如何debug
如何debug
写在前面
-
本节课介绍的内容是基于我个人的经验和网上搜集的资料,可供各位参考,希望大家有所收获;
-
讲授的内容是方法论,提高debug能力的最快方式就是多写多练;
-
debug不是我们的目的,重要的是要吸取教训,不要在同一个地方跌倒两次;
-
最好的debug方式就是少写bug。这需要:
-
足够的代码量的练习;
-
留心学习别人的写法,摸索出适合自己的最佳写法;
-
debug的步骤
第一步 通读代码
先解决编译错误
编译错误, 就是指不能通过编译的问题。 这种错误是最容易排除的。 通常由于变量未定义、忘记分号、括号不匹配等问题,只要遵循编译时的错误提示,对相应的语句进行修改即可。
首先要修复编译错误。
注意:IDE中编译器的报错不总是定位在正确的行。造成这个现象的一个可能原因是,要读到下一行才能知道代码的上一行是否是错误的。比如下图中,第20行末尾漏写了分号,但是编译器要读到20行的右括号后的第一个字符发现不是分号,才确认错误。
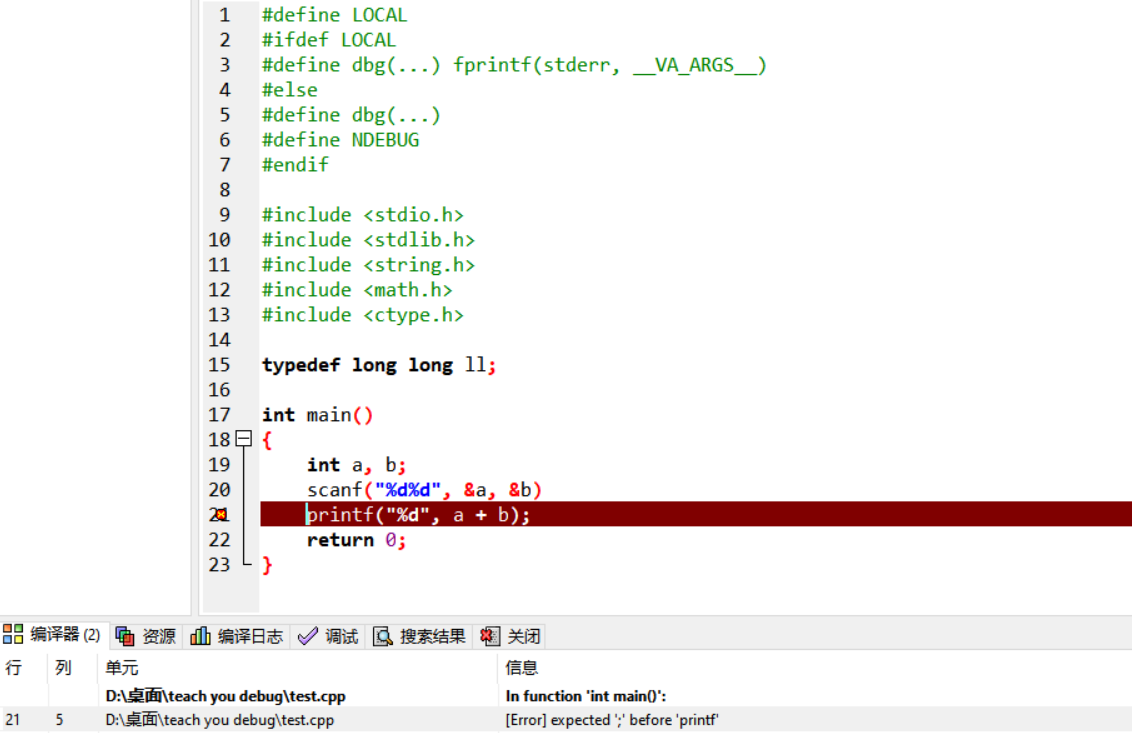
下图的编译错误定位在了第24行,验证了这一点
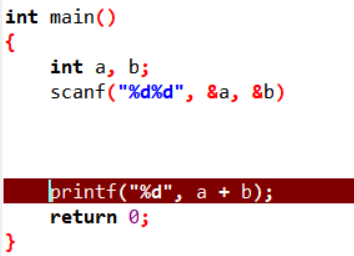
而下图的代码没有报错,再次验证。
这种问题也和选择什么编辑器有关。比如vscode的提示更加的具体,方便了修复。

但更重要的是预防错误,平时编写程序时应该养成习惯,先定义变量再使用变量,不要
出现错误后再去补。 做题不是打字竞赛,不要忙着向下写程序,写每一行时都要注括
号匹配、句末分号等“语法” 问题。应该采用合理的缩进,保持逻辑结构清晰,还可以使用编译器的高亮匹配功能,避免错误。
静态查错
一些同学编写完程序后测试样例,一看输出结果与正确答案相去万里,就忙于了解程序运行的内部原因,或编写输出语句,或利用编译器的断点功能,往往苦思冥想不得其果,浪费了大量时间,还严重影响心情。事实上,问题往往在于很小的一处失误,通过通读代码(静态查错)就能找出来。
当我们编译成功,输入样例后,发现输出的结果与预期结果不符、没有输出、程序卡住了等等,debug才真正开始。
出错情况分析
- 算法错误
- 算法的时间复杂度太高,超时了(Time Limit Exceeded,TLE)
- 算法的空间复杂度太高,内存超限了(Memory Limit Exceeded,MLE)
- 考虑情况不全
- 做法根本性错误
- 算法正确,代码实现错误
- 程序在运行的时候异常退出(Runtime Error,RE)
- 段错误(Segmentation fault)
- 格式错误,结果与正确结果就差一点(Presentation Error,PE)
- 其他各种错误导致程序运行结果与正确结果不一样(Wrong Answer,WA)
如何通读
读的顺序:头文件-全局变量-主函数-自定义函数
- 对照着自己的算法。逐行扫描代码,看代码是否如实实现了我们的做法。
- 是不是没有初始化;
- 是不是应该先做这步,再做另一步;
- 是不是在需要重置变量时没有重置;
- 是不是条件判断分支写错了;
- 是不是遗漏了某些操作;
- 是不是做某个操作的时机错了;
- 是不是在该结束时没有结束(死循环),该
return的时候没有return; - 是不是数组开小了;
- 是不是把0当成除数了(除0);
- ……
- 不漏过每一个字符。逐个字符去看。
- 是不是哪个变量名打错了或者写串了;
- 是不是for循环里内外循环变量是一样的,或者这个循环变量名已经用来定义别的变量了;
- 是不是什么地方漏打了几个字符;
- 是不是
+写成了-,-写成了+; - 是不是对于运算符的优先级不熟悉还不加括号;
- 是不是括号写串了;
- ……
- 通读代码的过程也是复盘我们的算法的过程。可能读着读着就发现做法错了,太理想化,忽略了某些情况。
第二步 输出检验、调试功能
当通读代码实在找不出问题,程序执行过程难以全程在脑子里或纸上模拟时,我们就应该灵活使用输出语句或者打断点调试,一边追踪程序的运行过程和变量的值的变化,一边自己手动或脑内跟着模拟,看是不是一致的。
输出什么?
