PostgreSQL全文检索功能FTS(Full Text Search,全文检索)
提到全文,你是否立刻想到了大名鼎鼎的Lucene和Elasticsearch。Elasticsearch 基于 Lucene ,并为开发者提供丰富的接口和工具,但是这也造成了它日益庞大。
使用它,你得备上大的服务器,优秀的运维团队,还要承受数据同步的心智负担。但你的需求其实很简单,只是,或者简单的全站。如果在项目的初期,花费如此大成本在上有些得不偿失。
如果本身就全文检索,那该多好啊!没错,Postgre 就全文,而且很强大,还扩展定制。
Postgre 全文是通过 FTS 配置库来的,大多数 Postgre 发行版都了 10 个以上的 FTS 配置库,我们可以通过p的\dF命令来查看已安装的配置库:
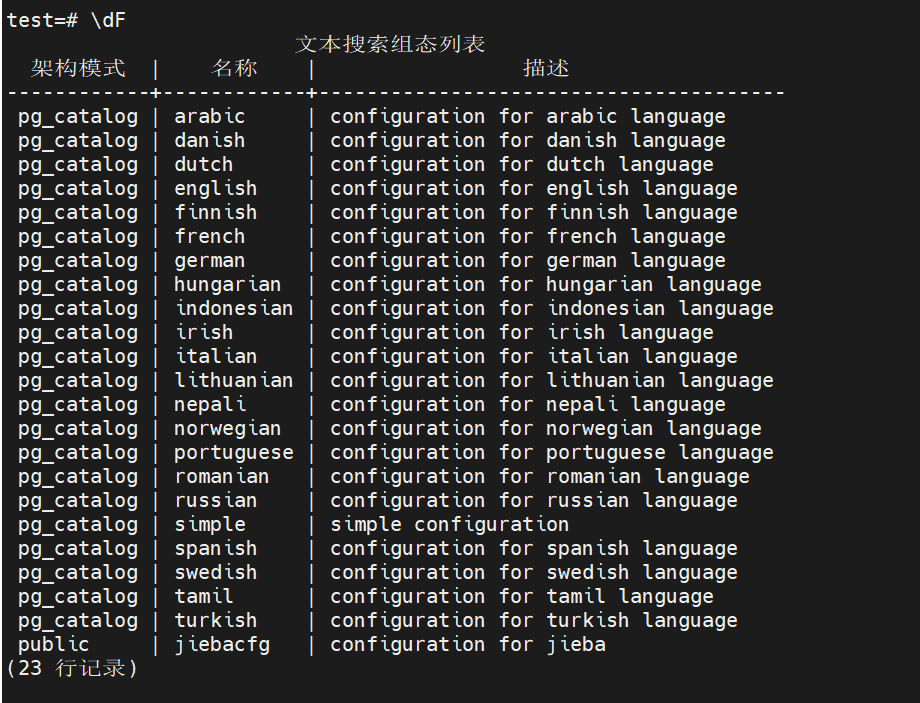
可以看到 Postgre 认已经安装了大量的 FTS 配置库,但是很不幸没有配置库。但好在,Postgre 的形式来扩展 FTS,所以我们可以使用成熟的扩展库。
jieba是国内颇为著名分词库,如果你是 Python 开发者,那么一定听过它的大名。有贡献者为 Postgre 提供了 jieba 分词——,让我们可以在 Postgre 使用到全文检索。
如果你想跟着我们一起,完成本节的实战,那么请先点开此安装 pg_jieba。
如果你安装成功,那么可以通过\dF命令来找到jieba相关的分词配置:

可以看到jieba提供了4种器,它们分别对应了不同的分词算法,如果你感兴趣,可以查阅相关的资料,这里我们不做过多的介绍,认使用jiebacfg即可。
全文大致可分为两部分:
在 FTS 中,原始文本在构建索引之前需要被向量化。原始文本(如:字符串)必须先被向量化后才能通过 FTS 对其检索,向量化后的需要存储到单独的向量字段中,该向量的数据类型是tsvector。
Postgre 提供了to_tsvector来将原始文本向量化,如下:

tsvector是由(词,序列)组成的列表,如是原始文本中的第词,所以它的序列是1。
有了索引后,我们如何来索引了?
一般情况下,我们是通过关键词来检索的,那么如何来组织关键词呢?
Postgre 提供了to_tsquery来将词组织成tsquery向量,然后通过向量去。tsquery是一种特殊的数据类型,它会将关键词拼接来表示条件,如&表示的必须包含和java。举个复杂的例子:

