
访问健康检查接口:http://localhost:9100/actuator/health
Hystrix 线程池队列配置案例:
有一次在生产环境,突然出现了很多笔还款单被挂起,后来排查原因,发现是内部系统调用时出现了Hystrix调用异常。在开发过程中,因为核心线程数设置的比较大,没有出现这种异常。放到了测试环境,偶尔有出现这种情况。
后来调整maxQueueSize属性,确实有所改善。可没想到在生产环境跑了一段时间后却又出现这种了情况,此时我第一想法就是去查看maxQueueSize属性,可是maxQueueSize属性是设置值了。
当时就比较纳闷了,为什么maxQueueSize属性不起作用,后来通过查看官方文档发现Hystrix还有一个queueSizeRejectionThreshold属性,这个属性是控制队列最大阈值的,而Hystrix默认只配置了5个,因此就算我们把maxQueueSize的值设置再大,也是不起作用的。两个属性必须同时配置
hystrix: threadpool: default: coreSize: 10 #并发执行的最大线程数,默认10 maxQueueSize: 1000 #BlockingQueue的最大队列数,默认值-1 queueSizeRejectionThreshold: 800 #即使maxQueueSize没有达到,达到queueSizeRejectionThreshold该值后,请求也会被拒绝,默认值5
Feign远程调用组件
Feign简介
Feign是Netflix开发的一个轻量级RESTful的HTTP服务客户端(用它来发起请求,远程调用的),是以Java接口注解的方式调用Http请求,而不用像Java中通过封装HTTP请求报文的方式直接调用,Feign被广泛应用在Spring Cloud 的解决方案中。
类似于Dubbo,服务消费者拿到服务提供者的接口,然后像调用本地接口方法一样去调用,实际发出的是远程的请求。
Feign可帮助我们更加便捷,优雅的调用HTTP API:不需要我们去拼接url然后呢调用restTemplate的api,在SpringCloud中,使用Feign非常简单,创建一个接口(在消费者--服务调用方这一端),并在接口上添加一些注解,代码就完成了
SpringCloud对Feign进行了增强,使Feign支持了SpringMVC注解(OpenFeign)
本质:封装了Http调用流程,更符合面向接口化的编程习惯,类似于Dubbo的服务调用
Feign配置应用
在服务调用者工程(消费)创建接口(添加注解)
(效果)Feign = RestTemplate+Ribbon+Hystrix
服务消费者工程(页面静态化微服务)中引入Feign依赖(或者父类工程)
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId> </dependency>
服务消费者工程(静态化微服务)启动类使用注解@EnableFeignClients添加Feign支持
@SpringBootApplication @EnableDiscoveryClient // 开启服务发现 @EnableFeignClients // 开启Feign public class PageApplication { public static void main(String[] args) { SpringApplication.run(PageApplication.class,args); } }
注意:此时去掉Hystrix熔断的支持注解@EnableCircuitBreaker即可包括引入的依赖,因为Feign会自动引入
在消费者微服务中创建Feign接口
/** * 自定义Fegin接口,调用Product微服务的所有接口方法都在此进行定义 */ @FeignClient(name = "lagou-service-product") public interface ProductFeign { /** * 通过商品id查询商品对象 * @param id * @return */ @GetMapping("/product/query/{id}") public Products queryById(@PathVariable Integer id); @GetMapping("/service/port") public String getPort(); }
1)@FeignClient注解的name属性用于指定要调用的服务提供者名称,和服务提供者yml文件中spring.application.name保持一致
2)接口中的接口方法,就好比是远程服务提供者Controller中的Hander方法(只不过如同本地调用了),那么在进行参数绑定的时,可以使用@PathVariable、@RequestParam、@RequestHeader等,这也是OpenFeign对SpringMVC注解的支持,但是需要注意value必须设置,否则会抛出异常
3) @FeignClient(name = "lagou-service-product"),name在消费者微服务中只能出现一次。(升级Spring Boot 2.1.0 Spring Cloud Greenwich.M1 版本后,在2个Feign接口类内定义相同的名字, @FeignClient(name = 相同的名字 就会出现报错,在之前的版本不会提示报错),所以最好将调用一个微服务的信息都定义在一个Feign接口中。
改造PageController中原有的调用方式
@RestController @RequestMapping("/page") public class PageController { @Autowired private ProductFeign productFeign; @RequestMapping("/getData/{id}") public Products findDataById(@PathVariable Integer id) { return productFeign.query(id); } @RequestMapping("/getPort") public String getProductServerPort() { return productFeign.findServerPort(); } }
Feign对负载均衡的支持
Feign 本身已经集成了Ribbon依赖和自动配置,因此我们不需要额外引入依赖,可以通过ribbon.xx 来进 行全局配置,也可以通过服务名.ribbon.xx 来对指定服务进行细节配置配置(参考之前,此处略)
Feign默认的请求处理超时时长1s,有时候我们的业务确实执行的需要一定时间,那么这个时候,我们就需要调整请求处理超时时长,Feign自己有超时设置,如果配置Ribbon的超时,则会以Ribbon的为准
#针对的被调用方微服务名称,不加就是全局生效 lagou-service-product: ribbon: #请求连接超时时间 ConnectTimeout: 2000 #请求处理超时时间 ReadTimeout: 15000 #对所有操作都进行重试 OkToRetryOnAllOperations: true ####根据如上配置,当访问到故障请求的时候,它会再尝试访问一次当前实例(次数由MaxAutoRetries配置), ####如果不行,就换一个实例进行访问,如果还不行,再换一次实例访问(更换次数由MaxAutoRetriesNextServer配置), ####如果依然不行,返回失败信息。 MaxAutoRetries: 0 #对当前选中实例重试次数,不包括第一次调用 MaxAutoRetriesNextServer: 0 #切换实例的重试次数 NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule #负载策略调整
Feign对熔断器的支持
1)在Feign客户端工程配置文件(application.yml)中开启Feign对熔断器的支持
# 开启Feign的熔断功能 feign: hystrix: enabled: true
Feign的超时时长设置那其实就上面Ribbon的超时时长设置
Hystrix超时设置(就按照之前Hystrix设置的方式就OK了)
注意:
1)开启Hystrix之后,Feign中的方法都会被进行一个管理了,一旦出现问题就进入对应的回退逻辑处理
2)针对超时这一点,当前有两个超时时间设置(Feign/hystrix),熔断的时候是根据这两个时间的最小值来进行的,即处理时长超过最短的那个超时时间了就熔断进入回退降级逻辑
