计算机考研失败,准备零基础学Java混口吃的(持续更新)
沉淀
我承认我是个废物
会重点记录一些自己之前没了解过的内容,或者觉得比较重要的内容
JAVA基础
-
枚举类
说实话写了那么久的代码,一直没用过枚举类型,因此也没有了解过,趁现在了解一下罢!
- 为什么要使用枚举?
使用枚举的地方会有更强的类型约束,编译器会帮助检查入参类型,规避潜在风险
public class Enum {
// 在我们常常会这样定义一些常变量,但这样定义会产生一定的风险
public static final Integer NORMAL = 0;
public static final Integer LOCKED = 1;
public static final Integer DISABLE = 2;
@Test
public void main() {
handleState(NOMAL); // 正常执行
handleState(Interger.MAX_VALUE); // 随便输入一个数字,依旧可以正常执行,但是结果可能不是你想要的
handleStateEnum(Integer.MAX_VALUE); //编译器报错
handleStateEnum(UserState.LOCKED); // 正常执行
}
public handleState(Integer state) {
if(state == NORMAL) System.out.print("Hello, World!");
}
public handleStateEnum(UserState userState) {
if(state == UserState.NORMAL) System.out.print("Hello, World!");
}
}
enum UserState {
// 同时还可以对这些成员变量赋予一些值,实际生产中也可能使用到
NORMAL(0, "员工"),
LOCKED(1, "管理员"),
DISABLE(2, "编外人员");
private long id;
private String name;
}
Java的集合框架
- Java 容器分为 Collection 和 Map 两大类,其下又有很多子类,如下所示:
Collection包括:List、ArrayList、LinkedList、Vector、Stack、Set、HashSet、LinkedHashSet、TreeSet
Map包括:HashMap、LinkedHashMap、TreeMap、ConcurrentHashMap、Hashtable
Collection 和 Collections 有什么区别?
- 区别如下:
Collection 是一个集合接口,它提供了对集合对象进行基本操作的通用接口方法,所有集合都是它的子类,比如 List、Set 等。
Collections 是一个包装类,包含了很多静态方法,不能被实例化,就像一个工具类,比如提供的排序方法:Collections. sort(list)。
List、Set、Map 之间的区别是什么?
