L1G6-OpenCompass 评测书生大模型实践
L1G6-OpenCompass 评测书生大模型实践
1. 大模型评测入门
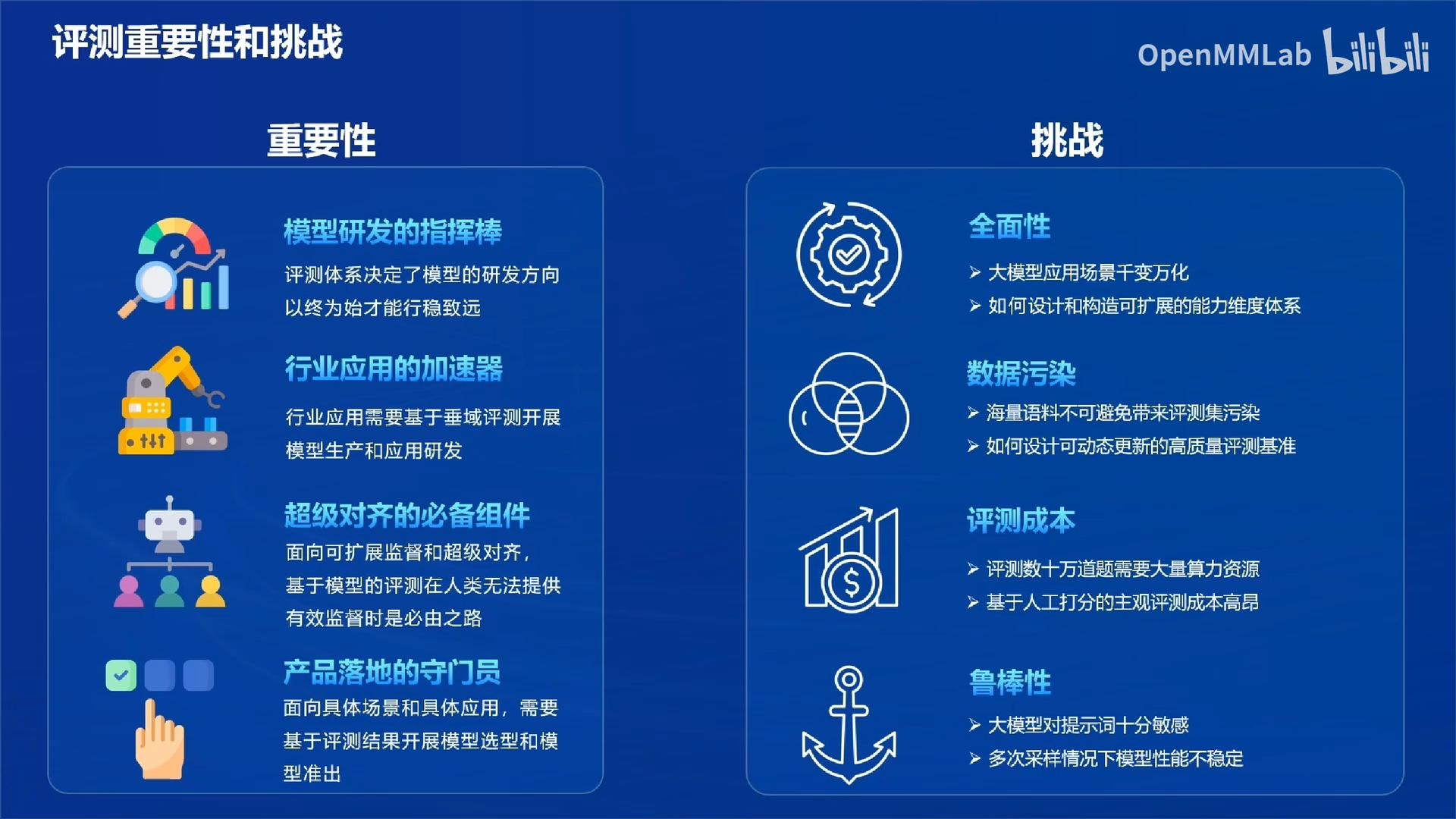
1.1 评测重要性和挑战
解释:
