L2G3-LMDeploy 量化部署进阶实践
L2G3-LMDeploy 量化部署进阶实践
1. LMDeploy部署模型
1.1 什么是模型部署?
1.2 一个大语言模型部署框架可以提供什么?
LMDeploy提供了大语言模型部署的全链条开源工具,能够十分便捷地帮助用户部署自己大模型应用。
推理引擎与大模型的关系(from claude 3.5 sonnet):
大模型是"内容",推理引擎是"容器"。具体关系如下:
大模型的角色:包含模型的权重参数,定义了网络结构,存储训练好的知识。
推理引擎的作用:适配特定模型架构,加载和管理模型文件,提供运行时环境,执行模型的前向计算并负责优化计算过程和推理性能,最后对外提供标准接口服务。
不同推理引擎对同一模型的性能可能不同,可以把推理引擎理解为"播放器",而大模型则是"视频文件"。不同的播放器(推理引擎)可以播放相同的视频(模型),但播放效果和性能可能不同。
工作流程
graph LR A[模型文件] --> B[推理引擎] B --> C[模型推理] C --> D[输出结果]
一个大模型部署框架会提供哪些服务(from claude 3.5 sonnet):
核心服务能力
- 标准化接口封装
- RESTful API 接口:提供标准的HTTP接口,包含模型推理、对话管理等功能,支持同步/异步调用模式。
- WebSocket 长连接支持:实现双向实时通信,支持流式输出,减少连接建立开销,适用于需要持续对话的场景。
- 类 OpenAI API 兼容:遵循OpenAI API规范,降低用户迁移成本,支持chat/completion/embedding等标准接口。
- 服务管理能力
- 模型加载与卸载:支持动态加载不同版本模型,实现模型热更新,保证服务不中断的情况下进行模型切换。
- 多模型并行服务:支持动态加载不同版本模型,实现模型热更新,保证服务不中断的情况下进行模型切换。
- 资源动态调度:基于负载情况动态分配GPU/CPU资源,实现资源利用最大化。
- 服务监控和日志:提供详细的性能指标、资源使用率、请求统计等监控数据,支持分布式日志收集与查询。
- 性能优化特性
- 请求队列管理:实现智能排队机制,避免资源过载,支持优先级调度和超时控制。
- 批处理优化:自动将多个请求合并处理,提高GPU利用率,降低平均响应时间。
- 动态批处理:根据实时负载自动调整批处理大小,在延迟和吞吐量之间取得平衡。
- 负载均衡:支持多种负载均衡策略,确保请求均匀分布到各个服务节点。
关键服务特性
可用性保障
- 服务健康检查: 定期检测服务状态,包括模型加载状态、资源使用情况、响应时间等关键指标。
- 自动故障恢复: 检测到异常时自动重启服务,支持多级故障转移策略。
- 服务降级策略: 在系统过载时启用降级机制,如限制请求速率、降低模型精度等。
扩展性支持
水平扩展能力:支持动态增减服务节点,自动同步配置和模型文件。
多实例部署:支持单机多卡、多机多卡等多种部署方式,灵活适应不同规模需求。
服务注册与发现:集成服务注册中心,支持动态服务发现,便于集群管理
安全性机制
- 访问鉴权: 支持多种认证方式(Token/API Key/OAuth),可集成企业内部认证系统。
- 接口限流: 支持多维度限流(QPS/用户/IP),防止滥用和资源耗尽。
- 安全防护: 实现数据加密传输、敏感信息过滤、防注入等安全措施。
在推理引擎接口方面:
-
本地调用大模型:支持Python接口,这允许我们通过import导入包的方式将推理引擎引入项目进行快速的集成。
-
api调用大模型:同时也支持常见的网络服务接口(Restful和grpc),方便我们将项目和推理引擎解耦,通过网络调用的方式来访问大模型服务。
在量化技术上:
- 支持常见的weight-only量化和kv-cache量化,能够在精度损失可接受范围内,在相同的硬件条件下提供更快更长上下文的推理服务。
推理引擎方面:
-
LMDeploy 自主研发了 TurboMind 推理引擎,实现了一套高效的扩展算子用于推理,专门针对 Llama 及类 Llama 系列模型优化(也只能用于这些模型)。
-
针对自定义算子的用户,LMDeploy提供了一套Pytorch的推理后端,使用上更灵活,但效率相对低一些。
服务化能力:LMDeploy提供完整的服务化封装
- 支持类 OpenAI 接口服务。
- 可通过 Gradio 组件与大模型。
支持的大模型方面:
- 支持主流的LLM和VLM。
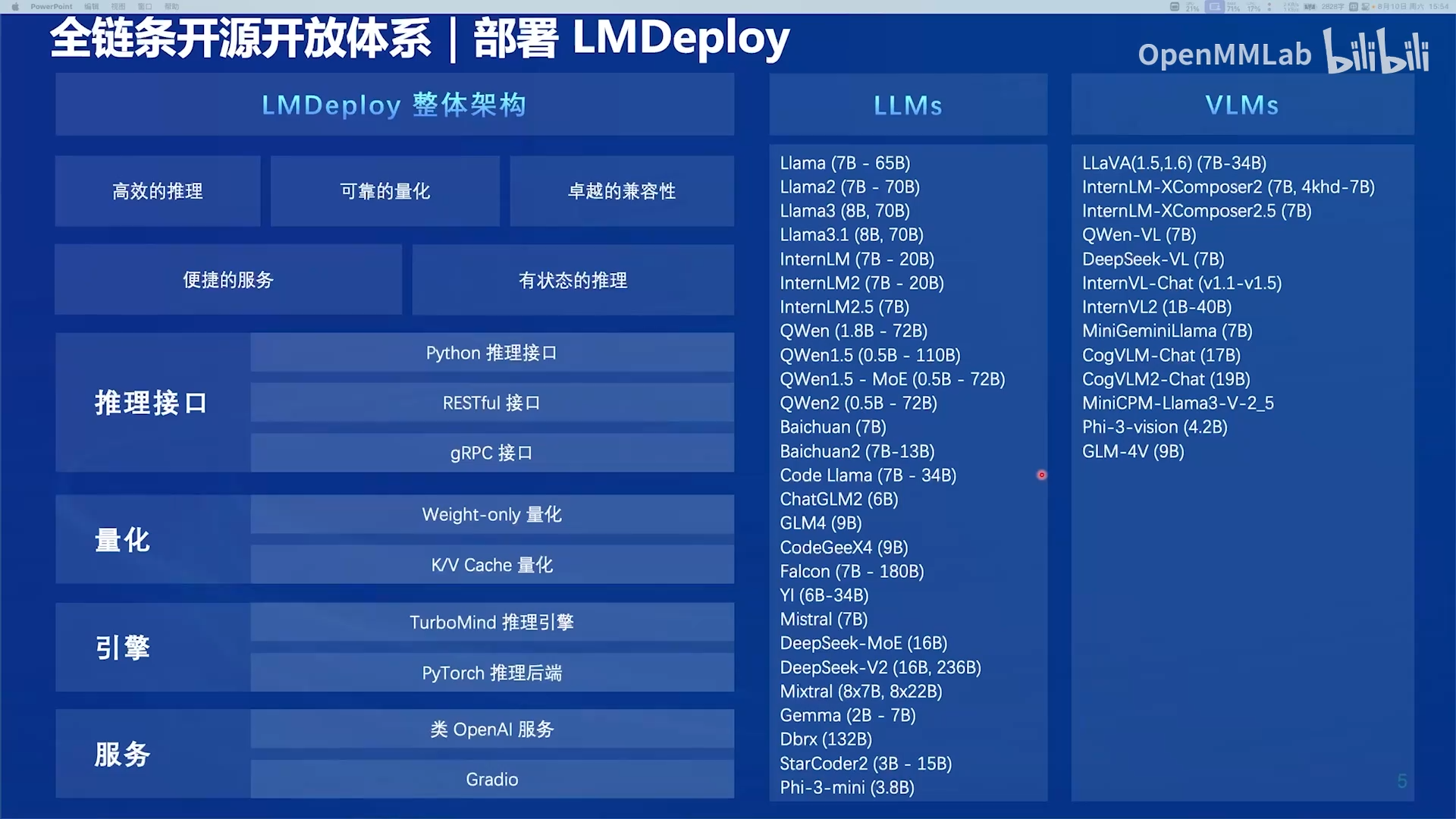
1.3 衡量部署框架性能指标
从多个用户请求来看:
- 请求吞吐量(Request throughput):,单位是
req/s,“requests per second”的缩写,也就是系统每秒处理的用户请求数。
对于单个请求,主要看以下指标:
对于目前基于 Decoder-only Transformer 架构的文本生成大模型而言,其推理过程分为两个阶段:
预填充(prefill)阶段,这一阶段会以并行方式处理输入提示中的词元(Token);
解码(decoding)阶段,又称为generation阶段,这一阶段文本会以自回归的方式逐个生成“词元”。每个生成的词元都会被添加到输入中,并被重新喂入模型,以生成下一个词元。当LLM输出了特殊的停止词元或满足用户定义的条件(例如:生成了最大数量的词元)时,生成过程就会停止。
简言之:
- 预填充(prefill)阶段:处理输入,尚未产生模型输出。
- 解码(decoding)阶段:从模型产生输出开始到所有输出产生完成结束。
LLM推理服务目标是首Token输出尽可能快、吞吐量尽可能高以及每个输出Token的时间尽可能短。就是模型服务能够尽可能快地支持尽可能多地为用户生成文本。

-
TTFT(Time to First Token):首Token响应时间,影响用户体验。从向模型输入 prompt 开始到模型生成第一个输出 token 所花费的时间,包括用户请求的排队时间(Queueing Time)和大模型推理的预填充(Prefill)阶段的时间。
-
Latency (Total Inference Time):从输入 prompt 到模型生成完整输出所消耗的总时间。总体的响应时间,包含 TTFT 和生成所有 tokens 的时间,当然对于需要快速响应的应用,延时越低越好。
-
TPOT(Time Per Output Token):模型在解码阶段 (Decoding 阶段,即输出阶段)每个输出Token的平均生成时间。用来衡量模型生成阶段自回归蹦出来输出的效率。

-
TPS(Tokens Per Second):模型每秒生成的token的数量。单位是Token/s,直接衡量模型的生成速度 (还是指 decode 阶段)。TPS 越高,表示模型生成文本的速度越快。

测试方法:见参考文章—大模型工程化实践之-大模型性能测试指标及测试方法实践
2.大模型部署技术1:大模型缓存推理技术(kv-cache)
2.1 基本原理
2.1.1 大模型推理的冗余计算
对于目前基于 Decoder-only Transformer 架构的文本生成大模型,生成输出的token步骤大致如下:
- 在prefill阶段,以并行方式处理用户输入提示中的token,得到每个用户输入token的注意力表示,接下来是generation阶段。在generation阶段的初始,使用最后一个用户输入token的注意力表示,预测得到下一个token(即第一个输出token)。
- 将预测得到的输出token,拼接到用户输入token,作为新的输入token序列,将其输入模型,得到所有输入token的注意力表示,使用新的输入token序列的最后一个token的注意力表示预测得到下一个token(即最新的输出token)。
- 将预测得到的新的输出token与原来的输入(指的是用户输入token+之前生成的输出token)拼接作为新的输入token序列,输入模型,依此类推,直到生成所有的输出token。
冗余计算:在每一步生成中,仅使用输入序列中的最后一个token的注意力表示,即可预测出下一个token。但模型还是并行计算了所有token的注意力表示,其中产生了大量冗余的计算(包含qkv映射,attention计算等),并且输入的长度越长,产生的冗余计算量越大。
举个例子:

用户输入“中国的首都”,模型续写得到的输出为“是北京”,模型的生成过程如下:
- 将“中国的首都”输入模型,得到每个token的注意力表示(绿色部分)。使用“首都”的注意力表示,预测得到下一个token为“是”(实际还需要将该注意力表示映射成概率分布logits,为了方便叙述,我们忽略该步骤)。
- 将“是”拼接到原来的输入,得到“中国的首都是”,将其输入模型,得到注意力表示,使用“是”的注意力表示,预测得到下一个token为“北”。
- 将“北”拼接到原来的输入,依此类推,预测得到“京”,最终得到“中国的首都是北京”。
冗余计算:
- 在第一步中,我们仅需使用“首都”的注意力表示,即可预测得到“是”,但模型仍然会并行计算出“中国”,“的”这两个token的注意力表示。
- 在第二步中,我们仅需使用“是”的注意力表示,即可预测得到“北”,但模型仍然会并行计算“中国”,“的”,“首都”这三个token的注意力表示。
2.1.2 从注意力表示的计算机制入手解决冗余计算
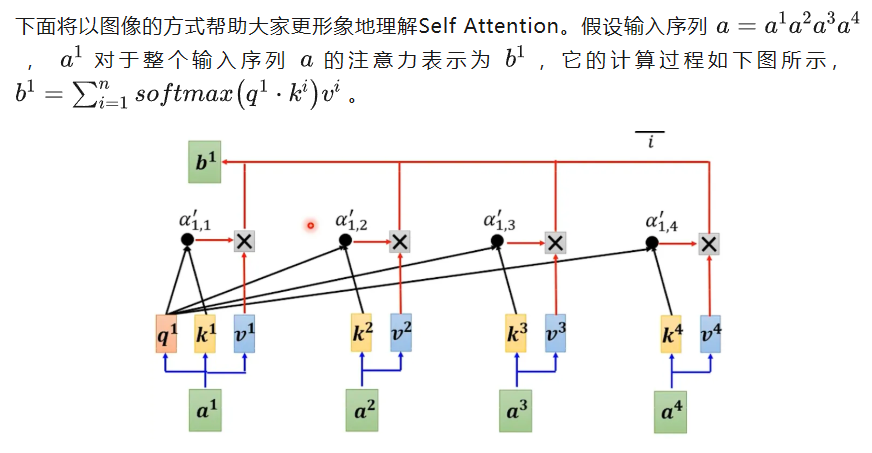
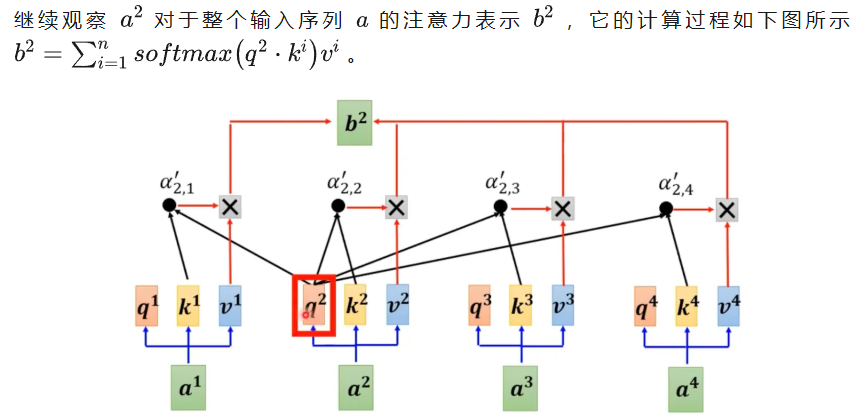
KV Cache正是通过某种缓存机制,避免上述的冗余计算,从而提升推理速度。在介绍KV Cache之前,我们有必要简单回顾self attention的计算机制,假设输入序列长度为\(n\),第\(j\)个token对于整个输入序列的注意力表示\(b^j\)如下公式:

第\(j\)个token对于整个输入序列的注意力表示的计算步骤大致如下:
- 向量映射:将输入序列中的每个token的词向量分别映射为\(q,k,v\)三个向量。
- 注意力计算:使用\(q^j\)分别与每个\(k^i\)进行点乘,得到第\(j\)个token对每个token的注意力分数。
- 注意力分数归一化:对注意力分数进行softmax,得到注意力权重。
- 加权求和:注意力权重与对应的向量\(v^i\)相乘加权,然后将所有的乘积求和,最终得到第\(j\)个token的注意力表示\(b^j\)。
2.1.3 kv-cache核心机制
在推理阶段,当输入长度为\(n\),我们仅需使用\(b^n\)即可预测出下一个token,但模型却会并行计算出\(b^1 \dots b^{n-1}\) ,这部分会产生大量的冗余计算。而实际上\(b^n\)可直接通过公式\(b^n = \sum_{i=1}^{n}softmax(q^n \cdot k^i)v^i\)算出,即\(b^n\)的计算只与\(q^n\)、所有\(k\)和\(v\)有关。
KV Cache的本质是以空间换时间,它将历史输入的token的\(k\)和\(v\)缓存下来,避免每步生成都重新计算历史token的\(k\)和\(v\)以及注意力表示\(b^1 \dots b^{n-1}\),而是直接通过\(b^n = \sum_{i=1}^{n}softmax(q^n \cdot k^i)v^i\)的方式计算得到\(b^n\),然后预测下一个token。
举个例子,用户输入“中国的首都”,模型续写得到的输出为“是北京”,KV Cache每一步的计算过程如下。
第一步生成时,缓存\(K,V\)均为空,输入为“中国的首都”,模型将按照常规方式并行计算:
- 并行计算得到每个token对应的\(k,v\),以及注意力表示\(b^1 \dots b^3\)。
- 使用\(b^3\)预测下一个token,得到“是”。
- 更新缓存,令\(K=[k^1,k^2,k^3]\),\(V=[v^1,v^2,v^3]\)。

第二步生成时,计算流程如下:
- 仅将“是”输入模型,对其词向量进行映射,得到\(q^4,k^4,v^4\)。
- 更新缓存,令\(K=[k^1,k^2,k^3,k^4]\),\(V=[v^1,v^2,v^3,v^4]\)。
- 计算\(b^4 = \sum_{i=1}^{4}softmax(q^4 \cdot k^i)v^i\),预测下一个token,得到“北”。

第三步生成时,计算流程如下:
- 仅将“北”输入模型,对其词向量进行映射,得到\(q^5,k^5,v^5\)。
- 更新缓存,令\(K=[k^1,k^2,k^3,k^4,k^5]\),\(V=[v^1,v^2,v^3,v^4,v^5]\)。
- 计算\(b^5 = \sum_{i=1}^{5}softmax(q^5 \cdot k^i)v^i\),预测下一个token,得到“京”。

上述生成流程中,只有在第一步生成时,模型需要计算所有token的\(k,v\),并且缓存下来。此后的每一步,仅需计算当前token的\(q,k,v\),更新缓存\(K,V\),然后使用\(q,K,V\)即可算出当前token的注意力表示,最后用来预测一下个token。
通过避免重复计算历史token的\(K\)和\(V\),将每次生成注意力表示的时间复杂度从\(O(n^2)\)降至\(O(n)\):
- 未使用kv-cache:生成一个\(b^n\)需要\(n\)次计算,\(b^n = \sum_{i=1}^{n}softmax(q^n \cdot k^i)v^i\),每次都要生成所有的\(b^i\),当输入序列长度为\(n\)时,复杂度为\(O(n^2)\)。
- 使用kv-cache:只需要做\(b^n = \sum_{i=1}^{n}softmax(q^n \cdot k^i)v^i\)这\(n\)次运算即可,复杂度为\(O(n)\)。
2.2 kv-cache的缺陷
参考文章-【每日一题】【大模型】Day10-KV Cache
KV Cache实际上是一种用空间来换时间的做法,因此不可避免地带来一些新的问题:
- 第一,通常情况下,在gpu上做大模型的推理时,当输入序列非常长的时候,需要缓存非常多k和v,显存占用非常大,更多的显存占用一方面限制了序列的总长度,影响了上下文的最大窗口长度;另一方面也限制了一次能处理的序列的总数量,也就是batch_size,进而影响到了系统的吞吐量。
- 第二,KV Cache减少了gpu在一次推理中的运算量,但是花费了更多的时间在读取缓存数据上。通常,加载1MB的数据到GPU核中的时间,比在GPU核上对1MB的数据做计算的时间更长,因此KV Cache开启后可能会导致GPU的使用率比较低,从成本上来讲这也是不划算的。
为了缓解该问题,可以使用MQA、GQA、Page Attention(分页注意力)等技术。比如PageAttention是一种用于有效处理Transformer模型中长序列的技术,它通过将注意力计算分解为更小、更易于管理的“页”或“块”来实现。这种方法降低了内存消耗和计算复杂度,从而能够处理原本因过大而无法放入内存的序列,可以缓解输入序列过长时,kv-cache显存占用大的问题。
2.3 Hungging Face对于KV Cache的实现
query, key, value = self.c_attn(hidden_states).split(self.split_size, dim=2)
query = self._split_heads(query, self.num_heads, self.head_dim) # 当前token对应的query
key = self._split_heads(key, self.num_heads, self.head_dim) # 当前token对应的key
value = self._split_heads(value, self.num_heads, self.head_dim) # 当前token对应的value
'''
重点:kv-cache的实现
'''
if layer_past is not None:
past_key, past_value = layer_past # KV Cache
key = torch.cat((past_key, key), dim=-2) # 将当前token的key与历史的K拼接
value = torch.cat((past_value, value), dim=-2) # 将当前token的value与历史的V拼接
if use_cache is True:
present = (key, value)
else:
present = None
# 使用当前token的query与K和V计算注意力表示
if self.reorder_and_upcast_attn:
attn_output, attn_weights = self._upcast_and_reordered_attn(query, key, value, attention_mask, head_mask)
else:
attn_output, attn_weights = self._attn(query, key, value, attention_mask, head_mask)
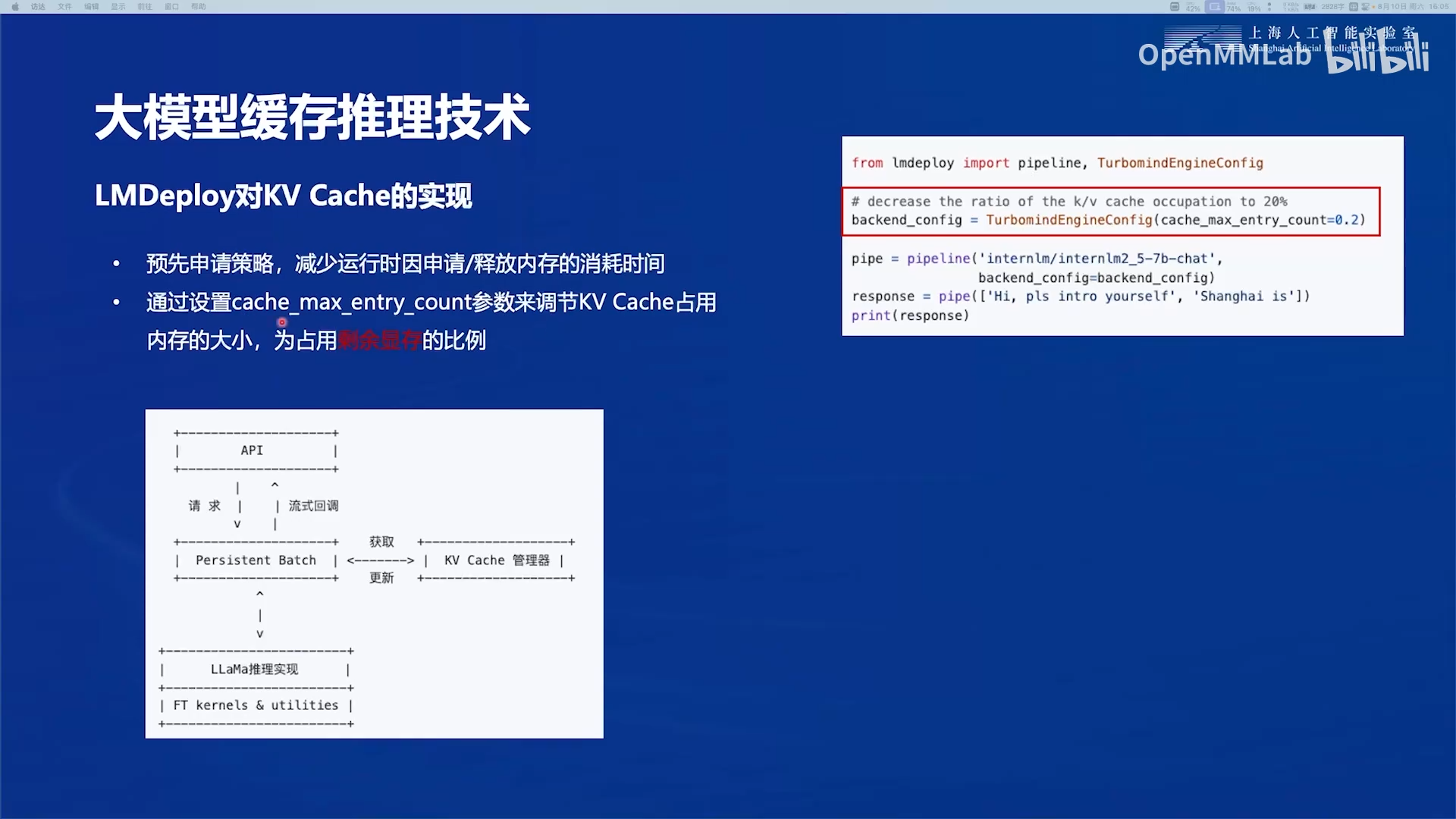
2.4 LMDeploy对kv-cache的实现
使用预先申请策略,减少运行时因申请/释放内存的消耗时间。因此在使用时会发现模型量化前后占用的显存大小没有变化,但实际上量化之后kv-cache的显存占用会变低,可以处理更长的输入序列。
下图代码的作用:告知LMdeploy最多可以使用加载完模型权重之后剩余显存的20%,则它会将全部的20%的显存预先占用,不论一开始是否可以用满。
3. 大模型部署技术2:大模型量化技术
3.1 基本原理
量化可以减少模型权重占用的体积。比如一个405B的大模型,如果采用传统的16位浮点数(fp16)储存,则1个参数占用2字节的空间,则要将整个模型加载到GPU中需要\(405Billion \times 2Byte= 405e9 \times 2Byte = 810e9 Byte\),约等于810GB的显存。如果将16位浮点数转为4bit的整数,则1个参数占用的空间降为原来的\(\frac{1}{4}\),整个模型权重占用的显存降为202GB,一个8卡的A100服务器总共有640GB显存,可以支持。剩下的显存空间可以用于存储更多的kv-cache,支持更长的上下文,或者同时处理更多用户的请求。
量化的思路:将原来的浮点数区间线性映射为整数。
激活值量化:
- 激活值:在线性层,\(Y=WX+b\),\(W\)是模型权重,\(X\)就是激活值。
训练后量化,将模型训练好之后,通过简单的数据集标定等方式,不需要额外训练,即可完成量化,属于较优的策略。量化感知训练和量化感知微调,在模型训练完成后,通常还需要额外的微调,来完成量化,生产中通常不会采用。