这个是具体问题具体分析的,可能会输出:
-
有没有成功读到输入;
-
中间变量的值;
-
循环到了第几轮了,这一轮某些开始时某些变量的值和这一轮结束时某些变量的值;
-
进入到某个函数、函数执行过程中和函数执行完成后某些变量的值;
-
某几行程序到底有没有执行,执行了多少次;
-
程序是不是执行到了它不该执行的地方,输出一个标志表示程序经过了某一行;
-
是不是执行完某一行程序就挂了,在这行之后输出检查一下;
-
……
输出的格式
- 输出时不要吝啬,要尽可能具体、易读。
- 当有多个地方输出时,对输出的语句要加以区分。如果不加区分,甚至只输出一个值,很可能会造成混乱,还要去辨认是哪一行输出的,舍本逐末。
- 输出的格式可以是
行号,变量名=值。 - 可以适当输出换行符或者
-----等分隔符号增加让错误信息更易于查找。
例子——冒泡排序
// 错误代码
#include <stdio.h>
#define N 100010
int a[N];
int main()
{
int n;
scanf("%d", &n);
for (int i = 0; i < n; i ++ ) scanf("%d", &a[i]);
for (int i = 0; i < n - 1; i ++ )
{
for (int j = 0; j < n - i - 1; j ++ )
{
if (a[i] > a[i + 1]) // 内外颠倒
{
int t = a[i];
a[i] = a[i + 1];
a[i + 1] = t;
}
}
}
for (int i = 0; i < n; i ++ ) printf("%d ", a[i]);
return 0;
}
// 输出检验的代码
#include <stdio.h>
#define N 100010
int a[N];
int main()
{
int n;
scanf("%d", &n);
for (int i = 0; i < n; i ++ ) scanf("%d", &a[i]);
for (int i = 0; i < n - 1; i ++ )
{
for (int j = 0; j < n - i - 1; j ++ )
{
if (a[i] > a[i + 1]) // 内外颠倒
{
int t = a[i];
a[i] = a[i + 1];
a[i + 1] = t;
}
}
// 把每一轮排序的结果输出,看最大的是不是到最后面了
printf("round: %d\n", i);
for (int j = 0; j < n; j ++ )
printf("%d ", a[j]);
printf("\n\n");
}
for (int i = 0; i < n; i ++ ) printf("%d ", a[i]);
return 0;
}
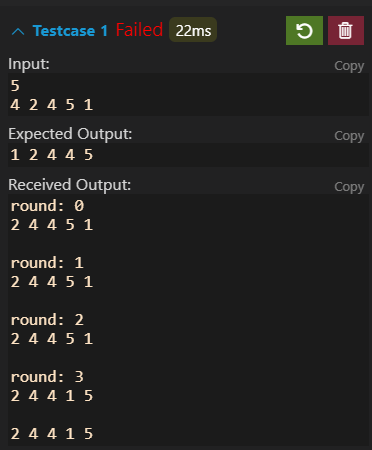
发现第一轮就错了,5根本没有被移到最后面。那就想,5能移到后面跟什么有关,就可以定位到交换部分的代码了。然后再仔细阅读代码,回想算法,找到bug。
// 正确代码
#include <stdio.h>
#define N 100010
int a[N];
int main()
{
int n;
scanf("%d", &n);
for (int i = 0; i < n; i ++ ) scanf("%d", &a[i]);
for (int i = 0; i < n - 1; i ++ )
{
for (int j = 0; j < n - i - 1; j ++ )
{
if (a[j] > a[j + 1])
{
int t = a[j];
a[j] = a[j + 1];
a[j + 1] = t;
}
}
}
for (int i = 0; i < n; i ++ ) printf("%d ", a[i]);
return 0;
}
第三步 造数据
当我们通过了样例,但提交上去后是部分正确或者完全错误时,我们可以考虑造数据来寻找程序的漏洞。
小数据
什么是小数据?
个人认为小数据就是能够完整跟踪程序运行过程,查看中间变量,手算或脑内模拟的数据。
小数据的优点
-
易于调试。
-
易于设计。
由于数据量小,我们往往可以手工设计质量更高的数据,同时对于数据本身也有直观的了解。与此同时,很多的题都会有所谓的“变态数据”,这和极限数据有着一些不同,它虽然数据量不大,但是剑走偏锋,比如某矩阵题给你一个全都是 1 的矩阵之类的。这种狡猾的数据在评测的时候往往并不罕见,由于这样那样的原因,我们就栽了跟头。为了使得自己的程序更加强壮,我们需要预先测试自己的程序是否能够通过这样的数据。这种变态数据只能够由我们手工设计,因此一般都是小数据。
-
覆盖面广
对于很多题目而言,测试数据理论上存在无穷多组; 但是如果有 n<5 并且所有数都小于 10 的限制,那么数据的个数就变得有限了,不妨设是 1000 组。我们可以通过写一个程序,直接把这 1000 组小数据全部都制作出来,然后逐个儿测试。 虽然这些数据的数据量小,但是由于它们把小数据的所有可能的情况都包括在其中了,因此你的程序的大部分问题都能够在这 1000 组数据中有所体现。同时,因为是小数据,程序可以在很短的时间内运行出解,例如是 0.05 秒,这样, 1000 组数据,也不过只要 50 秒,完全可以接受。但是要注意,生成所有数据的同时,我们还要写一个效率差,确保正确的程序来验证结果的正确性。因此这种想法至少需要 2 个程序。
极限数据
什么是极限数据?