- 超级对齐的必备组件:大模型安全问题日益突出,人工监管能力有限,需要有基于评测的安全监督。
- 数据污染:有的模型可能在评测集上训练,得到的分数不可信。
- 评测成本:客观题数量较多时,大模型推理消耗的GPU成本高;主观题上,人工评测的劳务费成本高。
- 鲁棒性:有的大模型对提示词非常敏感,可能出现同一个模型,换一套提示词的结果截然不同,如何解决这个问题,提升评测的鲁棒性是一个很重要的问题。
1.2 OpenCompass如何评测模型?
- 对模型分类:不同类型的模型采用不同的评测方式,如基座模型和对话模型。
- 支持本地推理和API两种方法。

-
根据问题有没有标准答案,可以将评测分为客观评测和主观评测。
- 客观评测:问答题和选择题。
- 主观评测:开放式主观问答,需要人类评价或者模型评价(找目前性能较好的模型给待评测模型的输出打分)。模型评价将成为主流,在专业知识领域,普通人类标注员的准确率可能相比先进大模型并无显著优势。

-
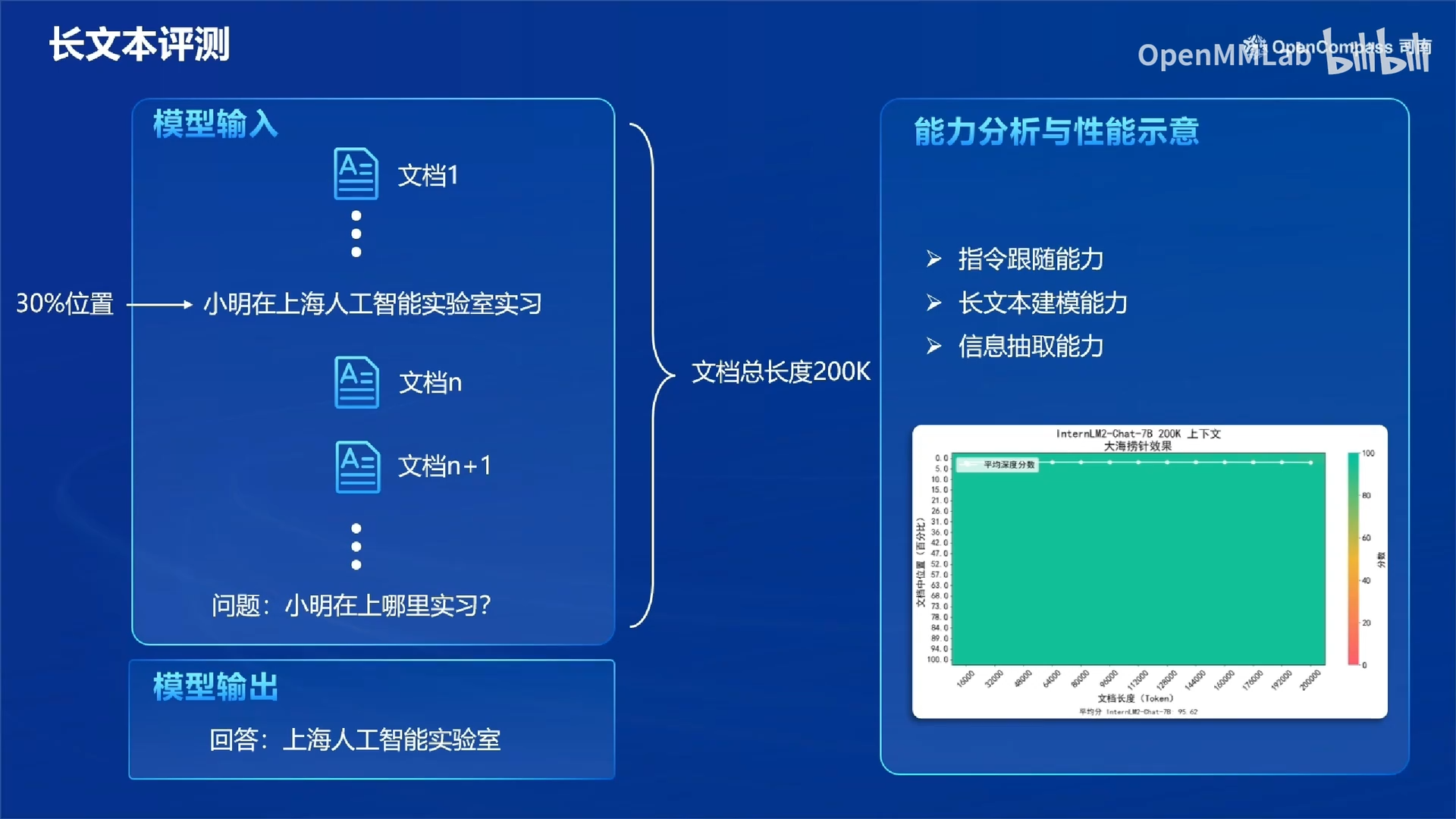
长文本评测:大海捞针实验。
1.3 基于评测得到的大模型发展趋势分析
端侧大模型的选型要点:
- 高推理速度
- 特定场景性能强,而不是通用场景
- 参数在2B以下的小模型

1.4 OpenCompass评测基准



2. OpenCompass评测实践
2.1 环境准备
OpenCompass 提供了 API 模式评测和本地直接评测两种方式。其中 API 模式评测针对那些以 API 服务形式部署的模型,而本地直接评测则面向那些可以获取到模型权重文件的情况。
我们首先在训练营提供的开发机上创建用于评测 conda 环境:
conda create -n opencompass python=3.10
conda activate opencompass
cd /root
git clone -b 0.3.3 https://github.com/open-compass/opencompass
cd opencompass
pip install -e .