# 配置熔断策略: hystrix: threadpool: default: coreSize: 16 #并发执行的最大线程数 maxQueueSize: 10000 #BlockingQueue的最大队列数,默认值-1 queueSizeRejectionThreshold: 6000 # 队列拒绝阈值, 即使maxQueueSize没有达到,达到queueSizeRejectionThreshold该值后,请求也会被拒绝,默认值5 command: default: circuitBreaker: # 强制打开熔断器,如果该属性设置为true,强制断路器进入打开状态,将会拒绝所有的请求。 默认false关闭的 forceOpen: false # 触发熔断错误比例阈值,默认值50% errorThresholdPercentage: 50 # 熔断后休眠时长,默认值5秒 sleepWindowInMilliseconds: 3000 # 熔断触发最小请求次数,默认值是20 requestVolumeThreshold: 2 execution: isolation: thread: # 熔断超时设置,默认为1秒 timeoutInMilliseconds: 5000
2)自定义FallBack处理类(需要实现FeignClient接口)
package com.lagou.page.feign.fallback; import com.lagou.common.pojo.Products; import com.lagou.page.feign.ProductFeign; import org.springframework.stereotype.Component; @Component public class ProductFeignFallBack implements ProductFeign { @Override public Products query(Integer id) { return null; } @Override public String findServerPort() { return "-1"; } }
@FeignClient(name = "lagou-service-product",fallback = ProductFeignFallBack.class) public interface ProductFeign { /** * 通过商品id查询商品对象 * @param id * @return */ @GetMapping("/product/query/{id}") public Products queryById(@PathVariable Integer id); @GetMapping("/service/port") public String getPort(); }
Feign对请求压缩和响应压缩的支持
Feign 支持对请求和响应进行GZIP压缩,以减少通信过程中的性能损耗。通过下面的参数 即可开启请求与响应的压缩功能:
#开启Feign对熔断器支持 feign: hystrix: enabled: true #开启请求和响应的压缩设置,默认是不开启的 compression: request: enabled: true mime-types: text/xml,application/xml,application/json #默认值 min-request-size: 2048 response: enabled: true
GateWay网关组件
网关:微服务架构中的重要组成部分
局域网中就有网关这个概念,局域网接收或者发送数据出去通过这个网关,比如用Vmware虚拟机软件搭建虚拟机集群的时候,往往我们需要选择IP段中的一个IP作为网关地址。
我们学习的GateWay-->Spring Cloud GateWay(它只是众多网关解决方案中的一种)
GateWay简介
Spring Cloud GateWay是Spring Cloud的一个全新项目,目标是取代Netflix Zuul,它基于Spring5.0+SpringBoot2.0+WebFlux(基于高性能的Reactor模式响应式通信框架Netty,异步非阻塞模型)等技术开发,性能高于Zuul,官方测试,GateWay是Zuul的1.6倍,旨在为微服务架构提供一种简单有效的统一的API路由管理方式。
Spring Cloud GateWay不仅提供统一的路由方式(反向代理)并且基于 Filter(定义过滤器对请求过滤,完成一些功能) 链的方式提供了网关基本的功能,例如:鉴权、流量控制、熔断、路径重写、日志监控等。
网关在架构中的位置
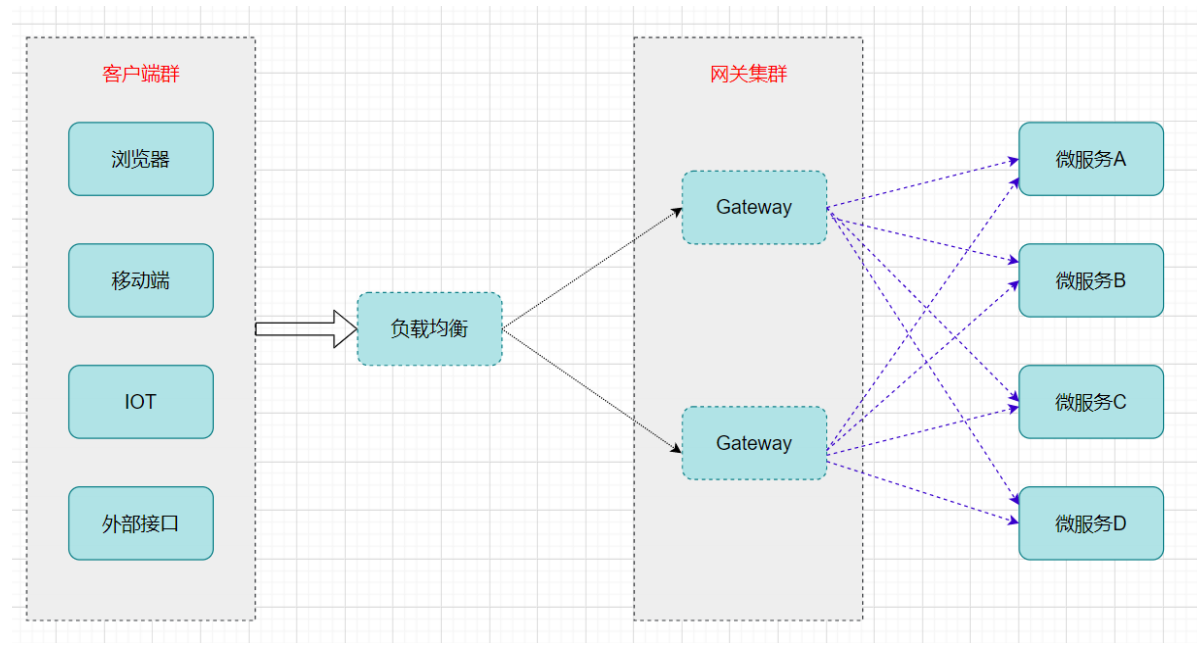
GateWay核心概念
Spring Cloud GateWay天生就是异步非阻塞的,基于Reactor模型(同步非阻塞的I/O多路复用机制)
一个请求—>网关根据一定的条件匹配—匹配成功之后可以将请求转发到指定的服务地址;而在这个过程中,我们可以进行一些比较具体的控制(限流、日志、黑白名单)
- 路由(route): 网关最基础的部分,也是网关比较基础的工作单元。路由由一个ID、一个目标URL(最终路由到的地址)、一系列的断言(匹配条件判断)和Filter过滤器(精细化控制)组成。如果断言为true,则匹配该路由。
- 断言(predicates):参考了Java8中的断言java.util.function.Predicate,开发人员可以匹配Http请求中的所有内容(包括请求头、请求参数等)(类似于nginx中的location匹配一样),如果断言与请求相匹配则路由。
- 过滤器(filter):一个标准的Spring webFilter,使用过滤器,可以在请求之前或者之后执行业务逻辑。
GateWay如何工作
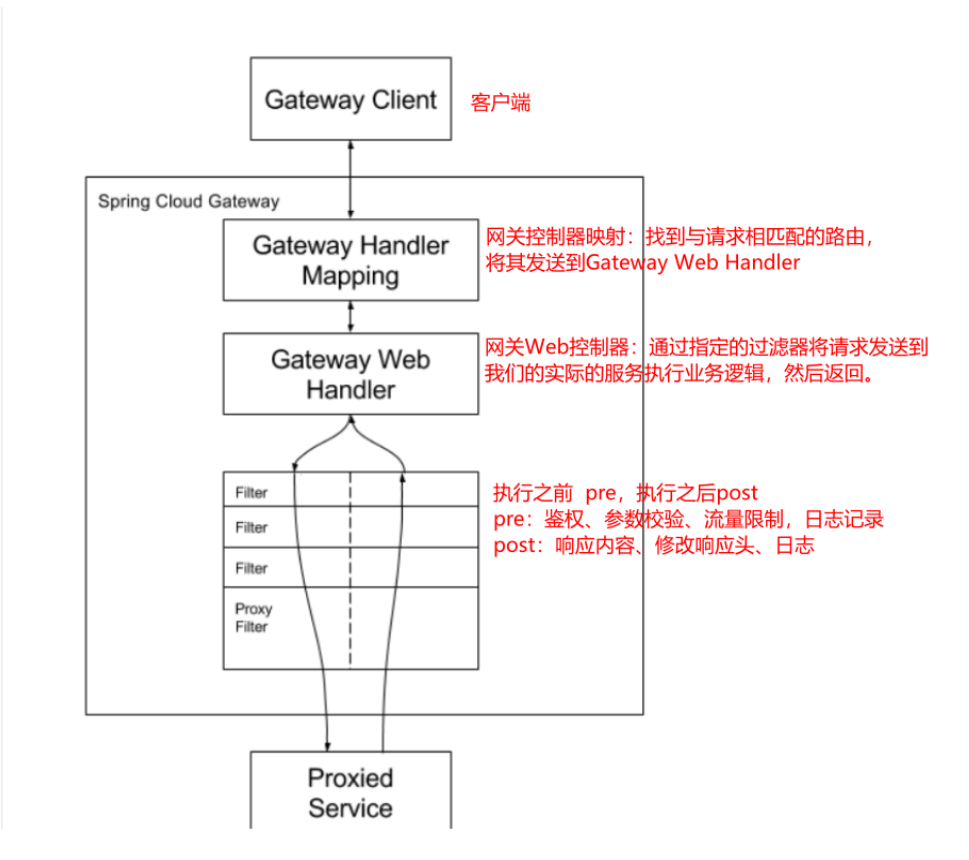
Spring 官方介绍:
客户端向Spring Cloud GateWay发出请求,然后在GateWay Handler Mapping中找到与请求相匹配的路由,将其发送到GateWay Web Handler;Handler再通过指定的过滤器链来将请求发送到我们实际的服务执行业务逻辑,然后返回。过滤器之间用虚线分开是因为过滤器可能会在发送代理请求之前(pre)或者之后(post)执行业务逻辑。
Filter在“pre”类型过滤器中可以做参数校验、权限校验、流量监控、日志输出、协议转换等,在“post”类型的过滤器中可以做响应内容、响应头的修改、日志的输出、流量监控等。
GateWay应用
使用网关对静态化微服务进行代理(添加在它的上游,相当于隐藏了具体微服务的信息,对外暴露的是网关)
创建工程lagou-cloud-gateway-server导入依赖
GateWay不需要使用web模块,它引入的是WebFlux(类似于SpringMVC)
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.zhf</groupId> <artifactId>lagou-cloud-gateway</artifactId> <version>1.0-SNAPSHOT</version> <!--spring boot 父启动器依赖--> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.1.6.RELEASE</version> </parent> <dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-commons</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-eureka-client</artifactId> </dependency> <!--GateWay 网关--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-gateway</artifactId> </dependency> <!--引入webflux--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-webflux</artifactId> </dependency> <!--日志依赖--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-logging</artifactId> </dependency> <!--测试依赖--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <!--lombok工具--> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.4</version> <scope>provided</scope> </dependency> <!