

Java面试——搜索
更多内容,前往 IT-BLOG
一、Elasticsearch了解多少
ElasticSearch 是一个基于 Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于 RESTful web接口。Elasticsearch 是用 Java开发的,并作为 Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。倒排索引是实现“单词-文档矩阵”的一种具体存储形式,通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。倒排索引主要由两个部分组成:“单词词典”和“倒排文件”。
二、Elasticsearch 索引数据多了怎么办,如何调优,部署
【1】避免索引稀疏,最佳的工作方式是密集的数据。
【2】避免把无关联的数据放在同一个index:不要把完全不同的数据结构 document 放在同一个 index 里面。最好是将这些 document 放到不同的index里面,可以考虑创建一些较小的index, 用较少的shard去存储。这个建议不适用于有使用 parent/child 这种带关系的 document 放在同一个 index 的情况。
【3】标准化 document 结构:如果必需把不同类型的 document 放在同一个 index里面,也是有机会减少稀疏情况的。
【4】避免不同的 type 放在同一个index:多个 type 放在单个 index 看起来是个简单的方法。但是Elasticsearch并不是基于 type来存储的,不同的 type 在单个 index 也会影响效率。如果 type 没有非常相似的 mapping,建议考虑放到一个单独的 index 上面。
【5】使用 bulk 请求:Bulk 批量请求比单次 document 索引请求性能更好。
【6】使用多进程/多线程去发送数据到Elasticsearch。
【7】增加 refresh_interval 刷新的间隔时间:index.refresh_interval的默认值是 1s,这迫使Elasticsearch集群每秒创建一个新的 segment (可以理解为Lucene 的索引文件)。增加这个值,例如30s,可以允许更大的segment写入,减后以后的segment合并压力。
【8】在初始化索引时,可以禁用 refresh 和 replicas 数量。
【9】禁用 swapping:把操作系统的虚拟内存交换区关闭。sysctl 里面添加 vm.swappiness = 1。
【10】确保有空闲的内存给文件系统缓存:文件系统缓存是为了缓冲磁盘的IO操作。至少确保有一半机器的内存保留给操作系统,而不是JAVA VM占用了全部内存。
【11】使用更快的硬件:当然这个不用说了上SSD是最好的了。
【12】索引 buffer 大小:如果节点在做非常大的索引动作,需要确保 indices.memory.index_buffer_size足够大,最多可以设置为512M的buffer。除此之外增加这个值,性能通常不会得到改善。
三、Elasticsearch 是如何实现 master选举的
㊤、Elasticsearch的选主是 ZenDiscovery模块负责的,主要包含Ping(节点之间通过这个 RPC来发现彼此)和 Unicast(单播模块包含一个主机列表以控制哪些节点需要ping通)这两部分。
㊥、对所有可以成为 master的节点(node.master: true)根据 nodeId字典排序,每次选举每个节点都把自己所知道节点排一次序,然后选出第一个(第0位)节点,暂且认为它是 master节点。
㊦、如果对某个节点的投票数达到一定的值(可以成为 master节点数n/2+1)并且该节点自己也选举自己,那这个节点就是master。否则重新选举一直到满足上述条件。
注意:master节点的职责主要包括集群、节点和索引的管理,不负责文档级别的管理;data节点可以关闭 http功能。
四、详细描述一下 Elasticsearch索引文档的过程
【1】协调节点默认使用文档ID参与计算(也支持通过routing),以便为路由提供合适的分片。
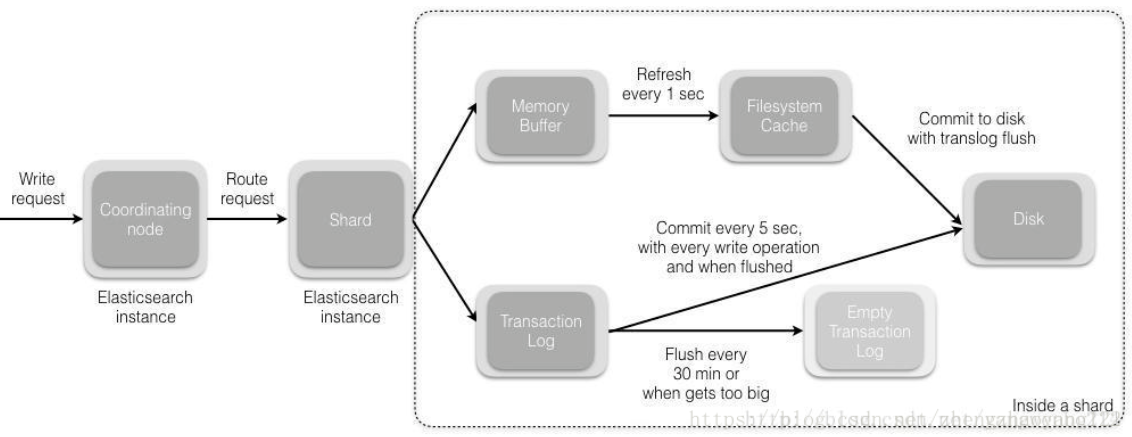
五、详细描述一下 Elasticsearch搜索的过程。
【1】搜索被执行成两阶段过程,我们称之为 Query Then Fetch