pip install -r requirements.txt
pip install huggingface_hub==0.25.2
pip install importlib-metadata
2.2 评测API模型
如果你想要评测通过 API 访问的大语言模型,整个过程其实很简单。首先你需要获取模型的 API 密钥(API Key)和接口地址。以 OpenAI 的 GPT 模型为例,你只需要在 OpenAI 官网申请一个 API Key,然后在评测配置文件中设置好这个密钥和相应的模型参数就可以开始评测了。评测过程中,评测框架会自动向模型服务发送测试用例,获取模型的回复并进行打分分析。整个过程你不需要准备任何模型文件,也不用担心本地计算资源是否足够,只要确保网络连接正常即可。
这里以评测 internlm2.5-latest 模型为例。
-
打开网站浦语官方地址 https://internlm.intern-ai.org.cn/api/document 获得 api key 和 api 服务地址 (也可以从第三方平台 硅基流动 获取), 在
.bashrc中加入:export api_key=xxxxxxxxxxxxxxxxxxxxxxx # 填入你申请的 API Key然后执行
source ~/.bashrc -
配置模型
在克隆的
opencompass/opencompass/configs/models目录下添加配置文件,配置文件的路径是opencompass/configs/models/openai/puyu_api.pycd /root/opencompass touch opencompass/configs/models/openai/puyu_api.py贴入以下代码:
import os from opencompass.models import OpenAISDK internlm_url = 'https://internlm-chat.intern-ai.org.cn/puyu/api/v1/' # 你前面获得的 api 服务地址 internlm_api_key = os.getenv('api_key') models = [ dict( # abbr='internlm2.5-latest', type=OpenAISDK, path='internlm2.5-latest', # 请求服务时的 model name # 换成自己申请的APIkey key=internlm_api_key, # API key openai_api_base=internlm_url, # 服务地址 rpm_verbose=True, # 是否打印请求速率 query_per_second=0.16, # 服务请求速率 max_out_len=1024, # 最大输出长度 max_seq_len=4096, # 最大输入长度 temperature=0.01, # 生成温度 batch_size=1, # 批处理大小 retry=3, # 重试次数 ) ] -
配置数据集
在克隆的
