
C语言基于Linux平台实现通讯录
C语言基于Linux平台实现通讯录
简介:从产品角度出发,根据功能将该项目分层实现,同时解决在实际工程问题可能会出现的问题。
引言
作为一个产品,从通讯录应该实现的功能切入,基于功能确定该产品中数据的组织存储方式。考录到代码的功能完整和拓展性,将结构层次化为支持层、接口层、业务层。通过阶段性的代码调试实现所有的功能。
方法架构及其实现
一 功能阐述及架构
用户信息包括基本的姓名、电话等,将用户信息存储在链表结构中进行操作。使用name: nameA,phone :phoneA \n name: nameB,phone :phoneB\n ...方式将信息以文本方式存入磁盘。
该系统在业务逻辑上需要实现六个功能,作为最底层的支持层需要向接口层提供最基本操作,包括链表的增删、文件的读写。进一步将提供的支持封装在接口层,向上展示为用户增添、查找、遍历,文件解包和打包。
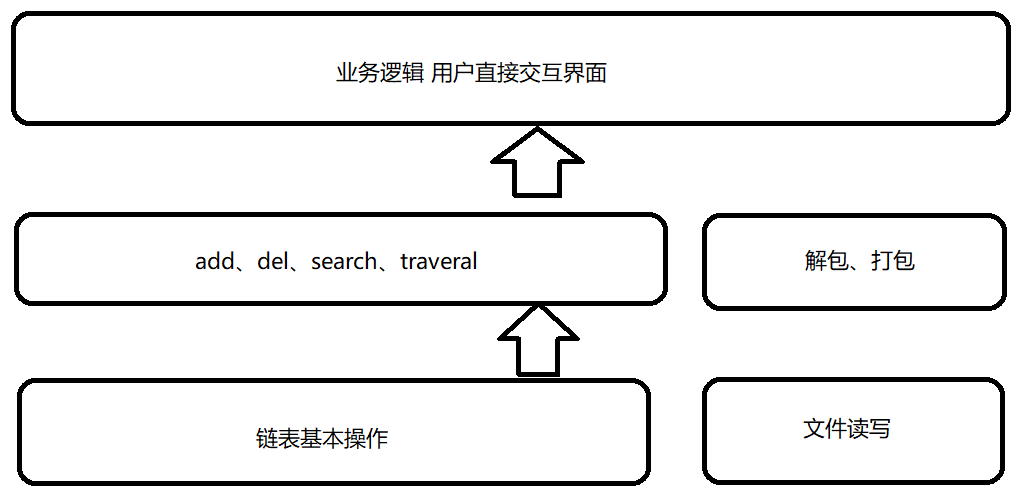
二 代码实现
- 支持层
定义用户结构体person,对于每个用户都有name、phone属性,底层使用双向链表,所以用户还额外拥前向向和后向指针prev,next。定义通讯录结构体,存储用户链表的头指针people,用户数量count。
struct person{//定于单个人的数据结构
char name[NAME_LENGTH];
char phone[PHONE_LENGTH];
struct person *next;
struct person *prev;
};
struct contacts{//定义通讯录的数据结构
struct person* people;
int count;
};
对于链表插入和删除操作使用宏定义方式,其中链表采用头插法。
//使用头插法插入节点
#define LIST_INSERT(item, list) do { \
item->prev = NULL; \
item->next = list; \
if((list) != NULL) (list)->prev = item;\
(list) = item; \
}while(0)
//删除节点
#define LIST_REMOVE(item, list) do{ \
if (item->prev != NULL) item->prev->next = item->next; \
if (item->next != NULL) item->next->prev = item->prev; \
if (list == item) list = item->next; \
item->prev = item->next = NULL; \
}while(0)
将输出,及部分数组初始值使用宏定义。
#define NAME_LENGTH 16
#define PHONE_LENGTH 32
#define INFO printf
#define BUFFER_LENGTH 128
#define MIN_TOKEN_LENGTH 5
- 接口层
基于上述代码,实现接口层。分别为person_insert、person_delete、person_search、person_traversal。在插入用户和删除用户方法中,因为需要在该函数内部修改指针指向的地址,需要获取到头节点指针的地址,此处使用二级指针。
int person_insert(struct person** ppeople,struct person* ps){
if(ps == NULL) return -1;
//获取到头节点的地址传入
LIST_INSERT(ps,*ppeople);
return 0;
}
int person_delete(struct person** ppeople,struct person* ps){
if(ps == NULL) return -1;
if (ppeople == NULL) return -2;
LIST_REMOVE(ps, *ppeople);
return 0;
}
struct person* person_search(struct person* people,const char* name){
struct person* item = NULL;
for(item = people;item != NULL;item = item->next)
if(!strcmp(name,item->name))
break;
return item;
}
int person_traversal(struct person* people){
struct person* item = NULL;
for(item = people;item != NULL;item = item->next)
INFO("name: %s,phone: %s\n",item->name,item->phone);