【2】在初始查询阶段时,查询会广播到索引中每一个分片拷贝(主分片或者副本分片)。 每个分片在本地执行搜索并构建一个匹配文档的大小为 from + size 的优先队列。PS:在搜索的时候是会查询Filesystem Cache的,但是有部分数据还在Memory Buffer,所以搜索是近实时的。
【3】每个分片返回各自优先队列中 所有文档的 ID 和排序值 给协调节点,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。
【4】接下来就是 取回阶段,协调节点辨别出哪些文档需要被取回并向相关的分片提交多个 GET 请求。每个分片加载并丰富文档,如果有需要的话,接着返回文档给协调节点。一旦所有的文档都被取回了,协调节点返回结果给客户端。
六、Elasticsearch 在部署时,对 Linux的设置有哪些优化方法
【1】64 GB 内存的机器是非常理想的, 但是32 GB 和16 GB 机器也是很常见的。少于8 GB 会适得其反。
【2】如果你纠结是选择更快的 CPU频率还是更多的核心之间交互时,选择核心更好。因为多个内核提供的额外并发远胜过稍微快一点点的时钟频率。
【3】如果你负担得起 SSD(固态硬盘),它将远远超出任何旋转介质。 基于 SSD 的节点,查询和索引性能都有提升。如果你负担得起,SSD 是一个好的选择。
【4】即使多个数据中心近在咫尺,也要避免集群跨越多个数据中心。绝对要避免集群跨越大的地理距离。
【5】请确保运行你应用程序的 JVM 和服务器的 JVM 是完全一样的。 在 Elasticsearch 的几个地方,使用 Java 的本地序列化。
【6】通过设置gateway.recover_after_nodes、gateway.expected_nodes、gateway.recover_after_time可以在集群重启的时候避免过多的分片交换,这可能会让数据恢复从数个小时缩短为几秒钟。
【7】Elasticsearch 默认被配置为使用单播发现,以防止节点无意中加入集群。只有在同一台机器上运行的节点才会自动组成集群。最好使用单播代替组播。
【8】不要随意修改垃圾回收器(CMS)和各个线程池的大小。
【9】把你的内存的(少于)一半给 Lucene(但不要超过 32 GB!),通过ES_HEAP_SIZE 环境变量设置。
【10】内存交换到磁盘对服务器性能来说是致命的。如果内存交换到磁盘上,一个 100 微秒的操作可能变成 10 毫秒。 再想想那么多 10 微秒的操作时延累加起来。 不难看出 swapping 对于性能是多么可怕。
【11】Lucene 使用了大量的文件。同时,Elasticsearch 在节点和 HTTP 客户端之间进行通信也使用了大量的套接字。 所有这一切都需要足够的文件描述符。你应该增加你的文件描述符,设置一个很大的值,如 64,000。
七、Lucence内部结构是什么。(大数据处理的一个基础)
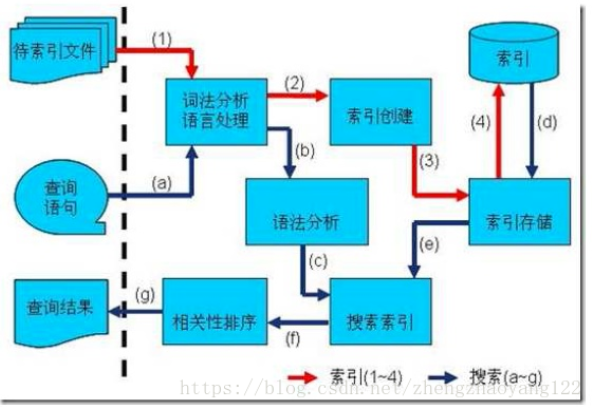
【1】索引过程:
1) 、有一系列被索引文件(索引:在Lucene中一个索引是放在一个文件夹中的。)
2) 、被索引文件经过语法分析和语言处理形成一系列词(Term:词是索引的最小单位,是经过词法分析和语言处理后的字符串)。
3)、 经过索引创建形成词典和反向索引表。
4) 、通过索引存储将索引写入硬盘。
【2】搜索过程:
a) 、用户输入查询语句。
b) 、对查询语句经过语法分析和语言分析得到一系列词(Term)。
c) 、通过语法分析得到一个查询树。
d) 、通过索引存储将索引读入到内存。
e) 、利用查询树搜索索引,从而得到每个词(Term)的文档链表,对文档链表进行交,差,并得到结果文档。
f) 、将搜索到的结果文档对查询的相关性进行排序。
g) 、返回查询结果给用户。
八、ES 存储原理
【博客链接】
九、ElasticSearch 与 Solr 的区别
【1】Solr 利用 Zookeeper 进行分布式管理,而 ElasticSearch自身带有分布式协调管理功能;
【2】Solr 支持更多格式的数据,而 ElasticSearch仅支持 JSON 格式的数据;
【3】Solr 官方提供的功能更多,而 ElasticSearch本身更注重于核心功能,高级功能多数由第三方插件提供;
【4】Solr 在传统的搜索应用中表现好于 ElasticSearch,但是在处理实时搜索应用的效率明显低于 ElasticSearch;
十、说说你们公司es的集群架构,索引数据大小,分片有多少,以及一些调优手段 。elasticsearch的倒排索引是什么

 浙公网安备 33010602011771号
浙公网安备 33010602011771号