在输入句子的情况下,to_tsquery会将句子分词,然后将其拼接为tsquery。
我们总结一下 FTS 的使用:
接下来,我们以实践的角度来使用和学习一下 FTS。
假设某个应用有点,我们将通过 FTS 来实现它。
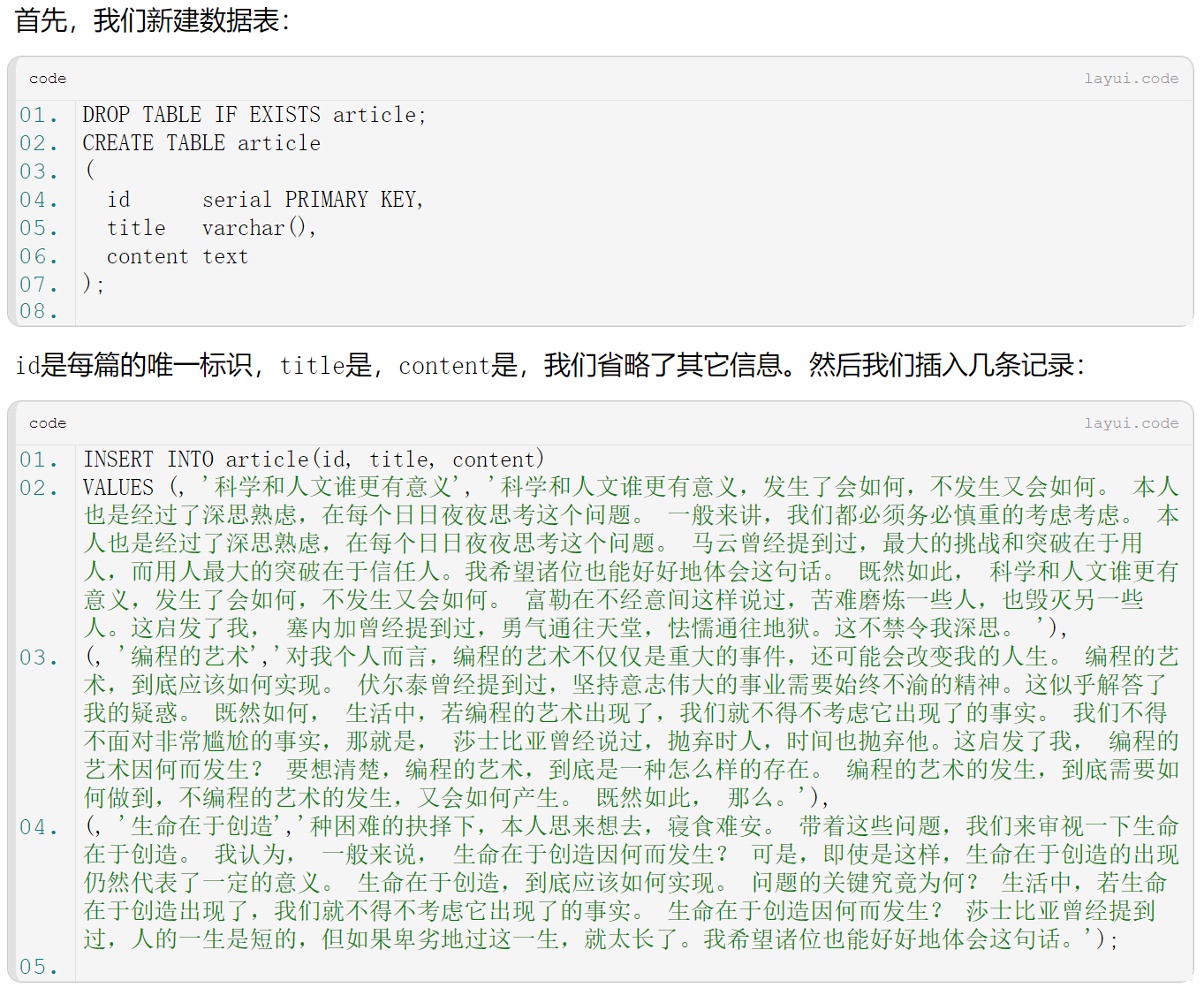
首先,我们新建数据表:
我们需要为每篇单独新建字段fts用来表示每篇的 tsvector 字段,并且给 fts 字段创建 gin 索引,这样后面就可以通过该字段来了。

在 语句中,我们首先为article数据表新增了fts字段,字段类型为tsvector。有了该字段后,我们需要为该字段赋值,通过to_tsvector我们将每篇的title和content分别向量化。
由于title和content的重要性不一样,的明显比数据更加重要,因此setweight设置的权重为A,而的权重为B,A的重要性大于B。||操作符合并向量后将结果赋给fts。
到此,article 表中新增了 fts 字段,字段中是和词组的列表。最后为 fts 字段我们新建了索引 article_fts_gin_index 来加速我们的效率。
: || 操作符是 Postgre 的特点,表示连接、合并。
接下来,我们便可以使用全文了,条件是需包含问题关键字,如下

Postgre 提供@@操作符来,上面语句将问题通过to_tsquery转化为向量后,使用@@来。从结果中可以看出,与问题相关的有两篇。
注意: 在 article 表中,只有 fts 是 tsvector 字段,因此只有它能使用 @@ 操作符。
我们再尝试一下复杂的,条件是必须含有问题和生命两个关键字:

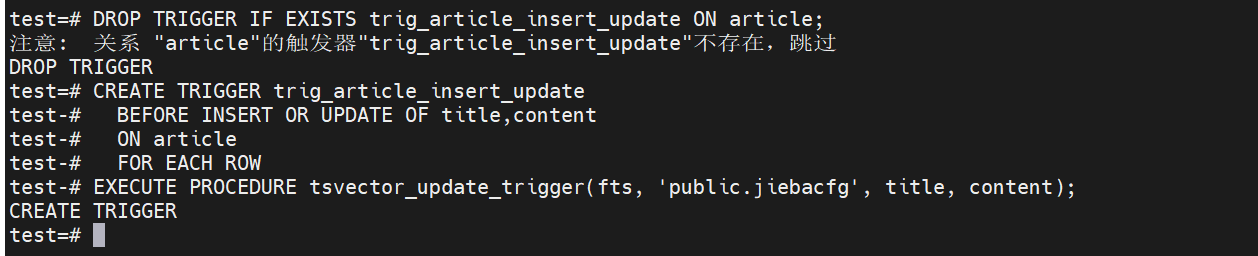
从结果中可以看到,全文已经可以工作了,但它还不完备,如果更新或者,发生了改变,那么索引也应该随之变化,我们可以使用触发器来这个需求点。运行如下 :

 浙公网安备 33010602011771号
浙公网安备 33010602011771号