opencompass/opencompass/configs/datasets/下添加配置文件。cd /root/opencompass/ touch opencompass/configs/datasets/demo/demo_cmmlu_chat_gen.py贴入以下代码:
from mmengine import read_base with read_base(): from ..cmmlu.cmmlu_gen_c13365 import cmmlu_datasets # 每个数据集只取前2个样本进行评测 for d in cmmlu_datasets: d['abbr'] = 'demo_' + d['abbr'] d['reader_cfg']['test_range'] = '[0:1]' # 这里每个数据集只取1个样本, 方便快速评测.这样我们使用了 CMMLU Benchmark 的每个子数据集的 1 个样本进行评测。
注意,如果
opencompass/configs/datasets目录下有同名文件,要删除。我们需要的是opencompass/opencompass/configs/datasets目录下的配置文件。 -
启动评测
完成配置后, 在
/root/opencompass下运行:python run.py --models puyu_api.py --datasets demo_cmmlu_chat_gen.py --debug
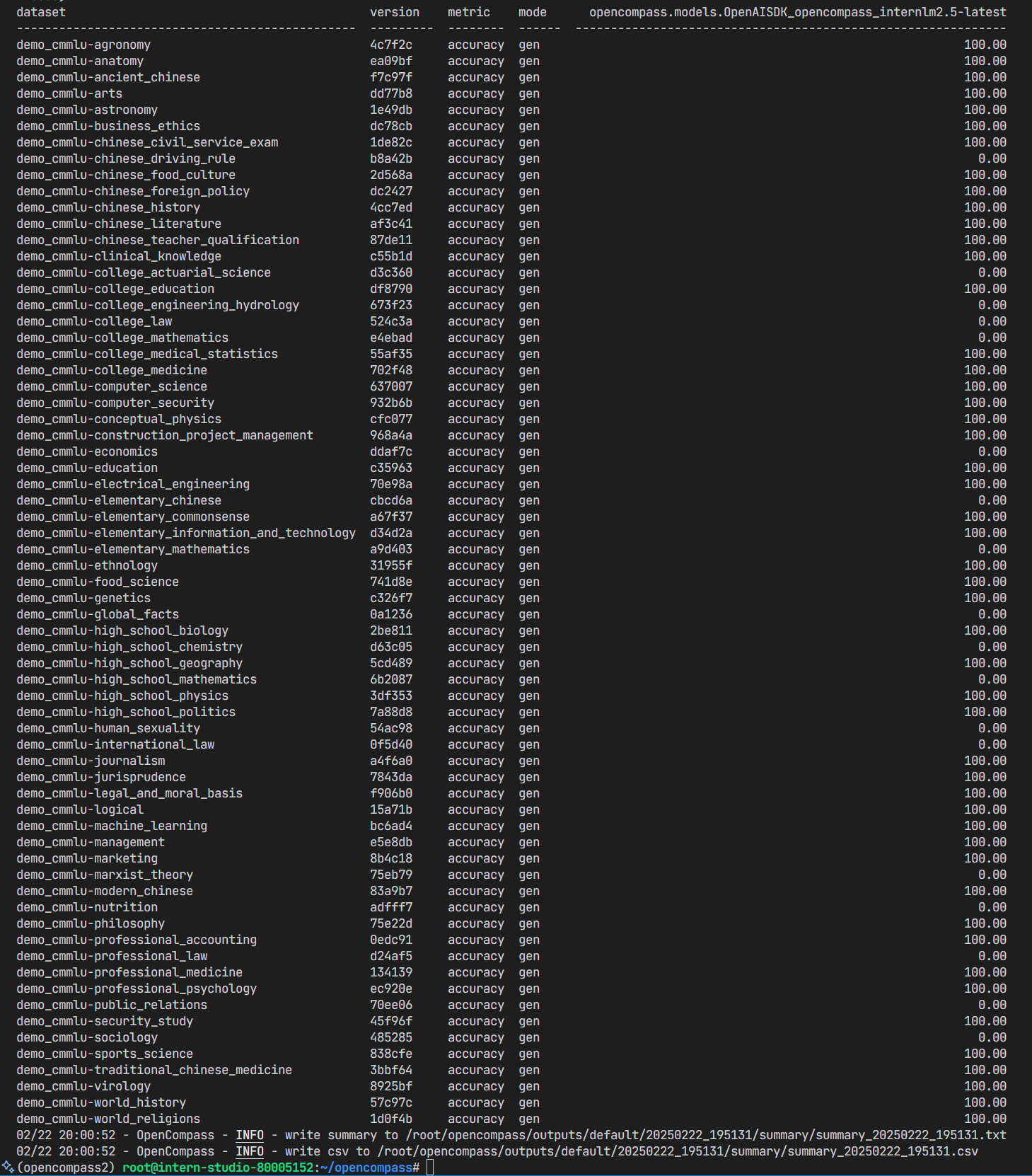
得到评测结果如下:
bug fix
-
问题1:transformers库与huggingface_hub版本不匹配。
运行
pip install huggingface_hub==0.25.2后,终端中显示transformers库需要更高版本的huggingface_hub。解决:
原因是transformers库的版本过高。通过查看
/root/opencompass/requirements文件夹下的依赖文件,发现其transformers库的版本说明是: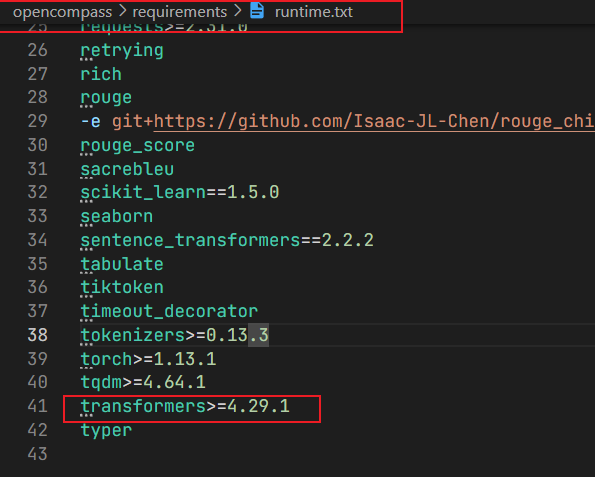
默认会安装transformers库的最新版本。
我们在终端执行
pip install transformers==4.29.1覆盖掉原来的transformers即可。
-
问题2:找不到
rouge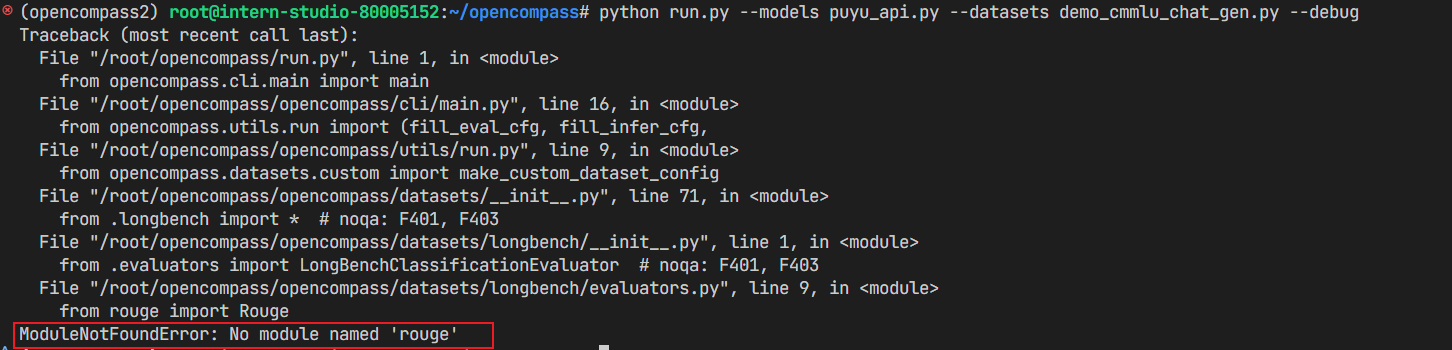
解决方法:
rouge包虽然在环境中存在,但并不能正常调用,需要重新卸载再安装一下。pip uninstall rouge pip install rouge
2.3 评测本地模型
如果你想要评测本地部署的大语言模型,首先需要获取到完整的模型权重文件。以开源模型为例,你可以从 Hugging Face 等平台下载模型文件。接下来,你需要准备足够的计算资源,比如至少一张显存够大的 GPU,因为模型文件通常都比较大。有了模型和硬件后,你需要在评测配置文件中指定模型路径和相关参数,然后评测框架就会自动加载模型并开始评测。这种评测方式虽然前期准备工作相对繁琐,需要考虑硬件资源,但好处是评测过程完全在本地完成,不依赖网络状态,而且你可以更灵活地调整模型参数,深入了解模型的性能表现。这种方式特别适合需要深入研究模型性能或进行模型改进的研发人员。