return 0;
}
对于文件操作,将文件读写以及解包打包合并编写在接口层中。
将用户信息保存在硬盘上方法save_file,需要用户链表头指针,及需要存入的文件名称。采用循环遍历所有用户,使用方法fprintf()将用户信息按照name: nameA,phone :phoneA \n name: nameB,phone :phoneB\n ...方式存入硬盘,fflush()将还在缓存内的数据写入磁盘中。
//将用户存储到硬盘上
int save_file(struct person* people, const char* filename){
FILE* fp = fopen(filename,"w");
if(fp == NULL) return -1;
struct person* item = NULL;
for(item = people;item != NULL;item = item->next){
//该方法类似printf 只是将数据写入文件
fprintf(fp,"name: %s, phone: %s\n",item->name,item->phone);
//将还在缓存中的数据写到硬盘上
fflush(fp);
}
fclose(fp);
return 0;
}
加载解包指定文件内用户的信息load_file,因为需要改变链表结构,参数需要用户链表的头指针地址。打开指定文件,在循环中方法feof()判断当前是否在文件结尾,准备一个固定长度的char类型数组buffer作为fgets()方法按行读取值的存储容器,对buffer中的数据进行解包操作parser_token(),返回整型值。若成功解包,向内存中申请一片新内存存储用户信息,将其插入到用户链表中。
//加载文件 此处使用二级指针 避免出现仅改变形参的情况
int load_file(struct person** ppeople,int* count,char* filename){
FILE* fp = fopen(filename,"r");
if(fp == NULL) return -1;
//feof 判断是否读到文件结尾
while(!(feof(fp))){
char buffer[BUFFER_LENGTH] = {0};
//fgets按行读取
fgets(buffer,BUFFER_LENGTH,fp);
char name[NAME_LENGTH] = {0};
char phone[PHONE_LENGTH] = {0};
int length = strlen(buffer);
if(0 != parser_token(buffer,length,name,phone)){
continue;
}
struct person* p =(struct person*)malloc(sizeof(struct person));
if(p == NULL) return -1;
memcpy(p->name,name,NAME_LENGTH);
memcpy(p->phone,phone,PHONE_LENGTH);
person_insert(ppeople,p);
(*count)++;
}
fclose(fp);
return 0;
}
处理读取数据方法parser_token(),将数据用,分隔开。对每一部分信息使用有限状态机,若当前值为空格,说明准备进入有效信息。对于,之后的数据按照同样的方法进行处理。
//处理读取到的数据
int parser_token(char* buffer,int length,char* name,char* phone){
if(buffer == NULL) return -1;
if(length < MIN_TOKEN_LENGTH) return -2;
int i = 0, j = 0, status = 0;
//使用有限状态机 处理 , 之前的数据
for(i = 0;buffer[i] != ',';i++){
if(buffer[i] == ' ')
status = 1;
else if(status == 1)
name[j++] = buffer[i];
}
//处理 , 之后的数据
j = 0,status = 0;
for(;i < length;i++){
if(buffer[i] == ' ')
status = 1;
else if(status == 1)
phone[j++] = buffer[i];
}
INFO("name ->%s,phone ->%s",name,phone);
return 0;
}
- 业务层
在该层次中,更多的是考虑与用户之间的交互,需要在每一步及时输出提示信息。使用菜单输出代表每种操作的数字,使用枚举将操作数字定义为可阅读的变量。
问题与解决方案
问题一:在用户结构体中如何做到将业务与数据结构分离?