在说明极限数据之前,我们要先了解一下什么是题目的时间限制和空间限制。
以洛谷的这道查找题为例。【模板】查找
输入 \(n\) 个不超过 \(10^9\) 的单调不减的(就是后面的数字不小于前面的数字)非负整数 \(a_1,a_2,\dots,a_{n}\),然后进行 \(m\) 次询问。对于每次询问,给出一个整数 \(q\),要求输出这个数字在序列中第一次出现的编号,如果没有找到的话输出 \(-1\) 。
11 3
1 3 3 3 5 7 9 11 13 15 15
1 3 6
1 2 -1
时空限制:
数据保证,\(1 \leq n \leq 10^6\),\(0 \leq a_i,q \leq 10^9\),\(1 \leq m \leq 10^5\)
解释:
-
时间限制:c/c++的代码,评测机1s能算1e8次。可以理解为,我们的程序基本操作重复执行的次数不能超过1e8这个数量级。注意,这里的解释不是很严谨,是为了方便本次讲解,实际上程序的运算次数是由一个名为时间复杂度的指标衡量的,是算法的时间复杂度在题目的数据范围内不能超过1e8这个量级。
假如我们用遍历数组来做这道题,代码如下:
#include <stdio.h> #define N 1000010 int a[N]; int main() { int n, m; scanf("%d%d", &n, &m); for (int i = 1; i <= n; i ++ ) scanf("%d", &a[i]); int q; for (int i = 0; i < m; i ++ ) { scanf("%d", &q); int found = 0; for (int j = 1; j <= n; j ++ ) { if (a[j] == q) { printf("%d ", j); found = 1; break; } } if (found == 0) printf("-1 "); } return 0; }评测结果如下(开了O2优化)。可以看到,这份代码在四个测试点上超过了时间的限制,也就是运行的时间超过了1s。
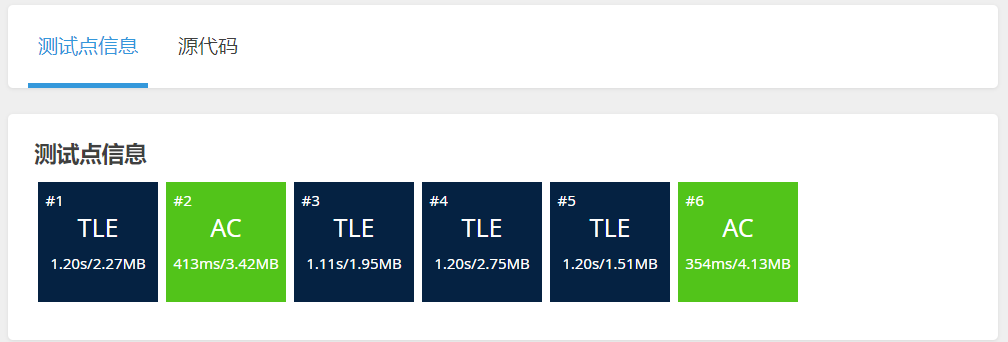
为什么超时了呢?我们可以这样看:
对于每个询问,我们都遍历了一次数组,数组长度是n,则遍历一次for循环内的语句就执行了n次。一共有m个询问,则for循环内的语句最多会执行
n*m次。题目给的数据范围中,n最大是1e6,m最大是1e5,n*m显然超过了1e8的数量级。也就是说,这份代码超出了题目的时间限制,不能通过所有的测试点。 -
空间限制:一个程序的运行会占用内存,内存的消耗一方面是我们定义变量开辟的空间,另一方面是程序运行需要的栈空间。栈空间主要是函数递归会消耗,这里先不做说明,来看变量占用的空间。在这道题里,我们定义了一个长度为1e6的int类型的数组。我们来算一下这个数组占用了多少内存。一个int是4字节,1e6个int就消耗了4e6个字节。题目的空间限制是125MB,大概是
125*10^6=1.25e7个字节。所以我们这里没有超过空间限制。但是,加入题目中的数据范围到1e7,那开的数组所消耗的空间就会超过题目的内存限制了。
Tips:有的时候其实空间没有超限,但程序还是MLE了,或者在本地跑不起来,一种解决办法是把需要空间较大的变量,比如数组,定义为全局变量。
了解了题目的时间限制和空间限制后,我们就可以给出极限数据的定义了:
极限数据就是会达到题目的时间限制或空间限制或同时达到两个限制的数据。
极限数据的作用
- 程序是否会超时
- 程序是否会越界
- 内存超限
- 溢出
构造的方法和例子
构造小数据
我们大部分构造的数据都是小数据,因为它方便调试。
-
造数据是选择不同类型的,不是改小或者改大,改的是模型或者模式。
比如查找这道题,样例给的是测试数据如下:
11 3 1 3 3 3 5 7 9 11 13 15 15 1 3 61 2 -1分析这三个数的模式:
1是找得到且只有一个3是找得到且有多个6是找不到
那如果我们改成1,3,8,等于没改,模式是一样的。
我们可以改成4,6,8,这是三个都找不到的测试数据,也可以改成3个都找得到,2个找得到且有多个,等等。
-
多考虑边界情况和特殊数据。
如果我们只是对着样例去想做法,那很容易忽略边界情况。比如这道题里,可能给的n个数都相等、或者没有重复出现的数,或者只有一个数等等,这些都是特殊的数据。对于我们的算法,这些数据当然统统都能通过,就是可能会超时,但对于其他的一些做法,可能它们就挂在这些特殊数据上。
构造极限数据
其实算法是否会超出时间和空间限制,是否会溢出,我们是可以分析出来的。但当你拿不准时,你可以造一些极限数据去测试。
-
验证是否超时
比如这道题,如果我输入一个长度为1e5的序列,询问1e6次,就会发现程序在本地很久才能给出结果,就说明我们的做法不够优秀,需要优化了。
-
验证是否会溢出
下面用实验5-5 归一法则来介绍一下如何造极限数据来验证溢出
-
题目如下

-
分析
这个题目的做法:输入
n,当n!=1时- 如果
n是奇数,n = 3 * n + 1 - 如果
n是偶数,n = n / 2
题目所给的
n的范围是n<=1e9,如果n定义为int且n是奇数,因为int能表示的最大整数是2147483647,大概2e9,那3*n+1就会超过int的最大数,溢出了。这是错误的代码:
// 错误代码 #include <stdio.h> #include <stdlib.h> #include <string.h> #include <math.h> #include <ctype.h> int main() { int n; scanf("%d", &n); int cnt = 0; while (n != 1) { if (n & 1) n = 3 * n + 1; else n /= 2; cnt ++ ; } printf("%d", cnt); return 0; }我们可以造可能输入的最大的奇数
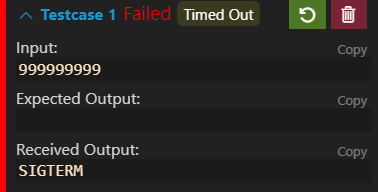
n来验证是否会溢出,即999999999,结果是发生了段错误。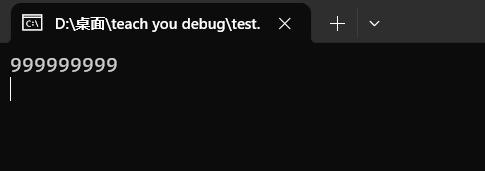
我们可以通过打印中间
n的变化来查看溢出的情况,这里就看前20次的变化吧代码如下:
#include <stdio.h> #include <stdlib.h> #include <string.h> #include <math.h> #include <ctype.h> int main() { int n; scanf("%d", &n); int cnt = 0; int print_err = 0; while (n != 1) { if (n & 1) n = 3 * n + 1; else n /= 2; if (print_err < 20) printf("n = %d\n", n), print_err ++ ; // 只看前20次的 cnt ++ ; } printf("%d", cnt); return 0; }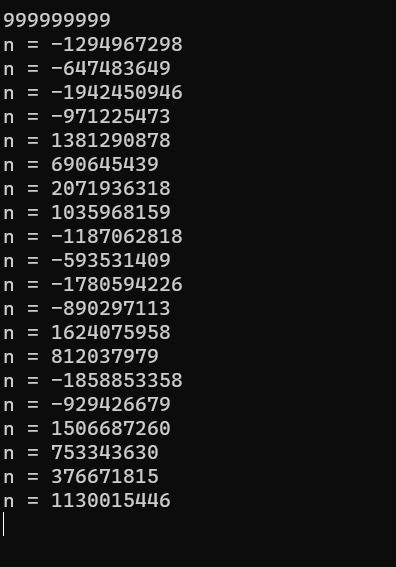
可以看到第一步就溢出了。
- 如果
-
一点说明
我给的错误代码在oj上是可以过的,原因是oj上没有给极限数据,而且测试数据中较大的数都是偶数,偶数会直接减半,也不会溢出,但这道题的数据范围确实是会爆
int的。解决方法是用long long来存。
-
认识oj错误类型
WA
答案错误(Wrong Answer,WA)
你的程序运行的结果和正确结果不同。
TLE
超时(Time Limit Exceeded,TLE)
由于每道题都会规定程序运行时间的上限,因此当超过这个限制时就会返回TLE。一般来说,这一结果可能是由算法的效率不符合要求(时间复杂度过大)而导致的,当然也可能时某组数据使得代码中某处地方死循环掉了。因此,要仔细思考最坏时间复杂度(一种评价算法效率的方法,大二的数据结构课会教,但建议同学们尽快自学了解)是多少,或者检查代码中是否可能出现特殊数据死循环的情况。
MLE
内存超限(Memory Limit Exceeded,MLE)
每道题目都有规定程序使用的空间上限,因此如果程序中使用太多的空间,则会返回MLE,例如数组太大一般最容易导致这个结果。
RE
运行时错误(Runtime Error,RE)
这一结果的可能性非常多,常见的有段错误(直接的原因时非法访问了内存,例如数组越界,指针乱指),浮点错误(例如除数为0,模数为0),递归爆栈(一般由递归时层数过深导致的)等。一般来说,需要先检查数组大小是否比题目的数据范围大,然后再去检查可不可能有特殊数据可以使除数或者模数为0,有递归的情况则检查是否在大数据时递归层数太深。
段错误
段错误(Segmentation fault)
这是RE的一种
PE
格式错误(Presentation Error,PE)
你的输出结果是正确的,但格式不正确,可能是你多输出或少输出了空格、Tab(\t)、换行(\n)等,请检查你的程序输出。
CE
编译错误(Compile Error,CE)
你的程序不能通过编译。
可能你会问:为什么我得到了CE?而在我的电脑上运行的很好?