2.3.1 环境准备(在2.1基础上)
安装相关软件包:
cd /root/opencompass
conda activate opencompass
conda install pytorch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 pytorch-cuda=12.1 -c pytorch -c nvidia -y
apt-get update
apt-get install cmake
pip install protobuf==4.25.3
为了解决一些本地评测时出现的报错问题,我们还需要重装一些 python 库
pip uninstall numpy -y
pip install "numpy<2.0.0,>=1.23.4"
pip uninstall pandas -y
pip install "pandas<2.0.0"
pip install onnxscript
pip uninstall transformers -y
pip install transformers==4.39.0
为了方便评测,我们首先将数据集下载到本地:
cp /share/temp/datasets/OpenCompassData-core-20231110.zip /root/opencompass/
unzip OpenCompassData-core-20231110.zip
将会在 OpenCompass 下看到data文件夹.
2.3.2 加载本地模型进行评测
在 OpenCompass 中,模型和数据集的配置文件都存放在 configs 文件夹下。我们可以通过运行 list_configs 命令列出所有跟 InternLM 及 C-Eval 相关的配置。
python tools/list_configs.py internlm ceval
结果如下:

打开 opencompass 文件夹下 configs/models/hf_internlm/的 hf_internlm2_5_1_8b_chat.py 文件, 修改如下:
from opencompass.models import HuggingFacewithChatTemplate
models = [
dict(
type=HuggingFacewithChatTemplate,
abbr='internlm2_5-1_8b-chat-hf',
path='/share/new_models/Shanghai_AI_Laboratory/internlm2_5-1_8b-chat/',
max_out_len=2048,
batch_size=8,
run_cfg=dict(num_gpus=1),
)
]
可以通过以下命令评测 InternLM2.5-1.8B-Chat 模型在 C-Eval 数据集上的性能。由于 OpenCompass 默认并行启动评估过程,我们可以在第一次运行时以 --debug 模式启动评估,并检查是否存在问题。在 --debug 模式下,任务将按顺序执行,并实时打印输出。