- List、Set、Map 的区别主要体现在两个方面:元素是否有序、是否允许元素重复。
太多了记不过来了,以后有时间再说了
-
ArrayList
- 初始化
底层数组名叫elementData,
1.初始大小是0;
2.当有数据插入时,默认大小DEFAULT_CAPACITY = 10;
3.如果在创建ArrayList时指定了initialCapacity,则初始大小是initialCapacity。 - 扩容机制
每次调用add()方法都会将数组需要的最小容量:minCapacity(size+1)与oldCapacity=elementData.length之间大小进行比较,如果minCapacity更大,则说明需要扩容。
1.实现关键:扩容核心方法是grow()方法。
/**
* ArrayList扩容的核心方法。
*/
private void grow(int minCapacity) {
// oldCapacity为旧容量,newCapacity为新容量
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
//然后检查新容量是否大于最小需要容量,若还是小于最小需要容量,那么就把最小需要容量当作数组的新容量,
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
// MAX_ARRAY_SIZE 为 `Integer.MAX_VALUE - 8`。
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
-
多线程编程
- 线程的生命周期
①新建状态;
②就绪状态:当线程对象调用了start()方法之后,该线程就进入就绪状态;
③运行状态:如果就绪状态的线程获取 CPU 资源,就可以执行 run(),此时线程便处于运行状态;
④阻塞状态:如果一个线程执行了sleep(睡眠)、suspend(挂起)等方法,失去所占用资源之后,该线程就从运行状态进入阻塞状态。;
⑤死亡状态:一个运行状态的线程完成任务或者其他终止条件发生时,该线程就切换到终止状态。 - 创建线程方法
1.实现Runnable接口;
2.继承Thread;
3.通过Callable创建线程;
4.通过线程池。
- 继承Thread类
public class MyThread extends Thread {
@Override
public void run() {
System.out.println("MyThread...run...");
}
public static void main(String[] args) {
// 创建MyThread对象
MyThread t1 = new MyThread();
MyThread t2 = new MyThread();
// 调用start方法启动线程,调用一次就是启动一个;
t1.start();
t2.start();
}
}
Tomcat部署Javaweb应用
-
安装Tomcat
-
