
Profile 分析 Erlang 虚拟机源码时要注意的一个问题
最近用 Intel Vtune 剖析 Erlang 虚拟机的运行,想看看那些函数和语句耗时最多,遇到一个小问题,那就是 Vtune 给出的源码和汇编码对应有问题。这个问题在 profile 或 debug 其他程序的时候也有可能会碰到的。
看下面的例子,运行 dialyzer 的时候用 Vtune 进行采样,然后看结果:
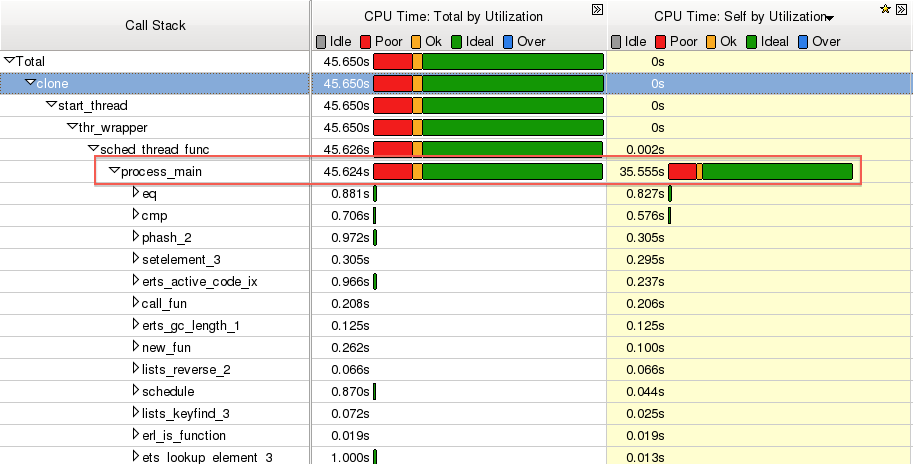
很自然,process_main 函数耗时最多,是 CPU 主要利用者,因为整个 Erlang 虚拟机的指令执行引擎都在这个函数中。那么双击这个函数,进去看详细的源代码的耗时信息,会看到奇怪的现象:
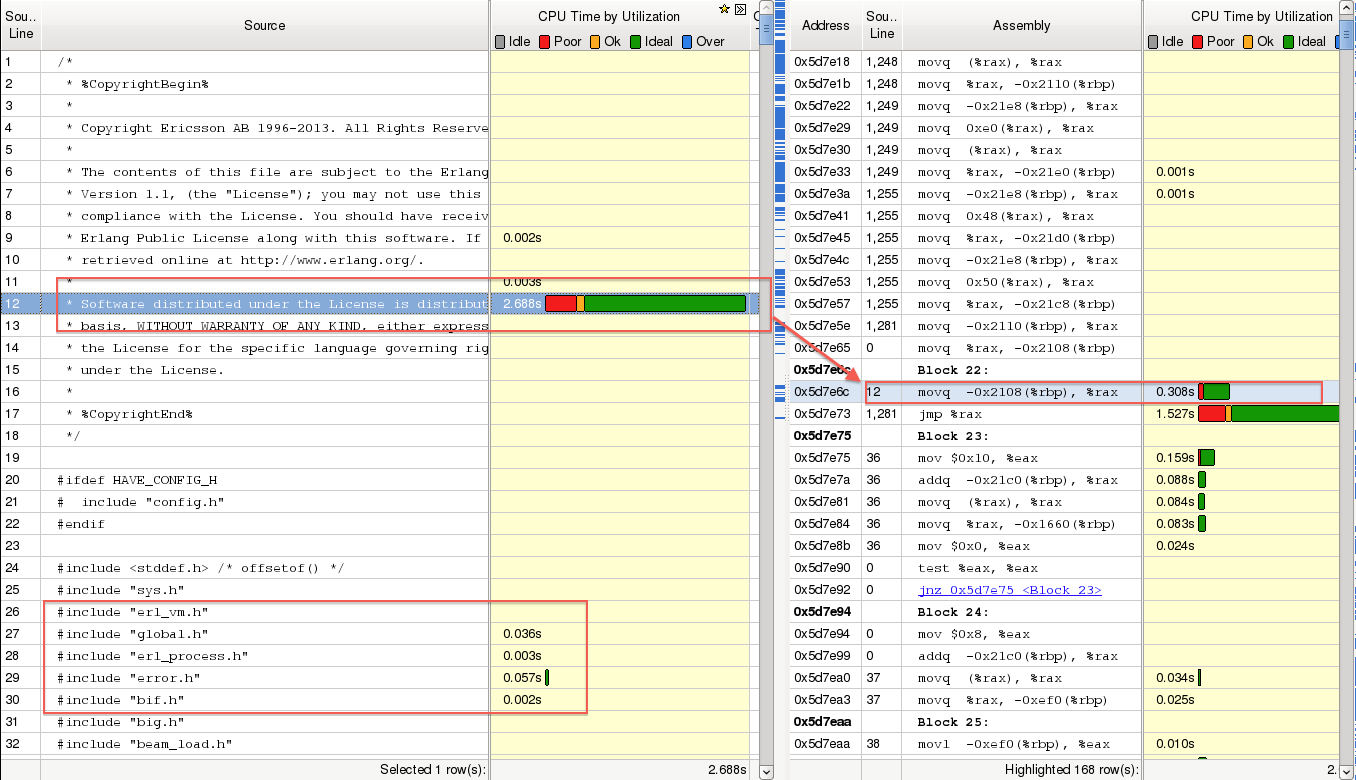
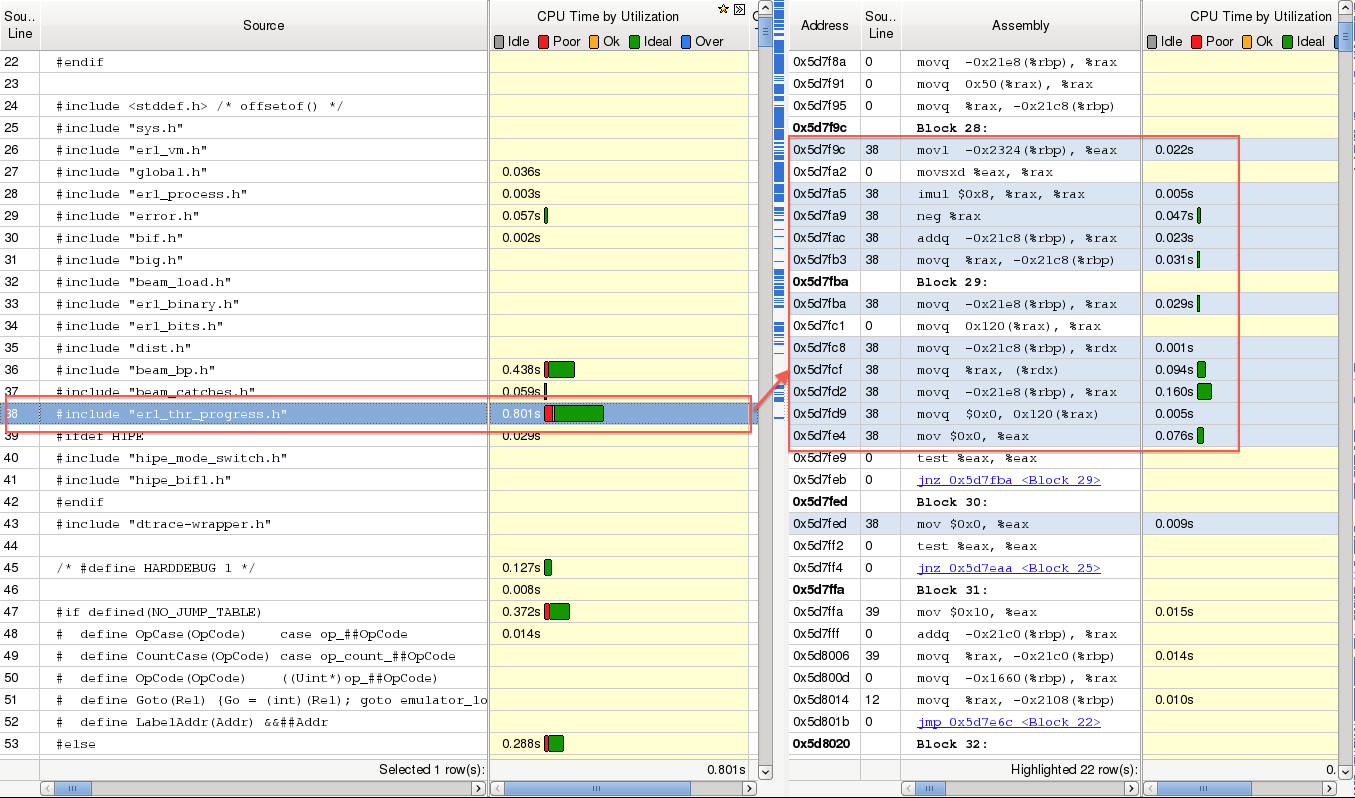