两点原因:
-
c语言标准不一样,一些函数在
c99上可以用,c11就会报错,比如gets -
编译器不一样,不同的编译器之间有一些语法的差异。比如你用的是
gcc,然后提交题目的时候选了clang,可能就会CE这是一个oj上可选的截图,可以看到,编译C文件,有两种选择,你选的要和本地保持一致。
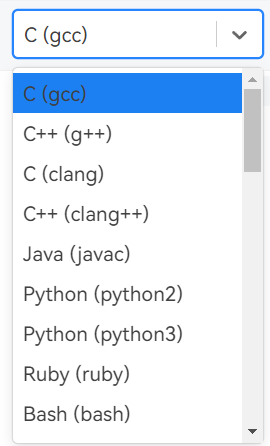
debug的技巧
技巧1:assert
函数解释
assert是定义在头文件<assert.h>中的一个函数,它的函数原型如下:
void assert(int expression);
-
参数:
assert函数的参数是一个表达式。那C语言里的表达式有很多种,比如逻辑表达式、算术表达式和关系表达式等。实际上,assert函数只要求括号里的东西的执行结果是一个数即可。assert(1 < 2); // 关系表达式 assert(1 && 2); // 逻辑表达式 assert(1 + 2); // 算术表示式 assert(0); // 一个数 int f() { printf("this is a function for testing."); return 1; } assert(f()); // 合法的,只要函数是返回一个可以判断真(不等于0)假(等于0)的数即可。其实相当于int res = f(); assert(res); void ff() { printf("this is a function for test"); } assert(ff()); // 编译错误,ff函数的返回值是空的,不能判定真假 -
行为
assert函数会执行传递给它的表达式,然后根据执行的结果,有两种情况:-
如果结果为真(不等于0),什么都不做,程序继续往下执行。但注意此时作为参数的表达式是确确实实被执行过一次了。因此在使用
assert时,作为参数的表达式不能对后面的运算产生影响。int c = 1; assert(c ++ ); // ++是先用再加,所以相当于assert(1),1为真,什么都不做 printf("%d", c); // 输出2,在assert中执行c++造成的。 -
如果结果为假(等于0),
assert函数报错,程序直接退出。报错的格式如下:
Assertion failed: expression, file filename, line line numberexpression:作为参数的表达式,其实把我们传给它的表达式照抄。filename:报错所在的文件的路径。line number:报错的assert语句所在的行号。这个行号就是我们想要的。
-
应用
总的来说,assert函数的作用就是捕捉程序里的错误,不能干扰程序的运行结果。
使用assert的核心原则是:用于处理绝不应该发生的情况
比如说,我们断言一个结论一定是正确的,我们把这个结论放在assert里,如果它确实始终是正确的,那程序就正常执行完毕,否则报错退出,并且我们可以知道报错在哪一行。
-
用
assert来判断变量的值是否符合要求// 这份代码读入一个n,输出100/n的结果 #include <stdio.h> #include <assert.h> int main() { int n; scanf("%d", &n); assert(n); // 0不能做除数,因为我们可以用assert的参数表达式的结果是假就会报错并终止程序的功能,先判断一下n是不是0。如果是0,就会报错退出,不会执行后面的语句了。 int res = 100 / n; printf("%d", res); return 0; }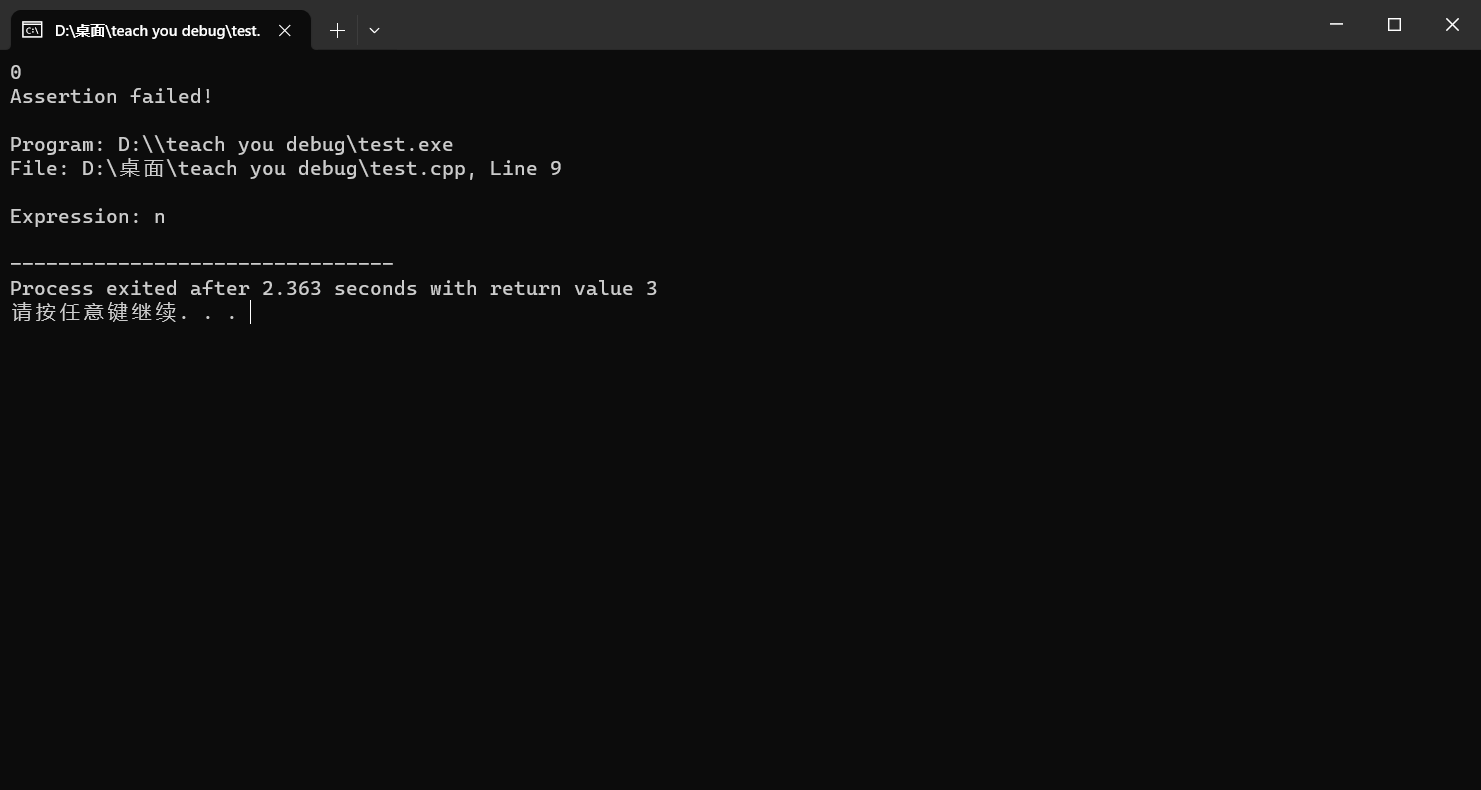
-
用
assert来判断变量的大小关系#include <stdio.h> #include <assert.h> int main() { int a = 1, b = 2; // 中间的语句改变了a和b的值 // 假如我们通过分析题目,认为经过上面的运算后,a一定大于b了 // 可以assert来验证我们的猜想 assert(a > b); // 继续执行其他语句 return 0; } -
assert(0)一定会报错退出,我们可以用它来验证程序是否执行到了assert(0)所在的行。这里用实验5-1 解铃还须系铃人来举例。
// 做法是,扫描读入的字符串的每个字符,输出它处理后的结果。 #include <stdio.h> #include <stdlib.h> #include <string.h> #include <math.h> #include <ctype.h> #define N 10010 char s[N]; char get(char c) // 字符c有三种情况 { if (c >= 'A' && c <= 'Z') return 'A' + 25 - (c - 'A'); else if (c >= 'a' && c <= 'z') return 'a' + 25 - (c - 'a'); else return c; // 这里漏写了就不对了,用assert(0) } int main() { fgets(s, N, stdin); for (int i = 0; s[i]; i ++ ) printf("%c", get(s[i])); return 0; }