python run.py --datasets ceval_gen --models hf_internlm2_5_1_8b_chat --debug
# 如果出现 rouge 导入报错, 请 pip uninstall rouge 之后再次安装 pip install rouge==1.0.1 可解决问题.
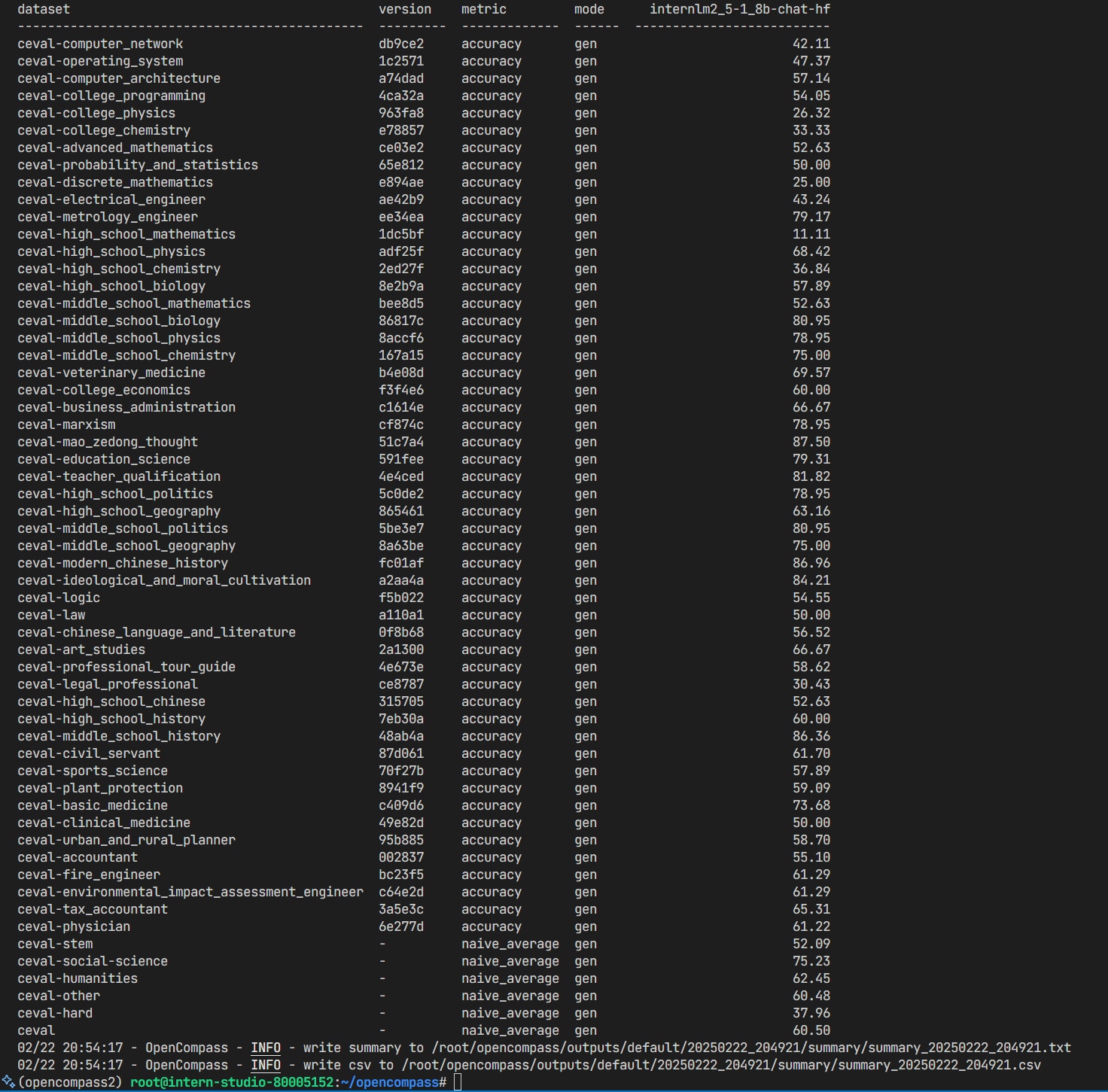
成功启动:
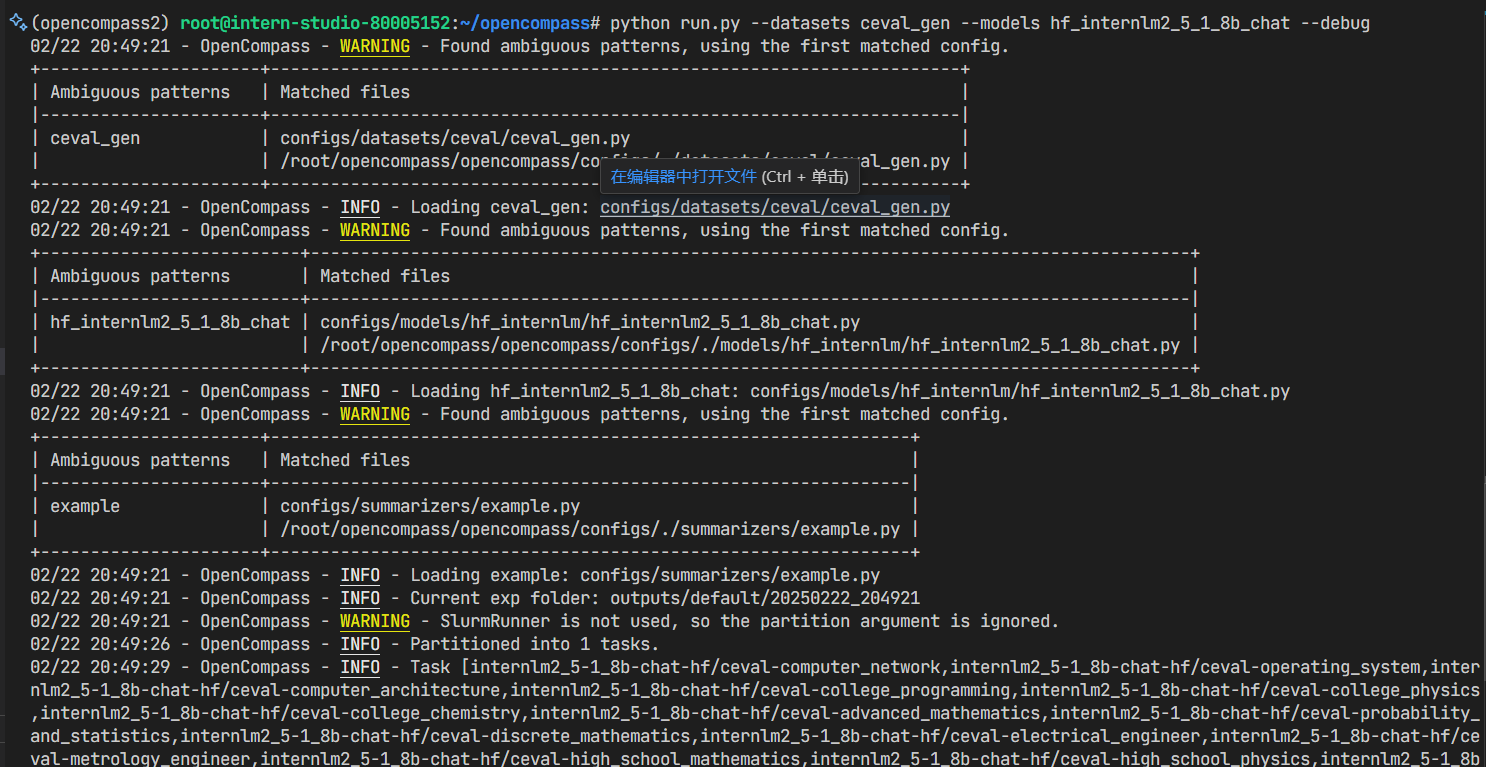
结果如下:
2.3.3 自定义评测的配置文件替代命令行参数指定数据集和模型
cd /root/opencompass/configs/
touch eval_tutorial_demo.py