- 官网下载并解压缩文件
-
- 目录结构
bin目录:存放各个平台(操作系统)下启动和停止Tomcat服务的脚本文件如stratup.bat:windows平台下;startup.sh:linux平台下的启动脚本文件;
conf目录:存放各种Tomcat服务器的配置文件。server.xml文件里可以配置端口,默认端口8080。
lib目录:存放Tomcat服务器所需要的jar。
log目录:存放Tomcat服务运行的日志。
temp目录:存放Tomcat运行时的临时文件。
webapps:存放允许客户端访问的资源。
work:存放Tomcat将JSP转换之后的Servlet文件。
- 目录结构
-
- idea中配置Tomcat
Spring项目学习
-
点赞模块
- 数据库表设计:
| 字段名称 | 数据类型 | 注释 |
|---|---|---|
| id | BIGINT | 主键id |
| user_id | BIGINT | 用户id |
| biz_id | BIGINT | 点赞的业务id |
| creat_time | DATETIME | 创建时间 |
| update_time | DATETIME | 更新时间 |
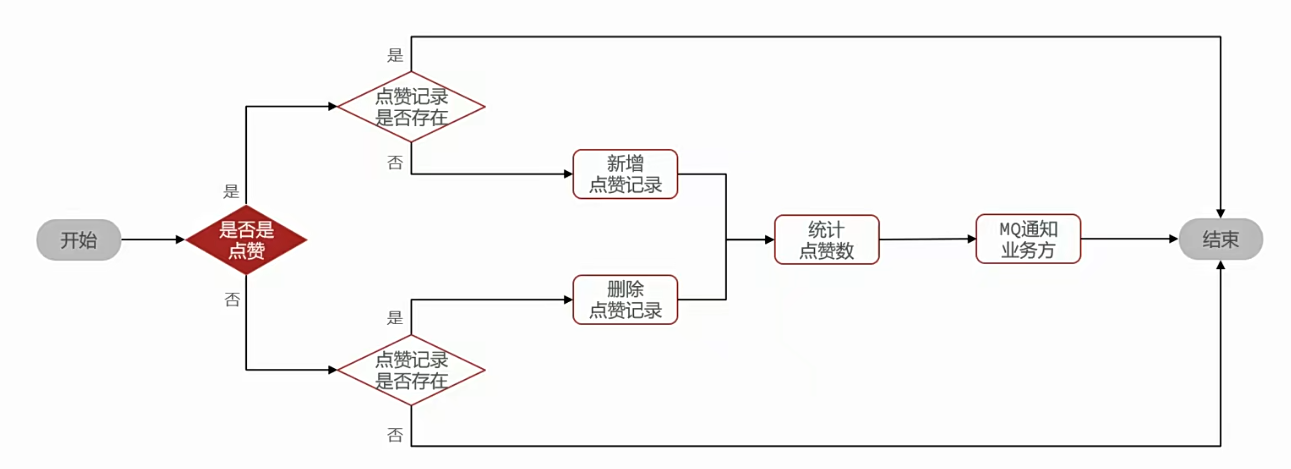
①如果是进行点赞业务,先使用user_id和biz_id查找有没有点过赞,如果点过就返回false,如果没有点过赞就加入表中
②如果是进行取消赞业务,先使用user_id和biz_id查找有没有点过赞,如果没有点过则返回false,如果点过就删除点赞记录
③使用biz_id查找该业务的总点赞数,并返回
项目改进:DB操作次数过多,性能不高,所以①②③改操作redis,并使用定时任务更新数据库。
- 点赞的数据结构设计:

使用set结构存储业务的点赞信息
①当进行点赞时,如果redis中存在则返回false,如果不存在则往redis中插入数据
②当进行取消赞时,如果redis中不存在则返回false,如果存在则删除相应的userId。 - 点赞总数的数据结构设计

使用zset存储点赞总数信息,其中value是业务id——biz_id,分值是该业务的点赞总数
①在点赞的set中获取点赞总数,并存储到redis中
②使用定时任务——SpringTask框架,在启动类中加上@EnableScheduling注解后再在使用定时任务的方法上使用@Scheduled(fixedDelay = 20000),实习每20s的定时任务。
八股文
听说八股也要背一背,那就背一背吧。这个主要是看b站上的黑马视频的。话说我记这个干嘛,简单写一写得了。
-
JVM
-
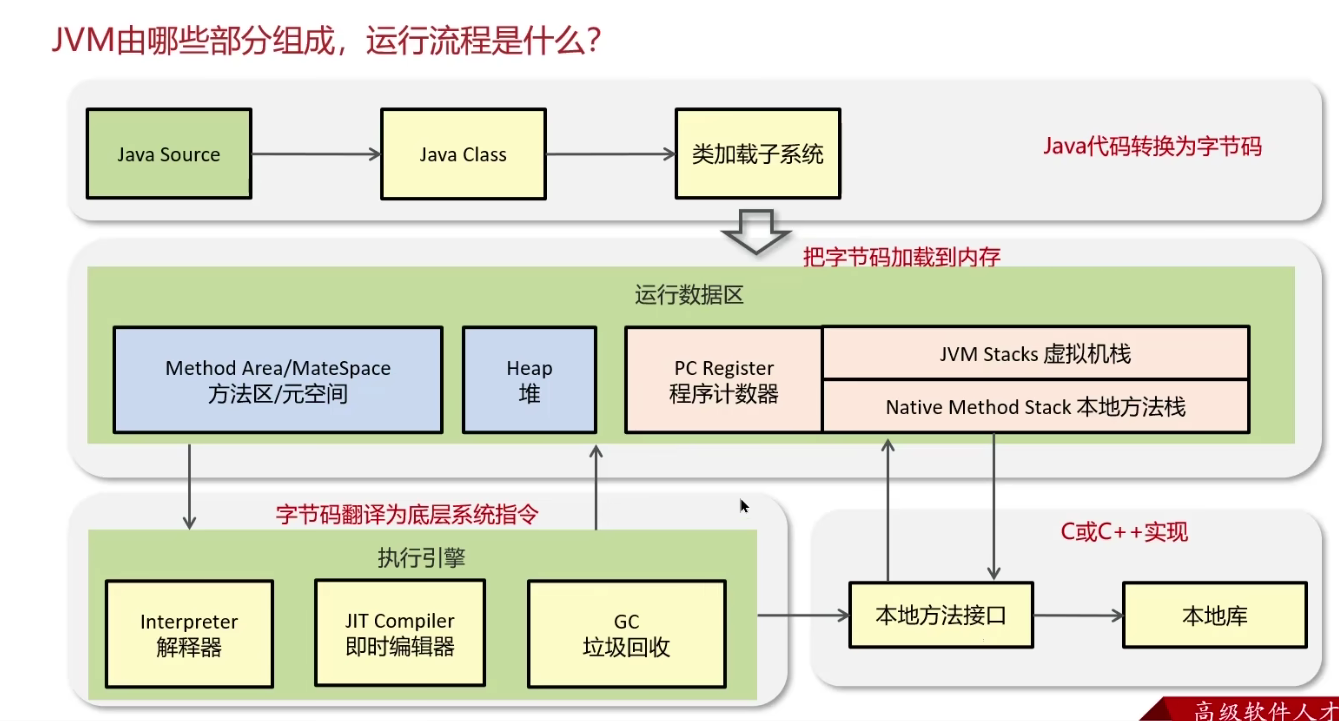
JVM的组成
JVM是JAVA程序的运行环境(java二进制字节码的运行环境)
好处:①一次编写到处运行;②自动内存管理,垃圾回收
-
什么是程序计数器
线程私有的,每个线程一份,内部保存的字节码的行号。用于记录正在执行的字节码指令的地址。
-
请详细介绍JAVA堆