--引入Jaxb,开始--> <dependency> <groupId>com.sun.xml.bind</groupId> <artifactId>jaxb-core</artifactId> <version>2.2.11</version> </dependency> <dependency> <groupId>javax.xml.bind</groupId> <artifactId>jaxb-api</artifactId> </dependency> <dependency> <groupId>com.sun.xml.bind</groupId> <artifactId>jaxb-impl</artifactId> <version>2.2.11</version> </dependency> <dependency> <groupId>org.glassfish.jaxb</groupId> <artifactId>jaxb-runtime</artifactId> <version>2.2.10-b140310.1920</version> </dependency> <dependency> <groupId>javax.activation</groupId> <artifactId>activation</artifactId> <version>1.1.1</version> </dependency> <!--引入Jaxb,结束--> <!-- Actuator可以帮助你监控和管理Spring Boot应用--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency> <!--热部署--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-devtools</artifactId> <optional>true</optional> </dependency> <!--链路追踪--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-sleuth</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency> </dependencies> <dependencyManagement> <!--spring cloud依赖版本管理--> <dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-dependencies</artifactId> <version>Greenwich.RELEASE</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <build> <plugins> <!--编译插件--> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <configuration> <source>11</source> <target>11</target> <encoding>utf-8</encoding> </configuration> </plugin> <!--打包插件--> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build> </project>
注意:不要引入starter-web模块,需要引入web-flux
application.yml 配置文件内容
server: port: 9000 eureka: client: serviceUrl: # eureka server的路径 defaultZone: http://LagouCloudEurekaServerA:9300/eureka,http://LagouCloudEurekaServerB:9301/eureka instance: prefer-ip-address: true instance-id: ${spring.cloud.client.ip-address}:${spring.application.name}:${server.port}:@project.version@ spring: application: name: lagou-cloud-gateway #网关的配置 cloud: gateway: routes: #配置路由 - id: service-order-router #动态路由:从注册中心获取对应服务的实例 uri: lb://lagou-service-order predicates: - Path=/order/** - id: service-goods-router uri: lb://lagou-service-goods predicates: - Path=/product/**
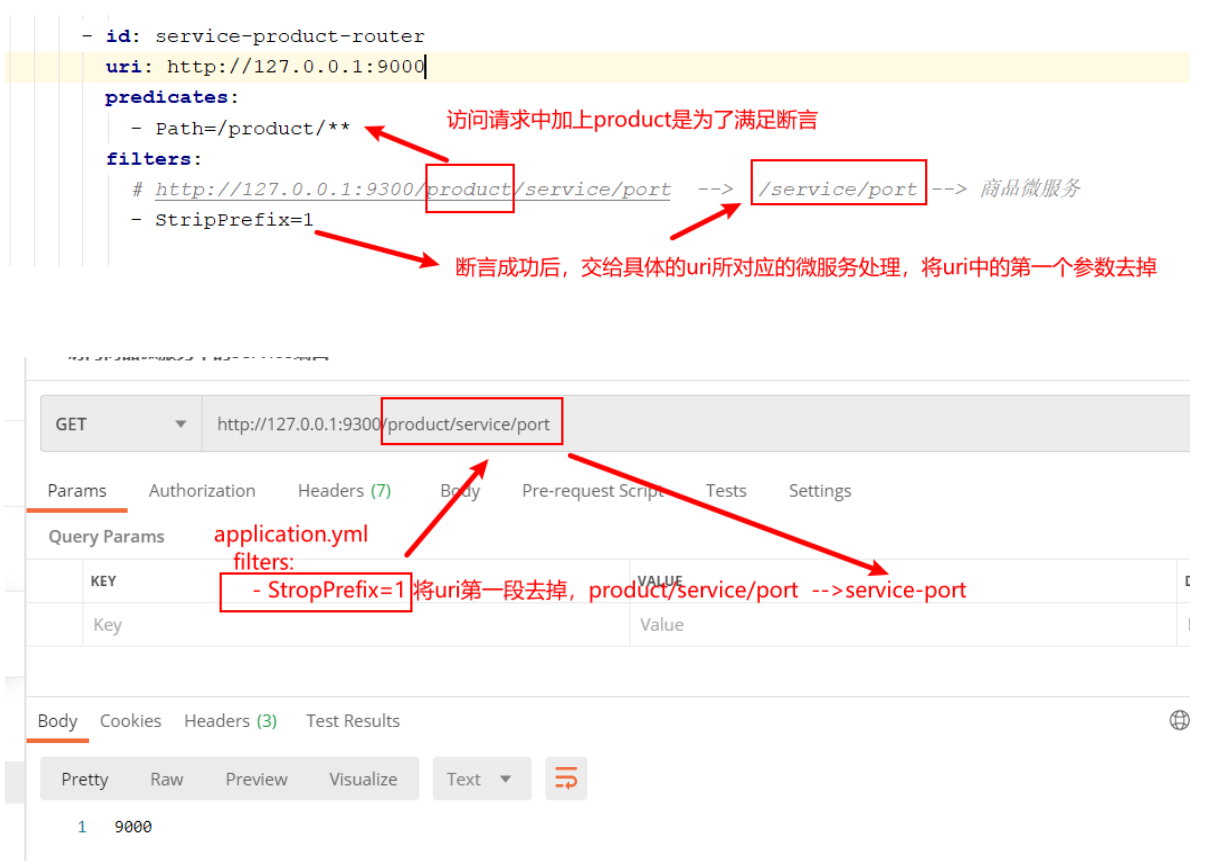
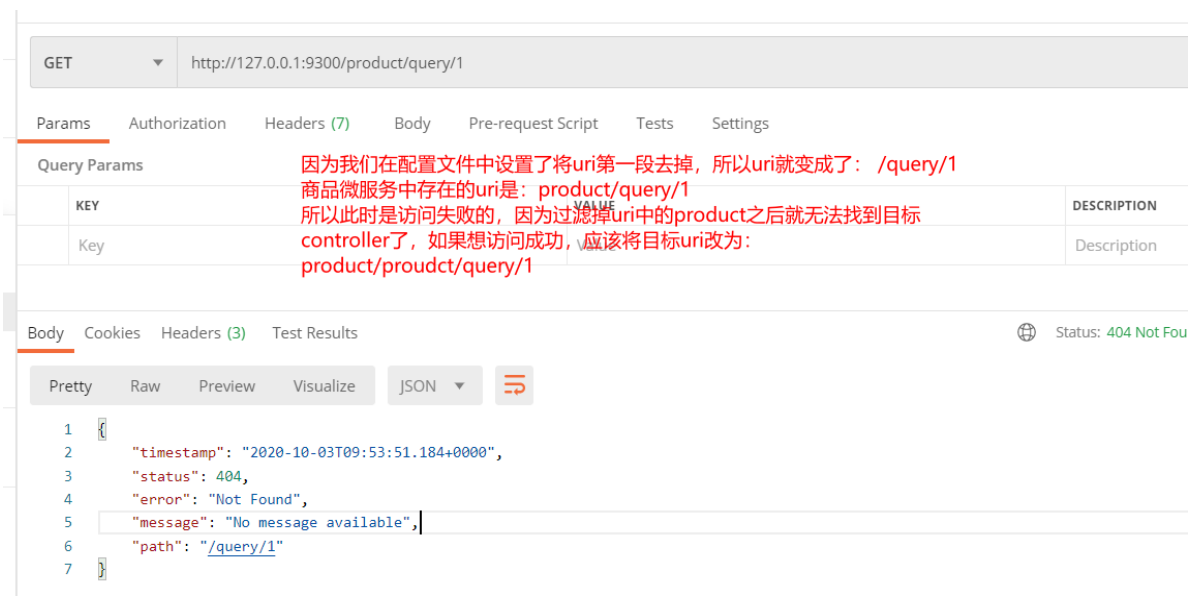
启动类
package com.lagou.gateway; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cloud.client.discovery.EnableDiscoveryClient; @SpringBootApplication @EnableDiscoveryClient public class GateWayServerApplication { public static void main(String[] args) { SpringApplication.run(GateWayServerApplication.class, args); } }
GateWay路由规则详解
Spring Cloud GateWay 帮我们内置了很多 Predicates功能,实现了各种路由匹配规则(通过Header、请求参数等作为条件)匹配到对应的路由。
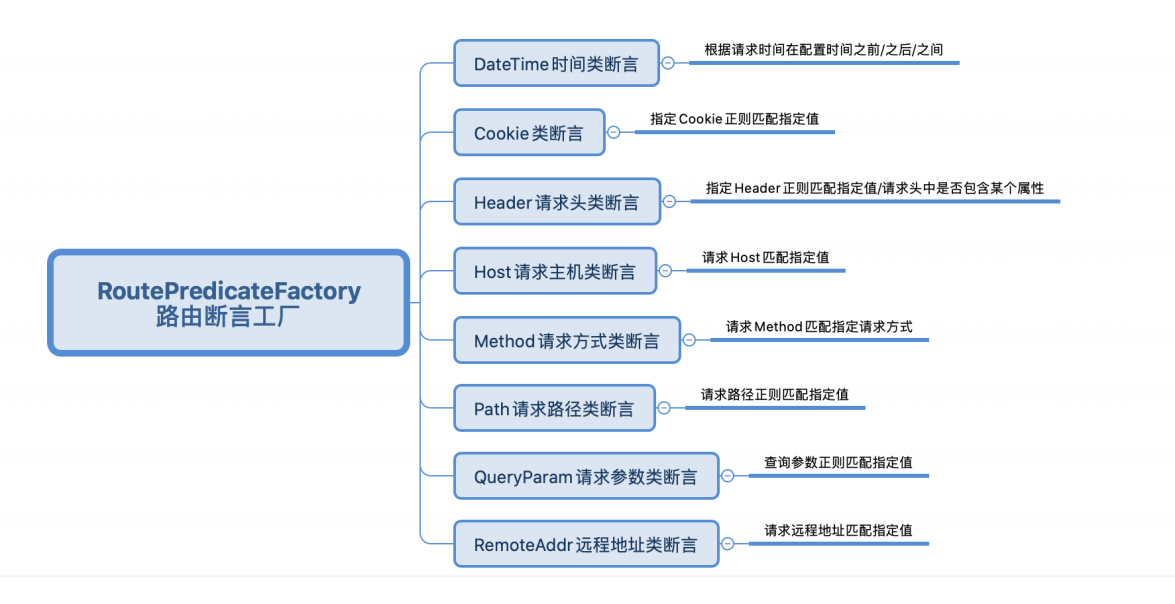
时间点后匹配
spring: cloud: gateway: routes: - id: after_route uri: https://example.org predicates: - After=2017-01-20T17:42:47.789-07:00[America/Denver]
时间点前匹配
spring: cloud: gateway: routes: - id: after_route uri: https://example.org predicates: - Before=2017-01-20T17:42:47.789-07:00[America/Denver]
时间区间匹配
spring: cloud: gateway: routes: - id: after_route uri: https://example.org predicates: - Between=2017-01-20T17:42:47.789-07:00[America/Denver], 2017-01-21T17:42:47.789-07:00[America/Denver]
指定Cookie正则匹配指定值
spring: cloud: gateway: routes: - id: after_route uri: https://example.org predicates: - Cookie=chocolate, ch.p
指定Header正则匹配指定值
spring: cloud: gateway: routes: - id: after_route uri: https://example.org predicates: - Header=X-Request-Id, \d+
请求Host匹配指定值
spring: cloud: gateway: routes: - id: after_route uri: https://example.org predicates: - Host=**.somehost.org,**.anotherhost.org
请求Method匹配指定请求方式
spring: cloud: gateway: routes: - id: after_route uri: https://example.org predicates: - Method=GET,POST
请求路径正则匹配
spring: cloud: gateway: routes: - id: after_route uri: https://example.org predicates: - Path=/red/{segment},/blue/{segment}
请求包含某参数
spring: cloud: gateway: routes: - id: after_route uri: https://example.org predicates: - Query=green
请求包含某参数并且参数值匹配正则表达式
spring: cloud: gateway: routes: - id: after_route uri: https://example.org predicates: - Query=red, gree.