3.2 LMDeploy的量化方案
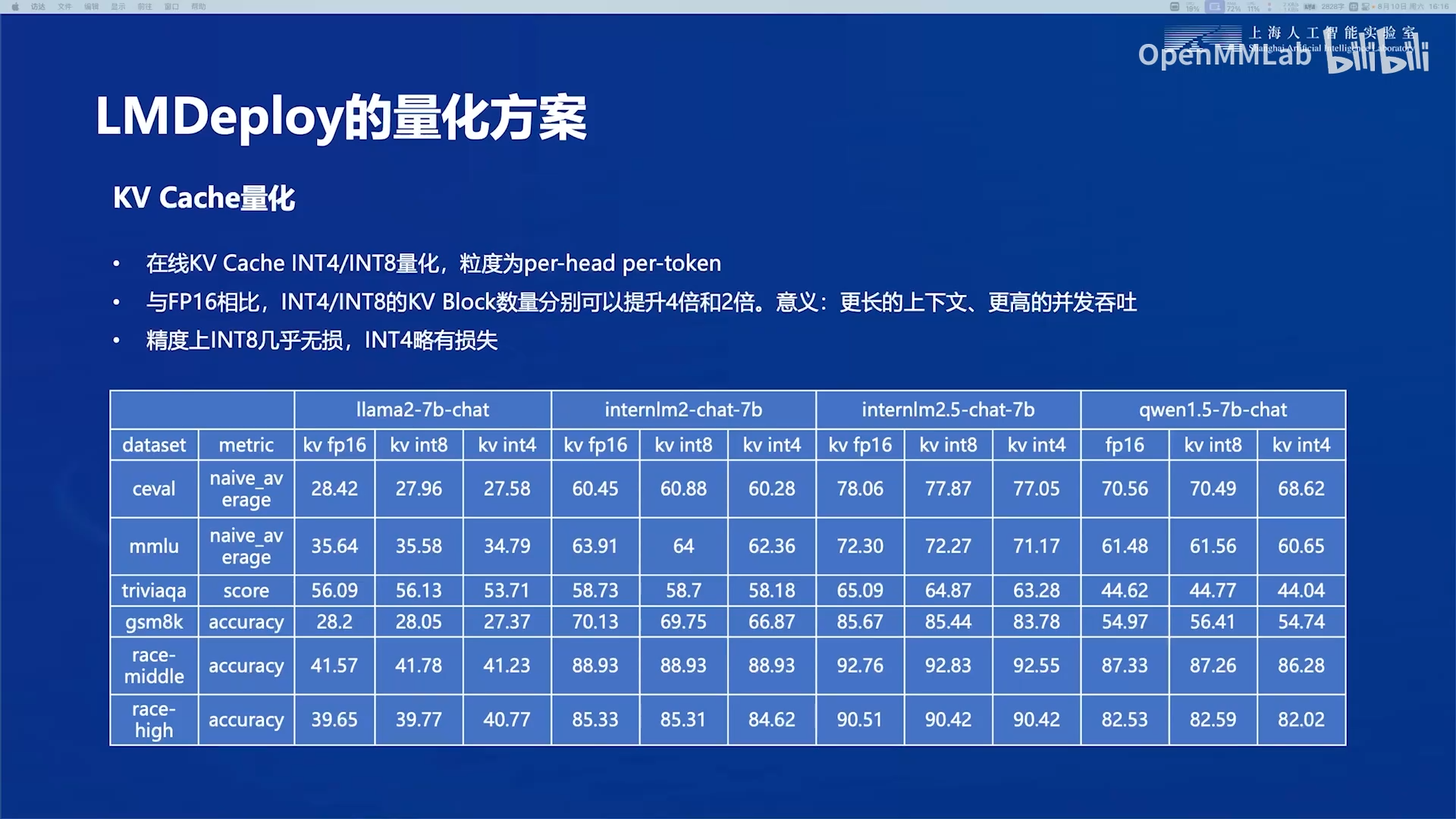
3.2.1 kv-cache量化
3.2.2 模型权重量化
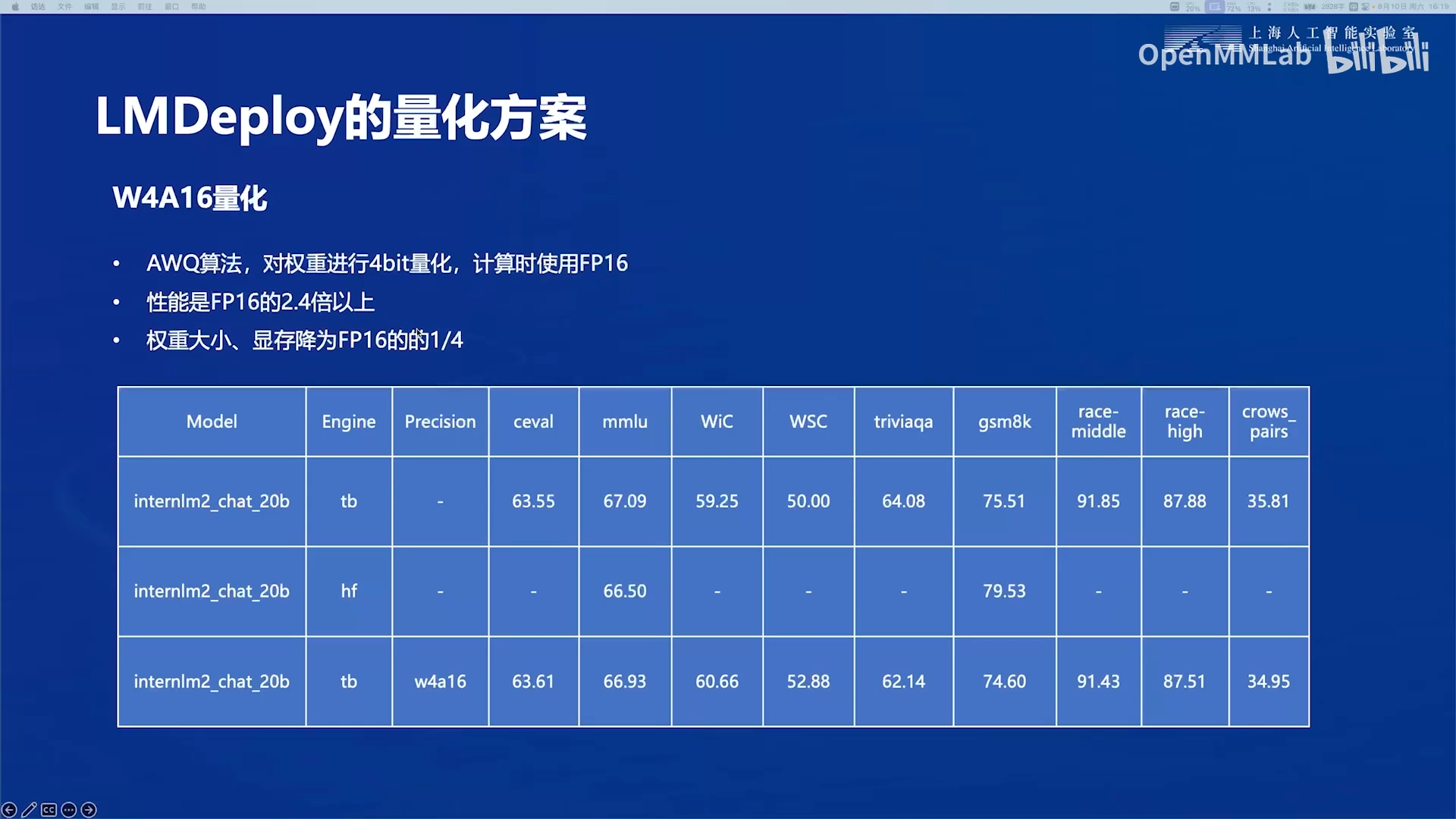
-
W4A16量化:采用AWQ算法,对weight(权重)做4bit整数量化存储,Activation(激活值)不做量化。在计算时,需要将模型权重反量化为fp16,与激活值进行计算。
注意:AWQ量化 != W4A16量化
AWQ是一种对模型权重进行低比特量化的方法,使用该方法可以将模型权重(Weight)量化为4bit,并在计算激活值(Activation)时反量化为FP16,即W4A16。也可以基于AWQ方法将权重量化为3bit/8bit,并在计算时是使用4bit/8bit/16bit,由此衍生出W4A4、W4A8等一系列方法。
W4A16可以在精度损失较小的情况下,大幅降低内存占用,且提升模型推理速度,是最常用的方法,因此AWQ和W4A16同镜率较高。
总结:W4A16是根据量化程度命名的,它可以采用AWQ算法实现,也可以采用其他算法实现。
-
性能(推理速度)是不量化,模型权重以fp16存储的2.4倍以上。
原因:在推理的解码(decode)阶段,大模型的decoder结构使得显卡处于超高速访存的状态。在大模型推理中,显卡的性能瓶颈不在计算上,而在于数据传输的带宽。4bit的模型权重可以传输更多的参数,减少了IO操作的次数,这带来的性能提升比起将其反量化为fp16的额外计算量大。
拓展阅读(todo)
3.3 模型权重量化的AWQ算法
3.3.1 AWQ算法原理
AWQ(Activation-aware Weight Quantization)量化是一种基于激活值分布(activation distribution)挑选显著权重(salient weight)进行量化的方法,其不依赖于任何反向传播或重建,因此可以很好地保持LLM在不同领域和模式上的泛化能力,而不会过拟合到校准集,属训练后量化(Post-Training Quantization, PTQ)大类。
核心观点1:权重并不同等重要,仅有小部分显著权重对推理结果影响较大
作者指出,模型的权重并不同等重要,**仅有0.1%1%的小部分显著权重对模型输出精度影响较大**。因此如果能有办法只对0.1%1%这一小部分权重保持原来的精度(FP16),对其他权重进行低比特量化,就可以在保持精度几乎不变的情况下,大幅降低模型内存占用,并提升推理速度。这就涉及到一个问题,如何鉴别显著权重,常用的方法有三种:
- 随机挑选:听天由命,随机选出0.1%~1%的权重作为显著权重,当然这种方法很不科学。
- 基于权重分布挑选:对权重矩阵(比如自注意力中的 \(W_q\) , \(W_k\) , \(W_v\) )中的元素按绝对值大小由大到小排序,绝对值越大越显著,选择前0.1%~1%的元素作为显著权重。
- 基于激活值分布挑选:作者用“激活值”一词很具有迷惑性,查阅了很多blog都没太确定其具体含义,阅读源码后确定,激活值就是与权重矩阵作matmul运算的输入值,比如自注意力机制中,计算 \(Q=W_q X\) , \(K=W_k X\) , \(V=W_vX\) , \(O=W_o[softmax(KQ^\top)V]\), \(X\) 就是 \(W_q\) 、 \(W_k\) 和 \(W_v\) 的激活值, \([softmax(KQ^\top)V]\) 是 \(W_o\) 的激活值。按激活值绝对值大小由大到小排序,绝对值越大越显著,选择前0.1%~1%的元素作为显著权重。
作者分别对三种方法进行了实验,将PPL(越小模型精度越高)作为评估指标,发现:
- 随机挑选显著权重(random列)的方式与对所有权重进行低比特量化(RTN列)的性能差不多,预料之内;
- 基于权重分布挑选(base on W列)的方式与随机挑选(random列)差不多,这是打破常规认知的,因为很多量化方法都是基于该方式挑选显著权重;
- 基于激活值分布挑选(based on act.列)的方式相比FP16几乎没有精度损失,是重大发现。
- 表格解读:表格中的数字都是PPL值,第1~3行分别是三个模型在不同情况下的PPL值,每一列表示三个模型在某种情况下的PPL值。比如FP16列表示未进行模型量化时的PPL值,RTN列表示将所有权重低比特量化的PPL值。

因此,基于激活值分布挑选显著权重是最为合理的方式。只要把这部分权重保持FP16精度,对其他权重进行低比特量化,就可以在保持精度几乎不变的情况下,大幅降低模型内存占用,并提升推理速度。
这里还有一个细节,作者为了避免方法在实现上过于复杂,在挑选显著权重时,并非在“元素”级别进行挑选,而是在“通道(channel)”级别进行挑选,即权重矩阵的一行作为一个单位。在计算时,首先将激活值对每一列求绝对值的平均值,然后把平均值较大的一列对应的通道视作显著通道,保留FP16精度。对其他通道进行低比特量化,如下图:
中间的图示解释:\(X\)矩阵是激活值,每一行是一个token,每个token都是一个embedding向量,向量的维度是hidden_size。token的数量,即embedding向量的行数是sequence_length。激活值的第二列是绝对值平均值最大的,这里将\(X\)与\(Q(W)\)相乘,\(X\)的第2列总是与\(Q(W)\)的第2行相乘,因此\(Q(W)\)的第2行作为显著通道。
%E6%B7%B1%E5%85%A5%E7%90%86%E8%A7%A3AWQ%E9%87%8F%E5%8C%96%E6%8A%80%E6%9C%AF_Coder.AN/(20240617)%E6%B7%B1%E5%85%A5%E7%90%86%E8%A7%A3AWQ%E9%87%8F%E5%8C%96%E6%8A%80%E6%9C%AF_Coder.AN/v2-1ade13e5b253be2c830d5f81aac5fb90_1440w.jpg)
但另一个问题随之而来,如果权重矩阵中有的元素用FP16格式存储,有的用INT4格式存储,不仅存储时很麻烦,计算时取数也很麻烦,kernel函数写起来会很抽象。
于是,作者想了一个变通的方法——Scaling。
核心观点2:量化时对显著权重进行放大可以降低量化误差
这个创新点不像是正常人能想出来的,请先顺着推导的思路来看。
考虑一个权重矩阵\(\textbf{w}\) ,线性运算可以写作\(y=\textbf{w}x\) 。对权重矩阵进行量化后,可以写作 \(y=Q(\textbf{w})x\) ,量化函数 \(Q(\cdot)\) 定义为公式1:

其中 \(N\) 是量化后的比特数, \(\Delta\) 是量化因子(scaler)。 \(\textbf{w}'=\text{Round}(\frac{\text{w}}{\Delta})\) 是量化过程, \(\Delta\cdot\text{w}'\) 是反量化过程。因为\(\Delta\)的分子是权重矩阵中所有元素的绝对值的最大值。\(\textbf{w}\)中的每个元素除以分子的商的范围在-1到1之间,然后乘上\(2^{N-1}\),则矩阵\(\frac{\textbf{w}}{\Delta}\)的每个元素都在\(-2^{N-1}\)到\(2^{N-1}\)之间。一个\(N\)bit的整数的表示范围是\(-2^{N-1}\le intN \lt 2^{N-1}\),因此可以用\(N\)bit来表示\(\frac{\textbf{w}}{\Delta}\)中的元素。然后使用\(\text{Round}\)将小数去除,就完成了\(N\)bit量化。实际上这篇论文的代码中并没有完全按照公式,\(\Delta\)的分母都不是\(2^{N-1}\)。

原始的 \(\text{w}\) 、 \(\Delta\) 和输入 \(x\) 都是FP16格式,不会带来精度损失。整个过程的精度损失全部来源于量化过程中的 \(\text{Round}\) 取整函数,其误差近似成[0, 0.5]的均匀分布,期望为0.25,可以写作 \(\text{RoundErr}(\cdot) \sim 0.25\) 。
考虑对于权重矩阵 \(\text{w}\) 中的单个元素 \(w\) ,引入一个缩放因子 \(s>1\) ,量化过程将 \(w\) 与该因子相乘,写作 \(\text{w}'=\text{Round}(\frac{\text{w}s}{\Delta'})\) ,相应地将反量化过程写作 \(\frac{\Delta'}{s}\cdot\text{w}'\),这样在计算过程上是“等价”的,如公式2:

虽然公式1和公式2在计算过程上是“等价”的,但是带来的精度损失是不一样的。两种计算方法的误差可以写作公式3:

\(\text{RoundErr}(\cdot)\) 视作常数0.25,公式2的误差与公式1的误差的比值可以表示为 \(\frac{\Delta'}{\Delta}\cdot \frac{1}{s}\) 。
通常情况下,我们对权重矩阵 \(\text{w}\) 中的某几个元素 \(w\) ,乘以缩放因子 \(s\) 后,大概率是不会影响权重矩阵 \(\text{w}\) 的元素最大值的,除非乘的 \(w\) 本身就是最大值,但这种概率很小。进而,根据公式1中 \(\Delta\) 的计算方法,我们认为 \(\Delta'\approx\Delta\)。加上 \(s>1\) ,公式2与公式1的误差比值<1,即公式2(量化中进行权重放大)的量化误差比公式1(朴素的量化)小。于是作者提出一个观点:量化时对显著权重进行放大,可以降低量化误差。
这种理论是否正确?作者进行了实验,如下表,随着 \(s\) 的增大, \(\Delta'\ne\Delta\) 的概率由0不断升高,但在 \(s<2\) 之前,概率还是很低的(<5%);同时,在一定范围内,随着 \(s\) 的增大,误差比值越来越小,这是完全支持作者观点的。
表格解释:从表格第1行可以看出,\(s=1.25\)时,有97.2%的概率\(\Delta'= \Delta\)。从表格第3行可以看出,随着\(s\)的增大,公式2与公式1的误差比值越来越小,由于公式1是固定的朴素量化误差,则说明\(s\)越大,采用对显著权重进行放大的量化方法的量化误差就越小,即量化后模型的精度越高。