可以看到第 12 行的注释和下面的 #include 指令竟然耗时间了,更神奇的是,这些源码行还输出了汇编,比如第 12 行对应右边的 mov 指令。还有下图中,第 38 行的 #include 生成这么多汇编码也是不可能的:
这会不会是和宏展开相关呢?会不会是和编译器的优化相关呢?会不会是编译器弄错了呢?
以上问题的答案都是否定的。因为这个文件(beam_emu.c)宏展开也不会在第 12 行有代码。而且编译器不会这么笨的。优化也不可能,因为我没开优化,为了详细观察语句(对应指令)执行耗时情况,关闭了优化(-O0),而且请求编译器包含最丰富的调试信息(-g3)。也不太可能是编译器弄错了,因为 gcc 和 Intel 的 icc 都出现了这个现象,而且都是在同样的位置。假设真的是编译器弄错了,那么完全不同的编译器也不太可能会错成一样,所以感觉这里肯定是有确定性原因的。
那到底是怎么回事呢?用 objdump -S 导出目标文件 beam_emu.o 的源码和汇编码信息,可以看出编译器是很忠诚的,没有奇怪的问题,而且很显然那些注释和 #include 指令那些地方是没有输出汇编代码的,编译器既然能在目标文件中内嵌正确的源码信息,那就不太可能会弄错行号。