远程地址匹配
spring: cloud: gateway: routes: - id: after_route uri: https://example.org predicates: - RemoteAddr=192.168.1.1/24
GateWay动态路由详解
GateWay支持自动从注册中心中获取服务列表并访问,即所谓的动态路由
实现步骤如下
1)pom.xml中添加注册中心客户端依赖(因为要获取注册中心服务列表,eureka客户端已经引入)
2)动态路由配置

注意:动态路由设置时,uri以 lb: //开头(lb代表从注册中心获取服务),后面是需要转发到的服务名称
GateWay过滤器
GateWay过滤器简介
从过滤器生命周期(影响时机点)的角度来说,主要有两个pre和post:
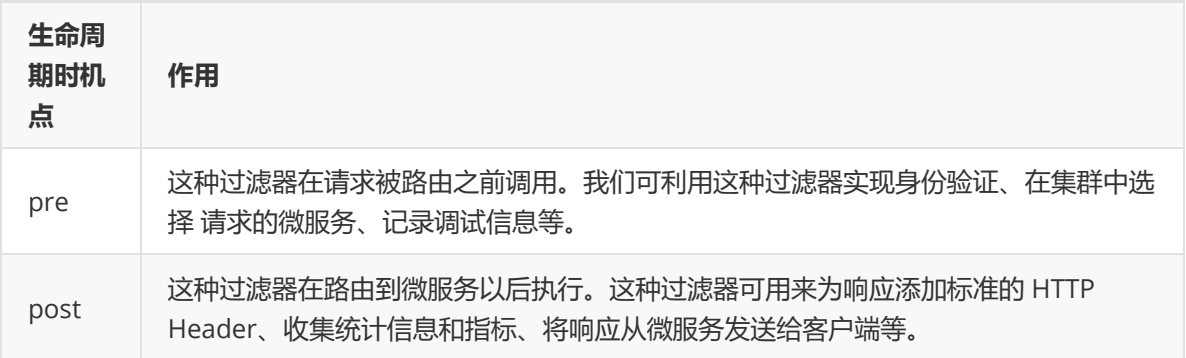
从过滤器类型的角度,Spring Cloud GateWay的过滤器分为GateWayFilter和GlobalFilter两种

如Gateway Filter可以去掉url中的占位后转发路由,比如
predicates: - Path=/product/** filters: - StripPrefix=1 # 可以去掉product之后转发
注意:GlobalFilter全局过滤器是程序员使用比较多的过滤器,我们主要讲解这种类型
自定义全局过滤器实现IP访问限制(黑白名单)
请求过来时,判断发送请求的客户端的ip,如果在黑名单中,拒绝访问
自定义GateWay全局过滤器时,我们实现Global Filter接口即可,通过全局过滤器可以实现黑白名单、限流等功能。
package com.lagou.gateway.filter; import org.springframework.cloud.gateway.filter.GatewayFilterChain; import org.springframework.cloud.gateway.filter.GlobalFilter; import org.springframework.core.Ordered; import org.springframework.core.io.buffer.DataBuffer; import org.springframework.http.HttpStatus; import org.springframework.http.server.reactive.ServerHttpRequest; import org.springframework.http.server.reactive.ServerHttpResponse; import org.springframework.stereotype.Component; import org.springframework.web.server.ServerWebExchange; import reactor.core.publisher.Mono; import java.util.ArrayList; import java.util.List; /** * 通常情况下进行网关自定义过滤器时,需要实现两个接口:GlobalFilter,Ordered(指定过滤器的执行顺序) */ @Component public class BlackListFilter implements GlobalFilter, Ordered { /** * 加载黑名单列表 * MySQL -> Redis -> 加载到内存中 */ private static List<String> blackList = new ArrayList<>(); static { //将本机地址加入到黑名单中 blackList.add("127.0.0.1"); } /** * GlobalFilter,过滤器的核心逻辑 * @param exchange :封装了request和response上下文 * @param chain :网关过滤器链 * @return */ @Override public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) { //获取请求和响应对象 ServerHttpRequest request = exchange.getRequest(); ServerHttpResponse response = exchange.getResponse(); //获取来访者的IP地址 String clientIP = request.getRemoteAddress().getHostString(); //判断是否在黑名单中 if(blackList.contains(clientIP)){//如果是黑名单 //拒绝访问 response.setStatusCode(HttpStatus.UNAUTHORIZED);//没有授权 String data = "request be denied"; DataBuffer wrap = response.bufferFactory().wrap(data.getBytes()); return response.writeWith(Mono.just(wrap)); } return chain.filter(exchange); } /** * Ordered,定义过滤的顺序,getOrder()返回值的大小决定了过滤器执行的优先级,越小优先级越高 * @return */ @Override public int getOrder() { return 0; } }
GateWay高可用
网关作为非常核心的一个部件,如果挂掉,那么所有请求都可能无法路由处理,因此我们需要做GateWay的高可用。
GateWay的高可用很简单:可以启动多个GateWay实例来实现高可用,在GateWay的上游使用Nginx等负载均衡设备进行负载转发以达到高可用的目的。
启动多个GateWay实例(假如说两个,一个端口9002,一个端口9003),剩下的就是使用Nginx等完成负载代理即可。示例如下:
#配置多个GateWay实例 upstream gateway { server 127.0.0.1:9002; server 127.0.0.1:9003; } location / { proxy_pass http://gateway; }
Spring Cloud Config 分布式配置中心
分布式配置中心应用场景
往往,我们使用配置文件管理一些配置信息,比如application.yml
单体应用架构,配置信息的管理、维护并不会显得特别麻烦,手动操作就可以,因为就一个工程;
微服务架构,因为我们的分布式集群环境中可能有很多个微服务,我们不可能一个一个去修改配置然后重启生效,在一定场景下我们还需要在运行期间动态调整配置信息,比如:根据各个微服务的负载情况,动态调整数据源连接池大小,我们希望配置内容发生变化的时候,微服务可以自动更新。
场景总结如下:
1)集中配置管理,一个微服务架构中可能有成百上千个微服务,所以集中配置管理是很重要的(一次修改、到处生效)
2)不同环境不同配置,比如数据源配置在不同环境(开发dev,测试test,生产prod)中是不同的
3)运行期间可动态调整。例如,可根据各个微服务的负载情况,动态调整数据源连接池大小等配置修改后可自动更新
4)如配置内容发生变化,微服务可以自动更新配置
那么,我们就需要对配置文件进行集中式管理,这也是分布式配置中心的作用。
Spring Cloud Config
Config简介
Spring Cloud Config是一个分布式配置管理方案,包含了 Server端和 Client端两个部分。
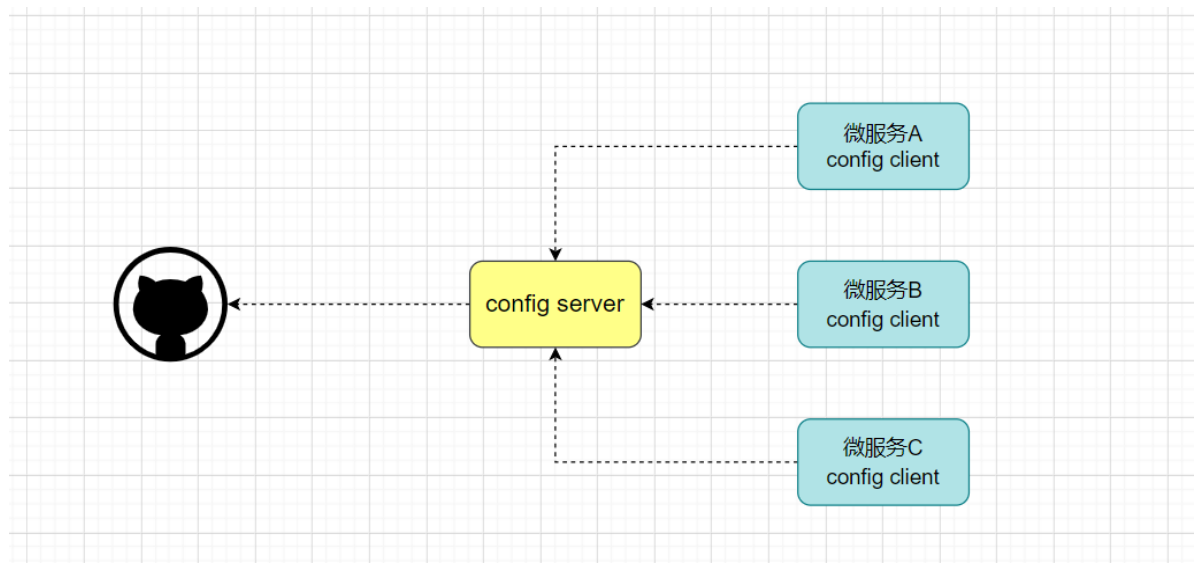
Server 端:提供配置文件的存储、以接口的形式将配置文件的内容提供出去,通过使用@EnableConfigServer注解在 Spring boot 应用中非常简单的嵌入
Client 端:通过接口获取配置数据并初始化自己的应用
Config分布式配置应用
说明:Config Server是集中式的配置服务,用于集中管理应用程序各个环境下的配置。 默认使用Git存储配置文件内容,也可以SVN。
比如,我们要对“静态化微服务或者商品微服务”的application.yml进行管理(区分开发环境(dev)、测试环境(test)、生产环境(prod))
1)登录GitHub,创建项目lagou-config
2)上传yml配置文件,命名规则如下:
{application}-{profile}.yml 或者 {application}-{profile}.properties
其中,application为应用名称,profile指的是环境(用于区分开发环境,测试环境、生产环境等)
示例:lagou-service-page-dev.yml、lagou-service-page-test.yml、lagou-service-pageprod.yml
3)构建Config Server统一配置中心
新建SpringBoot工程,引入依赖坐标(需要注册自己到Eureka)
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <parent> <artifactId>lagou-parent</artifactId> <groupId>com.zhf</groupId> <version>1.0-SNAPSHOT</version> </parent> <modelVersion>4.0.0</modelVersion> <artifactId>lagou-cloud-config</artifactId> <dependencies> <!--eureka client 客户端依赖引入--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-eureka-client</artifactId> </dependency> <!--config配置中心服务端--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-config-server</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-bus-amqp</artifactId> </dependency> </dependencies> </project>
配置启动类,使用注解@EnableConfigServer开启配置中心服务器功能