因此,作者改变了思路:为了更加hardware-friendly,我们对所有权重均进行低比特量化,但是,在量化时,对于显著权重乘以较大的 \(s\) ,相当于降低其量化误差;同时,对于非显著权重,乘以较小的 \(s\) ,相当于给予更少的关注。这便是缩放(Scaling)方法。
算法:自动计算缩放(scaling)系数
按照上文的分析,我们需要找到权重矩阵每个通道的缩放系数 \(\text{s}\) ,使得量化误差最小,即最小化公式4:

但是,量化函数 \(Q(\cdot)\) 是不可微的,我们无法使用梯度下降法优化求解上式。同时,上式是非凸的,使得该问题的求解更加困难。
从公式4可以看出,\(s\)是经过对角化得到方阵后与权重矩阵\(W\)相乘的。
按照作者的观点,激活值越大,对应通道越显著,就应该分配更大的缩放系数降低其量化误差。因此,作者统计了各通道的平均激活值(计算输入矩阵各列绝对值的平均值) \(\text{s}_\text{x}\),并直接将此作为各通道的缩放系数。同时引入一个变量 \(\alpha\) 用于平衡显著通道和非显著通道的系数,由此,问题转化为:
%E6%B7%B1%E5%85%A5%E7%90%86%E8%A7%A3AWQ%E9%87%8F%E5%8C%96%E6%8A%80%E6%9C%AF_Coder.AN/(20240617)%E6%B7%B1%E5%85%A5%E7%90%86%E8%A7%A3AWQ%E9%87%8F%E5%8C%96%E6%8A%80%E6%9C%AF_Coder.AN/v2-06b3186dd5d27926cb668dc21508eb68_1440w.jpg)
这里有个细节作者没有提,通过阅读源码发现,为了防止 \(\text{s}\) 过大或者过小,作者还进行了一步数据标准化:

注意在求 \(\alpha\) 时,会参照超参数group_size对通道进行分组,每组共享一个 \(\alpha\) 。
现在的问题就转换成了找最合适的 \(\alpha\) ,只优化一个数肯定比公式4中优化一堆缩放系数容易。作者在论文中提到,采用一种称为“Fast Grid Search”的方法即可在[0, 1]区间快速找出最合适的 \(\alpha\) ,具体实现是_search_module_scale函数。
3.3.2 LMDeploy中AWQ算法的参数
-
--calib-dataset:标定数据集,提供激活值\(X\),AWQ算法可以做到量化后的模型权重不会过拟合到校准集。 -
--calib-sampls:数据集的样本数量。 -
--calib-seqlen:样本的长度,每个样本的token个数,即\(X\)矩阵的行数(\(X\)矩阵每一行是一个token,每个token都是一个embedding向量,向量的维度是hidden_size。token的数量,即embedding向量的行数是sequence_length)。 -
--w-bits:量化位数。 -
--w-group-size:分组通道数-
group-size,分组大小。对于\(X\)矩阵按列分组,即hidden_size分为若干组。
-
group-size较大时,每组权重较多,量化参数较少,可能会降低量化后的模型精度,但计算和存储成本低。
-
group-size较小时,每组权重较少,量化参数较多,模型精度可能更高,但计算和存储成本增加
-
业界常用默认值128
-
-
--search-scale:True或False,是否对公式5中的\(\alpha\)参数做优化。

3.3.3 AWQ对设备端部署更友好
- 避免了混合精度,加速计算:硬件(如CPU、GPU、嵌入式设备)在处理统一的低比特位数据时更高效。混合精度会增加硬件设计和实现的复杂度,降低计算效率。AWQ的\统一的低比特位量化使得硬件能够充分利用数据并行性和SIMD指令,加速计算。
- 减少存储和内存需求,对内存带宽受限的设备友好:通过将权重量化为低比特位,模型的存储大小大幅减少;同时降低了对内存带宽的需求,提高了内存访问效率。
4. 大模型部署技术3:大模型外推技术
4.1 什么是外推
训练和预测的长度不一致:这里的长度指的是输入的上下文长度,即输入的token序列的长度。举个例子,训练时的文本在分词后最多是8192个token,而在预测时可能输入超长的文本,分词后的token数量超过了8192个,这时候就需要外推技术,这种技术可以在不额外训练模型的情况下,使其可以处理更长的序列。这种技术对于提升模型在实际应用中的泛化性至关重要,尤其在处理长文本推理、代码生成等场景中。
位置编码:能够让每个词向量(token对应的embedding向量)都能够感知到它在输入序列中所处的位置信息,对于模型的位置编码能力与训练时的输入长度有很大关系,因此当预测时提供超出训练的最大长度的输入序列时,会导致两个问题:
- 位置编码未覆盖:超出训练长度的位置无法生成合理的位置向量。
- 注意力熵偏移:长序列的注意力分布更均匀(熵更大),而短序列训练时注意力更集中(熵更小),导致模型对长序列的注意力机制失效。

大模型的外推性目前主要在这两个方面考虑,也是提升最有效的两个角度:
- 寻找或设计合适的位置编码;
- 设计局部注意力机制。
4.2 从位置编码角度提升外推能力
在transformer之前,大家处理序列问题的时候都是用循环神经网络,循环神经网络最大的一个问题是
就在输入序列时候需要逐个输入,不能并行输入。自注意力机制虽然解决了并行输入的问题,也导致了一个新的问题,就是理论上输入的多个嵌入向量对于注意力机制来说是等价的。也就是说,注意力机制并不具备区分token相对位置的能力。所以说我们就需要给每一个embedding向量再增加一个位置编码,从而让我们的这个注意力机制能够识别embedding向量的相对位置关系。
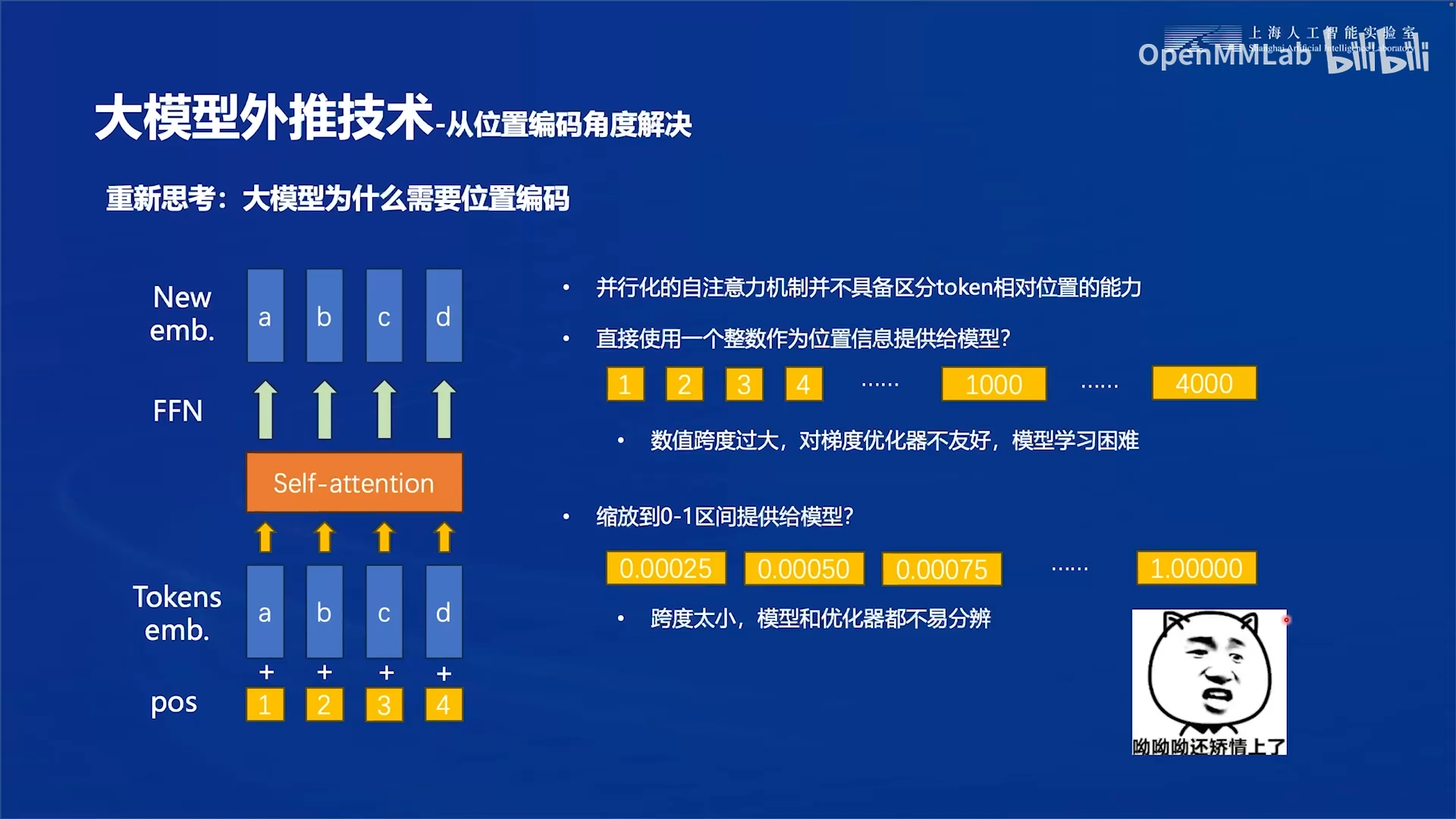
用一个整数表示位置有诸多缺点,因此我们考虑使用一组向量来表示位置,即位置向量。
下图中从十进制1234分别拆出1,2,3,4是一个常用的算法,可以推广到任意进制。

了解了用进制来构建位置向量的思想后,我们来看一下“Attention is all you need”中提出的Sinusoidal位置编码。
- 做一个换元操作:\(\beta = \theta^{\frac{2}{d}}\),则有\(\theta^{\frac{2i}{d}}=\beta^i\)
- 原来是mod进制的基数,其实是利用了取模的周期性,取模的结果总是在\(-(\beta-1)\)到\(\beta -1\)之间。