NDEBUG
正如前面所说,assert是用来捕捉程序的错误的,不影响程序的结果。因此在正常的程序里不应该存在assert语句。
我们可以通过宏定义#define NDEBUG,使程序中的所有assert失效,就相当于把它们统统注释掉了。这为我们调试代码提供了很大的方便,因为我们在提交给oj评测时,不需要把我们写的assert一个一个注释或删除,直接在最前面宏定义一下即可。
注意:#define NDEBUG要写在#include <assert.h>之前才有用。
#define NDEBUG // 写了这行,下面的assert都相当于没写。
#include <stdio.h>
#include <assert.h>
int main()
{
int a, b;
scanf("%d%d", &a, &b);
assert(a);
assert(b);
assert(a < b);
assert(a + 1 < b + 2);
.....
return 0;
}
使用建议
-
assert()中的表达式要简单,最好不要把多个条件写在一起,那样就不能判断是哪个条件为假了,可以分开写多行,根据行号判断。// 断言a一定大于0,b一定小于0 assert(a > 0 && b < 0); // 不太好 // 修改 assert(a > 0); assert(b < 0); -
assert中的表达式,应该正常情况下为真,也就是说,我们断言它是对的。// 我们希望a始终大于0,验证是否正确 assert(a > 0); -
警惕
asssert陷阱:assert里不要写对有实际影响的表达式,因为在定义了NDEBUG后,这个语句就相当于没写。有的oj会在评测时帮你定义NDEBUG。
技巧2:二分、注释代码
-
二分
可以用二分法定位代码错误。
把代码分成两部分 前一半有没有错? 有错 -> 找到了 没错 -> 错误在后一半,对后一半继续二分 -
注释代码
这个方法一般在程序发生运行错误或段错误时使用,具体的表现是程序在终端一直卡着不动,不退出也不输出结果。
程序运行错误一定是一部分代码出了问题,我们可以将代码分成几块,逐块注释代码,注释后看程序是否正常退出。如果是,说明我们注释的那段代码有问题。
也可以在某个变量出现了意想不到的值时使用,注释掉分批注释代码,看是哪行代码改变了它的值。
注释代码可以结合二分法,对于很长的代码,这个方法找到
RE的代码挺有效的。 -
例子
注意:这个例子过于简单了,只是示意性的演示
在输入的n个整数中找到k个大于5的数,并输出。
输入有两行,第一行两个整数,分别是n,k;第二行是n个整数。
样例输入: 5 2 1 6 6 3 4 样例输出: 6 6错误代码,这份代码会导致运行错误。可以通过注释法找到错误的位置。
#include <stdio.h> #include <stdlib.h> #include <string.h> #include <assert.h> #define N 110 int a[N]; int main() { int n, k; scanf("%d%d", &n, &k); for (int i = 0; i < n; i ++ ) scanf("%d", &a[i]); int cnt = 0, i = 0; while (cnt < k) { if (a[i] > 5) { cnt ++ ; printf("%d ", a[i]); } } return 0; }正确代码
#include <stdio.h> #include <stdlib.h> #include <string.h> #include <assert.h> #define N 110 int a[N]; int main() { int n, k; scanf("%d%d", &n, &k); for (int i = 0; i < n; i ++ ) scanf("%d", &a[i]); int cnt = 0, i = 0; while (cnt < k) { if (a[i] > 5) { cnt ++ ; printf("%d ", a[i]); } i ++ ; // 错误代码漏了这行 } return 0; }
技巧3:小黄鸭调试法
此概念是参照于一个故事。故事中程序大师随身携带一只小黄鸭,在调试代码的时候会在桌上放上这只小黄鸭,然后详细地向鸭子解释每行代码。
许多程序员都有向别人提问及解释编程问题的经历,而对象甚至可能是完全不懂编程的人。而就在解释的过程中,程序员可能就发觉了问题的解决方案。一边阐述代码的意图,一边观察它实际上的行为并做调试,两者间的任何不协调都会变得更明显,使人更容易发现错误所在。
我们可以通过给同学讲述我们的代码来发现错误。
技巧4:宏定义
前面介绍过输出检验的方法。如果每次输出都要写很多printf,改好后又要一行一行的删掉,挺麻烦的。我们可以输出语句定义成宏。
示例如下:
#define LOCAL
#ifdef LOCAL
#define dbg(...) fprintf(stderr, __VA_ARGS__)
#define debug(x) fprintf(stderr, ""#x" = %d", x)
#else
#define dbg(...)
