

使用有限状态机实现文件单词数量统计
使用有限状态机实现文件单词数量统计
简介:使用状态机规避了复杂的分支,将文本分为两种情况,使得单词数量统计更为简便。
引言
使用C语言读取文件,统计该文件中所有单词的数量。引入有限状态机,将文本一共分为两种状态:单词内部、单词外部。省略掉了繁杂的情况判断,只需要考虑两状态之间的转换。同时在编程中考虑到了一些工程问题,针对这些问题提出了一些简单的解决方案。
方法架构及实现
一 有限状态机
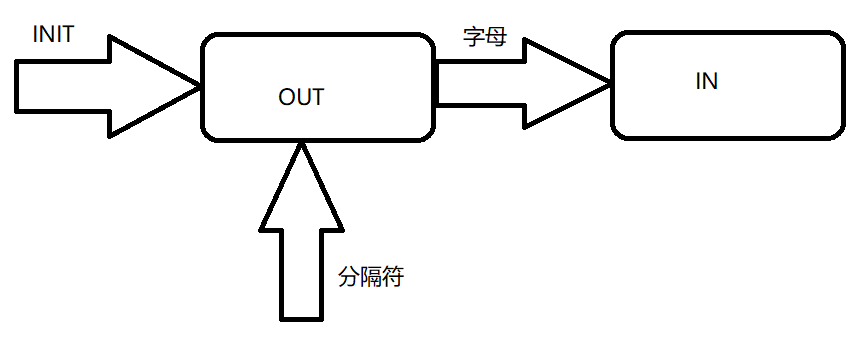
将文本视为由字母和分隔符组成,也即是说,有限状态机共有两种状态:单词内部(IN),单词外部(OUT)。初始将状态设置为文本外部OUT。仅当文本指针值为字母时,状态应为IN,表明此时指针进入了单词内部。除此之外指针遍历到任何非字母的符号,都认为是遍历到了非单词的状态,状态体现为OUT。状态机相关状态转换如下所示:
二 代码实现
为提高文件的可读性,将表示状态的整型使用宏定义起别名:
#define OUT 0
#define IN 1
#define INIT OUT
声明方法count_word,传入表示文件名称的字符数组常量指针,返回整型单词数量。方法中定义整型变量status初始化为单词外部值INIT。声明文件指针类型fp以只读方式打开指定名称的文件。循环使用char类型变量c接受文件指针遍历读取到的字符,当且仅当文件指针读取到文件末尾即文件指针值为EOF时退出循环。在循环内部通过条件语句判断当前字符是否为分隔符,若为真则将状态值设为OUT。在循环中若当前不再单词中,且当前字符不是分隔符则说明进入单词,status = IN同时单词数量加一。最后关闭文件指针并返回单词数量。
int count_word(const char* fileName){
int status = INIT;
FILE *fp = fopen(fileName,"r");
if(fp == NULL)
return -1;
char c;
int count = 0;
while((c = fgetc(fp)) != EOF){
if(splite(c)){
status = OUT;
}else if(OUT == status){
//本质上就是记录从OUT -> IN一共有几次
status = IN;
count++;
}
}
fclose(fp);
return count;
}
但考虑到多种分割符的情况,单独将判断当前字符是否为分隔符抽象为方法splite将所有分隔符的情况囊括在其中。
int splite(char c){
if(c == ',' || c == '.' || c == '!' ||
c == '?' || c == ';' || c == ':' || c == '(' ||
c == ')' || c == '"' || c == '\n' || c == '\t' ||
c == '\'')
return 1;
else
return 0;
}
问题与解决方案
问题一:如何进一步优化统计分隔符的方案?
使用C语言自带判断是否为字母方法,或使用ASCII码直接判断当前指针值是否为字母,将结果取反即可。
int is_separator(char c) {
return !isalpha(c); // 非字母字符返回1(是分隔符),字母返回0
}
问题二:如何统计特殊情况某一个单词中间被截断换行?
当一个单词被截断换行后,表示为符号-后紧跟一个换行符\n,所以引入一个新的状态机标记是否遇到连字符换行情况,使用char类型变量last_char记录上一次的字符。在符号判断中允许-作为字母的一部分。当且仅当last_char == '-' && c == '\n'时,单词数量加一。
while ((c = fgetc(fp)) != EOF) {
if (is_word_char(c)) {
if (status == OUT) {
status = IN;
// 如果前一个字符是连字符且换行,则不计为新单词
if (!(last_char == '-' && c == '\n')) {
word_count++;
}
}
// 标记连字符后的换行
if (c == '-') {
hyphen_break = 1;
} else {
hyphen_break = 0;
}
} else {
status = OUT;
// 如果是换行且之前有连字符,暂时不增加计数
if (c == '\n' && hyphen_break) {
hyphen_break = 0;
continue;
}
}
last_char = c;
}
问题三:如何统计每个单词出现的次数?
对于大量重复值,将单词作为key值,出现的次数作为value值组织一个哈希表。最后依次遍历该哈希表即可得到所有单词出现的次数。
int countWords(const string &filename) {
ifstream file(filename);
if (!file.is_open()) return -1;
unordered_map<string, int> wordCount;
string word;
char c;
while (file.get(c)) {
if (isalpha(c)) {
word += tolower(c); // 转为小写
} else if (!word.empty()) {
wordCount[word]++;
word.clear();
}
}
// 处理最后一个单词
if (!word.empty()) {
wordCount[word]++;
}
// 输出结果
for (const auto &pair : wordCount) {
cout << pair.first << ": " << pair.second << endl;
}
}
总结
在工程中往往采用状态机作为解决问题的方法,但具体应用到代码中需要考虑更多的边界条件,通过不断的积累代码来保持对边界条件的敏感。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号