那就看看第 12 行对应的汇编码到底对应的源码是什么。下图中框出来的 3 条汇编指令是 NextPF 宏生成的,中间那一条就是之前图中在 0x5d7e6c 处对应第 12 行的那条汇编。

那就找这几行源代码在 beam_emu.c 中对应的位置应该就可以看出究竟了。有趣的是,在 beam_emu.c 中其实找不到这几行代码。beam_emu.c 把一些热门指令的代码单独放在 beam_hot.h 文件中了,这个文件是在 build 过程中自动生成的。果然,在这个文件中看到了这段代码:

哈,找到原因了。调用 NextPF 宏的刚好是第 12 行,原来编译器记录的是被包含文件中的行数。当然这并不是编译器的处理方式不对,而是这种将源代码 #include 到另一个源代码文件中的做法本身不是一个好的编程习惯,但是鉴于 process_main 的特殊性,这有助于保持代码的简洁(尽管这样 process_main 还是有好几千行)。
注意,这里的代码映射错误的问题并不是 Vtune 的问题,Vtune 只是忠实地反映出目标文件中调试信息里面的内容,而调试信息是编译器生成的。
那么为了能在 profile 过程中准确对应到源码行,我们手工把 beam_hot.h 文件的内容(还有 beam_cold.h,对应冷门指令)拷贝到 beam_emu.c 中对应的位置并重新 build 即可。再次运行 profile,可以看出代码映射完全正确了:

对右侧的汇编指令的耗时排序:
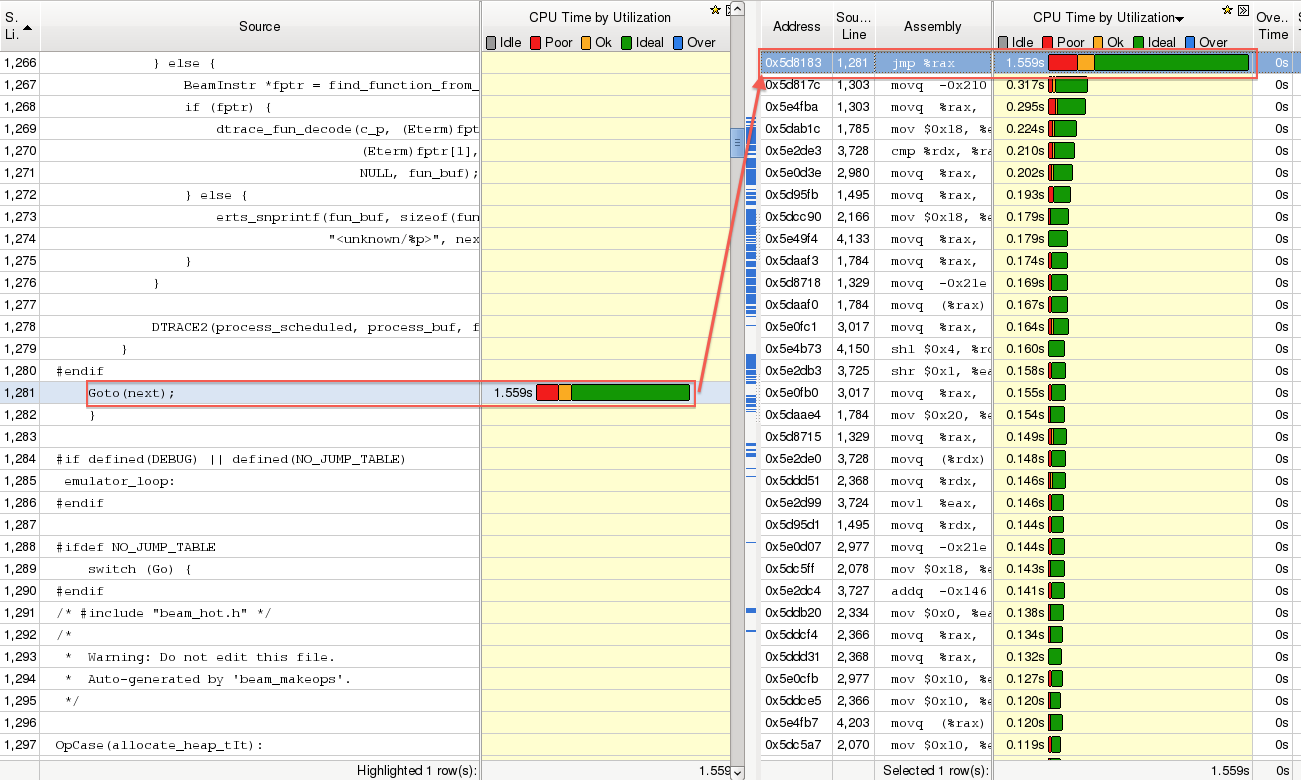
可以看出跳转指令的开销还是不小的,因为虚拟机每执行下一条指令都是一个跳转。所以 Erlang 虚拟机中的指令数目也非常多,每一条都尽量完成尽可能多的工作,以减少指令分发的次数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号