#define debug(x)
#define NDEBUG
#endif
#include <stdio.h>
int main()
{
return 0;
}
这里涉及到的知识有:
- 条件编译
#ifdef、#else、endif - 用宏参数创建字符串:
#运算符 - 变参宏:
...和__VA_ARGS__ assert和NDEBUG- 标准错误
stderr
具体的原理请看宏定义技巧相关知识原理_from c primer plus这个文件里的讲解。
具体的应用
#define LOCAL
#ifdef LOCAL
#define dbg(...) fprintf(stderr, __VA_ARGS__)
#define dbgl(...) fprintf(stderr, "line(%d): ", __LINE__), fprintf(stderr, __VA_ARGS__)
#define debug(x) fprintf(stderr, ""#x" = %d\n", x)
#else
#define dbg(...)
#define debug(x)
#define NDEBUG
#endif
#include <stdio.h>
int main()
{
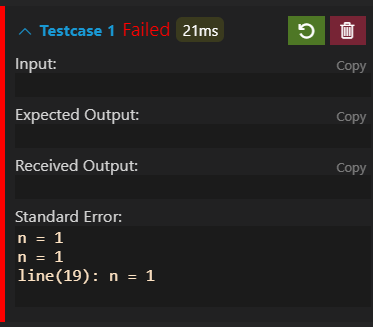
int n = 1;
debug(n);
dbg("n = %d\n", n);
dbgl("n = %d\n", n);
return 0;
}
技巧5:输入输出重定向、文件对比
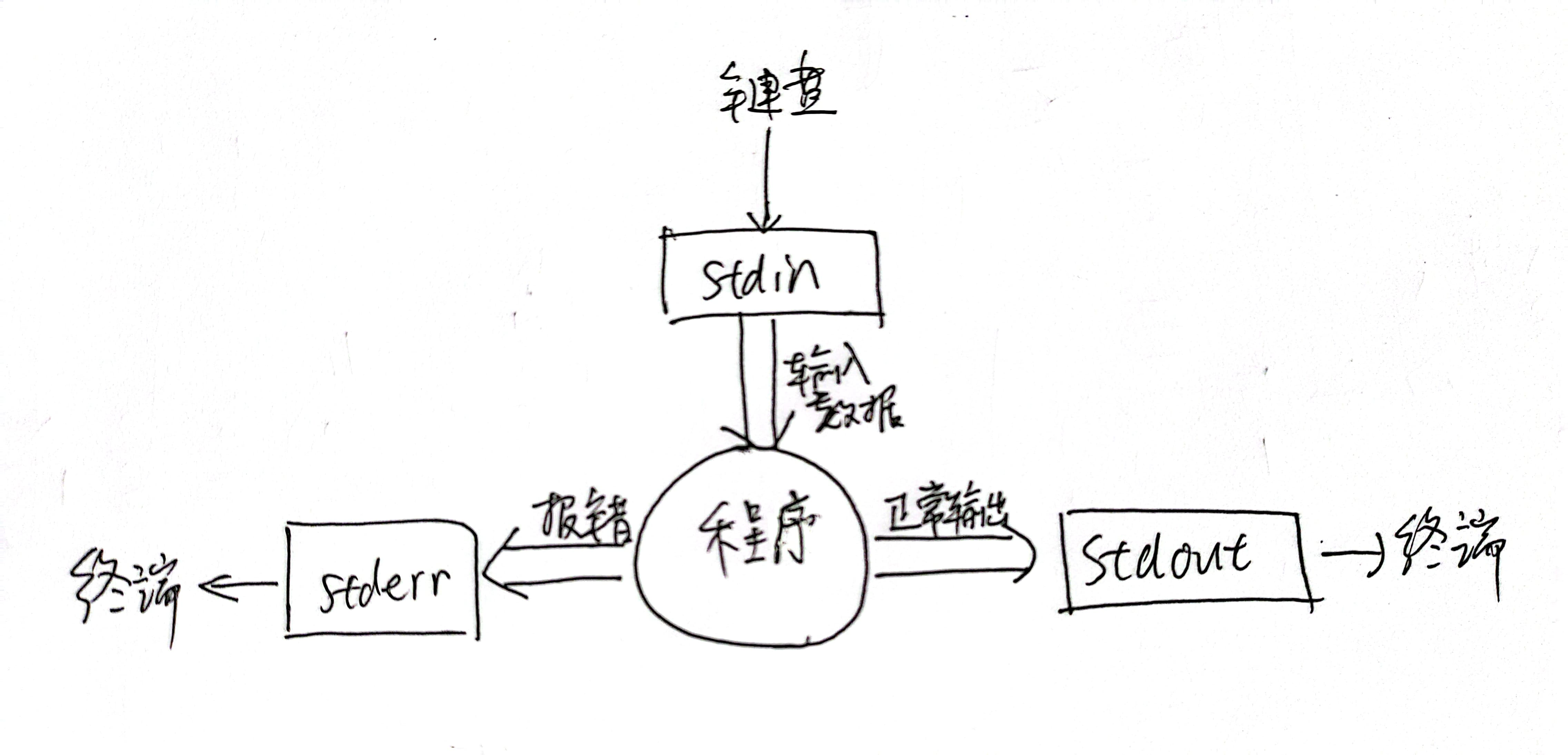
认识标准输入、标准输出、标准错误
在讲输入输出重定向前,需要先来了解一个程序运行后与它关联的三个“流”。“流”的概念这里就不讲了,具体到在终端运行程序来看就是:
| 类型 | 默认情况 |
|---|---|
| 标准输入(standard input) | 从键盘获得输入 |
| 标准输出(standard output) | 输出到屏幕(即控制台) |
| 标准错误(standard error) | 输出到屏幕(即控制台) |
程序从标准输入里读数据,正常的输出语句会输出到标准输出,报错信息会输出到标准错误。
重定向
某些情况下,从键盘输入是不方便的,输出到终端也不方便查看结果,报错信息和正常输出混在一起也不利于我们区分,所以我们需要重定向。
重定向的方法:
-
freopen函数freopen 是将原本需要从键盘( stdin)导入或导出到屏幕( stdout)的文本,重定向到文件中,便于编辑和阅读。因此可以利用 freopen 生成测试输入文件,利用 freopen 将输入文件导入到程序中,利用 freopen 将输出导出到文件中,便于阅读比较。
原型如下:
FILE * freopen ( const char * filename, const char * mode, FILE * stream );解释:
- 参数1:重定向到哪里,通常是一个我们自己创建的文件的名字
- 参数2:对那个文件的访问模式,一般使用两种取值
"r":打开一个用于读取的文件。该文件必须存在。"w":创建一个用于写入的空文件。如果文件名称与已存在的文件相同,则会删除已有文件的内容,文件被视为一个新的空文件。
- 参数3:要重定向哪个“流”
stdin:重定向标准输入stdout:重定向标准输出stderr:重定向标准错误
示例程序如下ISBN 号码
#include <stdio.h> int main() { freopen("P1055_4.in", "r", stdin); freopen("output.out", "w", stdout); int res = 0, cnt = 1; char map[15] = "0123456789X"; char a[20] = {0}; scanf("%s", a); for (int i = 0; i < 11; i++) { if (a[i] >= '0' && a[i] <= '9') res = res + (a[i] - '0') * (cnt++); } if (a[12] == map[res % 11]) printf("Right"); else { a[12] = map[res % 11]; printf("%s", a); } return 0; }提交的时候记得把
freopen注释掉 -
命令行重定向符
< input.in:将标准输入重定向为文件input.in> output.out:将标准输出重定向为文件output.out
program.exe(编译产生的可执行文件) < input.in > output.out注意:每次修改代码后要重新编译生成新的可执行文件。
文件对比
-
vscode文件对比功能
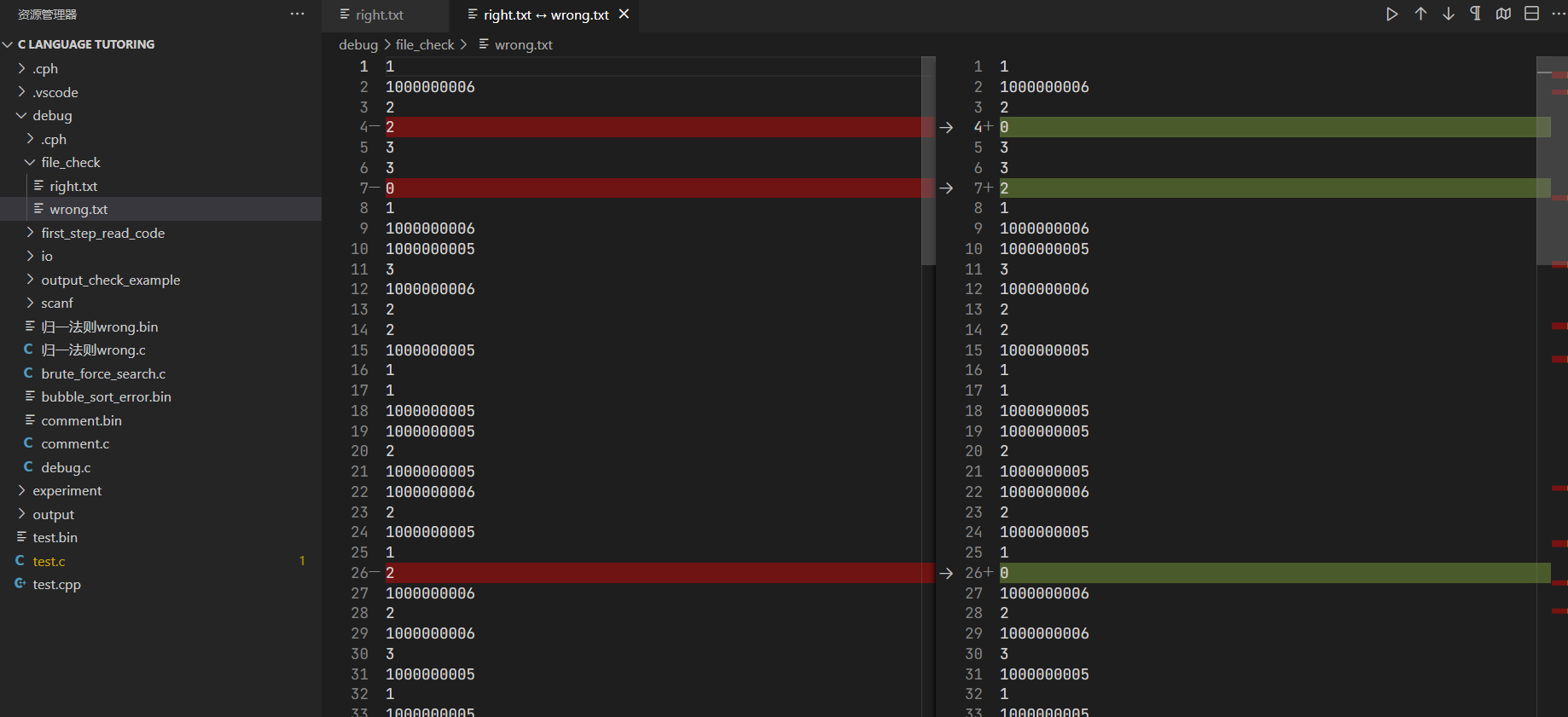
-
命令行
fc命令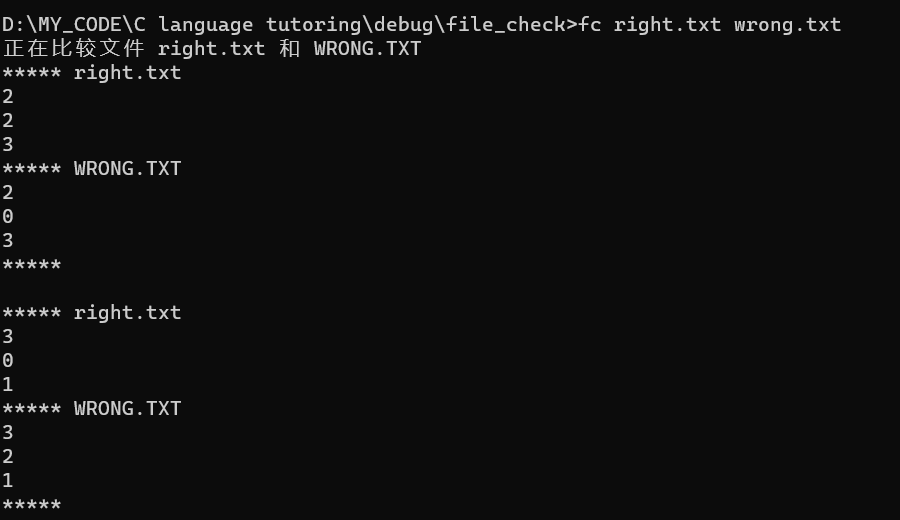
技巧5进阶:对拍
// 标准程序
#include <stdio.h>
#define N 1010
int n, m;
int f[N];
int main()
{
scanf("%d%d", &n, &m);
for (int i = 0; i < n; i ++ )
{
int v, w;
scanf("%d%d", &v, &w);
for (int j = m; j >= v; j -- )
f[j] = f[j] > f[j - v] + w ? f[j] : f[j - v] + w;