打开 eval_tutorial_demo.py 贴入以下代码
from mmengine.config import read_base
with read_base():
from .datasets.ceval.ceval_gen import ceval_datasets # 指定了数据集
from .models.hf_internlm.hf_internlm2_5_1_8b_chat import models as hf_internlm2_5_1_8b_chat_models # 制定了模型的配置文件
datasets = ceval_datasets
models = hf_internlm2_5_1_8b_chat_models
这样我们指定了评测的模型和数据集,然后运行
cd /root/opencompass
python run.py configs/eval_tutorial_demo.py --debug
# 对比:python run.py --datasets ceval_gen --models hf_internlm2_5_1_8b_chat --debug,即将命令行参数放到python文件中指定了。
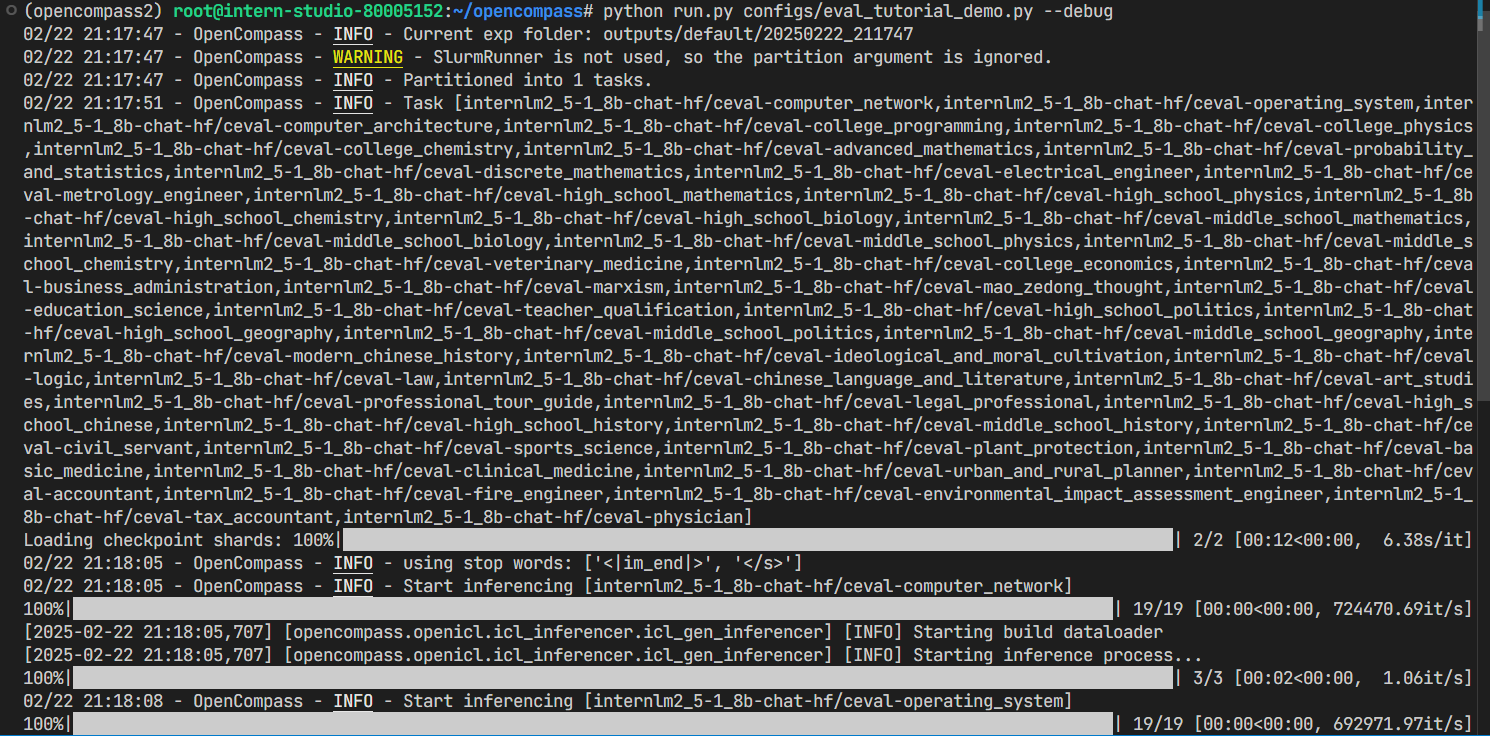
成功启动:
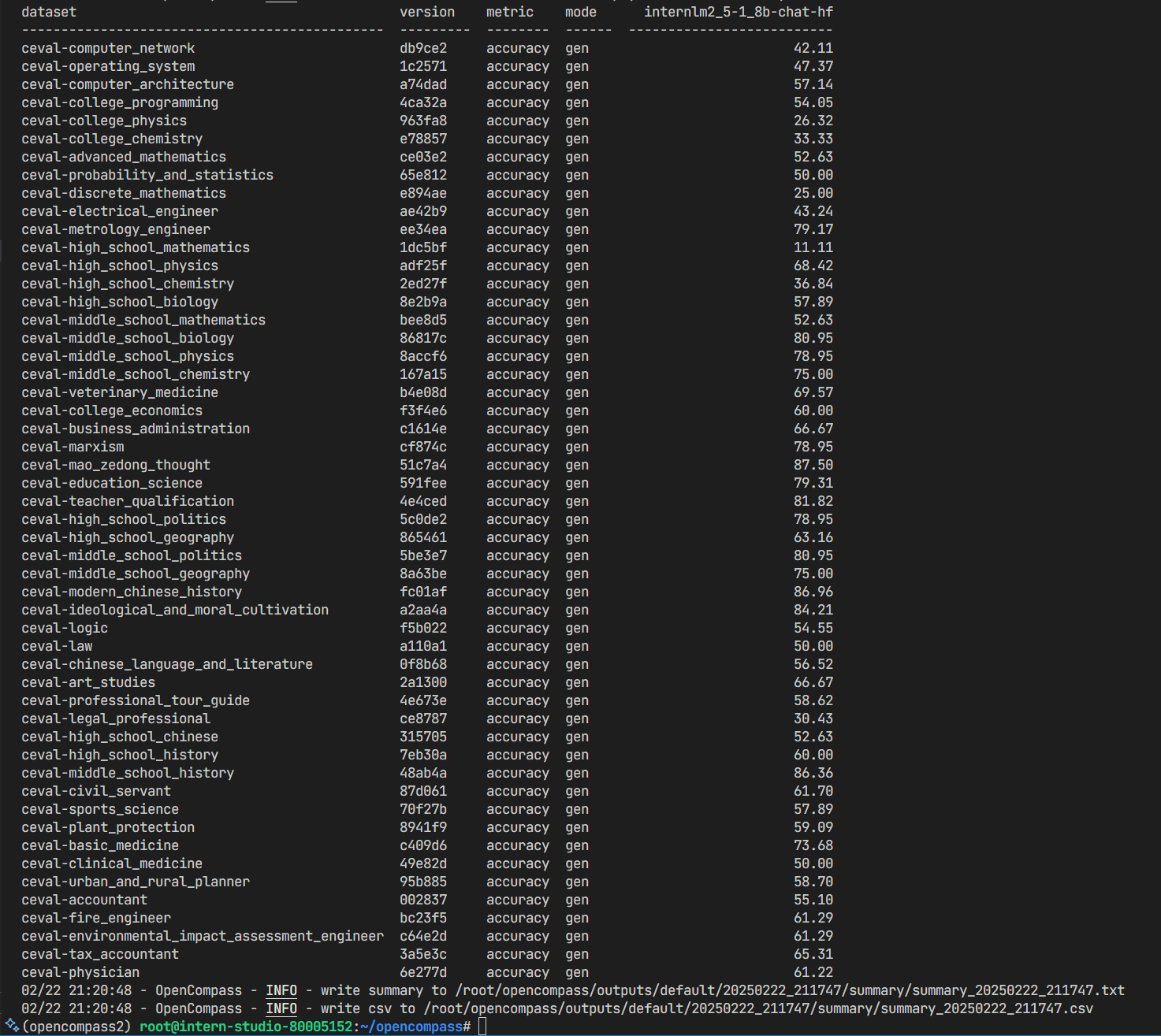
评测结果如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号