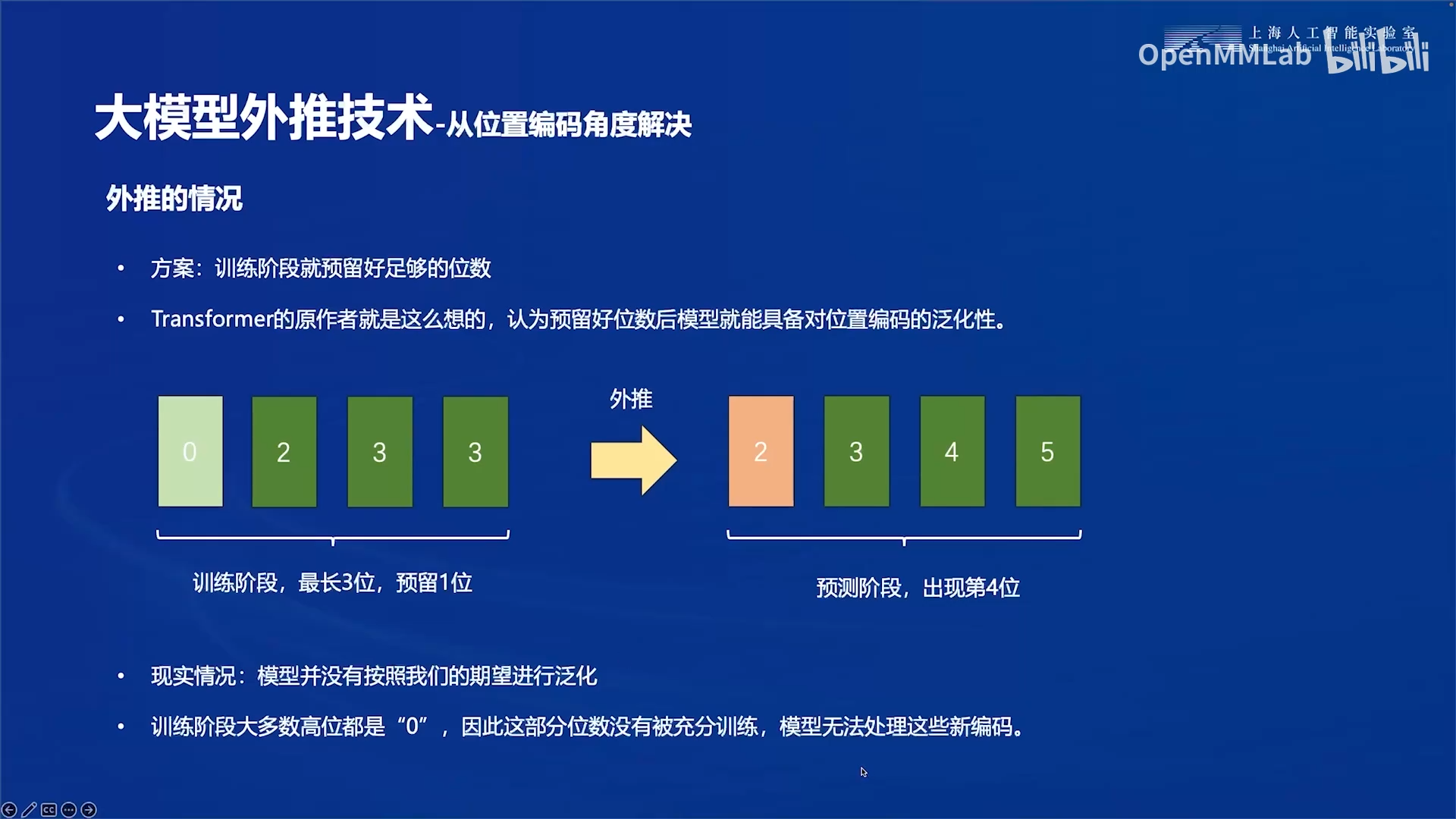
现在我们再来看外推的情况。

transformer论文的解决方法是预留好足够的位数,现实情况是模型并没有按照我们的期望进行泛化。
经过实验发现,模型至多能外推20%到30%,超过了限度后,模型的效果会断崖下跌,输出效果基本上就是一种乱码的状态。
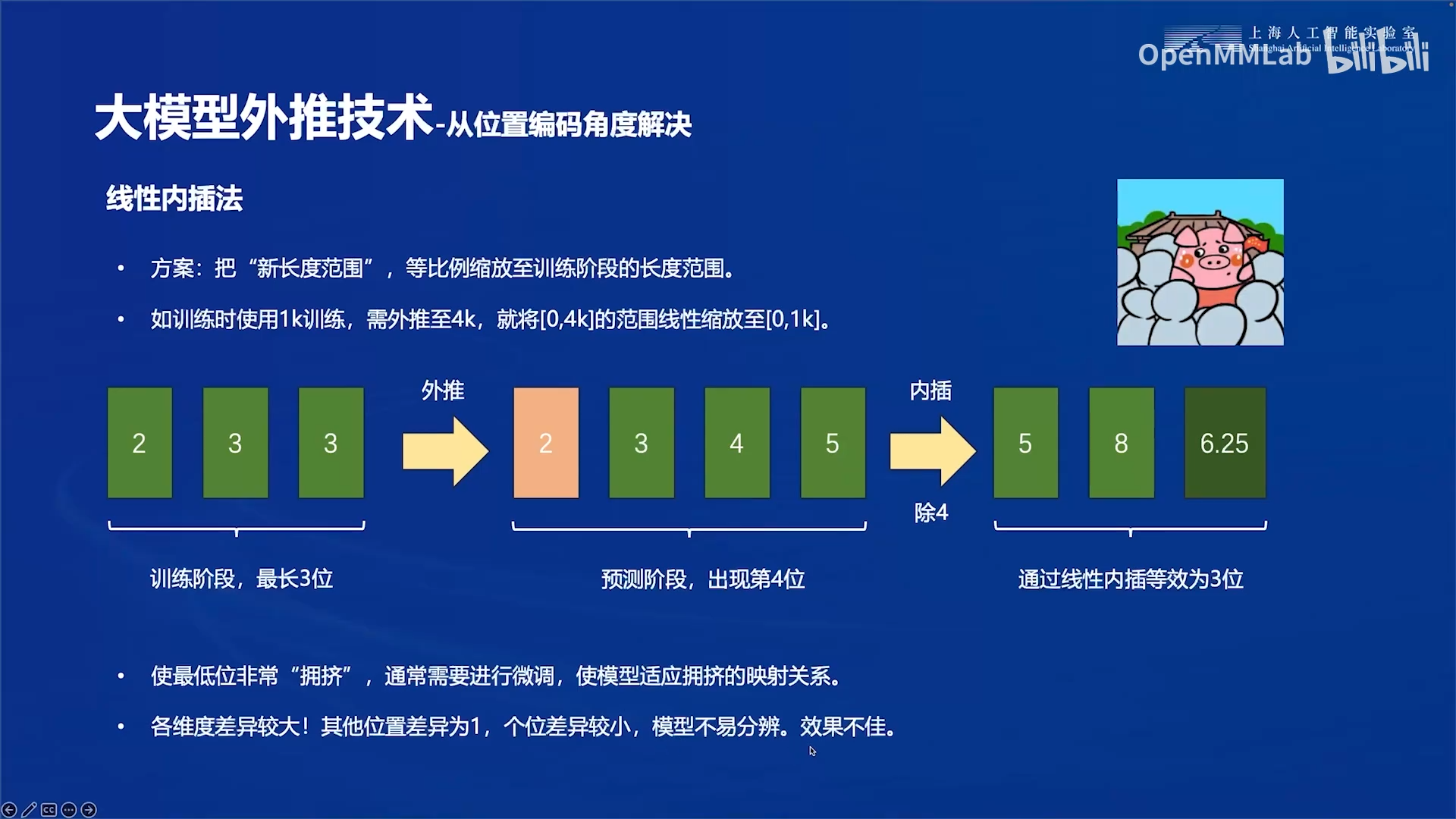
预留位数不行,又提出了线性内插法:
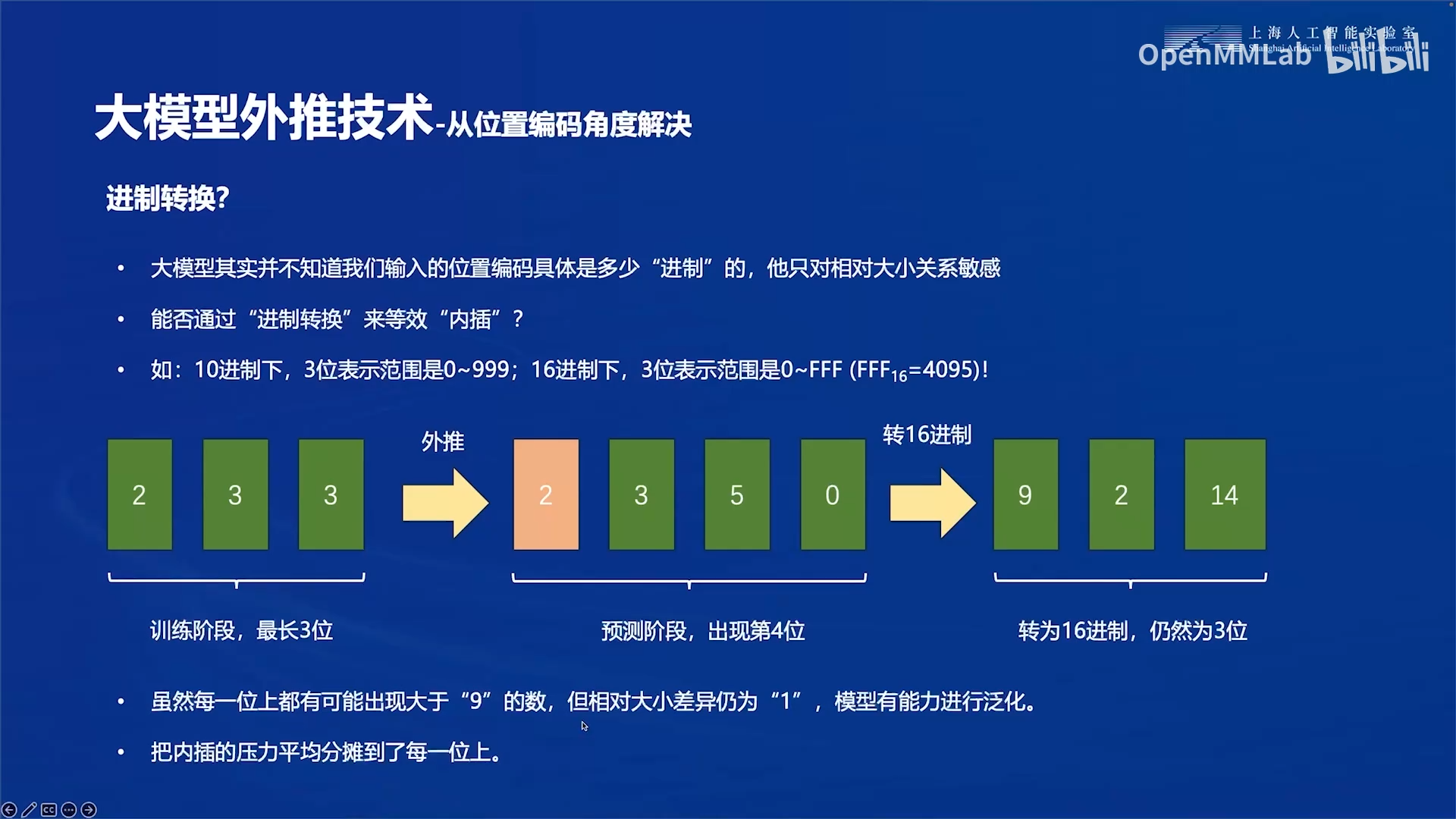
线性内插法也有缺陷,又提出了进制转换的方法:
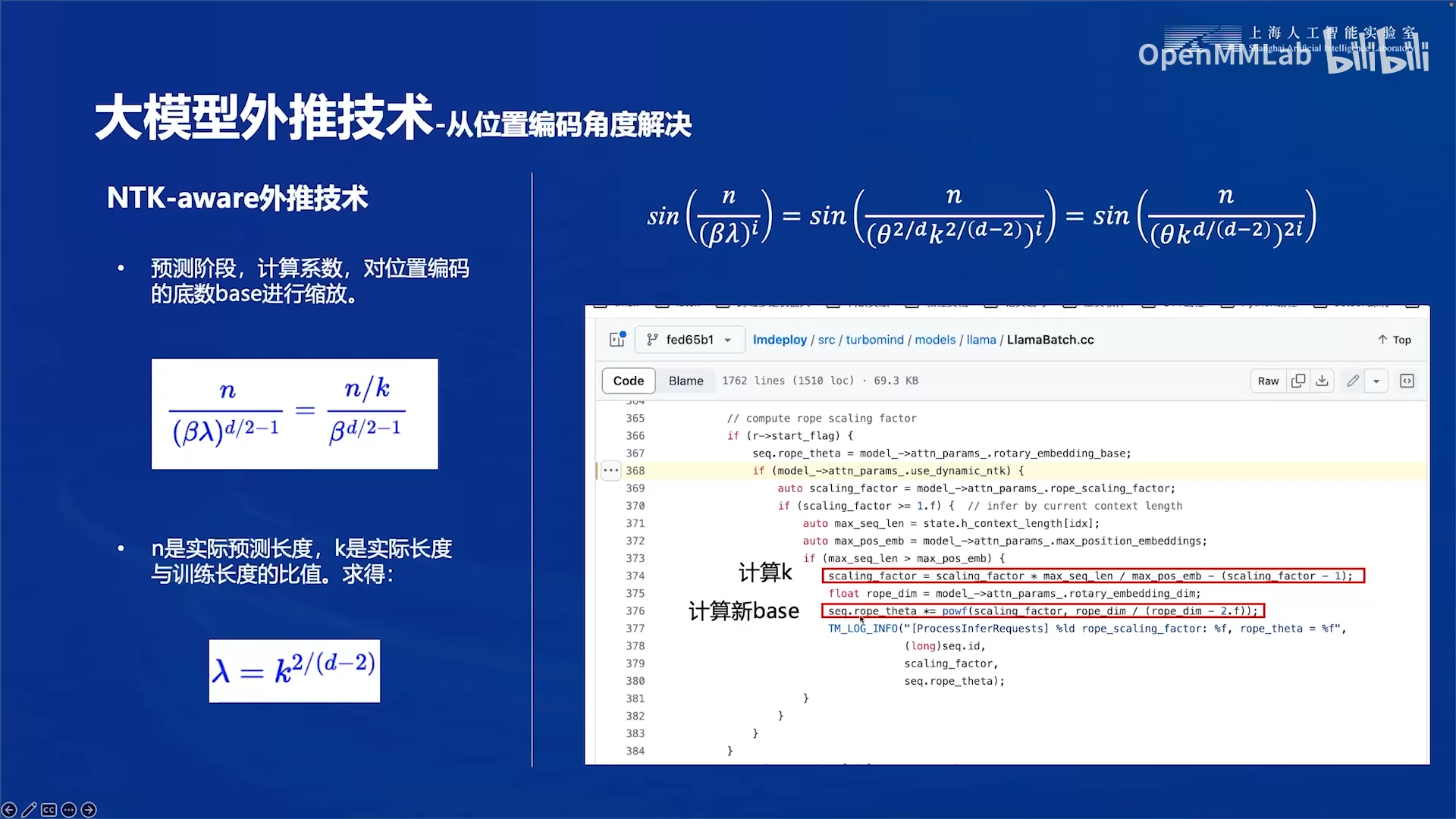
基于进制转换的思想,提出了NTK-aware外推技术:
n是实际预测时的长度,大于训练时的最大位置。等式右边是线性内插法,分子对n除以k,放缩到训练的范围内。等式左边是进制转换法,对base乘以\(\lambda\)进行扩大。k可以通过两个范围的比值算出,则\(\lambda\)可以用等式得到。
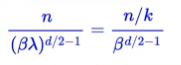
5. LMDeploy新特性:Function Calling