采用嵌入式链表节点方案,将链表节点作为业务数据的成员嵌入到结构体。大大解耦了业务数据与数据结构之间的联系。
在用户数据中,将结构体修改为:
// 业务数据结构
struct person {
char name[NAME_LENGTH];
char phone[PHONE_LENGTH];
struct list_head node; // 嵌入式链表节点
};
对数据结构,定义数据结构结构体:
// 纯链表节点结构(只有前后指针)
struct list_head {
struct list_head *next;
struct list_head *prev;
};
还需定义两个关键的宏,用于实现对数据结构成员及结构体的操作。
// 计算结构体成员偏移量
#define offsetof(TYPE, MEMBER) ((size_t)&((TYPE *)0)->MEMBER)
// 从链表节点指针获取包含它的结构体指针
#define container_of(ptr, type, member) ({ \
const typeof(((type *)0)->member) *__mptr = (ptr); \
(type *)((char *)__mptr - offsetof(type, member)); })
offsetof:计算结构体中某个成员相对于结构体指针的偏移量,该值是一个相对偏移量。((TYPE *)0),创建一个指向0地址的TYPE类型指针,->MRMBER,访问该结构体中的成员,&((TYPE *)0)->MRMER,取到该成员的偏移量。
container_of:该方法有三个参数,ptr:结构体成员的指针、type:外层结构体类型(、member:成员在结构体中的名称。const typeof(((type *)0)->member) *__mptr = (ptr);,这一步进行类型的安全检查,生成一个于member同类型的指针赋值给ptr进一步确保了类型的准确性。(type *)((char *)__mptr - offsetof(type, member)),(char *)__mptr因为char类型指针仅占一个字节,便于计算偏移量。offsetof(type, member),取到该成员在结构体起始地址的相对位置,最后从该位置回退偏移量长度回到结构体起始位置。
如上述代码,所示定义一个person初始化后获取外层结构体指针:
struct person p = {"Alice", "123456", {NULL, NULL}};
struct list_head *node_ptr = &p.node; // 已知成员指针
// 使用 container_of 获取外层结构体指针
struct person *person_ptr = container_of(node_ptr, struct person, node);
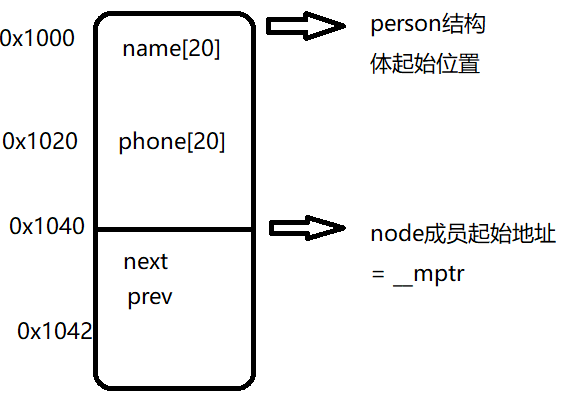
container_of方法就是通过得到__mptr的位置0x1040,取到其相对于person结构体的相对偏移量,此处为40,计算得到person结构体的其实地址,即该结构体的指针。
问题二:如何解决加载时最后一个为空的数据仍被解包并插入用户链表
因为数据是按行读取,读到最后一行数据为空,传入parser_token仍然被解包为一个用户插入。所以只需要在解包时判断该数据的长度,若小于某个值,则直接退出。
问题三:scanf方法若传入的字符过长会出现溢出问题,如何解决?
使用限定长度的缓存数组,在scanf的格式字符串中限定最长字符宽度,如scanf("%9s", buffer)限定最大读取9个字符。
问题四:按照用户首字母储存数据
引入一个新的数组,该数组长度为26,分别表示字a-b。在插入用户时,将用户首字母提取,通过ASCII码统一转换为小写,通过计算与字母a的相对位置,往相对应索引的位置插入用户。遍历依次按照索引将所有的用户遍历输出即可。
总结
从通讯录项目出发,在熟悉C语言基础的同时,对产品如何组织并形成统一的架构有了进一步的认识。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号