

Solr 入门配置
大多数搜索引擎应用都必须具有某种搜索功能,问题是搜索功能往往是巨大的资源消耗,并且它们由于沉重的数据库加载而拖垮你的应用的性能。这就是为什么转移负载到一个外部的搜索服务器是一个不错的注意,Apache Solr 是一个流行的开源搜索服务器,它通过使用类似 REST 的 HTTP API,这就确保你能从几乎任何编程语言来使用 Solr。
一、什么是 Solr
Solr 是一个开源搜索平台,用于构建搜索应用程序。它建立在 Lucene(全文搜索引擎)之上。Solr 是企业级的,快速的和高度可扩展的。使用 Solr 构建的应用程序架构非常复杂,可以提高性能。
Solr 可以和 Hadoop 一起使用。由于 Hadoop 处理大量数据,Solr 帮助我们从这些大量的数据中找到所需的信息。不仅限于搜索,Solr也可以用于存储。像其他 NoSql 数据库一样,它是一种非关系型数据库存储和处理技术。总之,Solr 是一个可扩展,可部署,搜索/存储引擎,优化搜索大量以文本为中心的数据。
二、Solr 安装
【1】安装 Tomcat,解压即可;
【2】解压 Solr;
【3】把 Solr 下的 dist 目录 solr-4.10.3.war 部署到 Tomcat/webapp 目录下(去掉版本号)
【4】启动 Tomcat (自动解压缩 Solr 的 war 包)
【5】把 Solr 下 example/lib/ext 目录下的所有 jar 包,添加到 Solr 的工程中(/WEB-INF/lib 目录)
cp -r /soft/solr/example/lib/ext/. /soft/apache-solr/apache/webapps/solr/WEB-INF/lib/
【6】创建 solrhome 目录(/soft/solr/solrhome) , Solr 项目下的 /example/solr 目录就是一个 solrhome。复制此目录内容到创建的 solrhome目录中
cp -r /soft/solr/example/solr/. /soft/solr/solrhome/
【7】关联 solr 及 solrhome (需要修改 Solr 工程的 web.xml 文件:主要是添加 solrhome 的路径,以下为 Linux 的安装示例)solrhome 中的 collection1 可以看做是一个数据库,
【8】启动 Tomcat :测试地址:http://IP:8080/solr/
【9】页面效果展示:
![]()
三、中文分析器 IK Analyzer
IK Analyzer 是一个开源的,基于 java 语言开发的轻量级的中文分词工具包。最初,它是以开源项目 Luence 为应用主体的,结合词典分词和文法分析算法的中文分词组件。从3.0版本开始, IK 发展为面向 Java 的公用分词组件,独立于 Lcene 项目,同时提供了对 Lucene 的默认优化实现。在2012版本中,IK 实现了简单的分词歧义排除算法,标志着 IK 分词器从单纯的词典分词向模拟语义分词衍化
IK Analyzer 配置步骤 :
【1】将 IKAnalyzer2012FF_u1.jar 添加到 solr 工程的 lib 目录中
【2】在 solr 项目的 WEB-INF 目录下创建 classes 文件夹(WEB-INF/classes),将扩展词典(mydict.dic)可以对自己定义的词语,或者网络出现的新词语,都添加到此文件中参与分析、形容词词典(ext_stopword.dic)配置文件(IKAnalyzer.cfg.xml)放置到刚才创建的目录。
【3】修改 solrhome 中的 scheme.xml 文件,配置一个 FieldType,引入 IKAnalyzer 分词器配置如下:

![]()
注意:如果传入的复制域参数中包涵空格需要将空格替换掉(.replace(" ", "")),因为空格会影响分词器的分词,导致结果出现空的问题。
四、配置域
域相当于数据库的表字段,用户存放数据,因此用户根据业务去定义相关的 Filed(域),一般来说,每一种对应着一种数据,用户对同一种数据进行相同的操作。
域的常用属性(schema.xml 配置文件中配置域):
● name:指定域的名称
● type:指定域的类型(可以是自己定义的 fieldType)
● indexed:是否索引(将用户可能作为查询字段的属性都设置为 true)
● stored:是否存储(复制域一般只用于查询,不用于存储)
● required:是否必须(相当于数据库中的非空字段)
● multiValued:是否多值(复制域就是多个字段的组合,就是需要设置为多个值)
实例:自己在项目中修改 solrhome 的 schema.xml 文件,设置业务系统的 Field 属性。为了与系统自带的 field 区分,我们命名 name 是添加前缀 item_
复制域的作用就是将一个 Field 的数据复制到另一个域中。如下:copeField 就是一个复制域,source 就是要复制的域,dest 就是目标域。目标域就是我们定义的一个用于后续查找的复制域
当系统中存在不确定的值时,例如:商品中的规格,会根据不同的商品类型(手机、电视等)进行变化。因此就需要动态扩充字段,我们就需要用到动态域来实现,需要在 schema.xml 文件中 添加如下信息以及示例展示: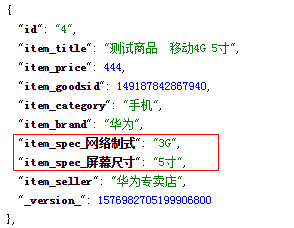
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号