6. 实践
6.1 环境准备
conda create -n lmdeploy_l2 python=3.10 -y
conda activate lmdeploy_l2
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia -y
pip install timm==1.0.8 openai==1.40.3 lmdeploy[all]==0.5.3
pip install datasets==2.19.2
6.2 LMDeploy常用命令
6.2.1 由本地模型启动API服务器
通用格式如下:
lmdeploy serve api_server \
"本地模型路径" \
--model-format "本地模型格式" \
--quant-policy 整数,kv-cache量化位数 \
--cache-max-entry-count kv-cache占用剩余显存的比例 \
--server-name ip地址 \
--server-port 端口号 \
--tp 可使用的GPU数量
-
本地模型格式:
- hf:hugging face格式
- awq:经过awq算法量化模型权重后的格式
-
kv-cache量化位数:
-
0:表示kv-cache不量化。
-
4 表示 kv-cache int4 量化
-
8:表示 kv-cache int8 量化。
-
示例:
lmdeploy serve api_server \
/root/models/internlm2_5-7b-chat \
--model-format hf \
--quant-policy 0 \
--cache-max-entry-count 0.4\
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1
命令解释:
lmdeploy serve api_server:这个命令用于启动API服务器。/root/models/internlm2_5-7b-chat:这是模型的路径。--model-format hf:这个参数指定了模型的格式。hf代表“Hugging Face”格式。--quant-policy 0:这个参数指定了量化策略。--cache-max-entry-count:0.4,即kv-cache会占用加载模型权重后的剩余显存的40%。--server-name 0.0.0.0:这个参数指定了服务器的名称。在这里,0.0.0.0是一个特殊的IP地址,它表示所有网络接口。--server-port 23333:这个参数指定了服务器的端口号。在这里,23333是服务器将监听的端口号。--tp 1:这个参数表示并行数量(GPU数量)。
6.2.2 以Gradio网页形式连接API服务器
首先要使用6.2.1的命令启动api服务器
输入以下命令,使用Gradio作为前端,启动网页。
lmdeploy serve gradio http://localhost:23333 \
--server-name 0.0.0.0 \
--server-port 6006
http://localhost:23333:api服务的地址,与启动时指定的保持一致。--server-name 0.0.0.0:这个参数指定了服务器的名称。在这里,0.0.0.0是一个特殊的IP地址,它表示所有网络接口。--server-port:网页启动的端口
6.2.3 以命令行形式连接API服务器
首先要使用6.2.1的命令启动api服务器
lmdeploy serve api_client http://localhost:23333
http://localhost:23333:api服务的地址,与启动时指定的保持一致。
6.2.4 在命令行启动chat模型
lmdeploy chat /root/models/internlm2_5-7b-chat
# 限定kv-cache
lmdeploy chat /root/models/internlm2_5-7b-chat --cache-max-entry-count 0.4
# 指定awq格式
lmdeploy chat /root/models/internlm2_5-7b-chat-w4a16-4bit/ --model-format awq
6.2.5 量化模型权重
使用AWQ算法量化模型权重。
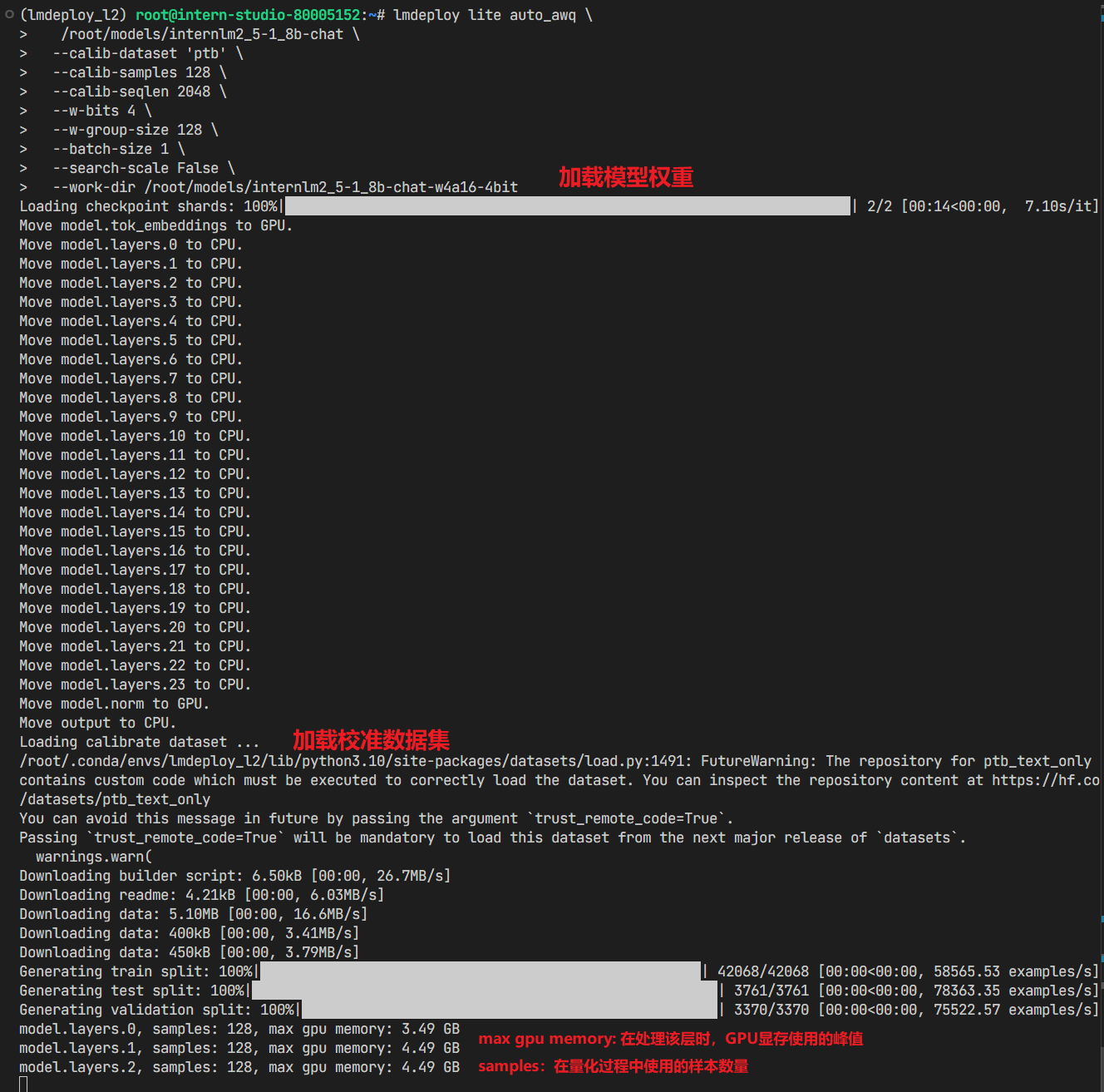
lmdeploy lite auto_awq \
/root/models/internlm2_5-7b-chat \ # 要量化的模型路径
--calib-dataset 'ptb' \
--calib-samples 128 \
--calib-seqlen 2048 \
--w-bits 4 \
--w-group-size 128 \
--batch-size 1 \
--search-scale False \
--work-dir /root/models/internlm2_5-7b-chat-w4a16-4bit
-
--calib-dataset:标定数据集,提供激活值\(X\),AWQ算法可以做到量化后的模型权重不会过拟合到校准集。这个参数指定了一个校准数据集,这里使用的是’ptb’(Penn Treebank,一个常用的语言模型数据集)。 -
--calib-sampls:数据集的样本数量。 -
--calib-seqlen:样本的长度,每个样本的token个数,即\(X\)矩阵的行数(\(X\)矩阵每一行是一个token,每个token都是一个embedding向量,向量的维度是hidden_size。token的数量,即embedding向量的行数是sequence_length)。 -
--w-bits:量化位数。 -
--w-group-size:分组通道数-
group-size,分组大小。对于\(X\)矩阵按列分组,即hidden_size分为若干组。
-
group-size较大时,每组权重较多,量化参数较少,可能会降低量化后的模型精度,但计算和存储成本低。
-
group-size较小时,每组权重较少,量化参数较多,模型精度可能更高,但计算和存储成本增加
-
业界常用默认值128
-
-
--search-scale:True或False,是否对公式5中的\(\alpha\)参数做优化。 -
--work-dir:这是工作目录的路径,用于存储量化后的模型和中间结果。
6.3 显存占用估算方法
6.3.1 未量化
加载internlm2_5-7b-chat模型:
lmdeploy chat /root/models/internlm2_5-7b-chat
这是InternStudio提供的资源监控。

30%A100,总共24GB显存,占用约23GB。
如果选择 50%A100*1 建立机器,同样运行InternLM2.5 7B模型,会发现此时显存占用为36GB。

那么这是为什么呢?由模型的huggingface主页的config.json文件可以查到InternLM2.5 7B模型为bf16。
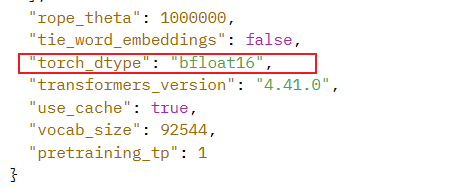
对于一个7B(70亿)参数的模型,每个参数使用16位浮点数(等于 2个 Byte)表示,则模型的权重大小约为:
7×10^9 parameters×2 Bytes/parameter=14GB
70亿个参数×每个参数占用2个字节=14GB
因此LMDpeloy推理精度为bf16的7B模型权重需要占用14GB显存;
如下图所示,lmdeploy默认设置cache-max-entry-count为0.8,即kv cache占用剩余显存的80%;
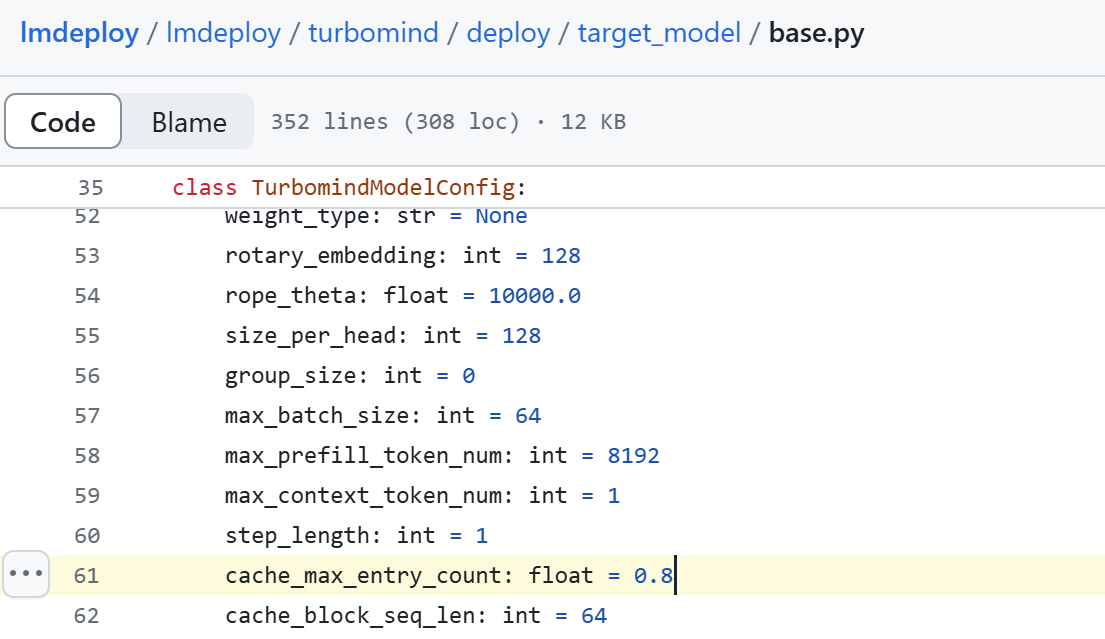
此时对于24GB的显卡,即30%A100,权重占用14GB显存,剩余显存24-14=10GB,因此kv cache占用10GB*0.8=8GB,加上原来的权重14GB,总共占用14+8=22GB。
而对于40GB的显卡,即50%A100,权重占用14GB,剩余显存40-14=26GB,因此kv cache占用26GB*0.8=20.8GB,加上原来的权重14GB,总共占用34.8GB。
实际加载模型后,其他项也会占用部分显存,因此剩余显存比理论偏低,实际占用会略高于22GB和34.8GB。
6.3.2 设置最大kv cache缓存大小
kv cache是一种缓存技术,通过存储键值对的形式来复用计算结果,以达到提高性能和降低内存消耗的目的。在大规模训练和推理中,kv cache可以显著减少重复计算量,从而提升模型的推理速度。理想情况下,kv cache全部存储于显存,以加快访存速度。
模型在运行时,占用的显存可大致分为三部分:模型参数本身占用的显存、kv cache占用的显存,以及中间运算结果占用的显存。LMDeploy的kv cache管理器可以通过设置--cache-max-entry-count参数,控制kv缓存占用剩余显存的最大比例。默认的比例为0.8。
首先我们先来回顾一下InternLM2.5正常运行时占用显存。

占用了23GB,那么试一试执行以下命令,再来观看占用显存情况。
lmdeploy chat /root/models/internlm2_5-7b-chat --cache-max-entry-count 0.4
稍待片刻,观测显存占用情况,可以看到减少了约4GB的显存。

对于修改kv cache占用之后的显存占用情况(19GB):
1、在 BF16 精度下,7B模型权重占用14GB
2、剩余显存24-14=10GB,kv cache修改为占用40%,即10*0.4=4GB,因此kv cache占用4GB。
3、其他项1GB
是故19GB=权重占用14GB+kv cache占用4GB+其它项1GB
6.3.3 设置在线 kv cache int4/int8 量化
lmdeploy serve api_server \
/root/models/internlm2_5-7b-chat \
--model-format hf \
--quant-policy 4 \
--cache-max-entry-count 0.4\
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1

可以看到此时显存占用约19GB,相较于6.3.1中直接启动模型的显存占用情况(23GB)减少了4GB的占用。此时4GB显存的减少逻辑与6.3.2一致,均因设置kv cache占用参数cache-max-entry-count至0.4而减少了4GB显存占用。
那么本节中19GB的显存占用与6.3.2中19GB的显存占用区别何在呢?
由于都使用BF16精度下的internlm2.5 7B模型,故剩余显存均为10GB,且 cache-max-entry-count 均为0.4,这意味着LMDeploy将分配40%的剩余显存用于kv cache,即10GB*0.4=4GB。但quant-policy 设置为4时,意味着使用int4精度进行量化。因此,LMDeploy将会使用int4精度提前开辟4GB的kv cache。
相比使用BF16精度的kv cache,int4的Cache可以在相同4GB的显存下只需要4位来存储一个数值,而BF16需要16位。这意味着int4的Cache可以存储的元素数量是BF16的四倍。
总结:设置在线 kv cache int4/int8 量化不会减少显存占用,但会增加kv-cache可以存储的元素数量,支持更长的上下文。
6.3.4 量化模型权重
这里以对internlm2_5-7b-chat做W4A16量化为例。
lmdeploy lite auto_awq \
/root/models/internlm2_5-7b-chat \
--calib-dataset 'ptb' \
--calib-samples 128 \
--calib-seqlen 2048 \
--w-bits 4 \
--w-group-size 128 \
--batch-size 1 \
--search-scale False \
--work-dir /root/models/internlm2_5-7b-chat-w4a16-4bit
首先可以查看模型量化后的内存占用变化:
使用的命令如下:
du -sh * # 列出当前目录下每个文件和子目录的总大小,结果以人类可读的格式显示。
# du(Disk Usage)是用来显示文件和目录所占空间的命令。
# -s(summary)选项表示只显示每个文件或目录的总大小,而不是列出所有子目录的大小。
# * 是一个通配符,表示当前目录下的所有文件和子目录。
输出结果如下。(其余文件夹都是以软链接的形式存在的,不占用空间,故显示为0)

原模型大小如下:
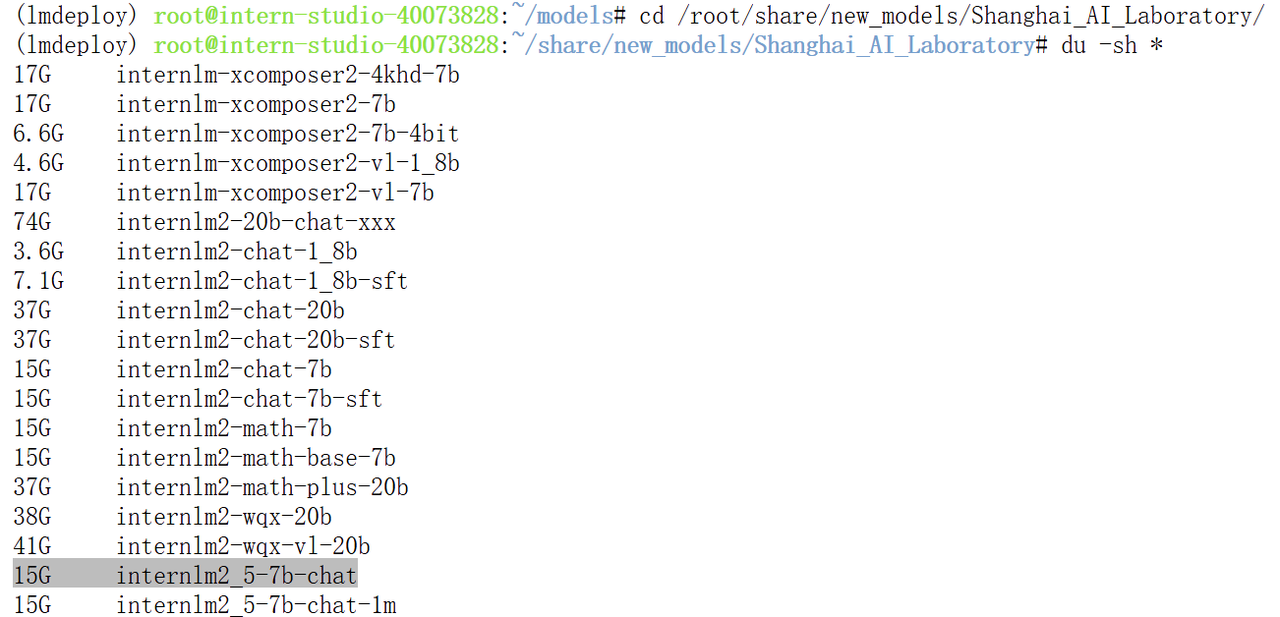
int4量化后,每个参数的内存占用由16bit降为4bit,但是模型权重文件的硬盘占用不一定减少为原来的1/4,还要看权重存储的格式,这里例子中是15G对4.9G。但是显存占用确实变为了原来的1/4。
再来看显存占用情况对比:
输入以下指令启动量化后的模型。
lmdeploy chat /root/models/internlm2_5-7b-chat-w4a16-4bit/ --model-format awq