-
线程共享的区域:主要用来保存对象实例,数组等,内存不够则抛出OutOfMemoryError异常
-
Redis
-
缓存
-
- 击穿:当某一key过期且Redis还未来得及重建时,此时数据查询等是直接通过数据库进行的,所以这时如果有大量的对此key的并发请求时,有可能会把数据库压垮。
解决方案:①互斥锁:当某一线程在Redis中未命中时,就申请互斥锁,并重建缓存
②逻辑过期:Redis中不设置过期时间,在数据中加一条“逻辑时间”字段。当“逻辑时间”过期,线程会新开一个线程进
行缓存重建,同时返回数据。也就是说在重建没有完成时,返回的都是“过期数据”,这样保证了高可用。
- 击穿:当某一key过期且Redis还未来得及重建时,此时数据查询等是直接通过数据库进行的,所以这时如果有大量的对此key的并发请求时,有可能会把数据库压垮。
-
- 穿透:查询一条不存在的数据,数据库查询不到数据也不会写如内存,导致每次查询都会请求数据库
解决方案:使用布隆过滤器。布隆过滤器主要使用位图和哈希函数实现。
- 穿透:查询一条不存在的数据,数据库查询不到数据也不会写如内存,导致每次查询都会请求数据库
-
- 雪崩:有大量key同时失效或Redis宕机,导致大量请求到达数据库,带来巨大压力
解决方案:①设置随机的TTL过期时间②利用Redis集群提高服务的可用性③给缓存业务添加④添加多级缓存
- 雪崩:有大量key同时失效或Redis宕机,导致大量请求到达数据库,带来巨大压力
-
双写一致
修改数据库数据后缓存数据也要保持一致
-
- 应用场景:实时性要求不高的文章热点数据,允许延时一致。
解决方案:采用异步通知。使用MQ中间件,更新数据之后,通知缓存删除。
- 应用场景:实时性要求不高的文章热点数据,允许延时一致。
-
Redis持久化
-
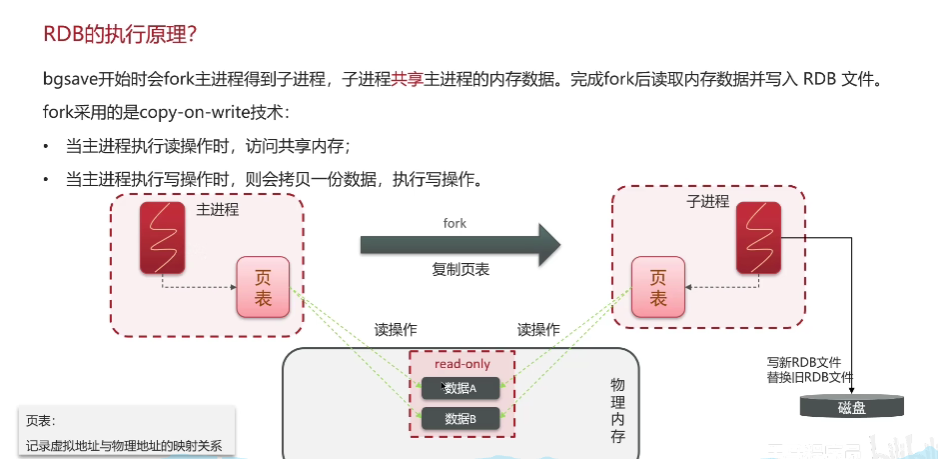
- RDB:简单来说就是把内存中的所有数据记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件,恢复数据。
RDB触发机制:可以在redis.conf文件中找到,格式如下:
其中bgsave:bgsave开始时会fork主进程得到子进程,子进程共享主进程的内存数据。完成fork后读取内存数据并写入RDB文件
- RDB:简单来说就是把内存中的所有数据记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件,恢复数据。
# 900秒内至少有一个1个key被修改,则执行bgsave
save 900 1
-
- AOF:Redis处理的每一个写命令都会记录在AOF中,可以看做是命令日志文件。
-
过期策略
-
- 惰性删除:访问key的时候判断是否过期,若过期则删除
-
- 定期删除:每隔一段时间,就对一些key进行检查,并删除过期的key
模式:①SLOW模式:SLOW是定时任务②FAST模式:执行频率不固定。
- 定期删除:每隔一段时间,就对一些key进行检查,并删除过期的key