package com.lagou.config; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cloud.client.discovery.EnableDiscoveryClient; import org.springframework.cloud.config.server.EnableConfigServer; @SpringBootApplication @EnableDiscoveryClient @EnableConfigServer //开启配置服务器功能 public class ConfigServerApplication { public static void main(String[] args) { SpringApplication.run(ConfigServerApplication.class,args); } }
application.yml配置
server: port: 9400 #注册到Eureka服务中心 eureka: client: service-url: defaultZone: http://LagouCloudEurekaServerA:9300/eureka,http://LagouCloudEurekaServerB:9301/eureka instance: prefer-ip-address: true instance-id: ${spring.cloud.client.ip-address}:${spring.application.name}:${server.port}:@project.version@ spring: application: name: lagou-cloud-config cloud: config: server: #git配置:uri、用户名、密码、分支.... git: uri: https://github.com/zhf19970510/lagouSpringCloudConfig.git #配置git地址 username: jetwu-do password: wu7787879 search-paths: - lagouSpringCloudConfig label: main
测试
http://127.0.0.1:9600/master/application-dev.yml
master:分支名称
application-dev.yml:文件名称
4)构建Client客户端(在已有页面静态化微服务基础上)
案例实现:在lagou-service-page微服务中动态获取config server的配置信息
已有工程中添加依赖坐标
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-config-client</artifactId> </dependency>
application.yml修改为bootstrap.yml配置文件
bootstrap.yml是系统级别的,优先级比application.yml高,应用启动时会检查这个配置文件,在这个配置文件中指定配置中心的服务地址,会自动拉取所有应用配置并且启用。
(主要是把与统一配置中心连接的配置信息放到bootstrap.yml)
注意:需要统一读取的配置信息,从配置中心获取
bootstrap.yml(部分)
server: port: 9101 #微服务的集群环境中,通常会为每一个微服务叠加。 spring: application: name: lagou-service-order datasource: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:3306/springcloud_lagou?useUnicode=true&characterEncoding=utf8&serverTimezone=UTC username: root password: 123456 cloud: config: # #config客户端配置,和ConfigServer通信,并告知ConfigServer希望获取的配置信息在哪个文件中 name: application # application-dev.yml profile: dev # profile的值 label: main uri: http://localhost:9400 # config server
ConfigController
package com.lagou.page.controller; import org.springframework.beans.factory.annotation.Value; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; @RestController @RequestMapping("/config") public class ConfigClientController { @Value("${mysql.user}") private String mysqlUser; @Value("${person.name}") private String personName; @RequestMapping("/remote") public String findRemoteConfig() { return mysqlUser + " " + personName; } }
启动日志:
测试:
http://127.0.0.1:9100/config/remote
Config配置手动刷新
不用重启微服务,只需要手动的做一些其他的操作(访问一个地址/refresh)刷新,之后再访问即可
此时,客户端取到了配置中心的值,但当我们修改GitHub上面的值时,服务端(Config Server)能实时获取最新的值,但客户端(Config Client)读的是缓存,无法实时获取最新值。Spring Cloud已 经为我们解决了这个问题,那就是客户端使用post去触发refresh,获取最新数据。
1)Client客户端添加依赖springboot-starter-actuator(已添加)
2)Client客户端bootstrap.yml中添加配置(暴露通信端点)
management: endpoints: web: exposure: include: refresh #也可以暴露所有的端口 management: endpoints: web: exposure: include: "*"
3)Client客户端使用到配置信息的类上添加@RefreshScope
package com.lagou.page.controller; import org.springframework.beans.factory.annotation.Value; import org.springframework.cloud.context.config.annotation.RefreshScope; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; @RestController @RequestMapping("/config") @RefreshScope //手动刷新 public class ConfigClientController { @Value("${mysql.user}") private String mysqlUser; @Value("${person.name}") private String personName; @RequestMapping("/remote") public String findRemoteConfig() { return mysqlUser + " " + personName; } }
4)手动向Client客户端发起POST请求,http://localhost:9100/actuator/refresh,刷新配置信息
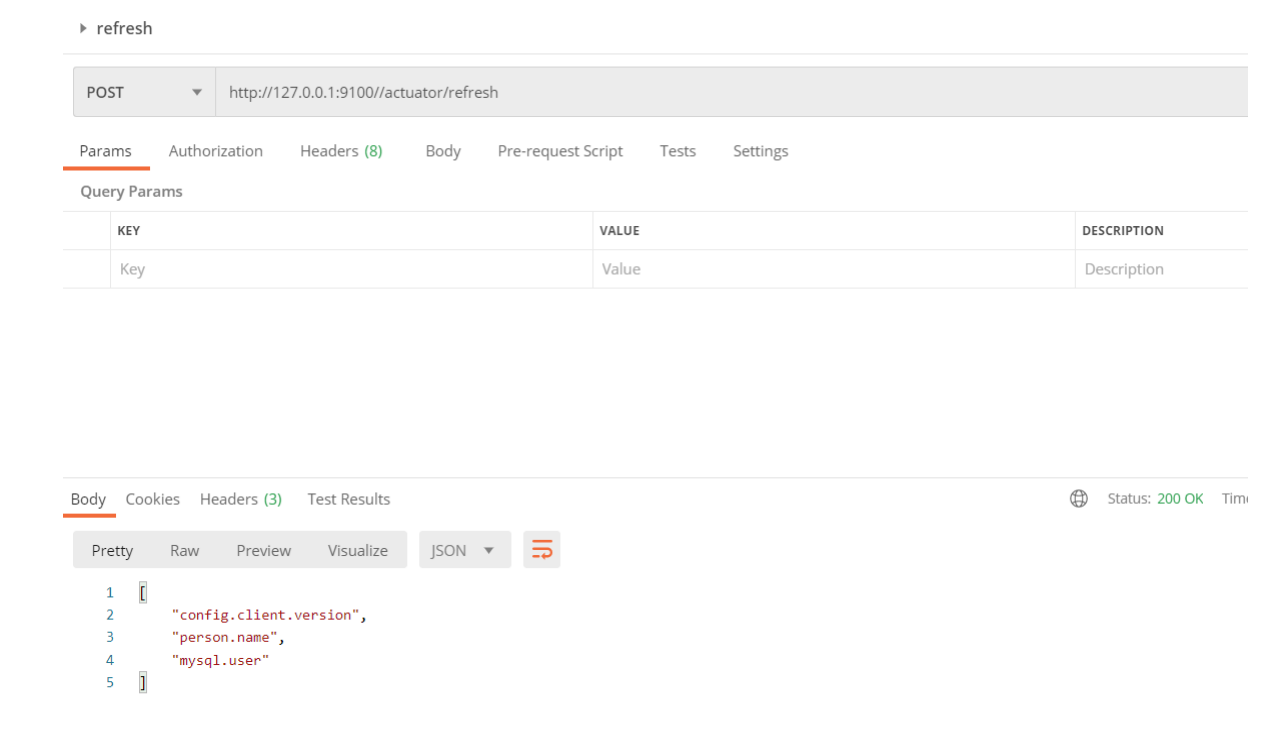
注意:手动刷新方式避免了服务重启
思考:可否使用广播机制,一次通知,处处生效,方便大范围配置自动刷新?
Config配置自动更新
实现一次通知,处处生效
在微服务架构中,我们可以结合消息总线(Bus)实现分布式配置的自动更新(Spring Cloud、Config + Spring Cloud Bus)、
消息总线Bus
在微服务架构中,我们可以结合消息总线(Bus)实现分布式配置的自动更新(Spring Cloud、Config + Spring Cloud Bus)、所谓消息总线Bus,即我们经常会使用MQ消息代理构建一个共用的Topic,通过这个Topic连接各个、微服务实例,MQ广播的消息会被所有在注册中心的微服务实例监听和消费。换言之就是通过一个主题连接各个微服务,打通脉络。
Spring Cloud Bus(基于MQ的,支持RabbitMq/Kafka) 是Spring Cloud中的消息总线方案,Spring Cloud Config + Spring Cloud Bus 结合可以实现配置信息的自动更新。
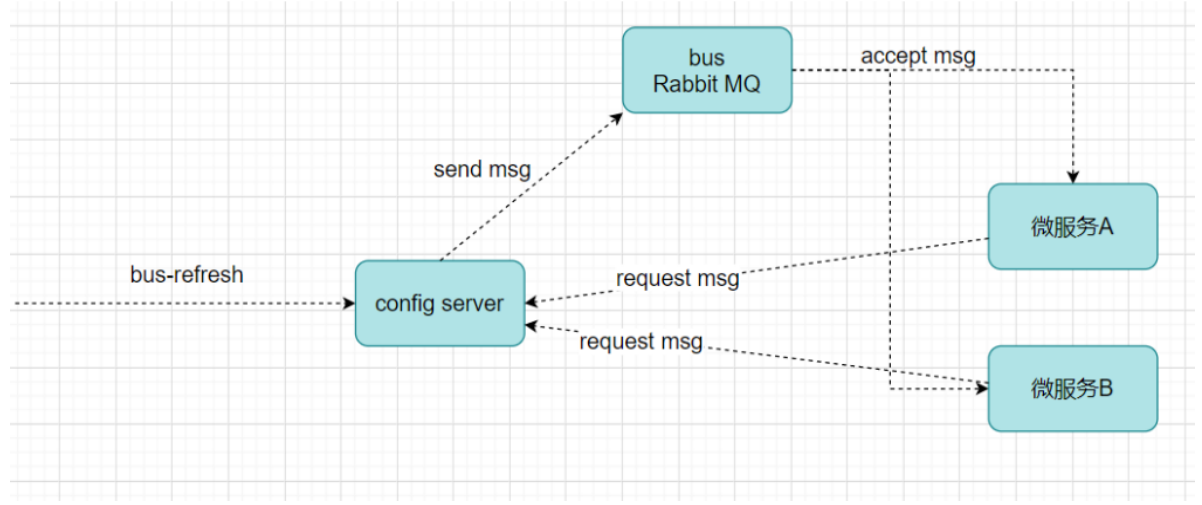
Spring Cloud Config + Spring Cloud Bus 实现自动刷新
MQ消息代理,我们还选择使用RabbitMQ,ConfigServer和ConfigClient都添加都消息总线的支持以及与RabbitMq的连接信息
1)Config Server服务端和客户端添加消息总线支持
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-bus-amqp</artifactId> </dependency>
2)Config Server和客户端添加配置
spring: rabbitmq: host: 192.169.200.128 port: 5672 username: guest password: guest
3)Config Server微服务暴露端口
management: endpoints: web: exposure: include: bus-refresh #建议暴露所有的端口 management: endpoints: web: exposure: include: "*"
4)重启各个服务,更改配置之后,向配置中心服务端发送post请求,各个客户端配置即可自动刷新
http://127.0.0.1:9400/actuator/bus-refresh
5)Config Client测试
http://localhost:9100/config/remote
在广播模式下实现了一次请求,处处更新,如果我只想定向更新呢?