可以发现,相比较于原先的23GB显存占用,W4A16量化后的模型少了约2GB的显存占用。
对于W4A16量化之后的显存占用情况(20.9GB)计算如下:
1、在 int4 精度下,7B模型权重占用3.5GB:14/4=3.5GB
注释:
bfloat16是16位的浮点数格式,占用2字节(16位)的存储空间。int4是4位的整数格式,占用0.5字节(4位)的存储空间。因此,从bfloat16到int4的转换理论上可以将模型权重的大小减少到原来的1/4,即7B个int4参数仅占用3.5GB的显存。
2、加载模型权重后剩余显存24-3.5=20.5GB,kv cache默认占用80%,即20.5*0.8=16.4GB,则kv cache占用16.4GB。
3、其他项1GB
是故20.9GB=权重占用3.5GB+kv cache占用16.4GB+其它项1GB。
6.3.5 W4A16 量化+ 限制KV cache比例 +KV cache 量化
输入以下指令,让我们同时启用量化后的模型、设定kv cache占用和kv cache int4量化。
lmdeploy serve api_server \
/root/models/internlm2_5-7b-chat-w4a16-4bit/ \
--model-format awq \
--quant-policy 4 \
--cache-max-entry-count 0.4\
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1
此时显存占用13.5GB。

让我们来计算一下此刻的显存占用情况(13.5GB):
1、在 int4 精度下,7B模型权重占用3.5GB:14/4=3.5GB。
2、剩余显存24-3.5=20.5GB,kv cache占用40%,即20.5*0.4=8.2GB,则kv cache占用16.4GB。
3、其他项1.8GB
是故13.5GB=权重占用3.5GB+kv cache占用8.2GB+其它项1.8GB。
6.3.6 多模态大模型量化
以InternVL2-26B为例,对它进行W4Q16+kv-cache量化+限制kv-cache比例。
输入以下指令,让我们启用量化后的模型。
lmdeploy serve api_server \
/root/models/InternVL2-26B-w4a16-4bit \
--model-format awq \
--quant-policy 4 \
--cache-max-entry-count 0.1\
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1
在30%A100上启动后观测显存占用情况,此时占用23.8GB的显存。