}
printf("%d\n", f[m]);
return 0;
}
// 暴力做法
#include <stdio.h>
#define N 1010
int n, m;
int v[N], w[N];
int main()
{
scanf("%d%d", &n, &m);
for (int i = 0; i < n; i ++ )
scanf("%d%d", &v[i], &w[i]);
int res = 0;
for (int i = 0; i < 1 << n; i ++ )
{
int sumv = 0, sumw = 0;
for (int j = 0; j < n; j ++ )
if (i >> j & 1)
{
sumv += v[j];
sumw += w[j];
}
if (sumv <= m) res = res > sumw ? res : sumw;
}
printf("%d\n", res);
return 0;
}
// 数据生成器
#include <time.h>
#include <stdlib.h>
#include <stdio.h>
int main()
{
freopen("input.txt", "w", stdout);
int n = 10, m = rand() % 100 + 50;
printf("%d %d\n", n, m);
for (int i = 0; i < n; i ++ )
{
int v = rand() % 50 + 10, w = rand() % 50 + 10;
printf("%d %d\n", v, w);
}
return 0;
}
// 对拍器
#include <stdio.h>
#include <stdlib.h>
int main()
{
for (int i = 0; i < 100; i ++ )
{
printf("iteration: %d\n", i);
system("datamaker.exe > input.txt");
system("Dp.exe < input.txt > dp_output.txt");
system("force.exe < input.txt > force_output.txt");
if (system("fc dp_output.txt force_output.txt"))
{
printf("错啦!");
break;
}
}
return 0;
}
debug案例
案例1:scanf
scanf读字符串的时候要非常注意,最好输出出来看看自己读到了什么
// 错误
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define M 110
int main()
{
int n;
scanf("%d", &n);
printf("%d\n", n);
for (int i = 0; i < n; i ++ )
{
char ls, rs;
scanf("%c %c", &ls, &rs); // scanf %s 自动忽略空白符
printf("%c %c\n", ls, rs);
}
return 0;
}
// 正确
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define M 110
int main()
{
int n;
scanf("%d ", &n); // 加空格
printf("%d\n", n);
for (int i = 0; i < n; i ++ )
{
char ls, rs;
scanf("%c %c ", &ls, &rs); // 加空格
printf("%c %c\n", ls, rs);
}
return 0;
}
// 更好
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define M 110
int main()
{
int n;
scanf("%d", &n);
printf("%d\n", n);
char ls[M], rs[M];
for (int i = 0; i < n; i ++ )
{
scanf("%s %s", ls, rs); // scanf %s 自动忽略空白符
printf("%s %s\n", ls, rs);
}
return 0;
}
案例2:for循环
-
--和++#define LOCAL #ifdef LOCAL #define dbg(...) fprintf(stderr, __VA_ARGS__) #else #define dbg(...) #define NDEBUG #endif #include <stdio.h> #include <stdlib.h> #include <string.h> #include <math.h> #include <ctype.h> #include <assert.h> typedef long long ll; int main() { int n; scanf("%d", &n); for (int i = n; i >= 0; i ++ ) // 错了 printf("%d", i); return 0; } -
内外混用