在发起刷新请求的时候http://localhost:9006/actuator/bus-refresh/lagou-service-page:9100
即为最后面跟上要定向刷新的实例的 服务名:端口号即可
第二代 Spring Cloud 核心组件(SCA)
SpringCloud 是若干个框架的集合,包括 spring-cloud-config、spring-cloud-bus 等近 20 个子项目,提供了服务治理、服务网关、智能路由、负载均衡、断路器、监控跟踪、分布式消息队列、配置管理等领域的解决方案。Spring Cloud 通过 Spring Boot 风格的封装,屏蔽掉了复杂的配置和实现原理,最终给开发者留出了一套简单易懂、容易部署的分布式系统开发工具包。一般来说,Spring Cloud 包含以下组件,主要以 Netflix 开源为主。
同 Spring Cloud 一样,Spring Cloud Alibaba 也是一套微服务解决方案,包含开发分布式应用微服务的必需组件,方便开发者通过 Spring Cloud 编程模型轻松使用这些组件来开发分布式应用服务。依托Spring Cloud Alibaba,您只需要添加一些注解和少量配置,就可以将 Spring Cloud 应用接入阿里微服务解决方案,通过阿里中间件来迅速搭建分布式应用系统。
阿里开源组件
Nacos:一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。
Sentinel:把流量作为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。
RocketMQ:开源的分布式消息系统,基于高可用分布式集群技术,提供低延时的、高可靠的消息发布与订阅服务。
Dubbo:这个就不用多说了,在国内应用非常广泛的一款高性能 Java RPC 框架。
Seata:阿里巴巴开源产品,一个易于使用的高性能微服务分布式事务解决方案。
Arthas:开源的Java动态追踪工具,基于字节码增强技术,功能非常强大。
阿里商业化组件
作为一家商业公司,阿里巴巴推出 Spring Cloud Alibaba,很大程度上市希望通过抢占开发者生态,来帮助推广自家的云产品。所以在开源社区,夹带了不少私货,阿里商业化组件,整体易用性和稳定性还是很高的。
Alibaba Cloud ACM:一款在分布式架构环境中对应用配置进行集中管理和推送的应用配置中心产品。
Alibaba Cloud OSS:阿里云对象存储服务(Object Storage Service,简称 OSS),是阿里云提供的云存储服务。
Alibaba Cloud SchedulerX:阿里中间件团队开发的一款分布式任务调度产品,提供秒级、精准的定时(基于 Cron 表达式)任务调度服务。
集成 Spring Cloud 组件
Spring Cloud Alibaba 作为整套的微服务解决组件,只依靠目前阿里的开源组件是不够的,更多的是集成当前的社区组件,所以 Spring Cloud Alibaba 可以集成 Zuul,GateWay等网关组件,也可继承Ribbon、OpenFeign等组件。
Nacos 服务注册和配置中心
Nacos 介绍
Nacos (Dynamic Naming and Configuration Service)是阿里巴巴开源的一个针对微服务架构中服务发现、配置管理和服务管理平台。
Nacos就是注册中心+配置中心的组合(Nacos=Eureka + Config + Bus)
官网:https://nacos.io 下载地址:https://github.com/alibaba/Nacos
Nacos功能特性
服务发现与健康检查
动态配置管理
动态DNS服务
服务和元数据管理(管理平台的角度,nacos也有一个ui页面,可以看到注册的服务及其实例信息(元数据信息)等),动态的服务权重调整、动态服务优雅下线,都可以去做
Nacos 单例服务部署
下载解压安装包,执行命令启动(我们使用最近比较稳定的版本 nacos-server-1.2.0.tar.gz)
linux/mac:sh startup.sh -m standalone windows:cmd startup.cmd
访问nacos控制台:http://127.0.0.1:8848/nacos/#/login 或者 http://127.0.0.1:8848/nacos/index.html(默认端口8848,账号和密码 nacos/nacos)
微服务注册到Nacos
1. 在父pom中引入SCA依赖
<dependencyManagement> <dependencies> <!--SCN--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-dependencies</artifactId> <version>Greenwich.RELEASE</version> <type>pom</type> <scope>import</scope> </dependency> <!--SCA --> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-alibaba-dependencies</artifactId> <version>2.1.0.RELEASE</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement>
2. 在商品服务提供者工程中引入nacos客户端依赖,必须删除eureka-client依赖
<dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency>
3. application.yml修改,添加nacos配置信息
在yml文件中需要删除调用config和eureka相关的配置,否则启动失败
cloud:
nacos:
discovery:
server-addr: 127.0.0.1:8848 #nacos server 地址
4. 启动商品微服务,观察nacos控制台
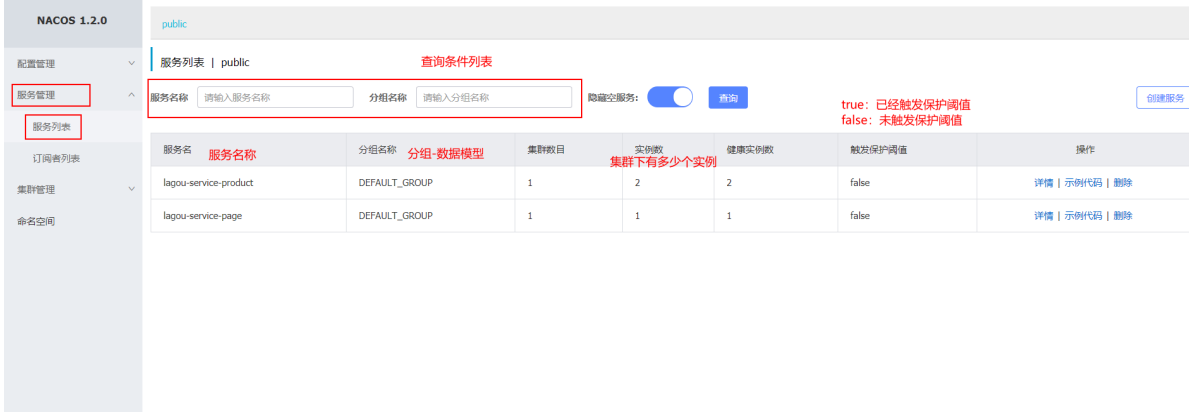
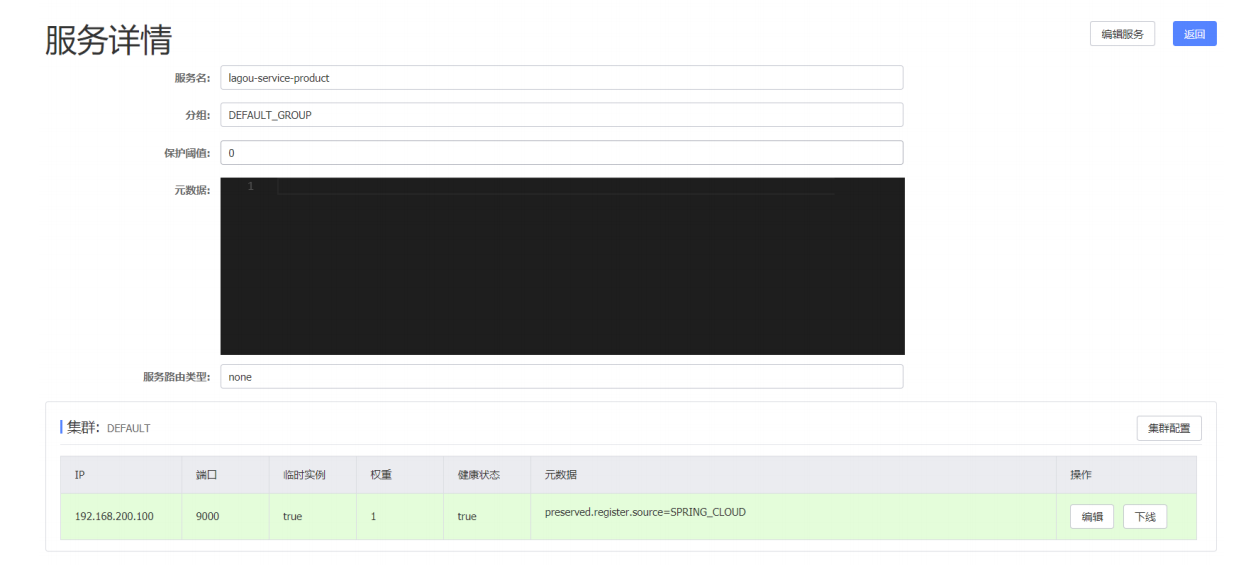
保护阈值:可以设置为0-1之间的浮点数,它其实是一个比例值(当前服务健康实例数/当前服务总实例数)
场景:
一般流程下,nacos是服务注册中心,服务消费者要从nacos获取某一个服务的可用实例信息,对于服务实例有健康/不健康状态之分,nacos在返回给消费者实例信息的时候,会返回健康实例。这个时候在一些高并发、大流量场景下会存在一定的问题
如果服务A有100个实例,98个实例都不健康了,只有2个实例是健康的,如果nacos只返回这两个健康实例的信息的话,那么后续消费者的请求将全部被分配到这两个实例,流量洪峰到来,2个健康的实例也扛不住了,整个服务A 就扛不住,上游的微服务也会导致崩溃,产生雪崩效应。
保护阈值的意义在于:
当服务A健康实例数/总实例数 < 保护阈值 的时候,说明健康实例真的不多了,这个时候保护阈值会被触发(状态true)
nacos将会把该服务所有的实例信息(健康的+不健康的)全部提供给消费者,消费者可能访问到不健康的实例,请求失败,但这样也比造成雪崩要好,牺牲了一些请求,保证了整个系统的一个可用。
注意:阿里内部在使用nacos的时候,也经常调整这个保护阈值参数。
负载均衡
Nacos客户端引入的时候,会关联引入Ribbon的依赖包,我们使用OpenFiegn的时候也会引入Ribbon的依赖,Ribbon包括Hystrix都按原来方式进行配置即可
此处,我们将商品微服务,再启动了一个9001端口,注册到Nacos上,便于测试负载均衡,我们通过后台也可以看出。
启动:
lagou-server-page
lagou-server-product-9000
lagou-server-proudct-9001
测试:
http://localhost:9100/page/getPort
Nacos 数据模型(领域模型)
Namespace命名空间、Group分组、集群这些都是为了进行归类管理,把服务和配置文件进行归类,归类之后就可以实现一定的效果,比如隔离
比如,对于服务来说,不同命名空间中的服务不能够互相访问调用
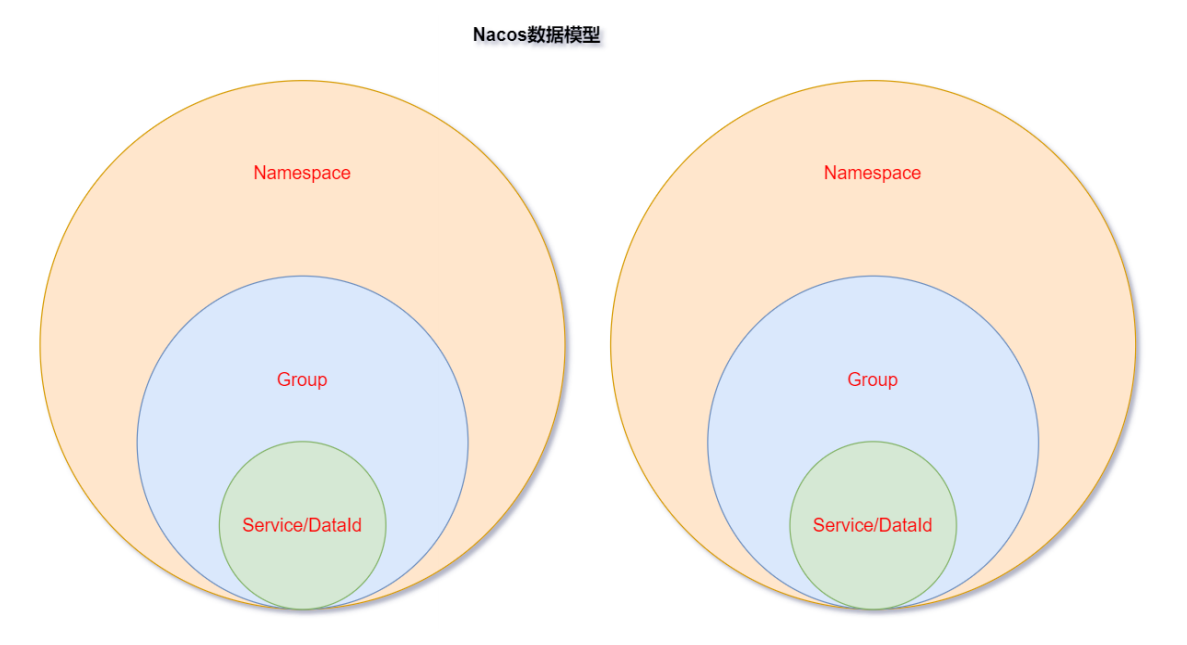
Namespace:命名空间,对不同的环境进行隔离,比如隔离开发环境、测试环境和生产环境
Group:分组,将若干个服务或者若干个配置集归为一组,通常习惯一个系统归为一个组(拉勾招聘、拉勾猎头、拉勾教育)
Service:某一个服务,比如商品微服务
DataId:配置集或者可以认为是一个配置文件
Namespace + Group + Service 如同 Maven 中的GAV坐标,GAV坐标是为了锁定Jar,而这里是为了锁定服务