根据InternVL2介绍,InternVL2 26B是由一个6B的ViT、一个100M的MLP以及一个19.86B的internlm组成的。
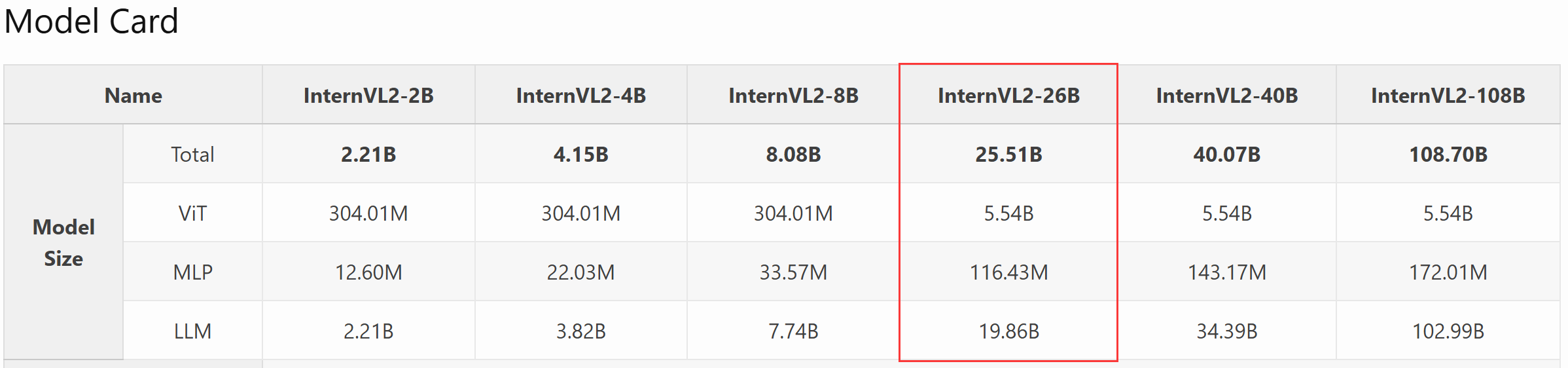
而要注意:ViT使用精度为fp16的pytorch推理,量化只对LLM的19.86B起效果。
对于使用30%A1001(24GB显存容量)联合部署的显存情况(23.8GB):
1、在 fp16 精度下,6BViT模型权重占用12GB:60×10^9 parameters×2 Bytes/parameter=12GB
2、在 int4 精度下,19.86B≈20B的internlm模型权重占用10GB:20×10^9 parameters×0.5 Bytes/parameter=10GB
3、剩余显存24-12-10=2GB,kv cache修改为占用10%,即2*0.1=0.2GB,则kv cache占用0.2GB
4、其他项1.6GB
是故23.8GB=Vit权重占用12GB+internlm模型权重占用10GB+kv cache占用0.2GB+其他项1.6GB
如果在100%A100上启动未量化的InternVL2-26B
让我们来计算一下此时的显存占用情况:
1、在 fp16 精度下,6BViT模型权重占用12GB:60×10^9 parameters×2 Bytes/parameter=12GB
2、在 fp16 精度下,19.86B≈20B的internlm模型权重占用40GB:200×10^9 parameters×2 Bytes/parameter=40GB
3、kv cache占用22.4GB:剩余显存80-12-40=28GB,kv cache默认占用80%,即28*0.8=22.4GB
4、其他项
是故总占用=Vit权重占用12GB+internlm模型权重占用40GB+kv cache占用22.4GB+其他项≥74.4GB
而经过量化后,InternVL2-26B-w4a16-4bit已经是一张30%A100即可部署的模型了。
6.4 量化日志分析
量化后的文件大小对比:
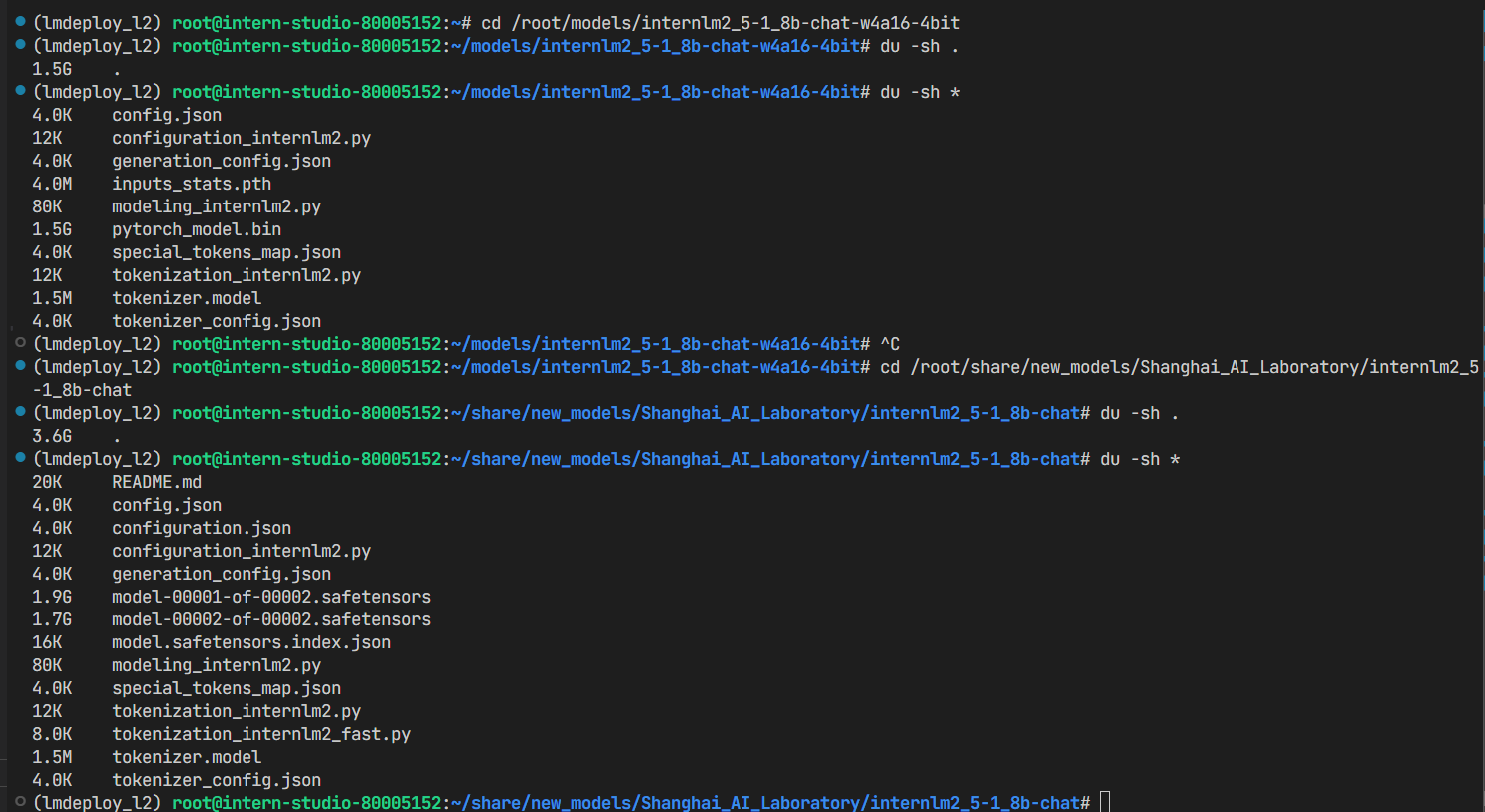
这里是internlm2_5-1_8b-chat模型:
- 量化前的模型权重的文件大小:1.9 + 1.7 = 3.6G
- 量化后的模型权重的文件大小:1.5G,pytorch_model.bin格式
量化前后的显存占用对比:
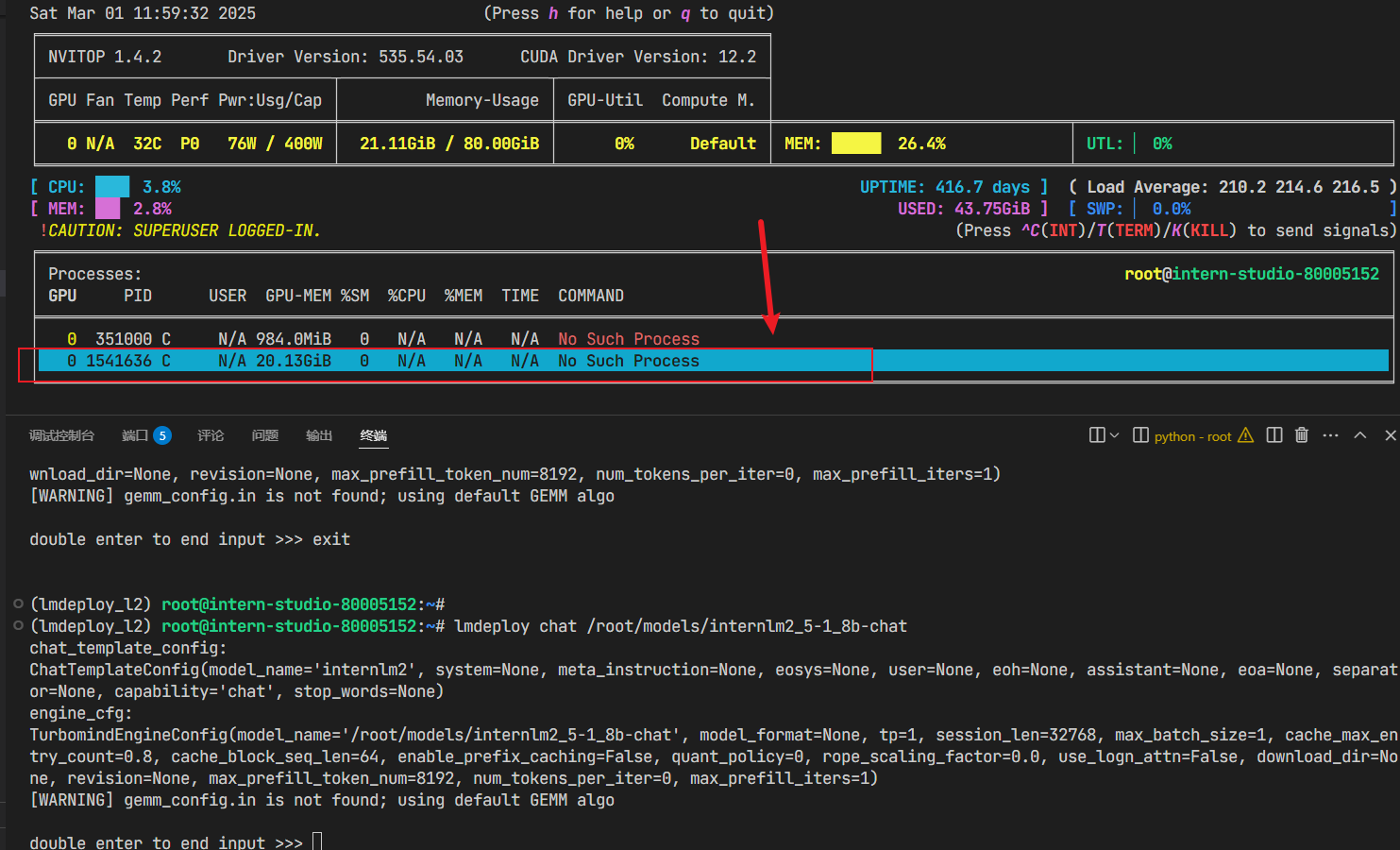
1、量化后:
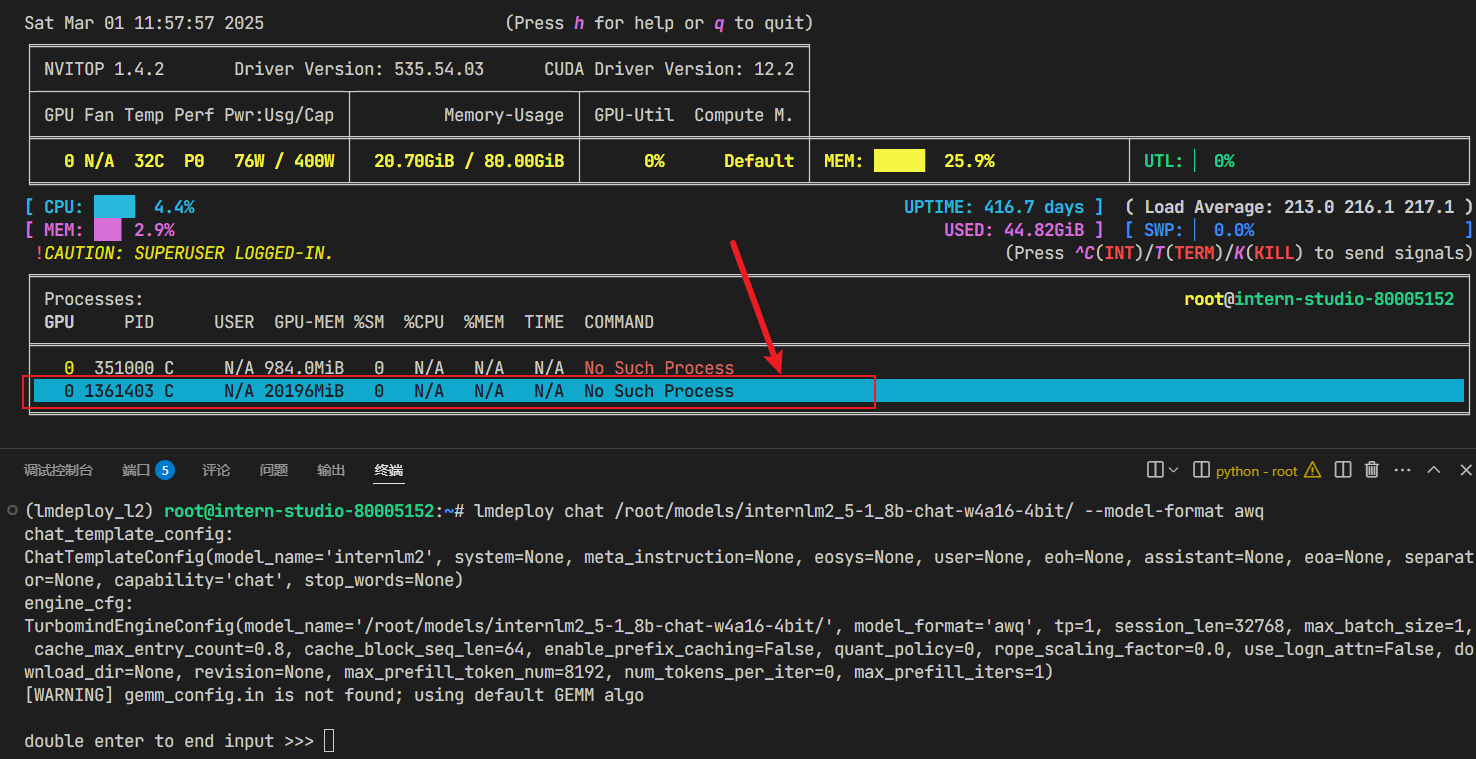
2、量化前:
7. 基础任务
输入指令启动API服务器
conda activate lmdeploy_l2
lmdeploy serve api_server \
/root/models/internlm2_5-1_8b-chat-w4a16-4bit \
--model-format awq \
--cache-max-entry-count 0.4 \
--quant-policy 4 \
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1
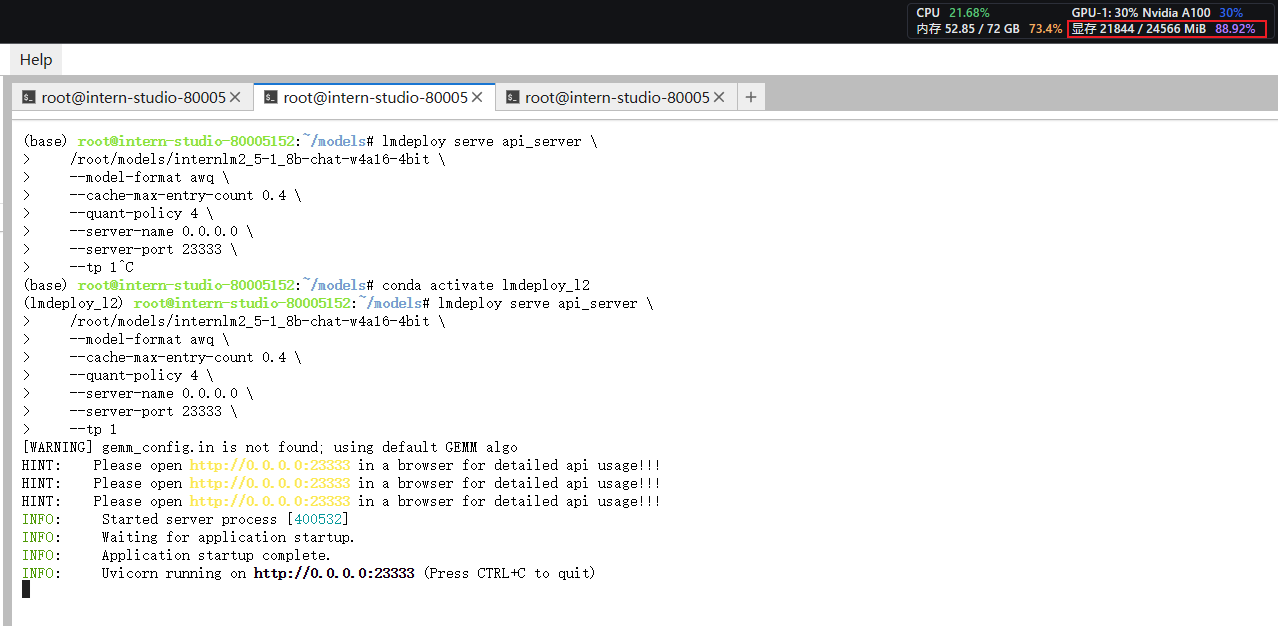
显存的占用情况如下图:
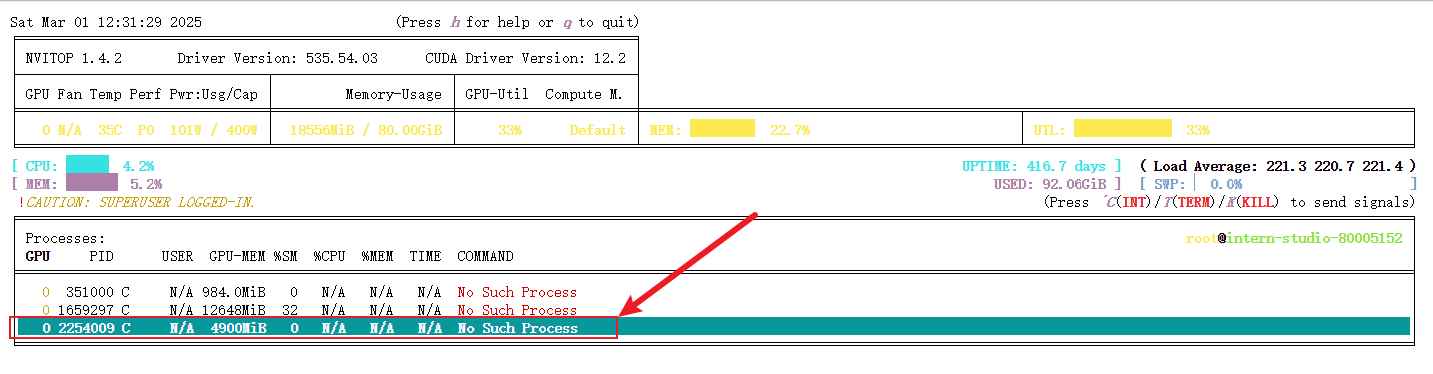
此时还在同步进行internvl2的模型权重量化,加载internlm2_5-1_8b-chat-w4a16-4bit的实际占用为4900MB显存:
新建internlm2_5.py,并贴入以下代码:
# 导入openai模块中的OpenAI类,这个类用于与OpenAI API进行交互
from openai import OpenAI
# 创建一个OpenAI的客户端实例,需要传入API密钥和API的基础URL
client = OpenAI(
api_key='YOUR_API_KEY',
# 替换为你的OpenAI API密钥,由于我们使用的本地API,无需密钥,任意填写即可
base_url="http://0.0.0.0:23333/v1"
# 指定API的基础URL,这里使用了本地地址和端口
)
# 调用client.models.list()方法获取所有可用的模型,并选择第一个模型的ID
# models.list()返回一个模型列表,每个模型都有一个id属性
model_name = client.models.list().data[0].id
# 使用client.chat.completions.create()方法创建一个聊天补全请求
# 这个方法需要传入多个参数来指定请求的细节
response = client.chat.completions.create(
model=model_name,
# 指定要使用的模型ID
messages=[
# 定义消息列表,列表中的每个字典代表一个消息
{"role": "system", "content": "你是一个友好的小助手,负责解决问题."},
# 系统消息,定义助手的行为
{"role": "user", "content": "帮我讲述一个关于狐狸和西瓜的小故事"},
# 用户消息,询问时间管理的建议
],
temperature=0.8,
# 控制生成文本的随机性,值越高生成的文本越随机
top_p=0.8
# 控制生成文本的多样性,值越高生成的文本越多样
)
# 打印出API的响应结果
print(response.choices[0].message.content)
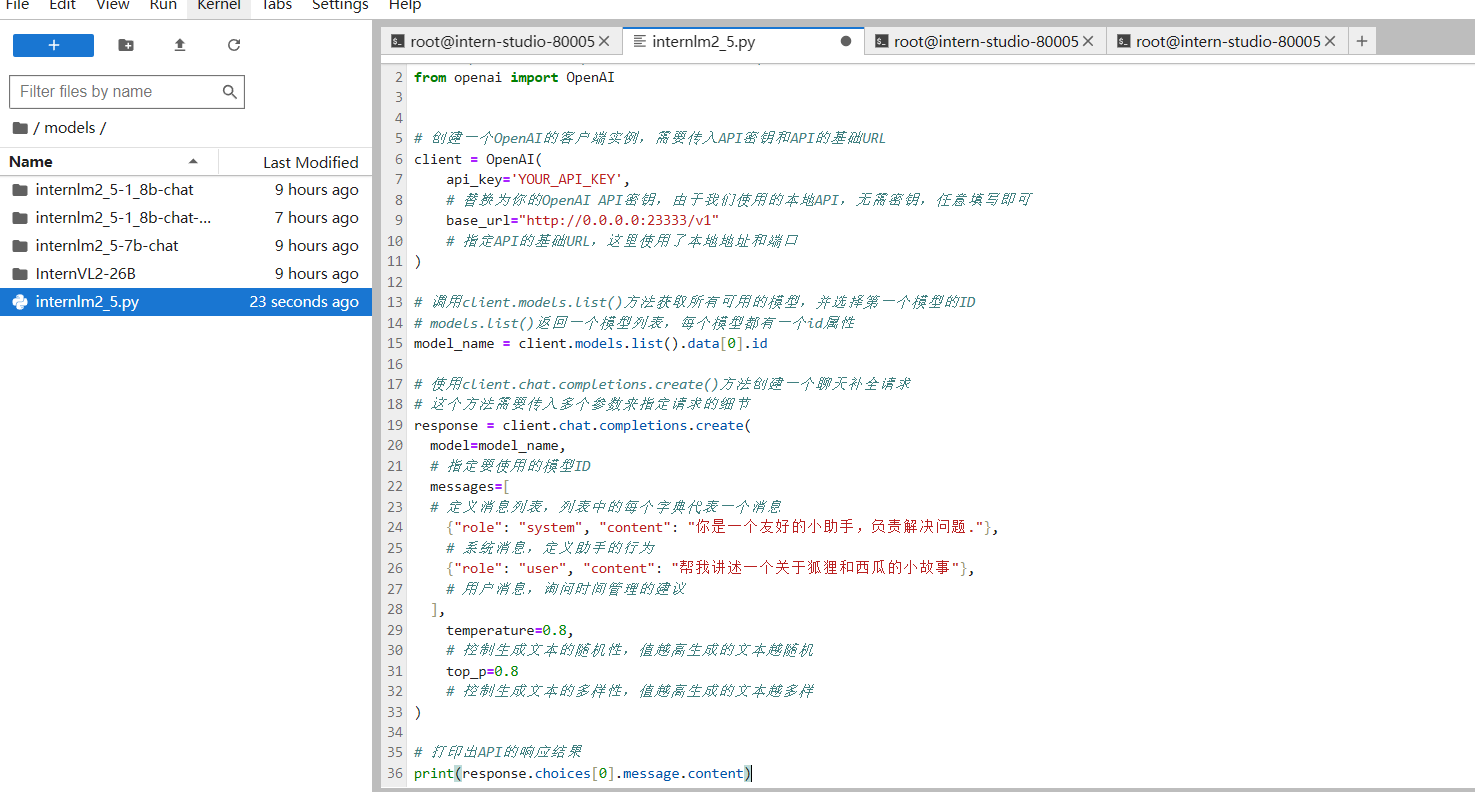
运行python internlm2_5.py,遇到报错:
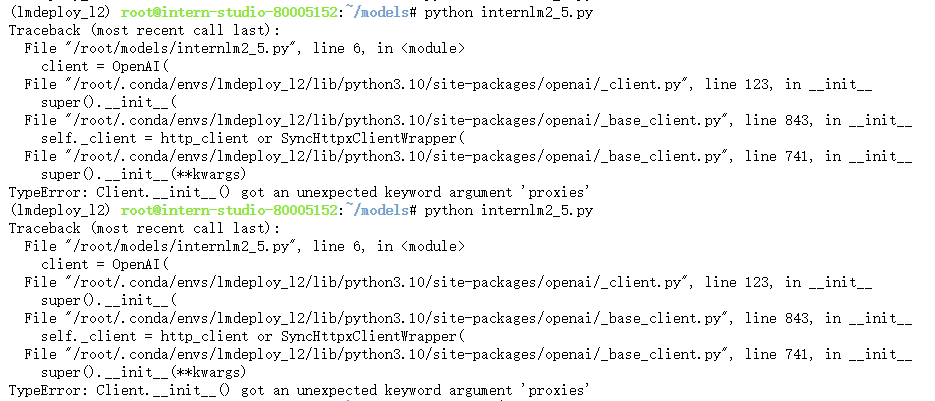
解决方法:pip install -U openai
再次运行,得到以下结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号