#define LOCAL #ifdef LOCAL #define dbg(...) fprintf(stderr, __VA_ARGS__) #else #define dbg(...) #define NDEBUG #endif #include <stdio.h> #include <stdlib.h> #include <string.h> #include <math.h> #include <ctype.h> // 谁是最佳歌手 // typedef long long ll; #define N 110 int a[N]; int main() { int T; scanf("%d", &T); while (T -- ) { int n; scanf("%d", &n); for (int i = 0; i < n; i ++ ) scanf("%d", &a[i]); for (int i = 0; i < n - 1; i ++ ) { for (int j = 0; j < n - i - 1; j ++ ) { if (a[i] > a[i + 1]) // 错了 { int t = a[i]; a[i] = a[i + 1]; a[i + 1] = t; } } } double sum = 0; for (int i = 1; i < n - 1; i ++ ) sum += a[i]; printf("%.2lf\n", sum / (n - 2)); } return 0; }
案例3:两个变量互相更新
题目:
输入x和y,用以下两个公式更新x和y,输出更新后的x和y
x = x * 2 + y * 3;
y = x * 3 + y * 2;
// 错误代码
#define LOCAL
#ifdef LOCAL
#define dbg(...) fprintf(stderr, __VA_ARGS__)
#else
#define dbg(...)
#define NDEBUG
#endif
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <math.h>
#include <ctype.h>
#include <assert.h>
typedef long long ll;
int main()
{
int x, y;
scanf("%d%d", &x, &y);
x = x * 2 + y * 3;
y = x * 3 + y * 2;
printf("%d %d", x, y);
return 0;
}
// 正确代码
#define LOCAL
#ifdef LOCAL
#define dbg(...) fprintf(stderr, __VA_ARGS__)
#else
#define dbg(...)
#define NDEBUG
#endif
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <math.h>
#include <ctype.h>
#include <assert.h>
typedef long long ll;
int main()
{
int x, y;
scanf("%d%d", &x, &y);
int tx = x, ty = y;
x = tx * 2 + ty * 3;
y = tx * 3 + ty * 2;
printf("%d %d", x, y);
return 0;
}
案例4:中间值溢出、爆int,爆long long
int的范围:2e9long long的范围:9e18
#include <stdio.h>
#include <limits.h>
typedef long long ll;
int main()
{
printf("int max: %d\nlong long max: %lld", INT_MAX, LLONG_MAX);
return 0;
}
所以两个大于1e5的数相乘就会爆int
怎么办?高精度
案例5:初始化和重置
- 定义了变量要及时初始化
- 该重置变量时要记得重置
结语
debug值得花时间吗?有什么意义?
值得,这是纠正自己对语法和算法错误理解的好机会
不要用手上的勤奋替代大脑的思考
不要疯狂输出检验,也不要盲目的单步调试,大脑要始终思考:
- 这一步的作用是什么
- 这个做法到底对不对
请人帮忙debug前最好格式化代码
好的格式赏心悦目
差的格式,虽然不至于影响心情,但妨碍阅读
附录
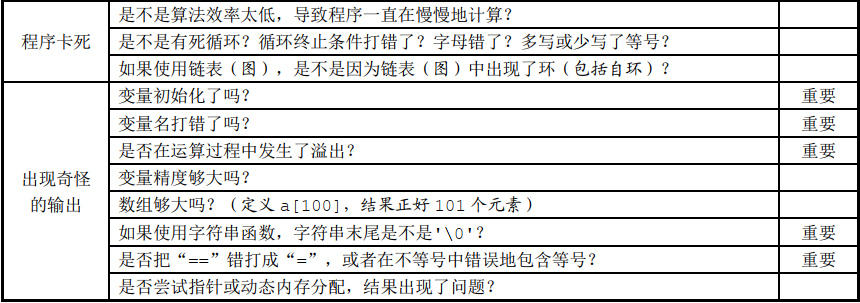
代码审查表


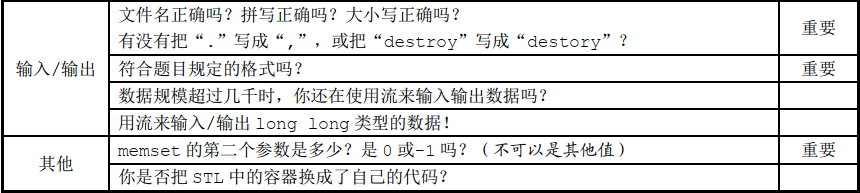
故障检查表

例题(二分查找)
题目描述
输入 \(n\) 个不超过 \(10^9\) 的单调不减的(就是后面的数字不小于前面的数字)非负整数 \(a_1,a_2,\dots,a_{n}\),然后进行 \(m\) 次询问。对于每次询问,给出一个整数 \(q\),要求输出这个数字在序列中第一次出现的编号,如果没有找到的话输出 \(-1\) 。
输入格式
第一行 \(2\) 个整数 \(n\) 和 \(m\),表示数字个数和询问次数。
第二行 \(n\) 个整数,表示这些待查询的数字。
第三行 \(m\) 个整数,表示询问这些数字的编号,从 \(1\) 开始编号。
输出格式
输出一行,\(m\) 个整数,以空格隔开,表示答案。
样例 #1
样例输入 #1
11 3
1 3 3 3 5 7 9 11 13 15 15
1 3 6
样例输出 #1
1 2 -1
提示
数据保证,\(1 \leq n \leq 10^6\),\(0 \leq a_i,q \leq 10^9\),\(1 \leq m \leq 10^5\)
本题输入输出量较大,请使用较快的 IO 方式。