Namespace + Group + DataId 如同 Maven 中的GAV坐标,GAV坐标是为了锁定Jar,而这里是为了锁定配置文件
Nacos抽象出了Namespace、Group、Service、DataId等概念,具体代表什么取决于怎么用(非常灵活),推荐用法如下

Nacos 配置中心
之前:Spring Cloud Config + Bus(配置的自动更新)
1) Github 上添加配置文件
2)创建Config Server 配置中心—>从Github上去下载配置信息
3)具体的微服务(最终使用配置信息的)中配置Config Client—> ConfigServer获取配置信息
有Nacos之后,分布式配置就简单很多
Github不需要了(配置信息直接配置在Nacos server中),Bus也不需要了(依然可以完成动态刷新)
接下来
1、去Nacos server中添加配置信息
2、改造具体的微服务,使其成为Nacos Config Client,能够从Nacos Server中获取到配置信息
Nacos Server添加配置
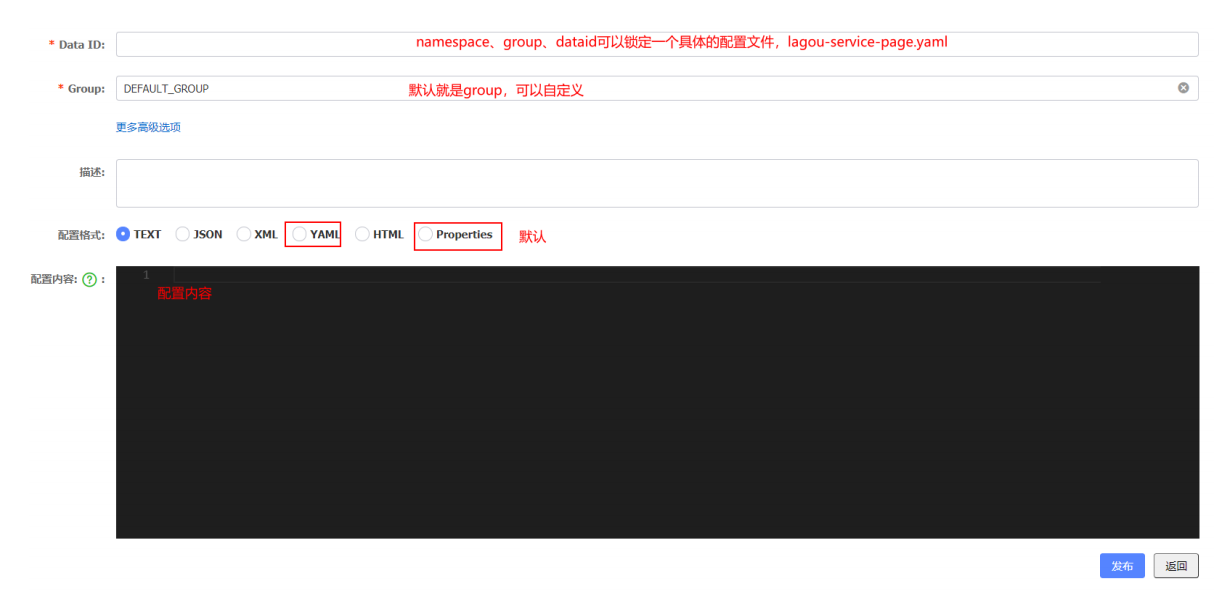
微服务中开启 Nacos 配置管理
1)添加依赖
<dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId> </dependency>
2)微服务中如何锁定 Nacos Server 中的配置文件(dataId)
通过 Namespace + Group + dataId 来锁定配置文件,Namespace不指定就默认public,Group不指定就默认 DEFAULT_GROUP
dataId 的完整格式如下
${prefix}-${spring.profile.active}.${file-extension}
- prefix 默认为 spring.application.name 的值,也可以通过配置项spring.cloud.nacos.config.prefix 来配置。
- spring.profile.active 即为当前环境对应的 profile。 注意:当 spring.profile.active为空时,对应的连接符 - 也将不存在,dataId 的拼接格式变成 ${prefix}.${file-extension}
- file-exetension 为配置内容的数据格式,可以通过配置项spring.cloud.nacos.config.file-extension 来配置。目前只支持 properties 和 yaml 类型。
cloud: nacos: discovery: server-addr: 127.0.0.1:8848 config: server-addr: 127.0.0.1:8848 namespace: 26ae1708-28de-4f63-8005-480c48ed6510 #命名空间的ID group: DEFAULT_GROUP #如果使用的默认分组,可以不设置 file-extension: yaml
3)通过 Spring Cloud 原生注解 @RefreshScope 实现配置自动更新
package com.lagou.page.controller; import org.springframework.beans.factory.annotation.Value; import org.springframework.cloud.context.config.annotation.RefreshScope; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; @RestController @RequestMapping("/config") @RefreshScope //自动刷新 public class ConfigClientController { @Value("${lagou.message}") private String message; @Value("${database.type}") private String dbType; @RequestMapping("/remote") public String findRemoteConfig() { return message + " " + dbType; } }
4)思考:一个微服务希望从配置中心Nacos server中获取多个dataId的配置信息,可以的,扩展多个dataId
# nacos配置 cloud: nacos: discovery: server-addr: 127.0.0.1:8848 # nacos config 配置 config: server-addr: 127.0.0.1:8848 # 锁定server端的配置文件(读取它的配置项) namespace: 07137f0a-bf66-424b-b910-20ece612395a # 命名空间id group: DEFAULT_GROUP # 默认分组就是DEFAULT_GROUP,如果使用默认分组可以不配置 file-extension: yaml #默认properties # 根据规则拼接出来的dataId效果:lagou-service-page.yaml ext-config[0]: data-id: abc.yaml group: DEFAULT_GROUP refresh: true #开启扩展dataId的动态刷新 ext-config[1]: data-id: def.yaml group: DEFAULT_GROUP refresh: true #开启扩展dataId的动态刷新
SCA Sentinel 分布式系统的流量防卫兵
Sentinel 介绍
Sentinel是一个面向云原生微服务的流量控制、熔断降级组件。
替代Hystrix,针对问题:服务雪崩、服务降级、服务熔断、服务限流
Hystrix:
服务消费者(静态化微服务)—>调用服务提供者(商品微服务)
在调用方引入Hystrix
1)自己搭建监控平台 dashboard
2)没有提供UI界面进行服务熔断、服务降级等配置(使用的是@HystrixCommand参数进行设置,代码入侵)
Sentinel:
1)独立可部署Dashboard/控制台组件(其实就是一个jar文件,直接运行即可)
2)减少代码开发,通过UI界面配置即可完成细粒度控制
核心库:(Java 客户端)不依赖任何框架/库,能够运行于所有 Java 运行时环境,同时对 Dubbo / Spring Cloud 等框架也有较好的支持。
控制台:(Dashboard)基于 Spring Boot 开发,打包后可以直接运行,不需要额外的 Tomcat 等应用容器。
Sentinel 具有以下特征:
丰富的应用场景:Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景,例如秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填谷、集群流量控制、实时熔断下游不可用应用等。
完备的实时监控:Sentinel 同时提供实时的监控功能。您可以在控制台中看到接入应用的单台机器秒级数据,甚至 500 台以下规模的集群的汇总运行情况。
广泛的开源生态:Sentinel 提供开箱即用的与其它开源框架/库的整合模块,例如与 Spring Cloud、Dubbo的整合。您只需要引入相应的依赖并进行简单的配置即可快速地接入 Sentinel。
完善的 SPI 扩展点:Sentinel 提供简单易用、完善的 SPI 扩展接口。您可以通过实现扩展接口来快速地定制逻辑。例如定制规则管理、适配动态数据源等。
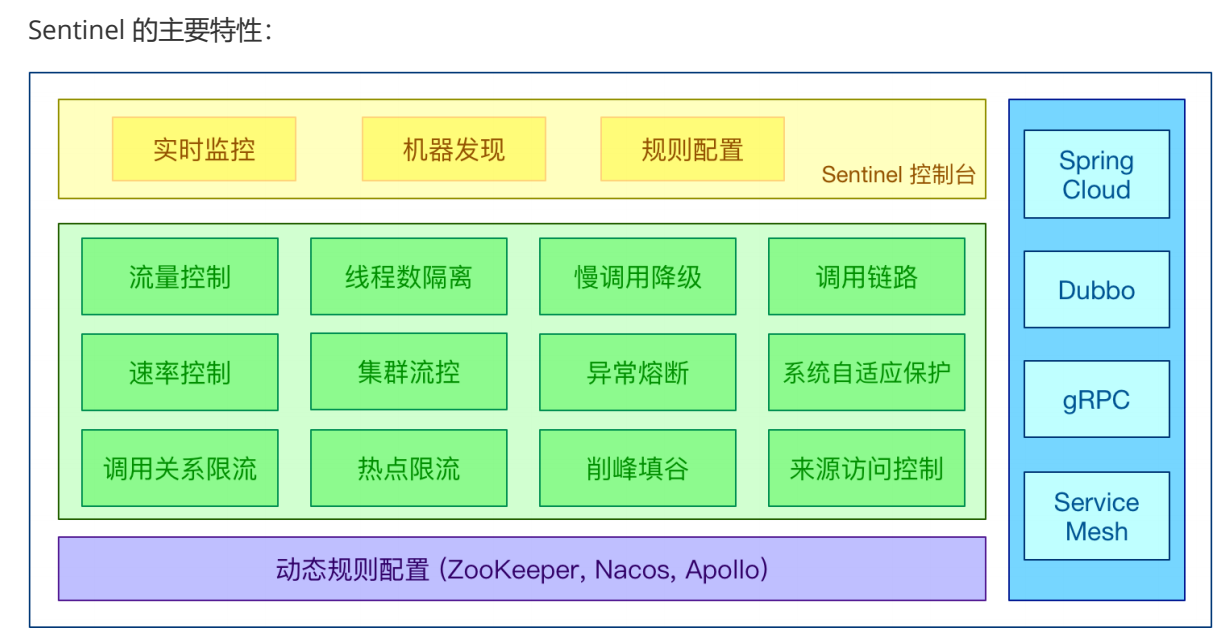

Sentinel 部署
下载地址:https://github.com/alibaba/Sentinel/releases 我们使用v1.7.1
启动:java -jar sentinel-dashboard-1.7.1.jar &
用户名/密码:sentinel/sentinel

服务改造
在我们已有的业务场景中,“静态化微服务”调用了“商品微服务”,我们在静态化微服务进行的熔断降级等控制,那么接下来我们改造静态化微服务,引入Sentinel核心包。
为了不污染之前的代码,复制一个页面静态化微服务 lagou-service-page-9101-sentinel
pom.xml引入依赖
<!--sentinel 核心环境 依赖--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-sentinel</artifactId> </dependency>
application.yml修改(配置sentinel dashboard,暴露断点依然要有,删除原有hystrix配置,删除原有OpenFeign的降级配置)
server: port: 9101 # 后期该微服务多实例,端口从9100递增(10个以内) Spring: #解决bean重复注册问题 main: allow-bean-definition-overriding: true application: name: lagou-service-page datasource: driver-class-name: com.mysql.jdbc.Driver url: jdbc:mysql://localhost:3306/lagou?useUnicode=true&characterEncoding=utf8&serverTimezone=UTC username: root password: wu7787879 cloud: nacos: discovery: server-addr: 127.0.0.1:8848 config: server-addr: 127.0.0.1:8848 namespace: 26ae1708-28de-4f63-8005-480c48ed6510 #命名空间的ID group: DEFAULT_GROUP #如果使用的默认分组,可以不设置 file-extension: yaml #sentinel配置 sentinel: transport: dashboard: 127.0.0.1:8080 port: 8719 # springboot中暴露健康检查等断点接口 management: endpoints: web: exposure: include: "*" # 暴露健康接口的细节 endpoint: health: show-details: always
上述配置之后,启动静态化微服务,使用 Sentinel 监控静态化微服务
此时我们发现控制台没有任何变化,因为懒加载,我们只需要发起一次请求触发即可
Sentinel 关键概念

Sentinel 流量规则模块
系统并发能力有限,比如系统A的QPS支持1个,如果太多请求过来,那么A就应该进行流量控制了,比如其他请求直接拒绝
资源名:默认请求路径
针对来源:Sentinel可以针对调用者进行限流,填写微服务名称,默认default(不区分来源)
阈值类型/单机阈值
- QPS:(每秒钟请求数量)当调用该资源的QPS达到阈值时进行限流
- 线程数:当调用该资源的线程数达到阈值的时候进行限流(线程处理请求的时候,如果说业务逻辑执行时间很长,流量洪峰来临时,会耗费很多线程资源,这些线程资源会堆积,最终可能造成服务不可用,进一步上游服务不可用,最终可能服务雪崩)
是否集群:是否集群限流
流控模式:
直接:资源调用达到限流条件时,直接限流
关联:关联的资源调用达到阈值时候限流自己
链路:只记录指定链路上的流量
流控效果:
- 快速失败:直接失败,抛出异常
- Warm Up:根据冷加载因子(默认3)的值,从阈值/冷加载因子,经过预热时长,才达到设置的QPS阈值
- 排队等待:匀速排队,让请求匀速通过,阈值类型必须设置为QPS,否则无效
流控模式之关联限流
关联的资源调用达到阈值时候限流自己,比如用户注册接口,需要调用身份证校验接口(往往身份证校验接口),如果身份证校验接口请求达到阈值,使用关联,可以对用户注册接口进行限流。
package com.lagou.page.controller; import org.apache.ibatis.javassist.Loader; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; import java.text.SimpleDateFormat; import java.util.Date; @RestController @RequestMapping("/user") public class UserController { /** * 用户注册接口-拉勾金融 * @return */ @GetMapping("/register") public String register() { String now = new SimpleDateFormat("yyyy/MM/dd mm:ss").format(new Date()); System.out.println(now); System.out.println("Register success!"); return "Register success!"; } /** * 验证注册身份证接口(需要调用公安户籍资源) * @return */ @GetMapping("/validateID") public String validateID() { System.out.println("validateID"); return "ValidateID success!"; } }
模拟密集式请求/user/validateID验证接口,我们会发现/user/register接口也被限流了
流控模式之链路限流
链路指的是请求链路(调用链:A-->B--C,D-->E-->C)
链路模式下会控制该资源所在的调用链路入口的流量。需要在规则中配置入口资源,即该调用链路入口的上下文名称。
一棵典型的调用树如下图所示:

上图中来自入口 Entrance1 和 Entrance2 的请求都调用到了资源 NodeA ,Sentinel 允许只根据某个调用入口的统计信息对资源限流。比如链路模式下设置入口资源为 Entrance1 来表示只有从入口Entrance1 的调用才会记录到 NodeA 的限流统计当中,而不关心经 Entrance2 到来的调用。

流控效果之Warm up
当系统长期处于空闲的情况下,当流量突然增加时,直接把系统拉升到高水位可能瞬间把系统压垮,比如电商网站的秒杀模块。
通过 Warm Up 模式(预热模式),让通过的流量缓慢增加,经过设置的预热时间以后,到达系处理请求速率的设定值。
Warm Up 模式默认会从设置的 QPS 阈值的 1/3 开始慢慢往上增加至 QPS 设置值。

流控效果之排队等待
排队等待模式下会严格控制请求通过的间隔时间,即请求会匀速通过,允许部分请求排队等待,通常用于消息队列削峰填谷等场景。需设置具体的超时时间,当计算的等待时间超过超时时间时请求就会被拒绝。
很多流量过来了,并不是直接拒绝请求,而是请求进行排队,一个一个匀速通过(处理),请求能等就等着被处理,不能等(等待时间>超时时间)就会被拒绝
例如,QPS 配置为 5,则代表请求每 200 ms 才能通过一个,多出的请求将排队等待通过。超时时间代表最大排队时间,超出最大排队时间的请求将会直接被拒绝。排队等待模式下,QPS 设置值不要超过 1000(请求间隔 1 ms)。
Sentinel 降级规则模块
流控是对外部来的大流量进行控制,熔断降级的视角是对内部问题进行处理。
Sentinel 降级会在调用链路中某个资源出现不稳定状态时(例如调用超时或异常比例升高),对这个资源的调用进行限制,让请求快速失败,避免影响到其它的资源而导致级联错误。当资源被降级后,在接下来的降级时间窗口之内,对该资源的调用都自动熔断,这里的降级其实是Hystrix中的熔断。
策略
Sentinel不会像Hystrix那样放过一个请求尝试自我修复,就是明明确确按照时间窗口来,熔断触发后,时间窗口内拒绝请求,时间窗口后就恢复。
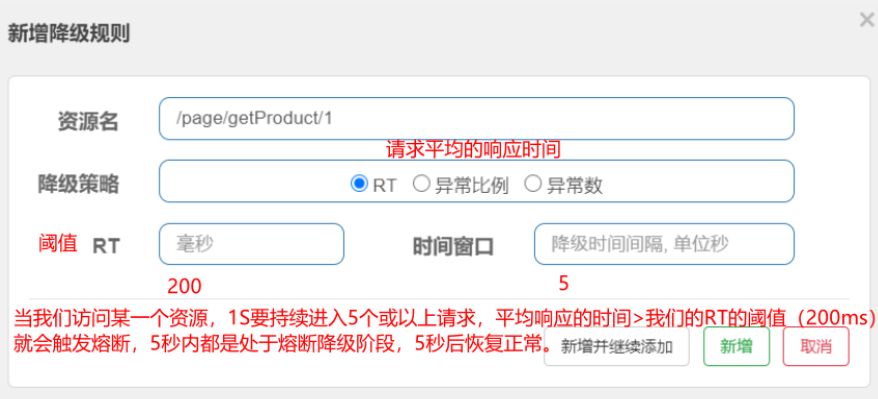
RT(平均响应时间 )
当 1s 内持续进入 >=5 个请求,平均响应时间超过阈值(以 ms 为单位),那么在接下的时间窗口(以 s 为单位)之内,对这个方法的调用都会自动地熔断(抛出 DegradeException)。注意Sentinel 默认统计的 RT 上限是 4900 ms,超出此阈值的都会算作 4900 ms,若需要变更此上限可以通过启动配置项 -Dcsp.sentinel.statistic.max.rt=xxx 来配置。

异常比例
当资源的每秒请求量 >= 5,并且每秒异常总数占通过量的比值超过阈值之后,资源进入降级状态,即在接下的时间窗口(以 s 为单位)之内,对这个方法的调用都会自动地返回。异常比率的阈值范围是[0.0, 1.0] ,代表 0% - 100%。

异常数
当资源近 1 分钟的异常数目超过阈值之后会进行熔断。注意由于统计时间窗口是分钟级别的,若timeWindow 小于 60s,则结束熔断状态后仍可能再进入熔断状态,时间窗口 >= 60s。
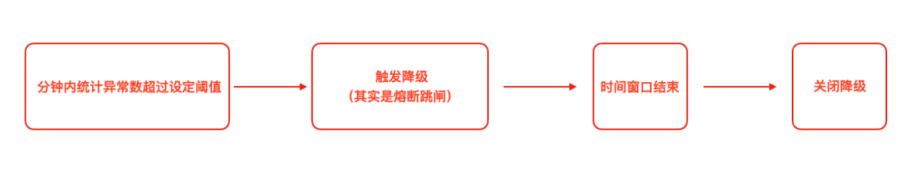
SCA 小结
SCA实际上发展了三条线
- 第一条线:开源出来一些组件
- 第二条线:阿里内部维护了一个分支,自己业务线使用
- 第三条线:阿里云平台部署一套,付费使用
从战略上来说,SCA更是为了贴合阿里云。
目前来看,开源出来的这些组件,推广及普及率不高,社区活跃度不高,稳定性和体验度上仍需进一步提升,根据实际使用来看Sentinel的稳定性和体验度要好于Nacos。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号